大模型在新能源汽车行业的应用与实践
本次分享的主题为大模型在汽车工业化的实践与应用,主要聚焦于工业制造相关的案例和落地经验。总共分为五部分:1. ChatGPT 发展历程;2. 大模型底层原理;3. 大模型赋能新型工业化;4. 工业化中的实践与探索。
01 ChatGPT 发展历程
首先为大家简单梳理下 ChatGPT 的发展历程。

早在 2018 年 OpenAI 就发布了 GPT,但是从 GPT-1 到 GPT-3 生成模型的效果并不是很理想。直到 GPT-3.5 开始,生成模型完成了 NLP 各种问题的统一解法,在生成文本、回答问题、翻译文本等方面具有非常出色的表现,甚至在一些任务上能够达到人类水平。同时 ChatGPT 可以直接使用自然语言的方式进行交互,更加符合人的习惯,随着发展,GPT4 支持多模态输入,能够完成看图作答、角色扮演、图表分析、编程、专业考试等各种各样的复杂任务。
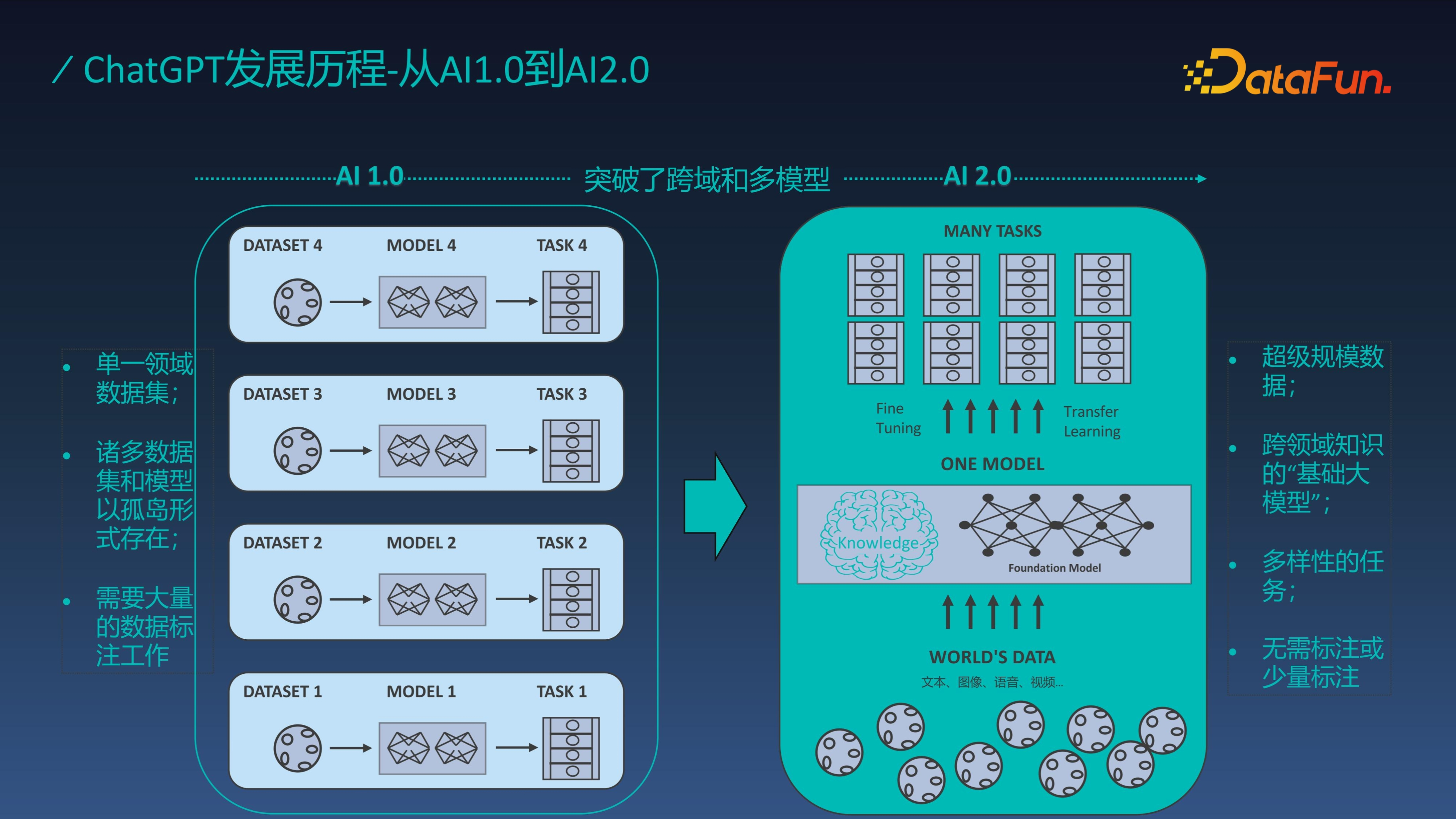
我们知道人工智能的发展经历了两个时代,从 AI1.0 小模型时代到 AI2.0 大模型时代。作为大模型的代表作,ChatGPT 突破了跨域和多模型,数据集由单一领域扩展到了通用领域,从需要大量标注到无需标注或少量标注,这是人工智能普遍落地的基础。比如在工业视觉质检领域中,图片数据的积累非常缓慢,大模型只需要少量标注就可以达到与小模型大量样本相同的效果,这样就能加速整个工业智能化的落地。
02 大模型底层原理
1. BERT 和 GPT 的区别
网络结构区别:BERT 类似于 Transformer 的 Encoder 部分;GPT 类似于 Transformer 的 Decoder 部分。
使用上的区别:BERT 用 CLS 对应的 Output 作为 Embedding 的结果,然后根据不同的任务进行对应的操作来 fine-tuning;GPT 接近于人类的使用方式,可以通过对话的方式得到问题的答案。
预训练任务区别:BERT 采用 Masking Input,使用“填空题”的方式;GPT 采用 Predict Next Token,预测下一个 token。
2. 基于 InstructGPT 的 ChatGPT 改进

ChatGPT 是基于 InstructGPT 发展而来的,主要改进在于:使用了人类偏好的大量对话语料;引入了强化学习。这两点保证了 ChatGPT 的回答更贴近人类的喜好,同时可以让模型不断逼近最好的效果。
3. ChatGPT 训练过程
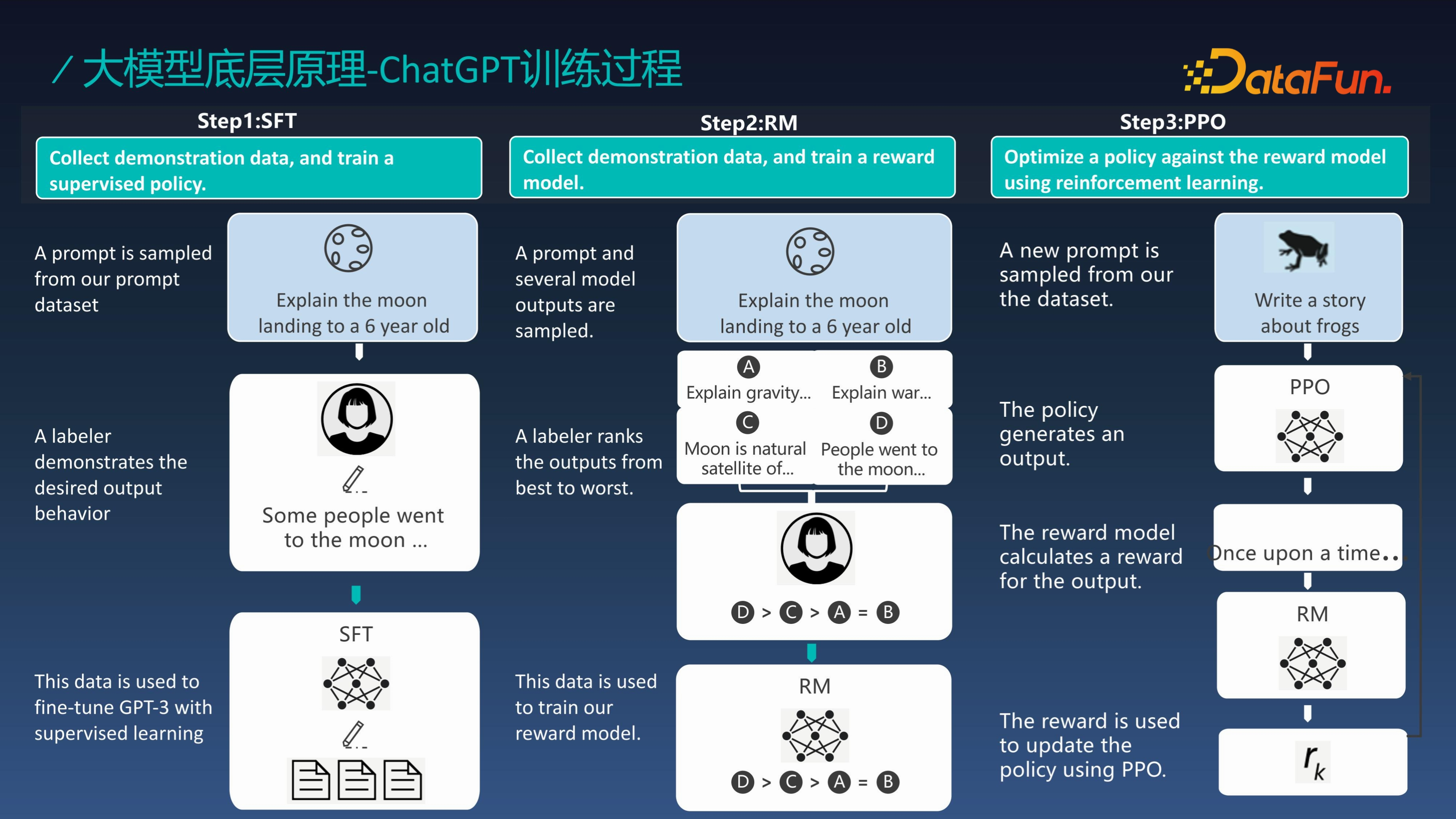
ChatGPT 的训练过程主要分为三步:
第一步,收集数据训练监督策略模型
第二步,收集数据训练奖励模型
第三步,通过PPO对奖励模型进行强化学习
这里讲 ChatGPT 的训练过程是突出一种思想,这种思想也会在后面的 Agent 闭环中得到应用,因此这里不仅仅是 ChatGPT 的训练过程,更是一种实现模型、Agent 持续增强的完美方案。
03 大模型赋能新型工业化
1. 实现路径
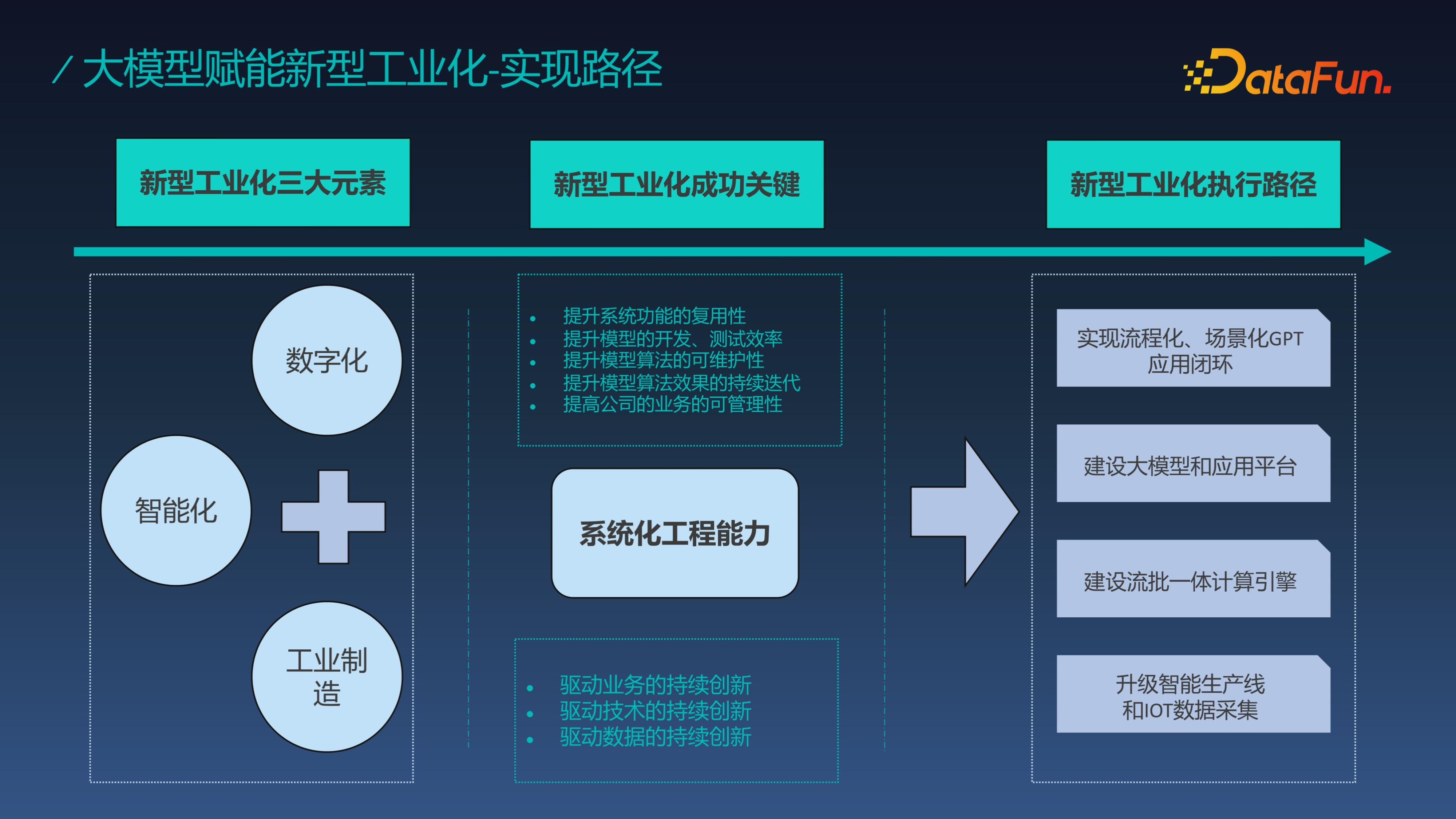
新型工业化是指将工业制造科技能力融入数字化能力和智能化能力,解决供应链和产业链的问题,增强其柔性,同时能够驱动整个工业化产业的技术创新。新型工业化成功的关键在于系统化的工程能力,在大模型发展的今天,新型工业化执行路径可以通过构建如订单系统、排产系统、分析系统、计划系统等的数字系统和建设包含整个 IOT 设备数据的数据系统,并基于数字系统、数据系统和大模型形成 GPT 解决方案平台。再基于 GPT 平台生成的各个 Agent 服务于下游各类业务。
2. 应用范式

大模型赋能新型工业化有三种基本应用范式:
范式 1:指令提示:使用自然语言交互的模式,告知设备或者系统来完成指定任务。例如可以通过语义设备发出指令,让机械手臂完成指定工作,也可以通过指令让大模型生成逻辑控制代码。
范式 2:辅助决策:通过数据驱动模式而不是人工进行交互,如在智能质检场景中,智能摄像机可以通过大模型判断铸件是否有缺陷,如果有缺陷则会给出有缺陷的概率,之后再交由人工判断确认。
范式 3:自主决策:无需人工辅助,常见场景如自动驾驶和自动分拣。
04 工业化中的实践与探索
接下来,详细讲解大模型在蔚来的优秀实践。
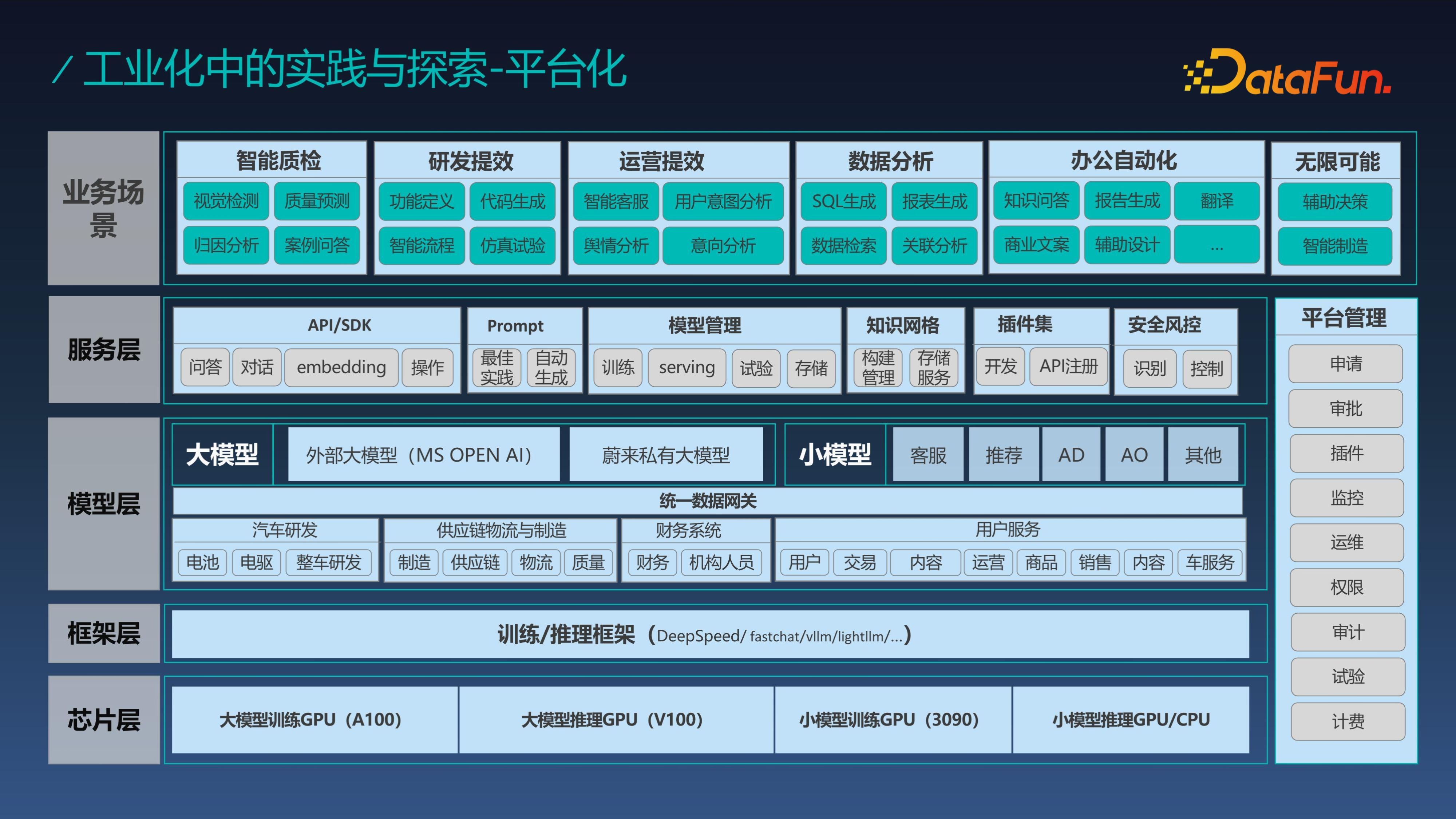
首先是平台化,在蔚来,几乎所有业务大模型AI应用都是基于这个 GPT 平台进行编织的,这里提到的 AI 应用就是一个 AI Agent,应用的编织过程实际就是 Agent 的构建过程。平台的架构整体分为芯片层、框架层、模型层、服务层,最上面是业务场景。服务层所有的能力都是围绕着创建 Agent 形成的。模型层中模型和数据是一体的,之所以如此,是因为数据和模型是不分家的,这也是新型架构的思路。过去数据的应用方式是建设数据库,然后通过 SQL 访问数仓。有了大模型之后,完全可以通过自然语言交互的方式直接访问数据,数据隐藏在模型底层,是模型的一部分,直接面向使用者的就是模型层的能力,我们再也不需要直接面向数据进行分析和使用。
1. Agent 逻辑架构
人工智能领域,现在最火的毫无争议是 Agent,那 Agent 是什么,其构件又是怎样的呢?下面就来介绍一下蔚来是如何设计 Agent 的。
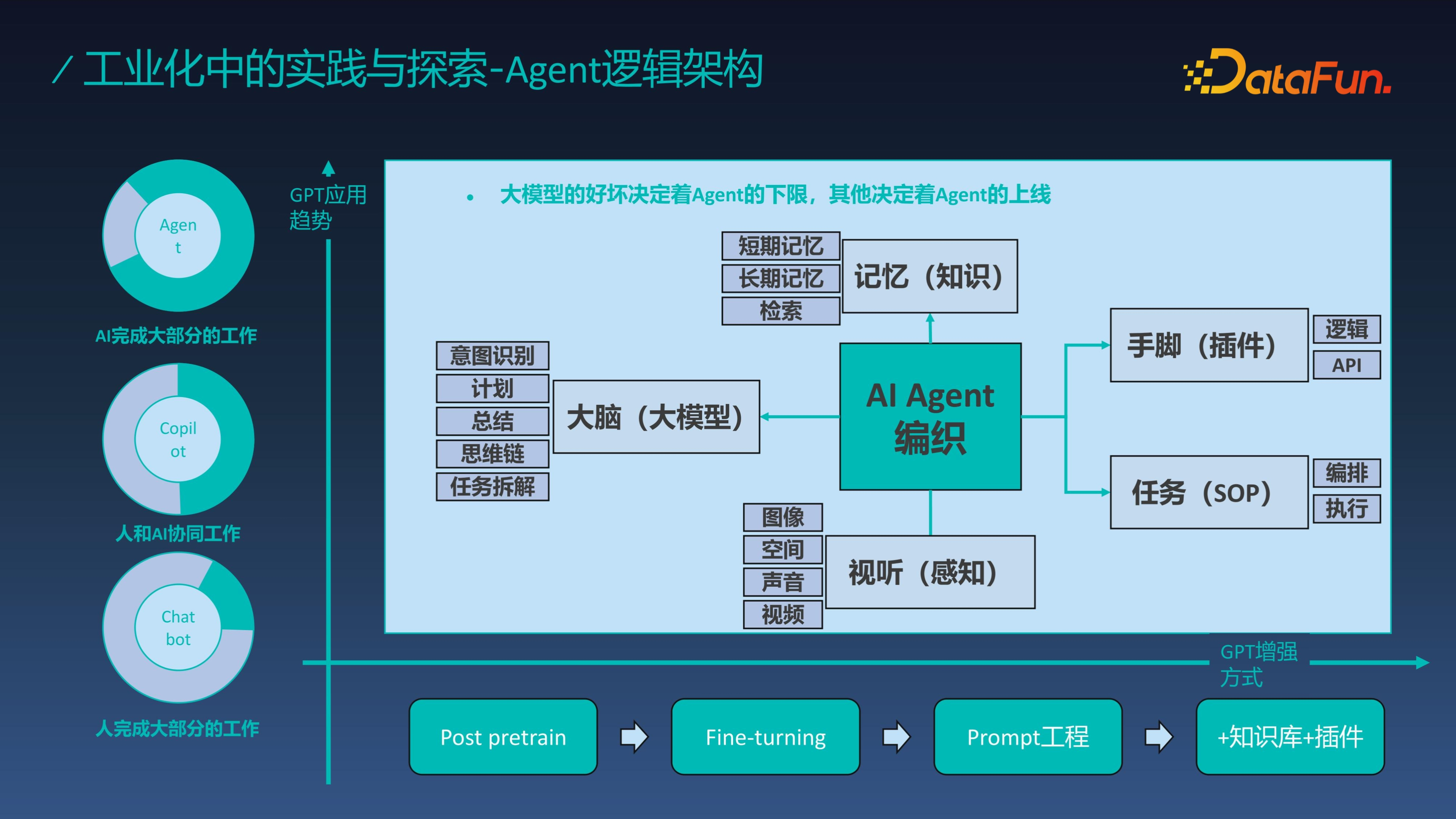
大模型应用分为三个阶段,第一个阶段是人类完成大部分工作,模型辅助人决策;第二阶段是人和 AI 协同工作,GPT 能力融入软件并成为软件的一部分,但这个阶段并没有改变整个系统的产品形态,还需要人类提供基础产品,AI 也只能成为原产品的辅助;第三个阶段是 AI 完成大部分的工作即 AI Agent 阶段,人类只需要给出指令并设定目标、给出资源(如系统接口资源),AI Agent 会自动完成目标。
那到底什么是 Agent 呢?其实 Agent 就是模拟人的思考模型、行动模型来工作的,整体分为四个组件:大脑、记忆、感知引擎、规划和任务执行,GPT 充当大脑,插件成为手和脚连接数据和系统,记忆以知识的方式进行存储,感知模型实现视听感知并通过插件和智能体进行对接,最后通过任务执行来完成工作。
2. 三大闭环
为了实现 AI Agent 的持续增强,我们提出了三大闭环:数据闭环、模型闭环和 Agents 闭环。数据闭环和模型闭环是中间态,为最终的 Agents 闭环服务。
(1)数据闭环
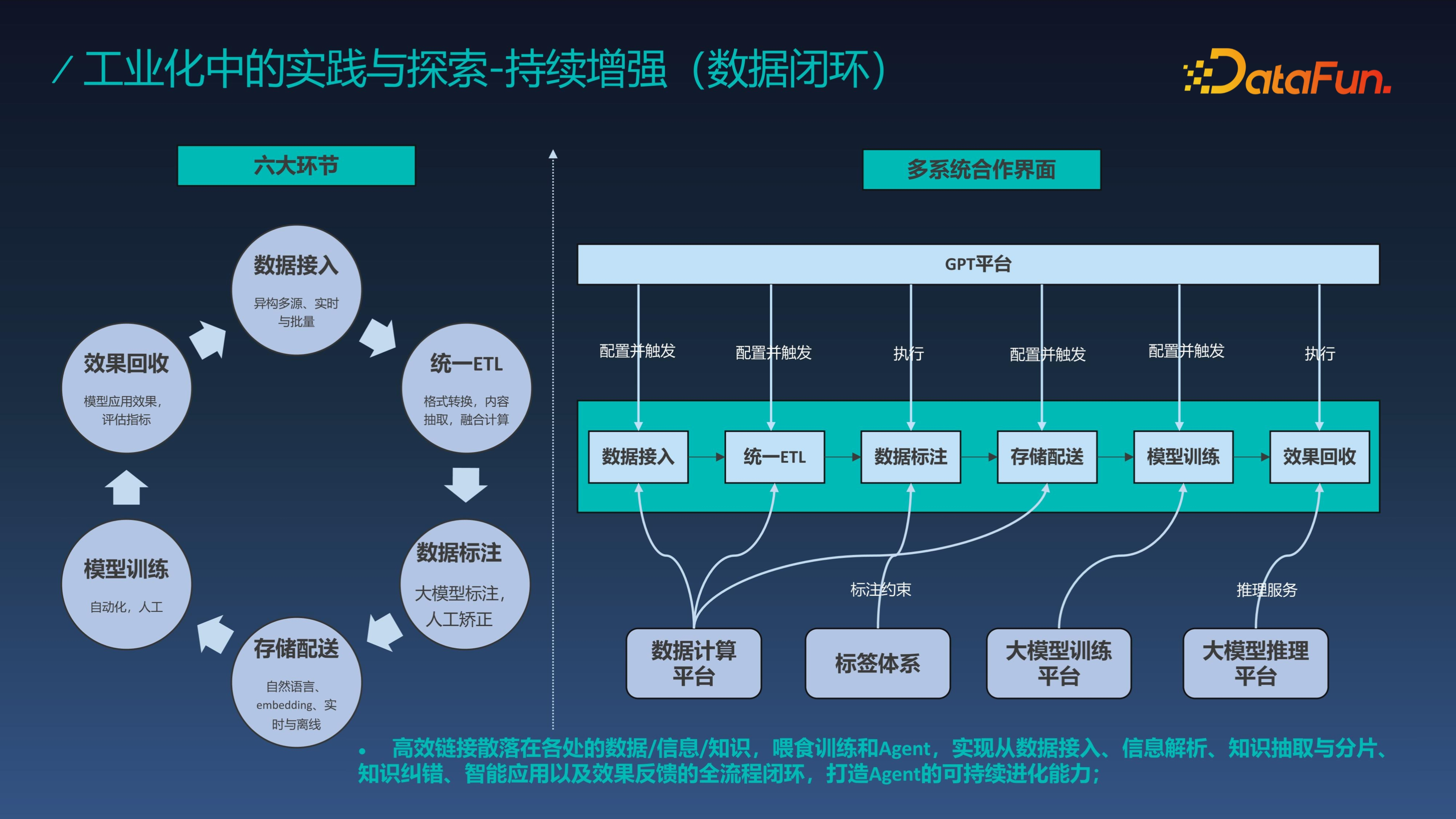
数据闭环分为六大环节,数据接入、统一 ETL、数据标注、存储配送、模型训练、效果回收,效果回收后会进一步修正数据。其中数据标注是由大模型来完成的,依赖给定范围内的标签体系。通过整个数据闭环可持续完善知识和数据,如果底层数据是语料,模型回答的问题一直是有偏的,则反映出训练语料有问题,需要修正;在基于 prompt 工程进行知识问答的时候,回答的问题一直不对,也可通过回溯修改知识。数据闭环能够高效链接散落在各处的数据、信息、知识,喂食训练模型和 Agent,整个闭环实现从数据接入、信息解析、知识抽取与分片、知识纠错、智能应用以及效果反馈的全流程闭环,从而打造 Agent 的可持续进化能力。
(2)模型闭环

模型闭环也是分为六大环节,语料、模型、训练、评估、A/B Test、上线,通过人工反馈的机制,当语料积攒到一定程度会触发模型再次训练,当评估达标之后上线。模型闭环实现的目标是模型持续增强,驱动 Agent 自动增强,这里是通过复用训练平台和大数据平台的能力,在这两大基础平台能力之上实现从语料构建、语料存储、模型托管、模型微调、模型测试、模型上线的全流程闭环。
(3)Agents 闭环
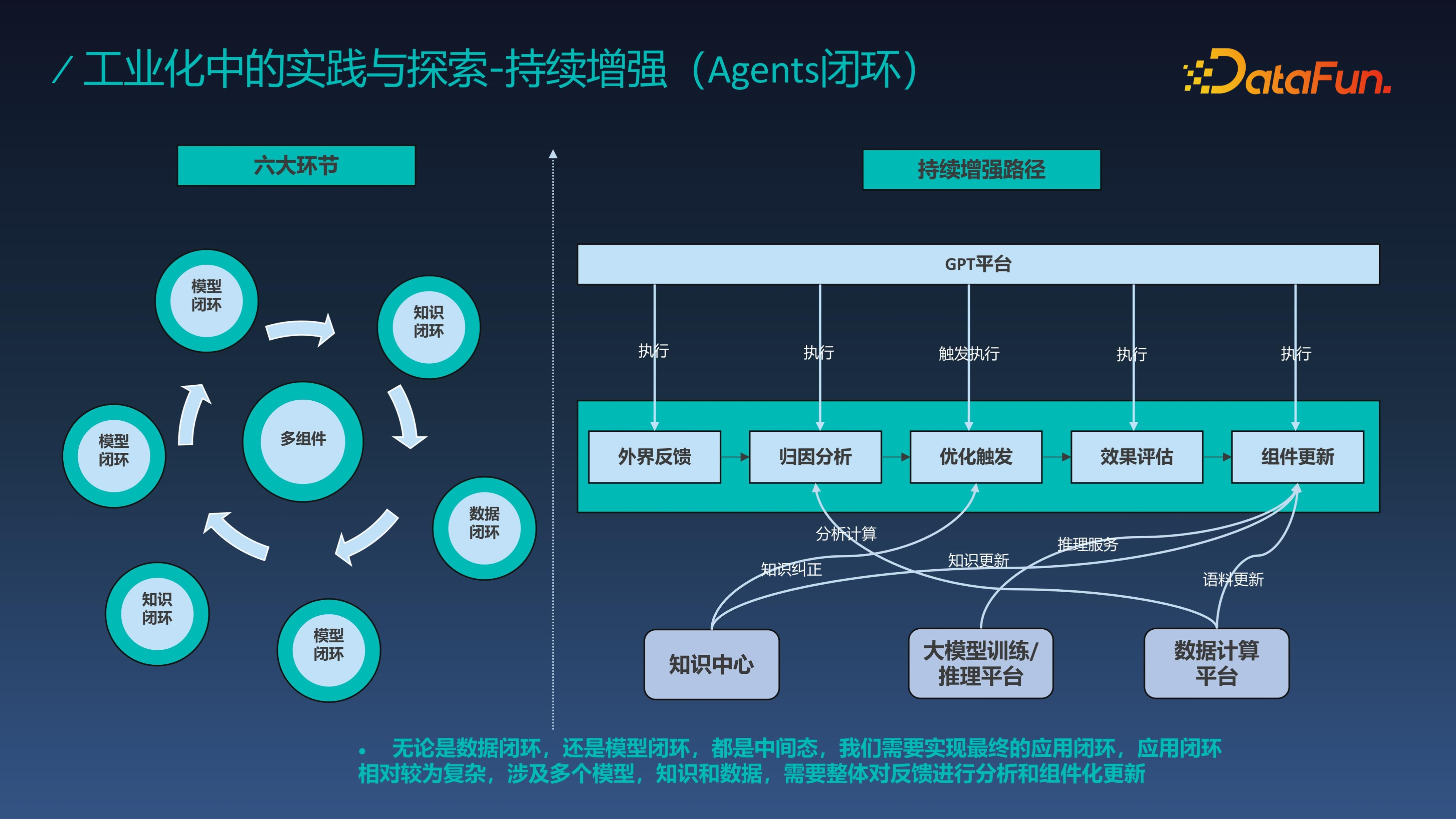
前文中提到,我们的终极目标是实现 Agent 的持续增强,下面就来介绍 Agents 闭环。
其涉及多个模型闭环、知识闭环和数据闭环的过程,其中数据闭环和知识闭环是分开的,数据闭环主要关注的是模型训练的过程,即语料闭环,知识闭环主要关心知识更新。为了实现 Agents 的闭环需要构建一个完整的流程,同时能够感知到外界反馈,然后经过归因分析触发相应优化,优化后经过效果评估,评估达标后再更新组件。
基于数据闭环和模型闭环,通过反复迭代不断地强化学习过程。这就是我前面讲到的 ChatGPT 训练方案的又一次再现,基于此思路我们实现了 Agent 闭环。
3. 应用案例
(1)三位一体智能质检
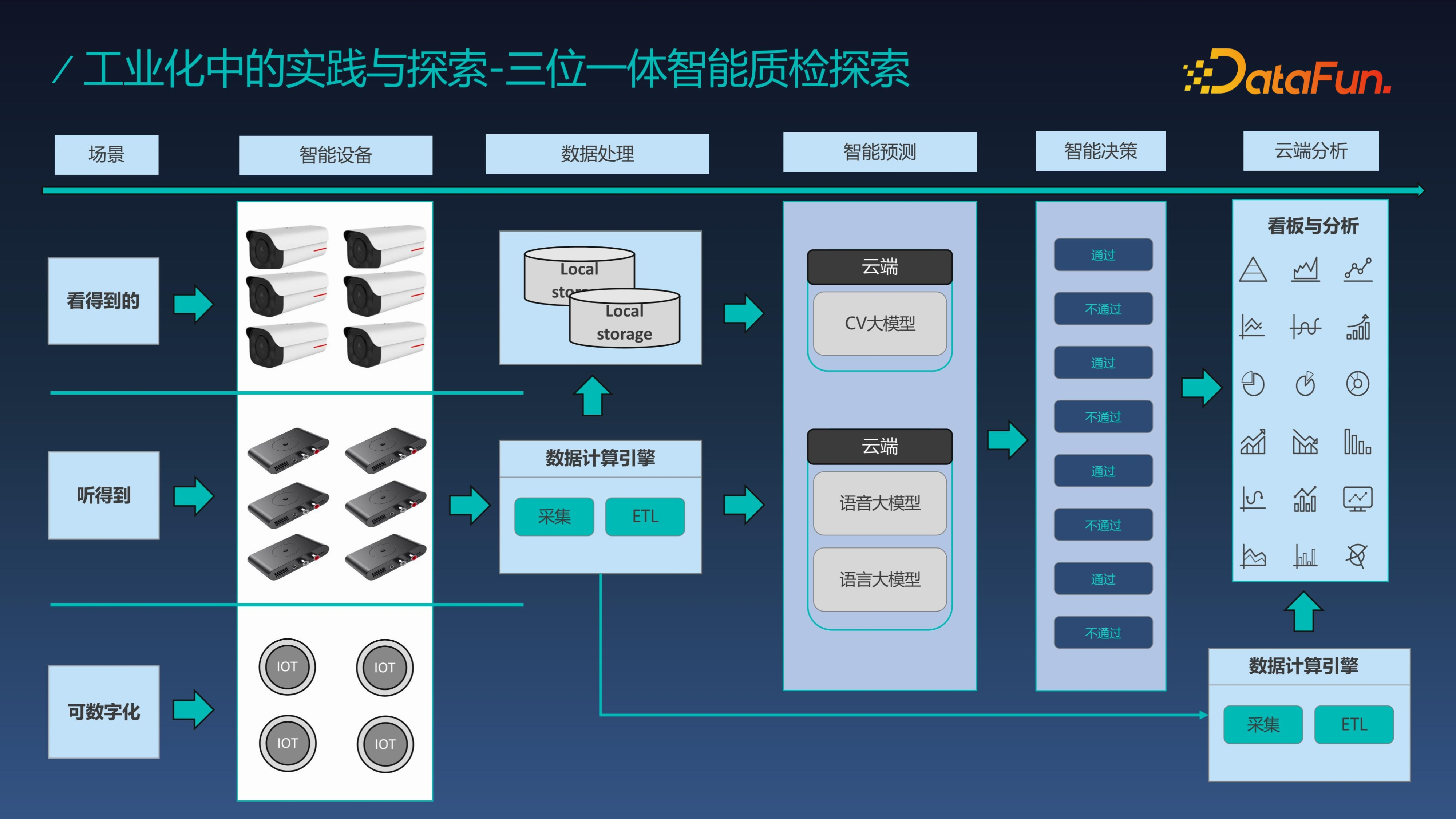
质检是工业制造中质量的保证,对于工业制造非常重要,我们提出了三位一体的智能检测方案,对于质检我们可以从三个方向实现突破,即看得到的、听得到的、可数字化的,对于“看得到的”可以通过 CV 大模型替代人工检测,由于大模型拥有跨域知识能力,能在缺少图片数据的场景中降低冷启成本;对于“听得到的”可以通过声音模型进行分析识别异响;对于可数字化的,可以通过大模型进行分析预测,比如和标准结果进行对比分析,看是否匹配。
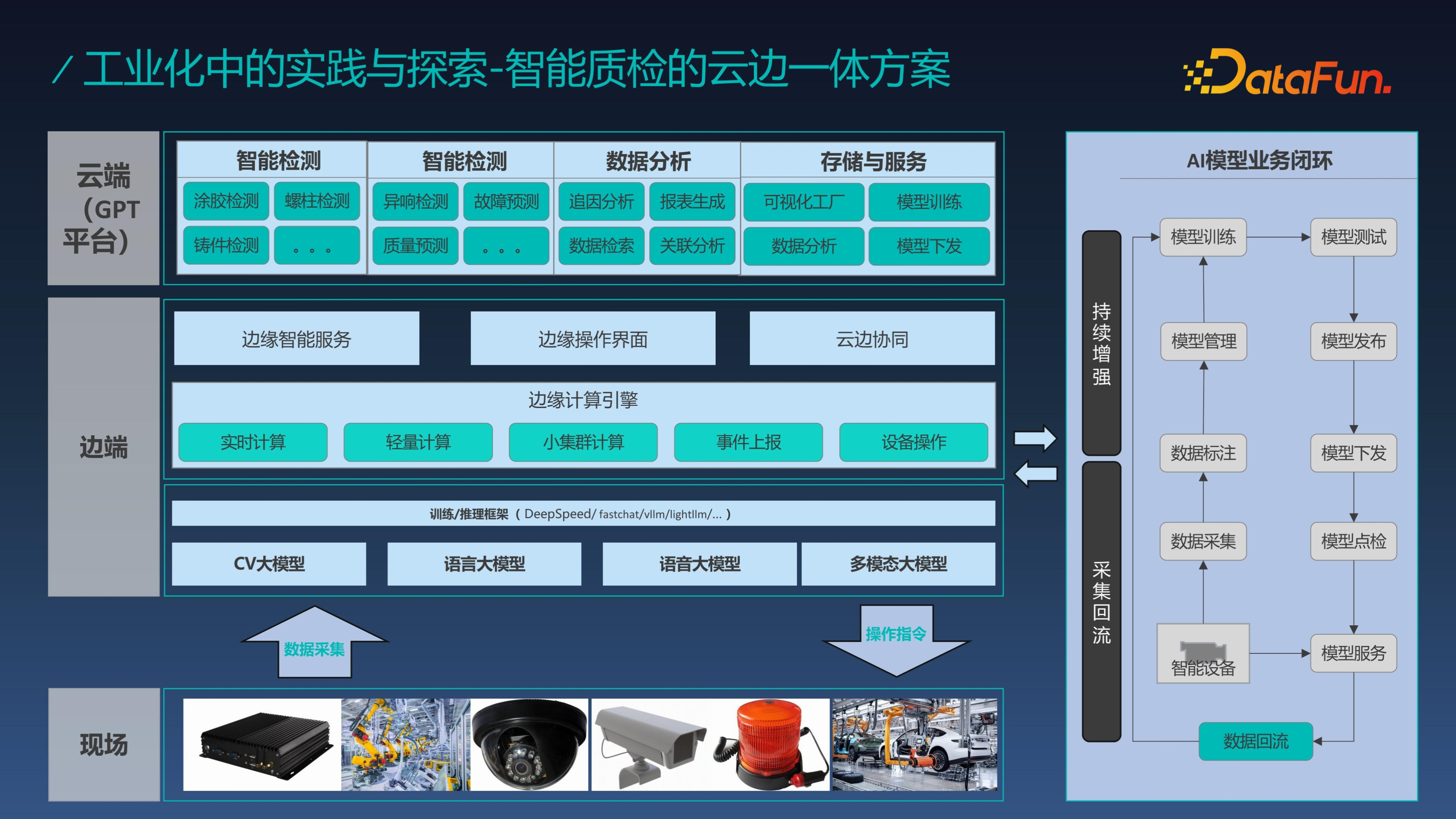
我们知道在实际的生产中,产线侧的系统不可能完全依赖于云端,由于一旦停网可能会影响生产,所以产线内无法完全依赖外网,我们提出了云边一体的架构,边端系统一般需要部署在产线旁边。边端系统的主要任务是检测,同时将数据上传到云端,云端系统主要是实现整体模型训练的闭环。云边一体的架构结合在一起,能实现边端系统的持续增强和云端可视化与综合分析。
云端的闭环训练流程对于每个场景都是独立存在的,需要数据持续累积。云端模型会根据持续新增的数据量来决定是否重新训练模型,在模型的指标评估、点检实验等都通过后模型才能上线,从而实现持续化的模型迭代。
(2)G8D Agents
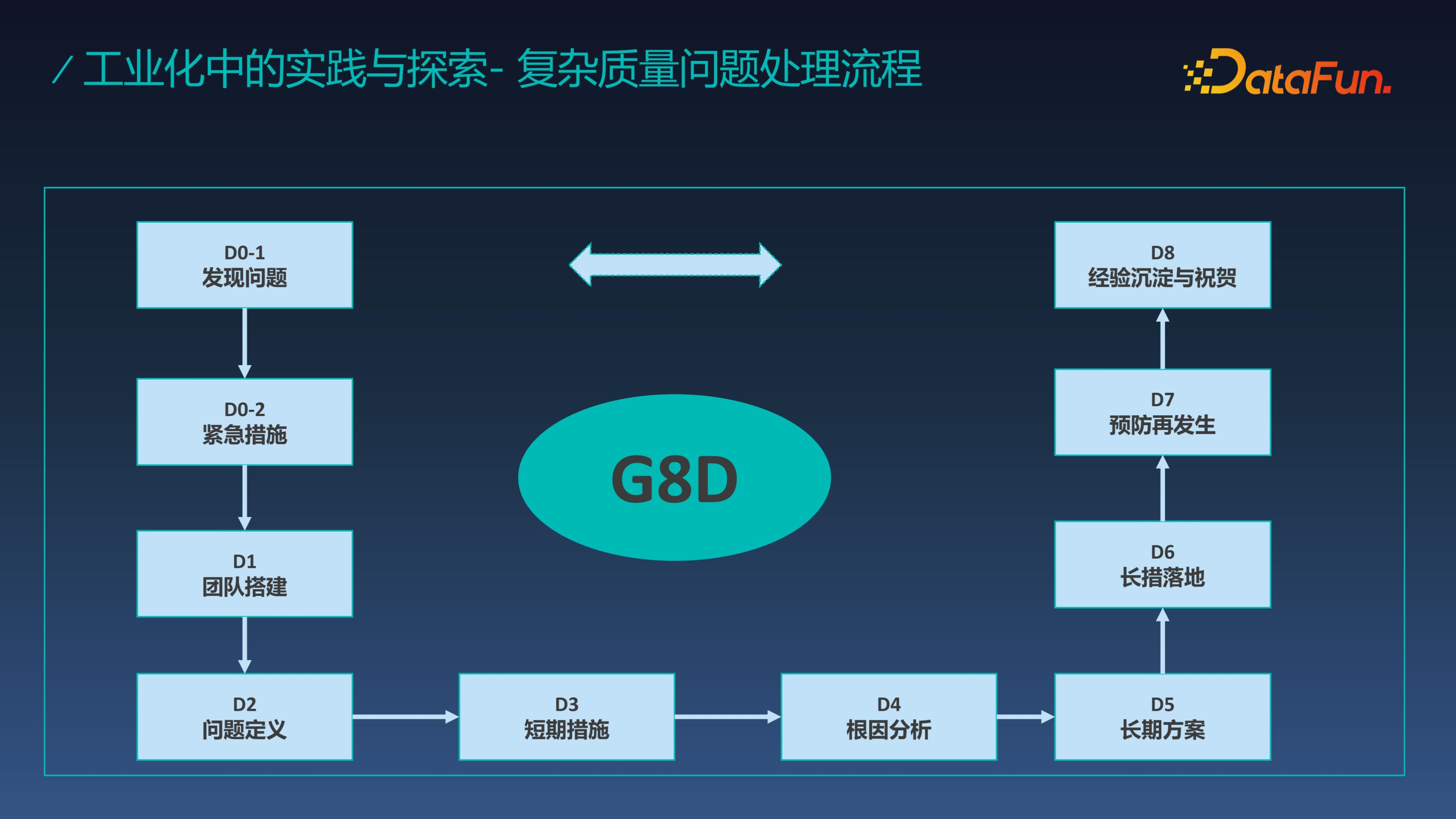
最后我们看一下如何解决工业生产过程中的复杂质量问题。在行业内,质量的处理流程一般采用 G8D 的方案来解决这类问题。G8D 主要分为八个模块:发现问题、紧急措施、团队搭建、问题定义、短期措施、根因分析、长期方案、长措落地、预防再发生、经验沉淀与祝贺。

设想当 G8D 和大模型结合时,会碰撞出怎样的火花呢?我们据此又提出了 G8D Agents 的复杂问题解决方案,这里需要构建 8 个 Agent,每个 Agent 对于 G8D 的每一个 D 承担相应的任务。当把 8 个 Agents 构建成一个 team 的时候,就可以完成整体复杂问题的分析与处理。当然这其中需要对接数据系统和质量分析系统,并沉淀经验给上游系统(如质量分析、质量案例池等)从而能够回馈到整个系统中。
在没有 G8D Agents 之前,质量分析过度依赖工程师的经验,其经验也没有很好地沉淀下来,而 G8D Agents 系统不单实现了质量问题的快速分析处理,同时能快速沉淀经验。最后 G8D Agent 系统可以跟各个系统打通或是成为系统的重要组成部分,相当于各系统拥有 8D Agents 的能力,可以避免沉重的数字化系统建设,以轻量的 Agent 解决方案节约开发成本,全面加速问题解决效率。

