本文介绍了百度数仓融合计算引擎的整体设计原理、优化及实践,阐述了在互联网产品快速迭代的趋势下,基于一层数仓宽表模型的数仓模型如何做到数十秒级查询的技术方案,并从互联网业务变化特性、传统计算引擎存在的问题、融合计算引擎的原理及优缺点、引擎应用场景和效果等角度进行了较为全面的分析,最终通过引擎设计和优化实现了提升查询性能的同时节约数仓存储的目标,降低了用户的数据使用成本。
01 业务背景
1.1 数据现状和数据分析引擎的演进
1.1.1 数据现状
互联网企业往往存在多个产品线,每天源源不断产出大量数据,数仓规模达到数百PB以上,这些数据服务于数据分析师、业务上的产品经理、运营、数据开发人员等各角色。为了满足这些角色的各种需求,需要稳定高效的计算引擎在海量数据中快速完成分析计算。
1.1.2数据分析引擎的演进及百度数仓引擎选型
单机分析时代(数仓TB级别)->
MapReduce、Hive基于磁盘的分析时代(数仓数PB级别,分析耗时数十分钟)-> Spark基于内存的分析时代(数仓数百PB,分析耗时数十秒)
百度数仓引擎选型:对比了业界常用的Adhoc查询分析引擎,通过对比Hive生态、大规模Join、存储引擎、列式存储、是否支持高并发以及适用场景等,如图1:

△图1
最终选型Spark SQL,因为SparkSQL对Hive生态兼容好,大规模Join性能好,支持大宽表列存,支持UDF等。
1.2 当前业务特性与趋势
互联网产品快速迭代,业务发展越来越快,跨业务分析越来越多,数据驱动业务越来越重要。数仓计算任务和数据量越来越多,adhoc场景日均参与计算的数据数十P,ETL场景日均数十P,数据服务的主要群体正在从数据研发转向分析师、产品及运营人员,查询计算速度需要进一步提升,使用门槛需要进一步降低。
02 面临的问题
2.1 在数据驱动业务越来越重要的大趋势下,分析效率越来越重要
面临如下问题,如图2、图3:

△图2

△图3
2.2 思考
那么在生产实践中如何解决上述面临的问题及痛点呢,在对数仓技术深度调研和对业务线具体用户访谈后,根据调研和访谈结论,得出以下想法:
(1)引擎层面:设计融合计算引擎、使用DataSkipping,Limit下推、Codegen和向量化,参数调优等方式加速数据查询,快速满足业务查询需求,助力数据驱动业务。
(2)数仓层面:数仓不分层,节约数仓整体存储,用更少的表满足业务需求,比如一个主题一张宽表,明确数据表使用方式,确保口径清晰统一,避免业务方线下拉会沟通,降低沟通成本,提高沟通效率。
03 技术方案
根据上述的想法,经过可行性分析后,提出设计开发出融合计算引擎和一层大宽表模型替代经典数仓维度模型的技术方案,来解决传统数仓adhoc场景查询性能低、存储大量冗余、表多且口径不清晰的问题。
3.1 融合计算引擎
融合计算引擎是一个百度自研的集常驻、查询、生产于一体的数仓融合的SQL计算引擎,它基于 Apache Spark 构建,具有快速、可扩展和高度可靠的特性,不仅用于在PB甚至EB级大规模数据处理和分析场景中执行 SQL 查询,也用于例行生产的 ETL 场景。
3.1.1融合计算引擎架构
融合计算引擎架构如下:由WebServer、Master、Worker三部分组成。具体各部分功能见图4:

△图4
基于Spark源码二次开发的Worker是核心执行模块,内部Container常驻做到资源复用。
3.1.2 融合计算引擎性能优化
3.1.2.1 如何算的更少DataSkipping
(1)PartitionSkipping:仅读取必要的分区,对性能提升最大
(2)Parquet列式存储
百度数据中台线上查询特点是宽表 500~1300列,平均查询列数15列以内,非常适合使用Parquet存储格式,优点是:
(a)同列同质数据拥有更好的编码及压缩
(b)Parquet映射下推,通过映射下推只需要从每个RowGroup中读取下推的列即可,实现文件IO量:TB->GB级别,如图5:

△图5
(3)RowGroup级别统计过滤
由于Parquet文件是基于RowGroup的方式分块存储的,并且Parquet Footer中存储了每个RowGroup的 min/max,sum,BloomFilter元信息等索引信息,因此可以结合谓词下推进一步过滤出必要的RowGroup,如图6:
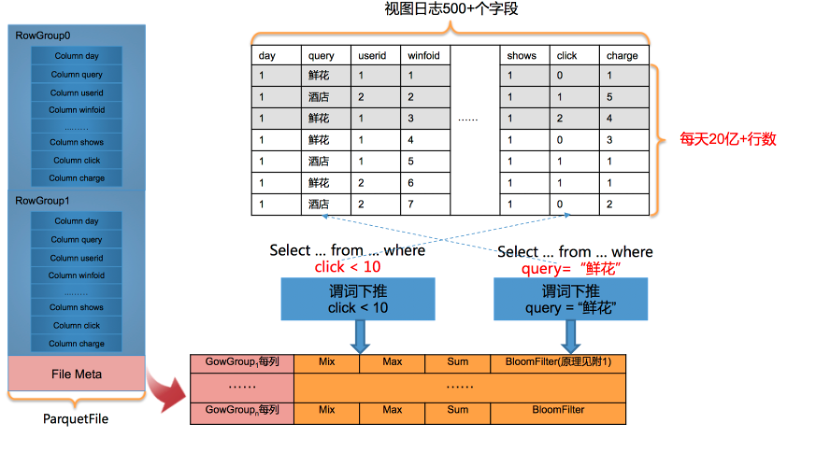
△图6
(4)Parquet ColumnIndex
在Spark 3.2.0 之前Parquet的谓词下推是基于Row group的统计信息来的,如:最大最小值,字典信息,以及Parquet-1.12的Bloom filter,在Spark 3.2.0 之后,我们可以基于page级别的数据过滤(只选择需要的page),这样能大大减少IO,因为在page级别过滤的话,不需要每次都会获取整个Row group的数据。
另外数据分布对于Parquet ColumnIndex的影响较大。数据分布越紧凑,min/max索引越精确,RowGroup Skipping效果越好。因此我们会在Spark引擎数据写入Parquet文件之前基于指定字段做一次文件内排序,这样能将Data Page内的数据分布更加紧凑,最大发挥出Parquet ColumnIndex中 min/max等索引的特性,实际业务落地时日增3千亿行的大宽表查询耗时降低43%,Parquet Index如图7:

△图7
3.1.2.2 如何算得更快
(1)ProjectLimit
Spark3.2之前对Select * from table Limit 1000 这种partten无法进行ProjectLimit下推,简单查询会执行非常久,通过分析物理计划,发现完全可以消除该查询物理计划中的Exchange节点也就是Shuffle阶段,优化后该类型的查询耗时从数十分钟级别降低到秒级别,性能提升百倍以上,如图8:
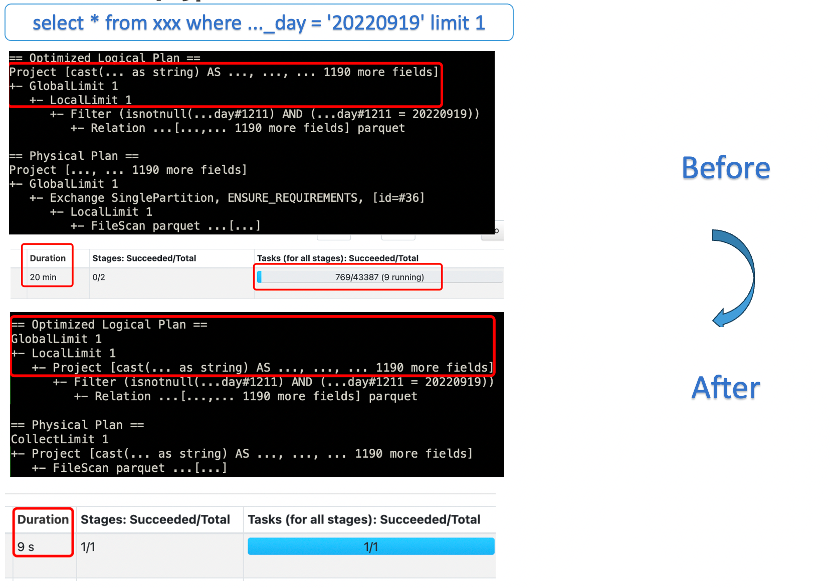
△图8
(2)CodeGen
CodeGen通过动态生成Java代码、即时编译和加载,把解释执行转化为编译执行,变成机器码执行,主要针对表达式计算和全Stage计算做代码生成,都取得了数量级的性能提升。
具体来说,Spark Codegen分为Expression级别和WholeStage级别,Expression级别主要针对表达式计算做代码生成,WholeStage级别主要针对全Stage计算做代码生成。
通过参数简化、函数嵌套简化、函数返回值简化,可以减少函数调用的开销,减少CPU计算资源的浪费和提高缓存命中率等从而加速计算,如图9:
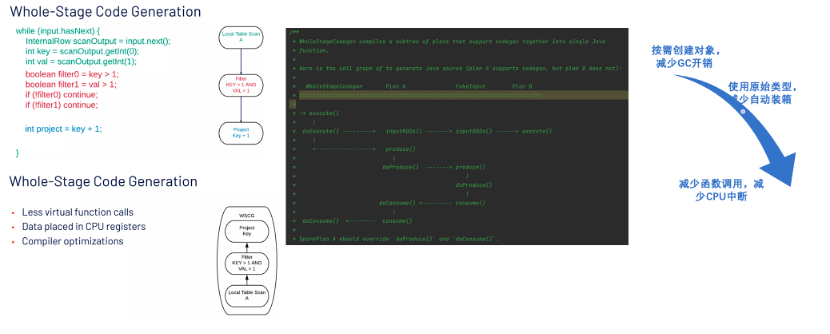
△图9
在百度内部生产中,我们实现了UDF、get_json_object、parse_url、sentences等算子的WSCG性能提升9%,如图10:
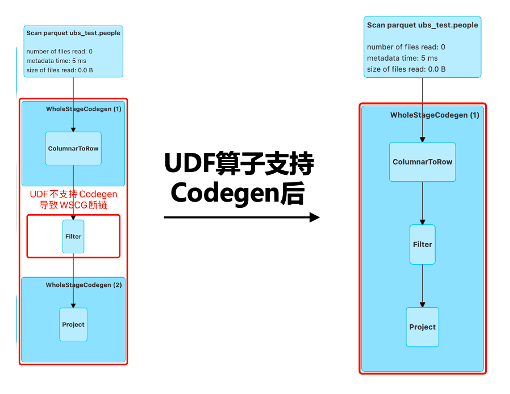
△图10
(3)向量化
列式存储向量化读取,减少虚函数调用,如图11:
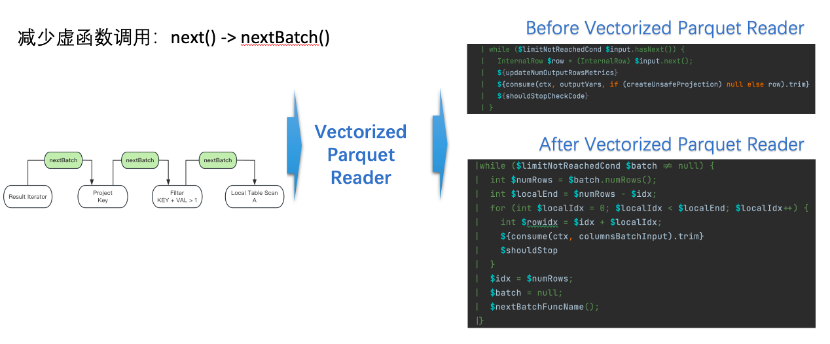
△图11
百度的内部场景中我们发现有大量的Like和JSON解析操作。因此,我们引入hyperscan 和simdJson使用向量化技术替换 Spark现有的Like和Json算子,以此提升查询性能。最终融合计算引擎查询性能提升了12%。
3.1.2.3 如何算的更稳定
Spark 有task级别的retry机制,但要保证查询又快又稳,需要避免这种retry,于是我们根据生产中不同业务场景不同任务类型,从上百个参数中调整改良了几十个参数,主要调整的参数包括堆内内存、堆外内存、资源并发参数、shuffle参数、推测执行参数、调度参数、序列化参数以及文件参数等。
3.1.3融合计算引擎例行ETL场景
融合计算引擎天然适合ETL场景,因为其是基于Spark进行的二次开发,可支持单语句、多语句、各种复杂的SparkSQL等语法,如图12:

△图12
3.2 融合计算引擎优点及性能
(1)查询引擎和ETL生产引擎统一,避免不同引擎之间的语义差距,使用成本更低
在同一个数仓生产场景中,使用相同引擎,可以显著降低业务同学的使用门槛,以及数据开发人员的学习成本,使其更关注其业务逻辑,提高生产力。
(2)适合超大规模的查询和生产
面对数仓数百PB数据进行大规模查询计算生产,可以完美支持日增3千亿行的超大表进行高频查询。
(3)性能对比
Adhoc查询场景,耗时在数十秒级别,相比于普通Spark性能提升5倍。
ETL生产场景资源节约20%的同时耗时相比普通spark性能提升4倍。
(4)计算引擎和数仓建模一体化
正是因为有融合计算引擎强大的计算能力,才可以完成百度数仓一层大宽表模型替代传统经典维度模型的数仓优化。融合计算引擎和一层大宽表模型整体规划,完成了百度数仓的整体降本增效,融合计算引擎推动一层大宽表替换维度模型,通过极少的冗余,做到了表更少,口径更清晰,业务使用上更方便,沟通更流畅,效率更高的同时,做到了数仓总存储下降 30% 左右,查询性能提升300%,大大提升了业务分析和数仓生产效率。
04 总结
(1)融合计算引擎和宽表建模更适合面向快速迭代的数据驱动型业务,能够极大的提升业务效率。
(2)基于当前的业务实践,引擎和宽表在存储和查询性能方面相比于传统数仓更优。
(3)在业务效率提升的同时,查询越来越多,计算量越来越大,引擎压力有所提升,宽表的建设在数据生产和维护成本有所提升,整体挑战越来越大,还需结合引擎技术和实际场景进一步优化探索。

