一 背景
我分享点 Java 相关内容。在得物,使用 Java 的同事们占据了相当大的比例,他们是我们业务线的中坚力量。我希望今天所分享的内容能对大家有所帮助,助力于公司价值的创造。
二 什么是ZingJDK
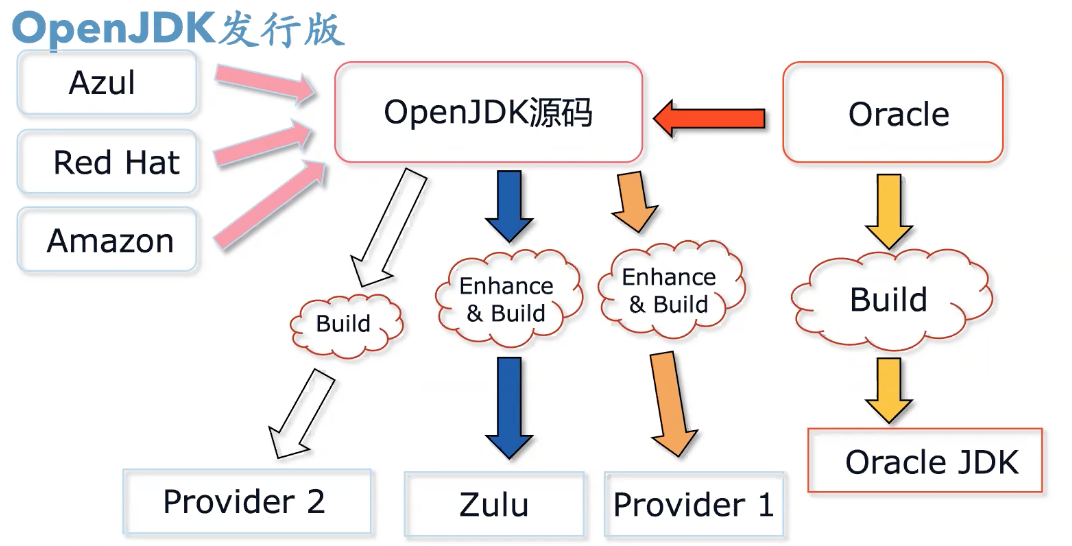
OpenJDK 是 Oracle 向开源社区贡献的源码。Azul、RedHat、Amazon、Alibaba 都可以拿到这份源代码,Oracle 要做的是,基于这个源码做漏洞修复和商业特性的实现、封装,生成 Oracle JDK。而 Azul 也可以基于源码做特性增强构建,生成 ZuluJDK 和 ZingJDK。前者属于开源版本,而 ZingJDK 是高性能低延时商业版。
三 Zing的特性
ReadyNow®预热
什么是“ReadyNow”?
ReadyNow 是 Azul Platform Prime 的一项功能,启用后可显着改善应用 Java 程序的 JIT 预热行为。让 Java 程序运行时,拥有近似 Native 机器码的性能。
什么是热身?
预热是 Java 应用程序达到更优性能所需的时间。即时 (JIT) 编译器的任务是通过从应用程序字节码生成优化的编译机器代码来提供更优性能。此过程需要时间,因为 JIT 编译器会根据应用程序的分析来寻求优化机会。
ReadyNow 如何运作?
原生的JIT并不会把运行中编译的 Native 持久化,而 ReadyNow 会保留应用程序运行期间收集的分析信息(本地或远端),以便后续运行不必再次从头开始学习。预热可以改善每个应用程序的运行,直到达到更优性能。如图所示:
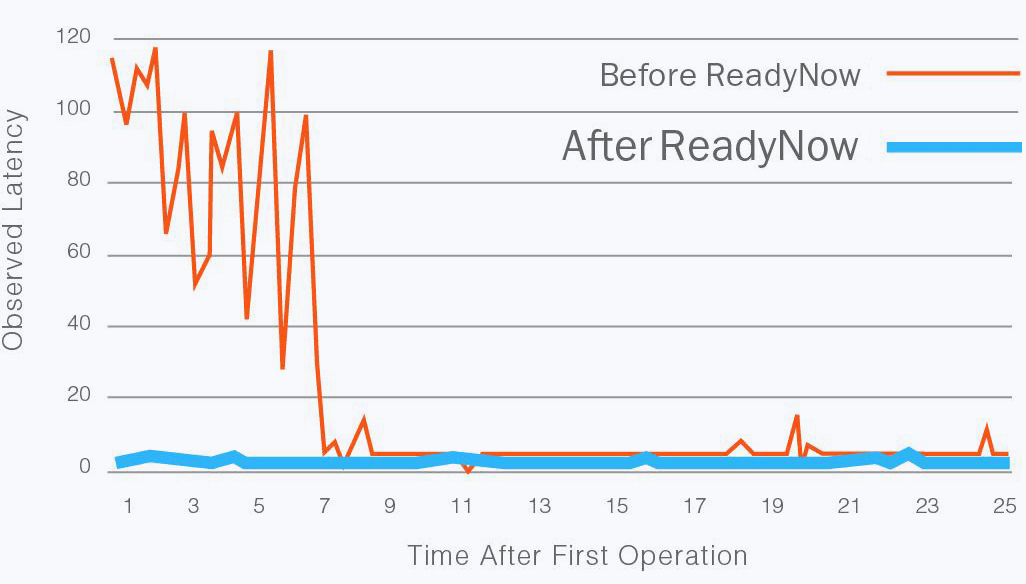
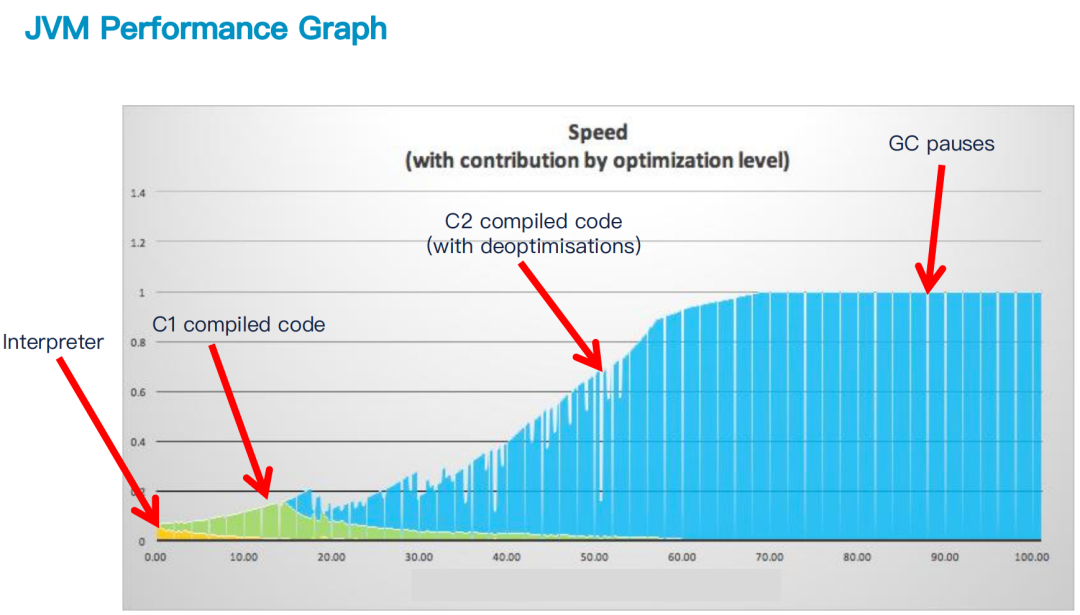
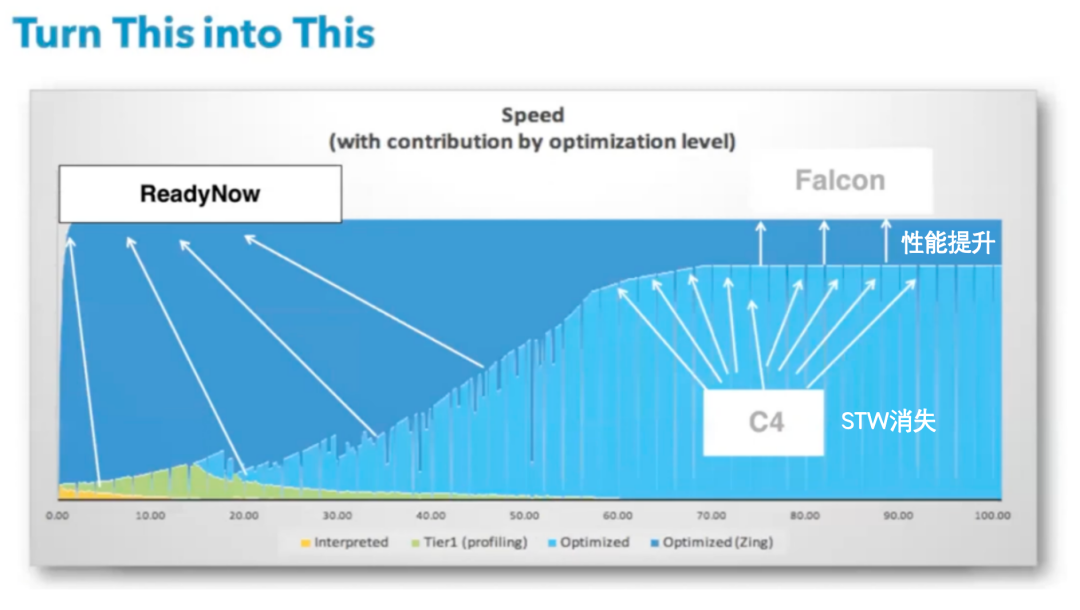
Ready Now Orchestrator
Azul 的平台 Prime 提供了 Ready Now 和 Ready Now Orchestrator 作为解决 Java 预热问题的解决方案。
Ready Now Orchestrator 进一步简化了使用 Ready Now 的过程,尤其是在容器化的 JVM 中。Ready Now Orchestrator 自动捕获并提供更优热函数配置,并且将 JIT 编译卸载到远端服务器上,以实现更优性能。
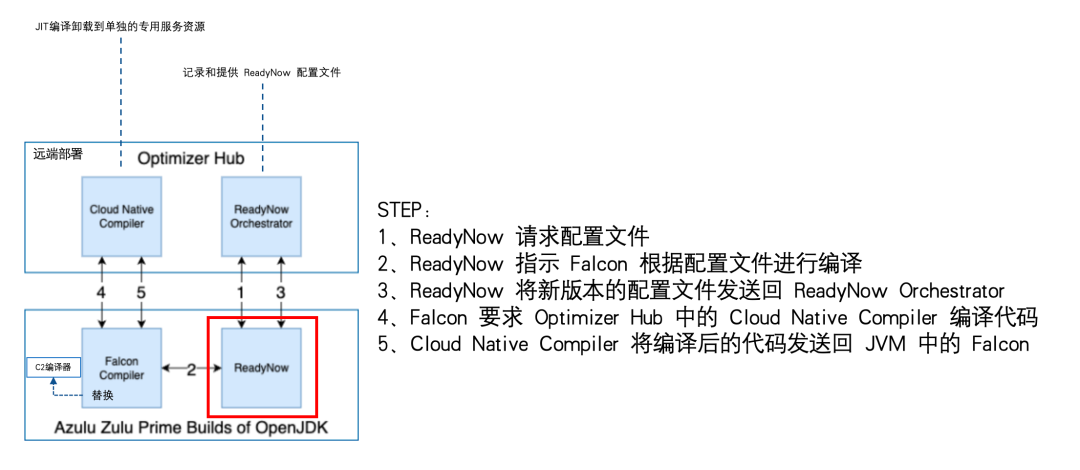
Falcon JIT编译器
Falcon JIT 编译器基于 LLVM 的技术,LLVM 是一个流行的编译器基础设施项目,得到了领先大学和数十家企业贡献者(包括 Adobe、Apple、Google、NVIDIA 和 Intel)的积极参与。
LLVM 是一个现代化的开源编译器框架,也是 Swift、Rust 等许多新语言首选的后端“引擎”。它获得了学术界的大力支持,并且拥有包括 AMD、Apple、Cray、IBM、Intel、 Microsoft、Sony 和 SAP 在内的众多商业支持者。广泛的支持可以帮助它充分利用新的服务器硬件和新的指令集,它经常利用新的处理器技术,如 Intel 的 Broadwell 和 Skylake 处理器提供的矢量化和加密优化。
以下是 Azul 首席执行官 Gil Tene 对 LLVM 的描述:
使用 LLVM 为我们提供了巨大的优势,数以百计的人对它进行优化,让它与最新的处理器能力保持同步,这些成果可以立即应用到 Java 代码上。
关于这一点,一个简单具体的例子是,Falcon 已经使用 Intel 最新的 CPU(例如,当前 Broadwell Intel E5-v4 服务器上的 AVX2 指令集)所提供的最新/最棒的矢量指令功能来优化常规的 Java 循环。由于 AVX2 增加了谓词矢量运算能力,所以 Falcon 能够在循环(例如,“将数组中的偶数相加”)中矢量化在之前的硬件上无法矢量化的谓词操作,因此,同样的 Java 类在较新的服务器上执行速度更快。[目前]HotSpot 甚至都没有试一下……
但最重要的是,我们获得了这种好处,不是通过一群 Azul 工程师花时间进行矢量化优化以及选择恰当的方法匹配每一种处理器。举例来说,我们是从 Intel 过去两年的投入以及他们将这些优化贡献给 LLVM 获益的。他们的贡献已经应用到了 C/C++/Clang/Rust,就像(现在)应用到 Java 一样。
Falcon 让我们可以做一些很酷的、JVM 相关的优化,而使用 C2 则无法应用这些优化。GC 屏障相关的优化就是其中的一个例子。此外还有更高层次的语言优化。关于更高层次的优化,一个具体的例子是,我们用较少的投入就在 Falcon 中引入了针对“真正 final”字段的优化,在 C2 中引入的话,投入要多得多。[实例 final 字段的挑战在于,它们可能不是“真正 final”的,因为反射和 Unsafe 可以重写它们,而且经常这样做]。Falcon 能够优化 Java 中使用实例 final 字段的操作,它所采用的方式是以前的 JIT 不曾做过的(例如,将数组范围检查提取到循环之外)。过去的几年里,在 HotSpot 和 Zing 中,这一特性一直处于原型模型开发阶段(在 OpenJDK 的部分邮件列表中可以找到相关讨论),但之前从没有在哪个 JVM 中实现产品化,其中有一部分原因是让 JIT 编辑器处理得很好复杂度很高。
有鉴于此,Falcon 在新硬件上性能超过 C2 就不奇怪了。在特定的加密负载基准测试中,它比 Oracle HotSpot 快 3.5 倍,比 Oracle HotSpot 使用基于 Skylake 的服务器(Intel Xeon E5-xxxx)进行 Cassandra 基准测试快大约 10%。另外,在低延迟环境中,它也比 Zing 以前的版本快许多。一个运行交易基础设施的 Azul Zing 客户观察到了大约 18~24% 的性能提升。
Azul C4垃圾收集器
Azul 的连续并发压缩收集器 (C4) 是 Java 中唯一可用于生产的、分代无暂停垃圾收集器,也是 Azul Platform Prime的关键组件。
C4 算法的 3 个阶段
C4 算法的一个基本假设是“垃圾回收不是坏事”和“压缩不可避免”。C4 算法的设计目标是实现垃圾回收的并发与协作,剔除 STW 式的垃圾回收。C4 垃圾回收算法包含以下 3 个阶段:
标记 (Marking) 找到活动对象;
重定位 (Relocation) 将存活对象移动到一起,以便可以释放较大的连续空间,这个阶段也可称为“压缩”;
重映射 (Remapping) 更新被移动的对象的引用。
下面的内容将对每个阶段做详细介绍。
C4 算法中的标记阶段
在 C4 算法中,标记阶段(Marking Phase)使用了并发标记(Concurrent Marking)和引用跟踪(Reference-Tracing)的方法来标记活动对象。
在标记阶段中,GC 线程会从线程栈和寄存器中的活动对象开始,遍历所有的引用,标记找到的对象,这些 GC 线程会遍历堆上所有的可达(Reachable)对象。在这个阶段,C4 算法与其他并发标记器的工作方式非常相似。
C4 算法的标记器与其他并发标记器的区别也是始于并发标记阶段的。在并发标记阶段中,如果应用程序线程修改未标记的对象,那么该对象会被放到一个队列中,以备遍历。这就保证了该对象最终会被标记,也因为如此,C4 垃圾回收器或另一个应用程序线程不会重复遍历该对象。这样就节省了标记时间,消除了递归重标记(Recursive Remark)的风险。(注意,长时间的递归重标记有可能会使应用程序因无法获得足够的内存而抛出 OOM 错误,这也是大部分垃圾回收场景中的普遍问题。)
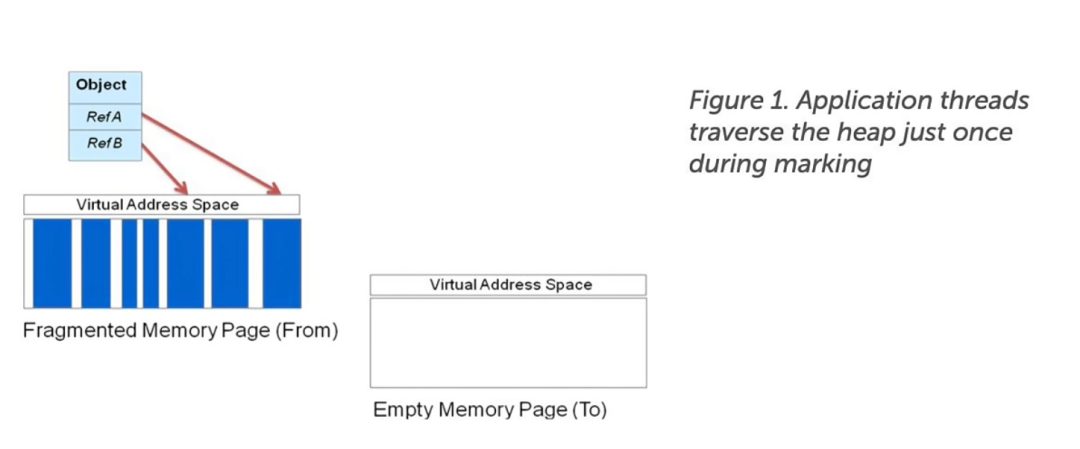
如果 C4 算法的实现是基于脏卡(Dirty-Card Tables)或其他对已经遍历过的堆区域的读写操作进行记录的方法,那垃圾回收线程就需要重新访问这些区域做重标记。在极端条件下,垃圾回收线程会陷入到永无止境的重标记中——至少这个过程可能会长到使应用程序因无法分配到新的内存而抛出 OOM 错误。但 C4 算法是基于 LVB(Load Value Barrier)实现的,LVB 具有自愈能力,可以使应用程序线程迅速查明某个引用是否已经被标记过了。如果这个引用没有被标记过,那么应用程序会将其添加到 GC 队列中。一旦该引用被放入到队列中,它就不会再被重标记了。应用程序线程可以继续做它自己的事。
脏对象(Dirty Object)和卡表(Card Table)
由于某些原(例如在一个并发垃圾回收周期中,对象被修改了),垃圾回收器需要重新访问某些对象,那么这些对象脏对象(Dirty Object)。这这些脏对象,或堆中脏区域的引用,通过会记录在一个专门的数据结构中,这就是卡表。
在 C4 算法中,并没有重标记(Re-Marking)这个阶段,在第一次便利整个堆时就会将所有可达对象做标记。因为运行时不需要做重标记,也就不会陷入无限循环的重标记陷阱中,由此而降低了应用程序因无法分配到内存而抛出 OOM 错误的风险。
C4 算法中的重定位——应用程序线程与GC的协作
C4算法中,重定位阶段(Reloacation Phase)是由 GC 线程和应用程序线程以协作的方式,并发完成的。这是因为 GC 线程和应用程序线程会同时工作,而且无论哪个线程先访问将被移动的对象,都会以协作的方式帮助完成该对象的移动任务。因此,应用程序线程可以继续执行自己的任务,而不必等待整个垃圾回收周期的完成。
正如 Figure 2 所示,碎片内存页中的活动对象会被重定位。在这个例子中,应用程序线程先访问了要被移动的对象,那么应用程序线程也会帮助完成移动该对象的工作的初始部分,这样,它就可以很快的继续做自己的任务。虚拟地(指相关引用)可以指向新的正确位置,内存也可以快速回收。

如果是 GC 线程先访问到了将被移动的对象,那事情就简单多了,GC 线程会执行移动操作的。如果在重映射阶段(Re-Mapping Phase,后续会提到)也访问这个对象,那么它必须检查该对象是否是要被移动的。如果是,那么应用程序线程会重新定位这个对象的位置,以便可以继续完成自己任务。(对大对象的移动是通过将该对象打碎再移动完成的。如果对这部分内容感兴趣的话,推荐阅读一下相关资源中的这篇白皮书 C4-the-Continuously-Concurrent-Compacting-Collector.pdf)
当所有的活动对象都从某个内存也中移出后,剩下的就都是垃圾数据了,这个内存页也就可以被整体回收了。正如 Figure 2中所示。
关于清理:
在 C4 算法中并没有清理阶段(Sweep Phase),因此也就不需要这个在大多数垃圾回收算法中比较常用的操作。在指向被移动的对象的引用都更新为指向新的位置之前,From 页中的虚拟地址空间必须被完整保留。所以 C4 算法的实现保证了,在所有指向这个页的引用处于稳定状态前,所有的虚拟地址空间都会被锁定。然后,算法会立即回收物理内存页。
很明显,无需执行 Stop-The-World 式的移动对象是有很大好处的。由于在重定位阶段,所有活动对象都是并发移动的,因此它们可以被更有效率的放入到相邻的地址中,并且可以充分的压缩。通过并发执行重定位操作,堆被压缩为连续空间,也无需挂起所有的应用程序线
算法中的重映射
在重定位阶段,某些指向被移动的对象的引用会自动更新。但是,在重定位阶段,那些指向了被移动的对象的引用并没有更新,仍然指向原处,所以它们需要在后续完成更新操作。C4 算法中的重映射阶(Re-Mapping Phase)负责完成对那些活动对象已经移出,但仍指向那些的引用进行更新。当然,重映射也是一个协作式的并发操作。
在重定位阶段,活动对象已经被移动到了一个新的内存页中。在重定位之后,GC 线程立即开始更新那些仍然指向之前的虚拟地址空间的引用,将它们指向那些被移动的对象的新地址。垃圾回收器会一直执行此项任务,直到所有的引用都被更新,这样原先虚拟内存空间就可以被整体回收了。
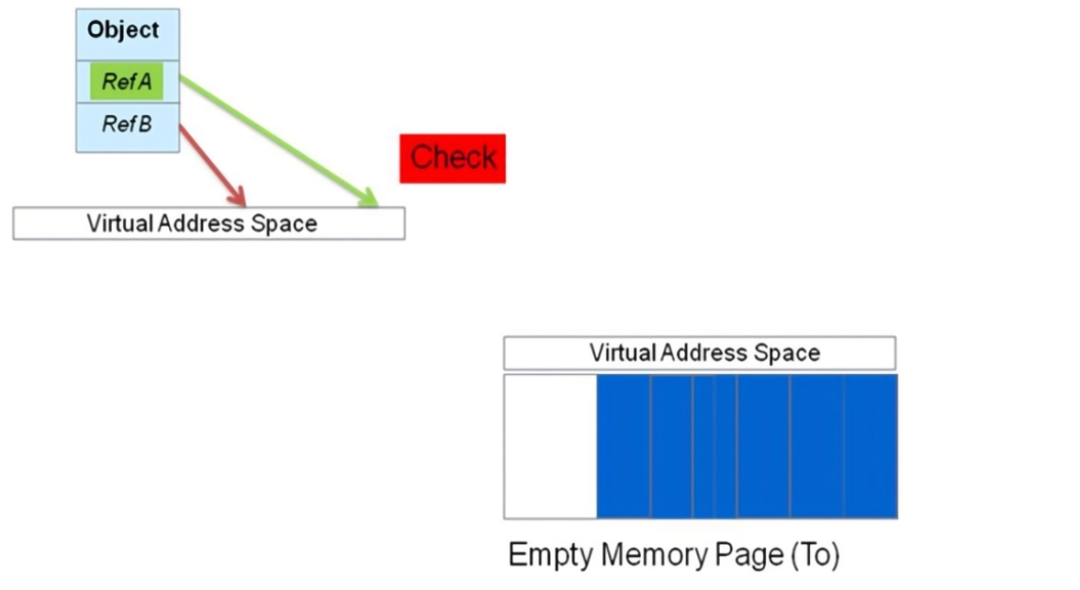
但如果在 GC 完成对所有引用的更新之前,应用程序线程想要访问这些引用的话,会出现什么情况呢?在 C4 算法中,应用程序线程可以很方便的帮助完成对引用进行更新的工作。如果在重映射阶段,应用程序线程访问了处于非稳定状态的引用,它会找到该引用的正确指向。如果应用程序线程找到了正确的引用,它会更新该引用的指向。当完成更新后,应用程序线程会继续自己的工作。
协作式的重映射保证了引用只会被更新一次,该引用下的子引用也都可以指向正确的新地址。此外,在大多数其他 GC 实现中,引用指向的地址不会被存储在该对象被移动之前的位置;相反,这些地址被存储在一个堆外结构(Off-Heap Structure)中。这样,无需在对所有引用的更新完成之前,再花费精力保持整个内存页完好无损,这个内存页可以被整体回收。
C4 算法真的是无暂停的么?
在 C4 算法的重映射阶段,正在跟踪引用的线程仅会被中断一次,而这次中断仅仅会持续到对该引用的检索和更新完成,在这次中断后,线程会继续运行。相比于其他并发算法来说,这种实现会带来巨大的性能提升,因为其他的并发立即回收算法需要等到每个线程都运行到一个安全(Safe Point),然后同时挂起所有线程,再开始对所有的引用进行更新,完成后再恢复所有线程的运行。
对于并发压缩垃圾回收器来说,由于垃圾回收所引起的暂停从来都不是问题。在 C4 算法的重定位阶段中,也不会有再出现更糟的碎片化场景了。实现了 C4 算法的垃圾回收器也不会出现背靠背(Back-To-Back)式的垃圾回收周期,或者是因垃圾回收而使应用程序暂停数秒甚至数分钟。如果你曾经体验过这种 Stop-The-World 式的垃圾回收,那么很有可能是你给应用程序设置的内存太小了。你可以试用一下实现了 C4 算法的垃圾回收器,并为其分配足够多的内存,而完全不必担心暂停时间过长的问题。
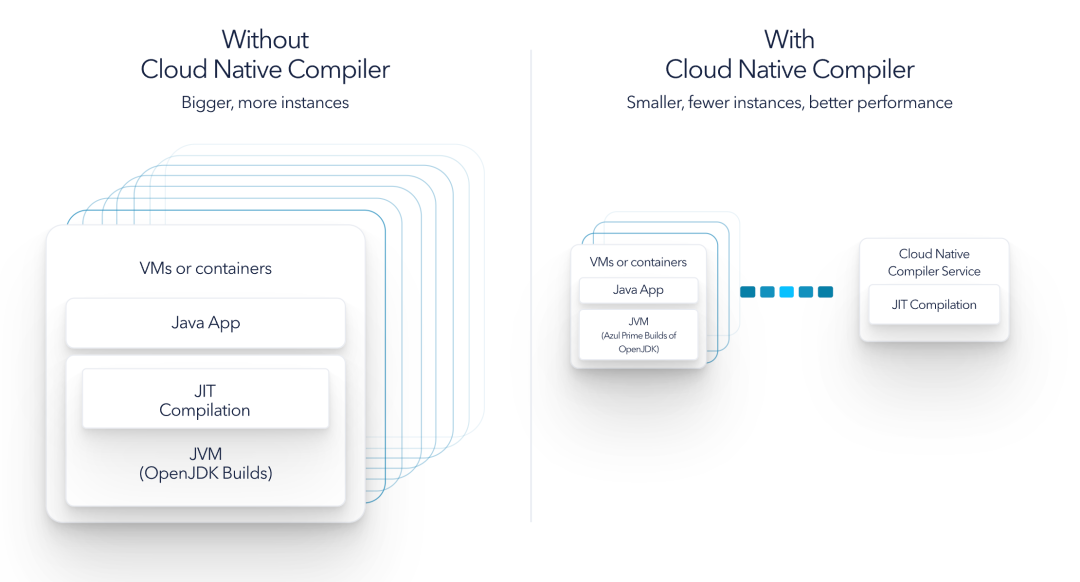
云原生编译器
Cloud Native Compiler 是 Optimizer Hub 的一个组件,提供服务器端优化解决方案,将 JIT 编译卸载到单独的专用服务资源,为 JIT 编译提供更多处理能力,同时使客户端 JVM 免于在本地进行 JIT 编译的负担。将字节代码编译为优化机器代码的繁重工作与 Java 应用程序的实际运行分开。
四 总结
ZingJDK的优势
更好的性能
支持 Zing 的 Falcon JIT 编译器是使用 LLVM 技术构建的,其可提供深入的优化。
更快速启动
凭借 ReadyNow!® 技术,支持 JIT 编译卸载,Java 应用程序启动速度快,且能保持高速运行。
支持进程快照
正在内测 JVM 虚拟机进程快照技术,支持秒级恢复 100GB 级 Java 进程,为 Java Serverless 弹性开创新可能。
无停顿执行 【★】
C4 解决了Java GC 停顿、停滞和抖动周旋。并支持较宽的 JDK 版本(7~21)
C4 算法的价值:
并发压缩是 C4 很大的优势。使应用程序线程 GC 线程协作运行,保证了应用程序不会因 GC 而被阻塞。
消除了重标记可能引起的重标记无限循环,也就消除了在标记阶段出现 OOM 错误的风险。
压缩,以自动、且不断重定位的方式消除了固有限制:堆中活动数据越多,压缩所引起的暂停越长。
垃圾回收不再是 Stop-The-World 式的,大大降低垃圾回收对应用程序响应时间造成的影响。
没有了清理阶段,降低了在完成 GC 之前就因为空闲内存不足而出现 OOM 错误的风险。
内存可以以页为单位立即回收,使那些需要使用较多内存的 Java 应用程序有足够的内存可用。
C4 将内存分配和提供足够连续空闲内存的能力完全区分开。C4 使你可以为 JVM 实例分配尽可能大的内存,而无需为应用程序暂停而烦恼。
ZingJDK的缺点
ZingJDK 为了追求极致性能,不支持 Java 动态 Attach 类型的动作。
ZingJDK 是商业化 JDK,引入到企业需要支付授权费用。
部分场景。如果引入 ZingJDK 在成本压缩,可以超过授权费用,或者追求 RT 性能,不得不优化。也是不错的选择。

