一 背景
在日常的技术支持过程中,经常会遇到如下玄学问题的咨询:
从监控上看,进程资源占用正常。
从监控上看,服务流量平稳,没有流量突增。
从监控上看,线程池状态正常,没有瓶颈。
但是,在上述条件下,上游调用方还是时不时反馈偶现 Thread pool is EXHAUSTED!
接下来笔者来把这个问题系统梳理下,帮助大家厘清这个问题的本质。
二 Thread pool is EXHAUSTED介绍
Thread pool is EXHAUSTED 是 Dubbo 中一个非常常见的现象,要理解它首先需要理解 Dubbo 服务端的线程模型。
Dubbo 服务端线程模型,我们站高一点鸟瞰的话,它本质上是一个经典的“生产-消费”模型:
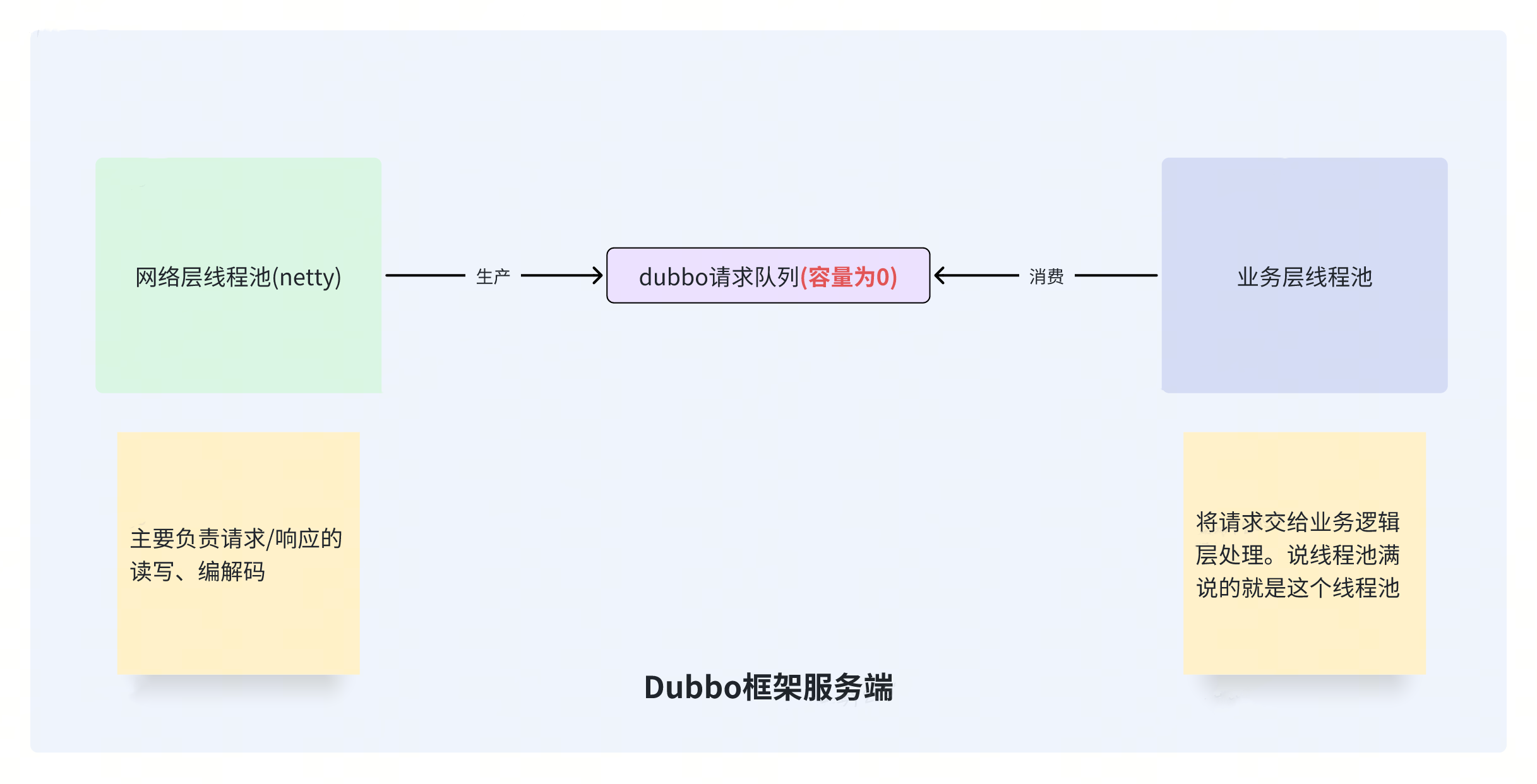
需要注意的是,与常见的“生产-消费”模型不一样的是,中间的队列容量为 0,不会暂存、堆积请求。
详见:java.util.concurrent.SynchronousQueue
如果请求入列失败,则直接快速失败,中断请求处理。其实细想也很合理,实时请求链路上如果暂存、堆积请求的话,要是链路上某个环节抖动了一下,直接全链路雪崩。
详见:org.apache.dubbo.remoting.transport.dispatcher.WrappedChannelHandler#sendFeedback
当网络层的生产速率大于业务层的消费速率时,就会产生 Thread pool is EXHAUSTED 异常。导致该异常的业代码层面的原因本质就是:请求处理慢导致消费慢。
在这个本质下,有如下典型的原因:
DB 慢查询,能产生 P1 故障的那种。
锁,互斥锁引起的并发度低,导致请求处理慢。
死锁,极端一点的锁问题,业务层线程全被夯死了。
网络抖动,导致向下游的请求耗时变长。
别的类似的...
可以看到,上述常见的导致线程池满的原因,总会在监控上留下痕迹。只要能从监控信息上定位到请求处理瓶颈,那总是能对症下药优化好的,总的来说,有问题,但是问题不大。
有时也总会遇到监控数据看起来一切正常,但线程池耗尽了的情况,这就有点让人头皮发麻了。
三 玄学Thread pool is EXHAUSTED
所谓的玄学 Thread pool is EXHAUSTED,指的是类似开头描述的那种,从监控层面排查、追溯发现业务层请求处理没有瓶颈、没有抖动。线程池监控数据看起来也一直很健康,但是就是发生了线程池耗尽问题,影响了业务。
如果一直停留在 Java 进程层面看问题,那是无解了。但是如果我们把格局打开,视角再下沉一点,可能又有新思路了。
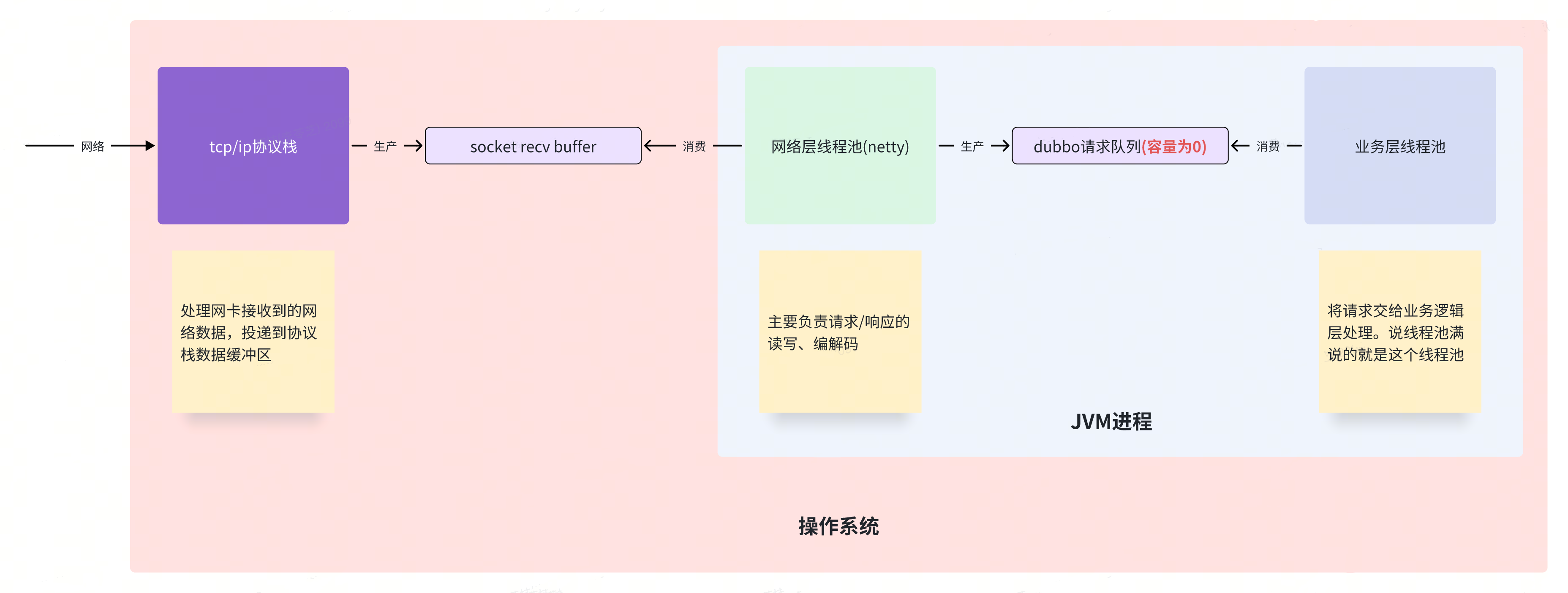
上面我们说过了,服务进程内的 Dubbo 框架线程模型是“生产-消费”模型,那在操作系统协议栈层面呢?数据从网卡流入进程的交互模型是什么样的呢?
我们站高一点鸟瞰的话,数据从网卡流入进程的交互模型本质上也是是一个经典的“生产-消费”模型:
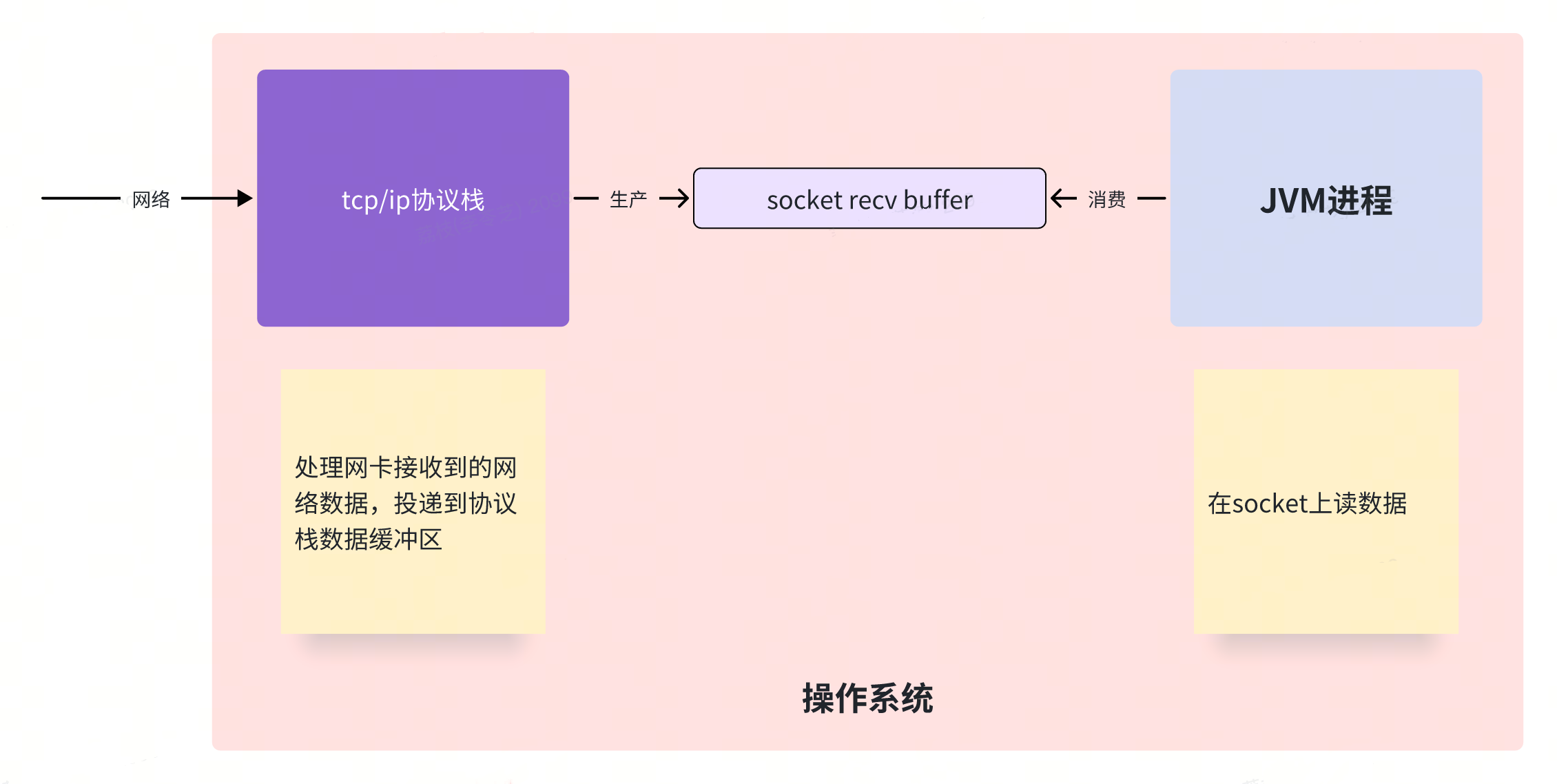
协议栈和进程中间也有一个缓冲队列,就是大家肯定都背过的八股文里常说的用于流量控制的 TCP 环形缓冲区。
在 Java 语言层面暴露的 API 如下图:

java.net.Socket#setReceiveBufferSize
总之,经过上述分析(洗脑),大家都知道了,操作系统协议栈和 JVM 进程间存在一个数据缓冲区。
正常来说,基于这个数据缓冲区的生产-消费速率是匹配的,因为 TCP 的流量控制可以背压,最终会让两端速率匹配上。
但是,如果说突然因为某些原因,JVM 进程抖动了一下,从 socket recv buffer 中消费数据的逻辑突然停顿了一下,如下图:
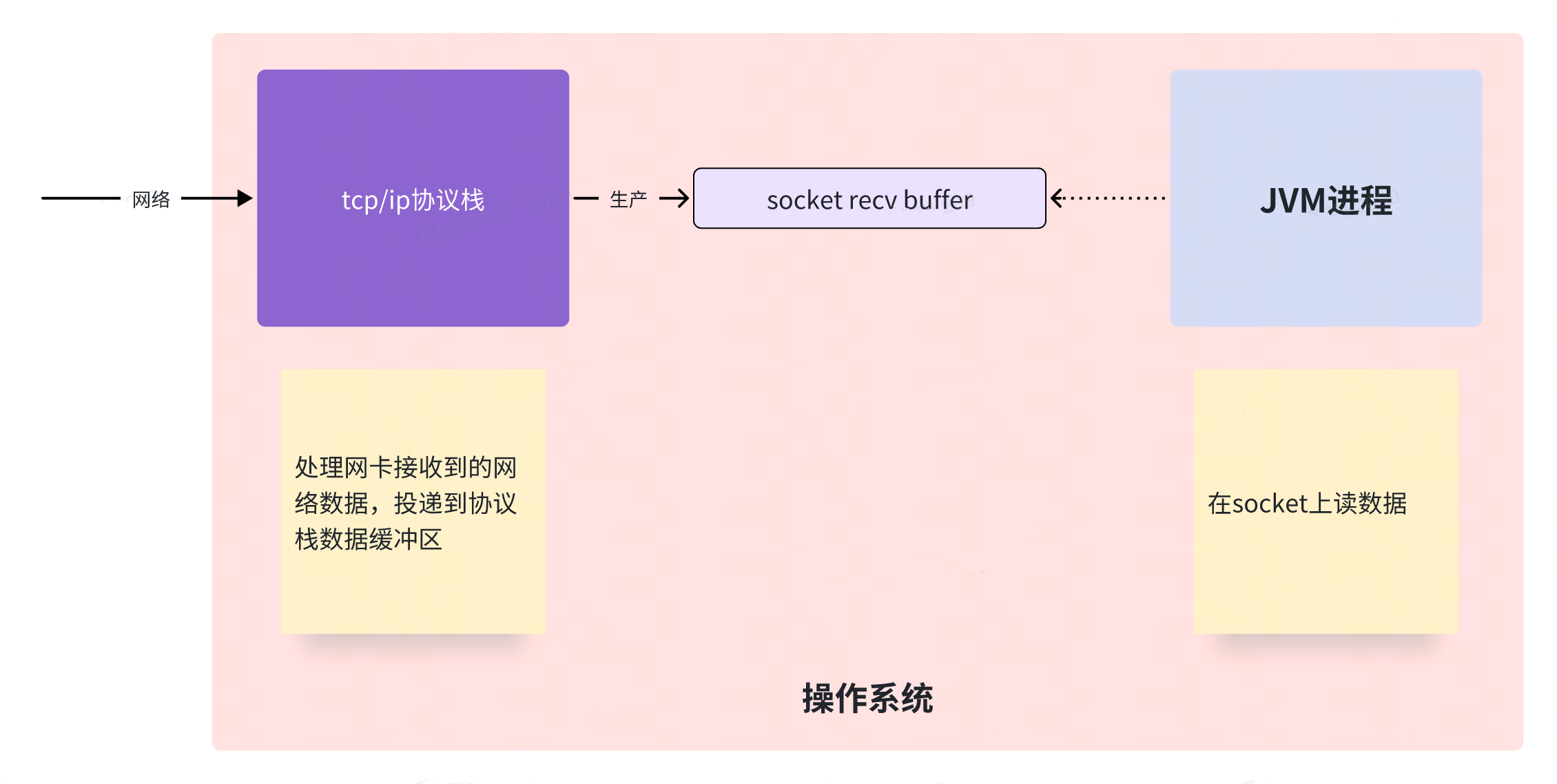
这个时候,网卡还在源源不断接收数据,然后投递到 recv buffer,直到 recv buffer 满,TCP 协议才会让对端减速。
到这个时候,recv buffer 里可能已经缓存了大量的 Dubbo 请求数据等待进程消费、读取、解码、触发业务逻辑。
小请求场景下更明显,比如一个请求 100byte,如果 socket recv buffer 的容量是 1024 byte 的话,那一个连接上可以缓冲 10 个小请求。
然后 JVM 进程停了一下又恢复了,进程里的网络层代码(Netty)会快速读取 recv buffer 中的数据,投递到业务层(Dubbo)。
总结来说就是 socket recv buffer 在特定场景下变成了请求蓄水池,然后脉冲式的一下子倾泻到业务层,进而会导致 Dubbo 线程池满。
这个过程发生的很快,按固定周期采样的监控数据无法体现这个过程。因为把尺度放大的话,由于对端发送请求的速率是稳定的,所以这个服务进程宏观监控视角上的平均 QPS 一直都是稳定的。
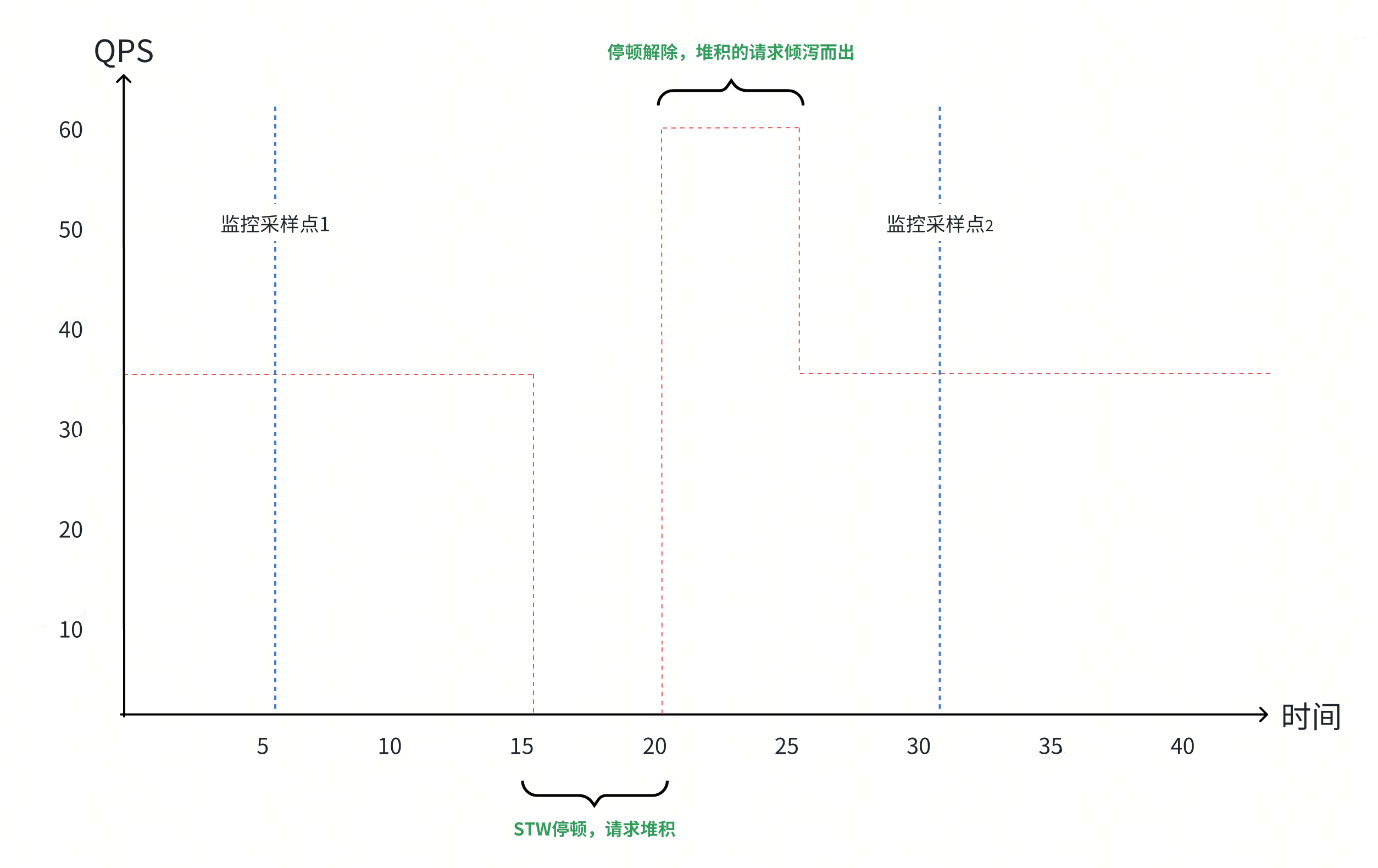
如图,在监控数据采样周期的时间尺度上,QPS 是稳定的。但是在更小的时间尺度上,QPS 产生了波峰波谷。
四 为什么不消费socket recv buffer
进程消费 socket recv buffer 的职责一般是由进程内网络层代码来承担,常见的网络层如 Netty,一般都是死循环(EventLoop)消费 socket recv buffer 的。所以正常情况下,消费延迟是可控的。
所以,如果网络层精心设计的死循环消费的代码不消费 socket recv buffer 中的数据了,最大的可能是消费 socket recv buffer 数据的线程(如 Netty 中的 EventLoop)停顿了。
线程停顿的原因,如果排除了对网络层库(比如 Netty)的错误使用,那往往是 JVM 进程直接整个停顿了,也就是 STW。
一说到 STW,大家可能就不困了,条件反射的就想着 GC 了。这里必须要科普一点就是:GC 会导致 STW,但是不光 GC 会导致 STW。
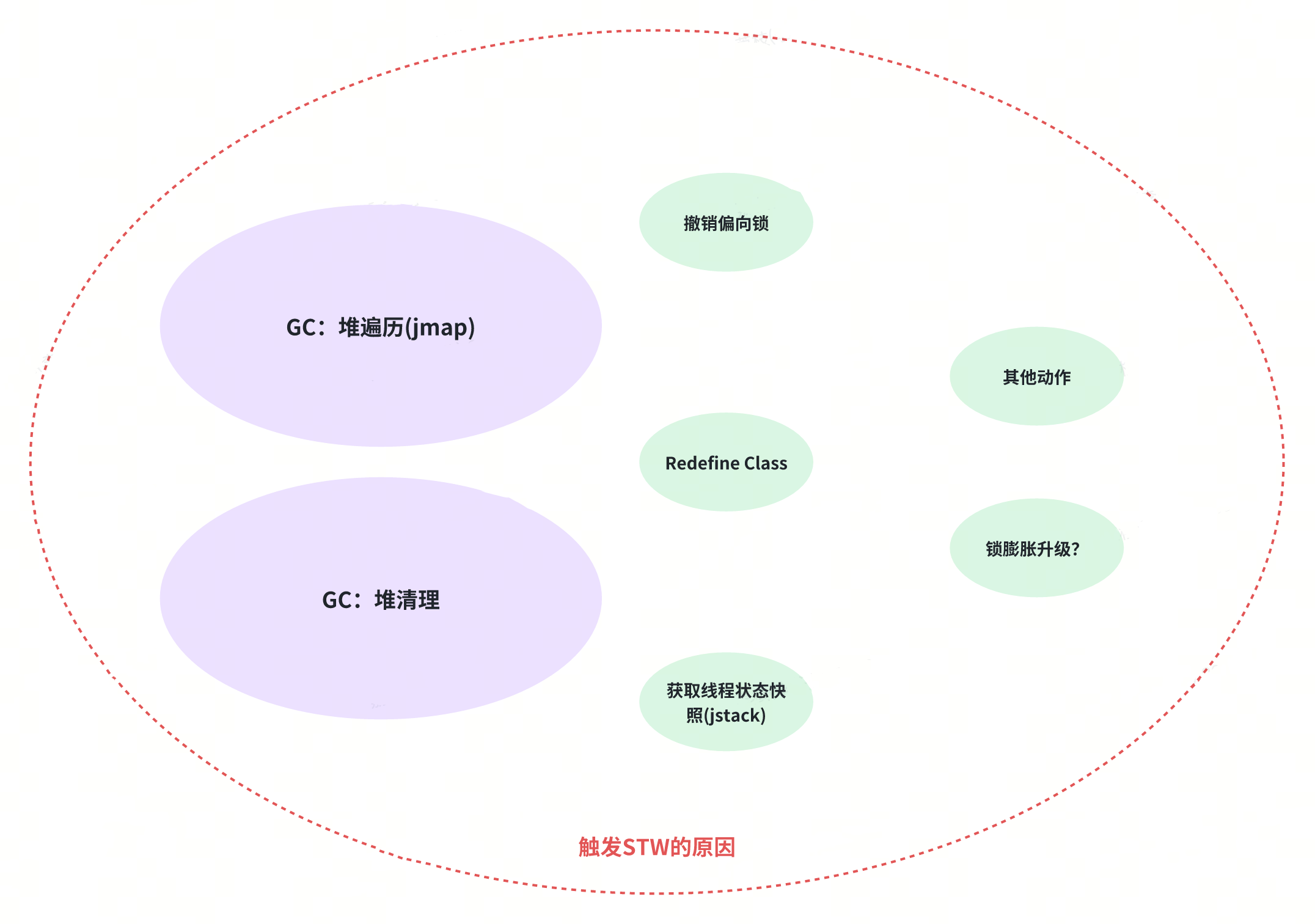
GC 是 STW 的充分不必要条件
STW 机制是 JVM 内部的一个基础机制,JVM 作为一个托管业务代码的 Runtime,在运行时进行一些监管、清理、优化等动作的时候,为了保证数据视图稳定一致、避免数据竞争,就会想办法让进程里的线程都停下来,让 JVM 执行托管动作。
JVM 将上述的监管、清理、优化等动作按 OOP 思想(模板方法设计模式)抽象为 VM_Operation 类,需要执行托管动作时就创建 VM_Operation,入列、出列、STW、执行,也就是说 VM_Operation 会触发 STW。
详见:Hotspot 垃圾回收之 VM_Operation 源码解析(https://blog.csdn.net/qq_31865983/article/details/103788358)
JDK8 源码中搜索到的 VM_Operation 子类有:
VM_Operation 驾到,所有线程统统闪开~
五 怎么追溯JVM进程STW
一路分析下来,我们发现压力全来到了 STW 这边,那么问题来了,我怎么知道 JVM 在事发时有没有 STW 过?
JVM STW 之前一定会先进入安全点,所以线索又到了安全点这里。
STW 和安全点的关系详见:JVM stop the world(https://zhuanlan.zhihu.com/p/91937583)
JVM 暴露了安全点的进、出事件日志,可以通过开关打开,后续可以通过安全点时间日志追溯。
添加如下启动参数,即可打开安全点事件日志:
-XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1
日志示例:

在 JVM 启动 5.141 秒后,因为【撤销偏向锁】进入安全点,STW 持续了 0.0000782 秒,其中让所有线程停下来花了 0.0000269 秒。
详见:通过 JVM 日志来进行安全点分析(https://developer.aliyun.com/article/486349)
六 总结
如上述的 Thread pool is EXHAUSTED 异常,结合应用层框架原理和底层网络原理可以推导出如下问题路径:
JVM STW阻塞了应用层网络框(Netty)IO读写。
网络数据驻留、堆积在协议栈 Buffer 中。
JVM STW解除后,应用层网络框架(Netty)快速的读取协议栈 Buffer 中的数据。
形成流量尖刺,超过应用层RPC框(Dubbo)的承载能力。
产生Thread pool is EXHAUSTED 异常。
同时,在诊断应用层框架或代码的异常行为时,在仔细审查、推敲代码逻辑以外,必要时还需要视角向下,考虑基础设施、底层能力的特性、行为。

