本文将从工业界物流领域视角出发,分享如何基于观测数据提升营销策略效率。
01
因果推断与营销观测数据
因果推断是一种用于确定一个事件(因)是否导致了另一个事件(果)的一种技术。在很多场景中,相关性不等于因果性。如在温度升高的情况下,冰淇淋销量与溺水量之间存在相关性,但两者之间不存在因果性。营销场景更希望关注因果性,如补贴/定价的原因如何影响结果单量的增长。相关性包含因果性,相关性主要产生于:因果(causation)、混淆(confounding)、样本选择偏差(selection bias)。

营销与每个人都息息相关,营销的底层逻辑在于创造需求、满足需求和唤醒需求。货拉拉营销的一个主要目标就是用户增长,在增长体系中,AARRR 关注获客渠道,RARRA 关注留存唤醒需求,Growth Loop 同时关注获客和留存,构成增长飞轮,可形成复利。营销工具包括:触达、广告、线索、补贴、定价等。随着营销技术的增长,营销领域逐步实现智能化。智能营销是通过大数据和 AI 技术实现营销自动化、精准化、最优化。
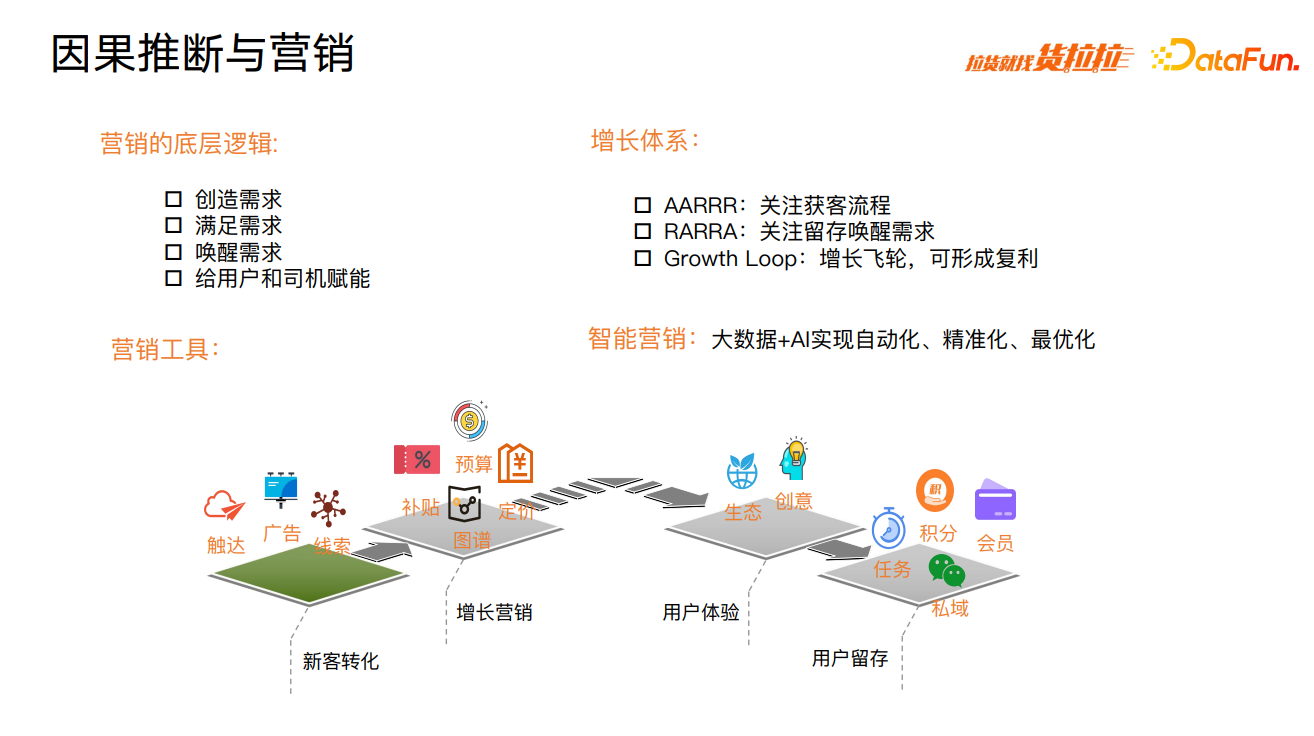
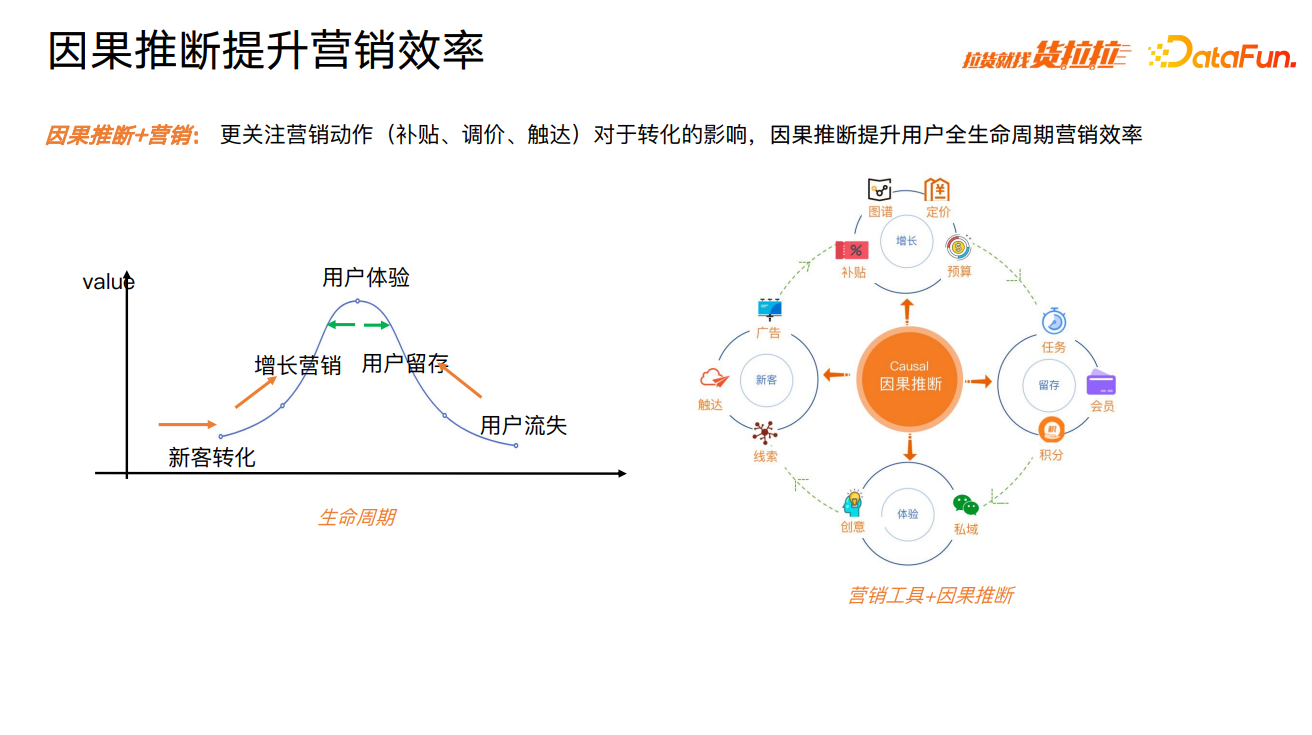
货拉拉使用因果推断技术,在所有营销领域实现了营销效率的提升,该技术覆盖了新客转化、用户增长、用户体验、用户留存、用户召回等用户全周期。
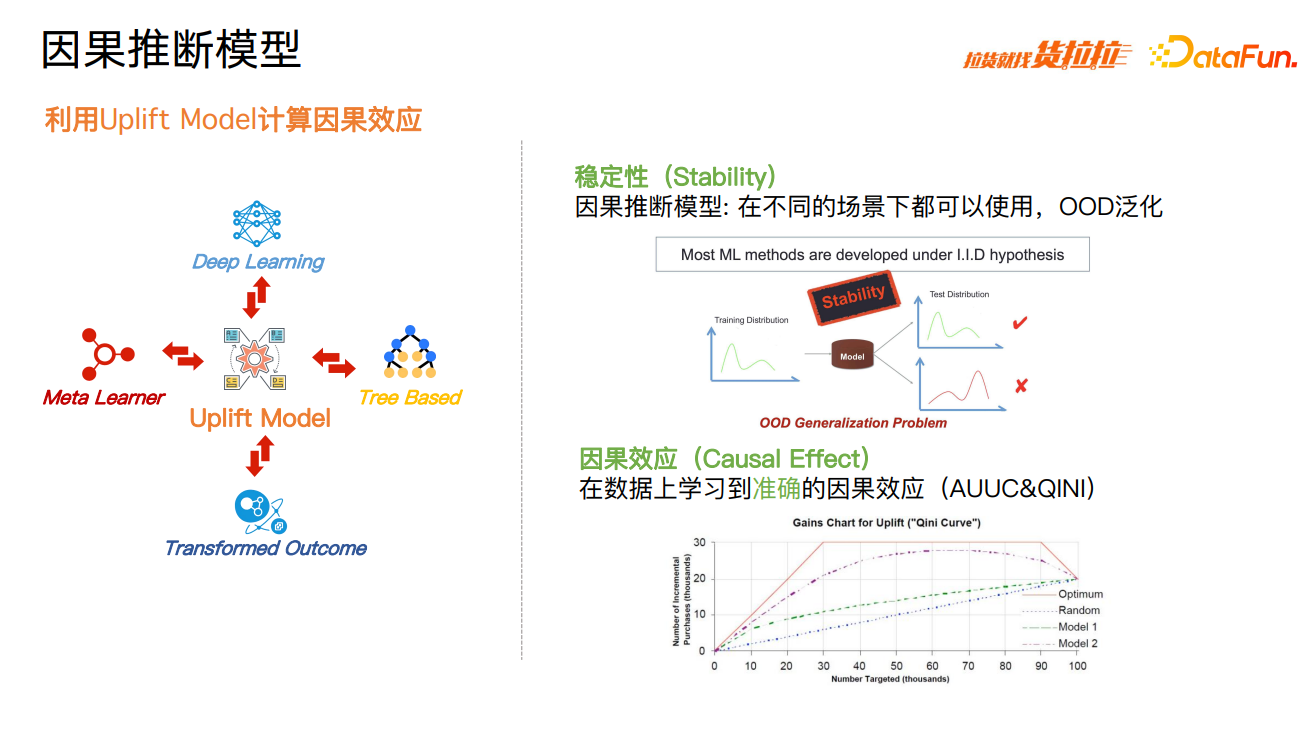
因果推断模型主要选择 Uplift Model 计算因果效应,并结合运筹优化策略来使用。Uplift Model 经过长时间的演变,目前演化出不同的技术方向,包括 Meta Learner、因果树、Deep Learning 等。
我们对因果推断模型最主要的要求有两方面:一是稳定性,在不同的场景下都可以使用,解决 OOD 泛化问题;二是能够在数据上学习到准确的因果效应,在工业上,如果没有学到好的因果效应,上线后就会产生负向的收益,因此准确性是非常重要的。
因果建模一定会使用到各种数据,可以分为随机试验数据(RCTs)和观测数据(Observational Data)。随机试验数据是最完美的数据,不用考虑混杂因素的影响,可以直接计算因果效应;但工业上随机试验数据成本极高,在货拉拉业务上可行性低。企业中更多使用的是观测数据,其优势在于成本低、数据量大,通过日常运营积累就可获得;但观测数据与混杂因素相关联,影响因果效应的计算。

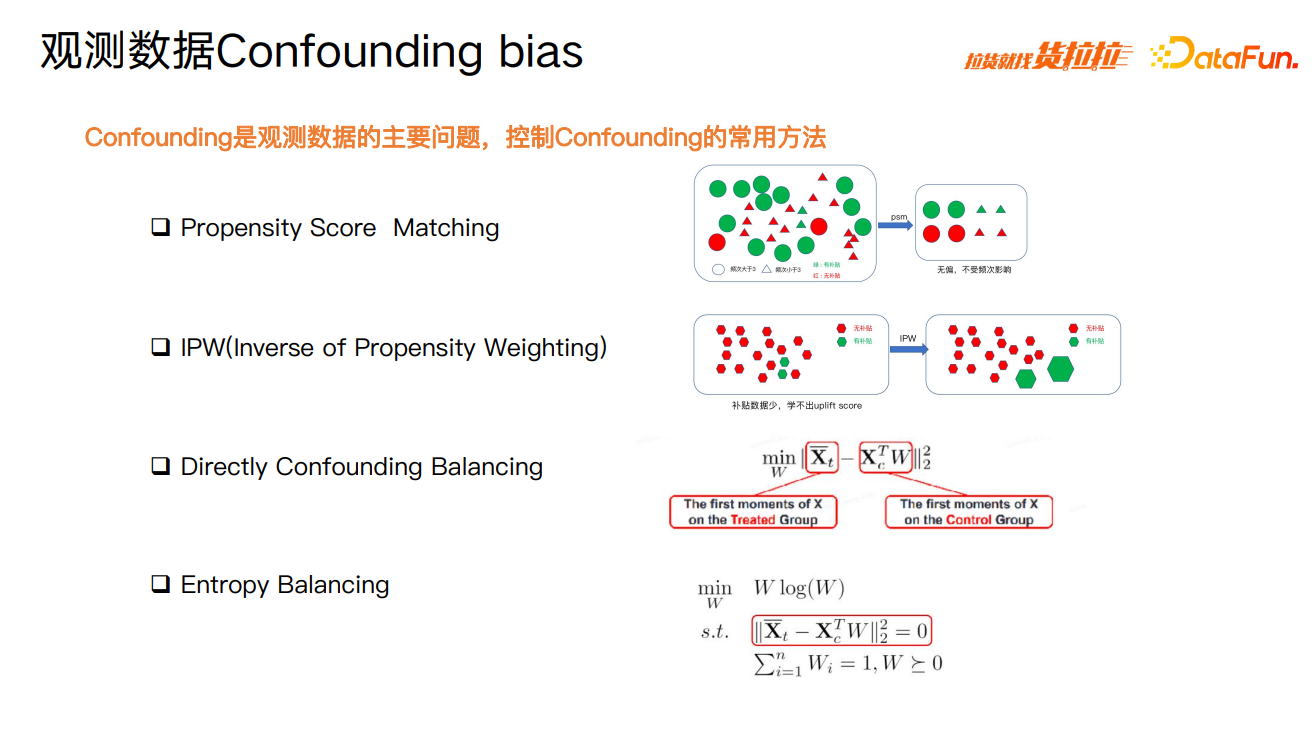
混杂因素是观测数据的主要问题,控制混杂因素的常用方法包括,倾向得分匹配(Propensity Score Matching)、逆向倾向加权(IPW)、混杂因素平衡(Directly Confounding Balancing)、熵平衡(Entropy Balancing)等。
熵平衡方法是在Directly Confounding Balancing 方法基础上优化得来的,目标是最小化熵,或者保证熵平衡,以 Confounding balance 作为限制条件,再加上一个权重的约束,从而保证平滑性。
在货拉拉,最常用的方法是 IPW 和熵平衡。求出权重值,给样本赋予权重,控制混杂因素。
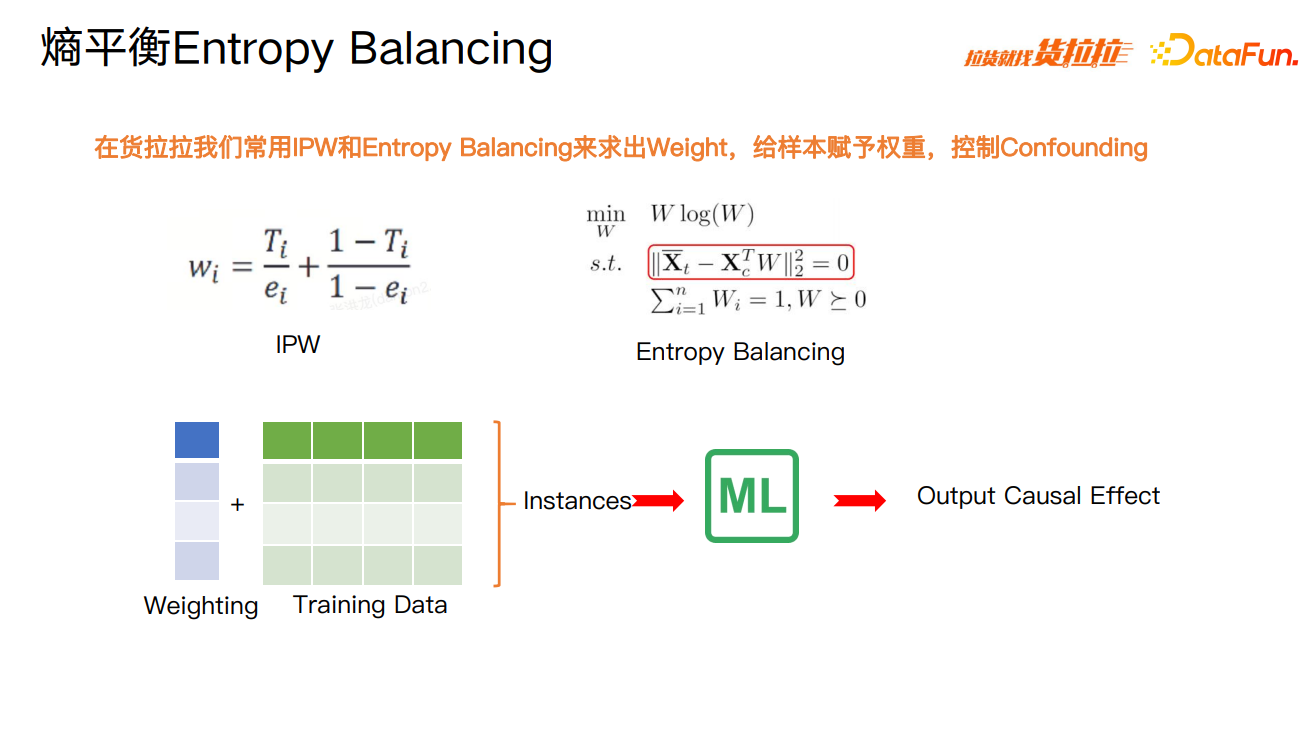
熵平衡方法和其它方法相比,具有以下三点优势:直接约束协变量平衡效果好;直接使用观测数据,无其他约束;使用全量数据,数据利用率高,权重平滑。

02
物流行业技术挑战
根据前文介绍,熵平衡是一种很理想的方法。但在实际的物流行业中,仍然面临着如下一些挑战:
精细化,要求运营策略能够精细化到某个地理围栏;
稳定性,物流行业场景多,需要一个模型适用多个场景;
效果好,要求 Uplift score 要准确,在观测数据质量下降的情况下依然保持因果效应学习质量。

物流行业受时间、空间影响比较大。
在时间维度上:①订单受时间影响大,每天存在两个高峰期,不在时间轴上均匀分配,引入了时间不平衡性;②同城货运中周一到周五单量多,周末单量少;③搬家周末单量多,周中单量少;④每天晚上22点-第二天6点单量稀疏。
在空间维度上:①市中心单量多,郊区单量少;②一、二线城市单量多,三、四线城市单量少;③专业市场(建材、水果、服装)单量多,居民区单量少。
因此,因果效应学习过程中在时间和空间会自然引入不平衡效应,导致在某些时空领域内因果效应学习不准确。
03
时空领域熵平衡
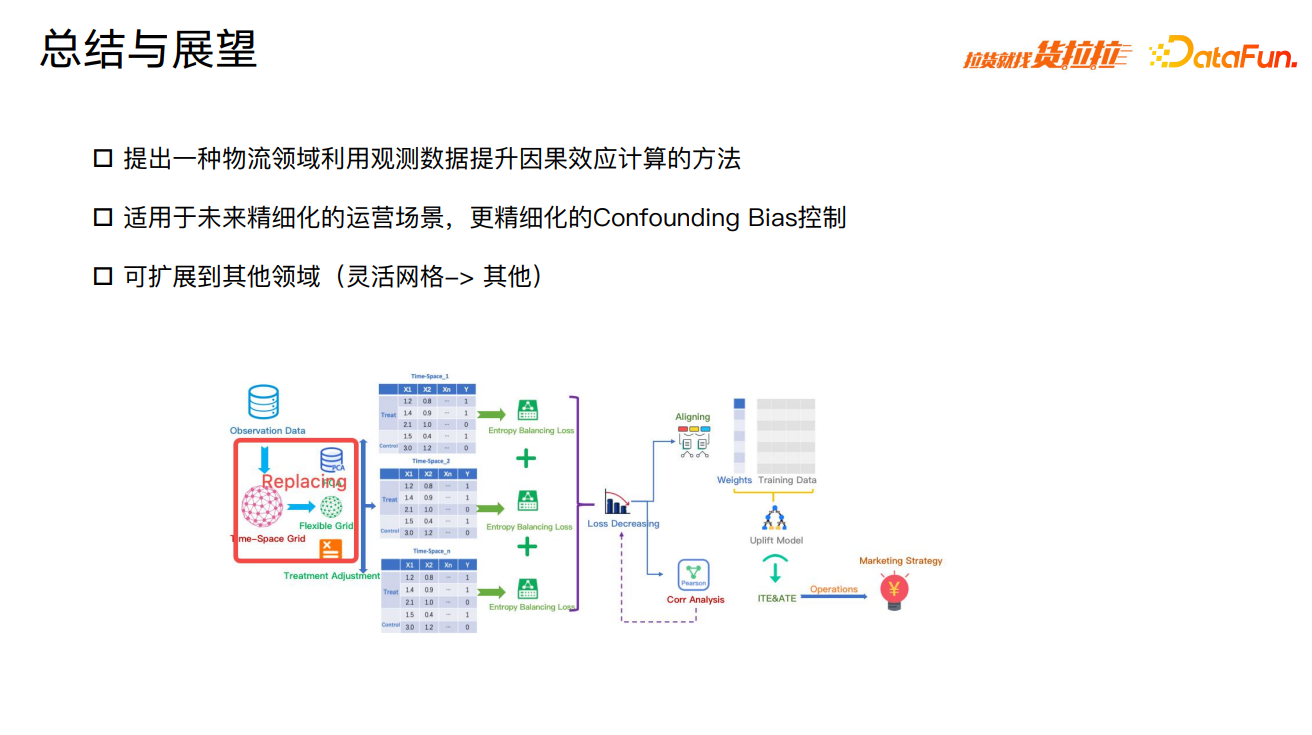
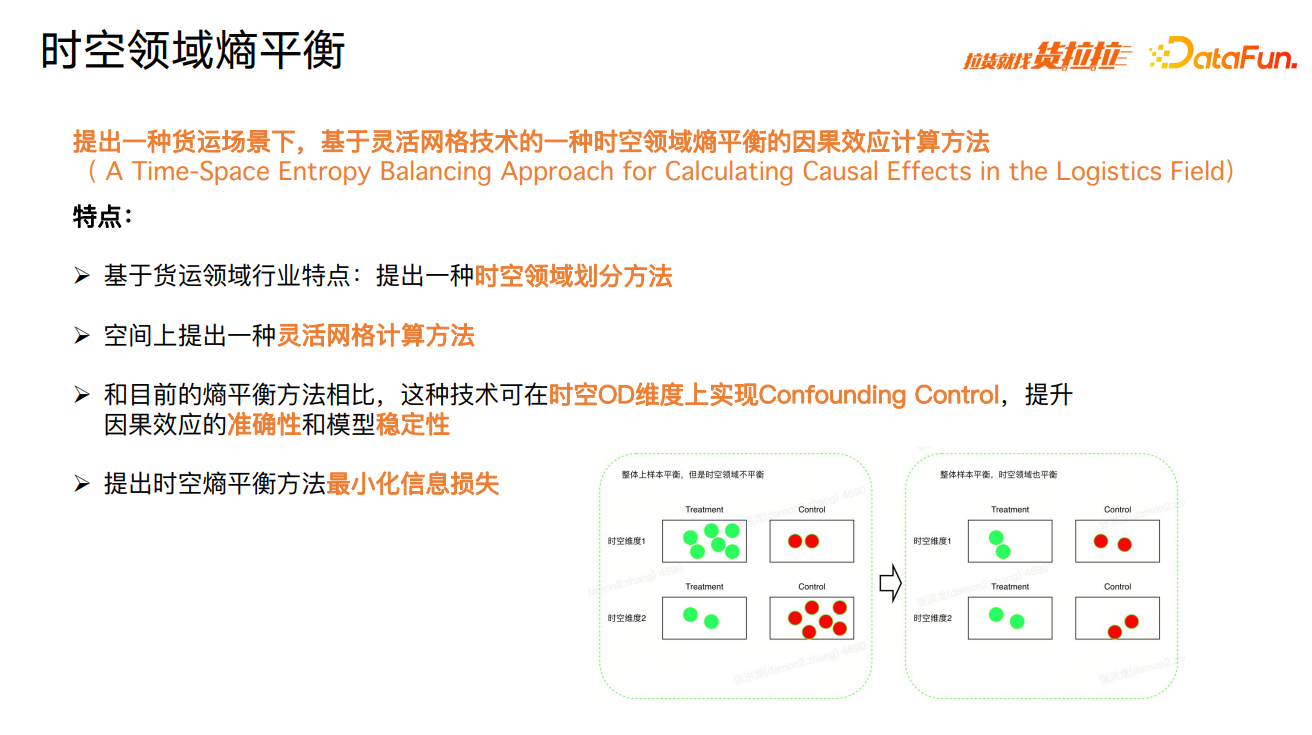
基于以上技术挑战,提出货运场景下,一种基于灵活网格技术的时空领域熵平衡的因果效应计算方法,提升因果效应计算的准确性。
这种方法包含几个特点:①基于货运领域行业特点,提出一种时空领域划分方法;②空间上提出一种灵活网格计算方法;③和目前的熵平衡方法相比,这种技术可在时空 OD 维度上实现 confounding control,提升因果效应的准确性和模型稳定性;④提出时空熵平衡方法最小化信息损失。
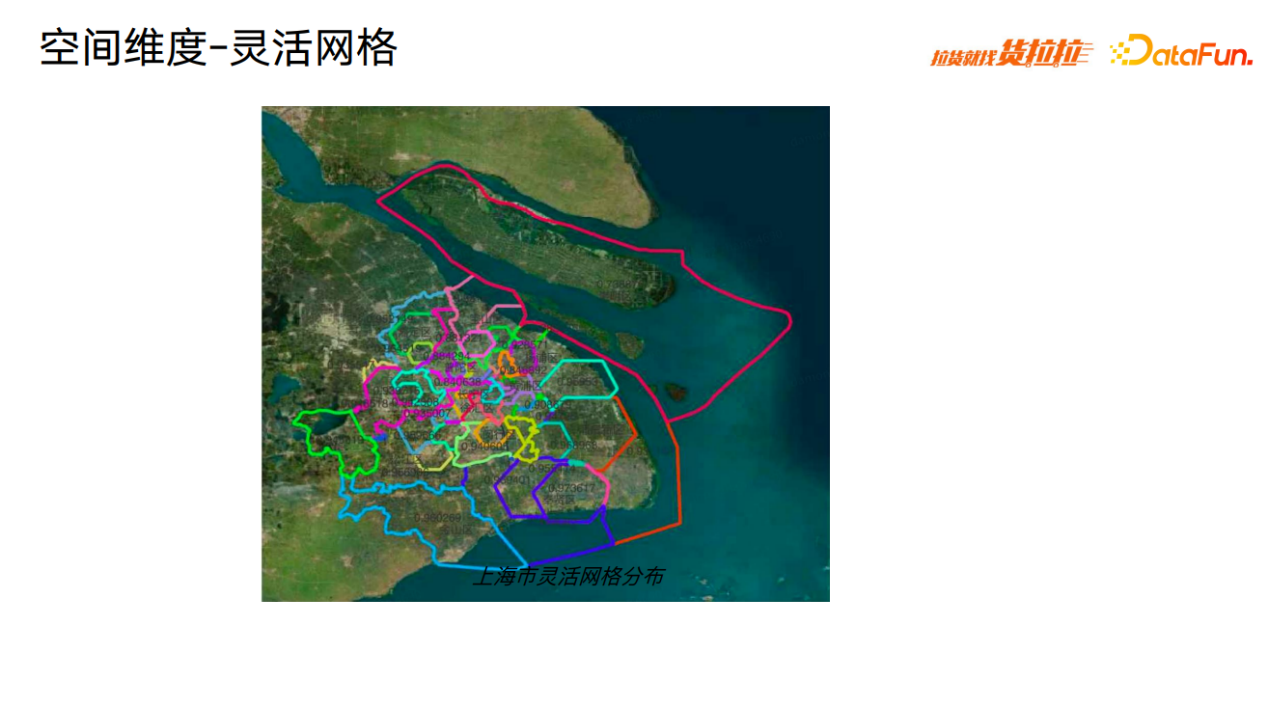
算法实现上,时间维度根据订单密度进行划分,空间维度使用灵活网格方法进行划分。H3 蜂窝网络由网约车平台 Uber 提出,是一个针对地球的空间划分和空间索引系统,可将地理空间分割为若干正六边形网格,并用 0-15 级分别定义网格大小。

灵活网格基于基础网格和订单量,将若干 H3 网格(同城物流 10 级,跨城物流 6 级)进一步聚合,以提高网格内的订单密度,灵活网格地理上仍是连通的。其中,聚合规则主要基于订单量,在保证网格尽量细的同时,保证每个网格内具有一定的订单量,以保证网格内因果效应学习的准确性。

以上海市为例,黄浦区、普陀区等上海市中心区域订单密度较大,网格就会划分得较为精细,单个灵活网格面积就会比较小。在崇明岛等上海郊区,区域内订单密度较小,按照网格内订单密度标准,划分的单个灵活网格面积就会较大。当订单密度标准变更时,灵活网格的划分也会随之变更。
基于时空网格划分,观测数据被细分到了不同的时空领域。之后,针对每一个时空领域,分别进行熵平衡损失的计算,再根据每一时空领域的信息含量进行加权,求解出总损失值。基于梯度下降的方法,求解熵平衡的权重系数,并在求解过程中持续观察干预与混杂因素之间的相关系数是否下降,相关系数下降才能保证损失求解是正确的。求解完成后,将得到的时空领域熵平衡权重值附加到观测数据上,使用 Uplift Model 计算 ITE 和 ATE,后配合运筹方法,最终实现营销策略的分发。
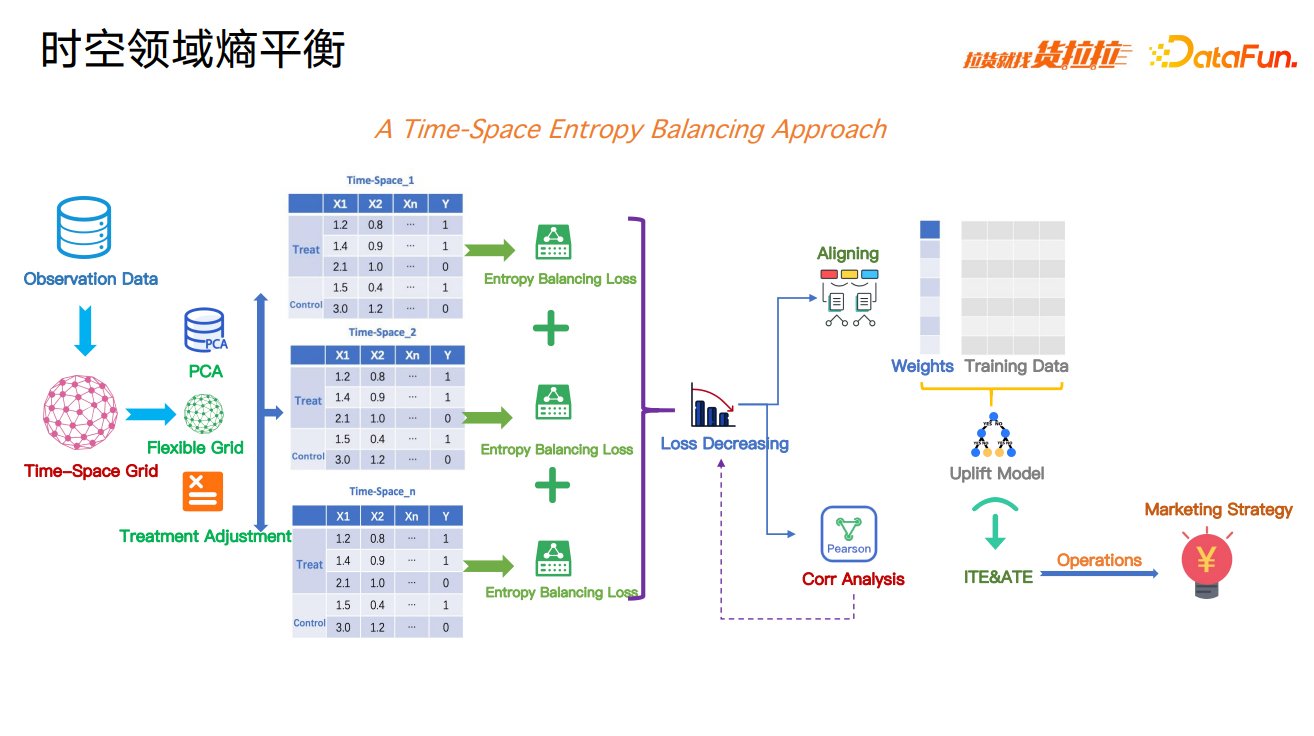
在数学推导上,基于传统的熵平衡方法进行了修改。目标是各时空网格内的熵平衡最小化,限制条件为在每个时空领域内保证混杂因素影响较小,并保证求解的权重系数平滑。这时,问题就转化为最优化问题,接下来使用拉格朗日对偶进行求解。

计算过程中为应对潜在的梯度爆炸问题,使用 PCA 对 confounding 特征进行降维,并设置灵活网格精细度的超参数。为应对凸函数的限定,根据业务常规性特点,如补贴和定价单调性特点,对干预进行微调以保证凸函数性质。

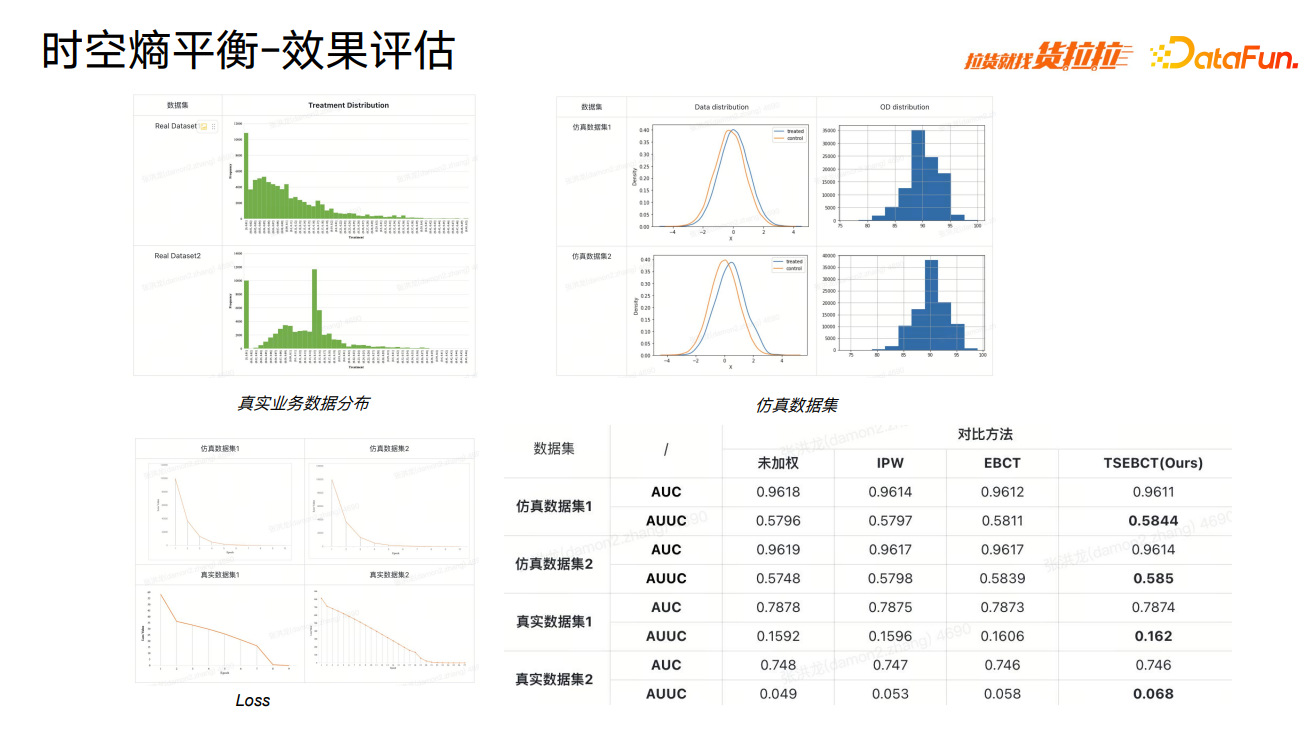
我们使用补贴和定价的真实业务数据,以及一些模拟数据,进行了验证,结果显示,loss 快速收敛。Loss 收敛速度与数据中 confounding 强度有关,如果强度较大,则收敛速度会降低。
为了验证人为改变观测数据分布对真实数据的结果会产生何种影响,我们使用 AUC 和 AUUC 指标来衡量模型准确度在数据更改情况下的变化,来验证模型的适应情况。结果显示,虽然 AUC 略有下降,但 AUUC 则会更强,该方法在不同数据集上的表现均符合预期。
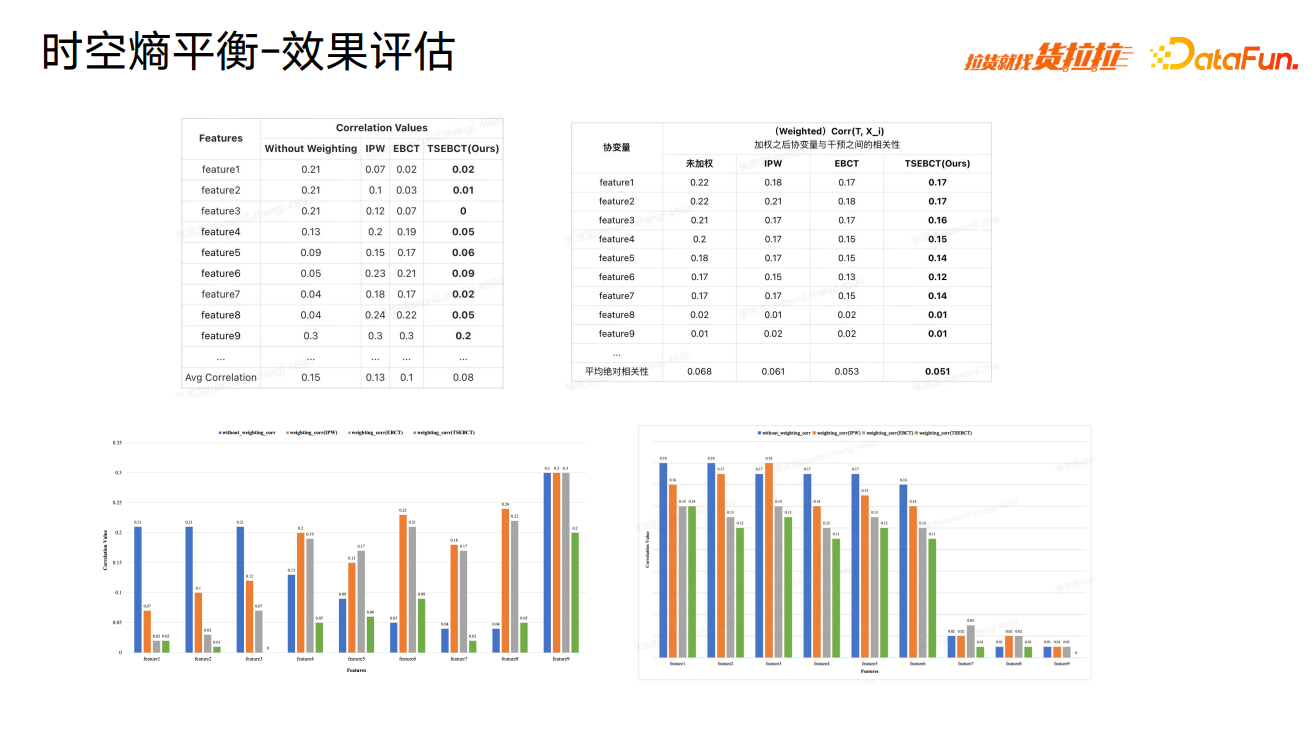
从各网格细粒度进行因果效应学习效果评估,和传统方法相比,在相关系数和 p-value 均有较好的提升,能更好地消除 confounding 的影响。时空熵平衡方法可保证各时空网格内混杂因素均能较好地消除。

04
总结与展望
本次分享是从业务角度,解决观测数据遇到的一个实际问题。针对物流领域,提出了一种利用观测数据提升因果效应计算的方法。适用于未来精细化的运营场景,更精细化的 confounding bias 控制。灵活网格划分方法可扩展至其他领域,针对业务中需进一步划分精细场景的因果推断问题,均可进行替换。