本文主要介绍离在线数据仓库建设在携程旅游团队的落地与实践,将从业务痛点、业务目标、项目架构、项目建设等维度展开。
一、业务痛点
随着数据实时化需求增多,离线数仓暴露出来的业务痛点也越来越多,例如:
实时需求烟囱开发模式
中间数据可复用性差
离在线数据开发割裂
数据生产→服务周期长
实时表/任务杂乱、无法管理
实时血缘/基本信息/监控等缺失
实时数据:质量监控无工具
实时任务:运维门槛高 质量体系弱
这类典型的问题,会对我们的人效、质量、管理等方面带来较大考验,亟待一个体系化的平台来解决。
二、业务目标
围绕已知业务痛点,依托于公司现有的计算资源、存储资源、离线数仓标准规范等,我们的目标是在人效、质量、管理这几个层面进行系统建设。如下图:
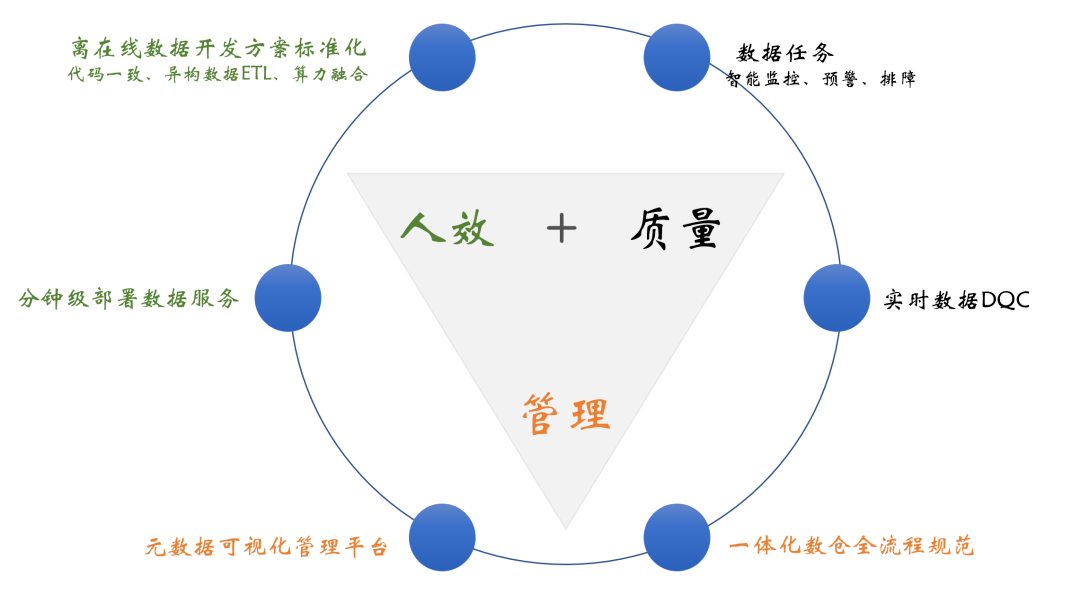
1.人效层面
实现离在线数据开发方案标准化,如标准化数据处理、离在线代码兼容、算力融合等
分钟级数据部署,实现BI同学层面的数据接口注册、发布、调试等可视化操作
2.质量层面
数据内容DQC,如内容对不对、全不全、是否及时、是否离在线一致等
数据任务预警,如有无延迟、有无反压、吞吐怎么样、系统资源够不够等
3.管理层面
可视化管理平台,如全链路血缘、数据表/任务、质量覆盖率等基本信息
一体化数仓全流程规范,如数据建模规范、数据质量规范、数据治理规范、存储选型规范等
三、项目架构
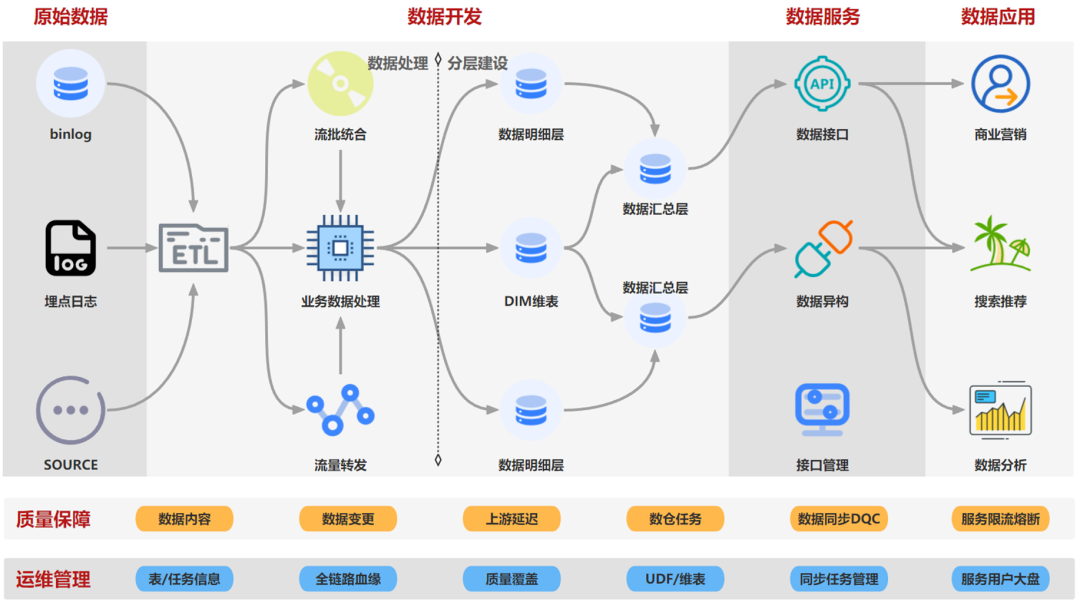
项目架构如下图,该系统主要包括:原始数据→数据开发→数据服务→数据质量→数据管理等模块,提供实时数据秒级处理、数据服务分钟级部署的能力,供实时数据开发同学、后端数据服务开发使用。
不同数据来源的数据首先经过标准化ETL组件进行数据标准化,并经过流量转发工具进行数据预处理,使用流批融合工具以及业务数据处理模块进行分层分域建设,生产好的数据使用数据服务模块直接将数据进行数据api部署,最终供业务应用使用,整个链路会有对应的质量和运维保障体系。
四、项目建设
1.数据开发
该模块主要包含数据预处理工具、数据开发方案选型。
1)流量转发工具
由于入口多、流量大,主要存在如下问题:
同维度的数据来源、解析方式可能有多种;
使用到的埋点数据占总量的比例大约20%,全量消费资源浪费严重,且每个下游都会重复操作;
新增埋点后,数据处理需要开发介入(极端情况下涉及到全部使用方);
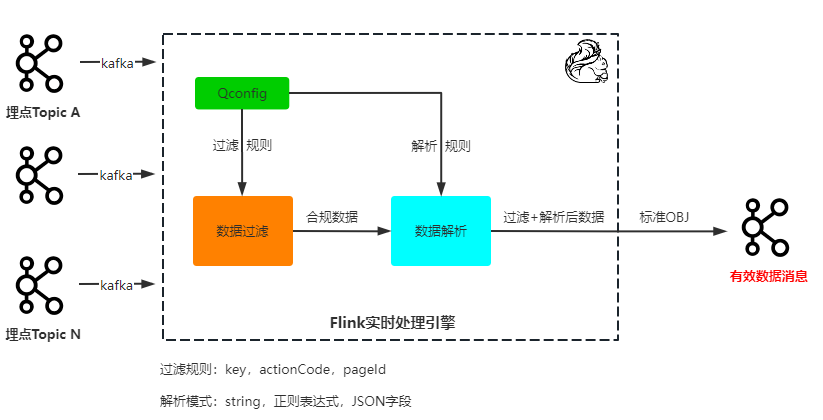
如下图,流量转发工具,具备动态接入多个数据源,并且做简单的数据处理,并且将有效数据进行标准化后写入下游,可解决上述问题。
2)业务数据处理方案演进
①方案1-离在线数据简单融合
背景
由于最开始的时候业务需求比较单一,如计算用户历史的实时订单量、聚合用户历史购买过的景点信息等。这类简单需求可以抽象成离线数据和实时数据简单聚合,如数值型的加减乘除、字符型的append、去重汇总等。
解决方案
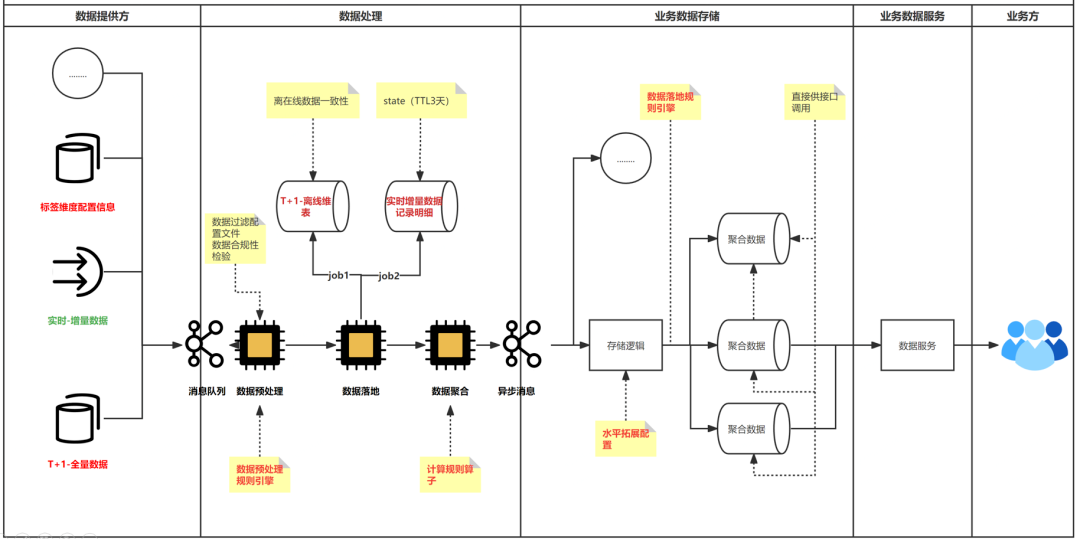
如下图,其中数据提供方:提供标准化的T+1和实时数据接入;数据处理:T+1与实时数据融合;一致性校验;动态规则引擎处理等;数据存储:支持聚合数据水平扩展;标签映射等。
②方案2 - 支持SQL
背景
虽然说方案1有如下优势:
分层简单,时效性强
规则配置响应迅速,可承接大量的复杂UDF
规则引擎等处理
兼容整个java生态
但是也存在明显劣势:
BI SQL开发人员基本无法介入、强依赖开发
SQL很多场景,使用java开发成本高,稳定性差
没有有效的数据分层
过程数据基本不可用,如果要保存过程数据,需要重复计算,浪费计算资源
解决方案
如下图,kafka承载数据分层功能,Flink SQL的计算引擎,OLAP承载数据存储、分层查询,完成典型的数仓系统分层建设。
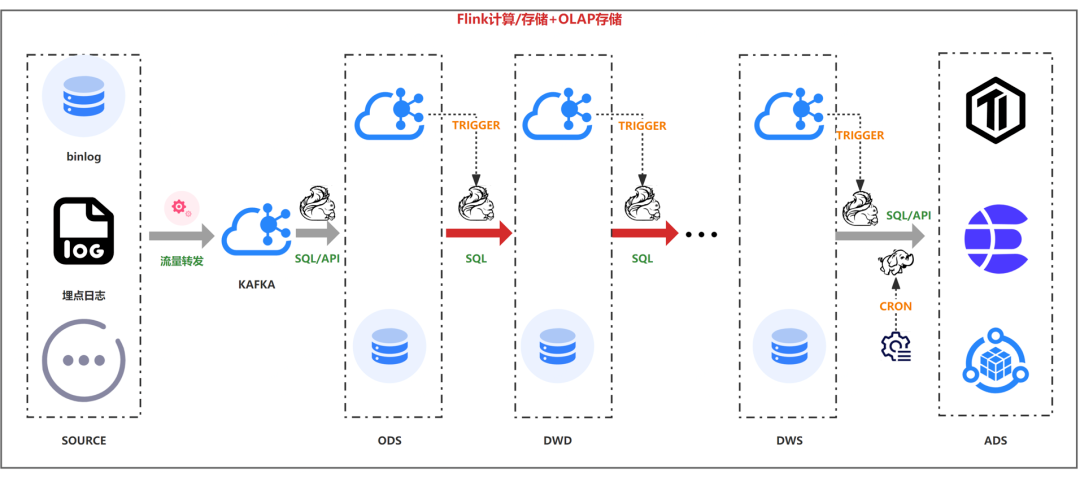
但是由于kafka和olap存储引擎是两个个体,可能会存在数据不一致的情况,比如kafka正常,数据库异常,会导致中间分层的数据异常,但是最终结果正常。为了解决上述问题,如下图,采用了传统数据库使用的binlog模式开发,kafka数据强依赖DB的数据变更,这样最终结果强依赖中间分层结果,还是不能避免组件big导致的数据不一致问题,但大部分场景已经基本可用。
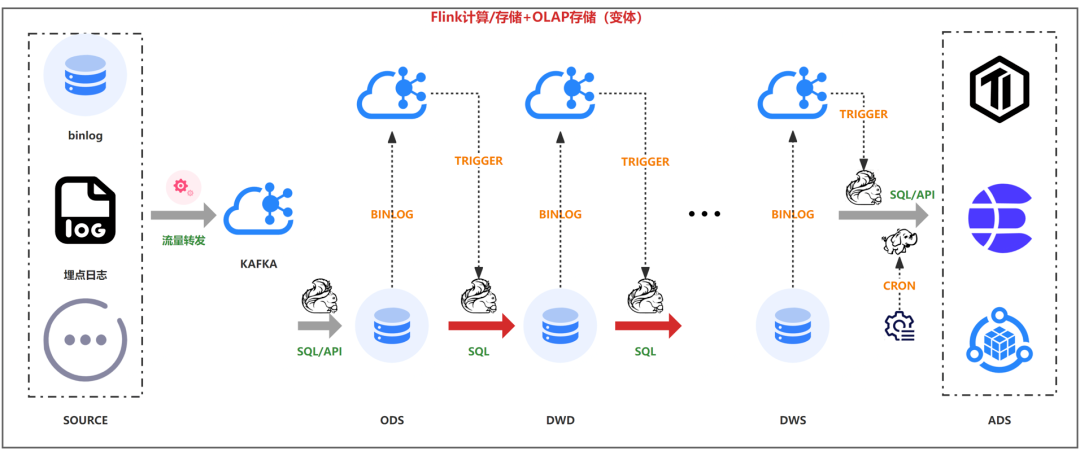
③方案3
背景
虽然说方案2有如下优势:
SQL化
天然分层查询
但是也存在明显劣势:
数据不一致的问题
binlog在insert的时候没啥问题,但是更新和删除不好搞,而且更新的时候要做大量的去重操作,sql很不友好
长时间数据聚合,部分算子如max、min等flink状态大,容易不稳定
还要考虑kafka数据乱序,导致的数据覆盖问题
解决方案
如下图借用存储引擎的计算能力,kafka的binlog只是作为数据计算的触发逻辑,直接使用Flink UDF进行直连DB查询。
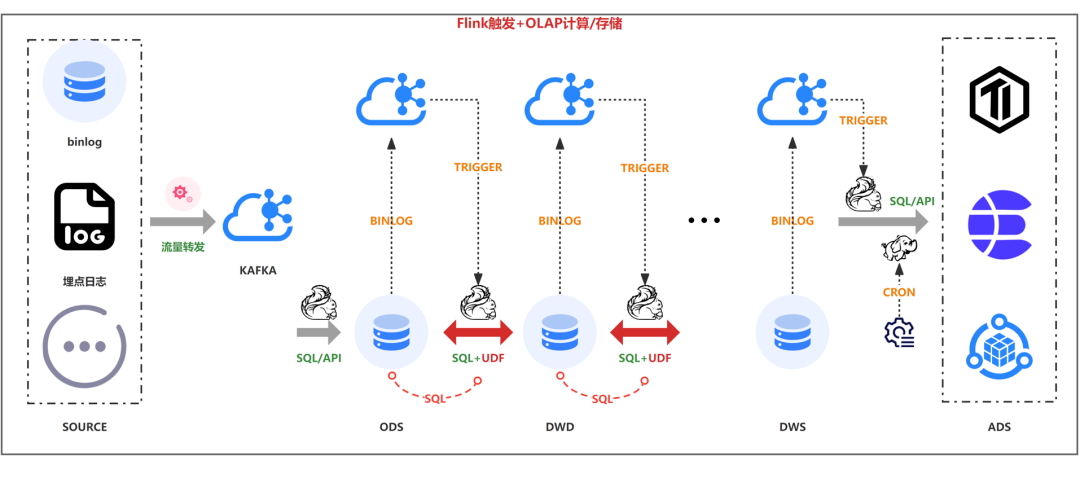
优势:
SQL化
天然分层查询
数据一致
FLink状态小
可支持长时间的持久化数据聚合
无需关心binlog乱序、update等带来的问题
劣势:
并发扛不起来,强依赖olap引擎性能,我们在数据源的时候会window限流,或者水平扩容db;
sink时与回撤流结合被打断,比如:group by,其实就是无脑的upsert,udf的聚合没法替代flink原生的聚合;
各个方案都有适用场景,需要根据不同的业务场景和延迟需求,进行方案选型。目前我们86%的场景都可以使用方案3进行承接,并且由于Flink 1.16各类离在线一体的特性加持,后期基本可覆盖全部场景。
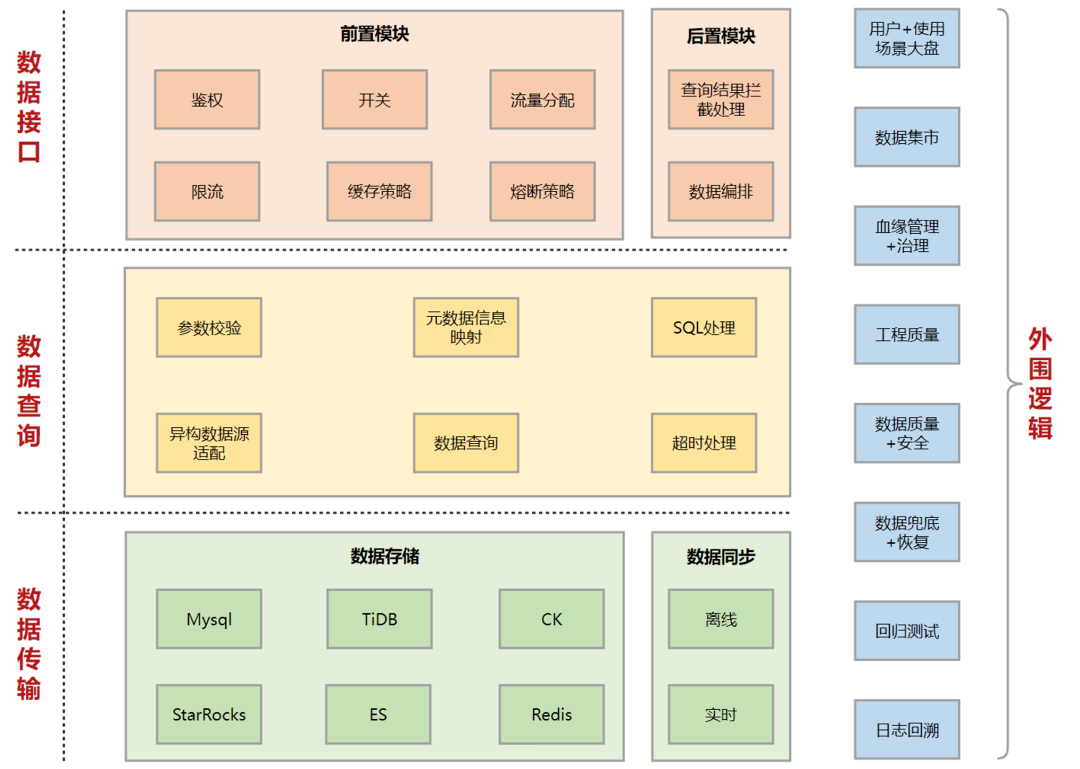
2.数据服务
该模块提供了数据同步→数据存储→数据查询→数据服务等能力,简单场景可实现分钟级的数据服务部署能力,可节约90%的开发工时。实现了离线数据DQC强依赖、工程侧DQC异常兜底、客户端->接口级别的资源隔离/限流/熔断、全链路血缘(客户端→服务端→表→hive表→hive血缘)管理等,提供了按需进行各类性能要求接口部署和运维保障能力。
架构如下:
3.数据质量
该模块主要分为数据内容质量和数据任务质量。
1)数据内容
①正确性/及时性/稳定性
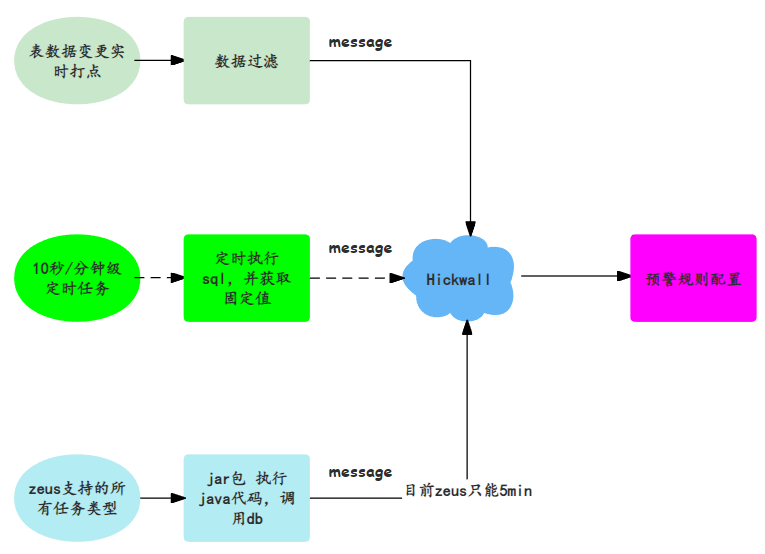
该部分又分为数据操作变化、数据内容一致性、数据读取一致性、数据正确性/及时性等。如下图所示,数据变更:如果异常,可将数据打入公司的hickwall告警中台,并根据预警规则告警。数据内容:会有定时任务,执行用户自定义的sql语句,将数据写入告警中台,可实现秒级和分钟级预警。
②读取一致性
如下图,数据读取时,如果存在跨表的联合查询,如果其中某张表出现问题,大多数情况下不会展示错误数据,只会展示历史上的正确数据,待该表恢复后才会全部展示。
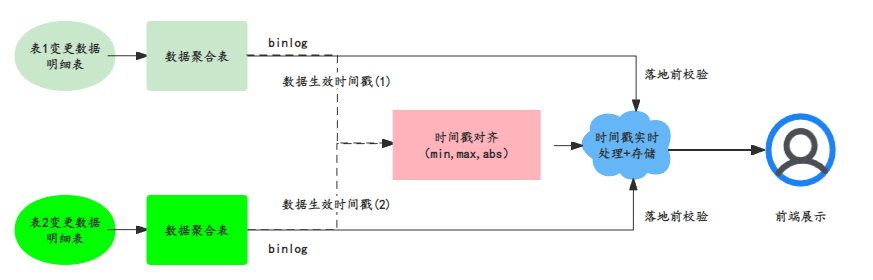
如:外露需要将表1和表2的数据做除法(表1/表2),如果表2数据生产异常,最近2小时没数据,在外露给用户时,业务需要只是展示2小时之前的数据,异常数据给出前端异常提醒 参照flink watermark的概念,将正确数据对其进行外显。
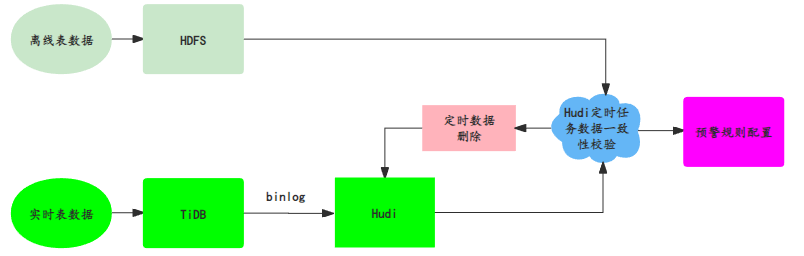
③离在线一致性
关于离线和实时的数据一致性。如下图,我们采用较为简单的方法,直接将实时数据同步至hudi,并且使用hudi进行离线和实时数据对比,打入告警中台。
2)数据任务
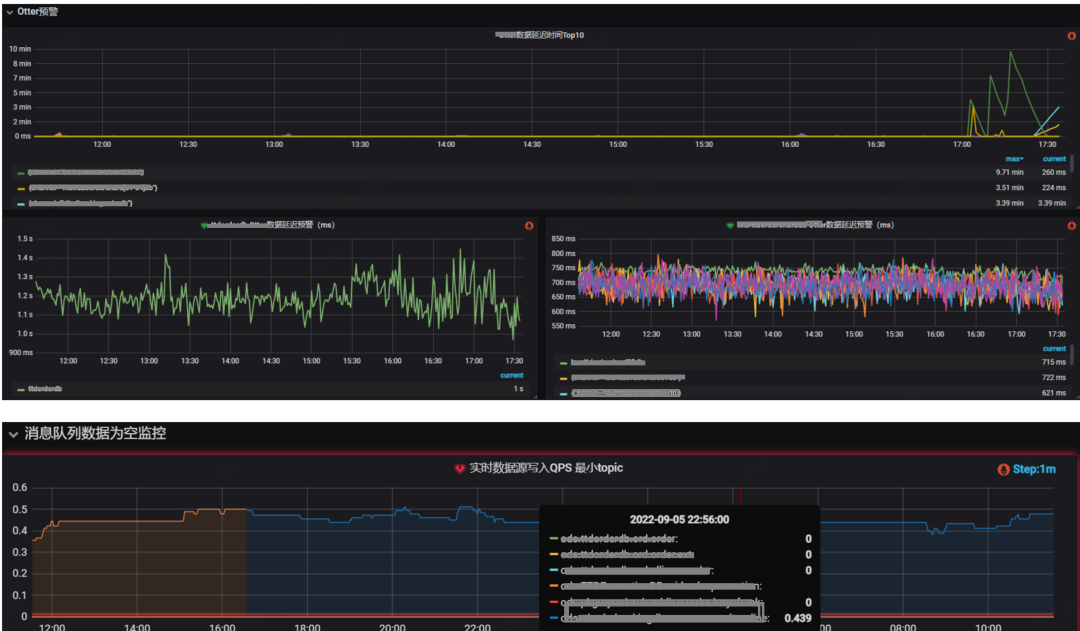
①上游任务
依托公司自定义预警埋点、告警中台、计算平台等工具,可将上游的消息队列是否延迟、量是否异常等关键指标进行监控预警。
②当前任务
可将数据处理任务的吞吐、延迟、反压、资源等关键指标进行监控预警,避免数据任务长时间异常。
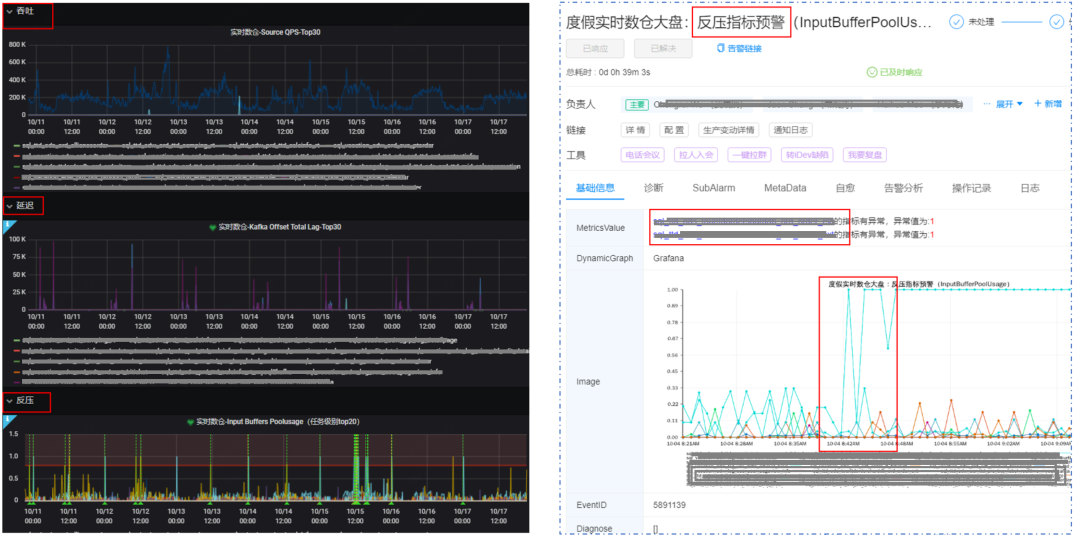
4.数据管理
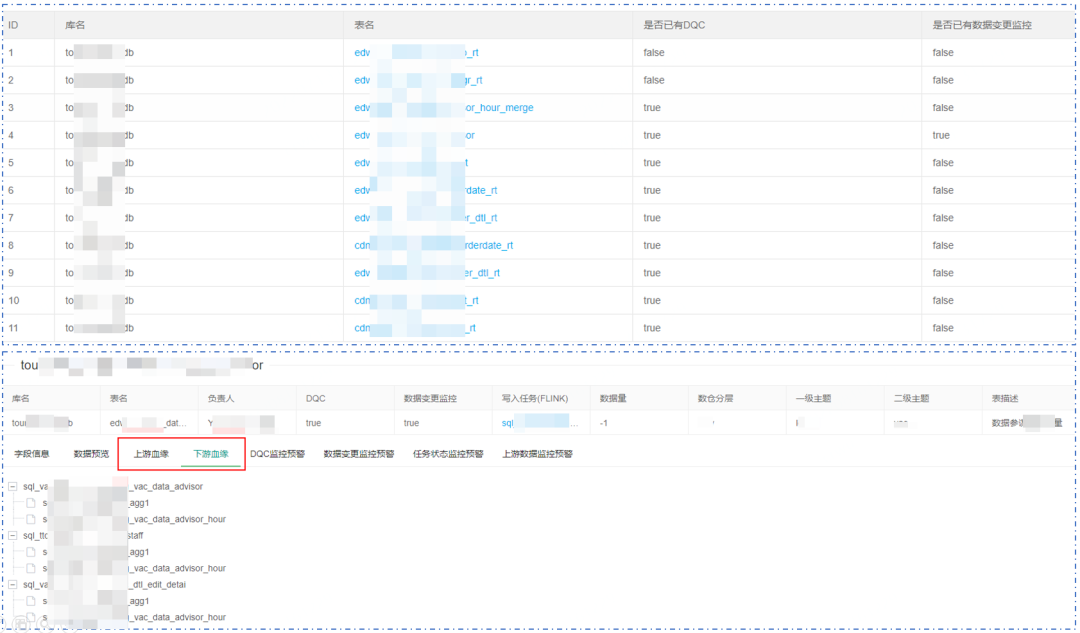
该模块可将数据处理、质量等各模块进行串联,提供可视化的管理平台,如:表血缘/基本信息、DQC配置、任务状态、监控等。
下图为各数据表上下游数据生产任务血缘关系。
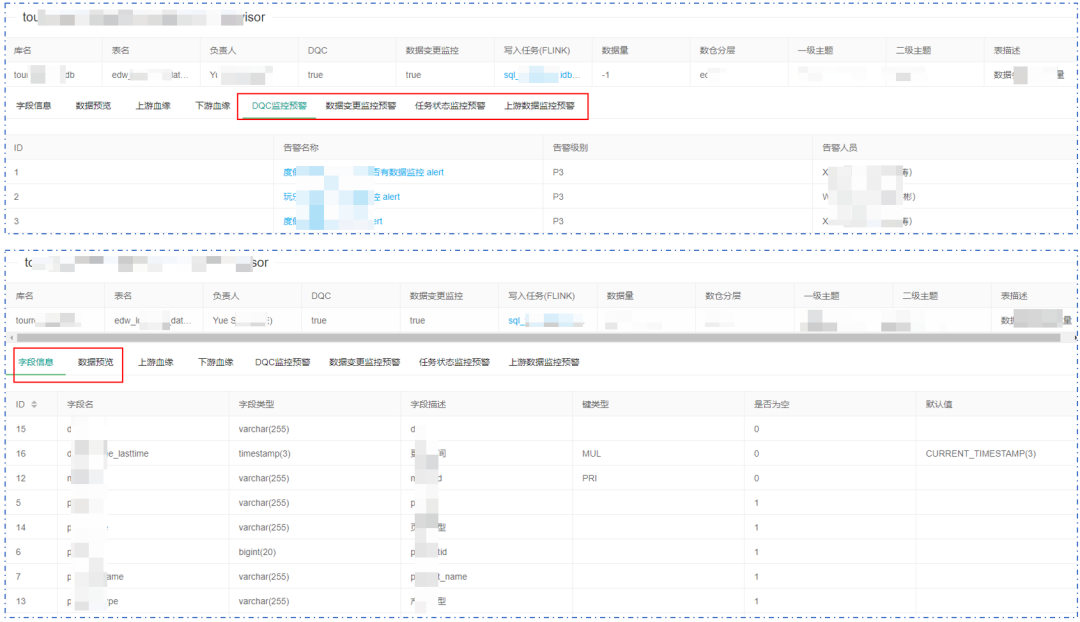
下图为数据表质量信息详情。
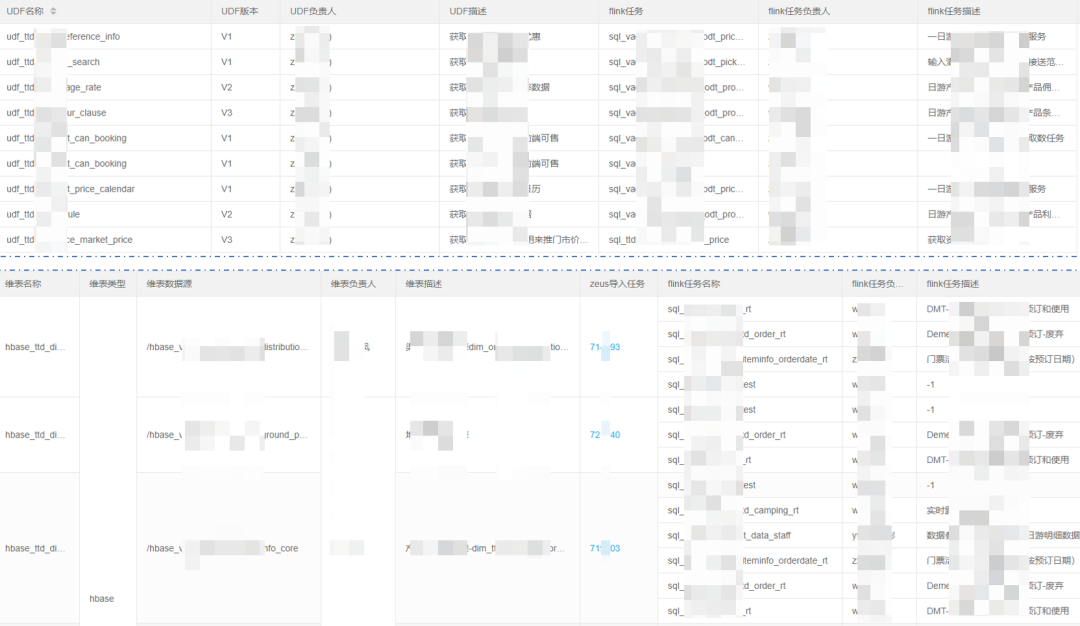
下图为各类UDF表的基本信息汇总。
五、展望
目前该系统基本上已经能承接团队绝大多数数据开发需求,后期我们会在可靠性、稳定性、易用性等层面继续探索,如完善整个数据治理体系、建设自动数据恢复工具、排障运维智能组件、服务分析一体化探索等。

