为什么需要可观测性?可观测性技术对业务团队的价值有哪些?如何建设一个可观测性技术体系?本文将从整体架构到核心设计一一为大家讲解。
前言
为什么需要可观测性
一年前写过一篇介绍弹性计算管控监控告警体系的文章《弹性计算管控监控预警体系建设之路》 介绍的是弹性计算管控监控告警体系的发展和设计思路。监控告警本质只是故障发现的手段之一,当前主要聚焦在稳定性的故障/问题发现领域(当然告警是一种业界共识的故障发现媒介,一定程度会传递故障定位信息)。可观测性是贯穿整个软件生命周期的,从稳定性视角看,可观测性覆盖了从故障预防->故障发现->故障定位->故障恢复->故障改进验收的完整周期。
当前业务研发同学普遍对可观测性体系的认识比较局限,或停留在监控告警层面,或者局限于部分观测技术,而从软件工程视角全面理解可观测性的价值,有助于帮助研发在研发质量、稳定性保障、成本控制等领域建立全面的意识,以及利用可观测技术帮助其更全面发现问题、定义问题。
业务视角看可观测性问题
ECS 管控近两年开始体系化做可观测性相关的事情,区别于云监控、SLS、ARMS 等可观测性能力平台,ECS 管控可观测性的定位是基于通用的可观测性平台与技术,构建符合 ECS 管控业务的可观测性体系与平台工具,解决 ECS 业务在可观测性领域遇到的问题。
首先,从组织、业务、技术等几个视角来定义 ECS 管控在客观性上遇到的问题:
集成复杂性,当前能力非标,数据割裂,难以输出标准化的API用于业务集成
业务体感差,可观测性大盘,预警整体体感对研发不够友好,仍然是运维思维
基建能力弱,研发构建业务自定义的能力没有完整的方法或者平台支持
问题定位难,metric和trace能力不足,故障定位大部分场景依托于专家经验
对业务团队应用价值
应用视角,全软件生命周期(SDLC)观测,包括研发、测试、交付、运维等
稳定性视角,多场景观测能力、监控发现、告警通知、根因定位
容量视角,建设产品与组织视角的容量观测能力
定义现状,构建产品视角的容量观测能力
评估未来,为后续资源降本提供决策支持
可观测性体系目标
构建一套全面而精细的可观测性体系,其核心目标在于实现 标准化、可集成、可扩展以及卓越的用户体验,从而有效地解决SRE(Site Reliability Engineering)与业务研发团队在故障发现、定位过程中面临的普适性挑战。
建立标准化机制与 SOP,通过遵循行业标准协议和优秀实践,确保数据模型、指标定义、日志格式等关键组件的一致性和互操作性。这将简化跨团队协作,降低技术壁垒,并提高整体运维效率,使得从不同维度获取的系统状态信息得以精准映射并整合到一个通用视图中,为故障快速响应奠定基础。
提供可集成性能力,支持与开源、阿里云产品工具、服务无缝对接,如日志收集平台、APM(Application Performance Management)、 tracing工具等。这样,在满足多样化需求的同时,也能保证所有相关数据源能够高效地融入观测平台,形成完整的端到端可观测链条,助力团队在面对复杂故障场景时迅速定位根源。
预留可扩展性,随着业务和技术的快速发展,可观测框架需要灵活适应不断增长的数据规模和新型应用场景。设计之初就要充分考虑模块化和水平扩展能力,以确保在系统扩容、新功能接入的情况下,仍能保持稳定高效的性能表现,满足未来可能出现的各种运维需求。
提供卓越的用户体验,直观易用的界面设计,实时准确的数据反馈,以及智能化的问题诊断辅助,都将大幅提升SRE和研发团队的工作效能。例如,通过对海量数据进行智能分析,结合 AIOps/LLMOps 技术提前预测潜在风险,甚至能够在故障发生之前即采取预防措施,显著降低系统的MTTR(Mean Time To Repair)。
简而言之,我们的目标是建立这样一套标准化、可集成、可扩展且体验佳的可观测性体系,不仅能有力解决SRE与业务研发团队在故障发现与定位领域的共性难题,还能够凭借强大的通用集成能力,应对不同团队、不同业务下的差异化需求,从而全面提升组织的IT运维管理水平和系统稳定性保障能力。
可观测性技术体系建设
整体架构
好的架构不止于解决单点问题,而是解决一系列问题,下图是 ECS 稳定性平台整体架构,可观测性的核心价值不止于解决观测能力本身,更重要的价值在于通过数据(包括技术与业务)与工具链打通,实现平台工具整合。
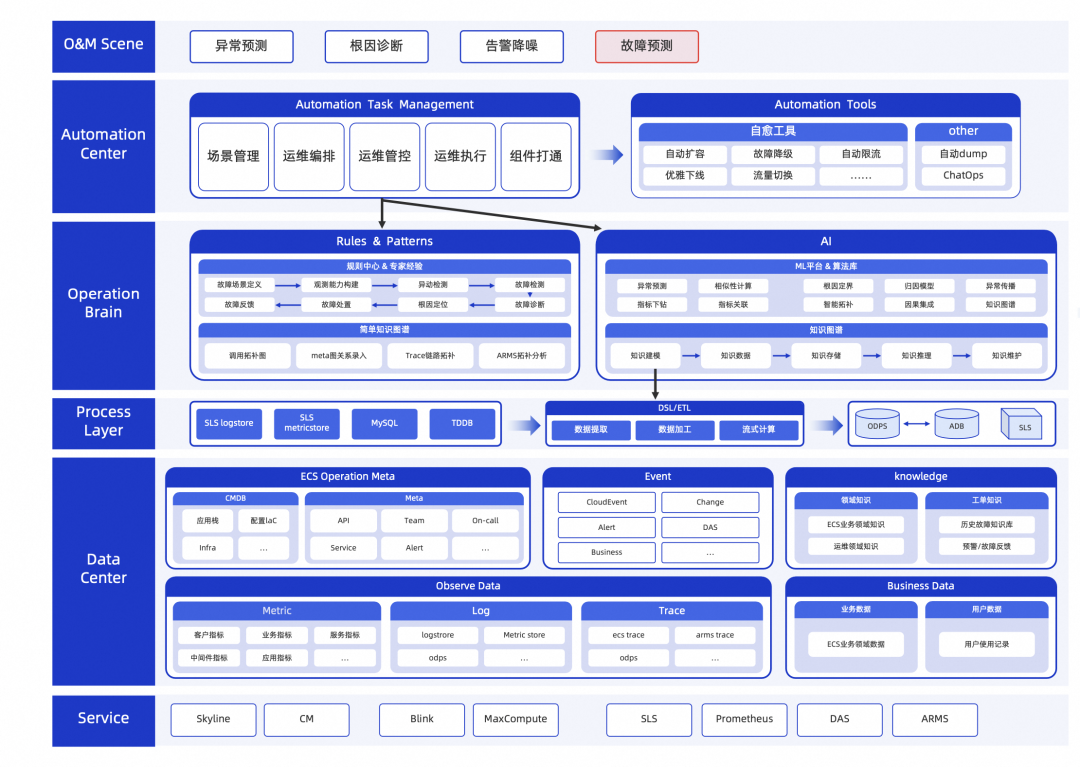
Service,依赖服务层,当前 ECS 管控可观测性构建于阿里云公共云云产品以及部分内部服务之上,核心原则:Cloud First。
Data Center,数据中心,数据质量与覆盖度是决定上层业务是否可以标准化运维与实现智能化运维的关键,当前观测数据层主要包括 log、metric、trace、event、cmdb 以及业务数据与运维知识等。
Process Layer,通过 ETL 等工具对数据进行加工并统一存储,包括时序数据库、关系数据库、知识图谱、数仓等多种形态,核心在于统一建模、标准化与业务适配。
Operation Brain,运维大脑,专家经验与 AIOps/LLMOPs 的能力组合,核心解决业务运维领域最复杂“思考”能力落地问题,比如故障领域经典的根因定位、容量预测等。
Automation Center,运维编排与工具管理,直接支撑典型的业务运维场景,比如告警事件通知、变更事件广播、自动化扩容、限流自愈、自动化 profile 等,核心在于解决标准化、与业务覆盖问题。
核心设计

Cloud Frist,吃狗粮,优先考虑基于云产品(尤其是公共云)的开放集成能力构建可观测性,比如 ECS 管控可观测性核心依赖了 SLS、ARMS、云监控、DAS 等多个云产品的 OpenAPI 与 InnerAPI。
SDLC,建立覆盖软件开发生命周期的观测能力,观测不仅仅用来在运维阶段发现故障,同样可以用于业务规划、容量规划、研发质量、交付效能、成本优化等领域。
Platform,平台产品思维,我们不做解决单点局部问题的方案,要做可以解决一系列问题的平台解决方案,同时要尽可能推动实现 研发自助->自动化->智能化 的演进。
Cloud Frist:生于云,长于云
来自 Netflix 的启示,众所周知,netflix 是成长于 AWS 巨型互联网公司,其技术架构几乎全部依托于AWS 提供的云产品(好比米哈游于阿里云)。Netflix 仅仅依靠少量的 CORE SRE 支撑了全球最大的流媒体服务供应,没有 AWS 这一切不可能实现。
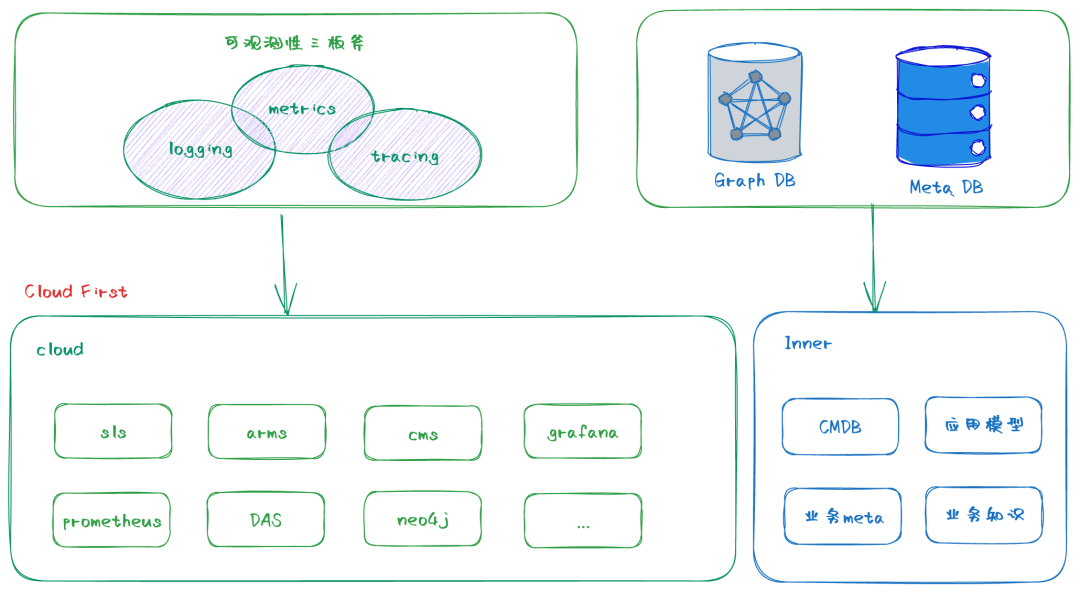
在ECS管控可观测性能力建设的漫长演进历程中,从内部monitor、sunfire,再到sls与prometheus生态结合并融入自主研发阶段,目前ECS管控观测已实现全链路“上云”,这一过程蕴含了几个关键性的洞察与思考,与大家分享一下:
观测数据构筑之重犹如基石(再次强调),组织视角下需洞见“恒定”与“变化”。在业务图谱中,业务核心数据可视作不变的“常量”,而观测技术则是持续迭代的“变量”。无论是昔日的Nagios、ELK,还是现今流行的prometheus生态系统,未来无疑会出现更为卓越的解决方案。然而,相对而言,业务的数据与核心关注点相对稳定, 比如在 ECS 团队,我们对保障 ECS及相关配件资源的有效交付与稳定运行(涵盖成功率、效率、规模承载力等关键指标)不会改变。
深度挖掘并充分利用云端产品潜能,旨在减少运维边际成本,达成高效运作。不论是SLS、ARMS,抑或是云监控服务中托管的prometheus、grafana等云原生工具集,它们所提供的强大功能足以支撑日常业务场景所需。独立运维乃至自主研发此类工具,其收益往往并不显著,尤其是在业务规模逐步扩大的背景下,独立运维的成本和风险将会呈现出上升趋势。
践行面向失效的设计哲学,以用户为中心,深知在不确定的世界中,“所有云产品皆有潜在不可靠性”。不妨提出一个挑战性的问题:倘若依赖的XXX云产品突发故障,我们将如何应对?近期AK故障引发的大量云产品异常事件,大量依赖云产品构建的观测能力在该场景也全部异常,这为我们提供了一个亟待深思的实例。当前我们团队正积极内省,并与云内监控团队密切沟通,共同探讨如何在云产品可能出现故障的情境下,仍能确保核心的观测能力和监控告警机制的有效性和可靠性,实现对未知风险的有效抵御。
Data Center:构筑运维基石

围绕可观测性三板斧(log+metric+trace),结合 event 与 meta 构建运维数据底座,建立应用视角的运维数据模型,其中可观测性数据作为其中的关键子项,所有上层的可观测性、自动运维工具都依赖同一份底层运维数据。
Log,ECS 管控所有服务以及业务日志,国内与海外双中心部署,统一存储在 SLS logstore。
Metric,ECS 管控度量指标数据, Prometheus 数据协议,存储在 SLS metric store,国内海外双中心存储。
Trace,基于 ARMS 与 SLS logstore 自研可编排、可扩展的全链路日志追踪服务。
Meta,基于 ECS 业务以及管控应用、架构、组织等信息建设统一的业务 meta 数据,基于 meta 数据与 Trace 构建知识图谱服务。
Event,事件中心覆盖了包括资源主动运维、变更、告警、数据库、异常检测、压测演练等多维的异动数据。
Business Data 与 knowledge 目前思路是提供标准化 meta 外的补充,可以作为大模型的语料输入。
Log:统一日志管理
ECS 管控所有日志统一采集存储在 SLS,当前系统有多个账号,每个账号下有多个project,其中部分 project是国内+海外双中心存储。双中心数据隔离会直接导致基于日志所做的 metric、 告警、大盘等需要维护至少两份,在大规模业务场景下,运维成本和风险都比较高。为了简化日志的使用与运维成本,我们基于 SLS 的开放 API 研发了日志管理能力。
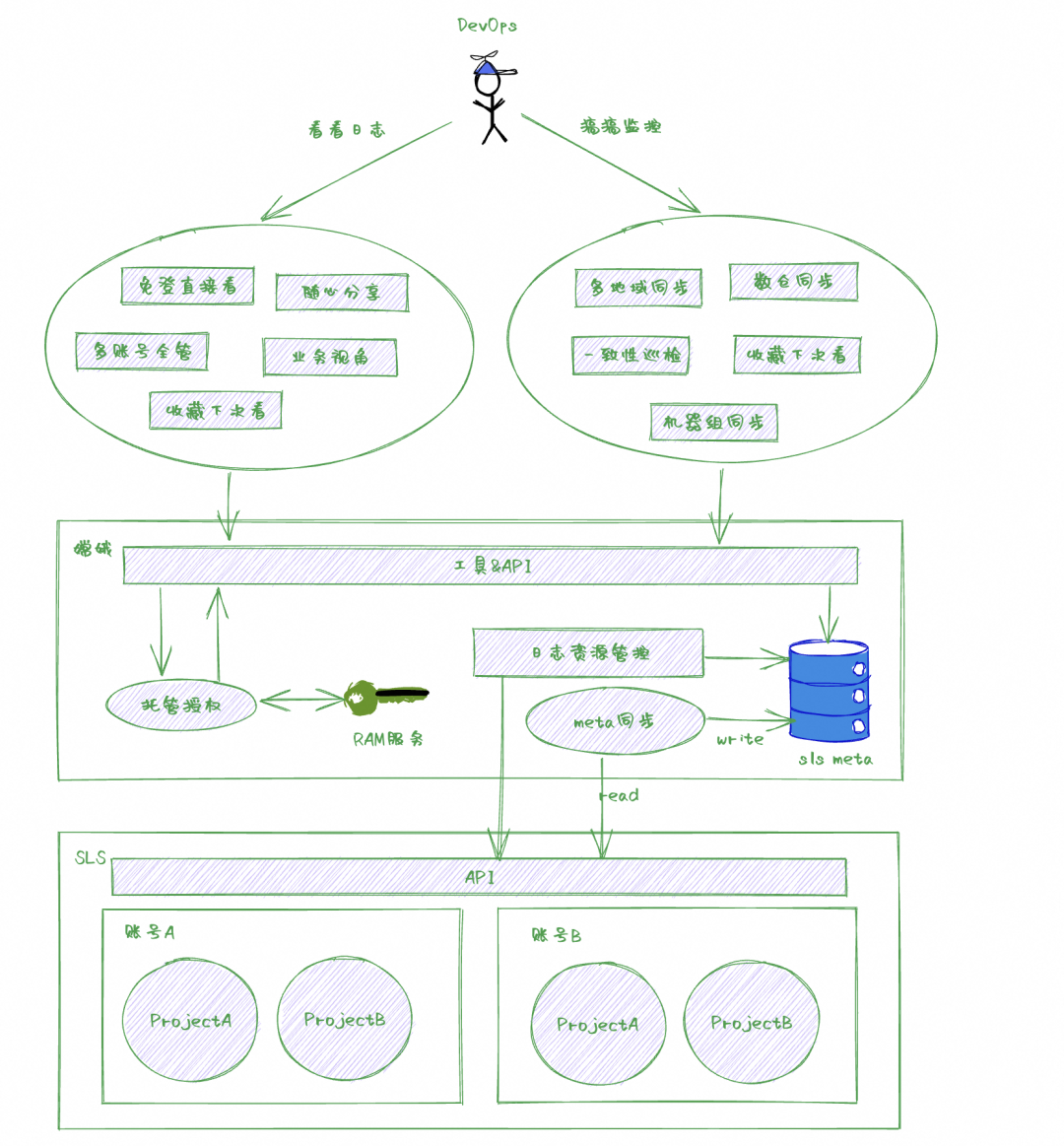
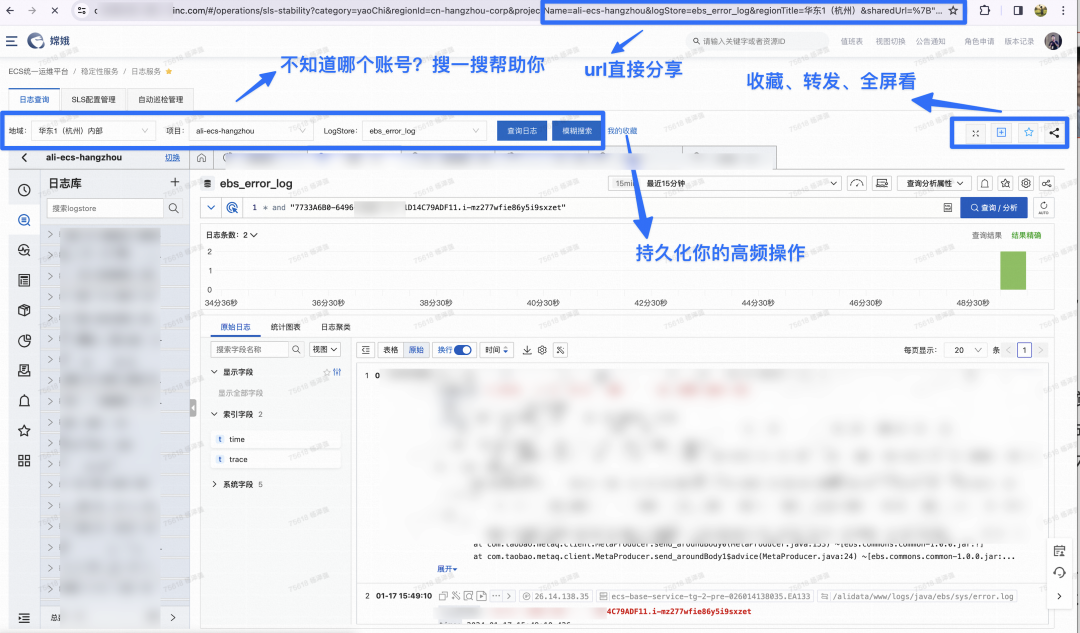
日志查询托管,解决研发最高频的多账号日志查询需求,通过RAM 角色扮演方式在嫦娥运维平台内嵌 SLS 控制台,解决单浏览器多阿里云账号日志查询需求,同时支持 全局 logstore 搜索、收藏与分享功能,可以将 SLS 查询条件持久化,实现快速访问以及分享给他人,以上所述所有操作用户都无需感知阿里云账号。
日志资源管控,通过持久化 SLS meta 以及 SLS 的 OpenAPI 结合业务形态实现 SLS 机器组分发、Dashboard 跨地域同步、数据投递数仓等高阶运维能力,简化研发运维操作与成本。
Metric:统一指标体系
metric数据是可观测性的底座,metric统一、标准化是可观测性高阶能力比如预警、诊断、根因定位等的基础。ECS 管控在 metric 体系上的建设也围绕 标准规范与技术建设两部分。
技术建设
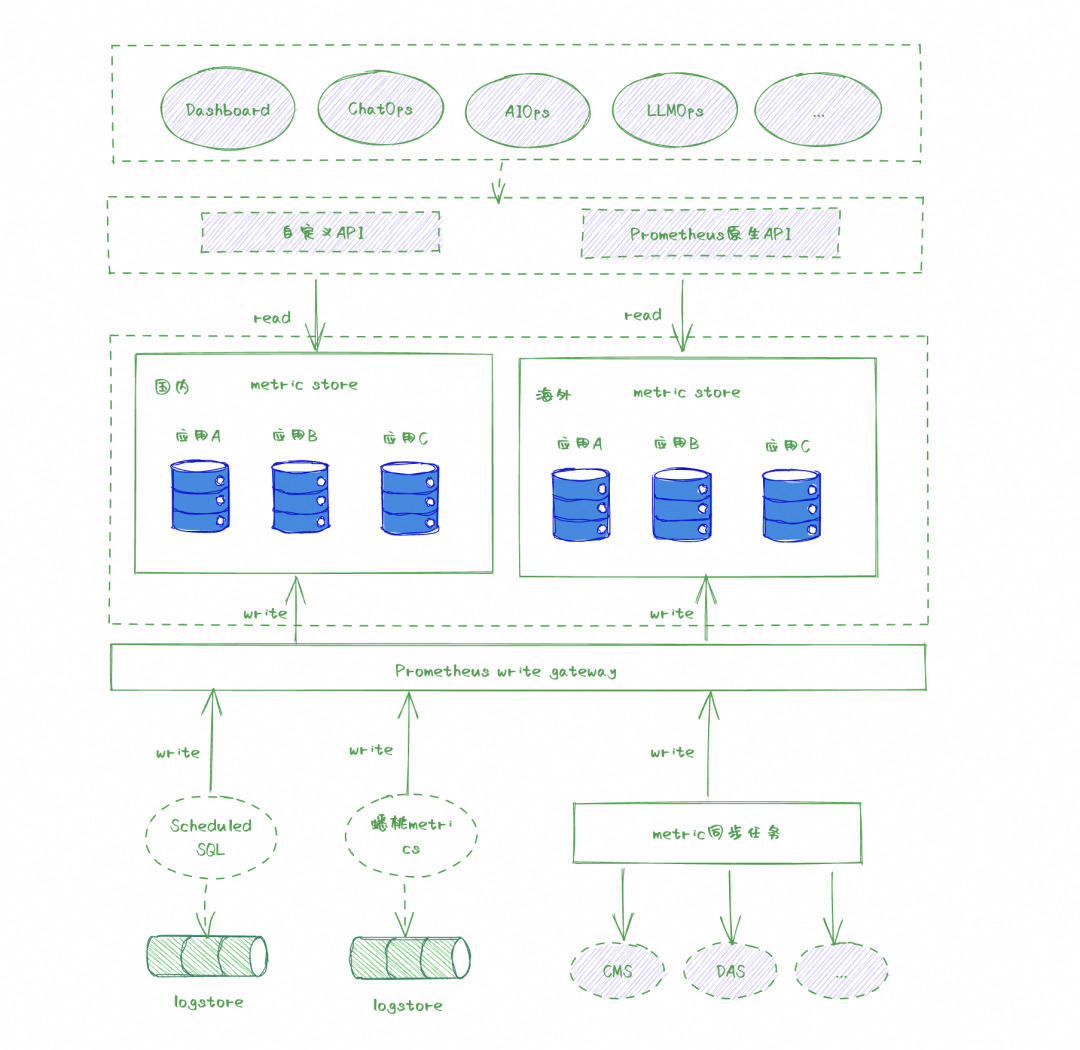
异构多数据源支持,统一 Prometheus 数据协议写入,支持 logstore 转 metric store、ECS自研metrics框架写入、以及同步第三方 metric 数据等多种异构数据源接入,通过统一的 prometheus 数据协议标准,数据源与数据存储皆具备扩展性。
自定义 HTTP API 用于业务被集成,通过自定义 HTTP API 方式统一封装业务模型,提供适配 ECS 业务的使用方式,天然支持 region、应用等模型参数。同时,通过 prometheus 原生协议提供 的查询能力,这部分能力通过 SLS metric store 提供。
业务 labels 注入非常关键,如果说 ECS 管控 metrics 最核心的两个价值,其一是数据标准化,第二就是我们通过结合业务 Meta,针对每个 metric 都加入了业务视角的 labels,这个对于上层运维能力构建至关重要。
标准规范
数据存储规范
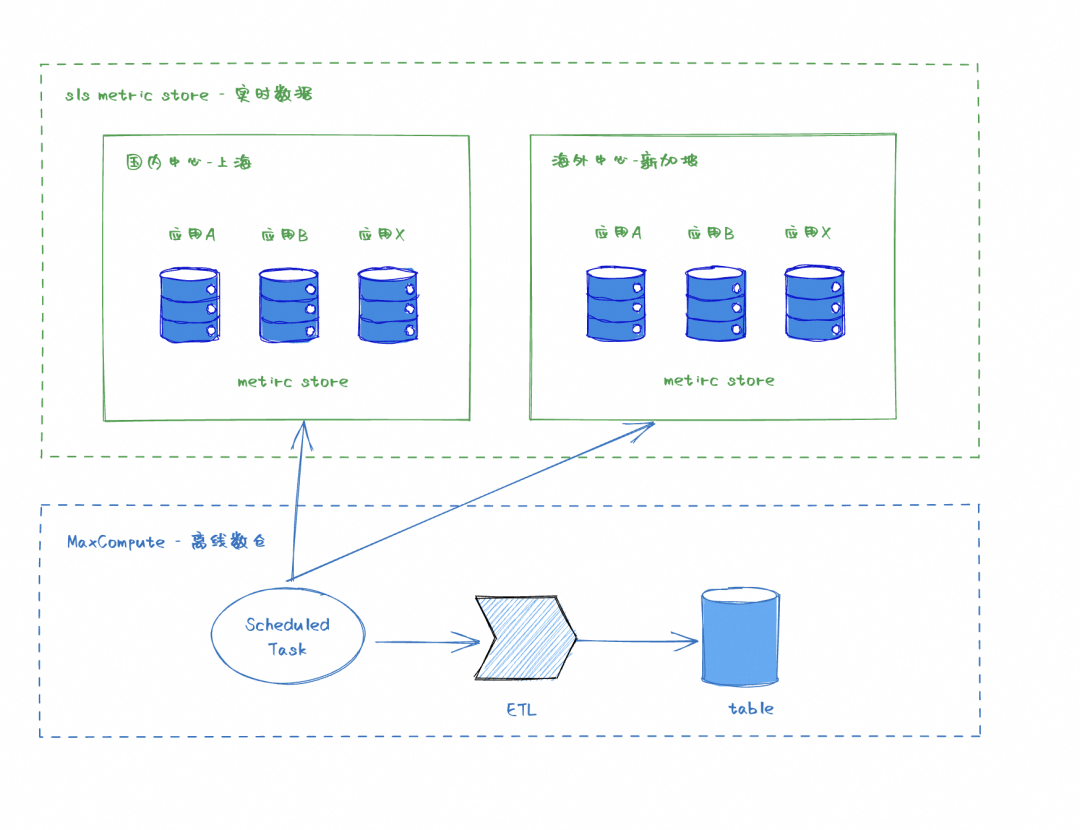
国内海外双中心存储,安全合规设计,ECS 管控 metric 数据不涉及用户面合规风险,权衡安全合规与运维成本考虑通过国内+海外双中心存储(当前通过数据同步链路汇总到上海,后续需要拆分)。
冷热数据分离,SLS 存储实时 metric 数据,最长保存一年,通过定时同步链路将数据回流到 MaxCompute,并经过 ETL 加工为业务需要的数据提供给 AIOps 与大模型使用。
指标分级规范
指标体系在实际建设过程中会有两个阶段,第一阶段,指标覆盖不全,体现在观测维度不够丰富、告警覆盖不全;为了解决第一阶段问题,业务侧通常会从多个维度层次进行指标补齐,进而指标的数量会膨胀,系统会遇到第二个问题,指标太多了,我们该怎么用?实际经验来看,系统需要重点关注的指标占总指标的比例不应该超过 30%,过多的重点指标意味着业务/问题题的定义不够清晰。所以在 ECS 管控我们定义了重点指标(核心指标、关键指标)占比控制在 30%以内。你可能会问,哪些指标可以定义为重点指标呢?我们的实践建议是从客户/业务视角出发,可以表征客户业务受损的指标。

指标分层规范
在 ECS 管控我们定义可观测性指标五层模型,其中 越底层指标越要求多而广,越顶层指标越贴近用户,要求少而精。

metric格式规范
完全遵循 prometheus metric format,time-series 存储,sample如下:
指标(metric):metric name和描述当前样本特征的labelsets;
时间戳(timestamp):一个精确到毫秒的时间戳,当前指标默认一分钟生成一次;
样本值(value):一个float64的浮点型数据表示当前样本的值。
metic命名规范
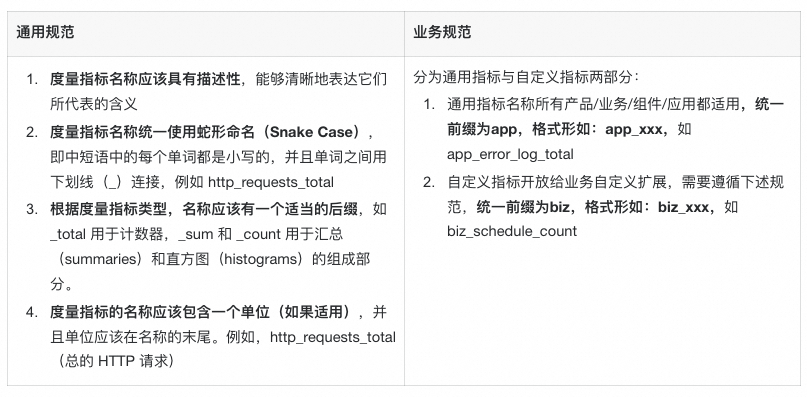
labels 使用规范
labels 可以方便业务聚合,比如统计应用 A 在地域 cn-hangzhou 下所有 check health 异常的机器总量,就可以通过 labels 快速过滤。为了简化业务使用成本,对 metric labels 进行统一使用规范,针对通用的 labels 进行命名统一。

Event:事件驱动运维架构
Azure的全局智能运维中心(支撑Azure所有product,在阿里云内部据我所知,我们没有这样的系统),核心的数据源是统一事件中心(全站事件数据),基于全局事件构建异常检测、预警与根因定位等能力。在ECS 当前业务规模与复杂性上,传统的被动运维或者基于告警的响应机制有明显弊端,比如类似单机异常等本质上不需要走告警应急,可以通过自动化方式自动 failover 掉,这类操作是不需要人工介入的,目前方式我们会推送告警并由 on-call 接收处理。
在过去一年,我们开始建设 ECS 管控的 Event Center,定位是:统一运维事件库,核心价值是基于事件重构运维自动化体系,即通过事件驱动运维。
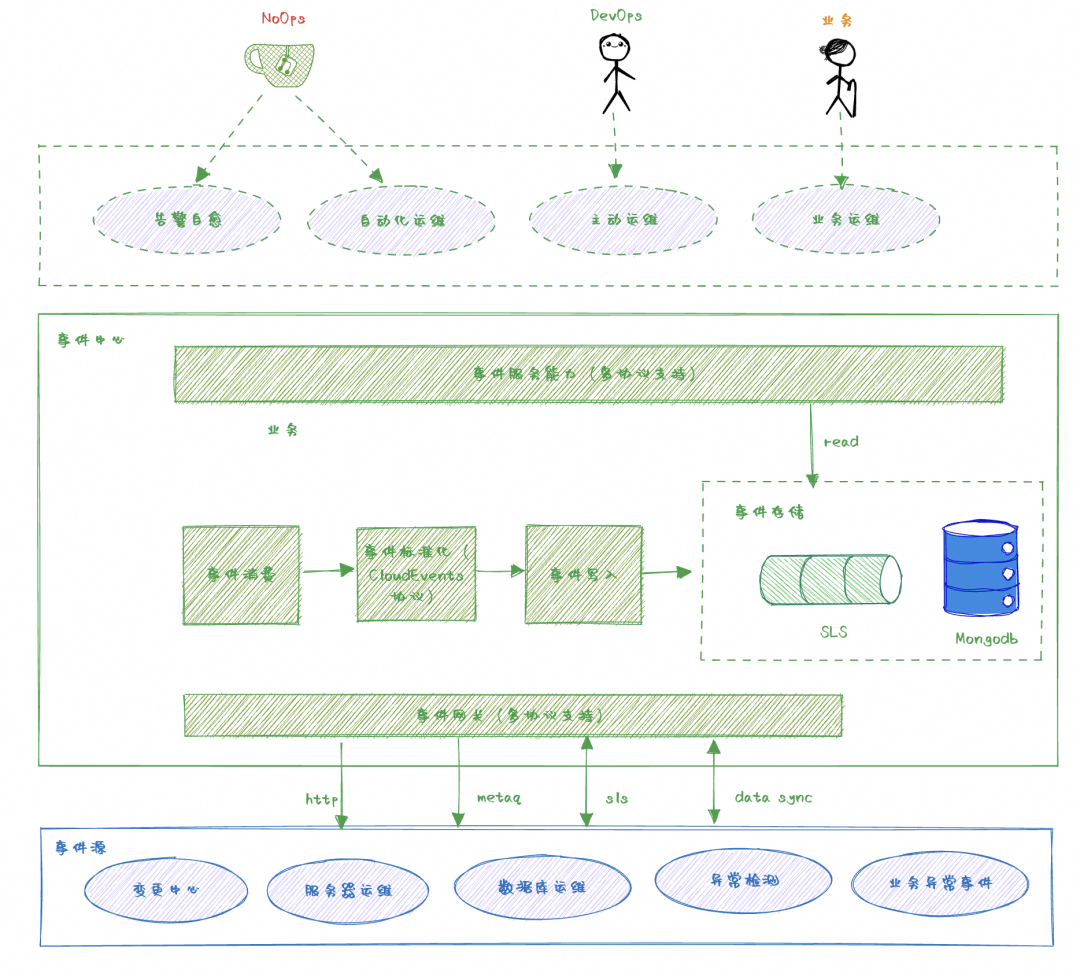
异构数据源扩展支持,Event Center 本身不生产数据,只是数据搬运工。这里我们设计了统一的事件网关,多协议支持汇总多数据源的事件信息,并提供统一的过滤加工能力,统一标准化为 CloudEvents 协议。
CloudEvents协议标准,统一标准化事件协议,集成视角,可以将多源数据进行统一整合存储;被集成视角,CloudEvents 协议作为开源标准,可以更好的被内部甚至是生态其它产品进行集成,比如阿里云的 EventBridge 等。
高可用存储方案,使用 SLS+mongodb 双写方式,保障单数据源异常情况,服务整体高可用。
事件驱动运维架构,可以简单理解成 event-driven architecture 在运维领域的应用,但这并不只是一种技术实现或者架构模式的改变,更是 DevOps 工作方式的改变。
Trace:全链路追踪能力
功能迁移自原飞天六部现GTS 云台(目前处于下线状态),核心用于帮助售后、技术支持、研发等角色基于日志关键字(常见的有Request ID、资源 ID 等)实现业务异常快速定位。
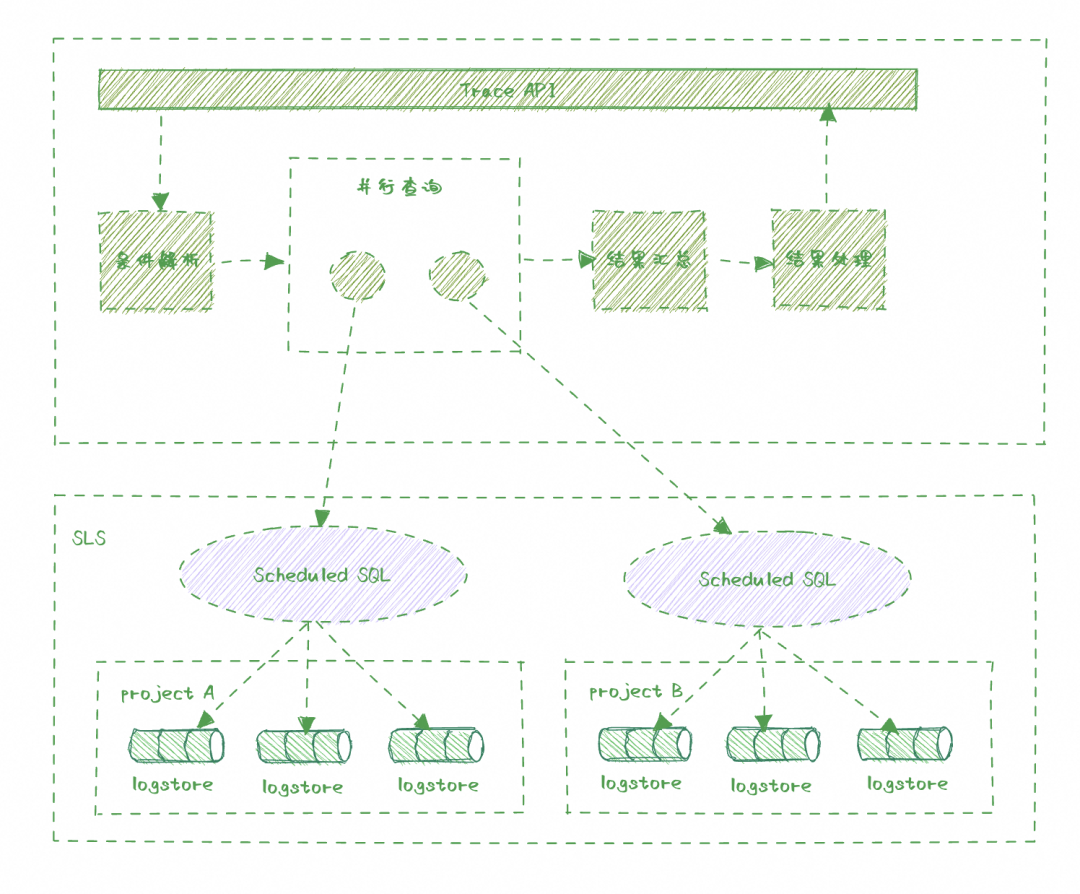
当前 Trace 系统仍然在演进中,Trace 系统在实现上有以下几个关键设计:
Trace 埋点打通,如何解决一个 Request ID 可以打通全链路包括业务、中间件、线程池、数据库全链路,整个过程极具挑战。对内,要解决上述如线程池、数据库串联问题,当前我们通过 ARMS、DAS、自研能力进行串联,目前串联了部分,仍然覆盖中;对外,如何打通依赖方,这个不是一个单纯的技术问题,这里不做讨论。
编排调度能力,在全链路 Trace 埋点都标准化输出到日志的情况下,编排能力和调度能力将会非常关键。前者解决业务自定义扩展能力,简单来说,除了支持 ECS 的业务,同样可以支持其它云产品接入;后者,在调用链路很长情况下,权衡查询的体验与准确性,这里需要在并行调度能力上不断提升。
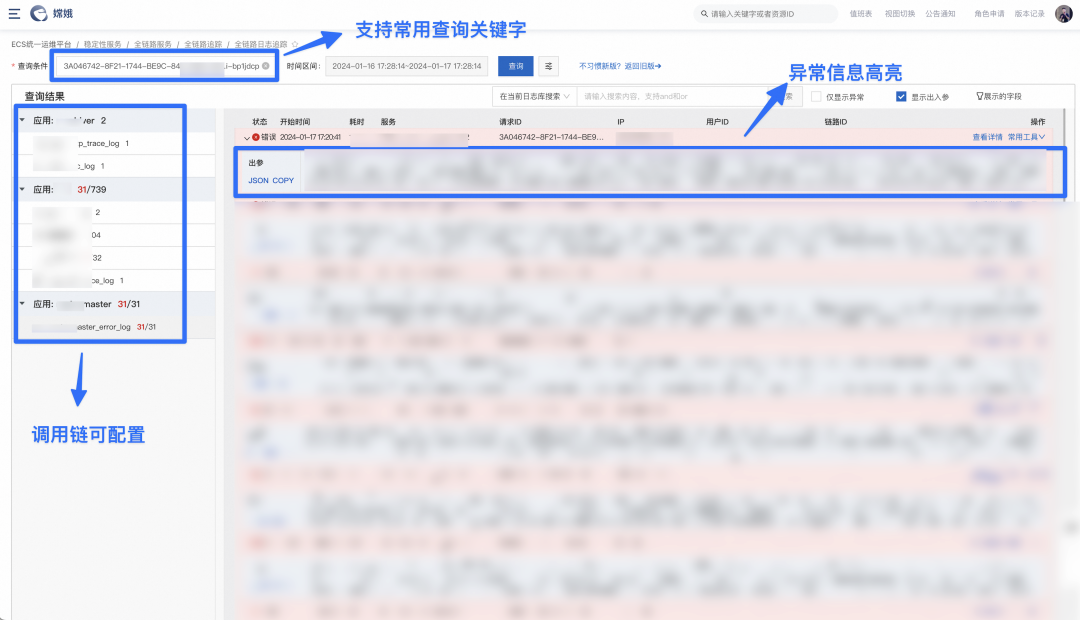
Dashboard:分层观测大盘建设
研发视角来看可观测性最直接的价值就是输出各种观测大盘,在集团内部从应用视角的基础监控大盘、 sunfire 自定义的业务大盘、大促各种盯盘,大家对此并不陌生。笔者认为大盘的数量以及对应支持平台都不是关键,观测大盘最大的价值在于推动研发建立全局视角、技术与业务全方位融合的实时度量看板,如果不知道观测什么,用什么观测都没有太大意义。
Dashboard 分层定义

观测大盘是为了快速准确辅助人工发现观测链路异常局点,所以核心是回到产品和业务本身,回到用户视角来定义。ECS 管控为例,业务特征是多地域单元化部署、业务形态复杂、依赖链路多。在观测大盘分层上,我们也从解决上述问题思考:
status 大盘,云产品维度的全地域健康状态,辅助人工发现当前异常地域。
核心指标大盘,覆盖地域维度核心指标,在定位到异常地域情况,辅助快速定位异常核心指标。
应用大盘,应用维度从核心指标、黄金指标、中间件、依赖服务等几个维度定义应用核心观测数据,用于在定位应用异常局点。
业务大盘,从业务视角出发,服务正常未必等同业务正常,核心在于从用户视角定义业务的健康状态,以及识别异常业务。
场景大盘,覆盖研发生命周期以及日常研发活动,比如 CI Dashboard、发布可观测性、重保(双十一大促)观测、容量大盘、以及垂直领域如数据、中间件整体的观测大盘。
技术建设
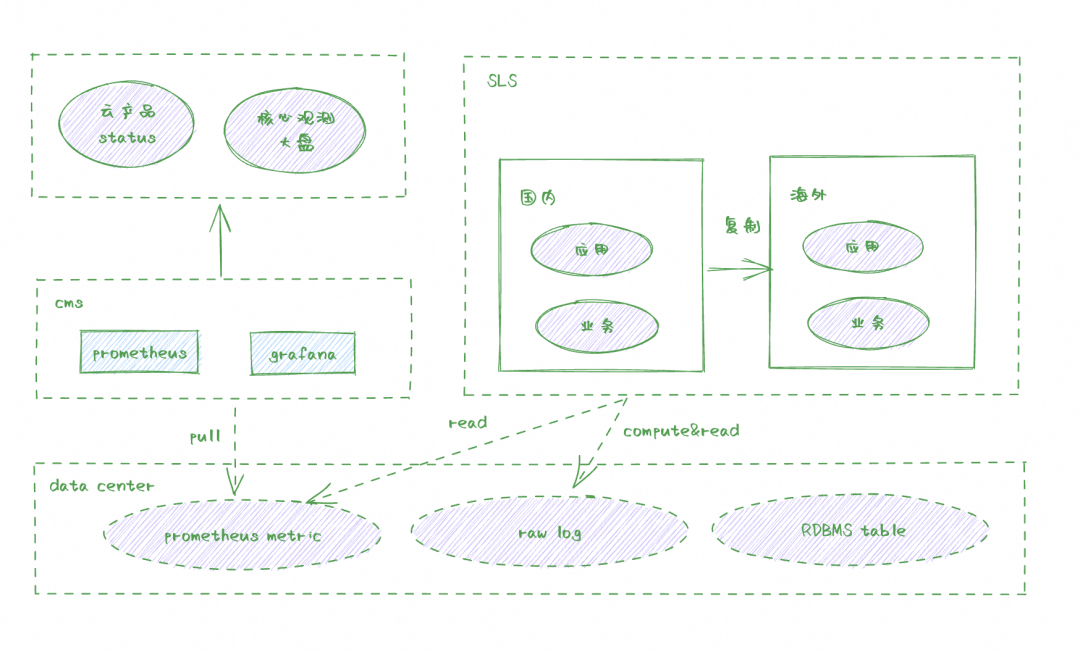
核心是 Data Center,当前包括 Log 与 Metrics,ECS 管控当前所有的 log 以及 metrics 都统一托管在 sls 的 logstore 与 metric store,同时基于 SLS 开放 API 实现了一定管控能力比如多地域同步。
充分利用云产品优势,回到最初架构设计 Cloud First 原则,ECS 管控在 Dashboard 建设上也充分利用了云产品优势。
通过 SLS 与云监控托管的 prometheus 与 grafana 能力,免去独立运维成本
通过 SLS 开放 API 实现了多地域 Dashboard 同步能力,简化多地域运维成本。
Alert: 智能告警平台
在监控预警体系建设中提过,由于历史上集团 monitor 下线、sunfire 对 OXS 支持不足等原因,以及 ECS 管控在多地域监控以及多团队监控统一管理等等方面的诉求, ECS 管控将监控体系逐步迁移至 SLS、云监控、ARMS 等平台。同时为了标准化告警管控处置流程与提供更贴合业务、更具扩展性的告警配置,我们进行了大量自研工作。
成熟度模型
首先,我们先尝试定义一下什么是好的告警,笔者从告警覆盖、管理、内容以及智能化程度几个方面出发,尝试定义了一份简单的告警成熟度模型。
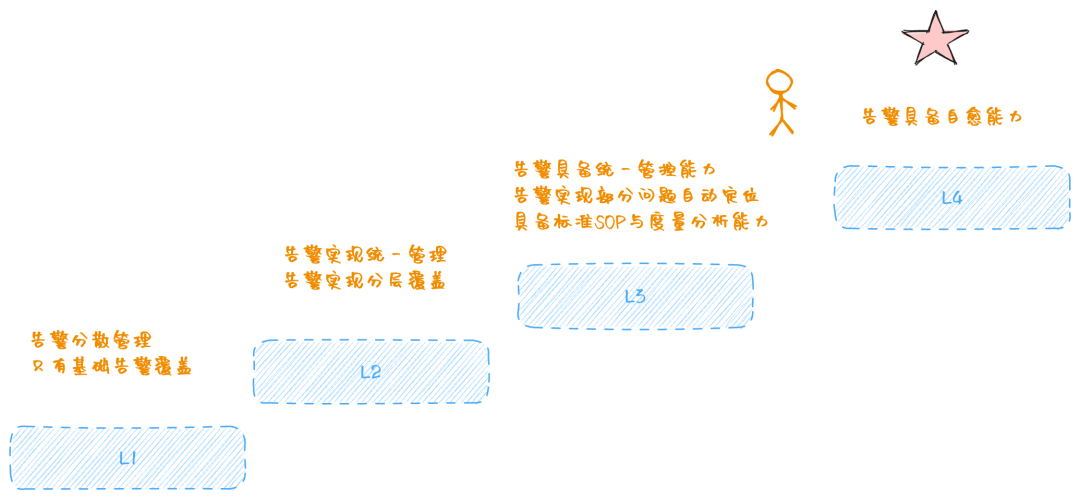
笔者认为告警成熟度最高的级别 L4 是告警自愈,而 实现告警自愈需要一套高度体系化、高度集成化的平台工具链支撑,包括业务运维领域的 CMDB、全覆盖且准确的监控告警、可靠运维任务编排调度能力、以及对应 ITIL系统的支持,这也就是ECS管控SRE在整体运维架构里我们坚持要定义管控的运维知识图谱以及前期大量标准化体系和流程建设的原因。笔者认为,决定智能(无论是 AIOps 还是当下火热的 LLM Ops)运维能否最终场景化落地的必要条件是这些最基础的数据和能力。
技术建设
当前弹性计算的告警整体实现了标准化、统一化的管控,其中部分核心告警实现了一定的根因定位能力,当前整体正在向告警自愈方向演进,下面是我们统一告警平台整体的技术设计。
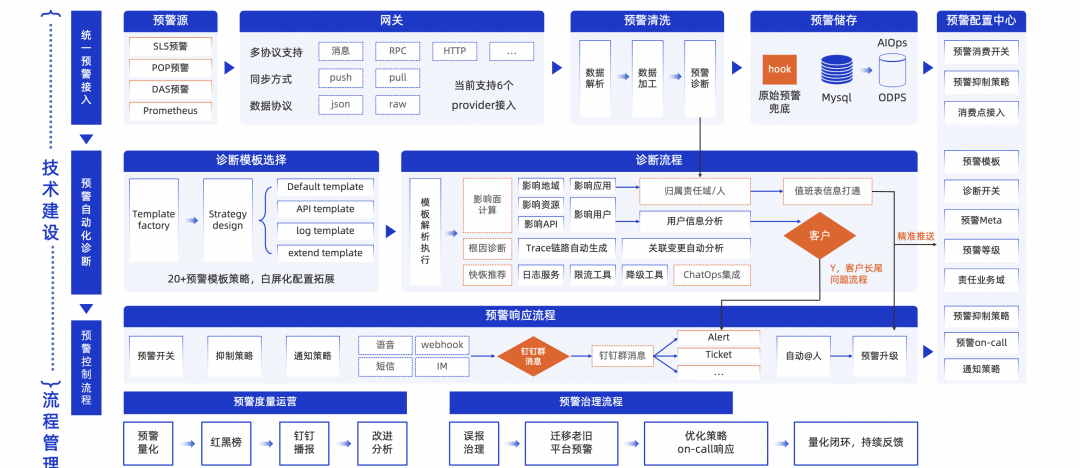
从产品设计角度看,有以下几个关键设计分享:
开箱即用,支持主流告警包括云监控、SLS、ARMS、POP、DAS 在内的七种数据源默认集成(大部分基于公共云开放能力集成),通用监控告警默认集成(比如云监控、数据库等),业务告警在SLS配置后默认自动消费生成配置。业务只需要按照自定义需求简单配置即可完成使用。
多源支持,支持云监控、SLS、ARMS、DAS、Grafana等多源异构告警集成,通过统一的网关模式进行集成,支持横向扩展。
丰富功能,支持告警抑制、关键关联、告警诊断、关联变更、ChatOps集成、移动端使用等丰富功能。
诊断支持,支持可插拔扩展的诊断架构,用户可以通过自定义告警诊断模版实现告警后的根因定位、工单路由等高阶能力;同时系统也提供了通用的公共组件,如热点日志分析、重保客户验证、多地域管控等。
业务打通,与弹性计算业务天然集成,配合嫦娥平台现有的meta数据可以实现告警精准投送,值班体系打通,以及业务诊断扩展,团队钉群定向投送,团队告警度量等业务视角高阶能力。

应用可观测性
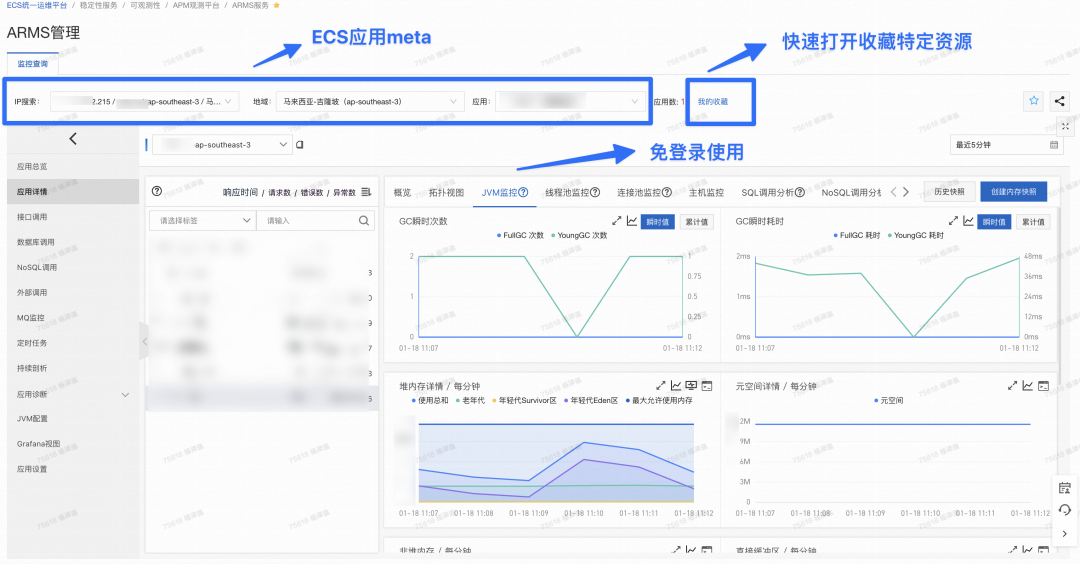
ECS 管控整个稳定性保障以及运维自动化体系都是围绕“应用”来建设的,对于可观测性视角来说,应用维度的可观测性能力至关重要。前面提到的无论是 Data Center、Event、Trace、Dashboard、Alert 都会从有一个重要维度是应用。而应用可观测性建设部分我们完全依托于 ARMS 应用可观测性能力,通过应用接入 ARMS 以及配合 ECS 应用 Meta 嵌入了 ARMS 控制台简化使用成本。
status:云产品健康大盘
阿里云有 status 对外公开了阿里云全站产品的健康状态,方便客户感知阿里云的运行“健康状态”。
https://status.aliyun.com/#/?region=cn-beijing
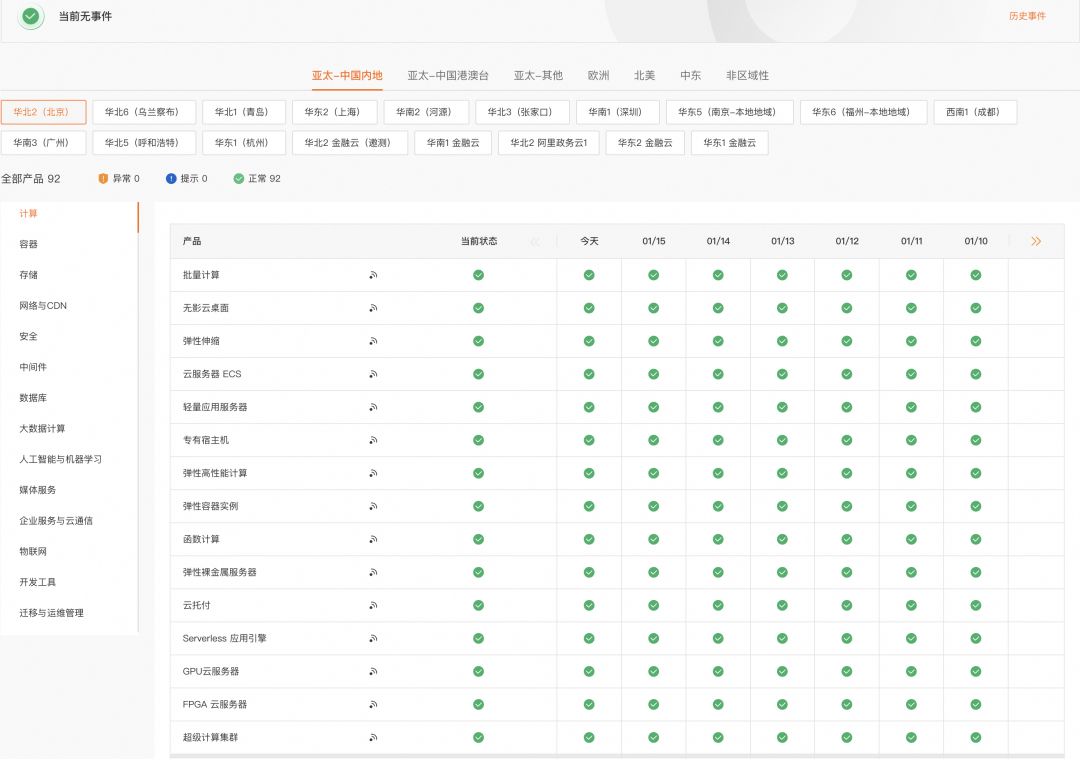
而从阿里云内部组织研发视角来看我们同样需要能力可以感知到关注产品的全局健康状态,对于 ECS 管控来说这里的全局核心是指:全地域、全服务,全应用。云内监控团队建设了内部的云产品 status 大盘,ECS 管控作为首批集成的云产品,将 ECS 管控的观测能力通过标准化 prometheus metric 的方式输出。同时基于云内监控的开放能力在 ECS 运维平台嫦娥进行了系统集成。
AIOps 与 LLMOps
在可观测性领域,标准化、体系化、平台化更多解决的是规模化带来的运维成本,而随之而来的复杂性问题,难以通过传统的手段解决。比如规模性或者故障反馈链路很长情况,如何快速定位故障根因。

智能运维这个方向以及对于大型研发团队的价值,个人坚定不移地相信。当然 AIOps 甚至最近火热的 LLMOps 只是手段,一切要回到解决业务问题的命题才有价值。而前文提到的 Data Center 里包括 metric、log、trace、meta、知识图谱、业务知识等数据是构建智能运维的基石,也是 AIOps、LLMOps 等可以在业务团队落地的关键。
最近的大半年时间里我们建设了包括 log、trace、metrics 、meta 、event 在内的业务运维数据底座,并基于静态 meta 与动态 tracing 数据构建了我们自己的知识图谱。同时在 AIOps 算法领域,我们正在异常检测、容量预测以及根因定位领域做研发工作,目前已经在部分地域开始灰度能力,在根因定位上,我们后续会通过 LLMOps 结合知识图谱来完成。
写在最后
最近两年花了一些时间 ECS 管控内可观测性领域做设计和研发工作,作为业务研发和 SRE 的双重角色,期间接触了阿里云内以及集团多个做可观测性相关产品的团队,也促进或者基于一些产品做了一些小东西,有一些个人对可观测性的认知简单分享一下:
首先,可观测性应该是一个体系化的事情,标准化、工具链、解决方案缺一不可。从普遍的开发视角来看,非常容易将可观测性等同于日志、监控告警等,这个可能是受限于开发者个体的局部意识。从更大的业务视角或者组织视角来看,可观测性应该是一个非常体系化的事情,尤其在中大型研发团队里,可观测性的规模化业务领域的落地方法论可以简化为五步:明确观测目标->确定标准和流程->建立平台工具链->输出解决方案->数据驱动改进。
其次,应该建立覆盖全研发生命周期的可观测性能力。当前谈及可观测性更多是在稳定性领域,比如围绕故障响应的故障发现、定位,以及围绕变更的观测能力等。个人认为观测性应该是覆盖研发、测试、交付、运维等全生命周期的,比如从技术视角看研发阶段,通过性能容量观测数据评估技术方案的设计;CI&CD 阶段通过建立对应流程与工具链的观测能力,提升组织的交付效能和质量;最后,就是老生常谈的,在故障期间通过观测能力快速定位根因,实现故障快速恢复。
最后,组织应该有可观测性的顶层设计。康威定律:组织决定产品形态。

