01 云原生技术栈
下图是 CNCF 公布的云原生基础架构的抽象图。
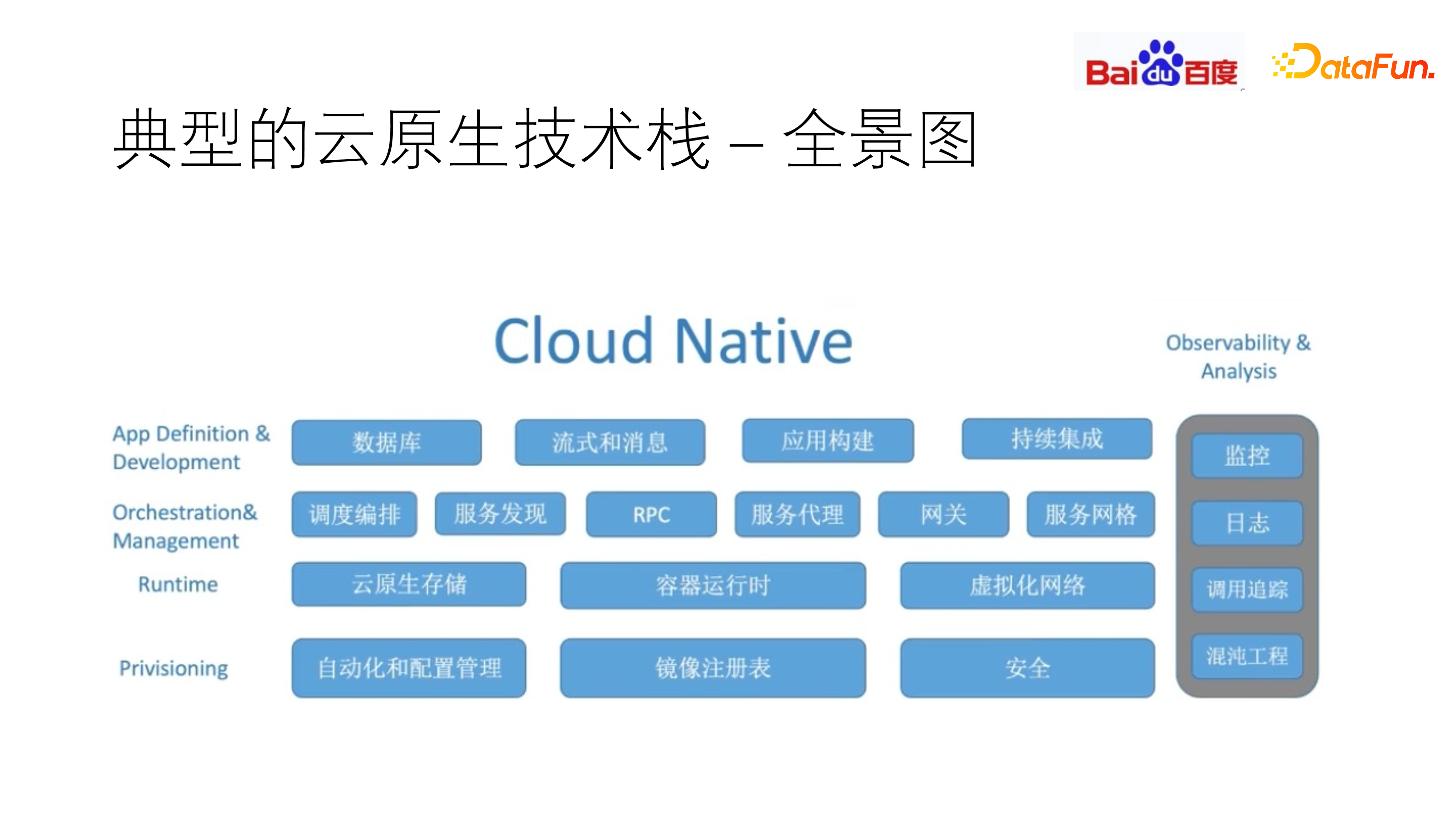
典型的云原生技术栈可分为四层:供给层(Provisioning)、运行时层(Runtime)、策划和管理层(Orchestration & Management)以及App定义和开发层(App Definition & Development)。还包括一些可观测性和分析的基础设施,比如监控、日志、调用追踪、混沌工程。
我们要做的,就是在推荐系统上,利用好 cloud native 的这几层架构,来实现基础技术能力。早期 cloud native 有些基础设施还没有完善,因此部分公司在搭建推荐系统时,部分基础设施是自建的。后期,在 cloud native 技术完善之后,在设计推荐系统时,就会基于 cloud native 的技术栈来进行模块设计。无论是哪一种形式,都要对云原生的技术栈和推荐系统的基础架构有比较深入的了解,才能做到较好的融合。
02 推荐系统架构
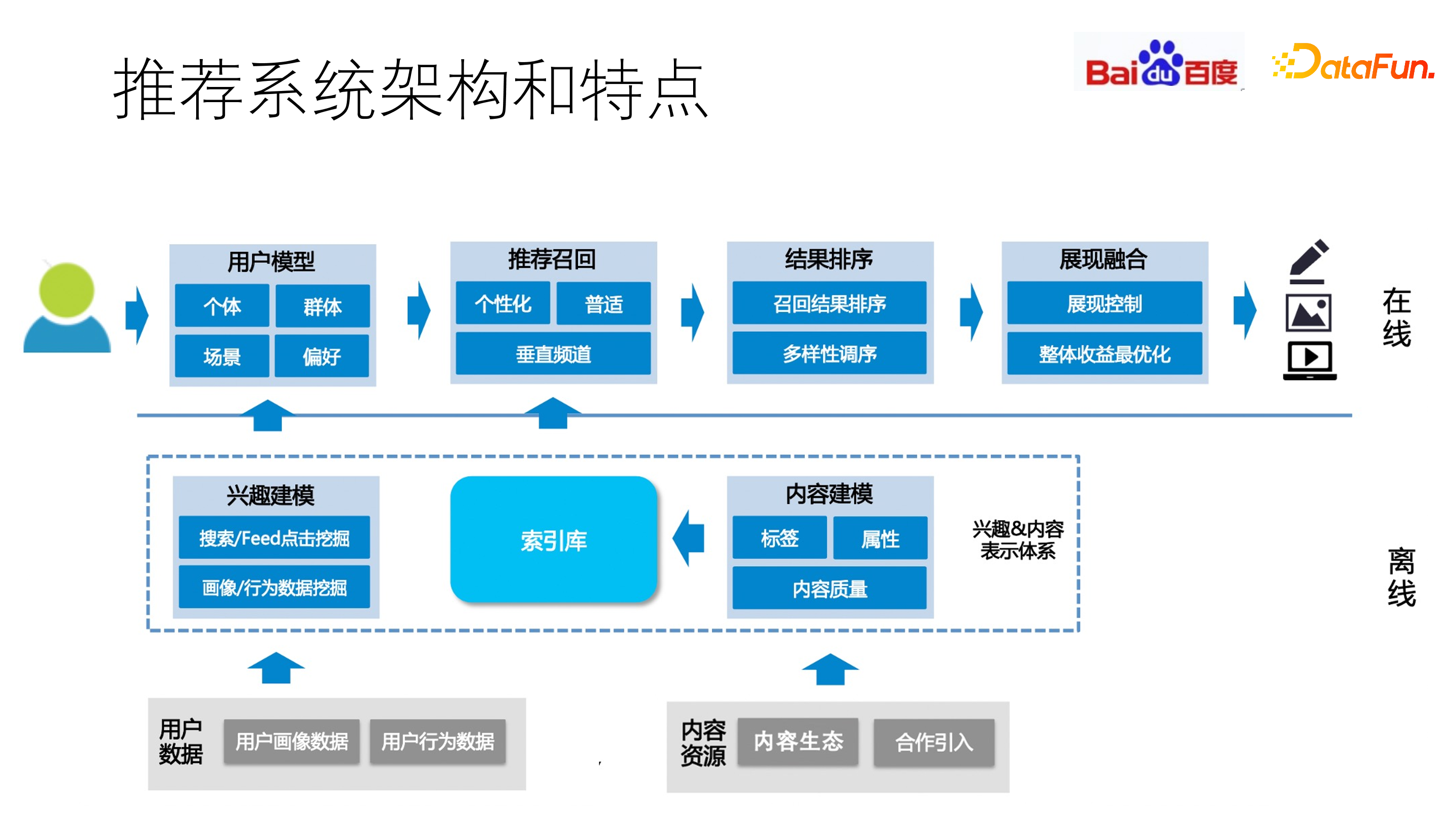
推荐系统的技术架构,可以分为在线和离线部分。
离线部分通常做内容建模,数据引入时,通常做内容建模,例如内容生态和合作数据引入。我们对这些数据进行内容处理,如标签化、标签特征抽取、向量化(即根据一些模型把 Doc 数据转化为向量)。对于用户数据,例如用户点展、共享和分享这些用户行为,我们会对其进行数据挖掘和用户画像、Attention 抽取等,并且对用户的属性也进行向量化。在此基础上,将用户的推送或相关性、关联性等 doc 维度的属性进行召回和排序,最终进行展现。
流量方面,在天级范围内体现出明显的潮汐现象。比如在晚高峰流量高,低谷期流量低。
03 基于云原生的推荐系统设计重点
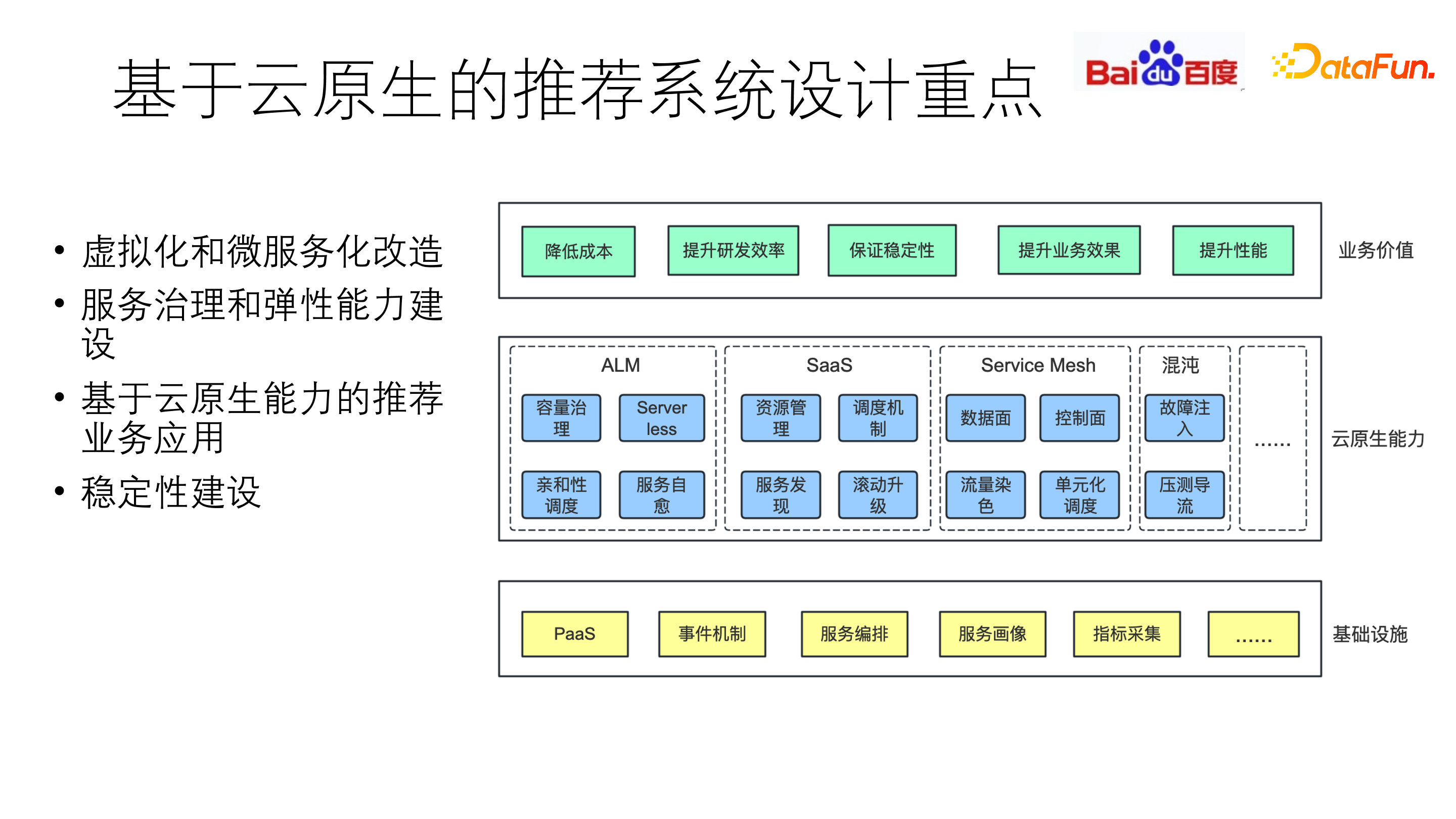
针对推荐系统的特点,在设计时需要从三个层次建设基础能力和业务架构。第一层,需要构建好云原生的基础设施,包括 PaaS、事件机制、服务编排、服务画像、指标采集等;在此基础上,是第二层,云原生能力的建设,包括构建 ALM 的全生命周期管理、容量管理,SaaS 方面的资源管理、调度机制,以及流量管理、混沌工程稳定性等等;最终体现在第三层业务价值上,包括降低成本、提升研发效率、保证稳定性、提升业务效果和提升性能。
接下来重点介绍四个方面:虚拟化和微服务化改造,服务治理和弹性建设,基于云原生能力的推荐业务应用以及稳定性建设。
1. 虚拟化和微服务改造
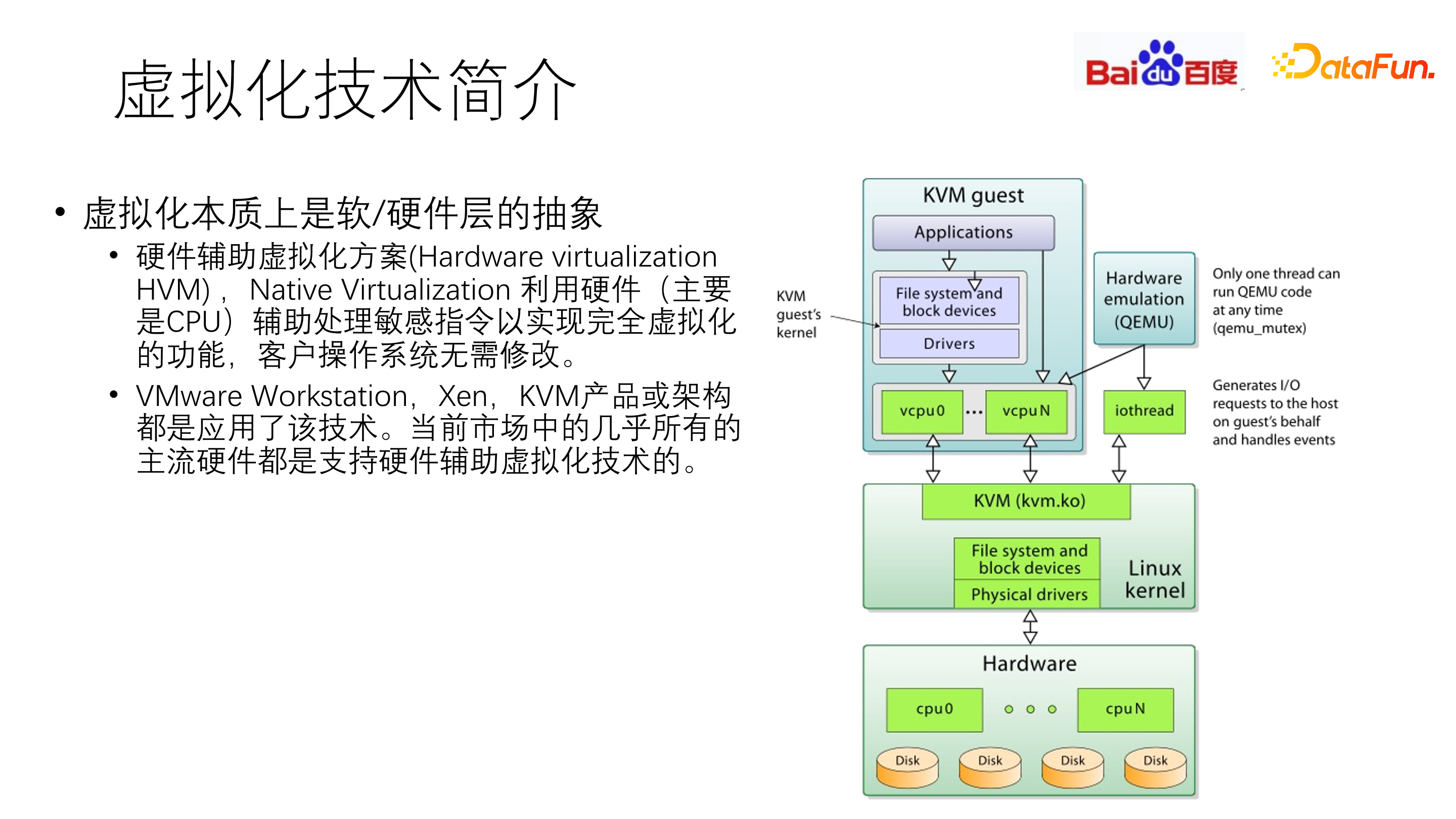
虚拟化技术是云原生系统中最基础的部分,本质上是软硬件的技术栈。硬件辅助虚拟化方案(Hardware virtualization,HVM),主要利用 CPU 等硬件辅助处理敏感指令,以实现完全虚拟化功能,无需修改客户端操作系统。
VMware Workstation,Xen,KVM 产品或架构都是应用了该技术,当前市场中几乎所有主流硬件都是支持硬件辅助虚拟化技术的。
最常见的虚拟化落地方式是 KVM 技术,通过处理敏感指令,实现 CPU、内存和 IO 的虚拟化技术。
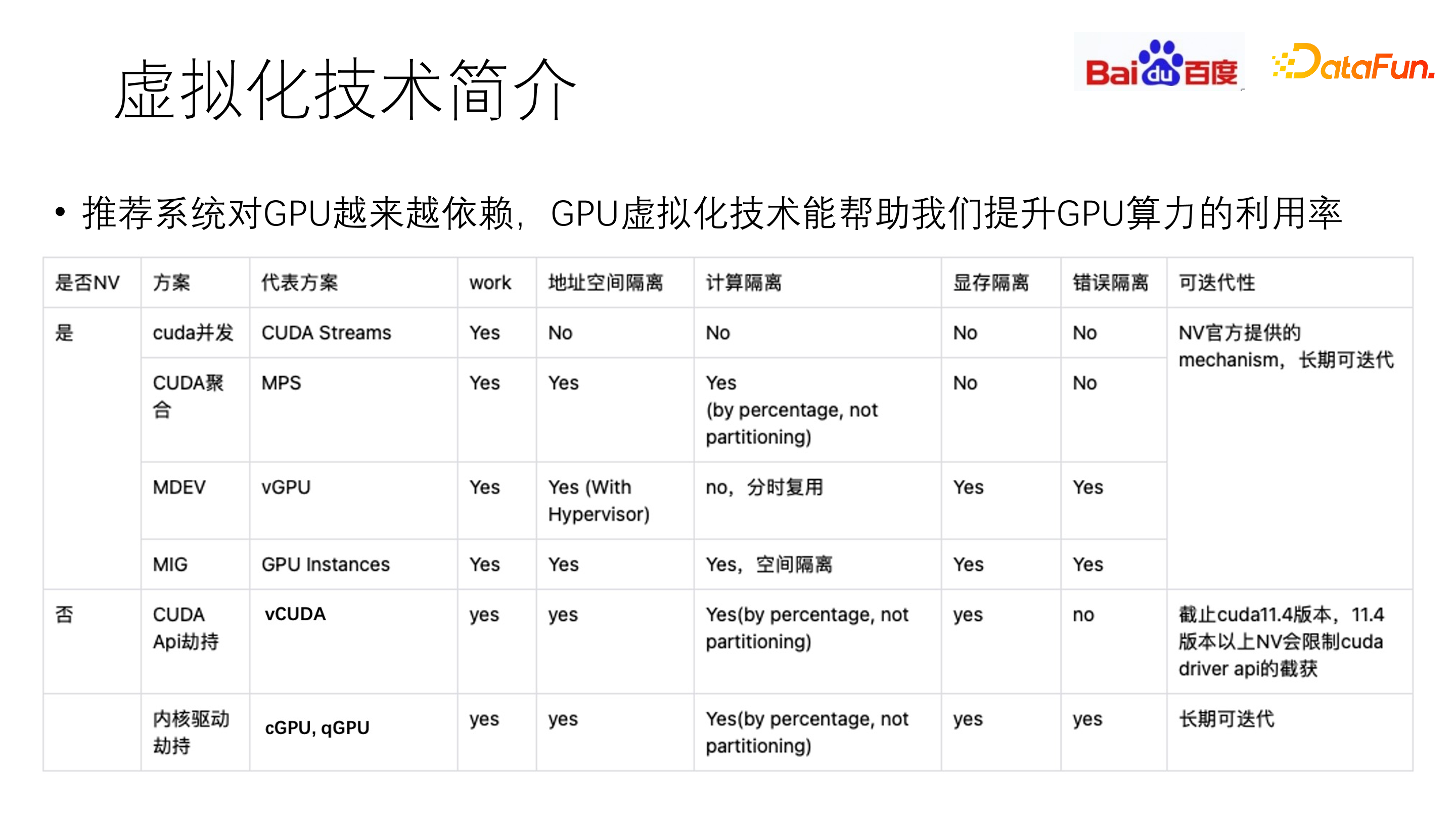
另一个趋势是 GPU,在推荐系统中日益盛行,主要用于模型训练、在线推理等一系列高密度复杂计算。GPU 显存大、计算能力强,需要对其进一步虚拟化切分,使业务能够以更低的成本使用,获得高效的运算效果。
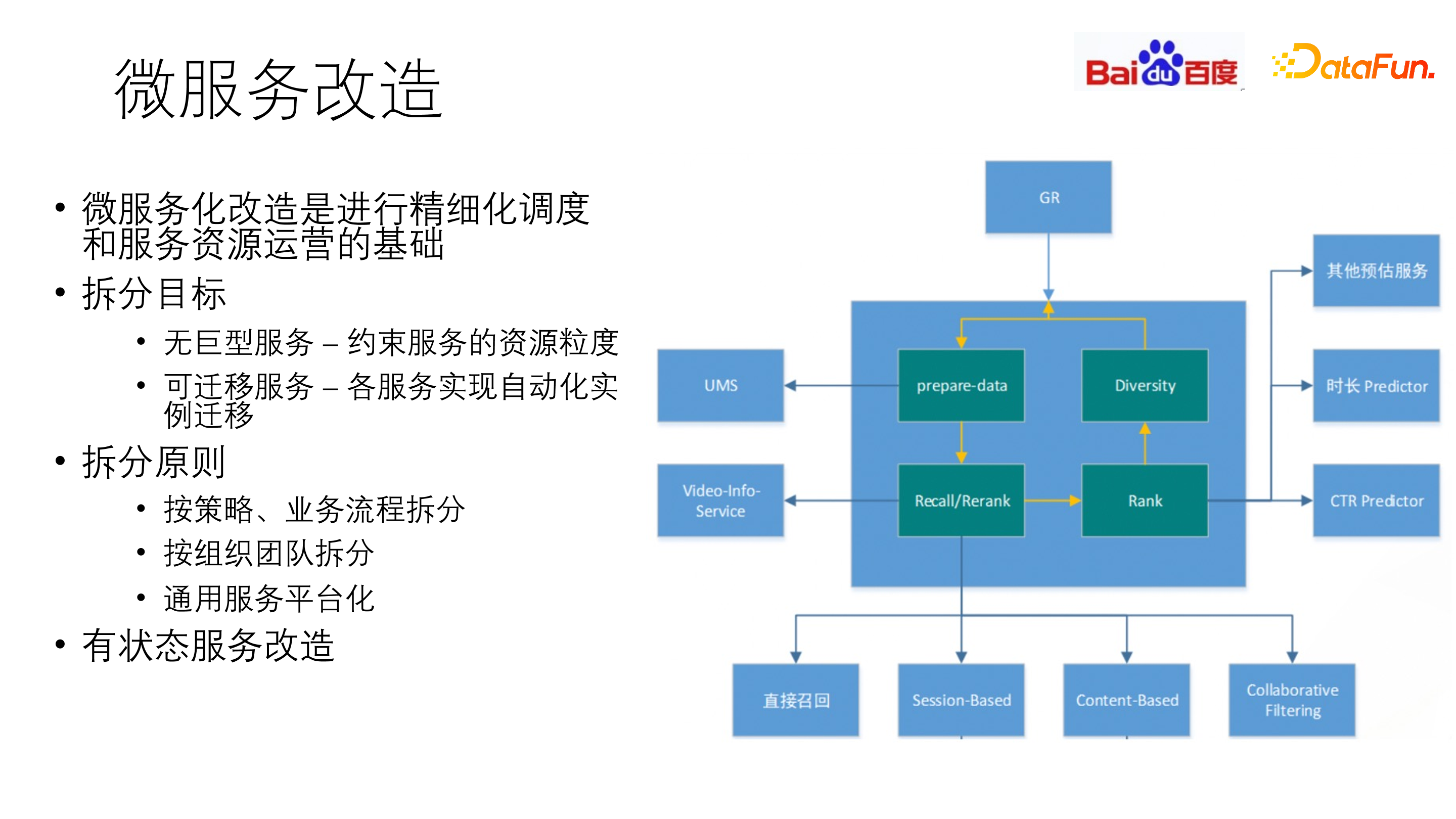
虚拟化构建之后,必不可少的步骤是微服务的改造。微服务化改造是精细化调度和服务资源运营的基础。以百度为例,早期业务流量增长迅猛,对研发迭代的效率要求极高,早期实现方式为巨型服务,每个业务模块功能变复杂后,功能依然在模块内部实现,导致开发迭代变得越来越困难。随着模块逐步庞大,会发现一台机器上的部分资源被占满,而部分资源空闲,因此需要进行微服务化改造。比如预估层,抽出 CTR 预估、时长预估等,将服务拆解。
微服务化拆分的目标是无巨型服务和可迁移服务。无巨型服务,即约束服务的资源颗粒度。同时做到可迁移,即各服务实现实例自动化迁移。可迁移除了常见的扩容外,还有服务实例自愈。比如当整机出现热点,或当服务模块出现异常时,能快速探测,并实现自愈。
拆分的原则包括:按策略、业务流程拆分,按组织团队拆分,以及通用服务平台化。
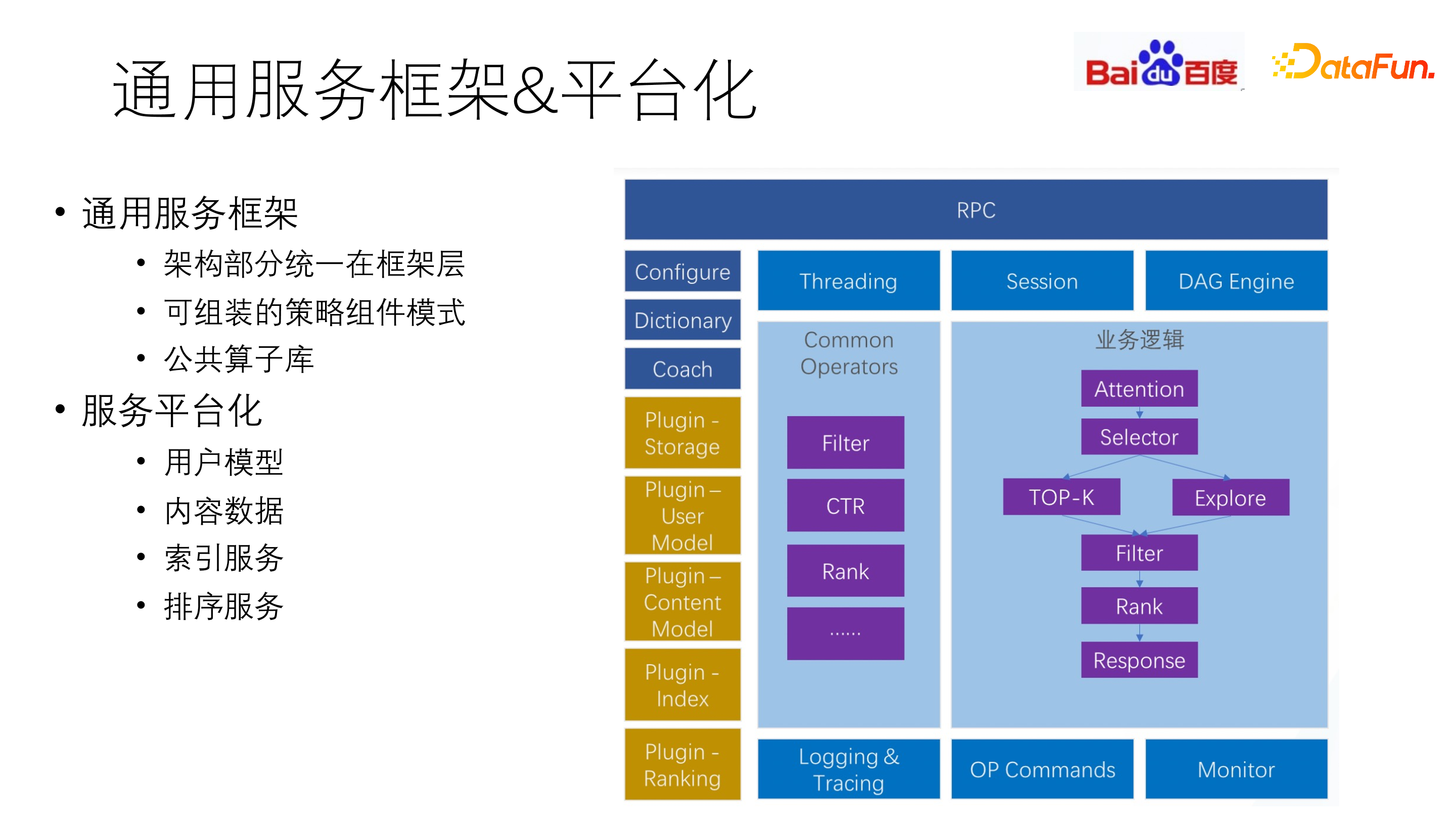
一个典型的推荐系统服务改造方式为,将一些巨型服务,如用户模型、内容数据、索引排序等,进行额外的抽象,进行独立的平台化处理,即通过 RPC 访问外部服务,使其从原本的推荐服务中抽离出来。
构建通用服务框架,通过组件式的开发构建可组装的策略组件。包括业务模块、架构模块。其中架构模块即一些可复用的基础模块,比如 Filter 或一些基础函数,还包括一些策略算子,如 CTR、Rank 等,以算子库的形式提供给业务,进行拼装式的使用。
常用的一种拼装方式是 DAG 引擎。通过一些配置文件,即可将整个代码逻辑组装起来。
2. 服务治理和弹性建设
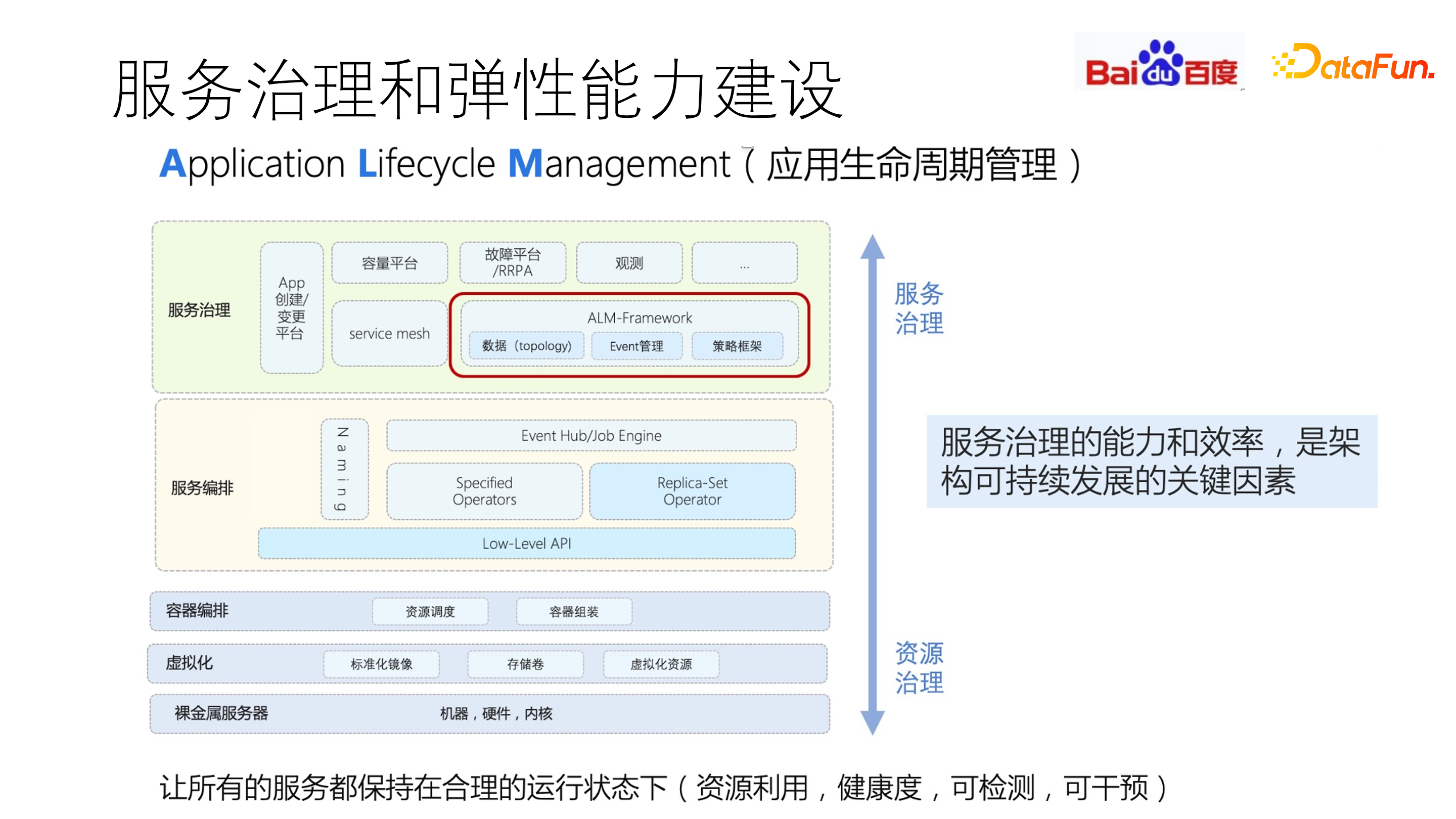
应用生命周期管理(ALM)的目标是通过服务治理,让所有的服务都保持在合理的运行状态下,确保资源利用健康度,可检测、可干预。服务治理的能力和效率,是架构可持续发展的关键因素,其基础依赖就是容器编排、虚拟化的支持,在此基础上通过对基础参数和性能参数的采集,进行服务编排。同时,还要做到可观测性。
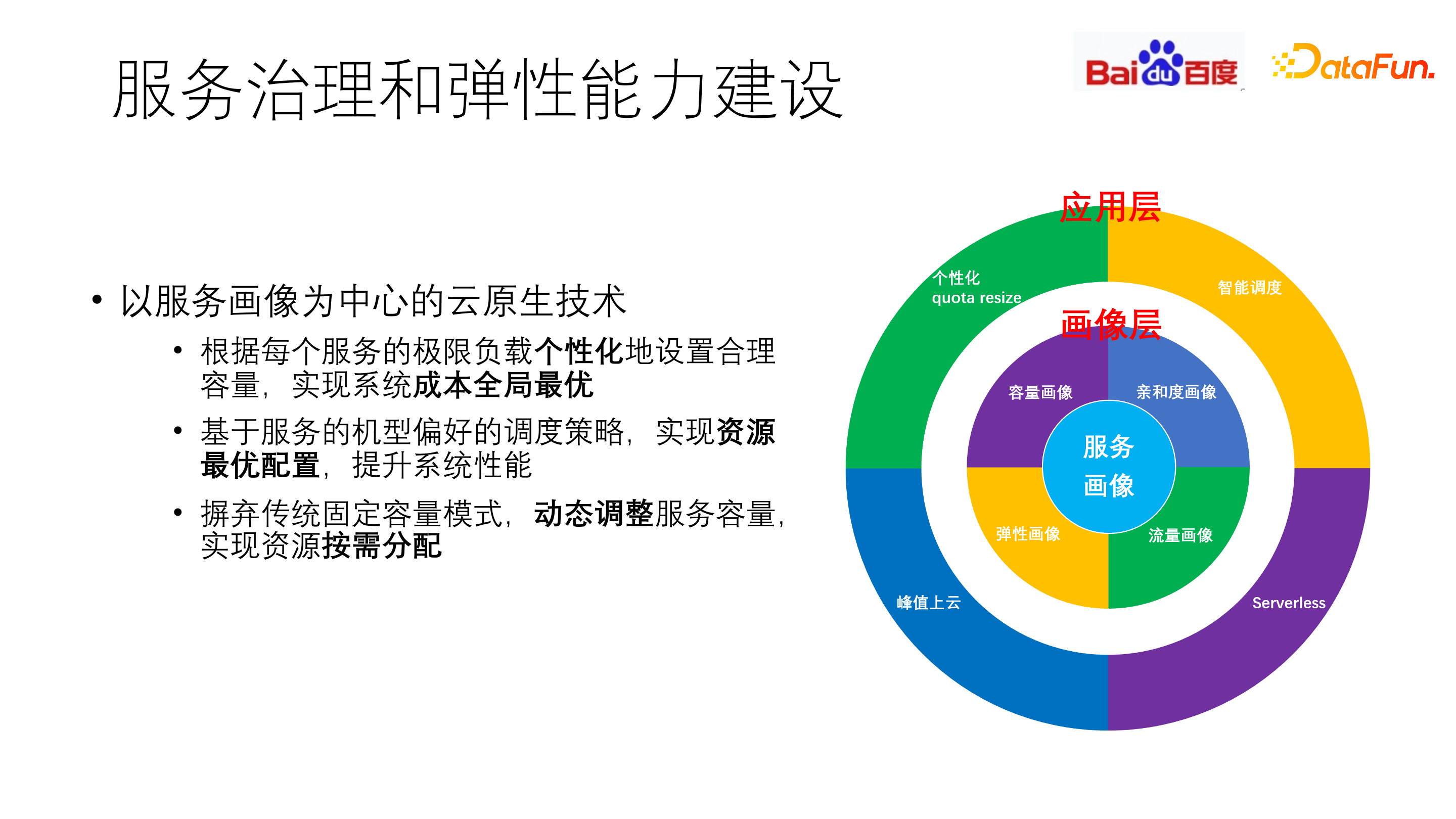
通过 ALM 采集的数据,可以对服务进行统一、标准化地治理,实现对资源的合理利用。但有些服务,其资源利用率并不是随 QPS 增长而线性增长的,不同服务对利用率的容忍率也不同。因此,我们构建了以服务画像为中心的云原生技术。
根据每个服务的极限负载个性化地设置合理容量,实现系统成本全局最优。基于服务的机型偏好的调度策略,实现资源最优配置,提升系统性能。摒弃传统固定容量模式,动态调整服务容量,实现资源按需分配。
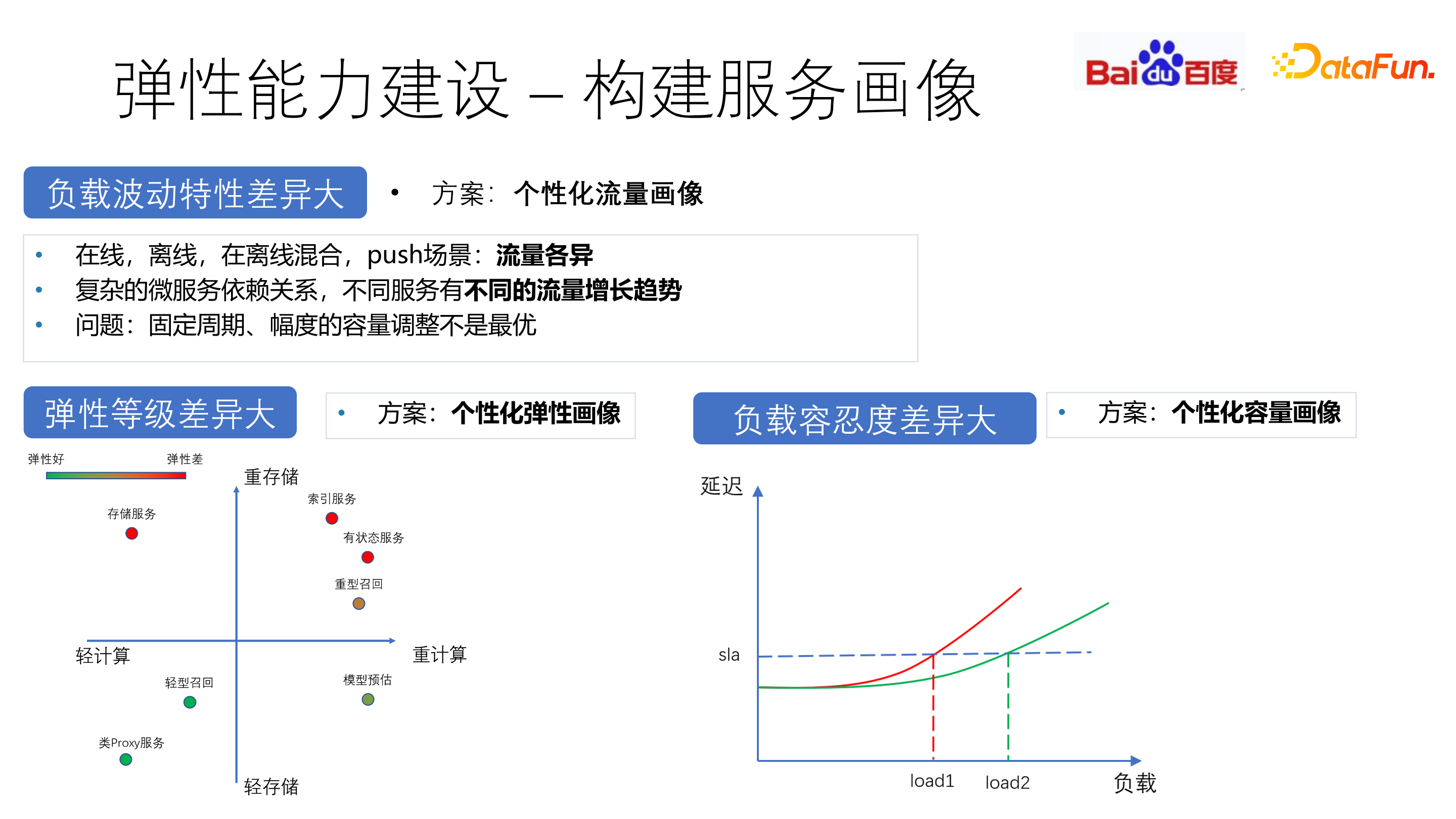
针对负载波动差异大,弹性等级差异大和负载容忍度差异大等问题,通过不同类型的画像来构建弹性能力。比如在线场景中晚高峰流量大,push 场景中新热点流量会明显上升,对于不同的服务构建个性化流量画像来描绘其波动特性。另外,从存储和计算两个维度对各个服务的弹性进行打分,以此作为弹性伸缩的依据。
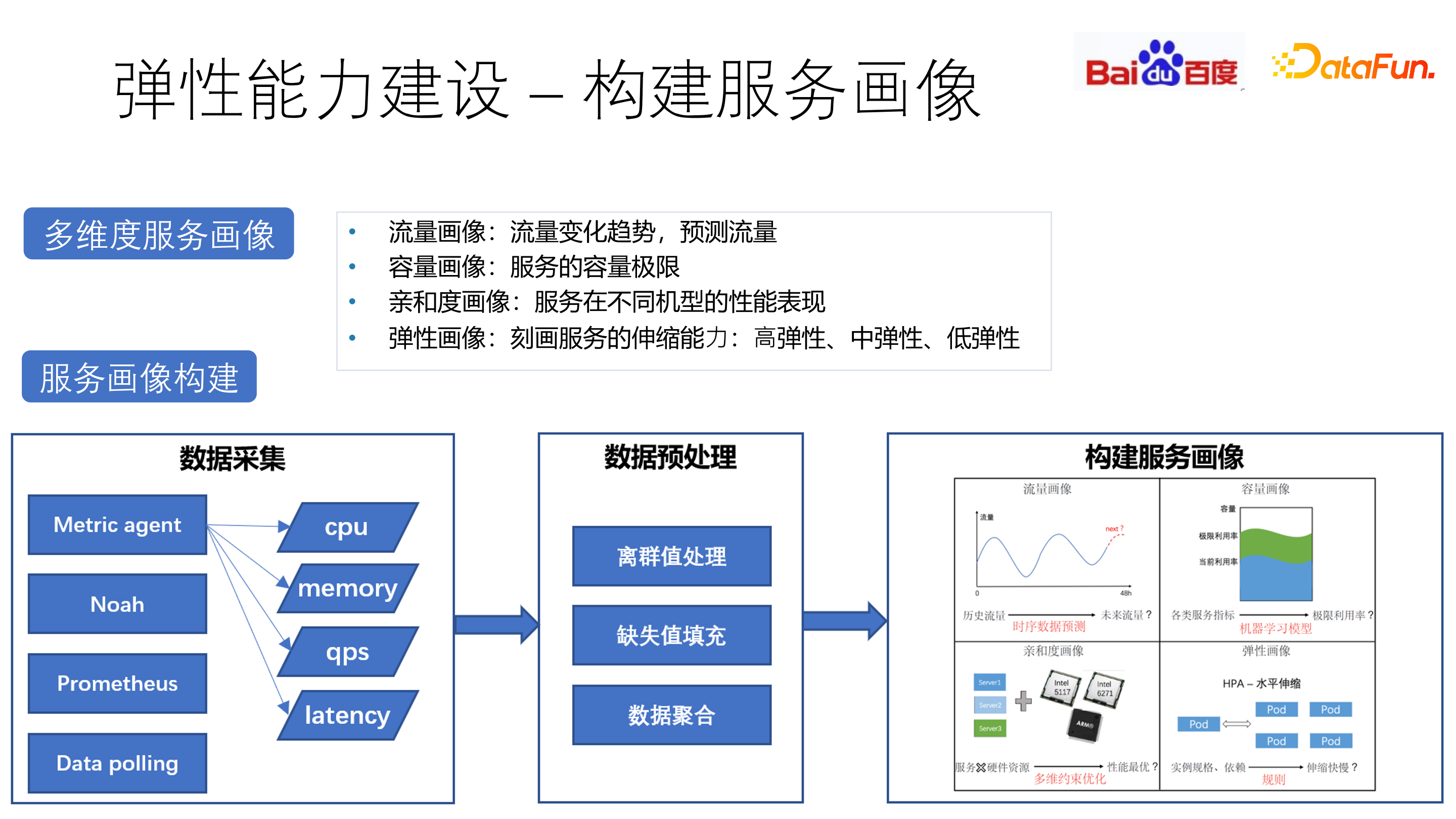
通过 Metric agent、Data Polling 等数据采集,离群值处理、缺失值填充以及数据聚合等预处理方法,构建多维度服务画像。
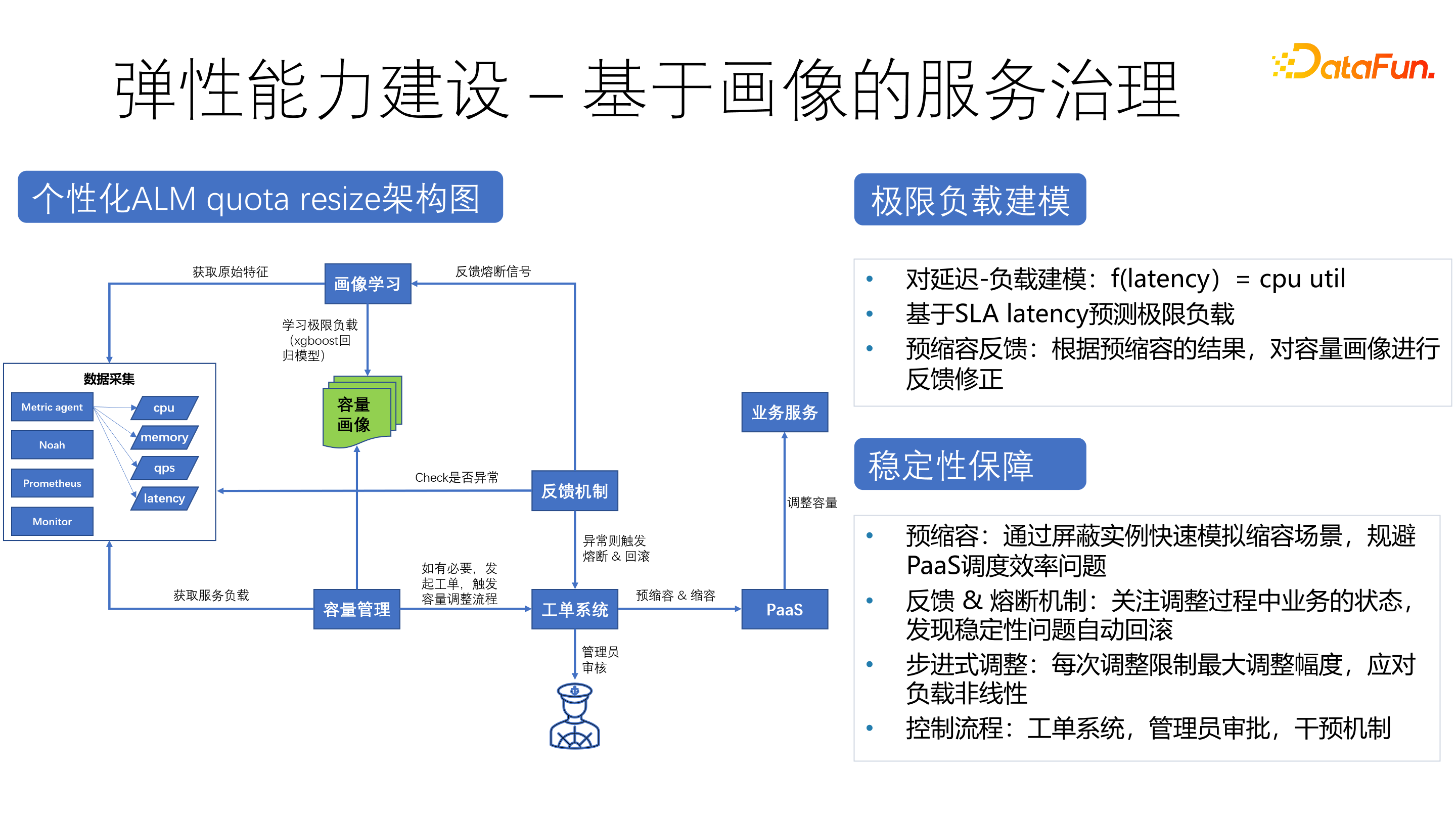
基于画像构建个性化的 ALM quota resize 架构,通过预缩容、反馈和熔断机制、步进式调整控制流程等方法保障稳定性。
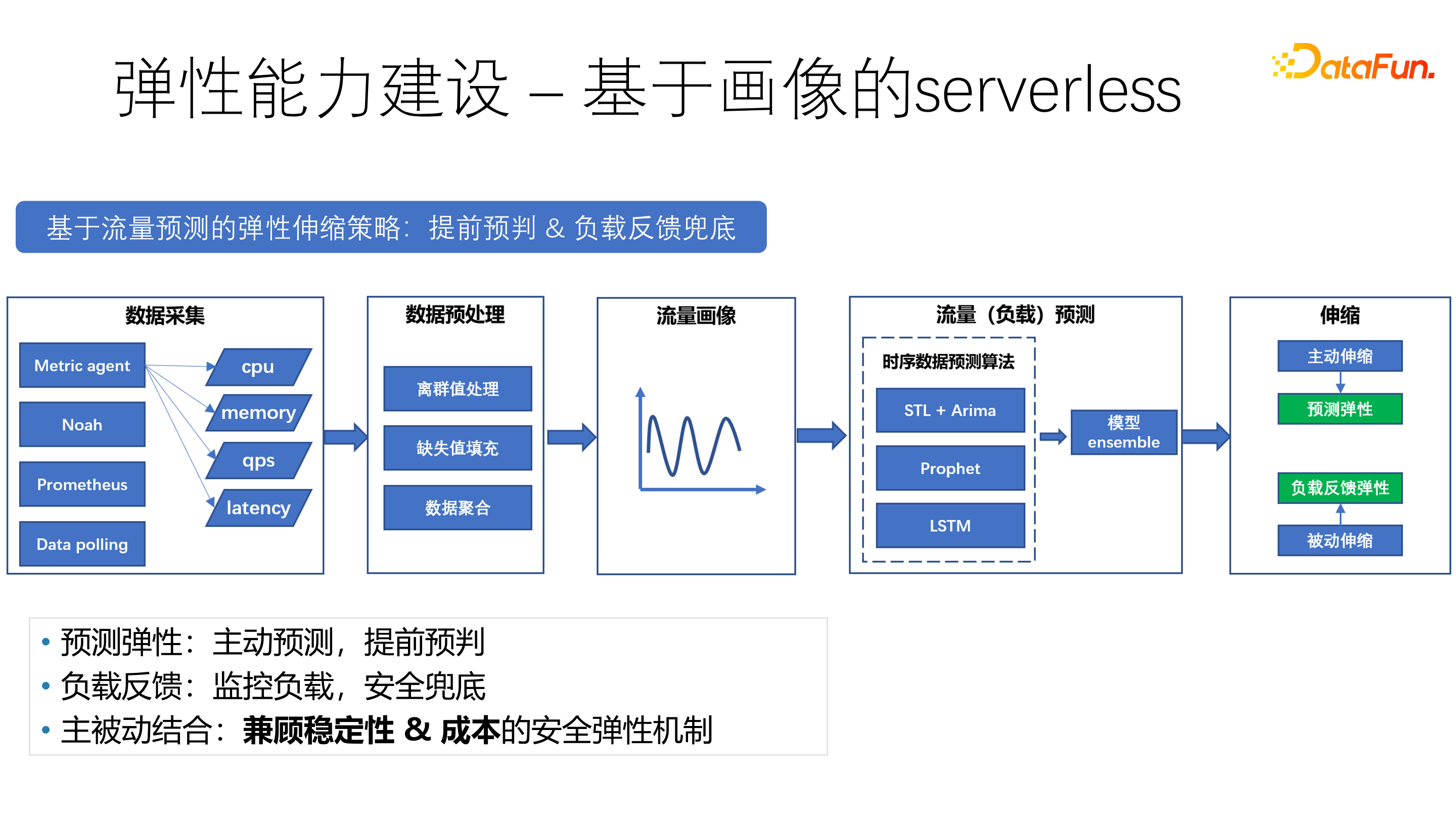
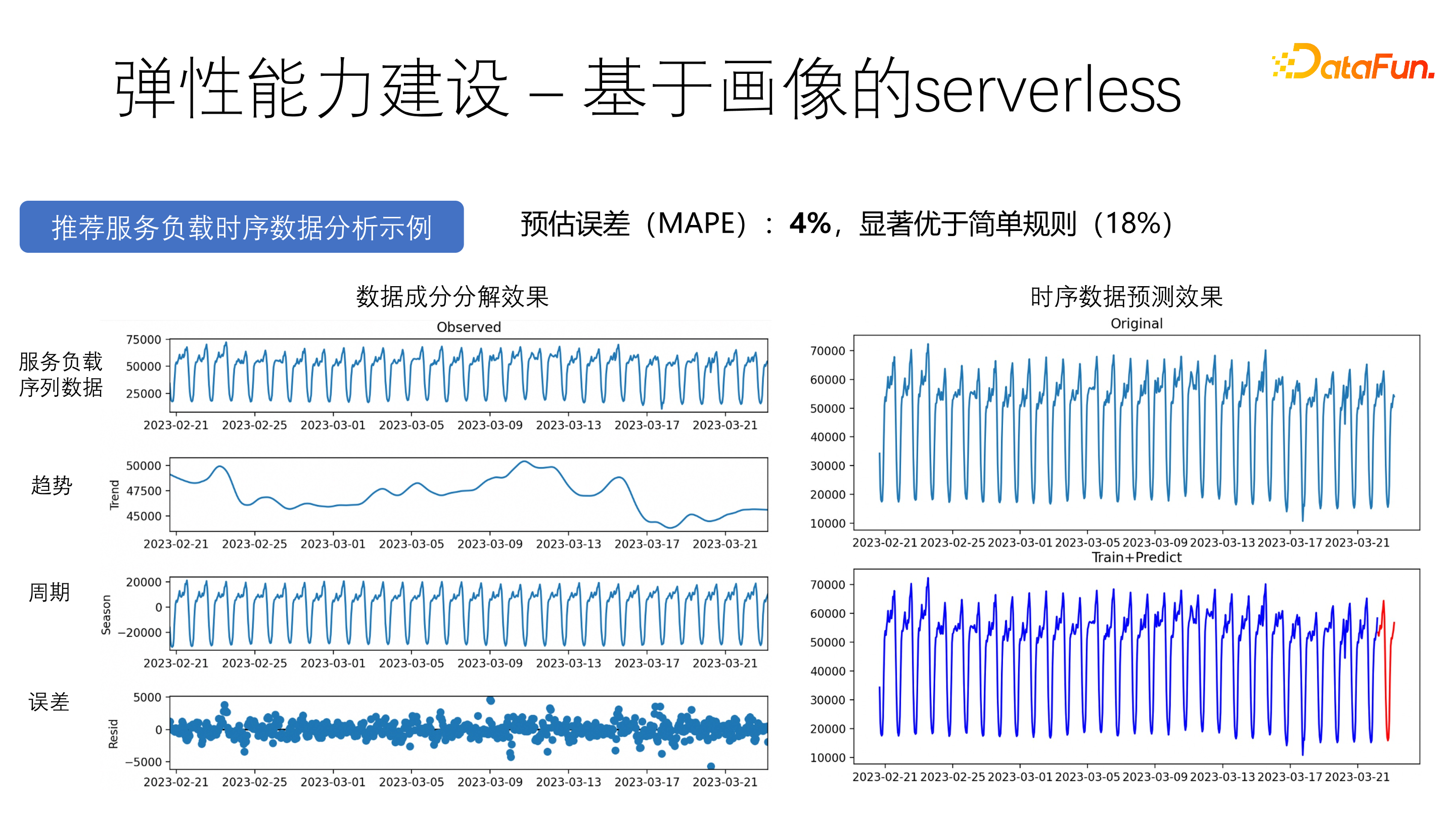
基于画像的 serverless,是一种基于流量预测的弹性伸缩策略,可以进行提前预判 & 负载反馈兜底。依托 STL、LSTM 等时序算法模型进行流量预测。通过主动预测、提前预判、监控负载、主被动结合的方式,构建兼顾稳定性和成本的安全弹性机制。
上图中展示了预测效果。可以看到预估误差为 4%,相较于简单规则的 18%,具有明显优势。
3. 基于云原生能力的推荐业务应用

释放出来的资源可以用于额外的计算,以获得更多收益。
推荐产品不依赖用户的主动输入,多数用户的“兴趣”长期稳定。Nearline 召回机制是介于在线离线之间的一类全新召回方式,容忍秒级延迟,有更大的计算规模和复杂度,可以使用碎片资源和闲置资源,降低机制成本。
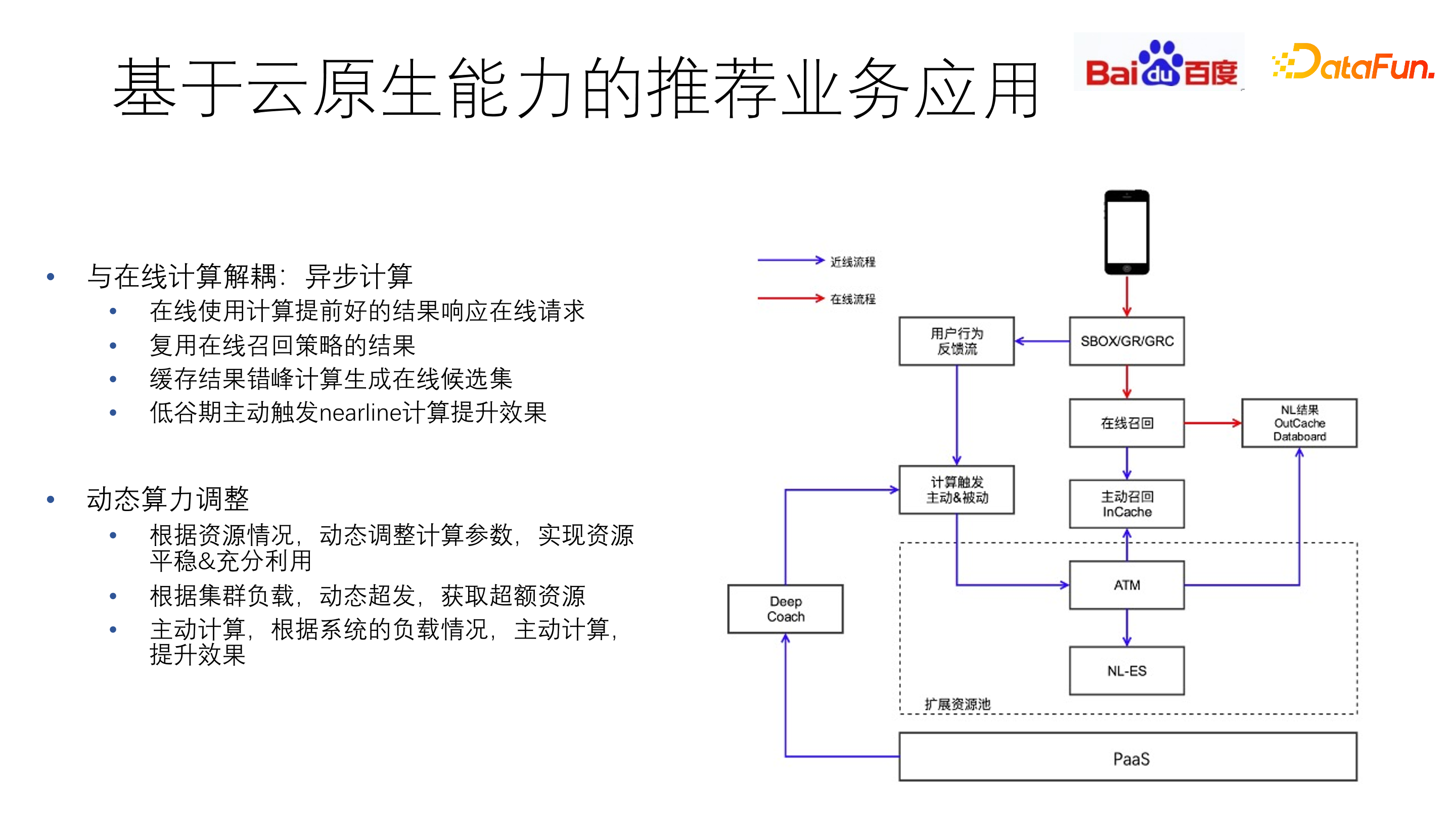
通过异步计算的方式,与在线计算解耦,根据系统负载主动计算,可以提前计算获得预估结果,提升效果。根据资源情况,动态调整计算参数,实现资源平稳与充分利用。
4. 稳定性建设 - 混沌工程
混沌工程在 2018 年由 CNCF 提出,是⼀⻔新兴的技术学科,通过实验性的⽅法,让⼈们建⽴对于复杂分布式系统在⽣产中抵御突发事件能力的信心。
传统的稳定性工作,建立在历史 case 和工程师经验基础上,是一个(发生故障->解决问题->下次发生故障)的循环。系统经过重构升级后,稳定性能力可能无法持续。
混沌工程的整体目标是通过实验主动驱动代替过去的 case 被动驱动,在可控范围内周期性注入故障,主动发现系统隐患,验证稳定性能力,推动架构迭代优化。
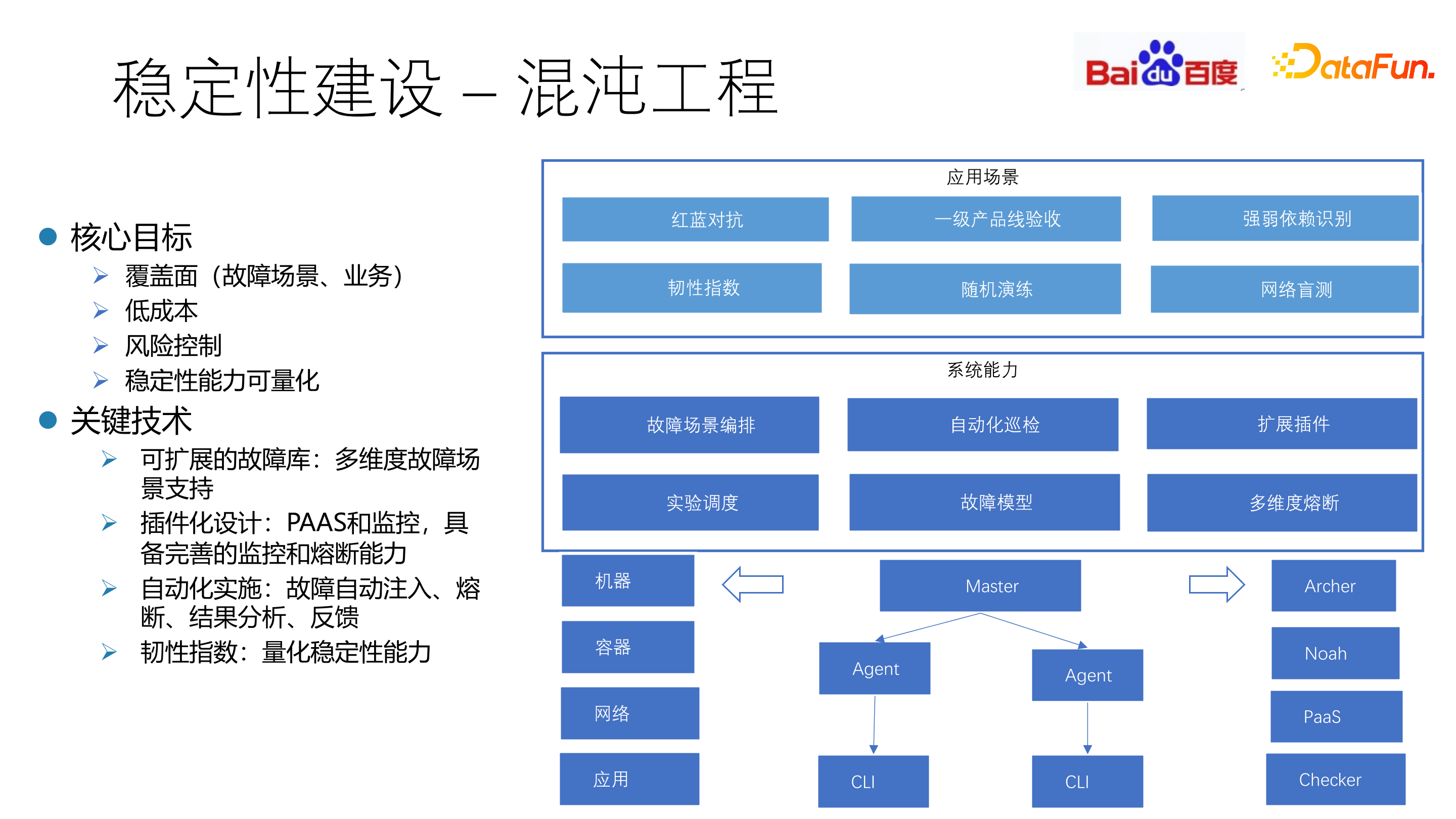
混沌工程的主要机制是通过红蓝对抗机制进行故障的随机预演练。通过对故障场景编排和自动化巡检,利用韧性指数把稳定性进行量化。
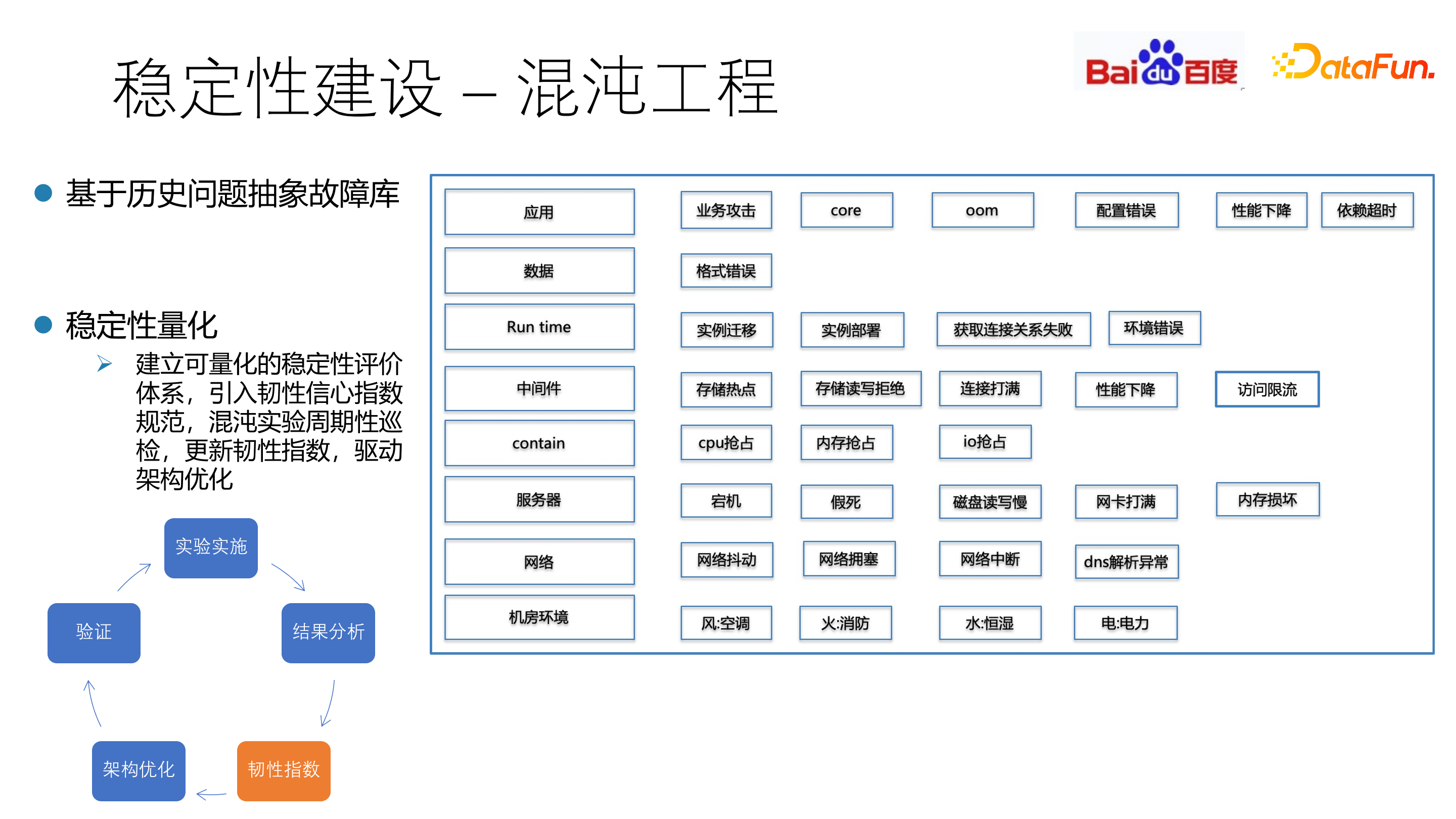
基于历史问题抽象故障库,建立可量化的稳定性评价体系,引入韧性信心指数规范,混沌实验周期性巡检,更新韧性指数,驱动架构优化。

