1. 治理背景和目标
1.1 治理背景
B站作为一个有用有趣的综合性视频社区,每个用户都是在与内容的互动过程中形成单向/双向关注和身份上的群体团结,具有相同兴趣爱好的小伙伴聚集在一起形成不同圈子,所以,当小部分用户在社区中有贬低或者拉踩其他用户的行为,甚至出现人身攻击等恶意发言,社区氛围很容易被破坏。
社区文化和价值的体现来源于内容的创作和交流,其中评论作为B站用户交流互动最重要的阵地之一,自然也是社区氛围的重要组成部分。根据2022年6月评论的举报理由分布,目前B站负向评论的主要来源为引战和人身攻击。
1.2 治理目标
社区一直面临一个挑战就是:减少贬损、侮辱、诽谤等粗俗人身攻击内容的曝光,一方面能够促进正向内容和情绪的流通;一方面希望通过治理引导用户正向发言,进一步促进社区友好互动、建设社区氛围,从而让用户看到良好的社区环境和氛围。
2.平台人身攻击内容现状
2.1 人身攻击短词
首先需要关注的是无差别的纯人身攻击文本,此类文本是不会随着社会或者站内热点事件而变化的包含辱骂、攻击性质的文本。
常规的攻击性短词是有限且可控的,但是其变体形式是治理的难点。攻击性短词的变体主要包括:
1) 同音同形类(如伞兵、剑冢);
2) 首字母匹配类(如出生、我测你码);
3) 特殊字符、表情、罕见字变体类(如大乃√、🐒)。

图2.1.1 :人身攻击短词变体分析
2.2 部分分区人身攻击问题突出
由于分区生态与用户习惯的不同,对所有分区一刀切的治理模式是不可取的。为了既能有针对性地解决问题,又能有效引导社区情绪正向发展,我们对生活、娱乐、影视、知识、科技、运动、游戏以及音乐这八个区的人身攻击以及引战的举报情况的摸底,从可评估性、可治理性两个角度发现娱乐、影视区和游戏区的问题更为突出,具体体现在以下两个方面:
在游戏、娱乐、影视三个分区中,人身攻击举报的数量远高于平均值,是总人身攻击举报量的大头。
在游戏、娱乐、影视三个分区中,人身攻击举报评论的前 100 个关键字里面,实体词的占比分别为 45%、57%、63%,相比于其他话题丰富的区域,这些分区的话题聚焦度更强、可治理性更高。
3.专项治理过程
我们首先结合问题评论锁定要治理的对象是人身攻击。需要特别说明的是,引战评论当然也是问题评论中需要去治理的,但引战问题相对而言更加复杂,定义问题难度更高,因此,在本次治理过程中我们更侧重于更能引发负向情绪的人身攻击评论。整个治理过程见下图3.1:
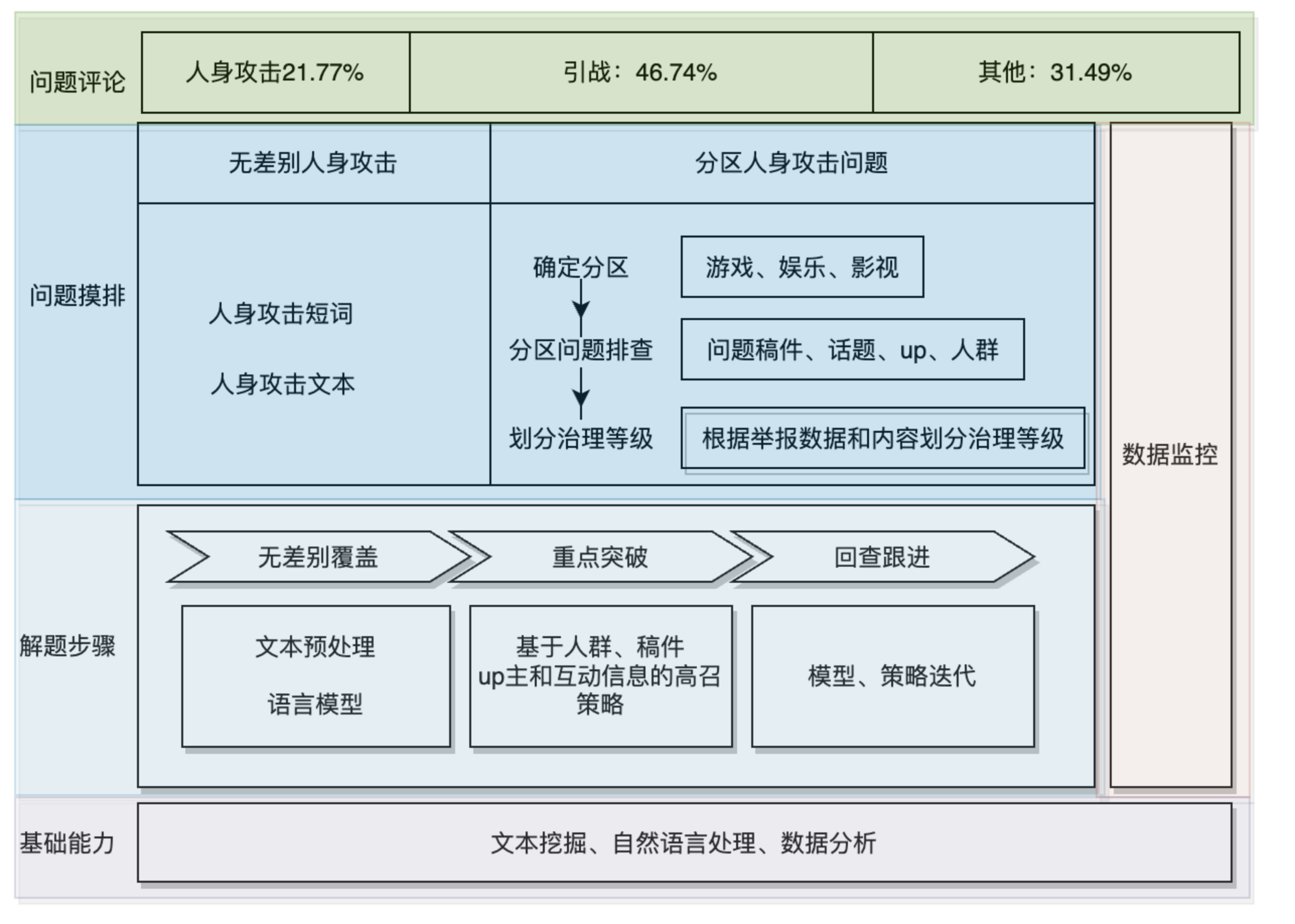
图3.1 :人身攻击治理过程
3.1 无差别覆盖治理
1.词匹配识别
针对变形体的识别,依赖已经积累的大量的技术手段包括:拼音识别、数字同音识别、汉字相似识别、单词检测识别、汉字关键词识别、变形体映射等文本预处理能力。通过对用户评论进行文本预处理,我们可以对评论进行归一化,然后使用汉字或拼音进行识别。

图3.1.1 :问题和相应文本预处理能力
举例其中的汉字相似能力,我们引进了“音形码“的概念(音形码的概念非自创,常用于输入法产品),借助音形码可以快速计算出汉字的相似结果,这里借助这个概念可以把汉字转化成机器可以理解的数字串,数据结构大体上如下图:

(图片来源于网络,如有侵权请联系删除)
这个结构涵盖了一个字的拼音和字形数据,可以很好的识别 音似例如“傻”和“杀”,形似例如“娘”和“狼”等。具体的上线效果如下:

接口直接根据设置好的相似阈值返回风险文本。
2. 模型识别
根据数据显示,不同分区中人身攻击举报评论的准确度在10%到40%之间,其中绝大多数为阴阳怪气或者对线过程中稍稍偏激的言论。为此,我们在前期准备了多种算法模型,包括人身攻击模型、对线模型以及阴阳怪气模型。依赖模型的语言理解能力,我们能够拦截覆盖掉一部分的纯人身攻击以及引战文本。

图3.1.1 :人生攻击专项依赖的模型能力
第一类文本分类模型
在分类问题上,Fasttext、DPCNN、TextRCNN、Attention、Bert等模型都是比较经典的可用于文本而分类问题上的模型。在 NLP 领域,BERT 的强大毫无疑问,但由于模型过于庞大,单个样本计算一次的开销也会比较大,因此,我们使用比较多的是体量更小、速度更快的tiny_bert。在模型训练的过程中,我们可能面临的一个问题是样本质量不够高导致模型效果不佳,在已有样本的基础上,我们会先通过Bert进行样本提纯,再喂给tiny_bert,以提高模型准确度。而在在对线模型中,我们将输入样本写成“[CLS] +当前评论 + [SEP] + 父评论 + [SEP] +“跟评论” + [SEP]”的格式,让模型学习到对线过程,并采用bert与图神经网络结合的方式进行对线文本的分类,将预训练模型BERT与图网络GCN(GAT)相结合用于文本分类,能充分融合二者处理数据、提取特征的能力,使得模型有比较好的预测效果。
第二类文本相似模型
分类模型能帮我们覆盖掉大部分的特殊case,而在B站这个社区平台上,不同的分区有着不一样的文化符号,并且随着各类社会舆情的发生,部分人身攻击文本会具有一定的特殊性,而文本相似模型能根据输入的负向样本种子,快速准确地覆盖掉同关键词、同核心思想文本。
为了使模型持续有效,我们每周对召回数据和举报数据进行校准,一方面用于评估模型的可用性,另一方面及时向算法侧返回Bad Case和提供新的训练样本,以实现模型对用户多变地发评习性及时作出反应。由于模型的更新并不是实时的,对于突发的高举报案例,我们将相关的数据经过筛选后放入模型后台的黑模型样本集中,对相关负向内容进行拦截。
3.2 重点分区突破
由于不同分区的人身攻击评论的发评人、讨论话题、稿件信息特性不一致,因此问题的严重程度也不一样,词+模型并不能完全解决问题,对于无法覆盖的部分,我们需要对单点问题进行重点突破。
我们把这一部分的治理分成了以下几个步骤:
1. 确定每个分区的治理内容;
基于每个分区特性,对重点分区深入分析,结合社区知识图谱系统,对重点分区的问题进行细致梳理并归纳。
2. 划分治理等级;
对不同分区的不同问题进行严重程度分级。
3. 确定治理策略。
结合社区阿瓦隆系统,对线上进行定向管控治理。
3.2.1 确定分区治理内容
结合社区知识图谱系统的抽象归纳,并通过分析上半年的的举报数据,得到重点分区现存人身攻击的需治理的问题,其中娱乐区4个,影视区3个,游戏区2个。
3.2.2 划分治理等级
综上,结合举报数据和评论内容,我们划分成两个治理方向:
一是针对某一具体对象(人或群体)的带有恶意引导性质或攻击性的评论,这类评论需要予以拦截;
二是减少引战类型且容易被举报的调侃或负向梗的曝光度。
3.2.3 确定以及实施治理策略
我们的策略围绕着三个维度展开,分别是关键词、人群、稿件以及up主。
1.关键词维度。
对于人身攻击言论,抨击或辱骂的对象通常是实体。基于此,除了人身攻击短词外,我们还分区维护了一个“实体——关键词”知识库。我们结合评论内容和稿件信息进行精准匹配,基于匹配情况决策处置策略。另外,为了及时发现讨论的话题和实体,我们线上使用高讨论度的事件人物识别模型,再基于报表展示讨论实体,以保证文档信息的持续更新。
2.人群维度。
从发评者角度来看,可按攻击目标分为两种:一种针对的是非现实个体(明星、游戏、视频内容等),占据大部分,第二种攻击的对象是站内用户或UP主。在大多数情况下,第一类用户群更具稳定性和聚集性,因此我们考虑综合行为等多重维度来识别第一类人群。
我们通过互动内容、关系等标记出第一类人群,并采取相应的治理策略。经过治理,被举报用户的重复率下降了40%。被举报用户的重复率指的是被重复举报用户与被举报用户总数的比例,这个下降趋势表明了极端用户的极端互动行为减少了。
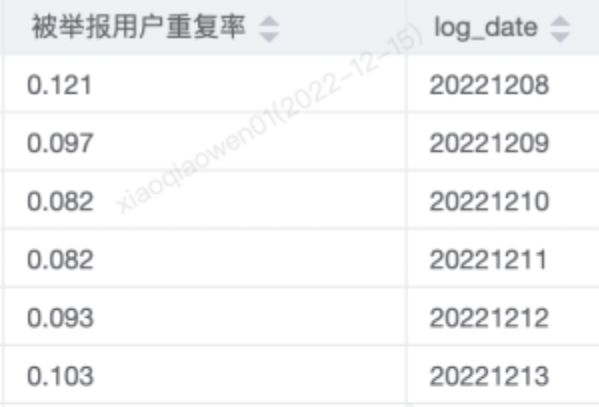

图3.4 人群包策略实施前(上)后(下)被举报用户重复率
3.稿件维度和UP主维度。
某些稿件自带引战或者人身攻击风险,需要及时干进行干预。对于不同的治理内容,我们结合了关键词、人群稿件以及UP主信息这几维度来部署相应策略。被策略识别为高风险的内容中包含较高浓度的攻击性评论,从中实施高召可以达到精准扩召的效果。
我们提高召回的方式通常包含两种,分别是调整单一模型分的阈值和基于多个模型(如阴阳怪气、对线、文本质量分、立场分)训练一个融合模型的方式。融合模型方式包括常见的线性融合(如多元回归、逻辑回归)和非线性融合(树模型)。而融合模型可以较大程度地丰富召回样本的多样性。
3.3 回查以及跟进
持续收集模型训练样本:数据同学根据标注标准,对每周的举报数据进行抽样打标,漏召回case放入模型重新学习,形成良性循环;
敏感词系统相似模型召回:漏召回的人身攻击样本清洗一遍以后,作为相似模型的种子,对问题文本召回;
基于举报数据线上回查删除:被举报过多次的人身攻击文本,文本的人身攻击模型分>阈值,直接删除;
策略的迭代和更新:更新的内容除模型外还有负向词、人群等,基于策略的聚集内容或被反馈的误召回案例对策略进行回查并迭代;
数据探查:通过报表展示或告警风险稿件、人群、单评以及各项举报数据的异常波动。
4. 治理效果
经过治理,影视、娱乐以及游戏三个重点分区23年12月份相较于23年6月份,人身攻击举报占比绝对下了31.97%,引战的举报占比24.77%。

图4.1 影视、娱乐和游戏区的综合人身攻击引战举报占比
5. 总结与展望
经过治理,人身攻击举报占比下降趋势比较明显,但是数值上仍有下探空间。互联网不是法外之地,为了维护一个正向和谐的社区氛围,我们还可以从以下几方面去进行优化:
考虑优化稿件下的内容展示逻辑,丰富内容排序标准。
对于“黑话”、负向关键词的挖掘需要更自动化;
如何引导用户正确选择举报理由或对举报理由进行二次判定以提高举报数据的准确度;
模型短周期的自动化训练和上线;

