vivo大模型从训练到产品落地的实践
导读:本文是由 vivo 算法总监,付凡老师带来的关于 vivo 蓝心大模型(BlueLM)从训练到产品落地过程的介绍。
01
大模型的演进
1. 大模型的演进过程
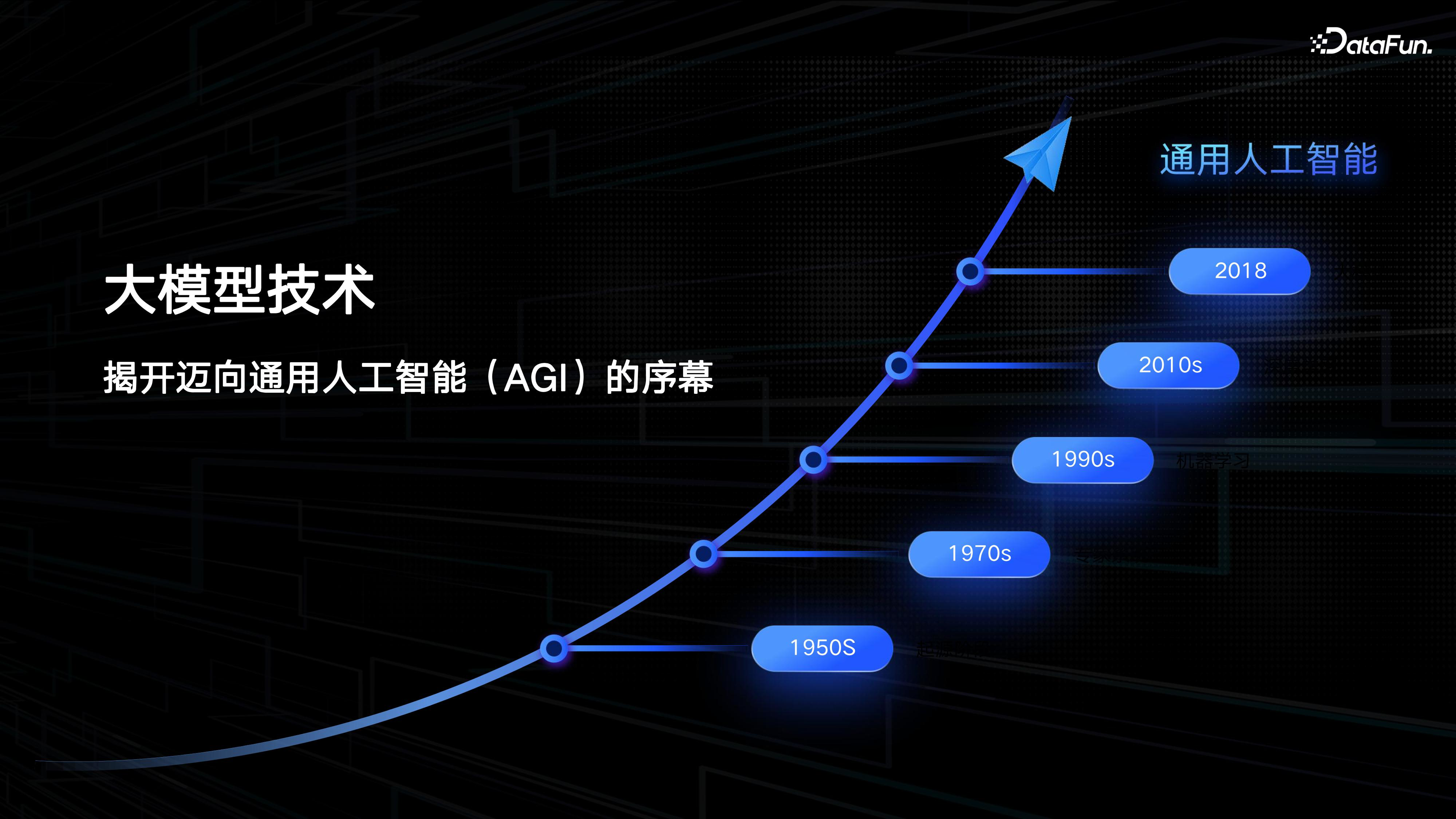
大模型的发展经历了如下几个阶段:
(1)起源阶段 (1950s):在 1950 年代,人工智能的起源阶段以专家系统为代表,这些系统通过预设的规则和知识库来模拟人类专家的决策过程。
(2)机器学习 (1970s):1970 年代见证了机器学习概念的提出,这一时期研究者开始探索算法,使计算机能够从数据中学习,而不仅仅是依赖于硬编码的规则。
(3)深度学习 (1990s):进入 1990 年代,深度学习作为机器学习的一个分支开始崭露头角,尤其是在神经网络的研究上取得了进展,尽管当时尚未达到广泛应用。
(4)深度学习复兴 (2010s):2010 年代,深度学习经历了复兴,特别是卷积神经网络(CNNs)和循环神经网络(RNNs)的出现,极大地推动了人工智能在图像识别、语音识别和自然语言处理等领域的应用。
(5)大模型技术突破 (2018):2018 年,OpenAI 的一系列技术突破,如 GPT 系列模型的推出,揭开了迈向通用人工智能(AGI)的序幕,标志着大模型技术进入了一个新的发展阶段。
2. OpenAI 一系列技术突破带来新一轮 AIGC 的发展
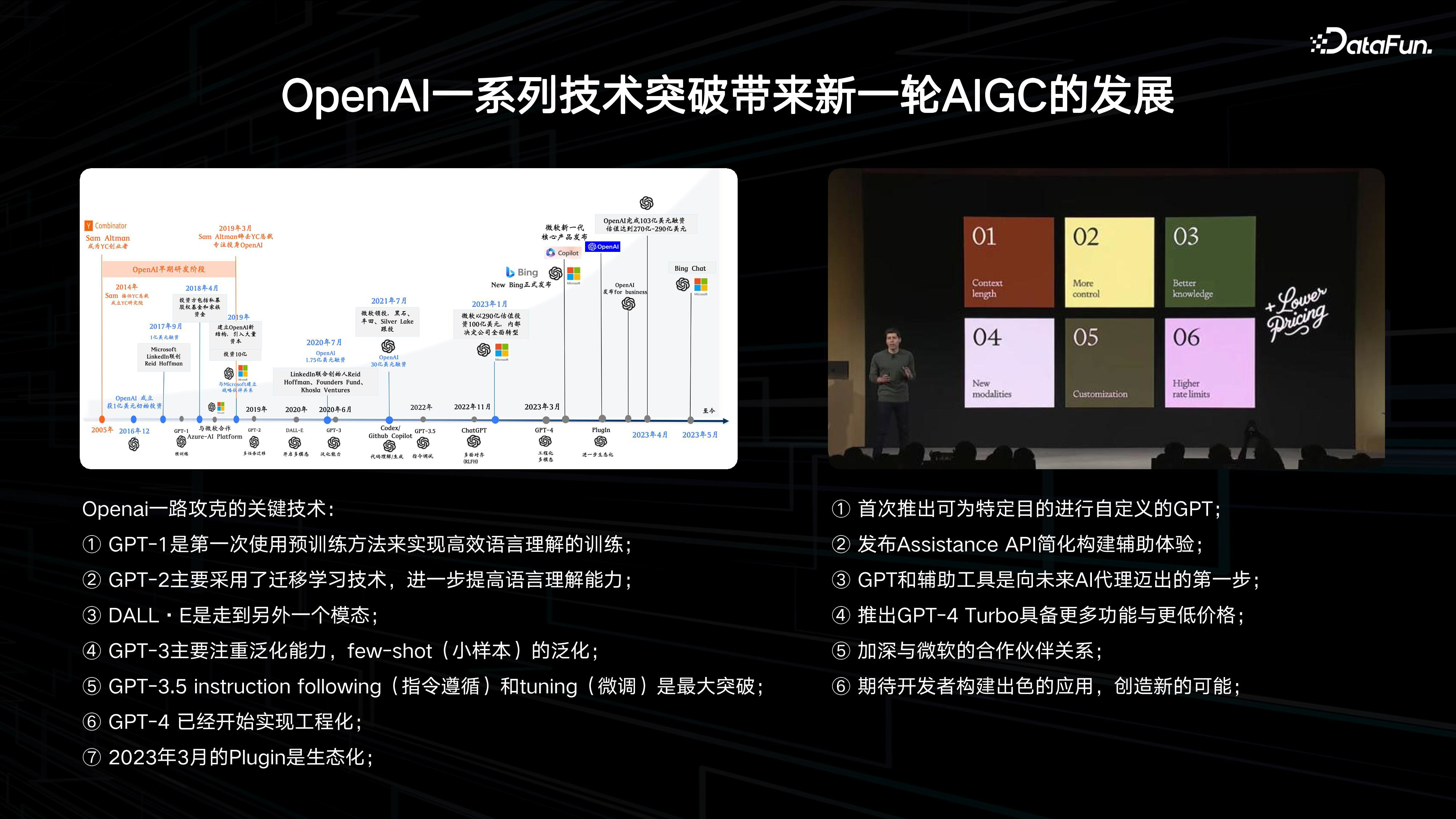
OpenAI 的一系列技术突破为大模型的发展提供了技术路线。从 GPT-3、3.5,到GPT-4,turbo,我们可以看到 OpenAI 在推进大语言模型方面的探索落地,图文结合的发展也越来越统一。他们也在构建自己的生态系统,将发布更多更强大的模型。这些结果让人们对未来充满期待。
3. 大模型应用正在渗透到各个行业

与此同时,国内厂商对大型模型的研究和投入也不断增长,大模型应用不断深入各个行业,每个月甚至每周都有不同版本的大模型出现,人们戏称当前的形势为“百模大战”。当然,我们也意识到与 OpenAI 相比,仍存在一定的差距,因此如何追赶 OpenAI 是每位从业者 & 公司思考的问题。
02
蓝心大模型训练过程跟挑战
接下来将介绍 vivo 蓝心大模型。
1. 蓝心大模型矩阵

vivo 大模型产品应用基于内部一个大模型矩阵,分别对应不同参数规模模型,包括1B、7B、70B、130B 和 175B。平衡模型任务效果、性能和推理成本,不同规模的模型去解决不同任务,比如目前端侧主要运用 1B 和 7B 的模型做定向任务,而在云端则使用规模更大的 70B 及以上参数规模模型做更通用能力和复杂任务。
蓝心大模型技术全景图

上图是我们对大模型应用的技术全景图。可以看到,蓝心大模型作为我们的模型基座,通过能力层输出到应用层,最终服务我们的用户,对于我们蓝心大模型,我们希望:
首先,“大而全”。大,是数据规模和模型参数要大。从而使得大模型具备丰富的知识量以及大家偶尔听到的智能涌现。"全"则体现在模型矩阵和模态支持上都要全,针对不同的应用场景、计算能力以及成本需求,覆盖十亿、百亿、千亿甚至是万亿各个参数级别,通过提供从小到大的选择来保证更好的产品体验。
其次,“算法强”。模型的算法是基于 transformer 的,需要多维度,矩阵式去压缩海量的知识,算法种类就非常多,有数据与图谱的算法,大模型无损压缩的算法,训练大模型和调优大模型的算法,还有建设训练集群和推理与部署的算法等等。我们需要强大的算法能力才能调优出比较好的模型效果。
第三,“真安全”。在数据收集、模型训练和模型审核流程中,严格遵循道德规范和人类正确价值观。并且对数据源进行严格筛选,确保模型训练数据的质量;同时提升模型的抗攻击能力,防止恶意攻击;最终采用完善的端云协同审核机制,确保大模型的输出结果,符合法律法规和伦理道德要求。在整个过程,保证用户都可以放心的使用大模型。
第四,“自进化”。当前,大模型还是处于一个需要不断进化的阶段,非常多的能力需要持续补强。比如,大模型的逻辑思维能力提升空间就非常大。同时,大模型数据的新鲜度非常重要,持续数据更新,才能保证用户得到的反馈,是最实时的信息。
最后,“广开源”。目前已开源 7B 模型,未来会开源更多在端社区运行的套件,为开发者提供工具,让他们可以在手机上运行自己的模型,我们也希望让更多的研究机构、企业和开发者能够获取优秀的大模型用于自己的研发。
2. 蓝心大模型优势
蓝心大模型面临着如下挑战:
(1)海量的数据
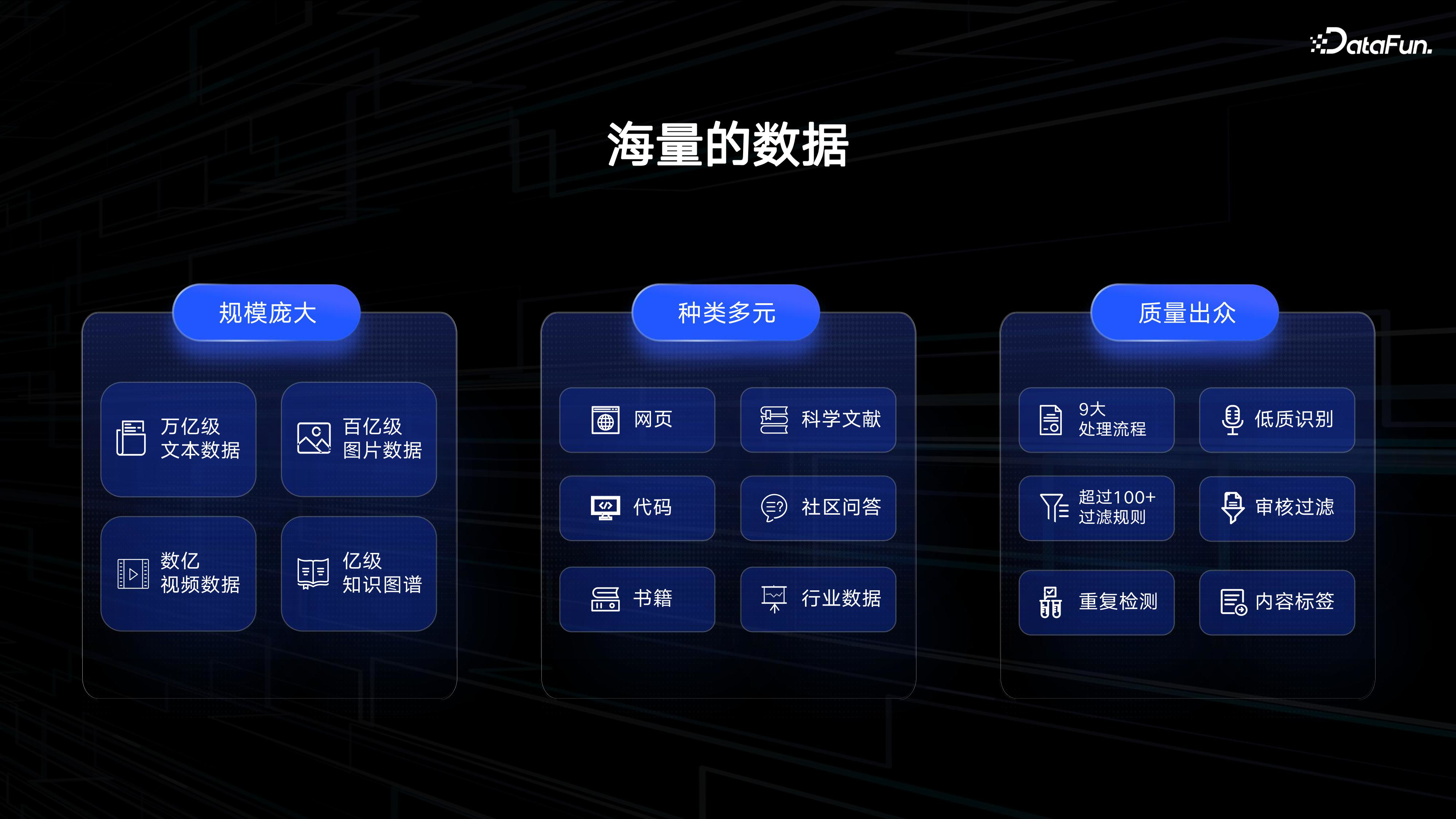
如何获取和处理这些海量数据是模型训练的基础。我们在 2018 年,成立了人工智能图谱研究院,致力于对人类知识进行图谱建设。目前,我们图片研究院已经积累了 13000T 的多种模态数据,以及 2800T 高质量中文文本数据,包括万亿级的文本数据和百亿级的图片数据。这些数据经过清洗和压缩后,仅用于百亿蓝心大模型的文本数据量就达到了 15TB,相当于 2.5 个中国国家图书馆的藏书量。这为蓝心大模型的训练和优化提供了强大的支持。
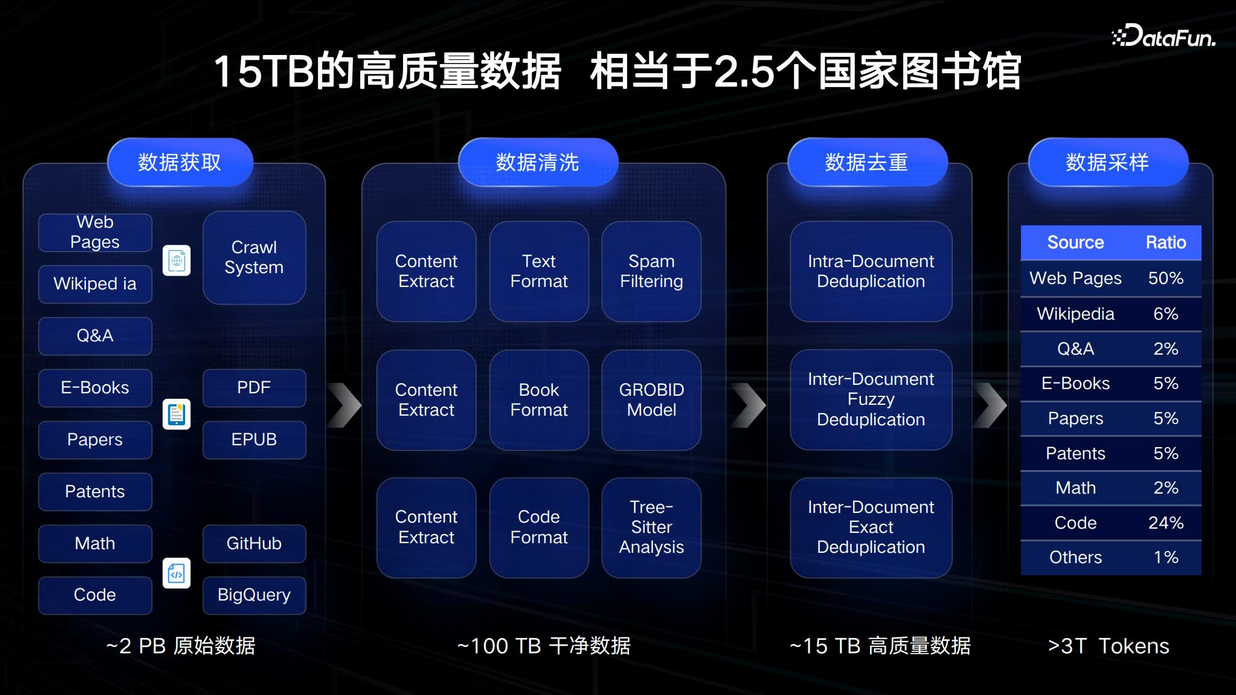
如何得到最终用于训练的高质量数据,我们拥有自己的数据处理流程,上图是处理的流程。首先,我们对不同来源的数据做了分类,比如网页、书籍、代码等。考虑到不同来源的数据类型、存储方式的不同,我们需要制定不同的清洗规则,比如去掉垃圾信息、格式化书本信息、抽取有效内容,这一步会大幅去掉低质数据。接着是数据去重,这一步非常重要,重复的数据会降低知识密度。我们知道网页信息之间是有大量重复,包括不同信息来源之间或多或少存在重新,我们需要对文档内部、文档之间进行去重和模糊去重,这里能够得到密度更高的训练语料;最后是数据采样,按照合适的比例采样出用于训练的数据,最终为模型训练提供了超过 3T + 的 token 数据。整个数据处理过程经历了获取、清洗、去重和采样等环节,以确保为模型训练提供高质量数据。
(2)高效算法
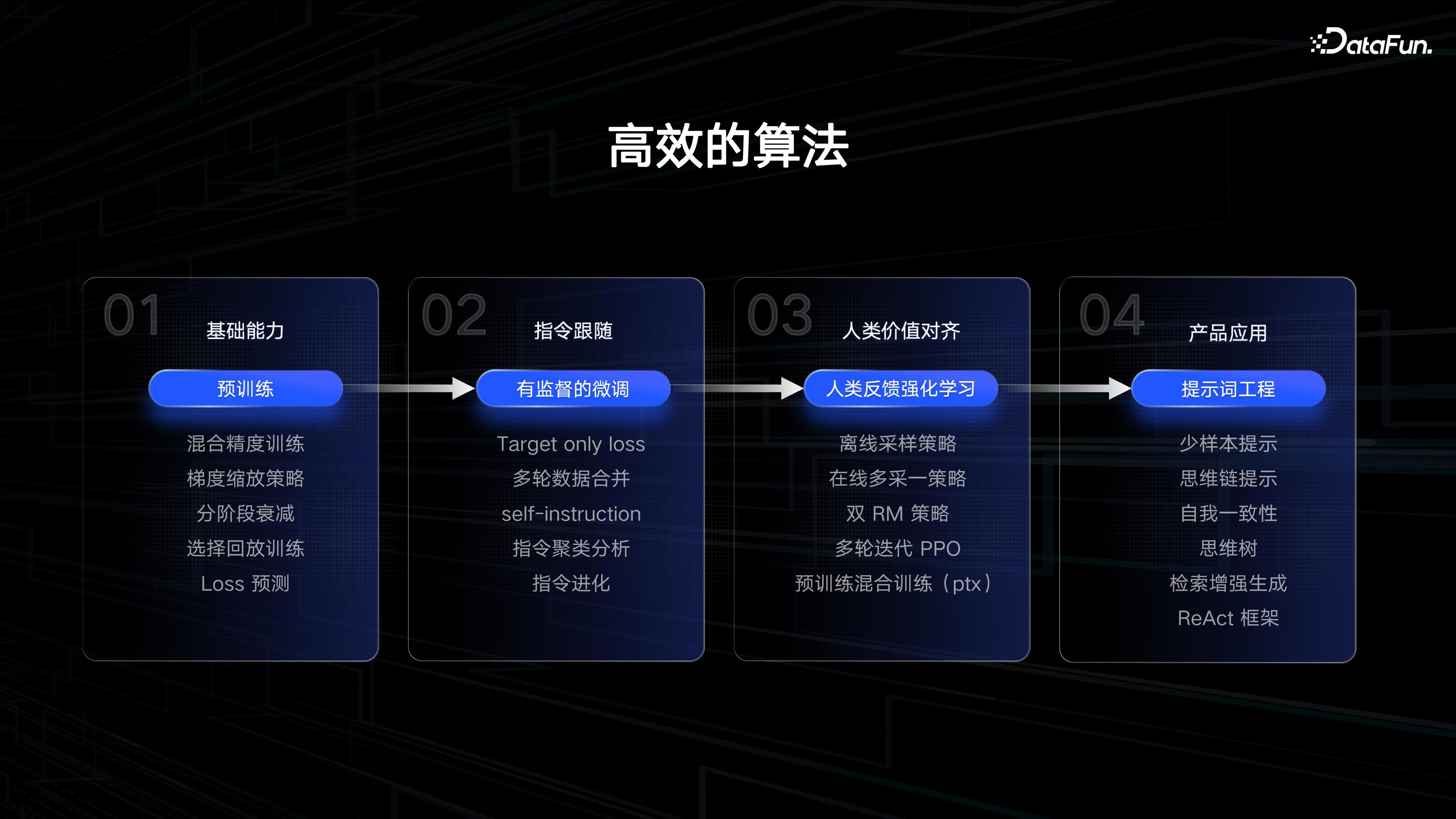
在数据处理之后,需要着手进行算法设计。目前,我们按照预训练、SFT(Self-training)、强化学习和 prompt 工程来分阶段设计我们的算法。这些方法为我们提供了一些经过验证是有效的的做法。
举例来说,对于预训练,我们采用了混合精度训练以及梯度缩放策略,因为这可以减少训练周期,训练周期较少会节省模型训练所需的时间和资源。选择回放训练能够让模型定向学会一类知识信息。Loss 预测确保在训练过程前对损失进行估计,以保证训练过程中的损失符合我们的预期,最终收敛较好的结果。
另外,我们对于微调采用了“target only loss”方法,并通过聚类分析对指令进行了适应性处理,以更好地确保模型的均衡性。
关于人类价值对齐阶段,我们采用了离线采样策略和双重奖励模型等策略,会在安全性上明显提升。
最终,会根据产品应用的需求设定相应的提示信息,以确保模型输出符合我们和用户的预期。我们也在尝试构建更好的提示工程,包括自我补全和检索增强等策略,以确保用户通过产品获得的结果是最优的。
(3)业务场景微调 效果对齐

这里要重点讲一下模型微调和效果对齐,如何准备最后一批数据以进行效果分析是非常关键的。在内部实验中,我们对数据做了几个关键的划分:
首先是多样性,我们希望数据具有多样性,更够激发模型更多的能力。
其次是均衡性,尤其是在模型需要支持更多任务的情况下,如何确保数据的均衡性是需要深入考虑的。我们通过实验和记录来验证和分析数据的聚类结果,以确保每次迭代都能保持微调效果,并在增加类别时保持效果提升。
第三是准确性。我们发现有时候 SFT 数据中存在不正确的数据,尽管模型仍能学到这些数据,但可能会影响模型的原有能力。因此,在提供数据之前,会进行明显的校验,包括模型自身对数据进行回答以进行校验。
最后是拓展性。指令构造是一个复杂的过程,我们根据指令复杂度逐步拓展数据,提高指令生产的效率。
通过保证数据的多样性、均衡性、准确性和拓展性,确保模型在不同场景下的适应性和稳定性。
(4)极致的端侧性能
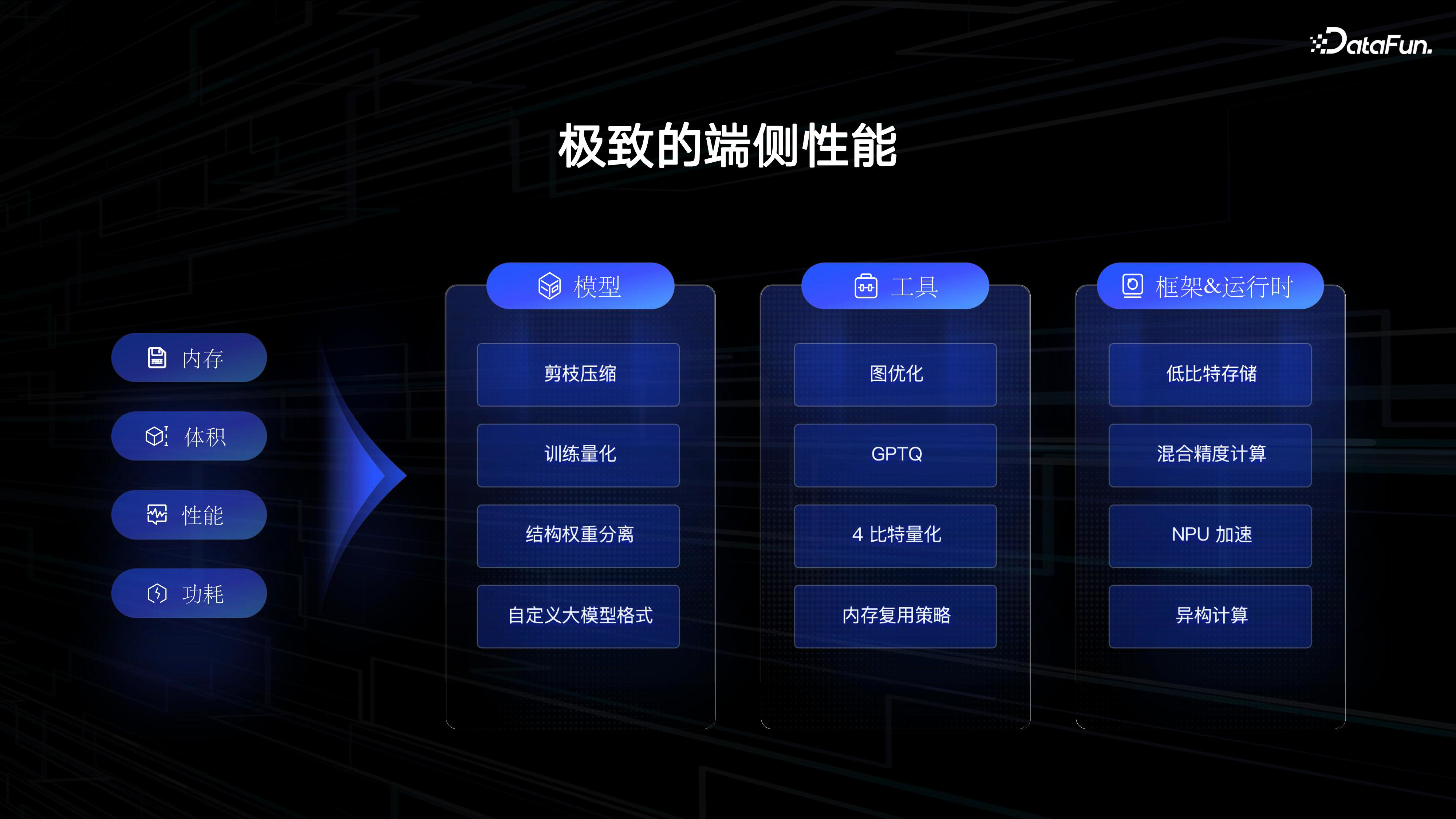
目前在手机端运行的是 1B 和 7B 的模型,我们也跑通了诶手机端 13B 的模型。实现更高的端侧性能,需要平衡内存、体积、性能和功耗。
我们从模型、工具和框架三个方面着手,为了保证在手机端运行 1B 和 7B 模型,我们进行了优化,包括模型压缩、量化,工具使用(如图优化、GPTQ 等),以及适配不同平台的框架(如低比特存储、混合精度计算等),最终能让 1B,7B 在手机终端运行上线产品。

我们进行了评估,例如在 1B 模型上进行手机端测试,极限能达到了 60 字每秒的性能正常我们做到人眼适合阅读的 20 字每秒,同时内存优化到 1B 需要 1.3G,7B 需要 3.8G。优化后的模型在手机端的流畅性得到了提升,这些努力旨在确保模型在手机上运行时的高性能。
(5)安全可控

安全在我们的工作中是首要考虑的事情,正确的价值取向是大模型的灵魂。我们建立了上百余名专业人员组成的审核团队,制定了 200+ 的安全审查机制,对模型的输出进行筛查和标注,并借此训练出高质量的奖励模型,保证为用户提供有价值的信息。通过我们内部大模型数据、训练、评测和应用等安全治理流程,最终能够让我们大模型安全符合标准,上线产品。
(6)模型效果
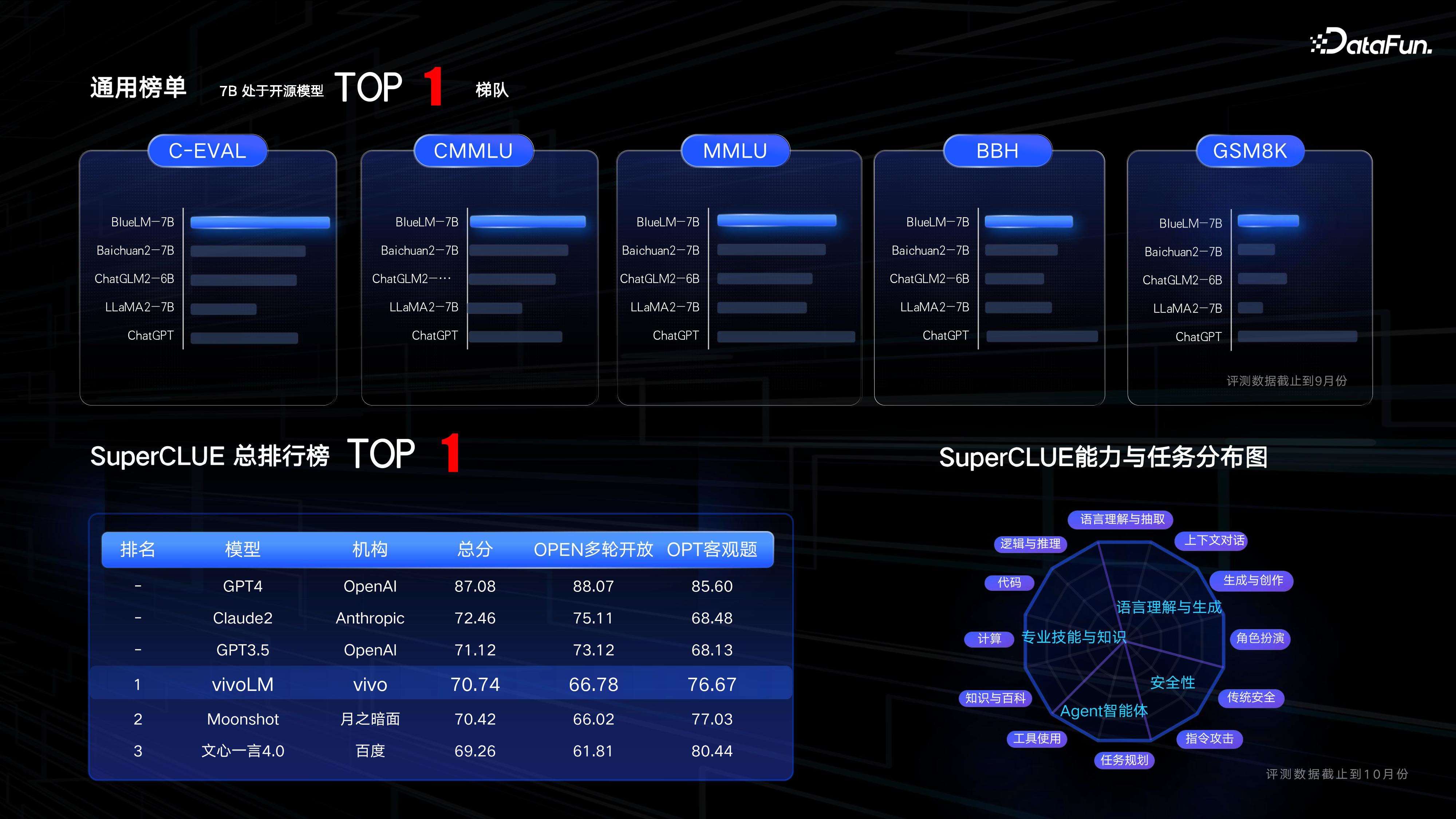
克服以上训练过程中调整,我们也训练出自己的模型,最终评测的结果是相当令人鼓舞的。我们对不同公开评测集做了评估,可以看到获得了比较领先的效果,我们开源的 7B 模型处于开源模型 top1 梯队。特别我们在 SuperCLUE 11 月份大模型通用能力综合评测中获得国内第一的成绩。蓝心大模型达到了国内领先的水平。
03
蓝心大模型产品落地
1. BlueLM 蓝心小 V

结合 BlueLM 大模型,我们在手机上推出蓝心小 v 产品,我们希望它是你的专属私人助理,让它拥有流畅的自然对话能力,强大的信息处理能力,和善解人意的洞察能力,深入理解用户从而更好地服务用户。目前在 vivo 的手机产品 X100 、iQOO12 和 S18 系列手机已上线蓝心小 v,大家可以去体验。

这里有一些具体的例子。比如,在工作场景中,用户可能需要编写市场分析报告,或者提出知识性问题,比如太阳系的奇特现象等。另外,在日常生活中,我们也考虑了烹饪场景,用户可能会询问如何做菜等常见问题,这些场景可能是用户使用频率较高的。

在产品方面,我们实现了一种更浅层次的交互形式,类似于漂浮框,用户可以随时唤醒小 V 进行提问。此外,还支持绘画功能,用户可以从相册中拖拽图片到悬浮球中,小 V 会自动弹出相关功能,例如照片去路人和风格转换。我们希望能在系统内提供的智能功能中便捷地交互。
2. 蓝心千询
另外,还发布了一个名为‘蓝心千询’的应用,可免费在安卓和 iOS 平台下载。蓝心千询提供云端综合的能力,能够实现智能语音交互、智能问答、图文创作等,在协助创作、生活百科,学习工作等各种场景帮助大家获取信息、知识和灵感。
3. BlueLM 的未来展望
目前,我们开源了 7B 模型,大家如果有合作需求,可以联系我们。目前,我们的团队专注于大模型训练到应用的全流程,希望通过我们的手机上的大模型,为用户带来更加惊喜极致的产品体验。

