基于AI的事件智能分析系统建设实践
一、背景
当前,随着虚拟化、云计算等新技术的广泛应用,企业数据中心内部IT基础设施规模成倍增长,计算机硬件和软件的规模不断的扩大,相应的计算机故障也频繁发生,一线运维人员迫切的需要更加专业、更加强大的运维工具。
在数据中心的日常运维工作中,一般是通过基础监控系统和应用监控系统,构建针对数据中心软硬件故障发现的机制。在这个过程中,各种软硬件发生异常时,指标项会超过预设的阈值,进而触发告警,通知运维专家进行排障。
事件智能分析系统即是为解决告警转故障并分析处置而生的系统。
二、总体架构
1、事件智能分析系统架构
事件智能分析系统打造“故障识别-故障分析-故障处置”全流程的故障处理体系,将运维专家的经验沉淀为数字化模型,当故障发生时,可以自动的对故障进行“识别-分析-处置”,进而缩短MTTR(平均故障修复时间,Mean Time To Repair)。
事件智能分析系统引入AI技术为系统各模块赋能,当运维专家没有手动建立故障模型时,AI会自动的为告警建立故障,并自动进行分析,进而给出分析方案,辅助运维专家对故障进行分析。AI赋能减轻了运维专家建模的工作量压力,同时也弥补了运维专家的经验盲区。
以下是事件智能分析系统的总体架构图:

其中蓝色部分是事件智能分析系统的功能模块,橙色部分是周边系统,提供相应的数据或接口。
2、和周边系统的关系
统一事件平台:Alert系统收集各监控系统(基础监控、应用监控、日志监控的)的告警,统一汇聚后,转化为统一的格式,发送到kafka;事件智能分析系统会从kafka系统中读取所有告警数据。
自动化平台:运维专家事前在自动化平台新建一些编排和脚本,作为处理故障的方法,当故障分析找到根因后,可以通过调用自动化平台接口实现处置任务编排和下发执行,最终实现自动处置的目的。
CMDB:在故障分析时,可使用CMDB中存储的对象实例属性和关系,将告警实例和处置实例进行逻辑关联;同时在展示告警对象周边对象的一些信息时,也需要关联对应的CMDB对象实例数据。
ITSM:提供变更单和事件单等工单数据,当发生故障时,需要使用这些工单数据进行分析。
运维大数据平台:大数据平台提供数据清洗工具,帮助事件智能分析平台对所需的数据进行清洗,同时提供海量数据存储的技术支持;大数据平台是事件智能分析所需数据的坚实基础,同时也为后续的AI分析提供了分析数据,包含了CMDB的对象数据、ITSM的工单数据、监控系统的指标数据和告警数据等。
三、功能详解
1、故障识别
故障识别的主要功能就是建立故障模型,其能够定义告警转化为故障的规则,同时对故障模型的定义,也是对故障的一次简单分类,比如会有CPU使用率高故障、内存使用率高故障、磁盘使用率高故障、网络延迟故障等,简单的说就是哪几个告警可以变成一个故障,告警和故障的数量关系既可以是1:1的,也可以是n:1的关系;只有形成了具体故障,才能方便后续的分析和处置。
告警格式化:
将从统一事件平台收到的告警,进行标准化处理,处理称为事件智能处置系统所需要的格式,部分字段需要查找配置管理的对象实例数据进行补充。
故障模型定义:
故障场景模型的定义主要包括基本信息、故障规则和分析决策等功能,具体描述如下:
1)基本信息包括故障名称、所属对象、故障类型和故障描述等信息;
2)故障规则可分为以下几类:
对告警匹配的关键字规则设定:告警的json字段中的摘要summary、级别level等字段都可以作为条件进行设定,而且可以将多个规则进行逻辑设定运算(规则的与或非计算);
时间规则:包括立刻执行(收到告警立刻生成故障实例)、等待固定时间窗口(初始告警开始后一段时间内的告警强制聚合故障实例)、等待滑动时间窗口(最后告警开始后一段时间内的告警强制聚合故障实例);
位置规则:包括同机器、同部署单元、同物理子系统,在指定范围内的满足条件的告警都聚合成一个故障实例。
3)关联指定的分析决策树,确定分析方案。
2、故障分析
故障分析是从关联数据展示、拓扑数据展示、分析决策树和知识库检索等多个方面对故障进行分析展示,为运维专家提供数据支撑,帮助其快速寻找故障根因并处置故障。其中分析决策树可以关联处置。
关联信息展示:
1)告警分析:告警对象所对应物理子系统和部署单元所关联的其他软硬件对象在最近48小时内的告警数据;
2)指标分析:告警对象所对应物理子系统和部署单元所关联的其他软硬件对象在故障前2小时内的指标数据;
3)变更分析:告警对象所对应系统在最近48小时内的变更工单记录,进行变革分析;
4)日志分析:对告警对象及周边对象的指定路径的应用日志和系统日志进行分析,并进行展示;
5)链路分析:以交易码为核心,将告警对象所涉及的交易码上下游链路数据进行分析,并进行展示;
拓扑结构展示:
以物理子系统为维度,将全系统所涉及的运维对象以树状的拓扑结构进行展示,同时对其中有告警的节点进行标红处理,以提示运维专家。
具体的例子如下:
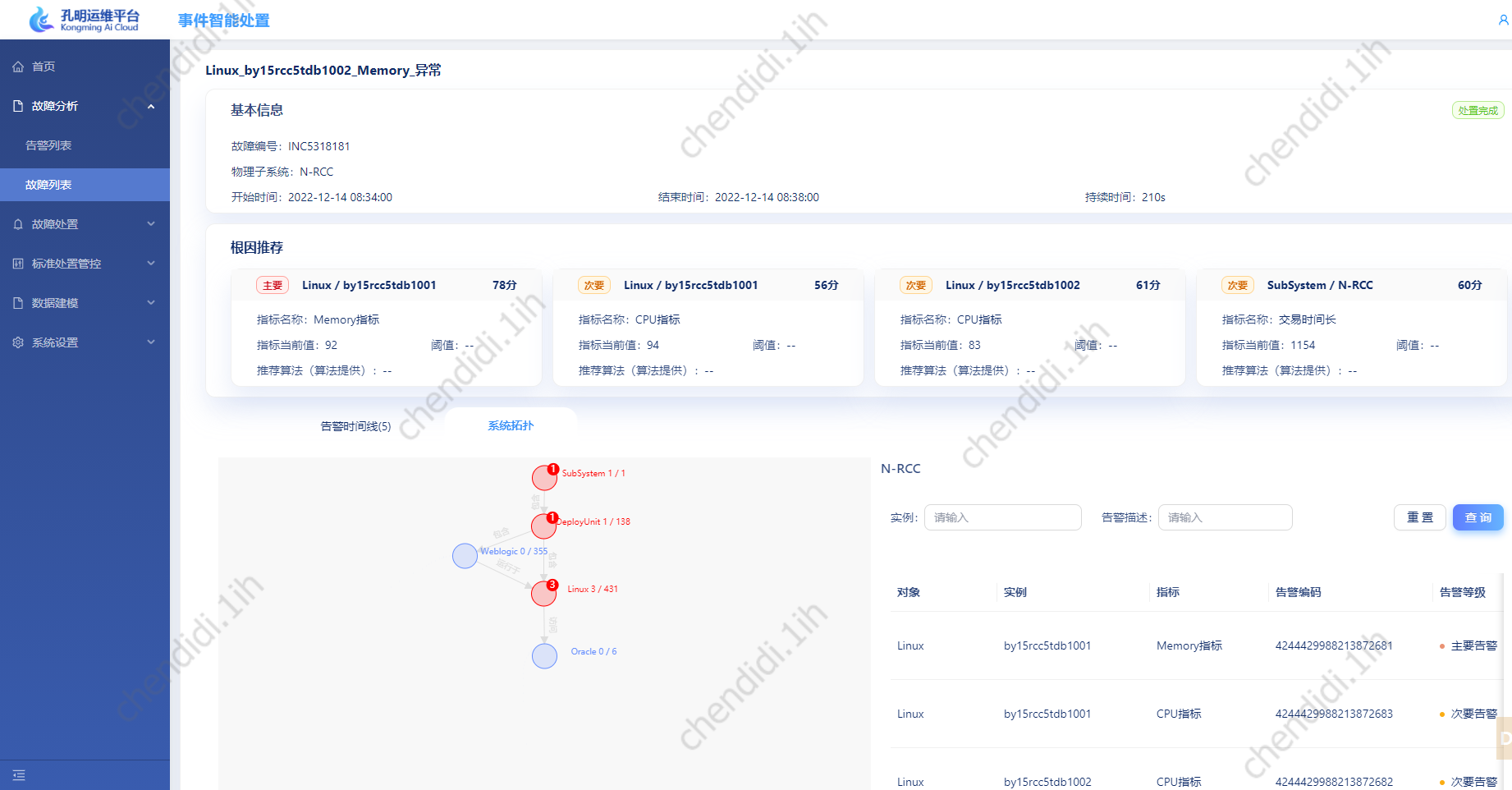
分析决策树:
以CMDB对象及关系、告警、指标、变更、日志和链路等数据为基础,融合到可自定义编辑的分析决策树中。
运维专家可以预设分析数据的顺序和判断标准,将运维经验以数字化模型的方式,沉淀到分析决策树中,当发生故障时,平台会根据预先设定的分析决策树对相关数据进行分析和判断,最终给出结果。
分析决策树最终的叶子节点可以关联处置,确保故障的“识别-分析-处置”全生命周期的自动化运行。
具体的样例如下:
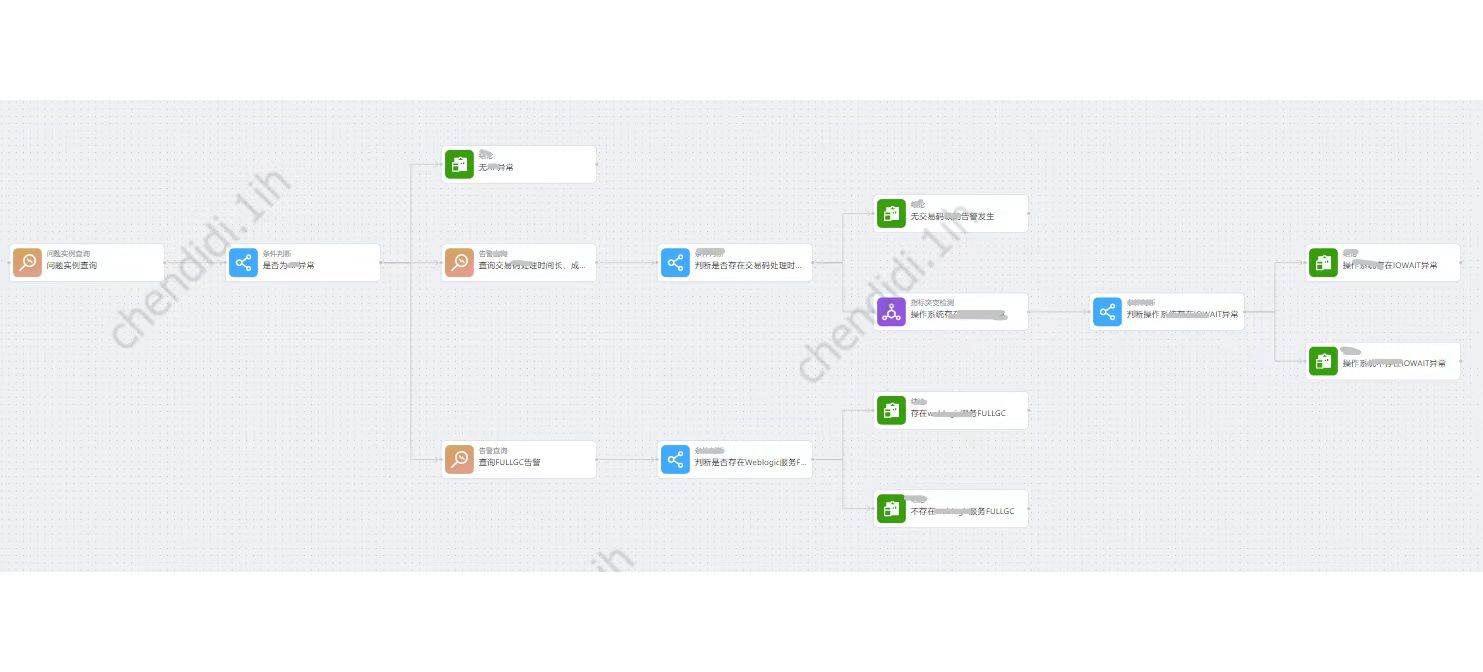
知识库检索:
数据中心以运维大数据平台上的数据为基础,构建知识库系统,主要收集应急预案、事件单处理全流程记录、运维专家经验总结等文本数据。
当发生故障时,会用故障的关键字去知识库进行检索(字符串匹配),返回对应的文本知识,作为专家经验返回。在AI赋能的章节会讲述使用文本分析的方式进行关联搜索,而不仅仅只是简单的字符串匹配。
3、故障处置
故障处置主要按事前定义好的处置模型进行处置,主要包括处置决策编排和处置操作,需依托于自动化平台实现处置任务的编排和执行。
1)处置编排:处置编排是一些列处置操作的有机结合,因为有些处置需要对运维对象进行先隔离再重启;将处置操作的脚本进行流程编辑,使得若干个操作脚本按照既定的顺序下发到具体实例机器并执行;
2)处置操作:对脚本(shell、python)进行封装,使其可以在实例机器上执行,也可以被处置编排调用;处置操作是处置的最小动作,比如tomcat的重启、隔离、熔断等脚本;
故障处置大都依据运维专家经验或应急预案文档,将其进行数字化沉淀为模型。
故障处置结束后,会根据流程记录处置相关记录,供后续回顾分析使用。
四、AI赋能
AI赋能是为了在故障的“识别-分析-处置”全流程中,尽量减少人工配置工作量,减轻运维专家工作压力,同时也可以弥补运维专家经验无法覆盖的部分,且可以在初始化阶段就覆盖历史上出现过的100%告警类型;总体原则是通过AI计算,在故障识别和分析的领域,通过自动建模、自动聚合、自动分析等方式,建设出故障模型和分析方案,给运维专家提供参考,但是确保最后的处置由运维专家做最后的判断和控制,保证算法做99%的工作,人工审核确保最后1%的工作。
1、自动建模
回顾三-1章节关于故障模型的定义,我们发现只要确定告警规则、时间规则和空间规则,同时确定分析决策树就可以建立一个故障模型,而时间规则和空间规则可以默认为最常见的立刻执行和同机器,分析决策树可以使用最常规健康检查。
因此建立故障模型,为同一类的故障建立模型,最核心的问题就是通过告警内容对故障进行分类,而我们使用告警内容的关键字来进行确定分类,进而建立某类型的故障模型。那么自动建模的问题,就退化为寻找告警的关键字并以此建立故障模型。
总体逻辑图如下:
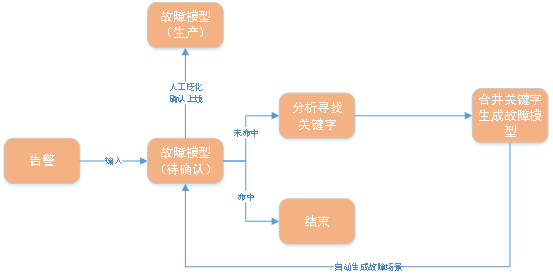
将历史告警和实时告警逐条输入到故障模型中,如果已经可以匹配现有的故障模型,则结束此条告警的处理;如果没有可以匹配的故障模型,则通过算法计算此条告警内容的关键字,并以此关键字构建故障模型,随后将新建成的故障模型加入到故障模型列表中。
运维专家可以通过人工确认的方式,将故障模型泛化上线。
此种自动建模的方式,有以下几个优点:
1)可以实时处理告警,实时进行故障建模,更新模型的速度非常快;
2)建模不依赖于运维专家经验,可以直接通过告警内容进行建模;
3)可以覆盖历史全部告警,且可以实时应对新型告警;
4)无需运维专家进行大量模型设置的工作,节省了人力;运维专家仅需做最后的人工确认,保证结果的前提下提升了效率;
总体来说,在待计算文档中频繁出现,但是在海量文档中出现概率不高的词汇,成为关键字的概率越大,拿部分告警内存进行处理的结果如下:
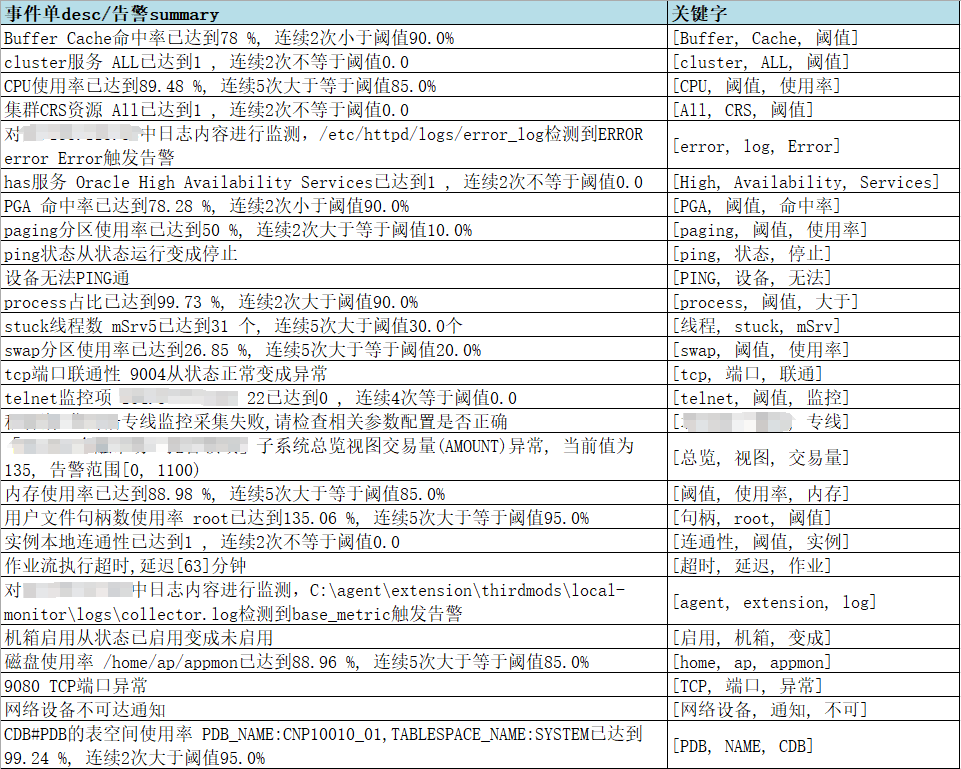
使用以上算法,使用部分告警内容进行计算后,得到的数据效果如下:
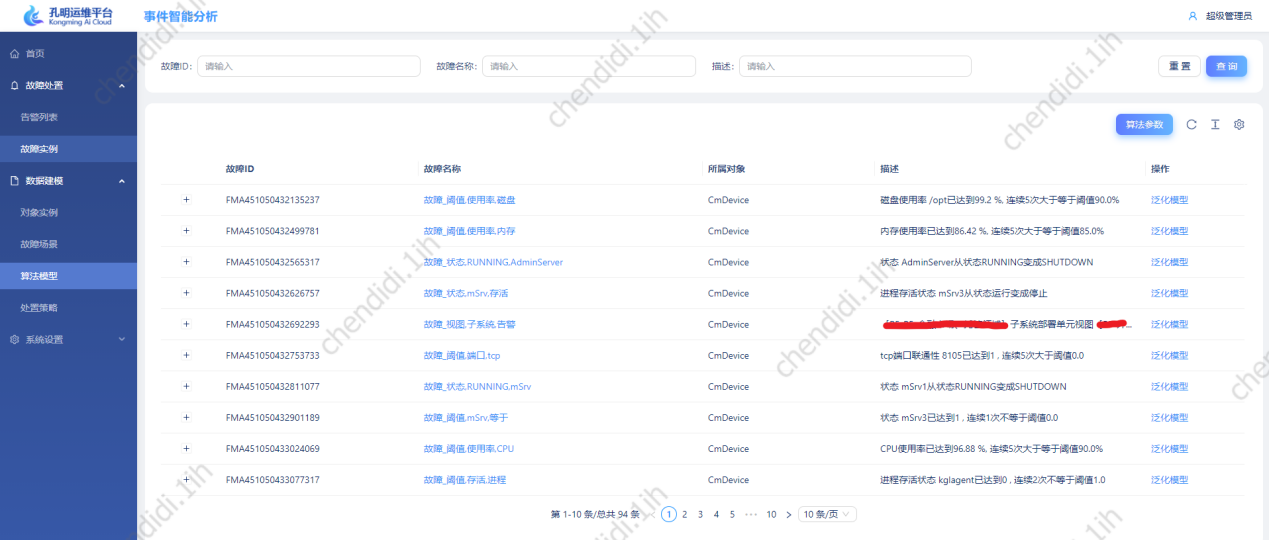
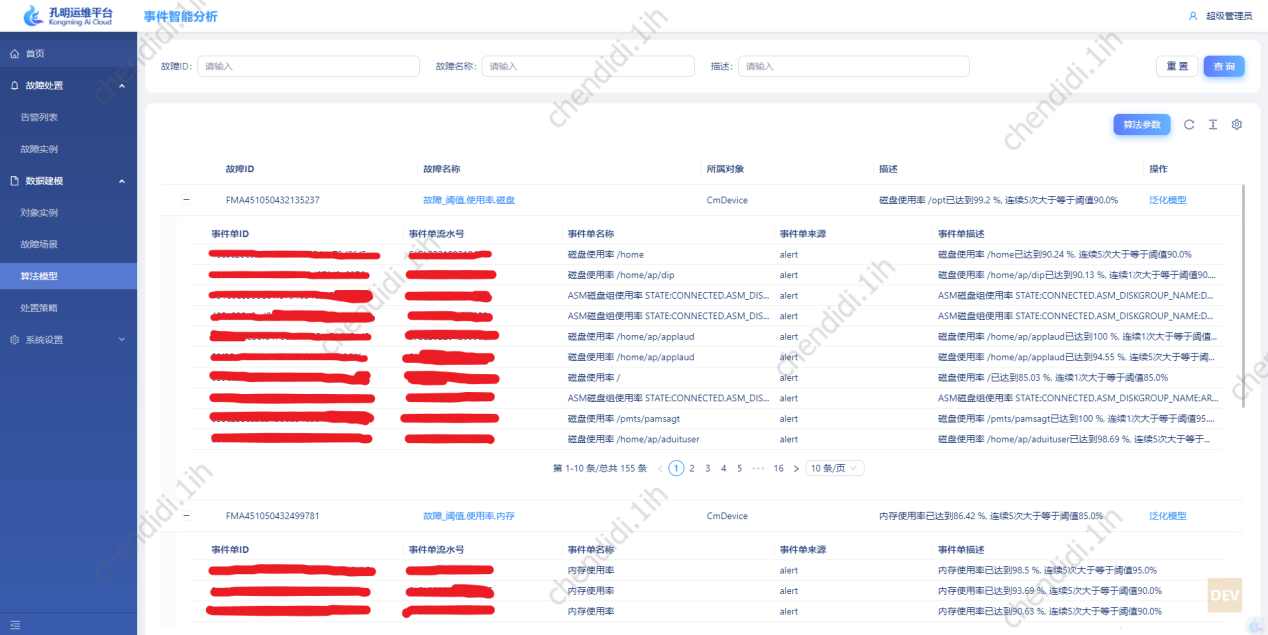
2、自动聚类故障
自谷歌发布BERT(Bidirectional Encoder Representations from Transformers)之后,在各文本任务中刷榜,取得了非常好的效果,因此使用其来计算文本相似性,主要是计算告警内容和故障描述之间的相似性。
现在构建我们的聚类算法,具体流程示意图如下:
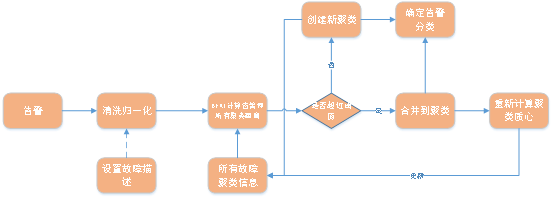
具体步骤如下:
1)如果有需要可以人工设置故障描述,作为故障聚类的锚定方向;本步骤并非必须的,如果没有,则直接跳过;
2)将告警信息进行清洗,去除一些无用的字符;
3)使用BERT模型,对告警摘要的文本内容和所有故障聚类的信息进行文本相似性计算,得到是否相似的结果(通过判断是否超过阈值来判断是否相似);
4)如果是相似的,则将此告警归属于此故障聚类;
5)如果距离值未超过阈值,则将此告警设为一个新的故障聚类;
6)第4,5步的结果更新到故障聚类信息列表中;
7)从第2步再处理下一个告警数据。
本算法可以将告警归属到不同类型的故障中,如果没有现成类型的故障,则自建一个类型,针对此不同故障类型的分类,可以有不同的分析方法。
本算法的优点如下:
1)通过历史和实时告警数据,无监督的自动做了故障分类,也无需建立故障模型,节省了人力;
2)针对实时告警,故障聚类的过程保证了可以做到实时在线更新,无需定期计算和更新模型;
3)告警自动生成或关联故障,可以进一步关联对应的应急预案,得到故障的分析方案和处置方法。
3、自动生成分析方案
回顾三-2章节故障分析,对故障的分析,主要集中在对故障节点及周边节点的信息进行展示,在分析决策树的设定上也需要较多的人工设置。
在AI赋能后,考虑以应急预案、告警详情和故障分析中的展示信息为提示词(prompt),利用现有效果非常好的大语言模型,自动的给出故障分析方案。
考虑到私有化部署问题,大语言模型可以考虑ChatGLM2、llama2等,具体实施阶段可以根据需要和硬件水平选择不同的大语言模型,在本文的方案描述中,统一使用LLM表示大语言模型,请读者注意区分。
主要流程示意图如下:
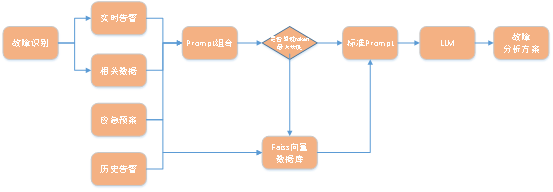
故障识别后,获得了对应的实时告警和展示的相关数据,结合应急预案数据,组成prompt组合,prompt提示词是为了在LLM大语言模型提问时,获得更好的输出效果。
同时将应急预案和历史告警数据,分批存入到faiss向量数据库,每批的文本量不超过LLM的token限制数量;当prompt组合提示词超过了LLM大语言模型时,会将prompt组合提示词向faiss向量数据库进行查询,获得向量最相似的文本;以这些不超过token长度限制的文本,向LLM查询,获得的返回即为故障分析方案(文本形式)。
具体效果参考下图:
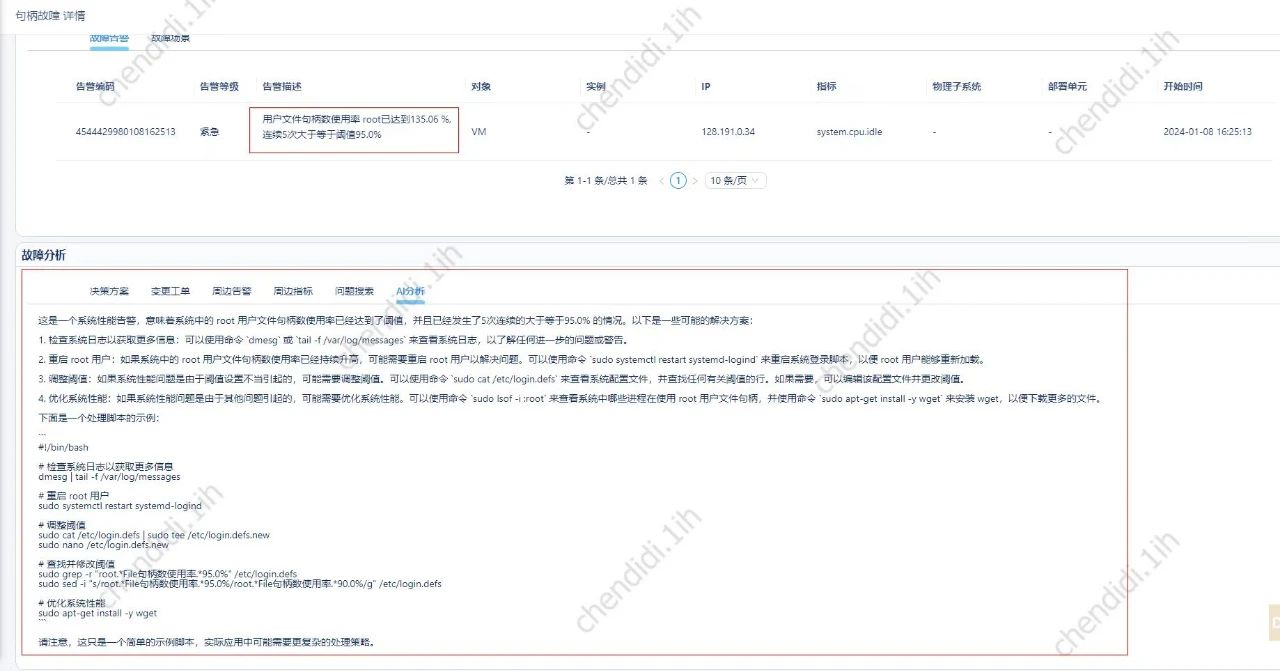
4、应急预案检索
应急预案作为行业内的必备手册,完善的记录了所有系统和所有运维对象对应故障的分析和处置步骤,是非常好的文本数据依靠,在本系统中会有很多地方都会使用到应急预案的内容。因此提供应急预案的检索能力十分必要,可以利用知识库系统作为应急预案的检索基数基础。
可以提供字符串匹配的文本检索,也可以提供文本分析后的关键字检索,同时也可以语义级的向量相似性检索,无论哪种方式都是为了获取系统所需要对应的应急预案文本。
以上若干种检索方式都可以利用前文中提到的技术手段进行处理,在此不再赘述。
五、结语
事件智能分析系统是为了帮助运维专家对各系统进行运维,因此提供了一系列可以建模的方法,让运维专家可以将运维经验沉淀为数字化的模型;当数据量(故障样本数据和运维相关数据)越来越大时,使用一些AI算法,可以减轻运维专家的工作量,辅助运维专家做分析决策;最终希望达到无需运维专家介入,也能够自动运维的境界,即对故障的“自发现,免维护”。

