一、前言
物流合约中心是京东物流合同管理的唯一入口。为商家提供合同的创建,盖章等能力,为不同业务条线提供合同的定制,归档,查询等功能。由于各个业务条线众多,为各个业务条线提供高可用查询能力是物流合约中心重中之重。同时计费系统在每个物流单结算时,都需要查询合约中心,确保商家签署的合同内容来保证计费的准确性。
二、业务场景
1.查询维度分析
从业务调用的来源来看,合同的大部分是计费系统在每个物流单计费的时候,需要调用合约中心来判断,该商家是否签署合同。

从业务调用的入参来看,绝大部分是多个条件来查询合同,但基本都是查询某个商家,或通过商家的某个属性(例如业务账号)来查询合同。
从调用的结果来看,40%的查询是没有结果的,其中绝大部分是因为商家没有签署过合同,导致查询为空。其余的查询结果,每次返回的数量较少,一般一个商家只有3到5个合同。
2.调用量分析
1)调用量
目前合同的调用量,大概是在每天2000W次。
一天的调用量统计:

2)调用时间
每天高峰期为上班时间,最高峰为4W/min。
一个月的调用量统计:

由上可以看出,合同每日的调用量比较平均,主要集中在9点到12点和13点到18点,也就是上班时间,整体调用量较高,基本不存在调用暴增的情况。
总体分析来看,合约中心的查询,调用量较高,且较平均,基本都是随机查询,也并不存在热点数据,其中无效查询占比较多,每次查询条件较多,返回数据量比不大。
三、方案设计
从整体业务场景分析来看,我们决定做三层防护来保证调用量的支撑,同时需要对数据一致性做好处理。第一层是布隆过滤器,来拦截绝大部分无效的请求。第二层是redis缓存数据,来保证各种查询条件的查询尽量命中redis。第三层是直接查询数据库的兜底方案。同时再保证数据一致性的问题,我们借助于广播mq来实现。
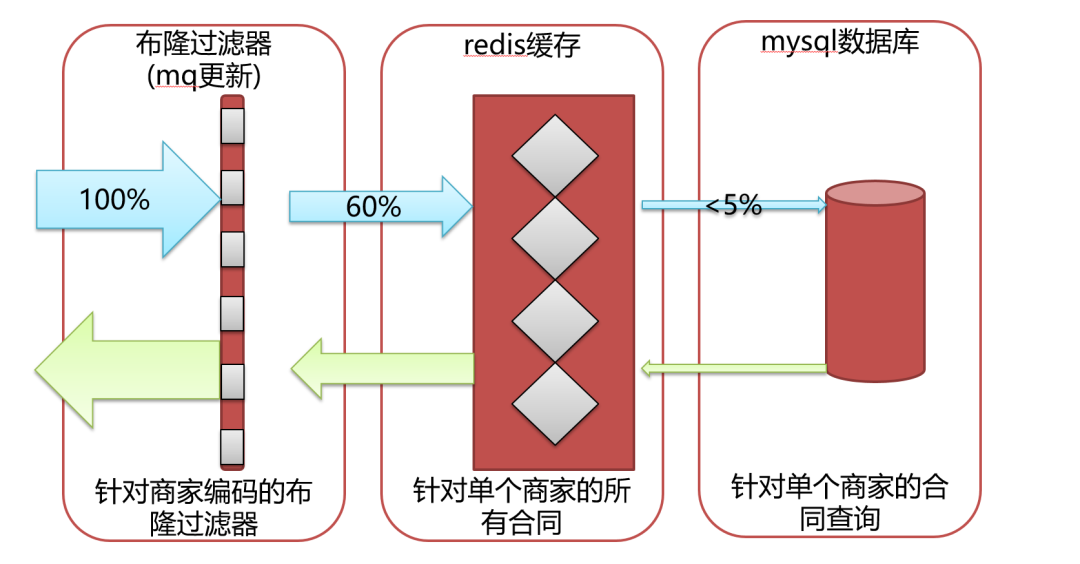
1.第一层防护
由于近一半的查询都是空,我们首先考虑这是缓存穿透的现象。
1)缓存穿透问题
缓存穿透(cache penetration)是用户访问的数据既不在缓存当中,也不在数据库中。出于容错的考虑,如果从底层数据库查询不到数据,则不写入缓存。这就导致每次请求都会到底层数据库进行查询,缓存也失去了意义。当高并发或有人利用不存在的Key频繁攻击时,数据库的压力骤增,甚至崩溃,这就是缓存穿透问题。
2)常规解决方案
缓存特定值
一般对于缓存穿透我们比较常规的做法就是,将不存在的key 设置一个固定值,比如说NULL,&&等等,在查询返回这个值的时候,我们应用就可以认为这是一个不存在的key,那我们应用就可以决定是否继续等待,还是继续访问,还是直接放弃,如果继续等待访问的话,设置一个轮询时间,再次请求,如果取到的值不再是我们预设的,那就代表已经有值了,从而避免了透传到数据库,从而把大量的类似请求挡在了缓存之中。
缓存特定值并同步更新
特定值做了缓存,那就意味着需要更多的内存存储空间。当存储层数据变化了,缓存层与存储层的数据会不一致。有人会说,这个问题,给key 加上一个过期时间不就可以了,确实,这样是最简单的,也能在一定程度上解决这两个问题,但是当并发比较高的时候(缓存并发),其实我是不建议使用缓存过期这个策略的,我更希望缓存一直存在;通过后台系统来更新缓存中的数据一致性的目的。
布隆过滤器
布隆过滤器的核心思想是这样的,它不保存实际的数据,而是在内存中建立一个定长的位图用0,1来标记对应数据是否存在系统;过程是将数据经过多个哈希函数计算出不同的哈希值,然后用哈希值对位图的长度进行取模,最后得到位图的下标位,然后在对应的下标位上进行标记;找数的时候也是一样,先通过多个哈希函数得到哈希值,然后哈希值与位图的长度进行取模得到多个下标。如果多个下标都被标记成1了,那么说明数据存在于系统,不过只要有一个下标为0那么就说明该数据肯定不存在于系统中。
在这里先通过一个示例介绍一下布隆过滤器的场景:
以ID查询文章为例,如果我们要知道数据库是否存在对应的文章,那么最简单的方式就是我们把所有数据库存在的ID都保存到缓存去,这个时候当请求过进入系统,先从这个缓存数据里判断系统是否存在对应的数据ID,如果不存在的话直接返回出去,避免请求进入到数据库层,存在的话再从获取文章的信息。但是这个不是最好的方式,因为当文章的数量很多很多的时候,那缓存中就需要存大量的文档id而且只能持续增长,所以我们得想一种方式来节省内存资源但又能请求都能命中缓存,这个就是布隆过滤器要做的。
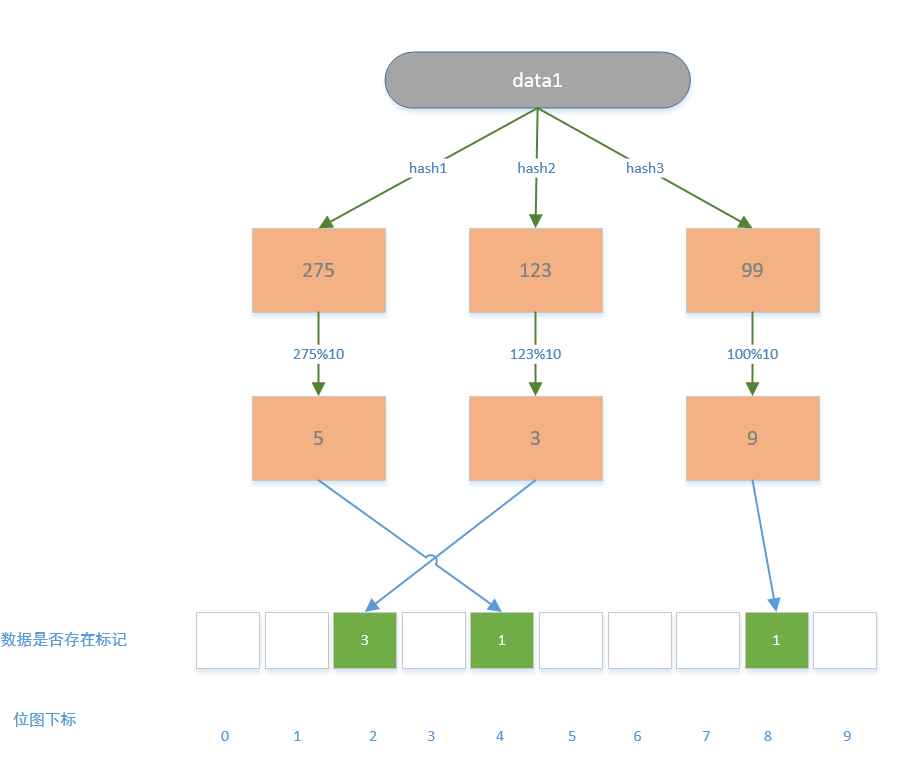
我们分析布隆过滤器的优缺点:
优点:
不需要存储数据,只用比特表示,因此在空间占用率上有巨大的优势;
检索效率高,插入和查询的时间复杂度都为 O(K)(K 表示哈希函数的个数);
哈希函数之间相互独立,可以在硬件指令层次并行计算,因此效率较高。
缺点:
存在不确定的因素,无法判断一个元素是否一定存在,所以不适合要求 100% 准确率的场景;
只能插入和查询元素,不能删除元素。
布隆过滤器分析:面对优点,完全符合我们的诉求,针对缺点1,会有极少的数据穿透对系统来说并无压力。针对缺点2,合同的数据,本来就是不可删除的。如果合同过期,我们可以查出单个商家的所有合同,从合同的结束时间来判断合同是否有效,并不需要去删除布隆过滤器里的元素。
考虑到调用redis布隆过滤器,会走一次网络,而我们的查询近一半都是无效查询,我们决定使用本地布隆过滤器,这样就可以减少一次网络请求。但是如果是本地布隆过滤器,在更新时,就需要对所有机器的本地布隆过滤器更新,我们监听合同的状态来更新,通过mq的广播模式,来对布隆过滤器插入元素,这样就做到了所有机器上的布隆过滤器统一元素插入。
2.第二层防护
面对高并发,我们首先想到的是缓存。
引入缓存,我们就要考虑缓存穿透,缓存击穿,缓存雪崩的三大问题。
其中缓存穿透,我们已在第一层防护中处理,这里只解决缓存击穿,缓存雪崩的问题。
1)缓存击穿
缓存雪崩是指大量热点key同时失效的情况,如果是单个热点key,在不停的扛着大并发,在这个key失效的瞬间,持续的大并发请求就会击破缓存,直接请求到数据库,好像蛮力击穿一样。这种情况就是缓存击穿(Cache Breakdown)。
常规解决方案:
缓存失效分散
这个问题其实比较好解决,就是在设置缓存的时效时间的时候增加一个随机值,例如增加一个1-3分钟的随机,将失效时间分散开,降低集体失效的概率;把过期时间控制在系统低流量的时间段,比如凌晨三四点,避过流量的高峰期。
加锁
加锁,就是在查询请求未命中缓存时,查询数据库操作前进行加锁,加锁后后面的请求就会阻塞,避免了大量的请求集中进入到数据库查询数据。
永久不失效
我们可以不设置过期时间来保证缓存永远不会失效,然后通过后台的线程来定时把最新的数据同步到缓存里去
解决方案:使用分布式锁,针对同一个商家,只让一个线程构建缓存,其他线程等待构建缓存执行完毕,重新从缓存中获取数据。
2)缓存雪崩
当缓存中大量热点缓存采用了相同的实效时间,就会导致缓存在某一个时刻同时实效,请求全部转发到数据库,从而导致数据库压力骤增,甚至宕机。从而形成一系列的连锁反应,造成系统崩溃等情况,这就是缓存雪崩(Cache Avalanche)。
解决方案:缓存雪崩的解决方案是将key的过期设置为固定时间范围内的一个随机数,让key均匀的失效即可。
我们考虑使用redis缓存,因为每次查询的条件都不一样,返回的结果数据又比较少,我们考虑限制查询都必须有一个固定的查询条件,商家编码。如果查询条件中没有查商家编码,我们可以通过商家名称,商家业务账号这些条件来反查商家编码。
这样我们就可以缓存单个商家编码的所有合同,然后再通过代码使用filter对其他查询条件做支持,避免不同的查询条件都去缓存数据而引发的缓存数据更新,缓存数据淘汰以及缓存数据一致等问题。
同时只缓存单个商家编码的所有合同,缓存的数据量也是可控,每个缓存的大小也可控,基本不会出现redis大key的问题。
引入缓存,我们就要考虑缓存数据一致性的问题。
有关缓存一致性问题,可自行百度,这个就不再叙述。
如图所示,对于商家编码维度的缓存数据,我们通过监听合同的状态,使用mq广播来删除对应商家的缓存,从而避免出现缓存和数据一致性的相关问题。
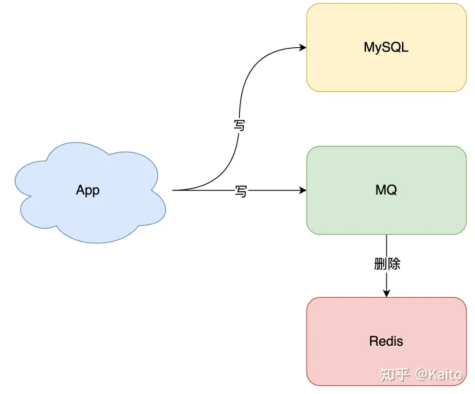
3.第三层防护
第三层防护,自然是数据库,如果有查询经过了第一层和第二层,那我们需要直接查询数据库来返回结果,同时,我们对直接调用到数据库的线程进行监控。

为避免一些未知的查询大量查询涌入,导致数据库调用保证的问题,尤其是大促时,我们可以提前对数据库里的所有商家合同进行提前缓存。在缓存时,为避免缓存雪崩问题,我们将key的过期设置为固定时间范围内的一个随机数,让key均匀的失效。
同时,为避免依然存在意外的情况,有大量查询涌入。我们通过ducc开关控制数据库的查询,如调用量太高导致无法支撑,则直接关闭数据库的调用,保证数据库不会直接宕机导致整个业务不可用。
四、总结
本文主要分析了面对高并发调用的调用场景设计及的技术方案,在引入缓存的同时,也要考虑实际的调用入参及结果,面对增加的网络请求,是否可以进一步减少。面对redis缓存,是否可以通过一些手段避免所有查询条件都需要缓存,带来的缓存爆炸,缓存淘汰策略等问题,以及解决缓存与数据一致等一系列问题。
本方案是根据具体的查询业务场景设计具体的技术方案,针对不同的业务场景,对应的技术方案也是不一样的。

