货拉拉大数据异构计算实践
背景
在公司控本增效目标下,除数据治理、资源超卖等常规降本手段外,货拉拉大数据考虑通过替换生产计算节点机型进一步降低计算成本。
作为 x86 机型的替换,ARM 机型具备高性能和相对更低成本的特点,单机能降低15%左右成本,满足我们对于降本的要求,且云厂商对于 ARM 机型也提供足够支持,ARM 生态也在逐渐完善。尽管通过业界调研,我们发现在大数据场景使用 ARM 机型的公司并不多,我们考虑可以逐步探索,把 ARM 机型逐渐应用到大数据生产环境。
货拉拉大数据探索使用 ARM 机型作为计算节点才刚刚开始,其中也遇到了一些问题,以下内容描述我们在探索过程中的一些实践。
ARM 介绍
ARM(Advanced RISC Machine)是一种基于 RISC(精简指令集)的处理器架构,由 ARM Holdings 公司负责设计,并将芯片设计成果授权给其他企业来生产。
ARM CPU 的架构以及指令集和 x86 不同,意味着类似 C、C++ 这种面向特定架构编译的程序无法直接跨平台运行,需要进行重新编译适配工作。
ARM 机器性能
在把 ARM 机器应用于生产之前,我们通过 Sysbench 工具对 ARM CPU 进行了压测。压测结果如下:
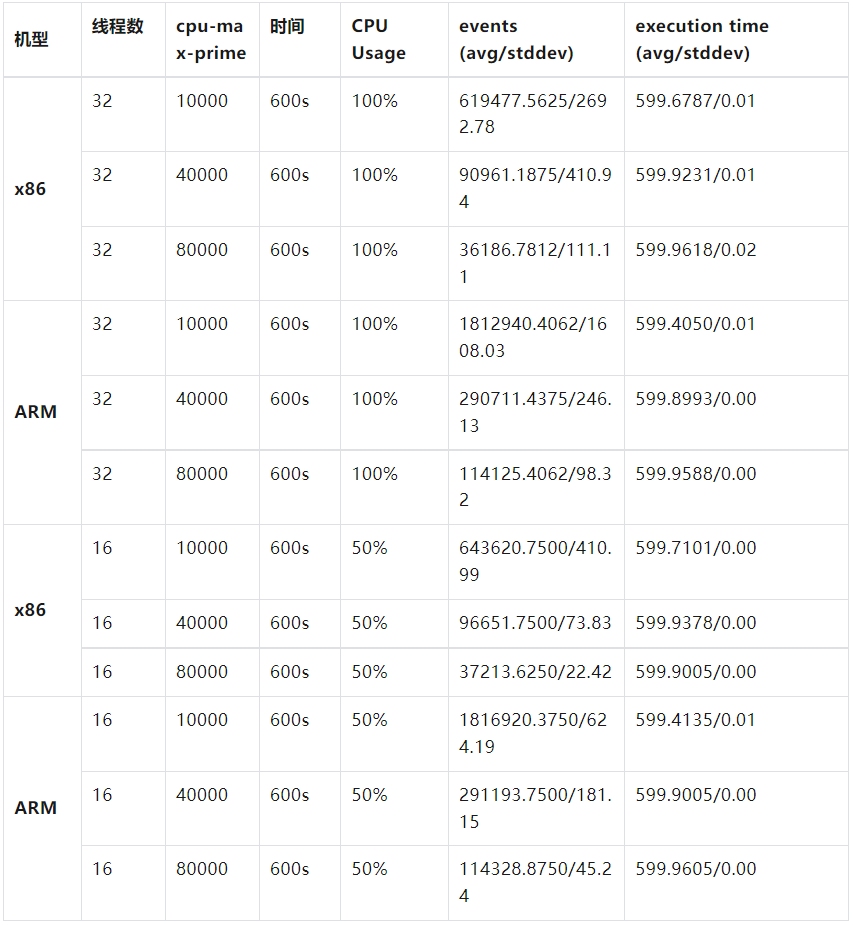
可以看到在相同压测条件下,ARM 处理的事件数是 x86 的3倍左右,显示 ARM CPU 在性能上无劣势。这给了我们在生产应用 ARM 机器的信心。
实践
货拉拉大数据对 ARM 的实践从离线场景开始,为了应用 ARM 机型,我们对 YARN、Tez/MR引擎、安全和运维基础组件进行了适配改造。
组件适配改造
1. YARN适配
YARN (Yet Another Resource Negotiator) 是 Hadoop 集群资源管理调度系统,在货拉拉主要承载着国内外离线、实时计算场景。同时社区 Hadoop 对 ARM 库支持已相对成熟,在适配中主要解决依赖 Jar 包中带有 naitive so 库文件和机器本地 native 库依赖。
依赖jar/native库适配

2. Tez/MR 引擎适配
目前我们离线计算主要是使用 Tez 引擎以及少部分的MR,在适配过程中主要解决:
• 引擎自身 native 库依赖,需要适配ARM编译
• Tez/MR依赖 Jar 包自带 native so 库文件
• UDF中 Jar 依赖 native so 库文件
依赖jar/native库适配
Tez/MR主要是Java语言开发,具备跨系统平台部署能力,在适配过程中主要解决压缩、解压缩以及用户 UDF 中依赖Jar 包 native so 库文件适配。

下面,将以 snappy-java-1.0.5.jar 和 crffpp-java-1.0.2.jar 分别介绍带 .so 库文件 Jar 适配过程:
Java Jar 包带 .so 库文件适配
在Java程序中通过Java Native Interface (JNI) 调用一些本地方法时,这些方法一般在 .so 库文件中实现。由于.so库文件是平台相关的,因此同一个Java程序在不同的平台上运行需要不同的 .so 库文件。
已支持 ARM .so 库文件
通常像 snappy-java 这类 Jar 是支持跨平台运行的,在Java程序中会根据不同系统架构通过 System.loadLibrary() 加载对应 .so 库文件,然后通过 JNI 在JVM中调用这些 .so 库文件中本地方法,我们一般升级到支持ARM机型 so 库文件稳定版本即可完成。
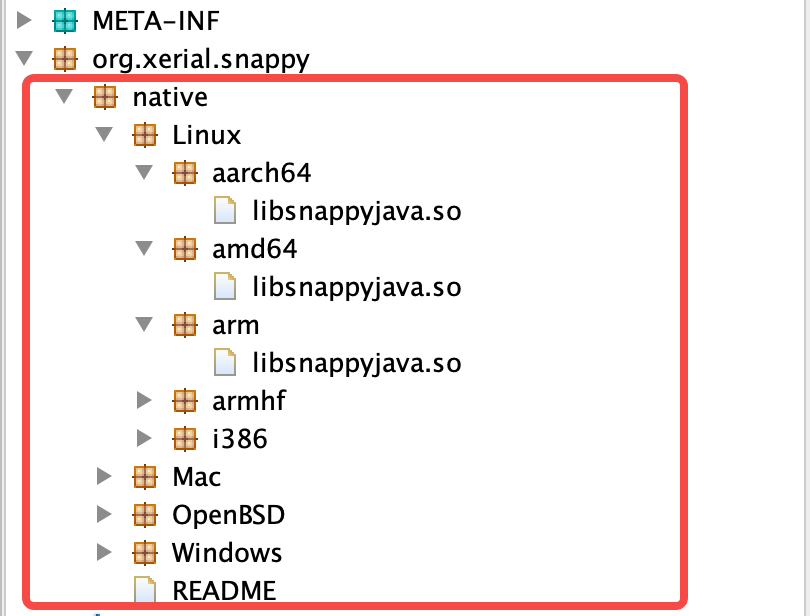
已兼容 ARM 机型 .so 库文件
不支持 ARM .so库文件
像 crffpp-java 这类 Jar 还不支持在 ARM 平台运行,需要我们下载对应源码交叉编译出对应 ARM 架构的 .so 库文件。
编译步骤:
1. 获取对应 .so 库的源代码
2. 在ARM机器上配置编译环境
3. 修改 Makefile 或者 CMakeLists.txt 指定 aarch64 架构
4. 使用make或cmake命令来编译源代码生成 aarch64 版本的 .so 库文件
5. 将新生成的 .so 库文件添加到源码 native 下并重新打包
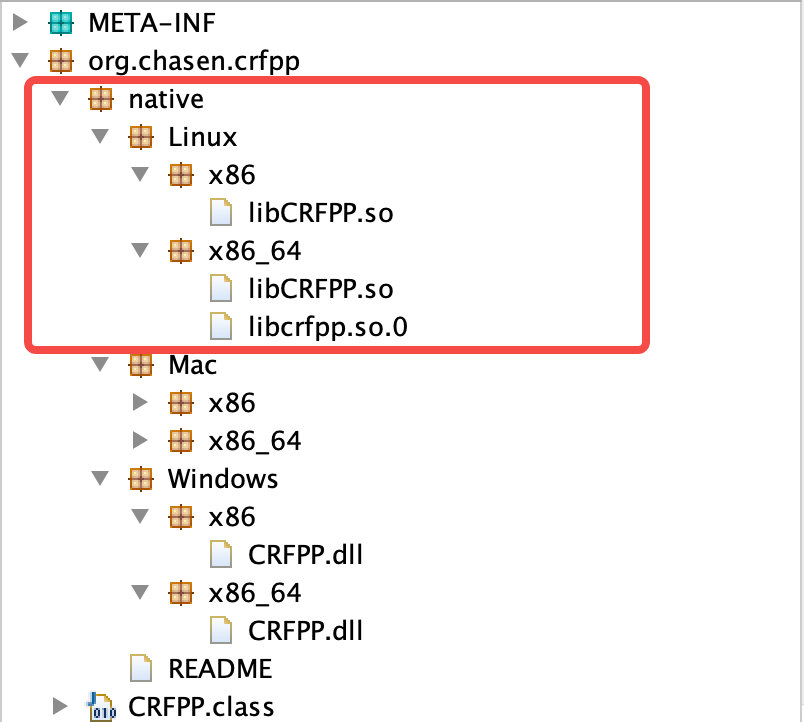
没有兼容ARM机型 .so 库文件
3. 基础运维和安全组件适配
• 主机安全组件、基础运维组件需适配 ARM机型
• 安全组件 OS Natvie相关 C++、C、go 应用层代码兼容ARM
上线效果
ARM机型在离线集群上线后,通过对公司核心链路产出时间监控和观察,发现没有明显延迟,反而有提升。同时 CPU 使用率也比较稳定,无明显的性能问题。
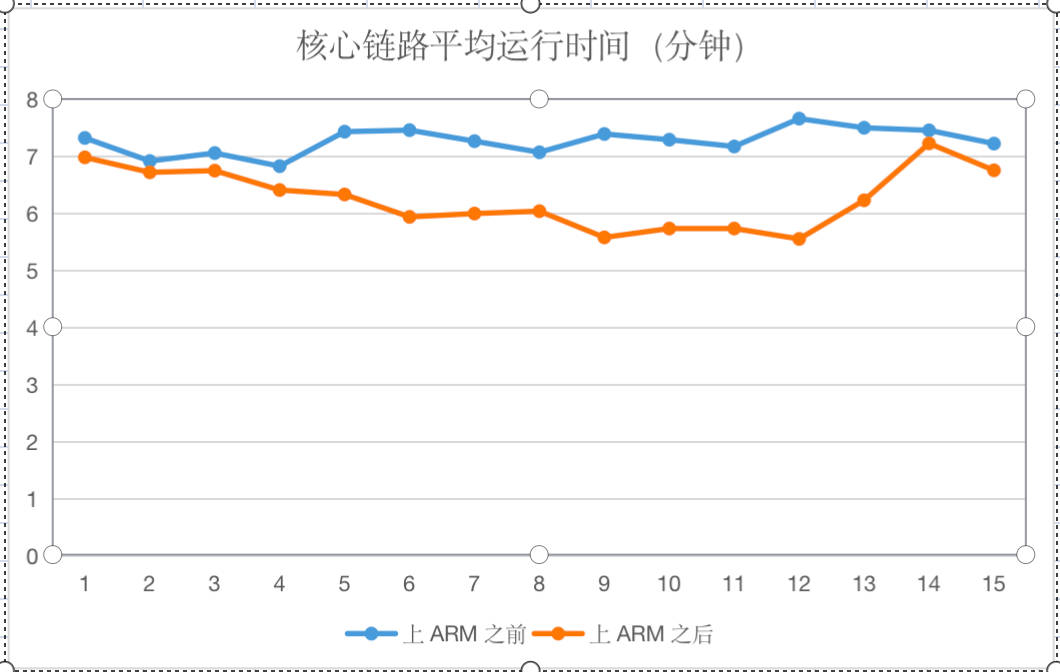
上线前后15天核心链路任务运行平均运行时间变化
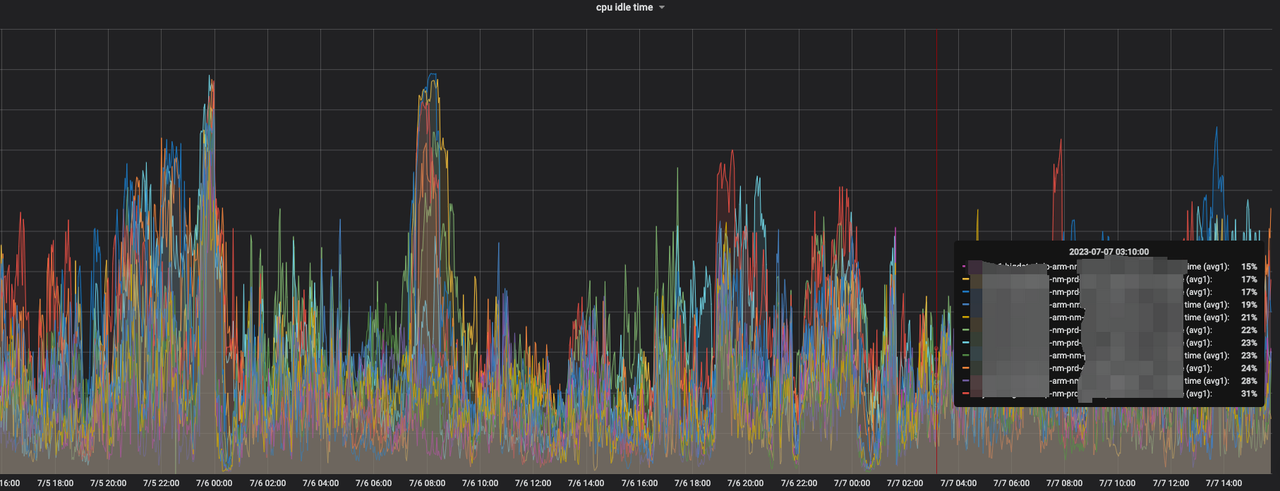
ARM 和 x86 CPU 使用率 Grafana
生产问题
除了上面的兼容问题外,在使用 OpenJDK java-1.8.0-openjdk-1.8.0.252 灰度上线 ARM 机器过程中遇见严重 JDK 性能问题。
用户相同的一段 SQL 在 Map 阶段跑在 ARM 机型和 x86 机型上的 Task 在处理数据相近情况下,ARM上的耗时是 x86 的 10 倍,导致下游链路延迟 1 个小时左右。
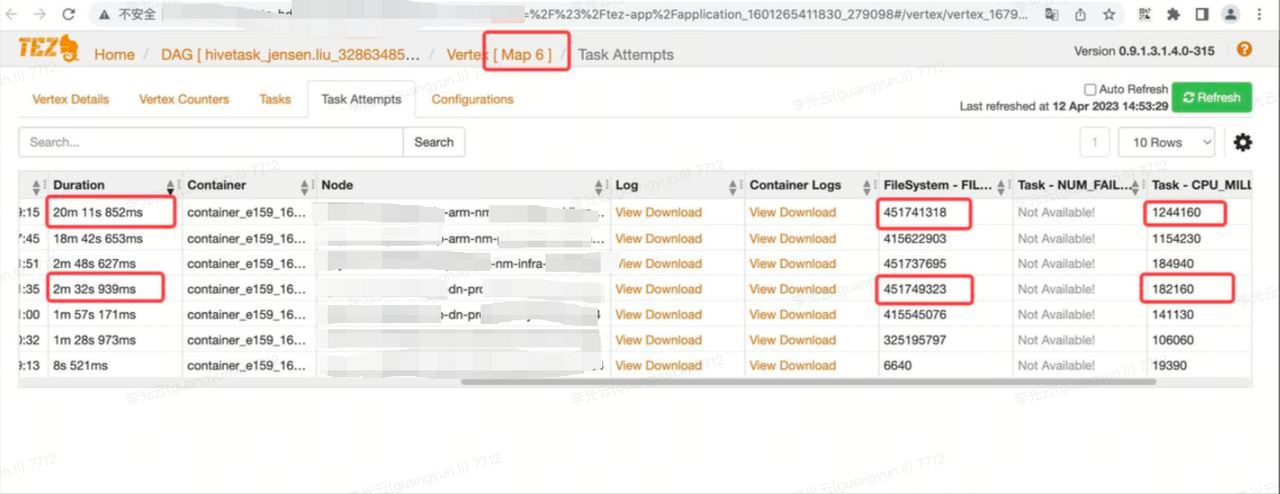
排查过程
通过分析用户 SQL 逻辑并不是很复杂主要使用窗口函数对数据分区排序再写到对应的 Hive 表中,查看ARM机型CPU使用率、IO、平均负载监控均没有发现异常,排除了ARM机型影响。
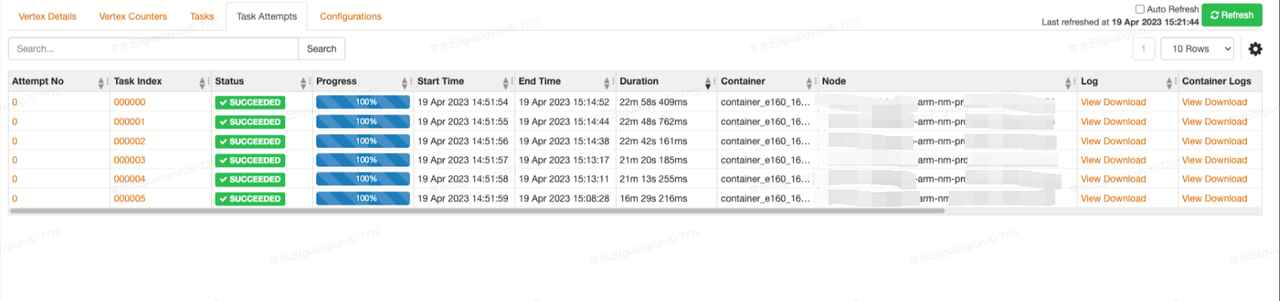
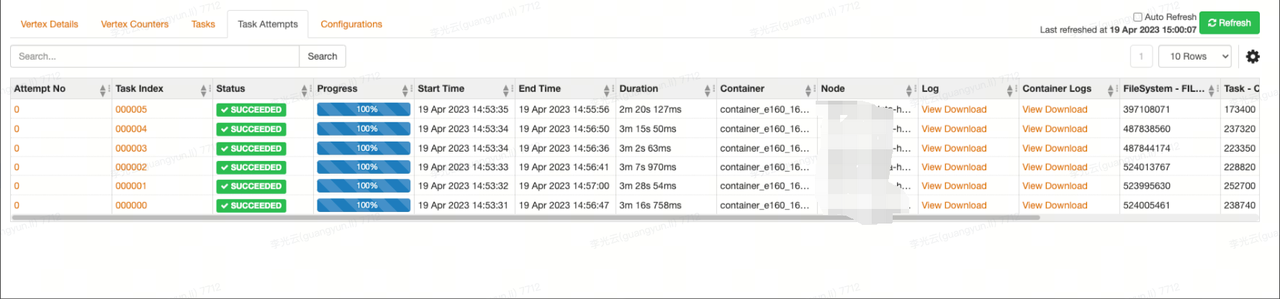
1.隔离 ARM、x86机型分别单独执行用户SQL,现象复现。
ARM单独执行结果:
x86执行结果:
2.使用 jstack 打印 ARM 节点上执行Map相关 Task container 堆栈发现都卡在开窗函数
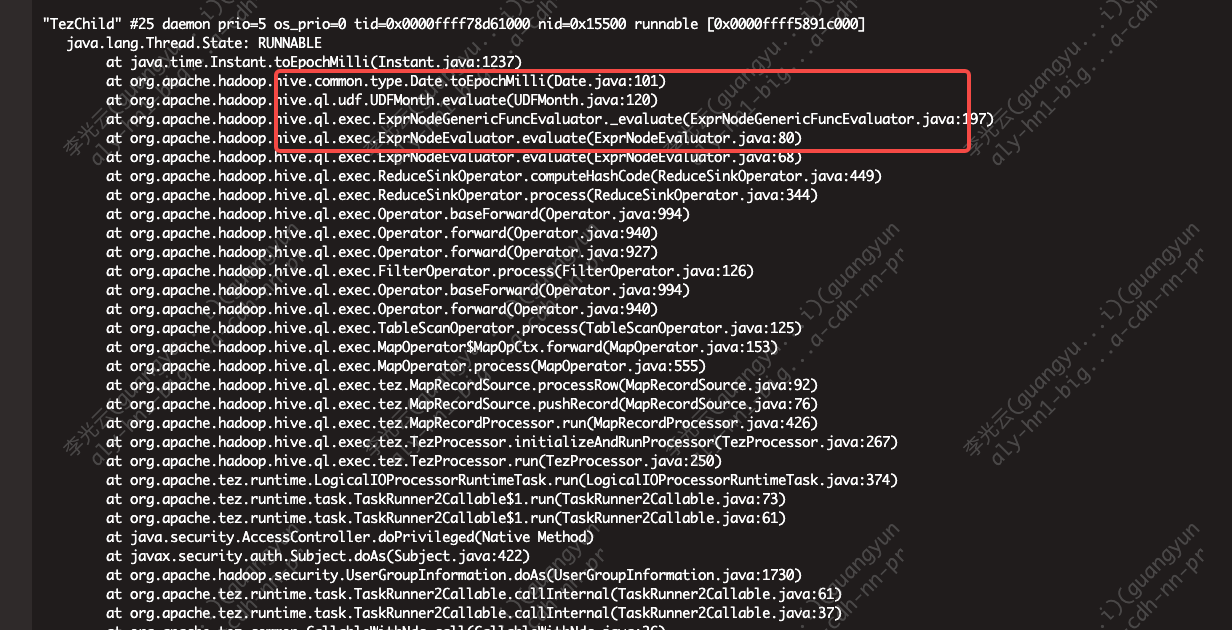
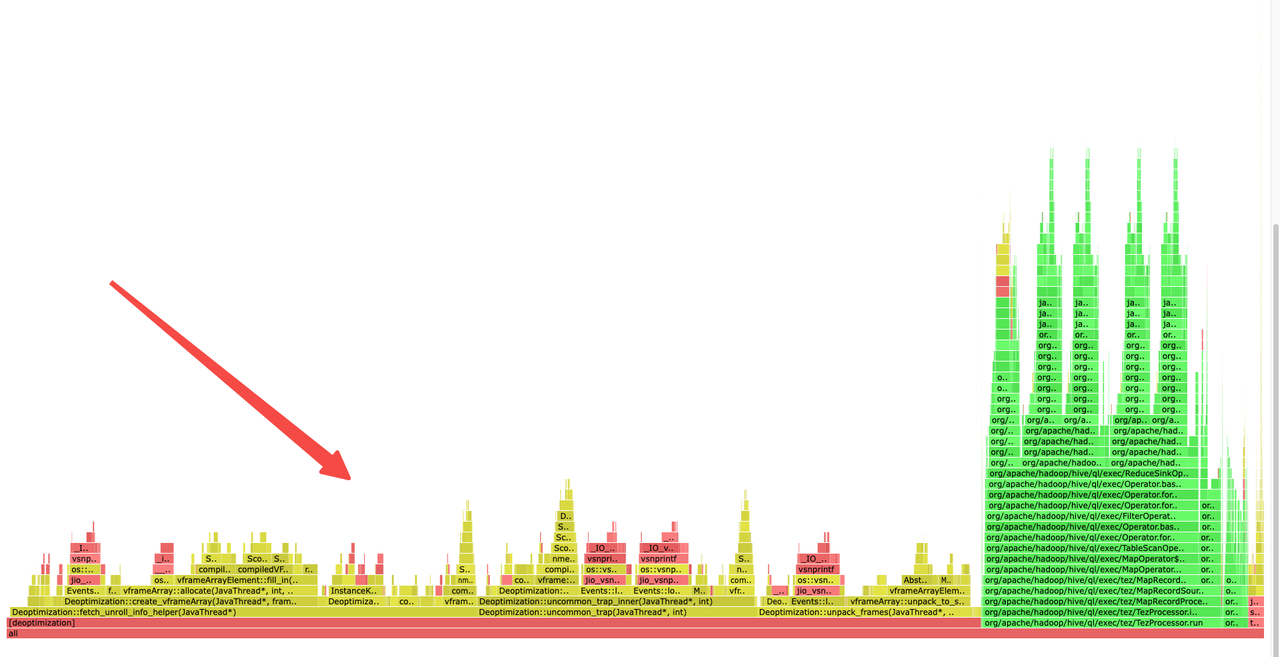
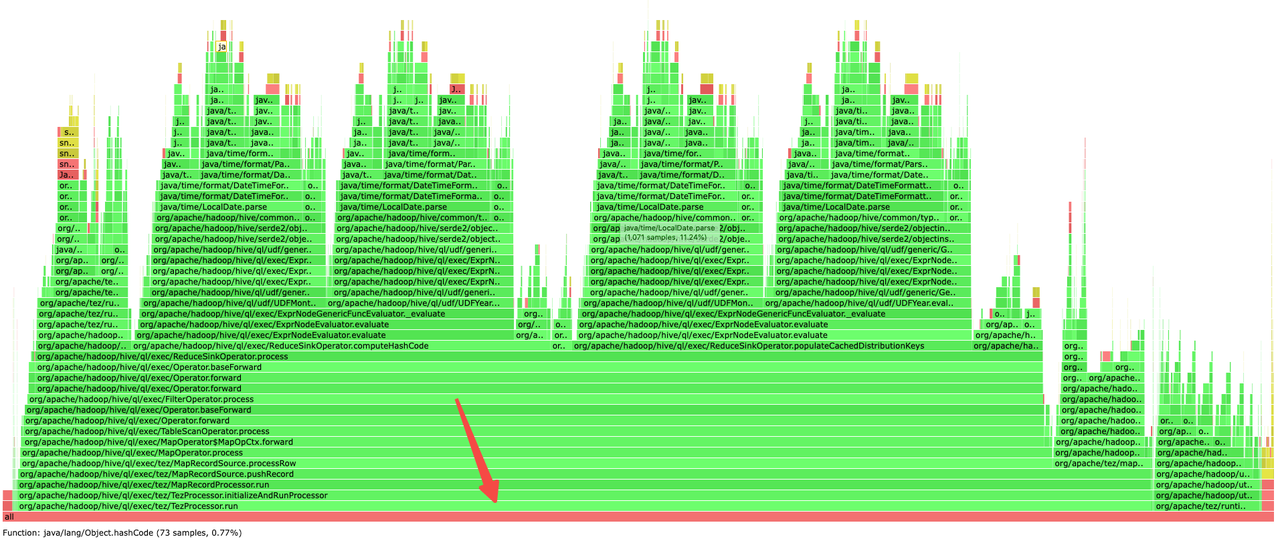
3.使用 Arthas profiler 分别采集 ARM 和 x86 上 Container 执行火焰图
ARM:
x86:
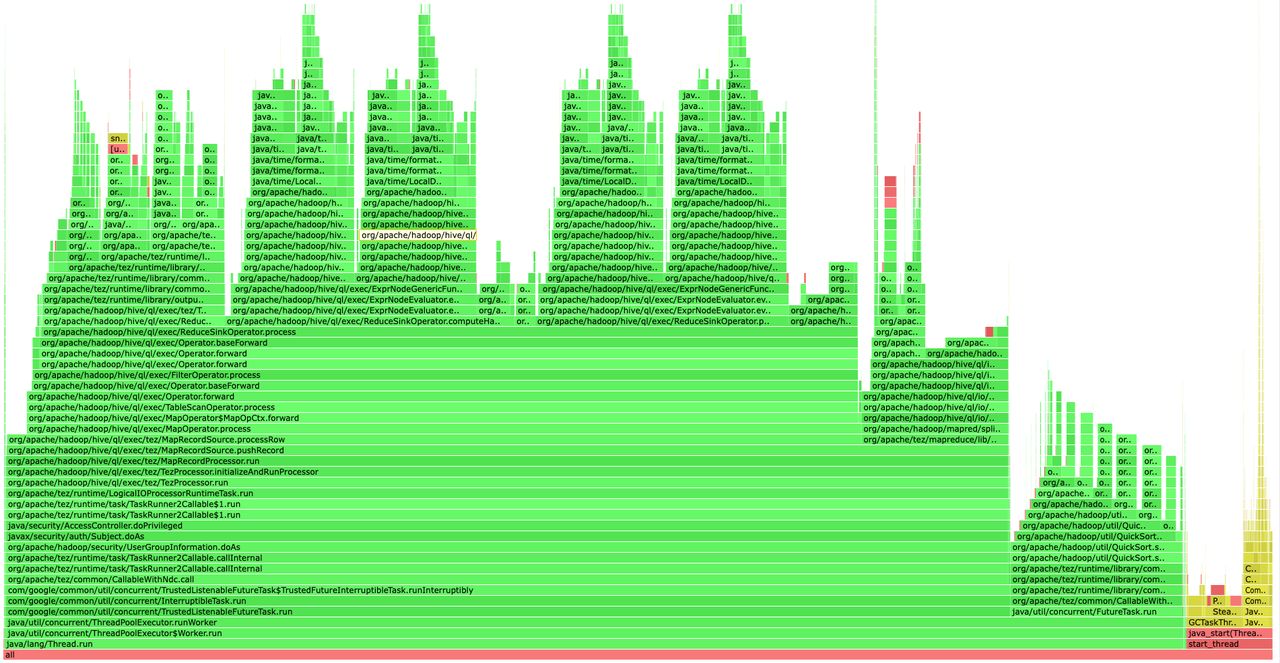
通过火焰图分析发现 ARM 机器上大部分耗时在 deoptimization 过程,关于 deoptimizatio 在Open jdk https://wiki.openjdk.org/display/HotSpot/PerformanceTechniques 中定义:
Deoptimization
Deoptimization is the process of changing an optimized stack frame to an unoptimized one. With respect to compiled methods, it is also the process of throwing away code with invalid optimistic optimizations, and replacing it by less-optimized, more robust code. A method may in principle be deoptimized dozens of times.
• The compiler may stub out an untaken branch and deoptimize if it is ever taken.
• Similarly for low-level safety checks that have historically never failed.
• If a call site or cast encounters an unexpected type, the compiler deoptimizes.
• If a class is loaded that invalidates an earlier class hierarchy analysis, any affected method activations, in any thread, are forced to a safepoint and deoptimized.
• Such indirect deoptimization is mediated by the dependency system. If the compiler makes an unchecked assumption, it must register a checkable dependency. (E.g., that class Foo has no subclasses, or method Foo.bar is has no overrides.)
4.解决方案
• 关于 deoptimization 问题,通过查阅资料是个JVM Bug(https://bugs.java.com/bugdatabase/view\_bug?bug\_id=8227523),在 JDK 11中已经解决了这个问题,在低版本JDK中可以通过调大-XX:PerMethodRecompilationCutoff、-XX:PerBytecodeRecompilationCutoff 参数值来缓解,但是上线后效果不是很好。
• 由于JDK 11 将JDK8 很多参数已经废弃,不计划升级JDK来解决。决定使用云厂商提供 ARM 机型定制开发的JDK来解决。在ARM机型上通过压测云厂商定制JDK 和社区 OpenJDK 执行用户出问题的 SQL,采样10次执行时间计算平均值,发现使用云厂商定制 JDK 执行耗时很接近 x86上任务耗时。
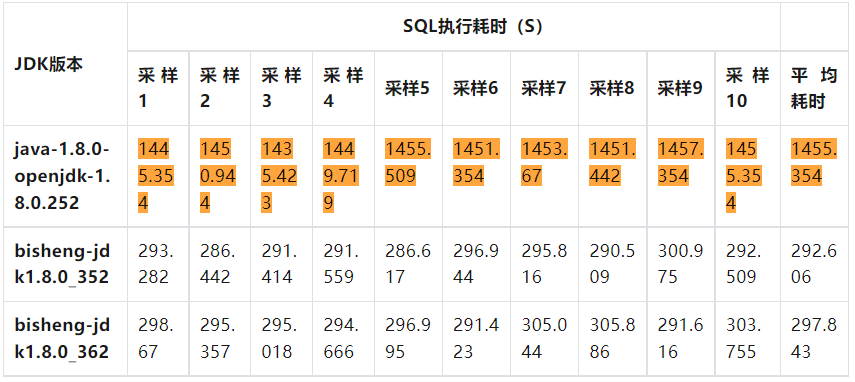
最终决定使用 bisheng-jdk1.8.0_362 适配ARM机型,上线后重跑用户出问题 SQL 发现 deoptimization问题解决。
总结
离线计算引擎目前以 Hive 为主,少部分用户使用 PySpark 也同样存在兼容性问题,需要在 YARN 调度层面进行研发改造和任务治理。为能在生产环境使用 ARM 机器,我们对 YARN 调度进行改造,先隔离 Spark 任务在 x86 机器运行,暂时规避兼容性问题。
目前通过对 YARN、Tez/MR 引擎、运维和安全基础组件等适配工作,完成生产离线 YARN 集群50% x86 机器替换为 ARM 机型,并已平稳运行两个月,除一起 JVM 问题导致生产故障外,无其他生产问题。
后续规划
货拉拉后续计划分两个阶段建立起以 ARM 机型为主力的大数据基座。
第一阶段目标替换离线 YARN 集群100%计算节点为 ARM 机型。第二阶段对大数据引擎服务 HiveServer2、Presto、Doris 等进行 ARM 适配改造。
等后续取得阶段性进展,再和大家分享我们的实践经验。
参考资料
https://developers.redhat.com/articles/2021/06/23/how-jit-compiler-boosts-java-performance-openjdk#
https://mp.weixin.qq.com/s/OK39zkUj-kJfY6HYixj\_Lw
https://www.slideshare.net/dougqh/jvm-mechanics-when-does-the

