货拉拉系统容量保障方案及实践
一. 前言
容量评估保障的目标有两个:
保证服务在大量用户、司机访问系统时,依然可以正常为用户、司机提供服务。比如,在“国庆高峰保障”拉货节的超高访问量下,各个线上服务都能稳定运行,保障业务高峰平稳过渡。
在非预期的快速流量增长下,比较充足的系统冗余量能够为我们的应急提供宝贵的时间;这就引出一个问题:我们的服务在目前的资源水平下,究竟能够提供多大限度的服务支持,有多大的冗余度,必须能有一个客观的评估;
“知己知彼,百战不殆”
二. 背景
在系统的维护过程中,我们可能需要面对以下问题:
应用系统能否应对业务预计的高峰流量且平稳过渡,是否需要提前扩容应对;
应用系统本身是否存在哪些性能瓶颈;
应用系统能否支撑业务复杂性和突发性。
三. 如何理解容量评估和保障
3.1 何为系统容量
系统容量是:单位时间内,系统能够承载的最大且正确的业务量所具备的QPS,这个容量评估主要还是以系统正常输出的QPS 为准,因为系统是要支撑业务平稳运行的,需要以正确的业务量产生的qps 为单位来衡量。当实际的容量大于这个系统限度,会存在以下可能两个现象:
上游请求出现排队,本应用的CPU变化不大,但对于上游看来系统的响应迅速变长、超时,服务不可用,最终拖垮整个链路系;
a. 长时间持续,请求的积压会打爆系统内存,造成整个系统不可用;
系统资源直接打爆,CPU迅速上升到100%,可能内存也同时增长,服务器被撑爆,服务迅速不可用;不管是请求排队或者机器资源用尽,最终都会造成服务的不可用,造成故障。而且从可干预的角度来看,情况2比情况1好,因为CPU的变化在100%前可以及时的发现,从而进行干预来避免风险。同时,进行容量的评估,及时对应用瓶颈进行处理,可以提前发现问题并优化,从而提前解决问题。
目前影响当前服务异常的场景可能有这些:
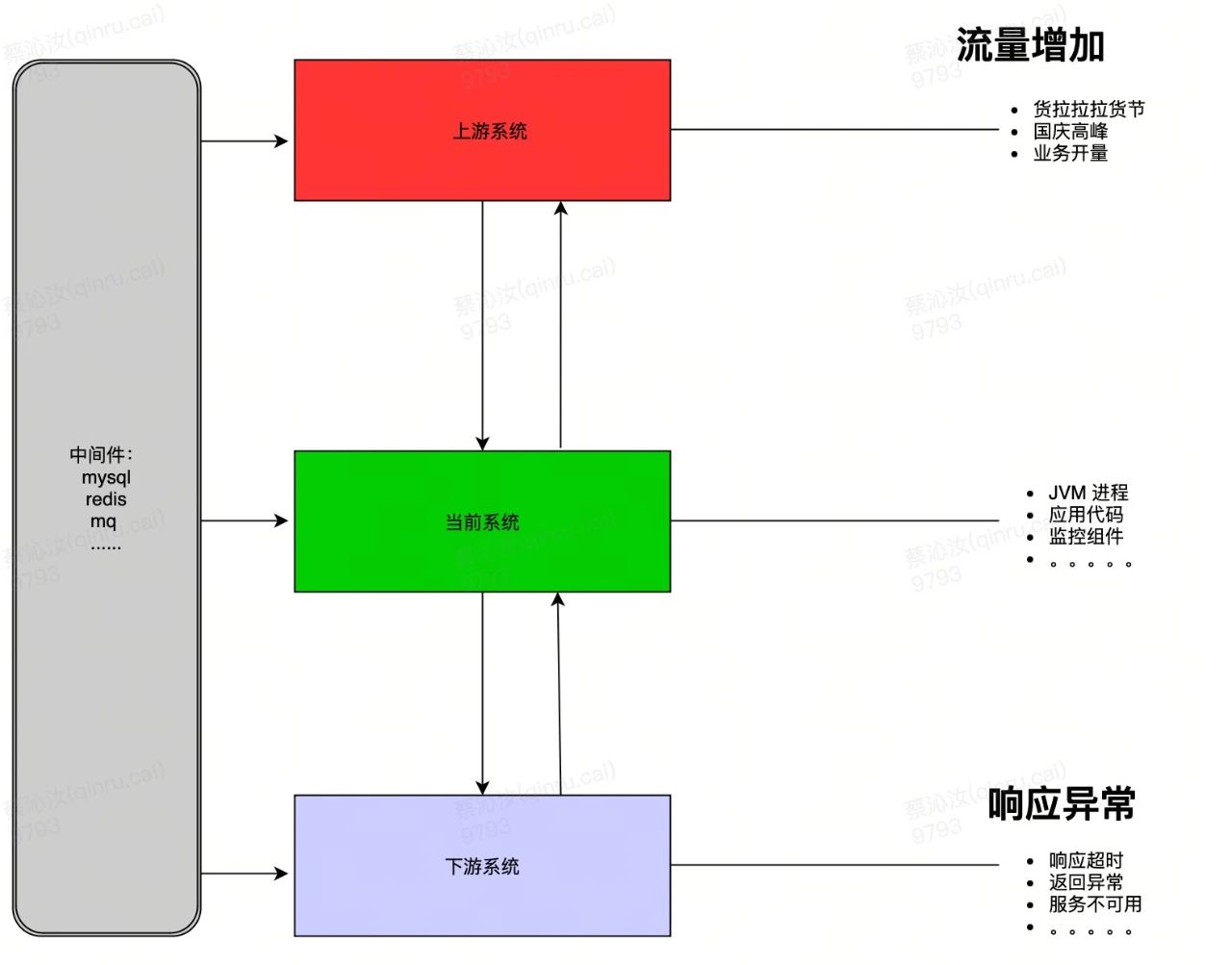
3.2 容量保障
容量保障,其实就是运用各种方法和工具来保障系统的容量可以承载并正确处理业务和响应,并且系统本身还要具备一定的容量冗余和弹性能力,弹性能力指的是系统本身要有比较灵活的扩缩容功能,当遇到突发的场景或者故障时,需要具备弹性的支撑和自愈能力。
3.3 容量保障的挑战
容量的不确定性:货拉拉货运整体的业务非常复杂,交易系统流程更加复杂,时刻存在各种流量突发场景;
容量评估的复杂性:系统容量治理是一个非常复杂的工程,再加上现在平台的微服务、k8s 容器的不断发展,系统架构变得越来越复杂,所以对这么复杂的系统容量评估十分困难;
容量测试的精准性:系统平台每周都会进行全链路压测,新接口线上单机压测、故障演练等等手段来测定和验证,后续才能进行容量规划治理;
容量规划治理的复杂性:现在的货拉拉的产品迭代速度快,业务不断的迭代,线上系统不断地发版,代码逻辑一直都在变,容量的规划本身就是一个持续性动作。
3.4 容量保障的方法
结合货拉拉及过往工作经验在高峰容量保障总结的一些方法:

四. 容量如何评估
4.1 影响系统容量的核心要素
对于JVM 应用来说系统容量的核心因子,主要还是这几个:
容器线程:
a. 简单来讲,容器的线程数越高,不考虑系统调度因素,系统的并发处理能力越强,目前线上配置:Tomcat默认的工作线程是200;我们假设处理一个请求需要1S的时间,那Tomcat在默认配置下一台容器1S内可以处理200请求,相当于单机支持200QPS;
响应时间:
单个请求的处理时间也会影响系统的整体吞吐量,比如一个接口的单个请求处理时间是1S,肯定比单个请求需要200ms的吞吐量低;Tomcat为例:
a. 1S:200(线程总数)*(1/1)(单个线程1秒内可以处理数)=200
b. 200ms:200(线程总数)*(1/0.2)(单个线程1秒内可以处理数)=1000 系统的吞吐量差距5倍;
依赖资源:
除了CPU&内存外,我们依赖的资源主要考虑2个方面,一是数据库,大部分IO型服务的核心,二是下游应用;
a. 数据库:数据库是依赖资源的重点,主要是目前我们使用数据库采用共享连接的方式,在小流量的情况下可能效率可以,但是在高QPS情况下,也会产生排队现象,从而RT升高产生问题;
b. 下游应用:针对下游应用,目前不管是HTTP还是其他RPC方式,我们对下游的调用主要取决于HTTP连接支持和下游容量,HTTP目前产生瓶颈概率较小,下游应用的容量可以单独评估,暂不考虑;
计算消耗:
a. 在线程和数据稳定的情况下,如果计算逻辑复杂,遍历计算等,必然会造成计算资源的消耗,针对应用来说,计算的资源是CPU。针对计算密集型应用,可以使用压测直接发现单机的容量;
容器 CPU&内存:
a. 我们不讨论CPU和内存在容量评估中的影响,希望这两个指标是我们系统运行负载的监控指标,通过指标的监控和跟进措施来优化系统;
i. 目前我们扩容的逻辑就是CPU,如果CPU高,除了逻辑优化,可以直接扩容;
ii. 内存:存在内存泄露的问题一定要解决,同时系统的初始及最大堆内存要设置合理;

4.2 容量评估的方法
有了上面的理论依据铺垫,假设:如果用系统的CPU & 内存指标作为系统服务是否健康的依据,排除外部其他接口、服务间的依赖外,现在从这两个方面计算下服务容量值。
4.2.1 容量评估计算公式
1. 工作线程和单个请求的处理时间
a. 理想情况单机支持QPS = 机器线程数 * (1S / 业务请求的平均RT)
b. 比如服务A:请求的平均RT为25ms, 目前undertow的线程数配置为256,单机理想QPS
i. 256*(1000/25) = 10240;
数据的整体资源和处理时间
a. 理想情况单机支持数据库SQL的QPS = 数据库连接数 * (1S / 数据库请求的平均RT)
b. 比如服务A:数据库SQL的平均RT为10ms, 目前数据库配置为200,单机理想SQL支持
i. 200*(1000/10) = 20000;
由于业务请求和数据的SQL不一定是1:1的关系,所以引入安全阈值来评估系统整体安全度。
针对服务A,目前总共4台机器,目前的高峰QPS在3000,数据库QPS在7000左右:
业务容器安全阈值 = 4 * 10240 /3000= 13.6
数据库安全阈值 = 4 * 20000 / 7000 = 11.2 整体上在目前的配置情况下,我们的理论容量是目前高峰的10倍以上,推测如果到达瓶颈,也应该是数据库先达到瓶颈。
我们没有考虑CPU和内存,实际上CPU和内存会在达到这个指标前成为瓶颈,但这时我们可以发现并及时干预,避免问题中的第一种情况出现。
说明:这个是理论的最大容量,实际单机的容量要比这个小很多,比如服务A,实际单接口压测的容量是有2300QPS左右,这时CPU已经100%了。
4.2.2 验证服务达到极限的标准
1. RT接近稳定 ;
2. CPU接近100%;
所以一定要同时满足以上条件,才能说明真正压测到服务的极限;RT稳定,说明依赖的资源和资源处理达到一个均衡状态;CPU接近100%说明系统已经开始处理接近系统容量的最大值,更多的请求已经无法再处理。
4.2.3 压测的三种方式
单接口
根据应用,针对核心的单个接口,进行压测。可以评估应用核心场景的单机容量,但由于场景比较单一,误差也比较大。
如果应用存在多个DB,可以每个DB涉及的接口都进行压测,保证核心资源不会造成阻塞,一个应用访问DatabaseA & DatabaseB,那压测至少要同时包括对DatabaseA & DatabaseB的接口;至少两个接口进行压测;
核心接口和DB
梳理应用的核心接口和DB,压测的接口要覆盖核心的接口和所有DB。成本更高,但评估比单接口要准确。
如果应用包括比如DatabaseA & DatabaseB两个,针对这两个DB的访问的核心接口,要包括:查询,添加,更新三种场景,压测接口至少要包括6个;
真实流量
应用的接口流量按照线上真实的流量进行配比,增加也按照对应的比例进行增加,评估准确,成本大。所以希望大家利用全链路压测,在全链路压测中发现的问题要及时分析和解决。这里我们重点讨论单接口压测的一些状况和分析,多接口情况类似,只是准备的工作会比较复杂。
4. 单接口压测的配置和表现
目前的压测核心的配置有几个:线上生产环境,单机剥离出来;
压测线程数:同时启动多少个线程进行压测
超时时间配置:
a. 不设超时:(应该是默认配置),就是单个线程要等前一个请求的结果返回才发下一个
b. 设置超时:就是超过设定时间(比如1S),不管前一个请求的结果,发下一个请求;
假设有应用,目前单机500QPS,RT500ms,使用2000压测线程压测:可能存在以下情况:
不设超时:
a. RT增加到比如2000ms,CPU增加到一定幅度后稳定:
相当于1S处理1000请求,其他应该是排队,CPU单个时间只处理部分请求,稳定
b. RT有一定增加,比如700ms,但CPU基本100%
机器基本达到瓶颈了,资源处理和CPU到达瓶颈
c. RT基本无增加,CPU增加到一定幅度后稳定:
机器还有余力,可以继续加量;
设置超时 600ms:
a. 机器开始响应正常,后续逐渐崩溃
对应1中的a&b情况,请求不断积累 1. 情况a,队列逐渐增大,大概率内存问题 2. 情况b,CPU和内存都逐渐爆掉;
b. 机器CPU升高,但是基本正常
对应1中的C情况,机器有富裕的容量
针对a,需要明确阻塞的点并进行优化和调整,对于b,应用基到达瓶颈,需要逻辑优化或扩容.
五. 实践出真知
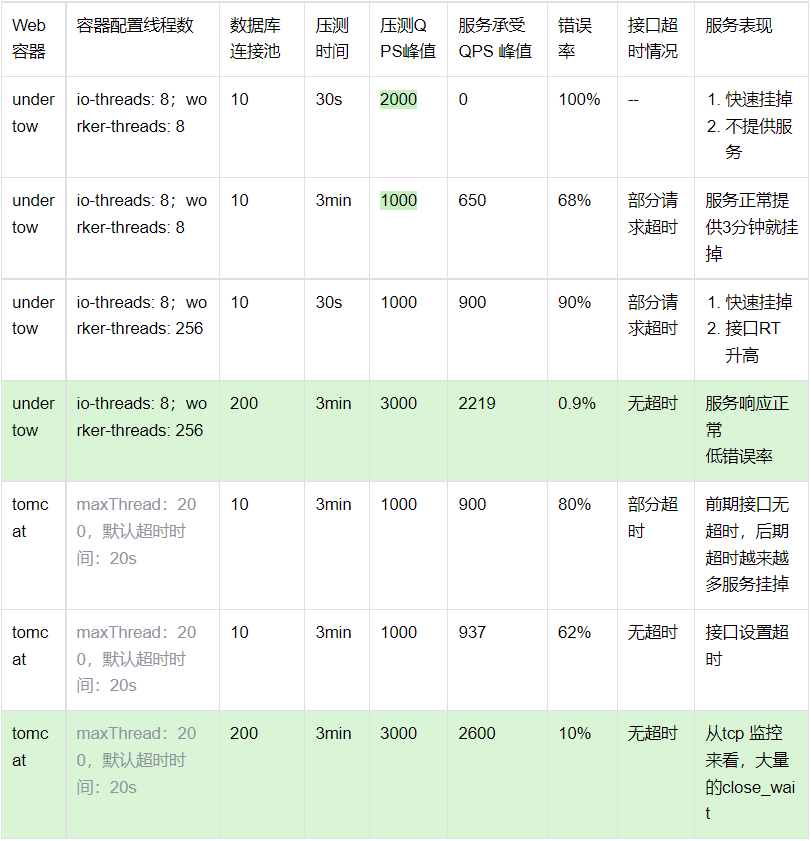
5.1 分别对tomcat、undertow 两个服务器都进行了压测
压测的基本情况包括acceptCount,worker-threads,DB连接池三个核心参数的不同组合情况。
下面是压测后基本数据对比:
5.2 基本结论
当worker-threads较低并配合业务接口的资源不足时,会导致系统整体的整体吞吐量稳定在一个大致水平(压测应用在不改配置的情况下,整体吞吐量Undertow在850左右,Tomcat略高不到900),如果上游请求超过该阈值,就会造成请求在worker之前积压,从而导致调用服务的RT上升。
5.3 核心变更:
针对测试应用,单独调高worker-thread数量,系统的吞吐量没有变化,但是业务接口的处理RT增加;
针对测试应用,调高worker-thread数量&数据库连接池数量,单机系统的吞吐量增加到2000以上,十分明显。
5.4 建议关键措施:
针对IO密集应用,建议调高worker-thread(包括自建线程池)数量,提升应用接收请求的能力,如果CPU或者RT升高问题出现可以及时发现并干预,防止系统在问题暴露前就被打挂掉;
(数据库链接池数量的调整针对压测应用比较有效,但从目前结果来看,worker-threads的调高,会暴露RT问题,所以暂时不建议做为标准操作,但是可以参考DBA建议配置)
另外:请求在worker之前阻塞,尝试了各种参数也没有达到超过系统容量是,无法处理的请求能及时返回报错的预期;
最后关于应用服务器选型:从硬件配置及外部影响一样的情况下,tomcat 的吞吐量要强于Undertow。

