作为企业级数据库的核心组件之一,查询优化器的地位不可忽视。对于众多依赖数据分析的现代企业来说,一个强大且完善的查询优化器能够为数据管理和分析工作带来巨大的便利。
作为一款火山引擎推出的云原生数据仓库,ByteHouse基于开源ClickHouse构建,并在字节跳动内外部场景的检验下,对OLAP引擎能力、性能、运维、架构进一步升级。ClickHouse以快速处理数据而著名,但其查询优化器在处理多表查询和高维度数据时却显得力不从心。为了解决这一问题,火山引擎ByteHouse自研并推出了一款全新的查询优化器。
本篇文章来源于火山引擎ByteHouse技术专家《ByteHouse查询优化器的设计与实现》的分享,从现状分析、设计思路、实现方案、高阶优化、优化效果五个部分,拆解ByteHouse查询优化器如何实现性能10倍提升。
现状分析
ClickHouse 的存储引擎、向量化计算拥有独特的优势。
ClickHouse缺乏复杂查询的优化以及执行能力,比如说多表 JOIN 的性能、子查询的执行,有很多的复杂的查询在 ClickHouse 上是无法执行的或者执行性能比较差。
社区在尝试构建 query plan 的概念和优化器相关的模块,但是现还处于比较初级的阶段。而且 ClickHouse 的下发执行查询的方式比较奇特:收到 SQL 的主 Server 会做一定的解析,然后会将解析完的结果又重新生成一个 SQL 再发到其他的 worker 上。这种方法能表达的信息是有限的,SQL 能表达什么样的信息,它其实就只能下发这样这些信息给其他的 Server 去执行。
syntax analyze和 tree writer 相关的模块复杂,有很多历史遗留的问题,设计上比较繁琐,所以在支持一些比较复杂的查询的时候它有一定的局限性。
设计思路
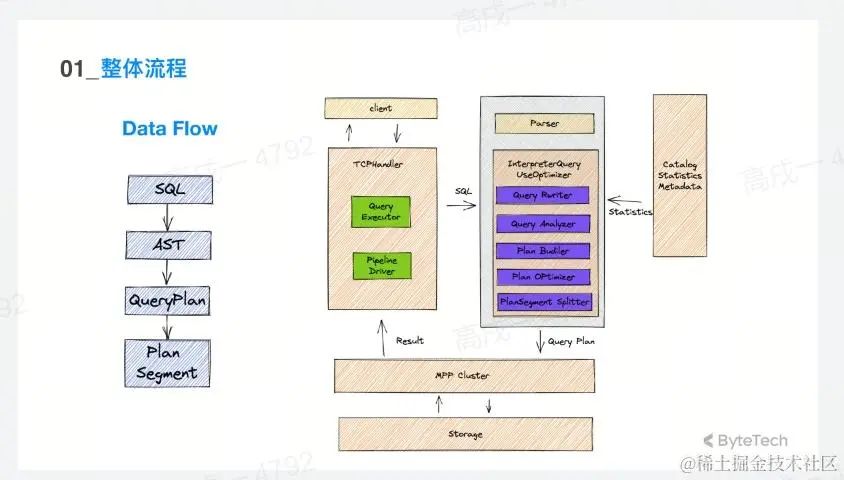
基于以上原因,ByteHouse团队重新实现了ClickHouse 的优化器,左边的是ByteHouse的查询优化器的数据流相关的部分。
首先客户端传来一条 SQL字符串,server 会将 SQL 字符串解析成AST,再将 AST 经过一系列的分析过程以及构建的过程构建出一个 query plan, query plan 经过一定的优化生成最好的计划,将这一个分布式计划切成 plansegment 去下发执行。
右边的紫色部分就是从 0 到 1 全部重新实现的一个优化器相关的模块。SQL 字符串经过Parser之后,然后再经过自研的优化器,最终会下发一个 query plan 到 MPP 的执行引擎上进行执行,最终将结果返回给client,除了 Parser 以外到执行之前的其他模块全部进行了重写,这样就会保证语法上和开源 ClickHouse 做了兼容,但是中间的分析和优化部分全部都是自研的,而且对于下发查询的方式也做了一定的改变,并不是转化成一个 SQL 下发到其他 Server 上执行,而是下发一个完整的 query plan 到不同的机器上,然后用 MPP 的方式进行执行。
主要模块:
第一个模块是Analyzer,主要分两部分,一个是 query writer,一个是 query analyzer。query writer 是在 AST 级别对查询进行一定的改写,比如说 with CTE/ view/ UDF 的这些简单的内容的展开,包括一些特殊函数的替换,比如用户虽然写了一个函数 count distinct 某一列,但是其实我们最终会转化成另外的一个函数来进行执行。这种简单的替换,是在 AST 级别来做的。第二部分是 query analyzer,主要是对名字进行解析,对数据类型和语法的一些校验,最终将整个分析的结果抽象化成一个结构化的数据结构,用来辅助后面的 query plan 的构建。整个数据结构能描述查询他想要表达的语义,然后利用这个结构化的数据结构构建出 query plan。
第二个模块是plan builder:改进社区 QueryStep 内容;增加序列化反序列化;补充高级算子。
第三个模块是optimizer:RBO,CBO,分布式计划优化,高阶优化能力(Runtime Filter,CTE,物化视图改写)
第四个模块是Statistics:以 Histogram 为主的统计信息;自动收集和更新
第五个模块是Diagnosis Tools:Plan Explain,Explain Analyze,Plan Visualization,Plan Dump
实现方案
优化器:经过一些规则的优化,把一个计划变成另外一个更好的计划。
Role Based Optimizer:根据优化规则对关系表达式进行转换,一个计划经过优化规则后会变成另外一个计划,同时原有计划会被裁剪掉,经过一系列转换后生成最终的执行计划。
Cost Based Optimizer:通过规则生成一系列计划,利用统计信息评估计划的代价,选择代价最低的作为最终计划。
除优化框架之外,还需要很多优化理论来应用这两个框架对计划进行变化。
主要有这四种能力:
基于关系代数的等价性 :join 交换律于结合率
基于数据特性:唯一键,functional dependency
基于分布式数据库特性:exchange 插入,算子拆分
高级优化手段:物化视图,Runtime Filter
RBO
RBO主要实现了两种优化改写框架:
基于 visitor 的改写框架
Top-Down / Botton-Up 的方式对一个 QueryPlan 做改写,适合于对上下文有依赖的优化规则。比如说把一个predicate 不停向下传递,将每一个条件放到它最应该存在的地方,让它尽量早地执行。这需要从上到下全部链路进行改写并传递信息进行优化。例如:predicate push down 和 Column pruning
基于Pattern-match
适合简单、通用的改写规则。例如:将两个连续的 filter 节点合并成一个,这样关注连续的两个是 filter ,然后把这两个进行合并,再替换回去完成优化了,并不需要对整个查询改写。
利用这两种改写框架实现了常见的优化规则,比如列裁剪,表达式的简化以及子查询的结关联,谓词下推,还包括冗余算子消除,Outer Join 转 Inner Join,算子下推存储、分布式算子拆分等常见的启发式优化能力。

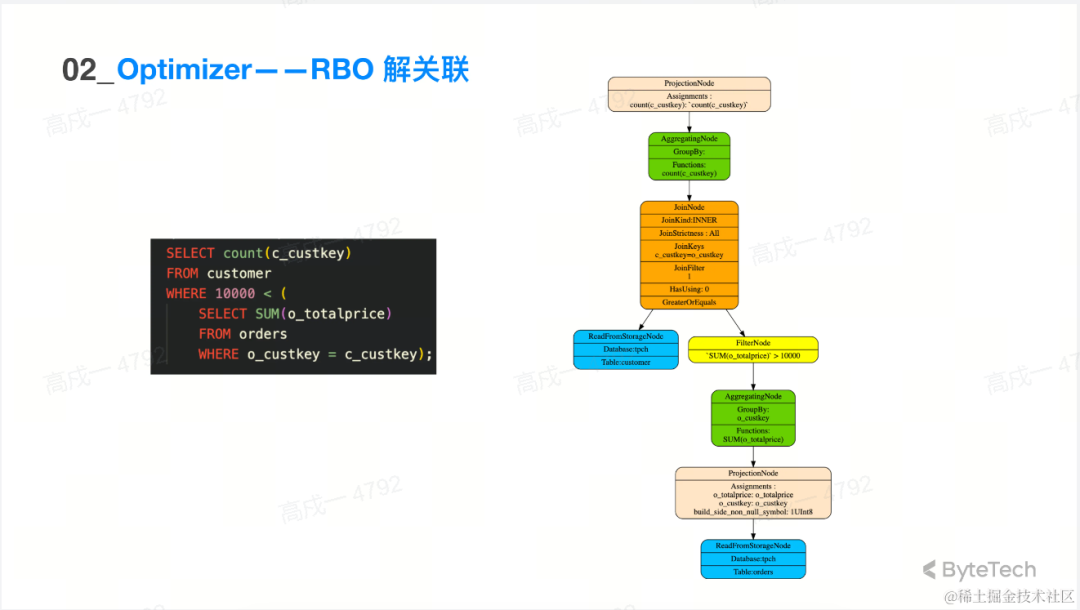
RBO 解关联
左边:这样一个SQL看起来只是查一张表,但其过滤条件里面又用了另一张表。子查询中既用了自己的列,又用到外面主查询的列。子查询和主查询是有一定的互相依赖的关联查询,这样的查询其实是正常情况下是很多数据库是不能直接执行的。
右边:经过解关联之后的一个查询计划的样子,转换成了常见的算子 join agg 等,这样查询就可以正常执行了。
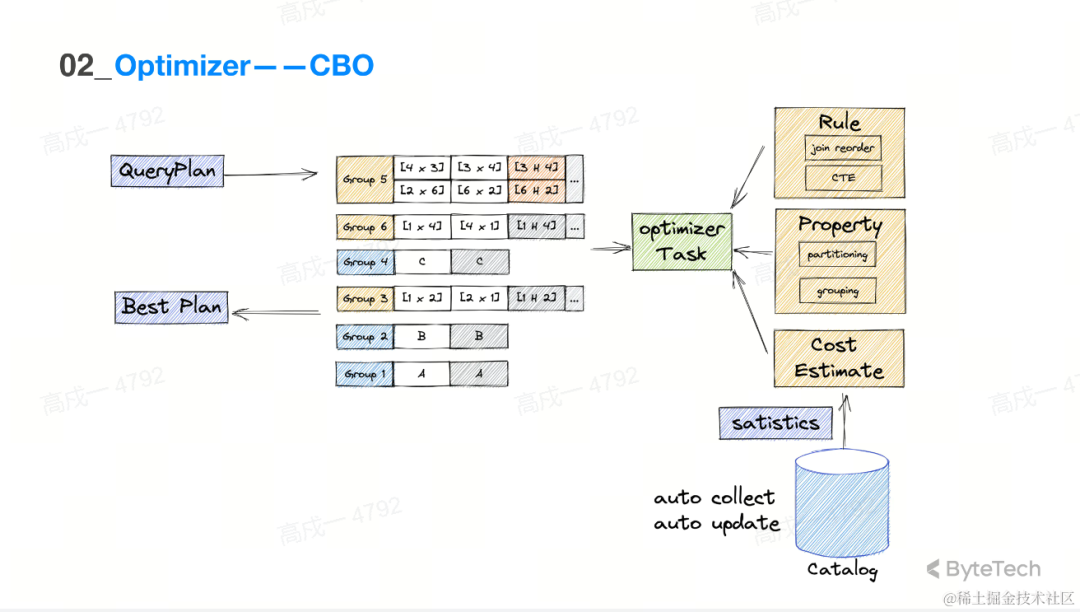
CBO
蓝色的 query plan经过右边的 optimize task 不停地扩展,利用右边的黄色的 rule(比如 join reorder 和CTE)转化,中间的搜索空间会被扩充,然后计算 cost,最终会基于 cost 选择一个最好的 plan 作为最终输出结果。而且在优化的过程中,因为是一个分布数据库,所以会利用一些 property 的信息去生成分布式计划,同样也会将分布式计划的 cost 考虑在内并基于综合代价去选择一个更优解。
详细展开一下 CBO 里内的每一个模块审具体是怎样实现。
CBO Cascades搜索框架:
下边这个表格描述了在不同 join 表的数量的情况下它真正要表达的搜索空间是多大。其实是阶乘级别的复杂度,对于10 个表来说已经是亿级别的量级了,由于枚举数量庞大的逻辑执行计划是不现实的,存储空间和搜索时间是接受不了的,所以就利用了 Cascades 的搜索框架,Group 和 GroupExpr 来表达数量庞大的搜索空间,可以将 n 的阶乘的复杂度的搜索空间来降低到 3 的 n 次方级别。这样可以在有限的时间内搜索出 10 表以内的所有的 join 情况,可以大大地降低整个搜索时间以及存储空间。

CBO计划枚举
规则
需要靠CBO的规则不停地扩充搜索空间,然后基于cost选出其中的更优解,扩充得越多,选出更优解可能性就更高。我们也实现了常见的 CBO rule。例如:Inner Join Reorder,Left Join to Right Join,Pull Left through Inner以及CTE和Magic Set这样高级优化。
分布式计划
作为分布式数据库,ByteHouse会利用分布式的属性,将分布式计划的生成和搜索融合在同一个Cascades搜索框架内,最终基于代价来选择最优的分布式计划。
利用三种property来优化和生成分布式计划:
partitioning 是指数据是如何分区的,每个数据分区内的数据是不相交的。例如第一个分区内的数据是AB,那第二个分区内数据是CD,所有 A 或者 B 都会在第一个分区内,所有 C 和 D 都会在第二个分区内。
grouping 和 sorting 描述的是数据行与行之间的关系。grouping 是相同值的数据都要连续地排布在一起,例如 BBA。sorting 被认为是一对 grouping 的加强,它不但要连续的数据在一起,而且是要有序的,例如 AABB。

我们将分布式计划和 CBO 框架结合在了一起。很多数据库的做法是用 CBO 先生成一个计划,在这个计划上推导如何插入 exchange 的节点,这样有可能会 miss 掉更优解,很多情况下可能是一个次优的 join order ,但加上生成的分布式计划,它反而是全局更优的。
以a、b, c 三个表为例子,这两个橙色计划分别对应两个不同的单机计划(对于每一个单地计划,其实都可以扩容出多个分布式计划)。比如说我们先进行 a join b,再 join c,这样的情况 a 表按 uid 进行repatition,这样 a b 都按 uid 进行分区之后,可以直接进行 join ,然后对 join 的结果再按 id 进行repatition,然后去和 c 进行join,这样的结果才是正确的。但也可以不需要对a做repatition,也可以对b做replicated,这就有两种不同的选择。对于另一个单机计划来说,同样也可以生成两种不同的数据分布方式。会对这四个计划都会去评估代价是多少,哪一个花费的时间更少,那基于 cost 选择最终的更优解。

高阶优化
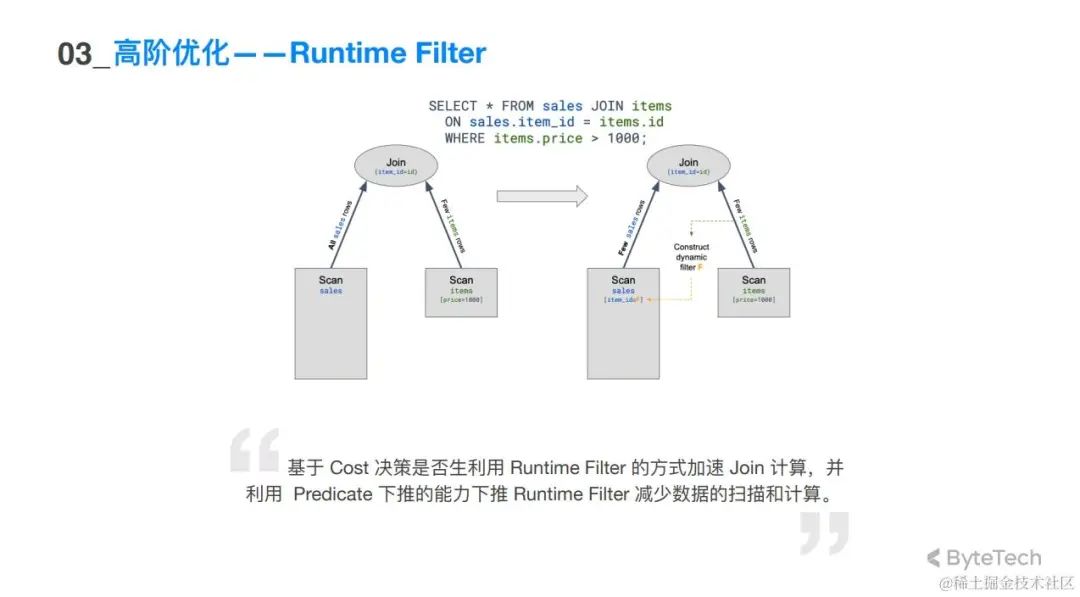
Runtime Fliter
此查询是对 sales 表和 item 表进行 join。现对 item ID 做了一个大于 1000 的过滤,利用过滤之后的 id 构建 filter,对 sales 用这个 filter 来过滤数据,过滤之后会让真正参与 join 的数据减少很不多。相比于正常执行,这种优化大大减少左边表格的扫描量,效率更高。
但是至于是否做这样的优化是需要做一定决策的,并不是所有 join 都能做这样的优化,而且优化是有一定代价的。决策和优化都需要优化器去决策。
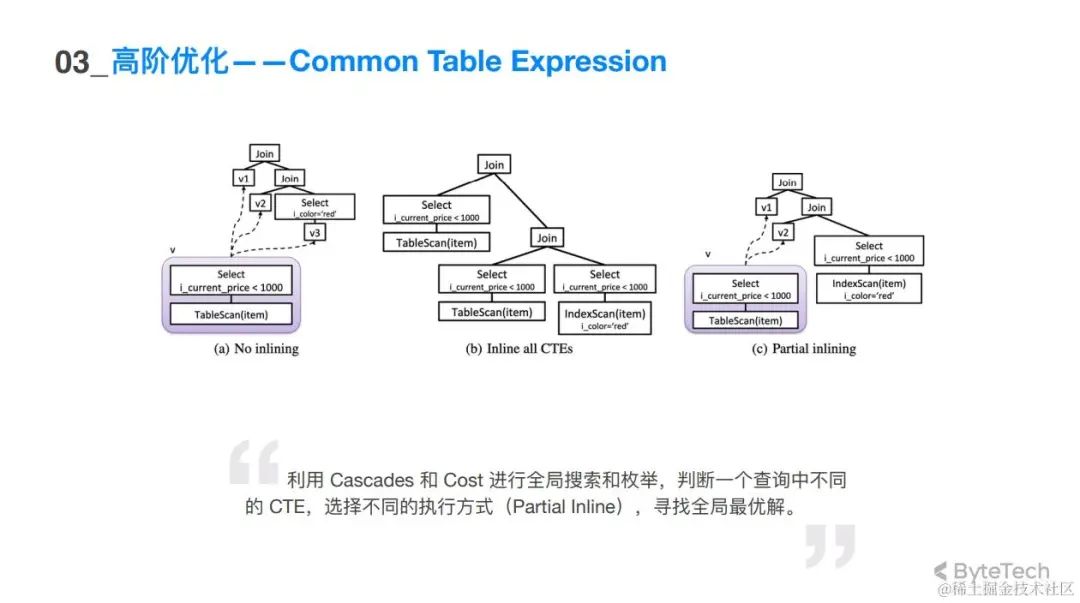
CTE (common table expression):
这个查询有三种可能性, SQL 是对同一张表 join 了三次,但是有不同的过滤条件, V1、V2 都是对这张表的 current price 做了一个小于 1000 的一个过滤之后进行join,那 V3在过滤之后还做了一个 color = red 的过滤。
第一个计划只做了一遍 tablescan,把扫描结果用了三次,但没法利用到color这个列已经建了索引的能力。扫描的时候要把整个表都扫上来,然后在内存里做price 小于 1000 的过滤。
第二个计划前两张表 V1 和 V2 是不要进行共享,V3 也不要进行共享,但是 V3 这个这个表在扫描的时候可以利用 index scan 的能力,因为在 color的这一列上建了索引,所以就用 index scan 的能力扫描数据,V3的扫描代价比较低。这些计划都不是最好的,应该让前面两个做共享,然后第三个自己独立的扫描,这才是最优的一个计划。
至于哪一个更好,要利用 Cascades 全局地去搜索,枚举这些计划,基于 cost 判断。
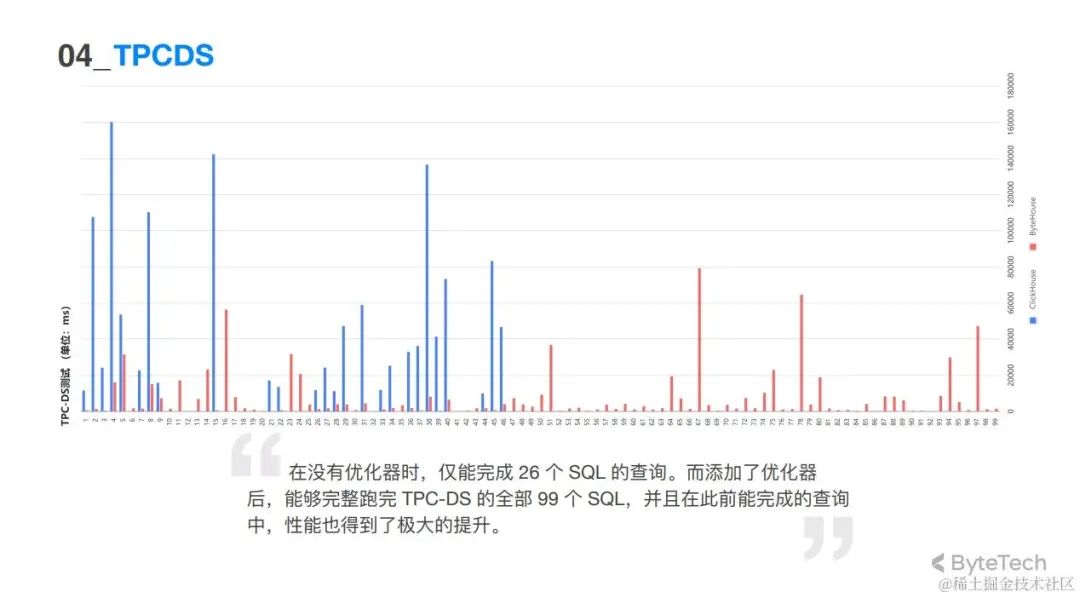
优化效果
在没有优化器的时,仅能完成 26 个SQL的查询,而且是在对一些 SQL 做了一定变换之后才能执行的。
添加优化器之后,ByteHouse能够正常跑完 TPC-DS的全部99 条查询,而且它的性能也是比较不错的。在之前同样都能支持的26 个查询中,它的性能也得到了极大的提升。