摘要
携程火车票包含1000+的业务指标,人工监测指标的异常情况耗时费力,而由于业务差异,基于规则和简单统计学的检测方案只能覆盖到单个指标或者单类指标,并且不能随着新业务上线或者功能变动灵活动态的调整相应的规则,并不适用于大量不同业务线的指标。我们希望使用AI算法来代替人工,对指标进行全自动的监控,旨在发现指标的异常和导致异常的潜在原因。
具体来说,对于异常检测,使用六种无监督检测算法计算异常得分,根据时间序列特性和指标的业务特点计算异常阈值,集成多种算法的异常结果进行硬投票,得到异常结果。对于根因定位,集成了Adtributor、Hotspot等四个算法做硬投票系统,按投票次数降序输出根因结果。此外根据指标的重要程度,设置不同的投票规则,来权衡精召率。
一、背景
最近几年,火车票业务持续高速成长,业务指标种类繁多,如何快速准确发现指标的异常以及导致异常的原因,并及时排除问题显得尤为重要。基于AI的异常检出能力,可以根据指标的历史数据分布规律,实现实时监测,帮助开发人员尽早发现问题和挖掘产生问题的原因。
1.业务指标特点
我们从已有的历史监控指标中,发掘时序数据的变化规律,从而根据数据的分布特点选取合适的算法。从图1我们可以看出,火车票业务的核心业务数据,主要呈现两种规律:
1)周期型时间序列,受人们出行规律的影响,大部分核心业务指标都会呈现较强的周期型规律。由于多数用户在工作日买票,周末出行,就形成工作日的支付票量和出票票量比周末多的规律,而出行票量则表现出刚好相反的趋势。在不同业务线下,相同的业务指标之间的周期规律也不尽相同。
2)平稳型时间序列,对于任意时刻,如果它的性质不随观测时间的变化而变化,那就认为是平稳型时间序列。由于指标本身的性质和偶发性的因素影响,有些指标没有很强的规律性,而展现出相对稳定的趋势。

图1 核心业务指标的时间序列类型
不论是平稳型还是周期型指标,根据当前的业务情况上线新的营销策略,发放优惠券等活动,尤其是对出行的影响巨大的疫情及其相关的政策,均会引起指标一定程度的剧烈波动,如陡升、陡降、整体抬升或降低。
2.主要痛点
1)基于规则的异常检测识别适用性差。火车票业务指标目前有1000+,人工对所有指标进行检测耗时费力。而基于业务规则的检测方案只能覆盖到单个指标或者单类指标,并且业务规则的配置需要对业务特点熟悉,对于新业务上线或者功能变动则不能灵活动态的调整相应的规则,并不适用于大量不同业务线的指标。
2)大部分核心指标都是和出行相关的,而近三年由于疫情的影响,在特定的时间窗口内,用户的出行规律变化复杂,导致精准捕捉指标的周期变得困难,从而增加了异常点的检出难度。
3)异常故障需要数据分析师排查。当某个业务指标发生异常,需要快速准确的定位到是哪个交叉维度的细粒度指标的异常导致的,以便尽快做进一步的修复止损操作。由于指标维度多,每个维度取值范围大,导致人工介入解决问题的难度和时间成本高。
二、异动归因系统介绍
针对业务需求、指标的特点和当前存在的痛点等问题,我们开发了一套异动归因系统,它分为异常检测和根因定位两个子系统。异常检测系统负责将各业务指标的突然上涨和下跌等异常情况检测出来,根因定位系统是在指标出现异常的情况下,找出引起异常的原因。
1.异常检测系统
由于不同业务线指标数量多,规律差异大,无监督算法更符合火车票业务需求。常见的无监督异常检测算法如表1所示【1】,对于局部异常点, LOF(局部异常因子)在统计上优于其他无监督方法,而使用K次(全局)最近邻距离作为异常评分的KNN是统计上最好的全局异常检测算法。
综合考虑局部异常和全局异常点的检出能力,以及训练时长,最终确定了LOF,KNN,CBLOF,COF,IForest,PCA作为火车票的异常检测算法。

表1 常见异常检测算法性能分析
无监督算法的性能在很大程度上取决于其假设和潜在异常类型的一致性【1】,所以对不同指标经常出现的异常类型的分析至关重要,以便于选择合适的检测算法。我们对典型的一些周期型指标序列和平稳型指标序列的异常情况进行分析统计,如图2所示:
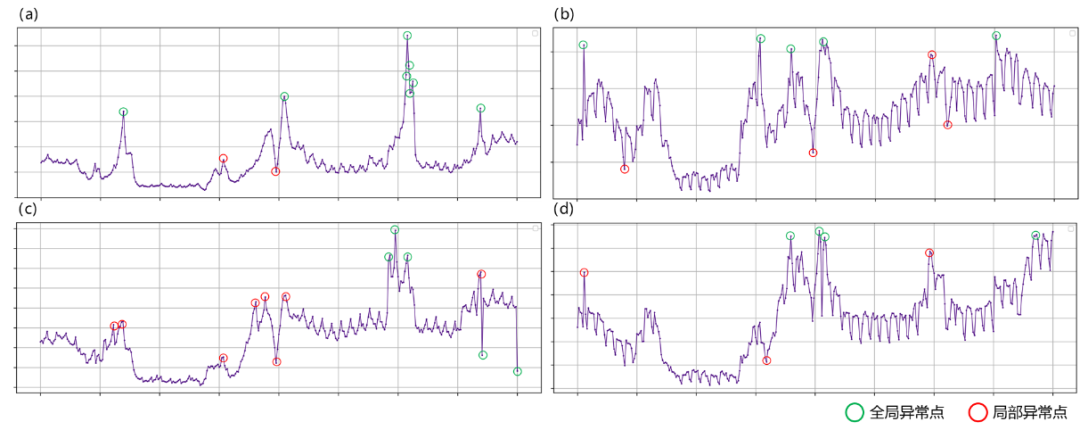
图2 核心业务指标的异常点类型
分析发现,平稳型指标序列(a)出现的主要是全局异常点,而局部异常点主要分布在具有趋势性和周期性的序列(b)、(c)和(d)中。由于相同业务线的指标趋势规律大致相同,出现的异常类型也大致一样,我们可以根据不同业务线的指标序列类型,应用不同的算法组合。
在分析指标的异常类型和算法选取之后,我们需要根据指标的不同分布情况,针对每种算法的异常得分选取合适的阈值,得到最终异常结果。我们分析了部分核心指标的概率密度分布,对不同数据的分布采用了不同的阈值算法,最终确定在低偏态高对称分布下,Z-score+肘部法则的方法计算阈值,在高偏态分布下,使用箱型图(Boxplot)计算阈值。
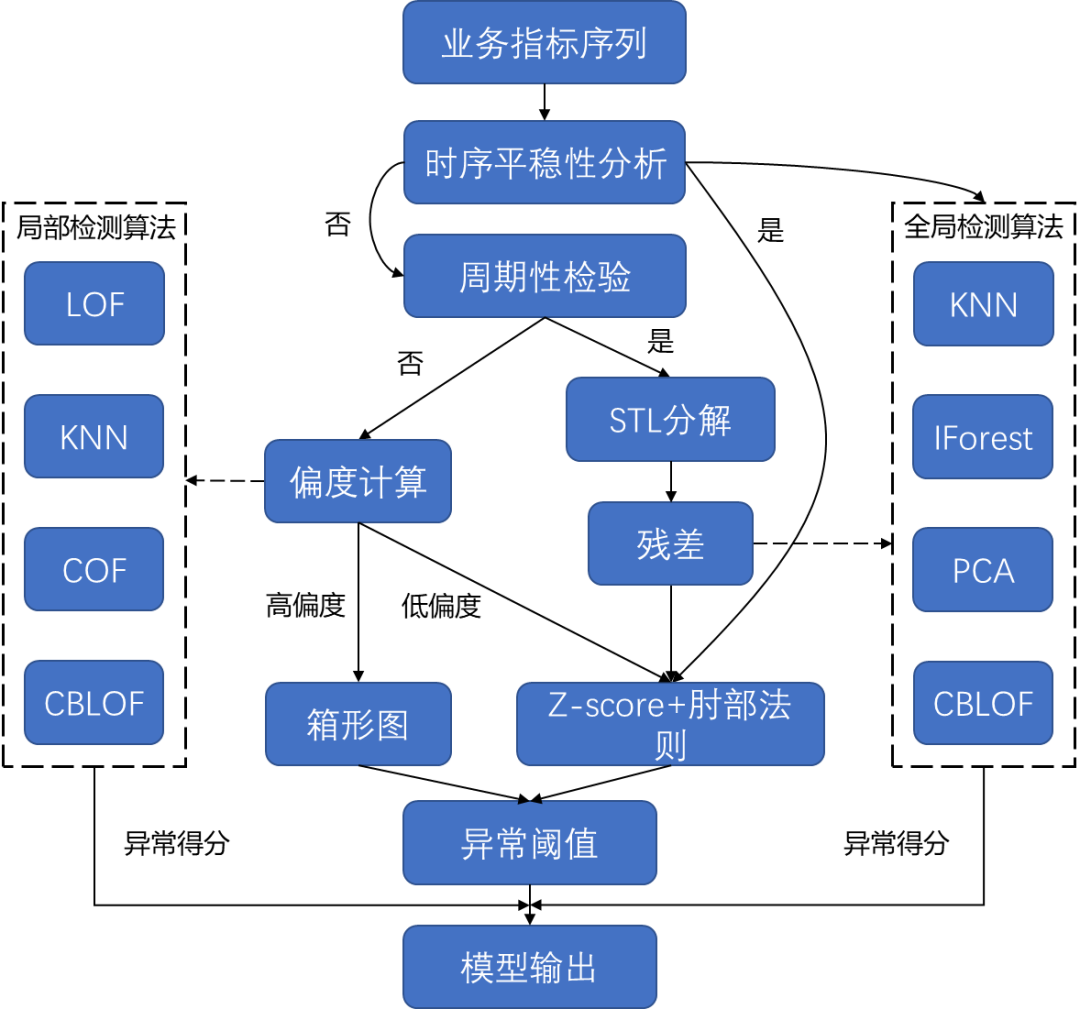
图3 异常检测系统流程图
经过如上分析之后,我们的异常检测分析流程如图3所示,主要分为时间序列分析、异常得分计算和异常阈值计算三个模块,下面我们分别介绍:
1)时间序列分析。当时序数据满足平稳型检验,直接使用全局检测算法进行序列的异常得分计算,同时使用Z-score+肘部法则的方法,计算异常得分阈值。当时序数据满足周期性检验时,使用STL算法提取时序数据的周期性分量和趋势性分量,将残差分量进行异常得分和异常得分阈值计算。当时序不满足周期性检验时,将时序数据转化为概率的分布图,如果偏度低于阈值,使用Z-score+肘部法则的方法计算异常得分阈值,否则使用箱型图计算。
2)异常得分计算。根据对异常类型的检出能力,分为全局异常检测算法组:{KNN, IForest, PCA, CBLOF}和局部异常检测算法组:{LOF, KNN, COF, CBLOF}。
3)异常阈值计算。箱形图是通过计算一组值的最大值Q4,上四分位数Q3,中位数Q2,下四分位数Q1,最小值Q0,来描述样本分布的离散程度以及对称性。一般情况下,箱形图不需要对样本进行任何假定,在对样本具有较高的异常容忍度的同时,能够描述样本的离群程度。
Z-score是描述一个值和一组值的平均值的偏离程度的统计测量分数,定义如下:z=((x-μ))⁄δ。肘部法则定义每个类的畸变程度等于每个变量点到其类别中心的位置距离平方和,随着类别数量的增加,平均畸变程度的改善效果会降低,而改善效果降幅最大的位置对应的值就是肘部,该方法一般用于聚类数量的选择。
这里我们结合Z-score和肘部法则,计算待检测时间序列的|z|序列,然后对其进行降序排列得到|z|desc序列,最后利用肘部法则得到肘部值作为异常阈值。
最后根据每种算法的异常得分和异常阈值进行分析,以投票最多的作为最后的异常结果。针对指标的重要程度设置不同的投票规则权衡精召率,比如更重要的P0指标,降低投票阈值保证异常不漏报,而对于不太重要的P2指标,适当提高阈值保证精确率。
2.根因定位系统
在我们的各类火车票核心业务指标中,都是多维度的可加性指标集合,当总指标被检测出异常之后,需要尽快定位是哪些交叉维度的细粒度指标导致了总指标的异常。
例如对于某个业务线的订单量指标A,它涉及到出发城市、APP渠道、订单类型等维度,各维度又包含一系列的维度值(元素),出发城市:北京,上海,广州等,APP渠道:支付宝小程序,微信小程序等,订单类型:国内,国外。当总指标A发生异常时,最可能的异常原因可以表示为不同维度的元素集合,如{订单类型=国内},或者{出发城市=北京&广州,APP渠道=微信小程序}等。这个查找定位交叉维度的细粒度元素集合的过程就是根因定位。
多维指标数据具有以下两个特征:
1)数据的总量大。指标包含多个维度,某些业务指标包含20+的维度,并且每个维度包含不同的属性值,比如城市维度包含全国600+属性值;
2)随着数据指标维度的分层,维度集合总数呈指数级增长,并且维度之间具有复杂的相互影响关系。
我们的问题可以归结为,在所有维度和维度值组成的集合里,找出导致总指标发生突变的维度和维度值子集。这样需要设计一个合理的得分函数,来评估每个子集是否是根因的得分,然后选出得分最高的子集即可,由于搜索空间很大,所以需要各种启发式搜索方法或者剪枝策略。
我们调研常见的几种启发式搜索算法:
Adtributor【2】算法假定导致总指标异常的根因只会出现在某一个维度上,它提出EP值(解释力)和S值(惊奇力)两个得分指标来评估子集,EP值表示该子集的指标波动和总指标的波动的比例,S值是指维度下各个维度值的取值分布是否有变化。它的核心思想是将多维度根因分析问题分解为多个单维度根因分析问题,采用解释力和惊奇力定位每个维度下的异常元素集合,最后根据每个维度总的惊奇力值大小汇总输出根因集合。
HotSpot【3】设计了一种叫potential score的得分函数,并显式的考虑了多个根因同时作用的情况,采用蒙特卡洛树搜索(MCTS)算法来解决巨大搜索空间的问题,并使用了分层剪枝策略降低搜索复杂度。
Squeeze【4】算法主要是针对HotSpot进行了三个改进,首先提出泛化的RE(ripple effect)原则,可以直接处理由可加性指标复合得到的率值指标;其次改进的PS(potential score)得分函数能捕捉到变化幅度较小的异常;最后是先对细粒度属性组合进行聚类,然后在每一类组合中去搜索根因,显著降低定位时长。
Psqueeze【5】是对Squeeze的扩展,它提出一种新的基于GRE(general ripple effect)的概率聚类方法,将属性组合分组到不同聚类中,然后根据GPS(general potential score)来评估属性组合是根因的可能性。

图4 根因定位系统流程图
最后我们根据火车票业务指标的特点,设计了如图4所示的根因定位系统,当异常检测系统检测到某个指标出现异常时,即进入根因定位系统。根因定位是根据指标真实值和期望值的差距大小来确定根因的,它分为数据构建和根因定位算法两个模块:
1)构建数据。首先对指标进行维度拆分,得到最细粒度指标的历史数据时间序列,再根据序列特性采用不同算法进行预测。如果序列具有平稳型,采用指数加权平均法(Ewma)进行预测,否则使用异常点前3个点位的中值作为预测值,最后结合历史值(真实值)和预测值(期望值)建立数据立方体。
2)根因定位算法。使用四种常见的根因定位算法分别定位,组成硬投票系统,按照票数倒序输出根因集合。根据火车票核心业务指标维度和维度值多的特点,结合奥卡姆剃刀原则思想,微调了Adtributor算法EP值阈值,以及对Hotspot算法的PS评分函数进行修正,在不损失根因定位准确率的情况下尽量精简根因集合。考虑到检测时长,当待检测指标元素组合数量大于1000时,不使用Hotspot算法,元素组合数量超过10000时,只采用Adtributor进行根因定位。
三、异动归因实践结果
案例业务背景:出行相关的票量受自然天气影响较大,当出现极端天气时,票量一般会出现突然下跌或上涨,如图5所示,该情况需要及时识别异常,并分析出引发指标异常的相关维度和维度值。
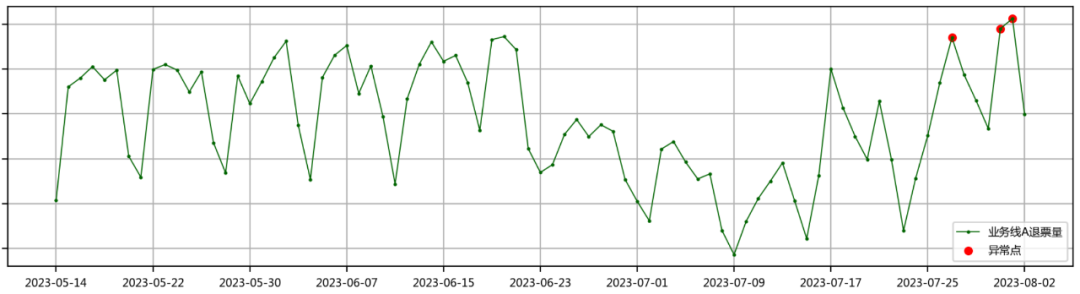
图5 业务线A退票量的异常检测结果
随着台风“杜苏芮“在7月24日被中央气象局升级为超强台风,并在28日上午登陆福建省晋江市,近日来造成多地区出现极端强降雨现象,导致大量交通工具延误甚至取消。图5展示的是业务线A在近两个月的退票量情况,退票量有较明显的工作日高于双休日的周期性规律,7月27日,7月31日和8月1日出现较明显的退票小高峰,符合需要识别异常点的预期。
在检测出异常之后,根因定位系统对出票票量的城市维度进行根因定位,结果如表2所示:

表2 根因定位结果表
为了分析根因定位系统的准确性,我们手动计算城市维度的根因得分,然后对比算法和人工分析的异同。首先根据adtributor算法的检测原理,分别计算EP值和S值,方程式如下:
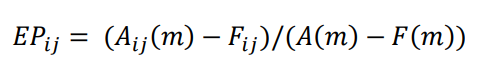
其中,A为真实值,F为预测值,下标i为维度名,j为维度下的元素名,m为异常指标名。
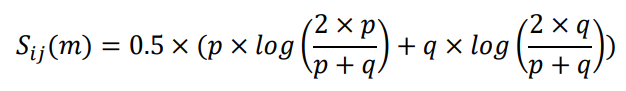
其中,p为先验概率,图片,q为后验概率,图片。然后以EP和S的加权和作为根因得分RT_score,得到不同异常日期的城市维度的人工根因定位结果,如图6所示:

图6 不同日期城市维度的人工根因定位结果
从图6可以看出,7月27日的退票票量异常,从出发城市维度分析,主要是由揭阳和厦门造成的;从到达城市维度分析,主要是由厦门和南昌造成的,人工定位的和算法检测的根因结果相符合。而超强台风杜苏芮正是在7月28日登陆福建,造成东南沿海部分城市出现暴雨天气,导致大量航班和列车取消或者停运,从而影响所在地区城市的退票票量异常升高。
7月31日和8月1日的退票票量异常,不论是从出发城市还是到达城市分析,北京都是引起退票退票升高的首要原因。这与根因定位系统的检测结果吻合,并且能将变化幅度大但是体量小的城市剔除。
比如7月31日的出发城市维度分析,威海和大理的RT_score较高,但是由于其退票量体量很小(只占南京15%的票量),算法没有将其判定为根因。这两天退票量异常的根本原因依然是受超强台风杜苏芮的影响,7月29日至8月1日杜苏芮在华北地区造成“远距离台风暴雨”,北京地区超300趟次航班取消和43趟列车停运,导致北京市退票量异常升高。
这个案例较好的展示了异动归因系统对陡升型异常的检测能力,同时能快速并且相对准确的定位到导致异常的原因。
四、总结和展望
1.总结
本文主要介绍了异动归因系统在火车票业务指标上的初步应用,首先分析业务指标的时间序列类型,以及不同业务数据出现的异常类型,针对指标的异常类型选择合适的检测算法。然后利用根因定位系统发掘引发异常的原因,根据不同的数据类型选择相应的预测算法,构建根因定位数据集,最后利用四种根因定位算法进行根因定位。
目前异常检测系统处于试运行初期,仅针对核心业务指标做监控,对平稳型时序和强周期型时序的异常检测能力较好。随机挑选了部分指标的异常检测案例,对照人工核验结果,精确率为67%,召回率为83%,F1-score为74%,为了满足核心指标减小漏报的需求,调低投票阈值以提高召回率。后期针对接入的非核心指标,可以适当调高阈值提高精确率。
在节假日出行期间,大部分指标迎来一定程度的连续性上涨,这部分日期很容易被算法识别成异常,但绝大部分异常在业务上属于正常的数据波动。目前的做法是对结果做后处理,将节假日的异常设为正常,这样虽然能避免误报,但会漏掉少数真实的异常。一种可以尝试的做法是,对去年同期的数据计算波动情况,根据阈值来判定异常。不过由于火车票业务发展迅速以及疫情原因,往年同期的数据参考意义不大,并且不同业务线指标的阈值设置和调整也是个问题。
最近几年由于疫情的影响,以天为单位的出行相关指标,周期规律难以捕捉,进而影响STL分解的准确率,导致检出难度大,这也是目前不选择通过对比实际值与预测值的偏离情况的方法做异常检测的一个重要原因。
根因定位系统可以较准确定位出维度较少的根因。多维度交叉的根因由于数据量大,细分到细粒度指标的KPI统计值就小,而值较小的时序容易引起较大的预测偏差,从而影响根因定位的准确性。
2.展望
1)提高其他时间序列类型的检出能力。比如时间序列漂移现象,平稳+漂移,周期+漂移等类型;
2)新增不同类型异常的检出能力。目前异常检测算法对指标陡升和陡降异常具有较好的检出能力,而对整体抬升或整体下降异常,连续性异常的检测能力不佳;
3)在业务需要的情况下,提高多维度交叉的根因定位准确性。

