AB实验平台建设实践助力业务决策
导读:AB实验是因果推断的黄金法则,能够帮助我们无偏的获得因果效应,从而帮助业务进行更好的决策。
而双边市场作为特殊的实验场景会存在网络效应等一系列特殊的挑战,如何从实验方式和实验平台设计上应对这些挑战是双边市场主体在科学实验上亟待解决的问题。
基于此,本文对Uber、Lyft、Doordash等在双边市场下提供供需匹配的公司进行实验科学与实验系统的调研,为双边市场的科学实验提供参考。
01 高峰附加费实验
1.1 一般定价因素拆解
以Uber为例:
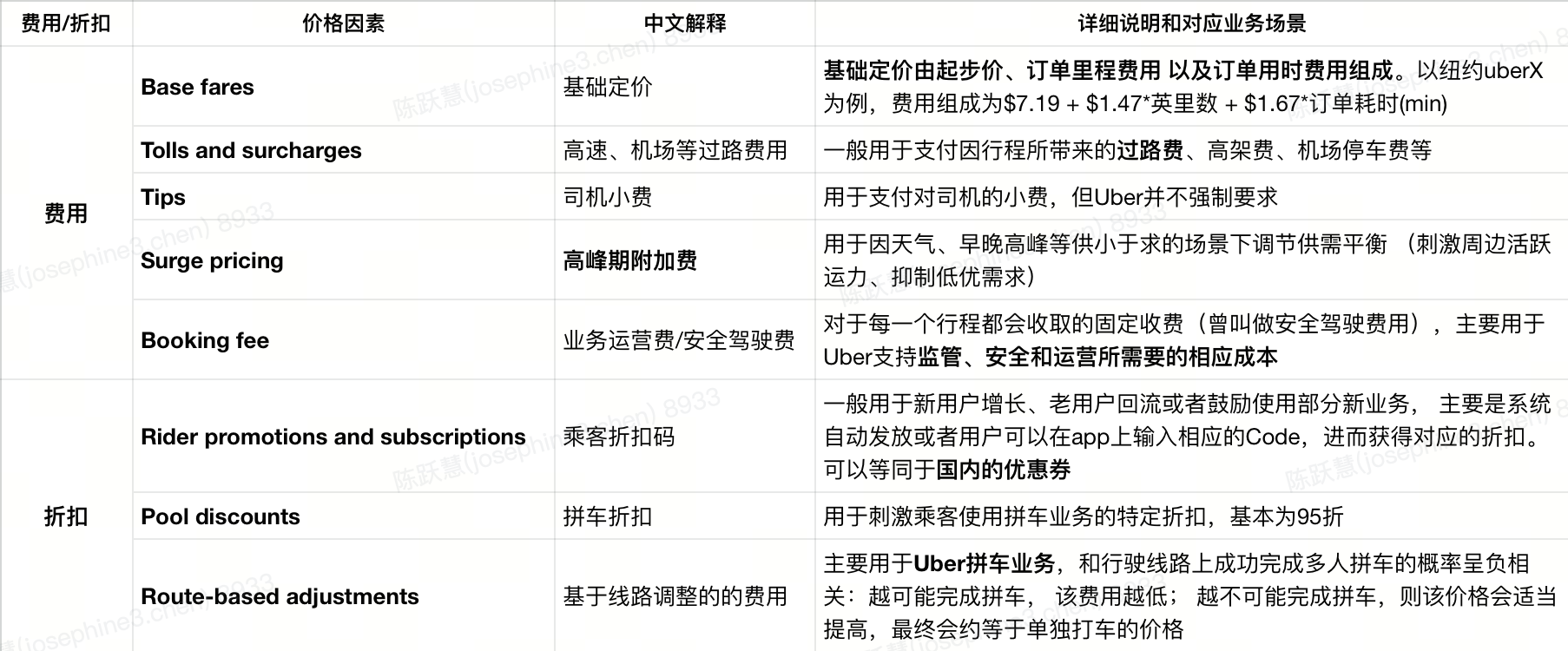
1.2 高峰期附加费详解
1.2.1 Uber
Uber利用自家开源的地理空间索引系统,将城市的空间以及Uber的订单映射到每一个六边形网格上。当某个区域内同一时间订单大幅增加、单司比大幅增加时, 附加费会触发。
在用户进行下单估价时,附加费会以平时X.X倍的形式(见下图)体现在用户端,并告知总费用是多少。
而司机端也可以通过热力图的方式看到附加费热区和冷区,以帮助司机进行更好的决策。

UberH3网格介绍:H3是一个由Uber开源的地理空间索引系统,是一个针对地球空间的离散全局网格系统,该系统由具有层次结构索引的球形多精度六边形拼贴组成。
1.2.2 Lyft
Lyft的高峰期附加费经历了四次迭代,整体变化如下:

1. V0:保证服务可用性 (Guarantees Service Availability)
通过排队论中的多服务台排队系统(M/M/c)对市场中司机利用率与司机可用率的关系进行建模。
在高峰期时,当预测到司机可用率会下降到一定阈值以下,就可以提高价格,以此保证服务可用性。
同时通过此关系建模,也可以更好的衡量司机规模带来收益 (即随着总注册司机数的增加,在司机可用率不变的情况下, 司机利用率也可以升高)。
2.V1:提高服务可用性 (Improves Service Availability)
在V0的基础上去除掉用户对价格调整的反馈是一致的强假设, 并通过指数函数对转化率与价格之间的关系进行建模。当已知某时空区域内的业务预期的司机可用率、当下要下单的乘客数 以及 当下总司机数,则通过模型可以返回价格需要调整到的目标值。
3. V2:提高服务标准 (Improves Service Levels)
V0和V1的重点在于减少极端供小于求的情况 以及该情况下乘客频繁发现周边无司机的现象,但在相对不极端的供小于求的情况下,前两版虽然可以让服务可用,但会导致过长的等待时间;
因此Lyft在此轮迭代中,是以等待时间为目标进行相应的附加费调整:
1. 先通过空间泊松过程对ETA和可用司机数进行关系建模;
2. 进而结合过去的迭代,Lyft可以根据目标ETA、当前的市场环境(总司机数、可用司机数、可能会下单的乘客数) 以及模型的超参等,推算出该时空下价格需要调整到的目标值。
4. V3 and Beyond: (Optimize Network Throughput)
前三个版本都聚焦在特定时空下的供小于求情景,但打车场景下,某网格内的司机调度、用户过量请求同时也会影响邻近网格的订单履约情况;例如如果只聚焦于某个供小于求的网格,对附加费调整不设置上限,则可能会严重影响周边网格的订单履约。
因此,本阶段全局考虑同一时间下包含供小于求的空间以及邻近空间的整体供需和履约情况。
1.3 高峰期附加费实验方式
1.3.1 时空分片轮转实验
(1)时空分片实验方式
诸如Uber、Lyft、Doordash、滴滴等公司的业务模式均是在双边市场下提供相应的供需匹配,因此此种业务模式在进行传统的A/B/N实验往往会面对因网络效应而带来的指标观测偏差。
网络效应即同一时空下,用户的需求会共享同一批运力池。如果简单对用户进行随机分流,那么对实验组用户的策略不仅会影响实验组本身,同时也会影响对照组下的其他用户, 进而天然违背了A/B/N实验下的个体干预稳定性假设(SUTVA),即实验组个体不会影响对照组个体。
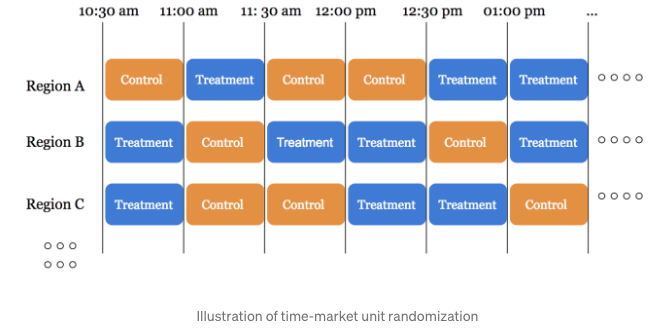
因此为了更好的在双边市场下进行科学合理的实验,Doordash采用了时空分片的实验设计,即在同一空间下,以及连续时间分片,实验组对照组轮转生效,主要如下:
1. 在进行高峰期附加费实验(SOS pricing)时,将单个时间片长度设计为30分钟,并对一天的时间进行切分;
2. 时间片下的实验策略随机生效,而非定序轮播;
3. 同一时间片下,不同空间区域单独随机,例如10:30-11:00下, Region A可能是对照组,而Region B会是实验组;
因此策略随机的单位会是由时间和空间组成的时空分片:
(2)分片颗粒度测试
时空分片实验设计其中一个重点在于时间片和空间片的颗粒度设计:
时间片长度越小,相同时间内的单位集合基数越多,集合间的同质性越好,variance 越小,但运力竞争影响越明显,bias 越大;
时间片长度越大, 相同时间内的单位集合基数越少, 集合之间的同质性越小, variance越大;但响应的随着时间片长度的增大, 运力竞争的影响越小,甚至没有, bias越小。
Bias:来自于因共享运力池/供给池,实验组个体会对对照组个体产生间接影响而带来的干扰
Variance:取决于随机分流时单位的颗粒度,和由此带来的不均匀

Doordash通过进行长期AA实验,并对时间片和空间片进行颗粒度大小不一的切分。通过对比不同颗粒度下误差界限以及标准差,也证明了上述Lyft对于分片颗粒度的认知(Doordash一般会将其时间颗粒度定为30分钟, 空间颗粒度定为城市)。
(3)实验评估方式
核心指标的评估方式一般有两种,即简单平均和加权平均:

(4)时空分片实验设计优化:减少延滞效应
时空分片实验下,由于实验设计为同一实验单元依次命中不同策略,所以上一个时间周期的策略效果会影响下一个时间周期的策略效果, 这种影响在交叉实验中叫做延滞效应 ( carryover effect)。
以滴滴客运业务为例,相较于需求,供给侧的资源往往是有限的,而平均一个司机完单时间约为20分钟,因此运力往往需要20分钟能被释放, 如果时间片太小, 则可能会造成运力竞争。
运力竞争:往往出现在播单相关AB实验,优势组可能会匹配出更优质的运力,而弱势组因运力在某个时空下相对有限, 因此只能匹配弱势运力。进而导致强者更强,夸大实验组和对照组之间的策略效果
2021年,学术界提出了如何更好地在时空分片实验设计下减少延滞效应的方式,即通过运筹学优化,寻找将下述衡量延滞效应造成的混淆现象最小化的参数组合,最终相较于传统时空分片在等节点进行策略的变换,新的优化方案会在不同的节点上进行策略变化,如下图:
在传统时空分片下,可能会在1、4、7、10策略会进行随机, 每一个策略会完整覆盖3个时空分片;
但在新的优化方案下,会在1、5、7、9进行策略随机, 不同策略覆盖的片数会不一致;
因此在实验评估时,指标计算也需要对片数不一致而带来的bias进行消偏。
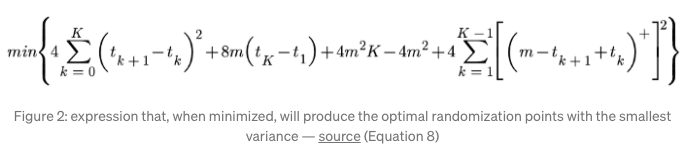

1.3.2 随机饱和度实验
2008年时,学术界提出了通过随机饱和度实验的方式以更好的衡量网络实验下网络效应带来的影响 ,即实验组的实验结果不仅取决于实验组个体本身,还会受到对照组的影响。
而从公开文献上,Lyft也曾经以随机饱和度实验的方式进行一定应用;同时 Airbnb以及MIT的学者也曾经应用该实验方式对Airbnb双边市场下的部分实验。
(1)随机饱和度实验简介
随机饱和度实验,也叫做两阶段随机化实验。顾名思义,该实验设计方式在设计过程中分别进行了两次随机,其中饱和度可以理解为在簇(cluster)中接受实验策略的比例。
整体实验设计流程可以抽象为以下三个步骤:
确定实验中独立且同分布簇的存在形式,例如地区、路线、用户、时间片等;
确定实验需要以及可以支持的饱和度集合,并随机给簇分配饱和度,一般饱和度边界为[0,1],即允许该簇内可以全部都为新/旧策略;
按照簇cluster被分配的饱和度随机给簇中的实验对象分配干预。
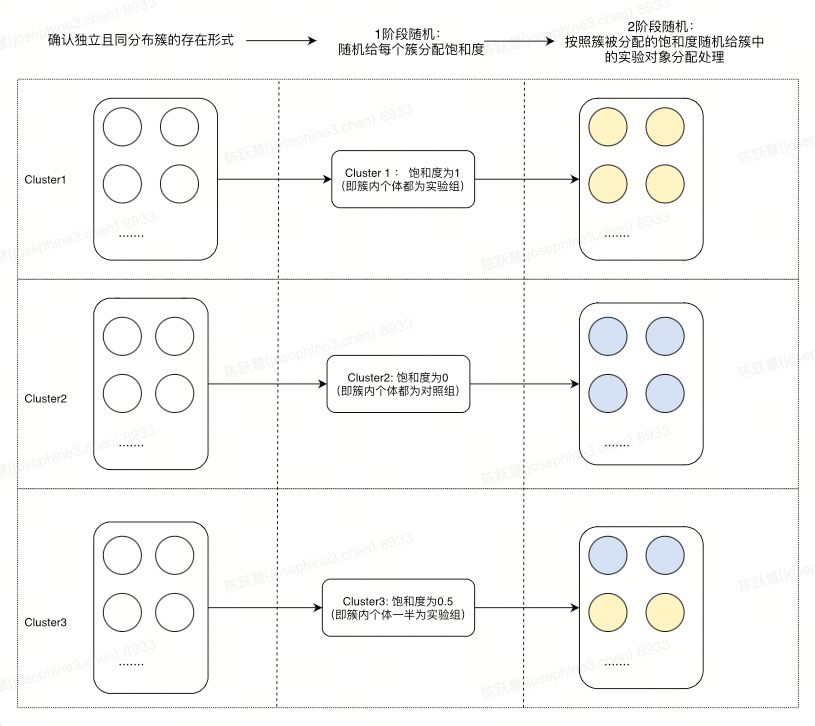

通过确定独立且同分布的簇,可以尽量减少簇与簇之间的互相干扰,进而尽可能的实现A/B/N实验中的个体干预稳定性假设,如:
在外卖行业中,通过对空间进行聚类,尽可能保证每个簇内订单都是被簇内的骑手接单,没有骑手跨簇接单;
在IM业务中的社交实验,用户之间会互相沟通,进而导致直接对用户随机分流,也会造成网络效应。因此可以通过对用户进行聚类,尽可能的将互相沟通的用户分到一簇,用户簇之间尽可能保证独立。
(2)实验评估方式
如果实验设计允许饱和度存在0和1的簇,那么直接对比这两组簇中的实验对象的指标就可以得出实际策略带来的核心指标变动;
如果实验设计中饱和度为(0,1), 则需要通过建立 实验饱和度与干预效应的线性关系,通过线性模型对比不同实验饱和度对于实验指标的影响;通过建立线性模型
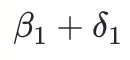
即为全量干预效应

02 Uber实验系统
2.1 实验系统整体概览
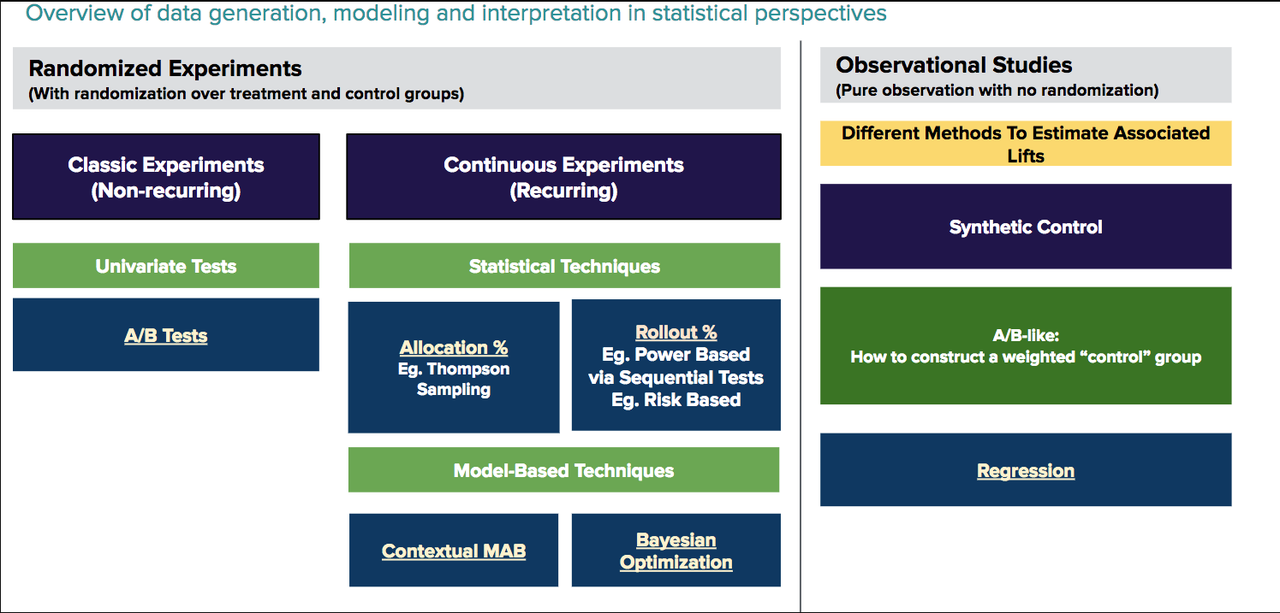
Uber实验系统,又称为XP,在整个科学迭代的过程中扮演了重要的角色,包含对于产品features、渠道投放、市场营销、模型迭代等多种迭代的发布、debug、效果衡量以及线上效果监控。
XP可以支持对于司机、乘客、Uber Eats 、Uber Freight(Uber货车)等多Apps和业务的迭代,并可以覆盖诸如传统A/B/N实验、因果推断、基于多臂赌博机算法的连续性实验等多个实验类型。
2.2 实验系统特点
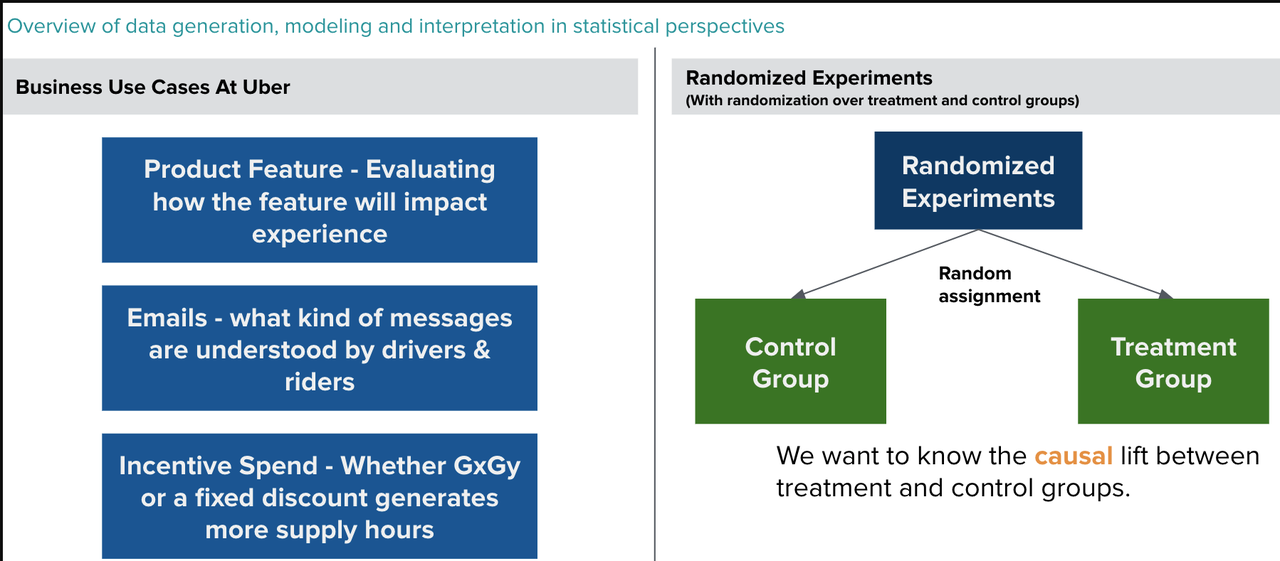
典型的A/B or A/B/N实验可以被认为在很多科学领域用来评估策略收益的黄金标准。包含简单的用户ID、司机ID的随机分流, 也同样可以用于上述提到的Switchback 时空分流实验。
Uber实验的典型场景包括:司机端以及用户端的功能层面上的改动;邮件营销,何种信息内容可以更容易被用户和司机理解;司机奖励是否可以鼓励司机服务更长时间;匹配策略以及定价类实验(分流单位会变成时空片)等。
Uber实验系统特点主要有:
2.2.1 实验分组的同质性检测 (Pre-existing Bias)
AB实验之所以可以成为黄金标准的前提假设是控制变量,即实验组对照组中除了想要观测的策略/变动以外,没有其他的区别。
Uber提供了对各分组下的同质性进行检测,确认在各组中是否有预先存在的偏差和不同;例如实验组和对照组天然在某些维度下分布不同、实验组天然有更好的司机。
2.2.2 科学多样(Statistics Engine)
为了更好的衡量我们当下观测到的指标是否置信,分析师往往会借用统计学进行相应的检验。但不同指标类型、是否齐方差等假设的不同往往需要不同的统计学检验方式。使用错误的统计学检验方法可能会导致错误的结论,进而影响业务迭代;
因此Uber实验系统为了保证检验的标准型以及减少使用人员相应能力的准入门槛, 在实验系统层面可以自动适配最合理的统计学检验方式。

2.3 连续型实验
2.3.1 连续型实验适用场景案例
1. 【内容优化】对于某个突发新闻,怎么样的标题文案才可以有更多的读者点击和阅读?
传统A/B/N测试选出更优标题的耗时较长,突发新闻的有效性可能只有短短几天,因此对于突发新闻的新闻标题这种重时效性的需求场景并不适用。
2. 【模型参数调整】超参很多时,如何在有限的时间下快速找到数据表现最好的超参组合?
超参过多时相应的组合就会很多,此时传统A/B/N测试需要更多耗时以及对应的更大的实验成本。
3. 【广告优化】BlackFriday 黑五当天电商广告网站的促销活动优化,哪种优化更能有收益?
黑五短期促销(尤其是季节性和节日促销)同样注重时效性,这种促销就存在于黑五及其前几天,因此面对这种天然短期且注重实效的业务场景下A/B测试可能并不适用。


2.3.2 连续型实验处理方法
从探索更优迭代策略到更优策略的应用的角度来看,传统的AB实验会清晰的划分出上述两个阶段 (第一个阶段进行实验,第二个阶段全量优势组)。因此会有以下两个问题:
从测试直接跳至应用,缺少中间的过渡阶段
测试阶段试错成本较高,容易造成资源浪费
Uber相应团队通过多臂老虎机算法(Multi-Armed Bandit)与贝叶斯优化处理上述业务情景下的问题,Bandit算法不对测试和应用阶段进行明确的区分,而是将两者同步进行,动态调优。
Bandit算法优势:最大限度地降低机会成本 or 实验试错成本(即:玩家每次操作老虎机的实际收益和最理想收益之间的差异)
Bandit算法潜在缺点:
1)相较于传统ab测试,Bandit算法需要更多的人力成本和工程开发;
2)bandit算法无法很好的处理更优选项判定的时间成本和收获更优效果的时效性需求间的矛盾;
3)Bandit算法可以动态的在短期内找到最优选项,但对于那些需要长期才能体现的策略 或者 需要观测长期效果的策略,Bandit并不适用。

03 总结
双边市场的定价是一个复杂的系统工程,Lyft的高峰附加费更是经历了从可用到全局优化的四次迭代。
为降低高峰附加费场景下因网络效应而带来的指标观测偏差,Doordash采用时空分片轮转实验方式加以应对,学术界则进一步在该实验方式下通过运筹优化来减少延滞效应,同时通过随机饱和度实验更好的衡量网络效应带来的影响。
此外,Uber实验系统通过对不同场景下实验的分流同质性、检验科学性方面进行规范化和流程化,支持高效科学实验,也可为实验平台建设提供思路和方向。

