存储方案作为产品——Midgard探索
导读:互联网业务大多是围绕数据展开,获取、生产数据,投入到产品中为用户服务。百度的搜索业务正是典型的数据密集业务,数据规模大,使用方式多样,极为关注如何构建高效低成本的存储系统。
然而软硬件技术升级、业务增长与变迁从未停止,一个久经验证的方案可能在短短半年后就偏离了设计之初的更佳状态。Midgard是搜索场景下提出的智能化的数据存储方案管理器,本文简要介绍了Midgard如何有效利用数据自身提供的信息,如何利用存储系统的先进特性,始终保持数据服务的高效低廉。
01 存储需求如何变动
为了说明业务和技术同时驱动着存储方案的变化,此处举一个较为容易理解的例子:网页的倒排索引构建。假设我们要经营一个叫做tendu的检索服务,业务就是接受一批网页集合,并对这些网页提供检索服务,当网页集合或者网页内容发生变化时,也将这些变化更新到检索结果中。
1.1业务起步——方案 1.0
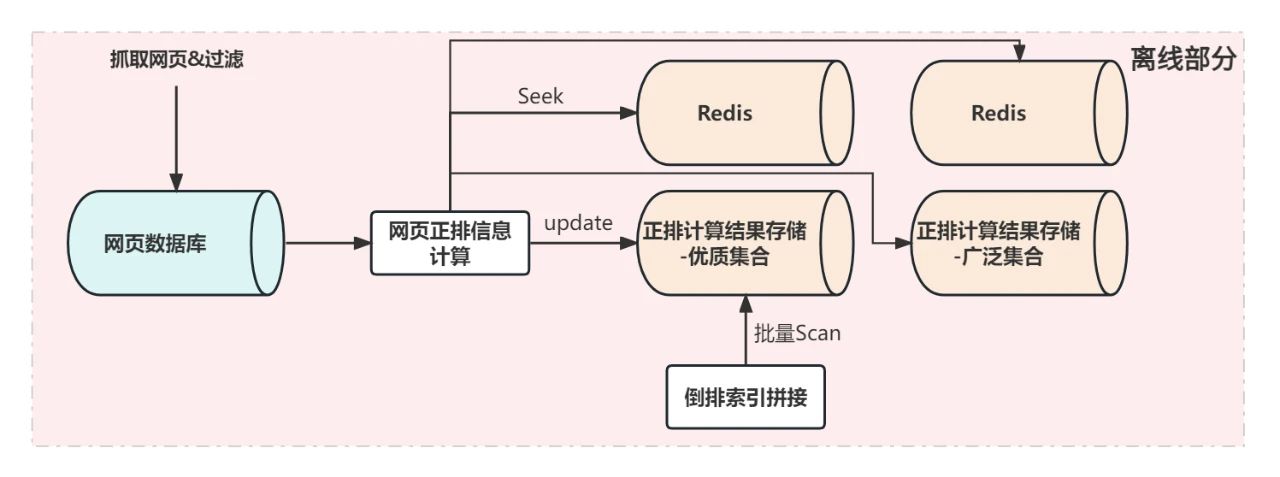
tendu业务初起步的时候需求是非常简单明了的,因为规模和性能并非瓶颈,需求说明往往是流程性的。我们给出下面这样一个模型来示意这批网页的检索服务应该如何构建:
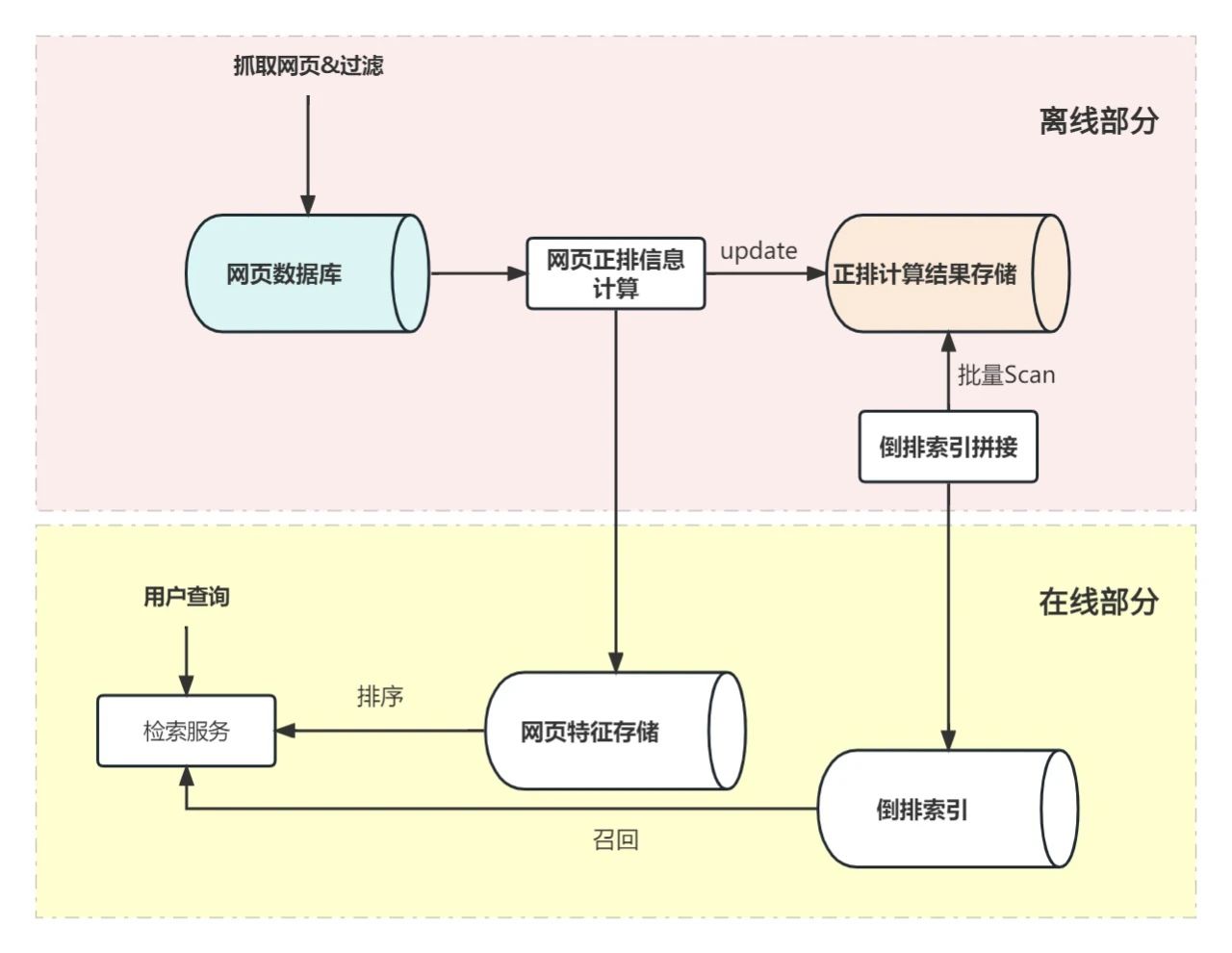
为了说明清楚,上图中完整表述了离在线的结构,但是在本文中,我们只关注离线的部分。除去网页数据库之外(假设这个数据库在我们的目标之外,并且极为稳定),最为主要的数据组件就是”正排计算结果存储“这个数据库,这个数据库有两个主要作用:
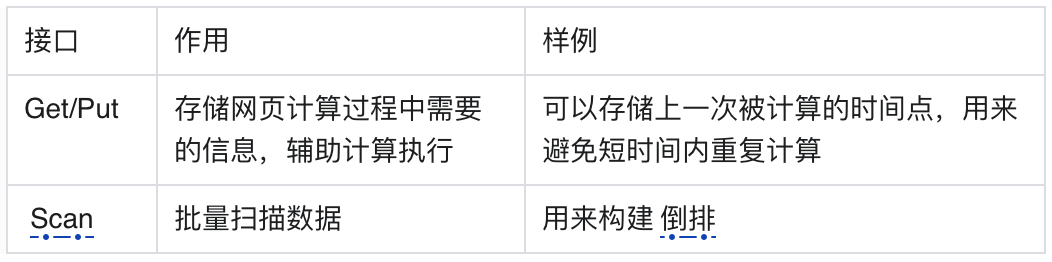
这时我们可以看到这个数据系统的需求是明了简单的:
1、根据key和数据名随机读写数据。
2、全量扫描所有数据。
那么一个简单的类Big-Table表格存储系统就可以解决上述问题,此时我们的方案是1.0版本,计算系统面对唯一一个数据库,使用Get/Put接口来计算网页正排数据,使用Scan接口来扫描数据全集组装倒排。
1.2 快速更新 —— 方案 2.0
随着tendu的用户越来越多,用户也发现了产品有一些问题:更新非常慢,一个已经更新到第10话的漫画,在检索结果中,依然显示为一周前的第2话。面对这些用户反馈,业务很快总结出了这个阶段的新目标:提升更新速度。在1.0方案当中,整个系统的需求都是流程性的,在这个目标下,只要正排对应的网页特征以及倒排索引被正确的产出,这就是一个合格的方案。为了完成更新速度提升的目标,业务需求补充了一些量化描述:
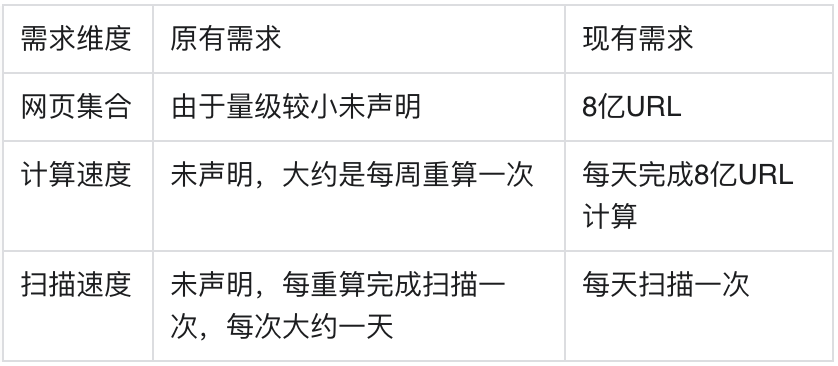
我们在1.0当中采取的类表格存储很快遇到了瓶颈:计算过程中需要从数据库当中Get一些列,而1.0方案中采用了HDD介质的数据库来存储所有数据,HDD介质的随机IO能力非常低,要提升随机Get的吞吐量则需要非常高的成本,为此,我们重新修改上述的架构。
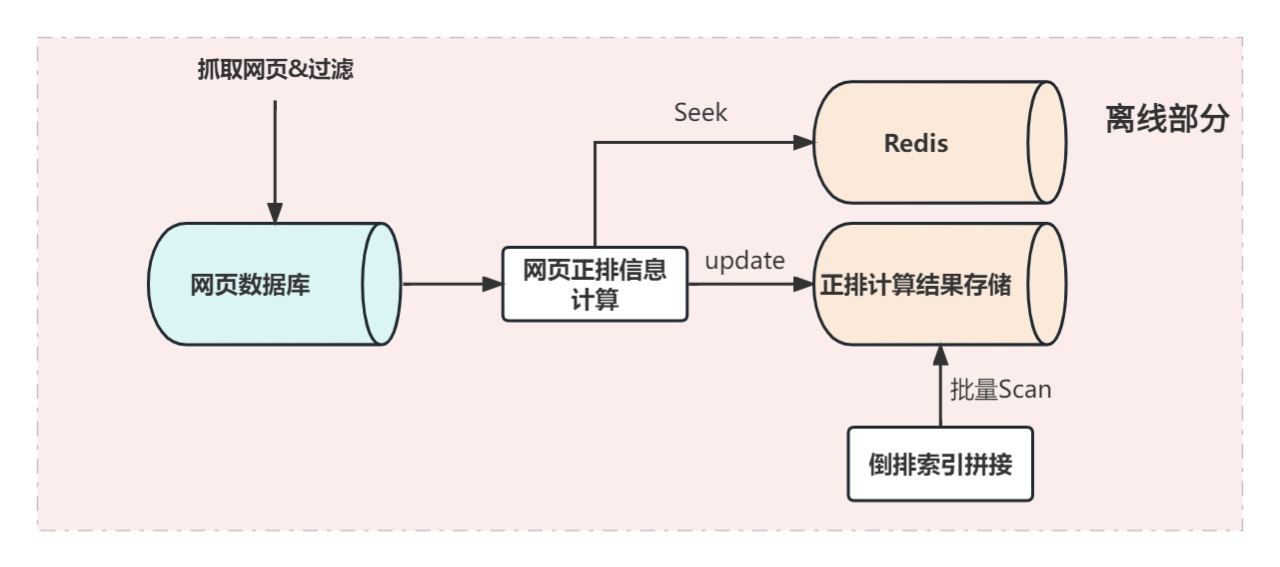
经过业务的一番分析发现,有频繁Get需求的只是一部分非常少的数据列,大约只占数据库整体的5%,因此需要一个支持对小体积数据进行高频查询的存储服务。我们在这里增加了一个redis作为这个类型数据的缓存,正排计算服务的随机Get请求发送给Redis,写入请求同时发送给Redis和我们的表格存储。至此,使用HDD和内存混合存储的方案基本满足了业务的快速更新需求。
1.3大范围收录 —— 方案3.0
随着更新速度越来越快,用户在检索服务上可以得到的结果越发精准、有效,业务效果广受好评,但是也迎来了新的产品需求:有一些小众的需求不是大多数人的需要,但是恰好有一些网页可以满足这部分需求,这部分网页的数量是非常巨大,但是往往更新并不频繁。此时需求中出现了两组数据集合:
优质集合
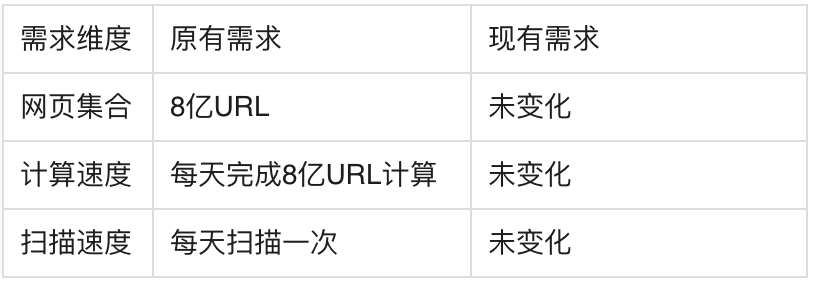
广泛集合
为满足分别的扫描需求,做出分库分表的方案,一个库存储优质集合,另外一个库存储广泛集合。
02 引入存储方案层
2.1 精细化存储方案的问题
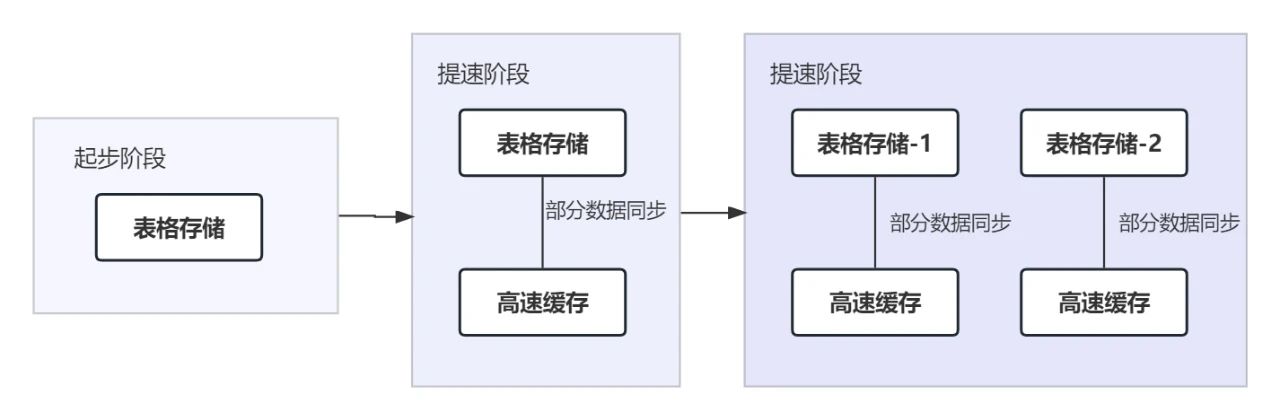
如上,我们讲述了一个检索服务的演变,为了不断适应新的业务需求,不停变换存储方案。带来的结果是:
1、存储效果——到达了较为理想的状态。
2、存储后端数量翻倍(1到2)再翻倍(2到4)。
3、不同存储之间的数据存在关系,这些关系需要所有业务计算模块知晓,管理成本上升。
2.2 Midgard——存储方案管理
开篇的例子很好的说明了存储方案调整的方式,根据数据使用需求、结合存储介质特性,反复迭代。Midgard是基于这一思路做出来的数据层,让业务脱离对具体存储的管理和维护。用户可以使用变更需求描述的方式表达业务变化,而代码和各种设施层面则不需变动,因为Midgard提供了稳定的接口。
核心结构——按名访问数据
Midgard的核心可以看作以下几个部分:
1、Meta模块,元信息管理,存放了各种数据的基础配置信息,比如某字段是否拥有Cache,存储在何处。
2、Server模块接口层,处理用户请求,将用户请求根据元信息加载进来并进行预处理。
3、算子/执行器层,接口层会将用户请求编译成多个算子,并组织成一定结构交给执行器执行。
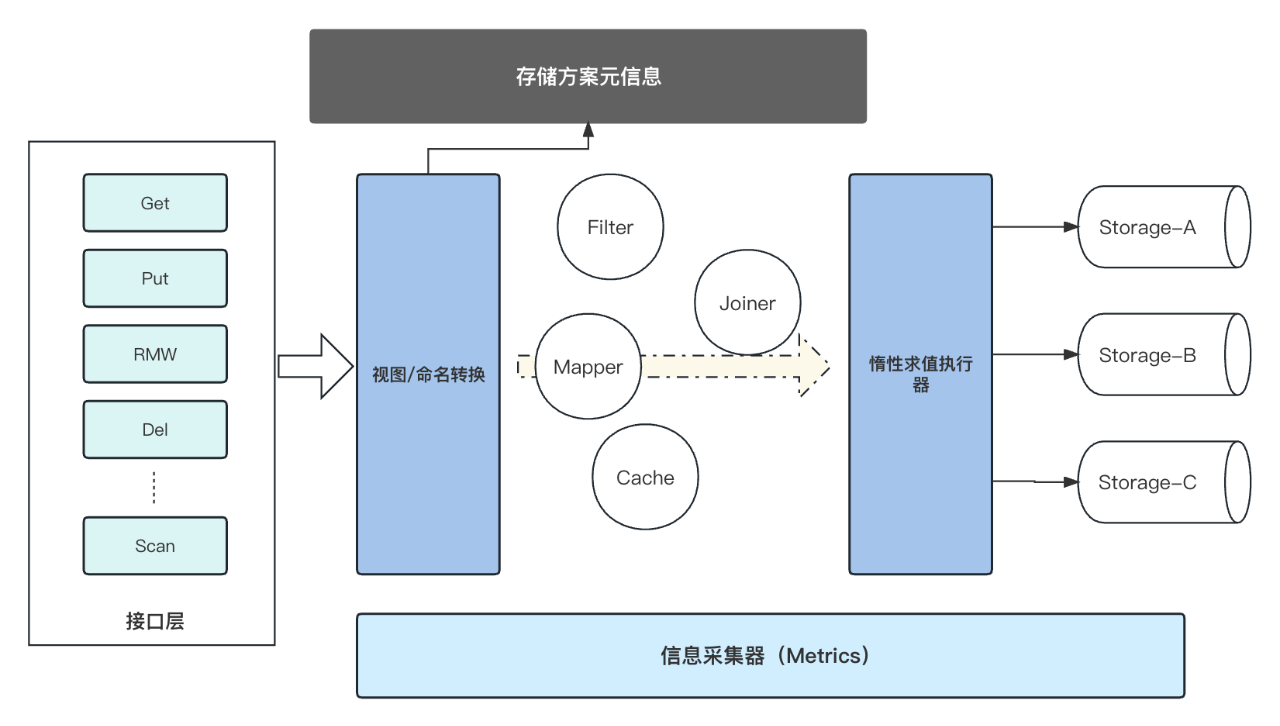
通过较为简单的分层结构满足了数据名与接口实现分离的要求,算子和执行器通过从Meta模块获取的编排信息就可以知道有哪些步骤需要执行,接口层面则对用户完全屏蔽掉这些细节。并且修改Meta当中的信息就可以修改一个数据列的具体行为,实现了数据存储方案的灵活管理。
按需调整能力
1、用户向Midgard注册数据接口的需求量
例如数据PAGE_SCORE需要get接口供给1000QPS的服务能力
2、根据业务需求,修改存储方案的元信息
一般来说业务会有两类需求:新增添加数据,定期更新存储方案重新调优
3、稳定使用
4、Midgard根据从执行器和存储服务上采集到的数据反过来优化存储方案
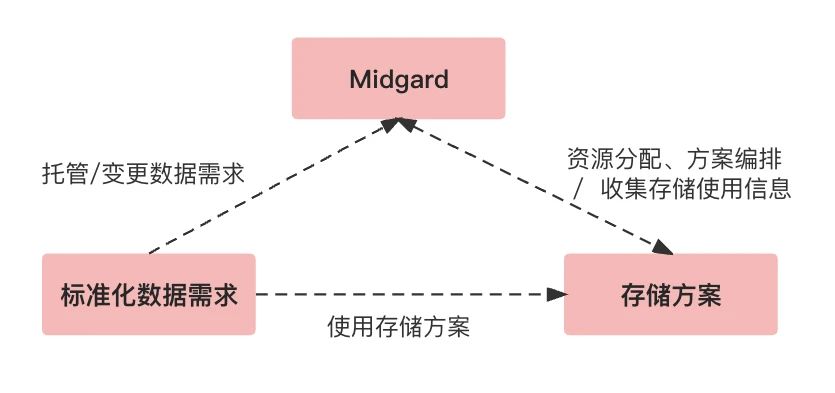
从上面的示意图来看,Midgard是数据需求与存储方案之间的桥梁,接受各种需求,落地成各种存储方案,后续再根据从执行层获取到的后验信息积极的调整存储方案。在我们一开始举的例子当中,那些嵌在各个业务代码里的存储间处理逻辑,对业务就可以简化成一步:对Midgard更新数据需求描述,并且业务无需管理这些具体的存储组件,当我们要开展一个新的业务时也可以复用我们现有的技术方案。
组合计算能力
此外,得益于执行器的结构,每个操作都是由若干个独立的算子组合形成的,Midgard因此具备一定的组合计算能力。举一个例子:现有两张表,表A包含了网页的主要信息,表B是一个用户评分系统,记录了用户对网页的打分,其中有一项sham_score标记了用户是否认为网页有虚假信息,并且这一列加载了cache。我们现在想要组装一个任务,从表A中定期扫描所有的网页,将sham_score>5的数据全部清除。一般来说这可能需要一些复杂的代码来同时读取三个存储:a) 表A b) 表B c) sham_score的缓存,但是Midgard的组合计算能力,可以将细节隐藏在冰山之下。用户传递给Midgard的可能是一个简单的原语序列:

这样一套逻辑如果由各个业务单独实现可能会非常繁琐,但是得益于Midgard算子的原子化拆分,很容易通过简单组装完成数据的功能组合。
03 结语
整体来说,Midgard是搜索的数据系统在智能化方面的尝试。很多数据业务都是人工了解业务诉求、分析合适的方案,方案一经制定极少变动,只有在极少数大规模架构变革时顺带修改。这种运营模式依赖人工经验,缺少持续维护的途径,并且在产生新的技术突破时很难惠及存量业务,而且会随着时间推移,需求的变动使得最初的方案设计逐渐腐化。Midgard希望提供一个对业务稳定的数据接口层,让存储方案变更对业务屏蔽,并且具有长久的可维护性。例子当中的分表和缓存也不是Midgard仅有的能力,未来可能会接入更多的功能和方案选择,让存储系统面向数据使用者,持续迭代。

