推荐系统范式之争,LLM vs. ID?
TLDR: 本文与已有的LLM4Rec一个主要区别在于,已有的ChatGPT4Rec文献大多是调用OpenAI API来做prompt工程,本文则是将1750亿的GPT-3作为item encoder替换ID。为了对该范式(论文称之为TCF范式,在过去几年涌现了大量相关论文,不过多是使用BERT,word2vec等中小型item 编码器)性能进行极限研究和评价,论文甚至对600亿LLM做微调或者重新训练,目的是为了回答基于文本的推荐范式的若干核心问题,相关实验可以看出完成该论文的算力成本之高。

论文:arxiv.org/abs/2305.11700
研究动机
推荐系统模型经典ID(userID、itemID及各种categorical ID)范式已经主导社区长达10年,是否有望继续主导下一个十年?与此同时,LLM(超大语言模型)在NLP乃至整个AI领域都掀起了巨浪,展示出近乎超越人类的语言理解和生成能力。那么,一个自然的问题:如果将文本item用LLM表征,是否能大幅超越原有的ID范式?基于此,论文进行了极限研究,采用175B参数的GPT-3作为item encoder,并进行了一些计算成本极其昂贵的实验验证(如微调600亿参数的item encoder),目的在于回答基于LLM的推荐算法是否达到了性能极限。
首先让我们回顾下NLP领域的发展。近十年,语言模型取得了重大进展,其中一些具有里程碑意义的突破塑造了今天的NLP领域。2013年的Word2vec为NLP带来了首次革命性的变化;2018年,BERT问世在一系列NLP任务上展示出了一流的性能,并且引入了基于预训练-微调的经典范式。与此同时,同时期的GPT系列也为语言模型的发展做出了巨大贡献,随着GPT的不断进步,超大参数量的语言模型如GPT-3 [1],ChatGPT [2]等大规模语言模型(LLMs)在自然语言处理方面取得了极其惊艳的结果。

鉴于此,作者们提出了疑问:如果将物品编码器替换为最大且最强大的语言模型,比如拥有1750亿参数的GPT-3模型,会对推荐性能产生什么影响?能否期待前所未有的结果呢?并且探究在大参数量的LLM作为预训练模型的条件下,经典的文本协同过滤(TCF)推荐算法可否展现出通用模型潜力,实现推荐系统foundation 大模型?文章没有设计新的推荐系统算法,而是对目前最主流的推荐范式进行了严谨的经验验证,相关核心问题的解答对于推荐系统社区发展具有一定的向导作用。
文章探索了以下几个重要的问题:
Q1: 基于文本的协调过滤推荐算法(TCF)的性能随着物品编码器参数量不断增加表现如何?是否在千亿规模能达到上限?
Q2: 超大参数的LLM,如175B参数GPT-3,是否能产生通用的item表征?
Q3: 装配了175B参数量的LLM的推荐系统算法能否打败基于ID的经典算法?
Q4: 基于LLM的TCF算法距离推荐系统通用大模型还有多远?
Q5: 随着ChatGPT的出现,近期产生了一系列基于prompt技术的推荐算法ChatGPT4Rec,此类算法通过prompt技术引导ChatGPT给出推荐,并且不需要训练专门的推荐模型。ChatGPT4Rec的优点效率高,不需要训练。自然地,本文也顺带调查了经典的TCF算法是否能被ChatGPT4Rec取代。
本文给出了一些正向的结论,也展示了一系列令人惊讶的发现。在LLM狂欢之时,也应该正视其不足,推荐系统经典范式仍然十分具有竞争力。
模型架构
该文章选择了两种有代表性的推荐架构进行评估:双塔DSSM[3]模型作为简化版CTR模型的代表以及SASRec[4]作为序列模型代表。
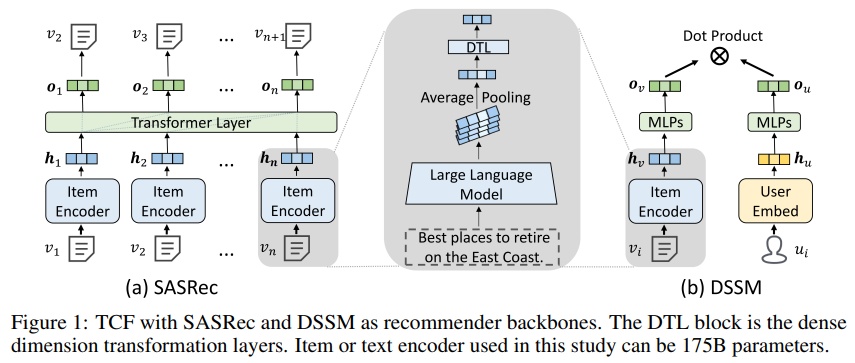
作者们没有探索其他的CTR模型,因为这些模型通常与DSSM同属一类,主要的区别在于多数CTR模型使用的是单塔骨干网络,而这个区别不太可能显著影响论文结论。因此文章采用了两个具有代表性的推荐模型作为代表。
数据集
在这篇文章中,作者们使用了三个真实世界的文本数据集进行评估:Microsoft发布的MIND新闻点击推荐数据集,H&M平台的HM服装购买数据集,以及在线视频推荐平台Bili数据集。

对于MIND数据集,使用新闻文章标题来表示item;对于HM和Bili数据集,他们使用产品或视频的相应描述和标题来表示item。在所有三个数据集中,每个正向的用户-物品交互都是点击、购买或评论,这些都被视为用户偏好的隐式指标。
实验观察
接下来将通过实验结果分别展示在研究动机中所提出的研究问题。
问题1:文本基础的协同过滤(TCF)范式的性能极限是什么?通过将item编码器的大小从一亿增加到一千亿,能揭示TCF范式性能极限吗?

为了回答这个问题,作者通过增加TCF模型中的文本编码器的规模来进行实验并且选择了9个不同规模的LLMs从1.25亿(125M)到1750亿(1750B)参数不等。如图所示,无论是SASRec还是DSSM作为推荐模型,TCF模型都可以通过增加其文本编码器的大小来提高其性能。此外,值得注意的是,文本编码器大小和性能之间的比例关系不一定是严格的线性关系,可以发现使用350M参数的语言模型的TCF模型在所有三个数据集上都显示出最差的结果。
图中的结果表明,175B的参数LM可能还没有达到其性能上限通过观察到LLM的参数量从13B到175B时,TCF模型的性能还没有收敛。这一现象表明将来使用更多参数的LM用作文本编码器是有带来更高的推荐准确性的潜力的。
作者们也观察到采用SASRec主干的TCF在很大程度上优于使用DSSM主干的TCF。类似的发现在以前的许多文献中也有报道。文章解释一个原因是使用<用户,物品>的交互作为表征来代表用户比只采取用户ID特征更有效。另一个原因是,基于序列到序列(seq2seq)训练方法的SASRec架构比DSSM架构在此结构中表现更好。
问题2:这些极大的语言模型LLM是否能为推荐任务提供通用的物品表示?

文章试图回答具有175B参数的LLM生成的物品表征是否具有一定程度的通用性。在NLP领域一个很关键的目标就是建立通用的LLM。本文不同于传统的NLP任务,在这里采用文本推荐任务作为下游任务评估LLM的通用性能。文章做了简单的分析,认为对于一个完美的通用向量
来说,使用冻结表征应该和微调一样有效,甚至优于微调。从优化的角度来看,使用冻结表示比微调需要更少的训练参数,因为如果所需的物品特征已经事先决定,那么训练过程通常会更容易。
论文针对两种推荐模型(微调vs 冻住表征)进行了几组不同对比实验。如图所示,结果表明即使是由极其庞大的LM(如GPT-3)学习到的物品表示,也未必能形成一个通用的表征。结果表明在相应的推荐系统数据集微调仍然对于获得SOTA仍然是必要的,至少对文本推荐任务来说是如此。另外, 论文也指出采用微调的方式虽然效果好很多,但是成本高于高昂,不难想象,微调或者训练带有66B的LLM至少也得需要几十张A100显卡,这里可以看出本文的工作量着实不小。
问题3:175B参数的LLM是否能轻松打败ID?
TCF是基于文本的推荐系统的经典范式,而IDCF是整个推荐系统领域的最经典的范式。那么很自然的产生一个疑问:具有175B参数的TCF模型语言模型能够轻易地击败基于ID的方法,也就是IDCF模型?虽然之前的许多关于推荐系统的研究都报道,TCF模型取得了先进的结果,但很少有人明确地将他们的模型与相应的IDCF模型进行比较。

为了探究这个问题,此文章对IDCF进行了仔细的搜参,发现即使采用175B和微调的66B的语言模型,当使用DSSM作为推荐骨架时,TCF仍然很大程度的劣于IDCF。文中解释,DSSM的结构和训练方法对TCF不是很友好,使用DSSM的IDCF和TCF都比基于seq2seq的SASRec模型表现得差。而采用SASRec架构时,TCF模型即便在LLM被冻结的情况下表现仍然与IDCF相当,尤其是在MIND和Bili数据集(论文对HM数据集TCF表现不佳进行了解释)。
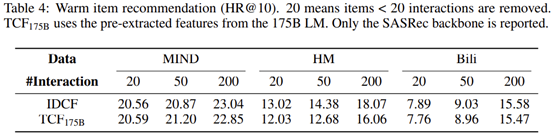
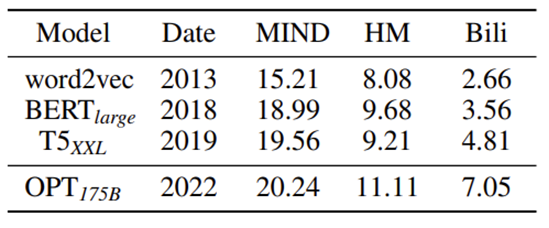
对于warm推荐场景, TCF在LLM被冻结的情况下甚至有时也可以超过IDCF,这是一个重要的发现,因为之前没有研究表明采用冻结的NLP编码器直接输出物品表征可以在warm推荐场景达到与IDCF可比较的性能,而这是推荐系统去ID化很重要的一步。同时,也说明先前文献中的文本编码器,如BERT[6]和word2vec[7],在生成文本表征方面是不够的。文章展现了使用各种不同的文本编码器推荐结果,结果显而易见(如下,NLP十年发展对推荐系统也带来了红利)。
作者指出,对于以文本为中心的推荐,采用SASRec为主干的TCF并利用一个175B参数的冻结LM可以达到与标准IDCF相似的性能,对于warm item推荐场景也是如此。然而,即使通过重新训练一个超大型的语言编码器LLM,采用DSSM架构的TCF也几乎没有机会达到IDCF一样的结果,说明简单的IDCF在warm物品推荐环境中仍然是一个极具竞争力的方法。另一方面,如果计算量可以显著降低,那么端到端训练序列推荐模型和LLM可以带来明显优于IDCF的推荐性能。
问题4:TCF范式与通用推荐模型有多接近?
论文认为对TCF而言与主流的IDCF范式进行对比是十分必要的,因为ID特征(包括用户ID和项目ID)被认为是推荐系统大模型(又称基础模型)的一个主要障碍。文章认为要实现推荐系统基础模型需要至少满足两个条件:(1)放弃ID特征,因为ID特征在不同业务系统无法共享,自然没办法实现迁移学习;(2)实现有效的跨域、跨平台迁移。从以上结果可知,基于LLM的TCF模型(SASRec架构)基本上可以取替ID方法,也就是去ID是可行的。而对于(2),论文中提出TCF虽然直觉上可以迁移,但是否真的具有很好的迁移效果,仍然是不确定的。因此,论文对基于LLM的TCF做了迁移学习的探究。
论文中采用175B参数的LLM作为物品编码器,在一个8百万用户,40万item的数据集上进行预训练并且在MIND、HM、QB(短视频数据集)三种数据直接评估预训练的模型。

结果如表所示,虽然装配了175B参数量LLM的TCF模型的表现优于随机采样的item的推荐,甚至达到了6-40倍的提升。但与在推荐数据上重新训练的TCF模型相比,它们仍然有巨大的差距。
因此,论文通过结果观察到 LLM具有一定程度的迁移学习能力,但仍然远远不能成为一个通用的推荐模型。对于一个通用的推荐大模型来说,不仅item表征应该是可迁移的,而且用户和物品之间的匹配关系 应该能够迁移。然而,匹配关系是与具体推荐系统的曝光策略密切相关。因此,与NLP和计算机视觉(CV)相比,推荐系统模型的可迁移性更具挑战性。即便如此,论文对于推荐系统大模型仍然是持有乐观态度,但是可能需要整个社区共同努力。
问题5:ChatGPT4Rec vs TCF
最近,由于ChatGPT的巨大成功,出现了很多ChatGPT用于推荐系统的文献。文章评估了使用基于prompt技术的ChatGPT4Rec是否可以打败经典的TCF范式。结果如下表所示。
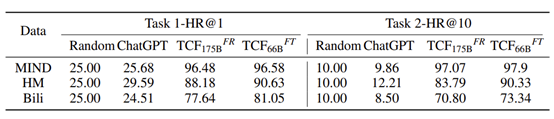
结果如图,ChatGPT在典型的推荐系统场景与TCF相比表现存在较大的差距,文章猜测需要更加精细的prompt,ChatGPT才有可能用于某些推荐场景,实际上论文附录中,也测试了文章使用的prompt,ChatGPT的回答是完全理解这个推荐需求,但推荐结果很不理想,另外,ChatGPT的另一个主要缺点是,在真实推荐场景,候选item池可以达到百万千万级别,ChatGPT暂时不能用于此类推荐。因此,论文认为,基于ChatGPT目前的性能和局限性,其无法替代经典的TCF范式。
总结
这篇文章没有去设计一个新的文本推荐算法,相反,通过实验,作者探讨了经典的TCF范式性能相关的几个根本问题。从积极的角度来看,TCF还没有达到性能极限,意味着,随着NLP大型模型表示能力的进一步提高,TCF有望具有更好推荐效果。另外一方面,很令人遗憾,即使是一个拥有千亿规模参数的LLM, 使用它作为item编码器,仍然需要重新训练模型。此外, TCF模型并没有表现出预期的迁移学习能力,这表明构建推荐系统大模型可能是一项比NLP和CV领域更艰巨的任务。尽管如此, 1750亿参数的LLM对于TCF范式已经是一个重大的飞跃,因为它从根本上挑战了基于ID的推荐范式,而ID范式被认为是构建推荐系统大模型的最大障碍,但如文章所属,这并不是唯一障碍。

