大模型在知乎舰桥平台的应用和实践
导读:舰桥平台是知乎内部的一个企业经营分析平台,本文将分享大模型在舰桥平台的应用和实践。文章侧重于大模型在企业中的应用落地,会一起探讨大模型如何预企业经营分析相结合,以及大模型在搭建、微调和服务中可能遇到的问题。
01 业务现状和背景
首先来介绍下舰桥平台。

舰桥是知乎内部的一个运营分析平台,它主要的场景涉及找人、找内容、盯人、盯内容、找机会、查问题,它提供的能力包括筛选、打包、分析和监控。

在这个过程中,我们是如何和大模型进行结合的呢?
知乎的业务发展起源于灵感,可以分为外部灵感和内部灵感。外部灵感主要是来源于站外的新闻,我们会讲站外的新闻根据知识体系聚合成事件,再根据事件产出问题,最后基于问题形成讨论场,讨论会产生站内的供用户消费的内容。内部灵感主要是来源于站内已有的内容,对已有的内容进行整理、分析、合并和分类。我们把这一部分的工作称为知识体系整理,也是大模型在舰桥平台应用的第一部分。
第二部分针对知乎站内的内容生态建设,我们会利用大模型通过自然语言在推荐系统的基础上宏观调控内容生态。
第三部分针对业务分析,利用大模型通过自然语言进行数据分析。
以上就是大模型在舰桥平台的应用场景,这三个场景无论在业务上还是在技术上都具有一定的独特性和代表性。
02 知识体系分类整理
下面来具体介绍第一个场景,即知识体系的分类整理。
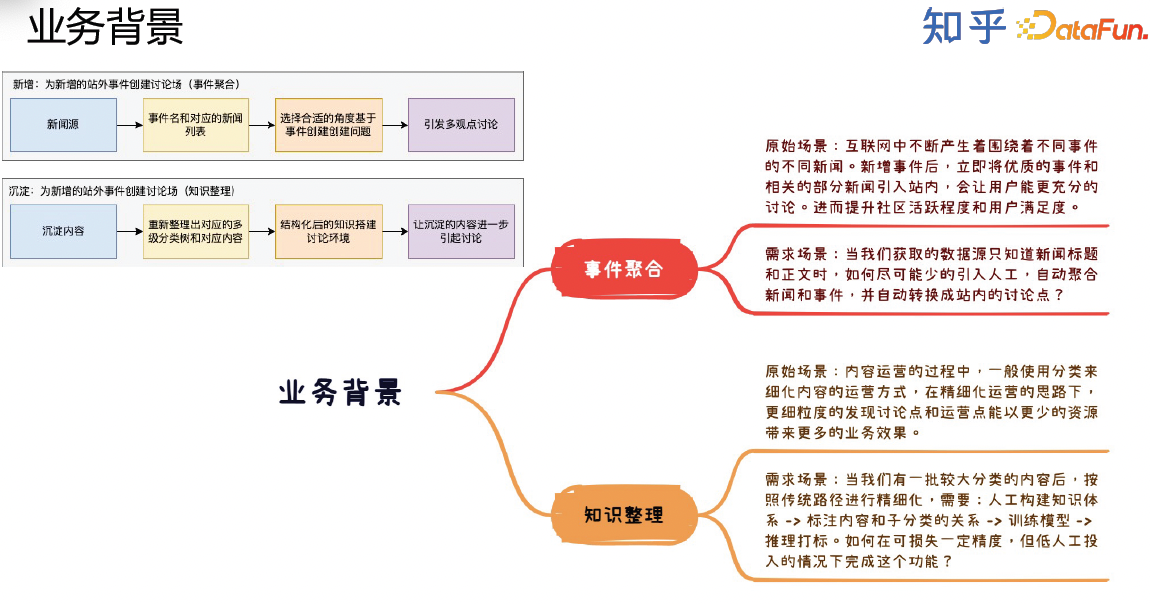
这个场景有两种业务形态,第一种是事件聚合,传统的做法是从站外的新闻源获取新闻,通过聚类的算法进行聚合,再根据聚类结果人工新增事件,接着选择合适的角度基于事件创建问题进而引发多观点讨论。第二种是沉淀内容,我们需要重新整理出对应的多级分类树和对应内容,结构化已有的知识,让沉淀的内容进一步引起讨论。
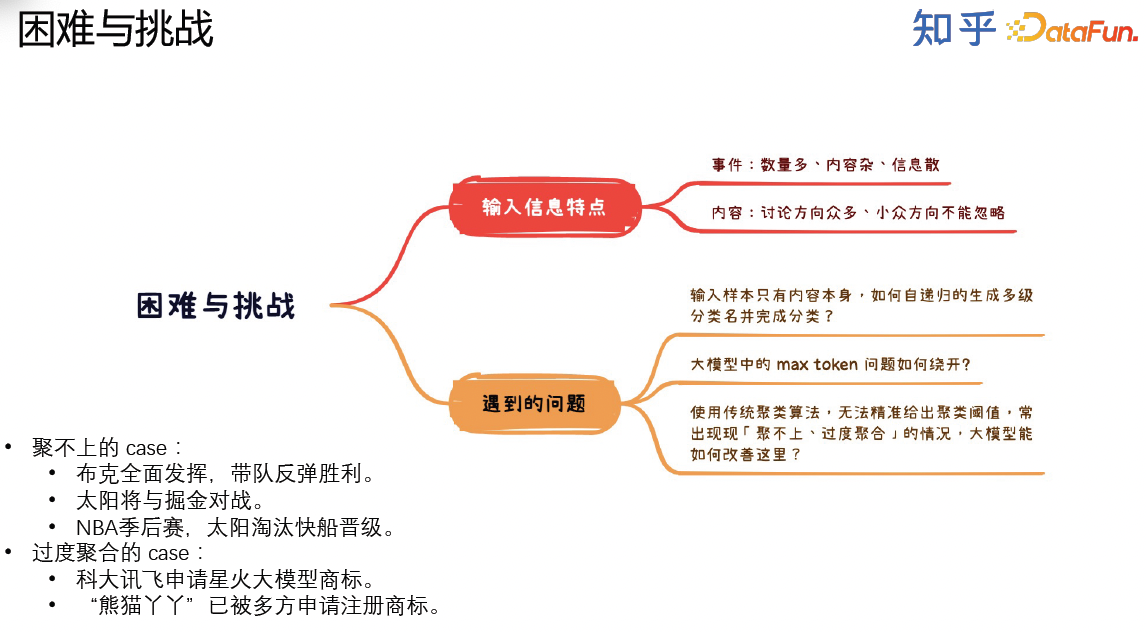
在用大模型解决以上两个业务需求的时候,我们遇到了很多问题,包括聚类准确性的问题、max token问题、流程复杂性问题。
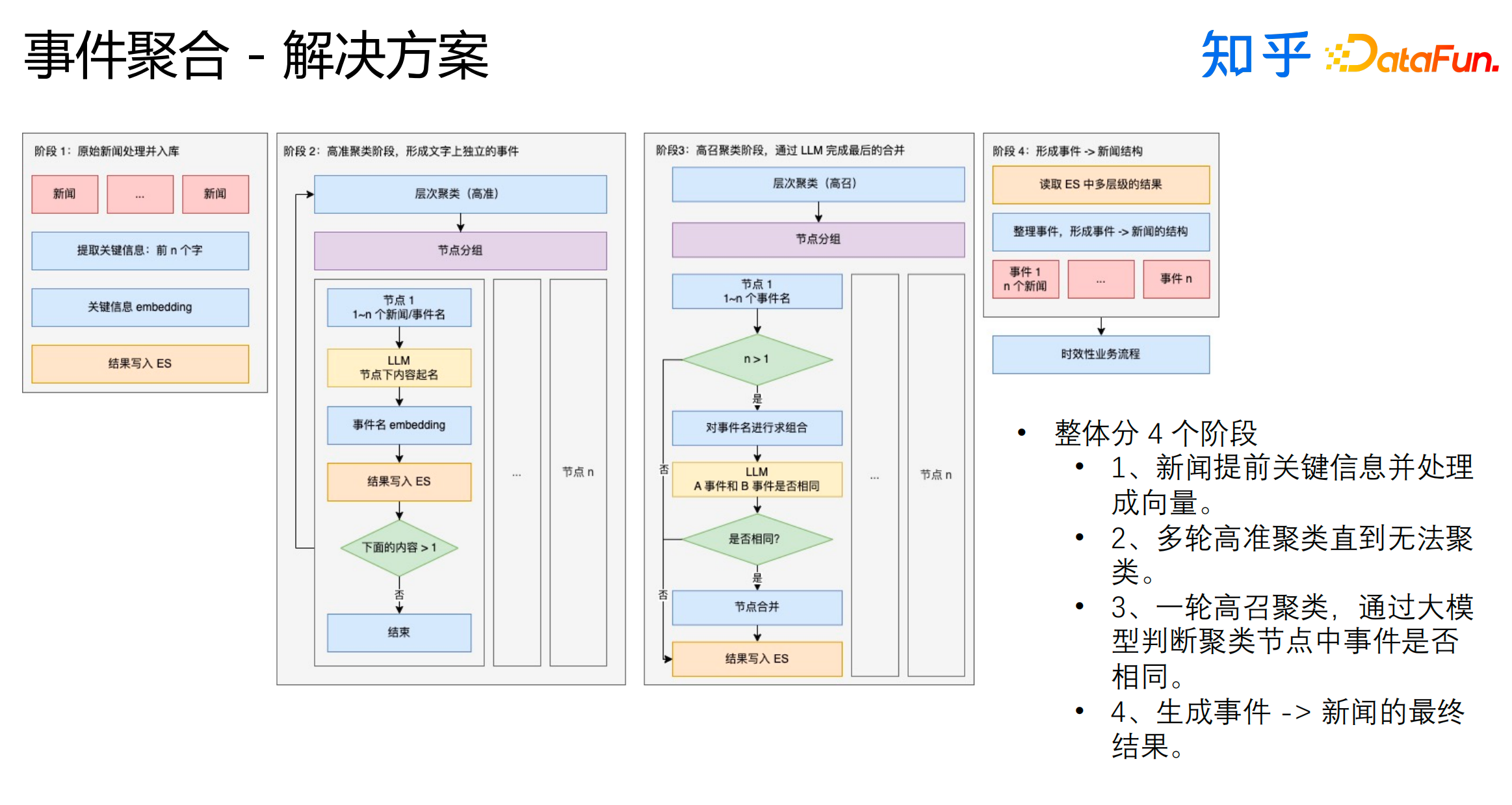
我们基于大模型设计的事件聚合流程如上图所示,整体分4个阶段:
新闻提取关键信息并处理成向量。
多轮高准聚类直到无法聚类,大模型在这个阶段起到的作用是给节点下的新闻或者事件起名。
一轮高召聚类,聚类后,再通过大模型判断聚类节点中事件是否相同,如果相同则合并。
生成事件-->新闻的最终结果,交付给业务方使用。
将对新闻进行层次聚类替代为对大模型生成的事件进行层次聚类有效地解决了聚不上的case;让大模型判断聚在一起的新闻或者事件是否真实是相同的事件并根据结果采取相应的措施有效地解决了过度聚合的case。
由于已经通过层次聚类对节点下的内容进行了分组,所以输入给大模型的prompt都比较小,这也有效地解决了max token问题。
由于基于大模型去完成整个任务的流程相对比较困难,我们设计并开发了针对该任务的类似于MapReduce的方案,这也很好地解决了流程复杂的问题。

这套新方案有以下优点:
事件名可以自动生成,无需人工介入。
准确率的提升。
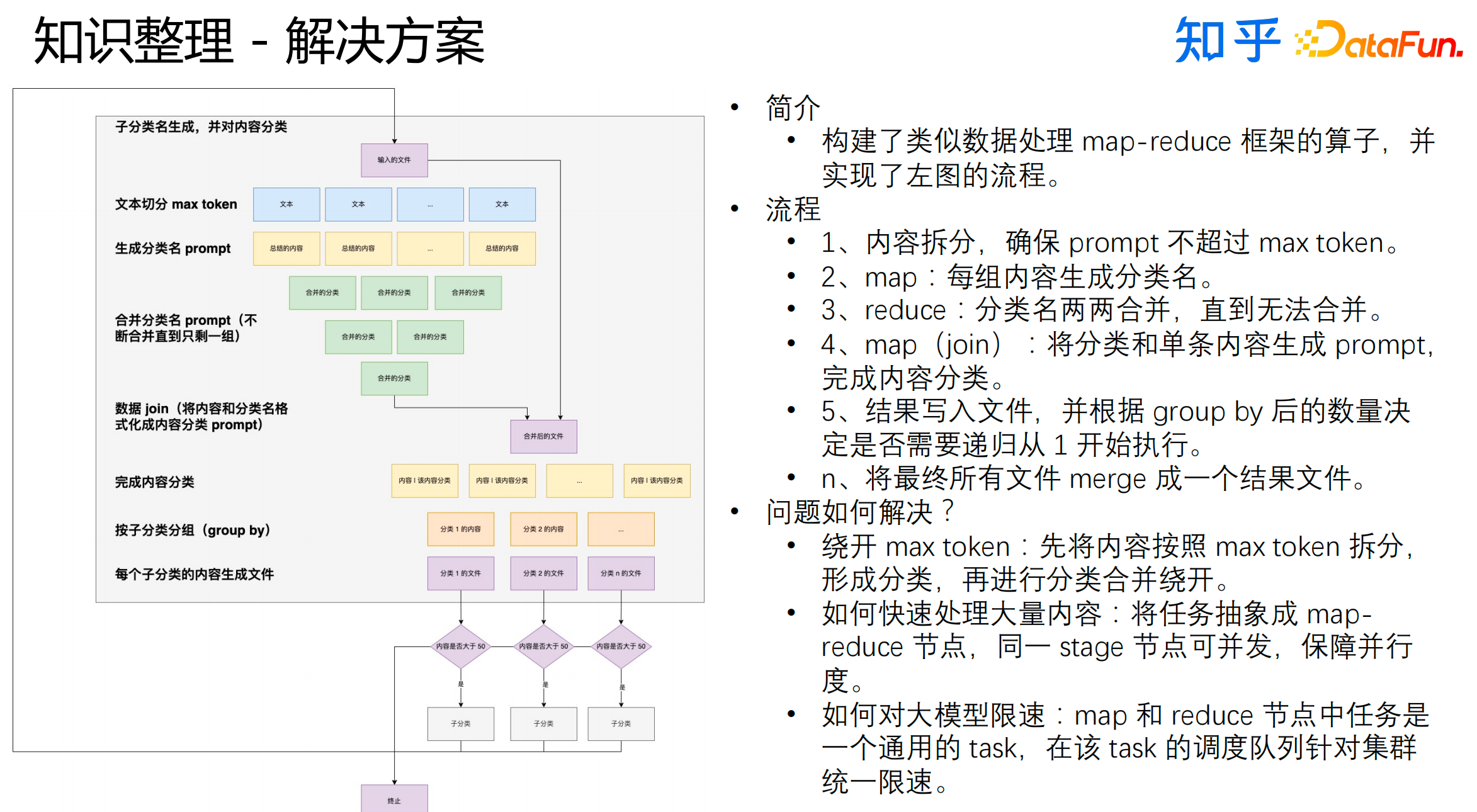
至于知识整理,我们基于大模型搭建了如上图所示的流程。整体流程大致可以分成以下几步:
内容拆分,确保prompt不超过max token。
map阶段:将每组内容生成分类名。
reduce阶段:分类名两两合并,直到无法合并。
结果写入文件,并根据group by后的数量决定是否需要递归从初始阶段开始执行,最终将所有文件merge成一个结果文件。
在这个过程中,我们也会遇到一些问题,具体的解决方法为:
绕开max token:先将内容按照max token拆分,形成分类,再进行分类合并。
快速处理大量内容:将任务抽象成MapReduce节点,同一stage节点可并发,保障并行度。
大模型限速:MapReduce任务是一个通用的task,针对该task的调度队列进行集群统一限速。
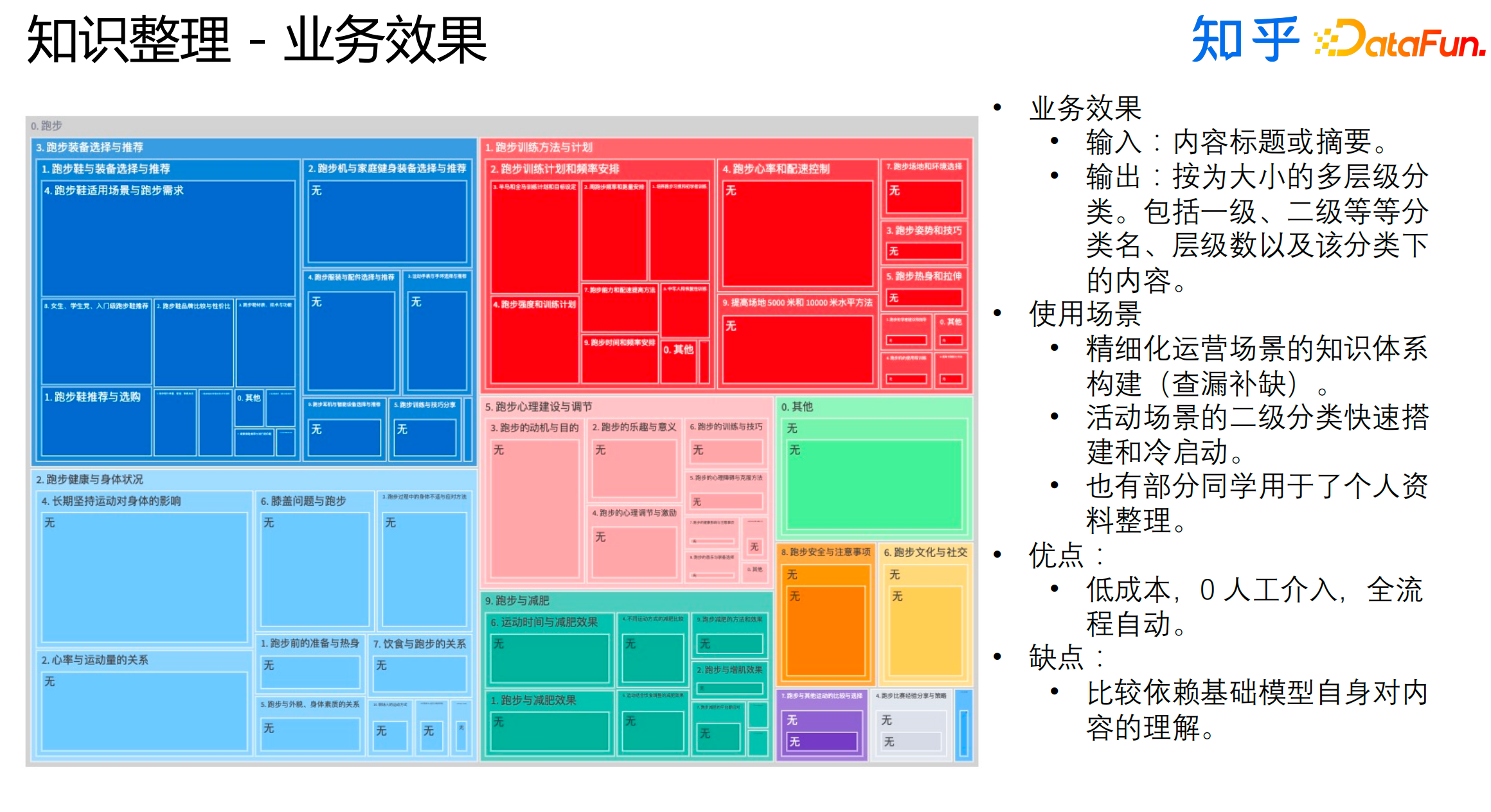
最终的业务效果如上图所示。这套新流程的优点是成本低,0人工介入,全流程自动;它的缺点也比较明显,就是比较依赖基础模型自身对内容的理解。
03 自然语言转筛选条件
接下来介绍自然语言转筛选条件部分,这部分面向的场景主要是打包、找人、找内容。
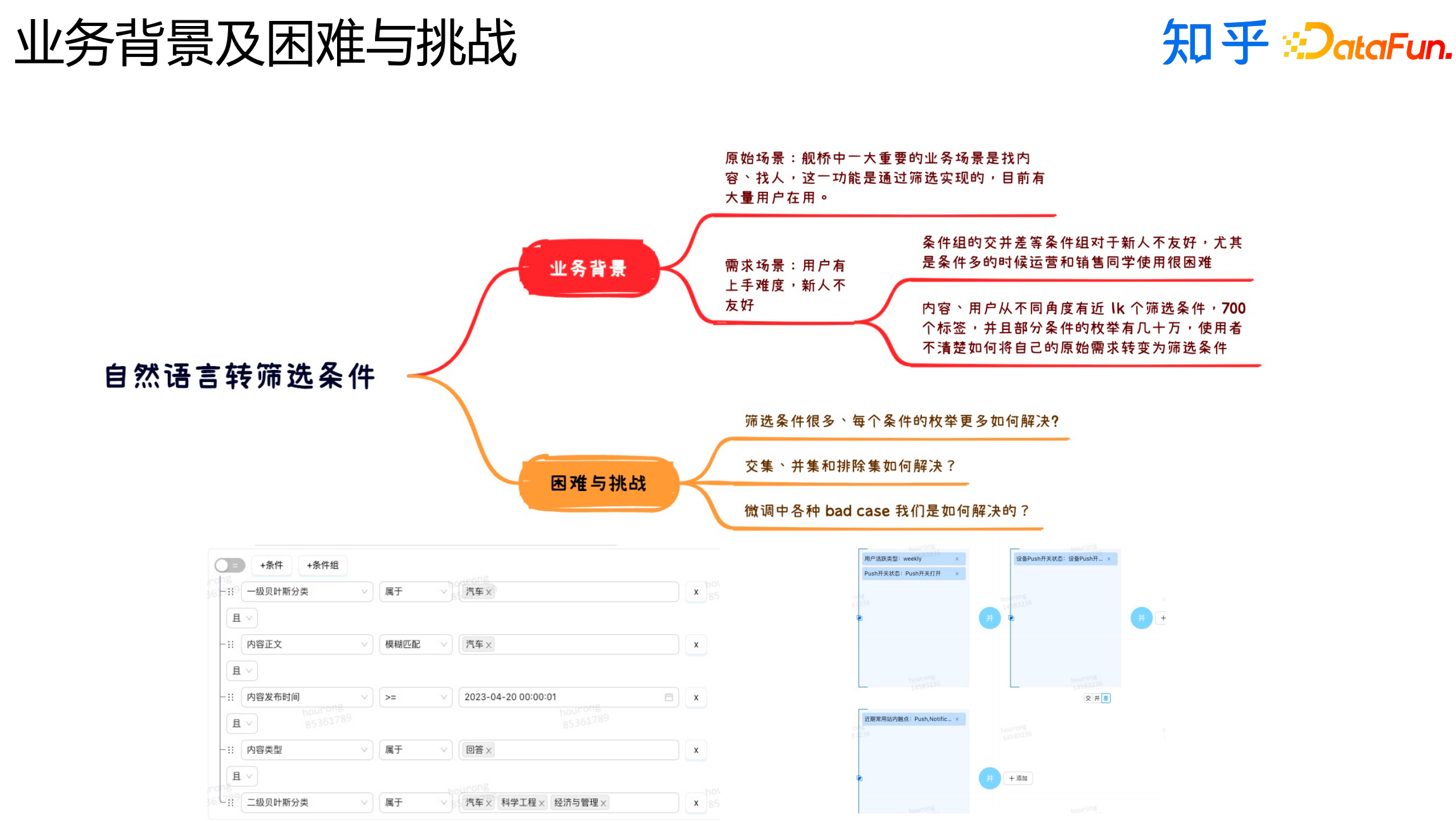
在我们的业务中,业务人员需要根据条件找到用户和内容。这样的任务有以下几个特点:
筛选条件很多。
不同条件之间的逻辑组合很多。

根据以上特点,我们选择采用大模型微调的方式来完成任务,早期我们尝试过纯PE的方式来实现,这种方式虽然简单,但并不能很好地满足业务需求。我们构造的微调数据上图右半部分的表格所示,我们输入给模型的问答对是分别是表格中的content列和result列。我们有如下数据构造的思路:
阶段一:基于原子条件构造筛选条件。
阶段二:将原子条件完成交并差构造筛选条件。
阶段三:使用模糊语句构造筛选条件。
阶段四:构造有明显逻辑错误的筛选条件。

完成这个任务的过程大致可以分为两个阶段,在第一阶段,我们迭代了三个版本。
版本一中我们遇到了输出和输入毫不想干的问题。主要的原因是基础模型缺乏逻辑能力。我们将代码和数学题输入给模型进行训练,这种方式有效地解决了这个问题。
版本二中我们遇到了两个问题。首先是JSON截断问题,主要的原因是max token限制,我们尝试调大max token,有效地解决了这个问题;其次是存在输出重复的问题,主要原因是进入某一个概率后,相同字词的概率始终最高,我们使用random sample有效地解决了这个问题。

在版本三中我们主要解决了以下问题:
JSON格式错误,我们构造了大量的JSON的样本。
存在额外条件,我们尝试使用随机条件组合构造样本。
大于小于号错误,我们用筛选条件随机生成多种大于小于的样本。
且或非理解错误,我们尝试随机组合筛选条件构造一批样本。
时间区间理解成时刻,我们尝试使用多个时间类筛选条件构造一批样本。
条件部分缺失,我们尝试使用随机条件组合构造样本。
在训练的过程中,我们遇到了训练速度的问题,我们尝试调小epoch,在一定程度上解决了这个问题。

经历了第一阶段的迭代,基本可以做到线上可用了,但是我们遇到一个非常吊诡的问题,就是必须要保证训练和推荐在一台机器上,一旦机器有差异,就会出现异常。在第二阶段,我们依然有一些优化方向。首先是模糊问题构造,我们需要构造一批类似“高质量创作者创作的优质大模型回答内容”的问题,对大模型进行问题;其次,我们需要定向解决用户实际使用中的case,根据用户实际反馈的问题,生成对应的样本进行微调。
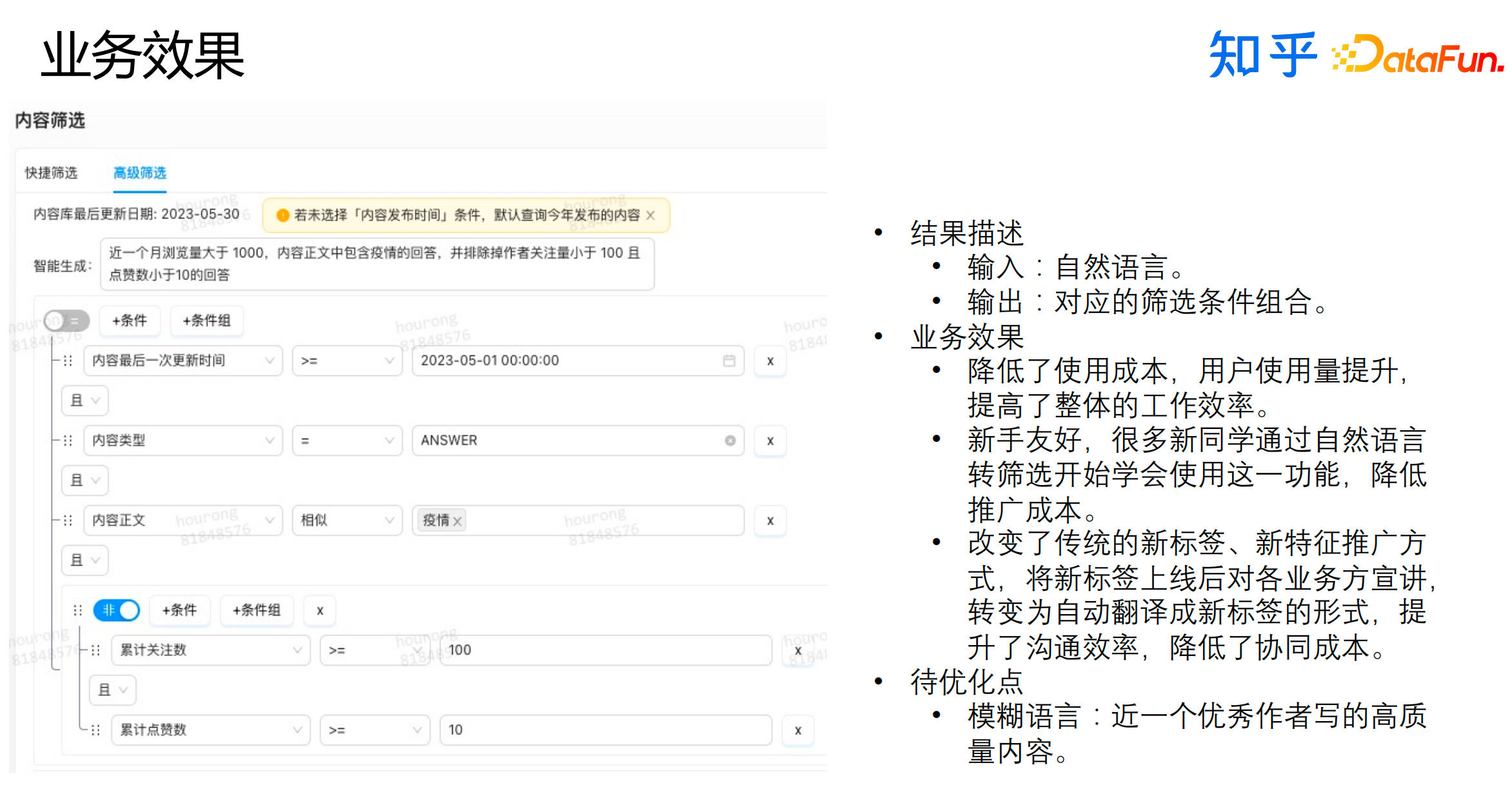
以上就是我们上线后的效果,主要有三点:
降低了使用成本,用户使用量提升,提高了整体的工作效率。
新手友好,很多新同学同坐自然语言转筛选开始学会使用这一功能,降低了推广成本。
改变了传统的新标签、新特征推广方式,将新标签上线后对各业务方宣讲转变为自动翻译成新标签的形式,提升了沟通效率,降低了协同成本。
这个方向的待优化点是模糊语言,我们还需要持续在这个方向上进行探索。
04 自然语言数据分析
最后一部分介绍自然语言数据分析,这一部分主要是AdHoc分析。
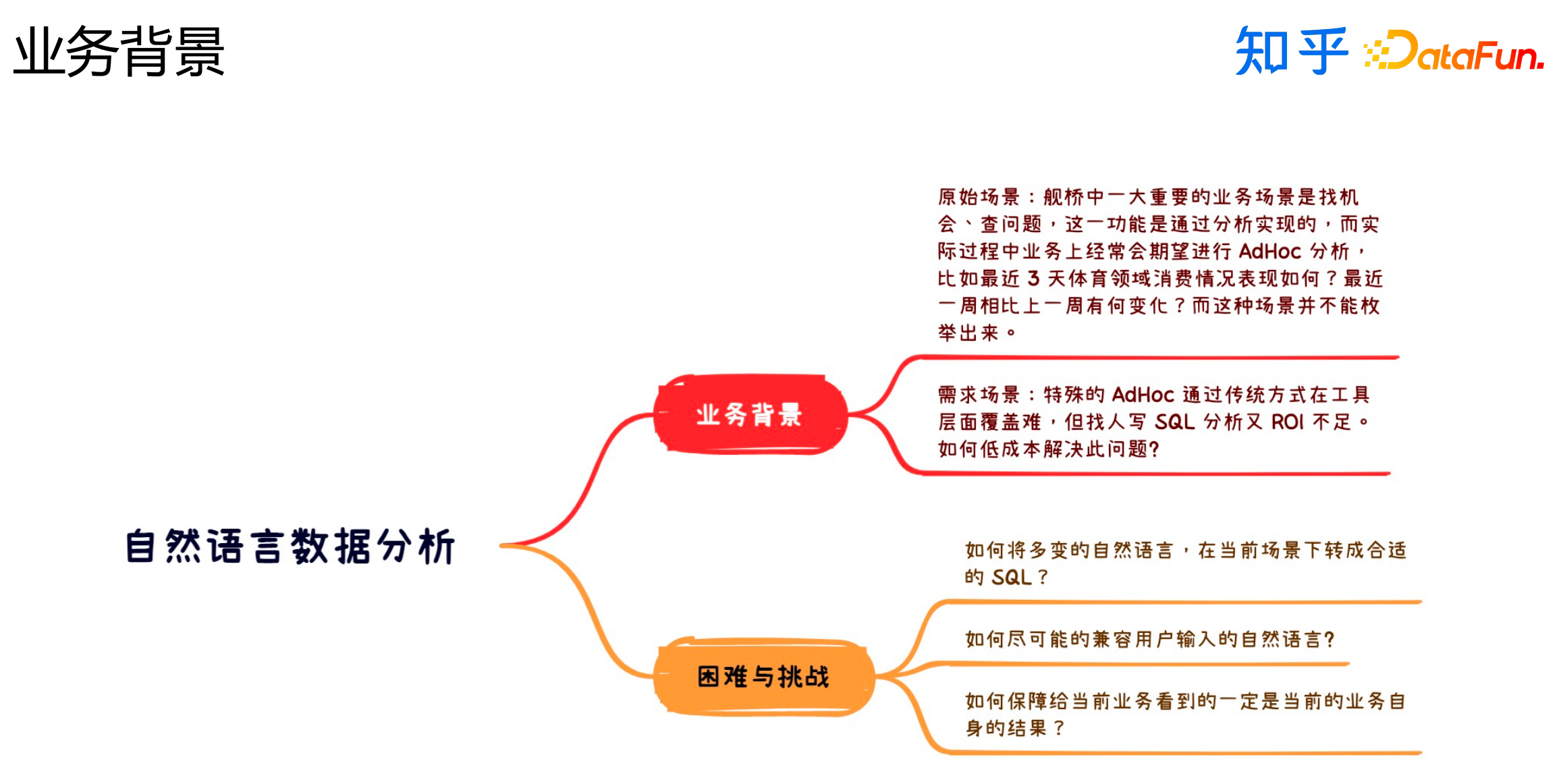
这个任务主要面临以下困难和挑战:
如何将多变的自然语言在当前场景下转成合适的SQL?
如何尽可能地兼容用户输入的自然语言?
如何保障给负责当前业务的同学看到的一定是当前业务自身的结果?
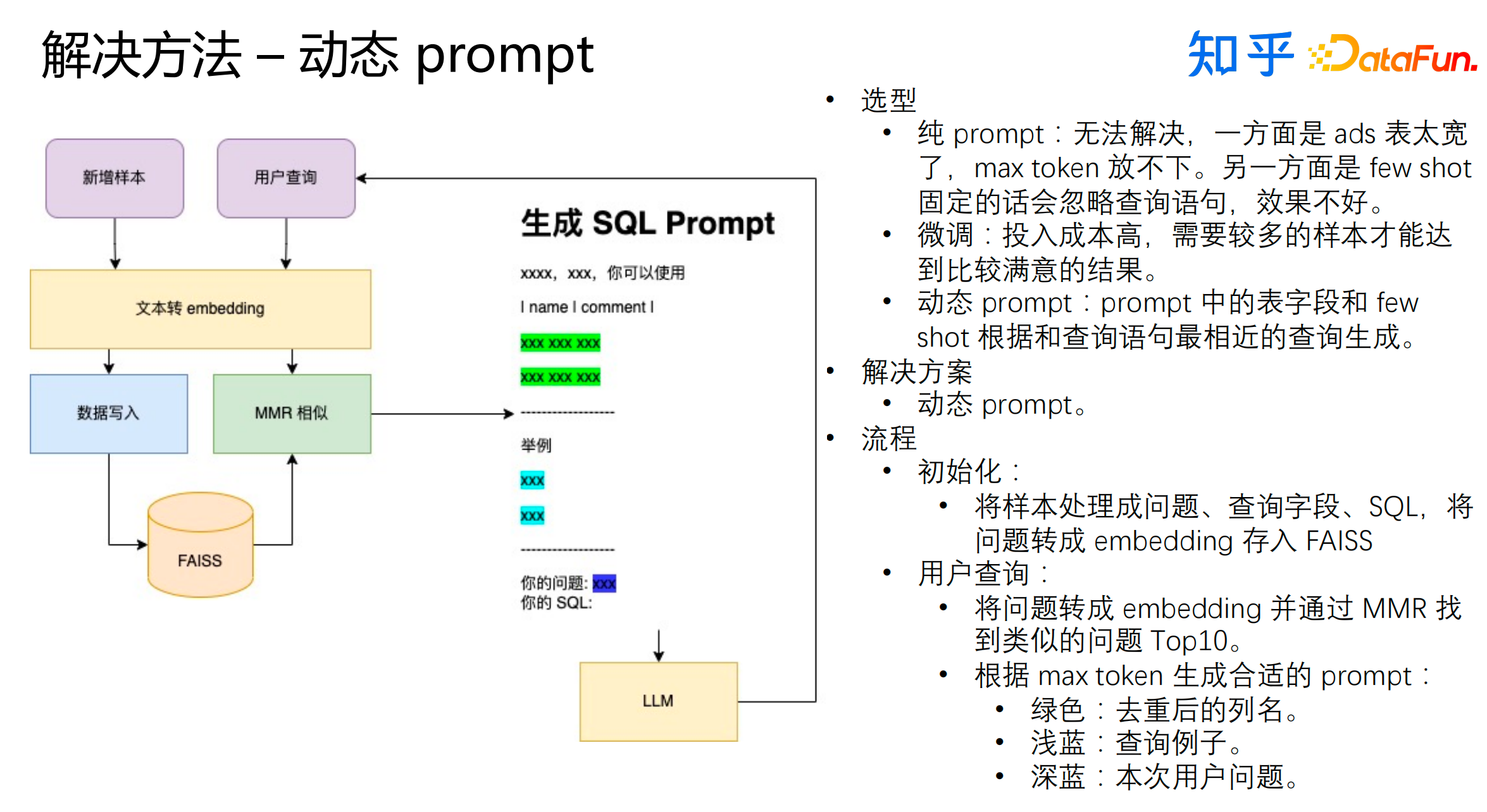
我们使用动态prompt来解决这个问题。我们早期使用纯prompt的方法,这种方法并不能很好地解决业务需求,主要原因是ads表太宽,会超过max token的限制,另外few shot固定会忽略查询语句,效果不好。我们也尝试使用了微调的方式,但是这个方法对样本的要求较高,我们用于微调的样本的难度较大。最终,我们决定采用动态prompt的方式来解决问题。主要流程如下:
(1)初始化:将样本处理成问题、查询字段、SQL,将问题转成embedding存入FAISS。
(2)用户查询会经历如下的步骤:
将问题转成embedding并通过MMR找到类似的问题Top10
考虑max token限制生成合适的prompt:
绿色:去重后的列名
浅蓝:查询的例子
深蓝:本次用户的问题

以上是上线后的业务效果。当然我们也遇到了很多问题,我们也尝试了各种方法并最终解决了问题。
早期使用余弦相似,类似的样例太多,效果不好。
解法:改用MMR通过多样性避免prompt输入不够。
如何尽可能将查询和数据源关联好?
解法:采用产品方案,让用户自行选择用户需要查询的数据源。
用户输入的自然语言很泛,如何在这种情况下尽 可能准确的满足用户需求?
解法:根据用户反馈补充样本进行优化。
目前这种方案还是有一些问题的,准确率不足,当前由于分析场景还是很灵活多变的,简单的case表现还行,但一旦复杂效果就不好了。未来我们会尝试fine tune,进一步加强在各业务场景的表现效果。
05 总结与展望
最后,做一下总结与展望。

在尝试用大模型解决业务问题的过程中,我们发现了很多痛点:
PE 工作没有成熟经验,大家都在摸索,摸着石头过河。
max token是一个挑战,需要设计很多绕行方案。
prompt几乎没有什么优秀实践,凡事靠试。
会有提示注入的问题。
大模型比较慢,且这个问题在复杂场景下会被放大。
数据量大或者场景复杂时没有高效的框架。
构造微调的数据缺乏通用的方法和工具,需要仔细思考。
我们针对这个方向也有一些展望:
会出现面向大模型复杂任务的处理框架。
需要有业务的想象力,模型能力决定下限,想象力决定上限。

