B站动态outbox本地缓存优化实践分享
问题的发现
动态综合页比较容易因为高热事件,引起大量用户持续消费feed流,导致线上拉取动态时间线feed流接口快速飙升至平时峰值2~3倍以上而大量超时,较多用户无法正常消费其feed流。从监控上发现outbox(用户发件箱)服务依赖的redis集群大量实例CPU使用率皆超过了95%甚至达到100%(如图1)。因此,瓶颈在于outbox redis集群压力太大,无法扛住过大的高热流量。而痛点在于redis集群无法高效快速扩容,因此,我们遇到此类情况通常只能被迫降级限流,以防情况进一步恶化。
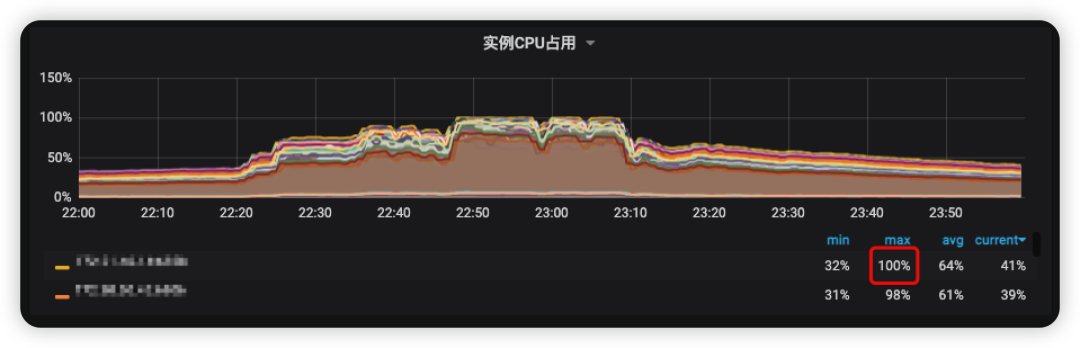
图1 outbox-redis集群实例cpu使用率过载
瓶颈根因的分析
在分析outbox redis集群压力过大的原因之前,先简单介绍一下拉取动态时间线feed流的实现方案——”推拉结合“(如图2)。在动态系统中,为每个用户都分别维护了一个收件箱”inbox“与一个发件箱”outbox“。inbox存储用户关注的UP发布的所有动态,outbox存储了用户本人发布的所有动态。”推“是指一个UP发布的动态会推送至其所有粉丝的inbox中。而”拉“则是指从用户关注的UP的outbox中分别拉取一页feed流。我们一般对于粉丝数量大的UP主(简称大粉UP)采用拉的模式,其他UP主采用推的模式,因为”推“大粉UP写扩散比较严重,会影响写入性能并大幅提升存储空间。所谓的“推拉结合”,就是从用户的inbox拉取一页feed流以及从用户关注的所有未做推处理的大粉UP的outbox分别拉取一页feed流,合并并按发布时间降序排序取TopN最终形成用户的一页feed流。不难发现,对于”拉“outbox而言存在着用户关系链的读扩散,所以,对outbox redis集群读放大较严重(几百甚至上千倍)。引入”推“inbox的本质其实是缓解”拉“outbox读扩散的压力,因为用户关注的且已经做推处理的UP发布的动态可以直接从用户的inbox中得到,无需去拉他们的outbox。然而,高热事件引发的大量用户同时访问带来的瞬间高并发再叠加上outbox的读放大效应,依然足以将outbox redis打过载。
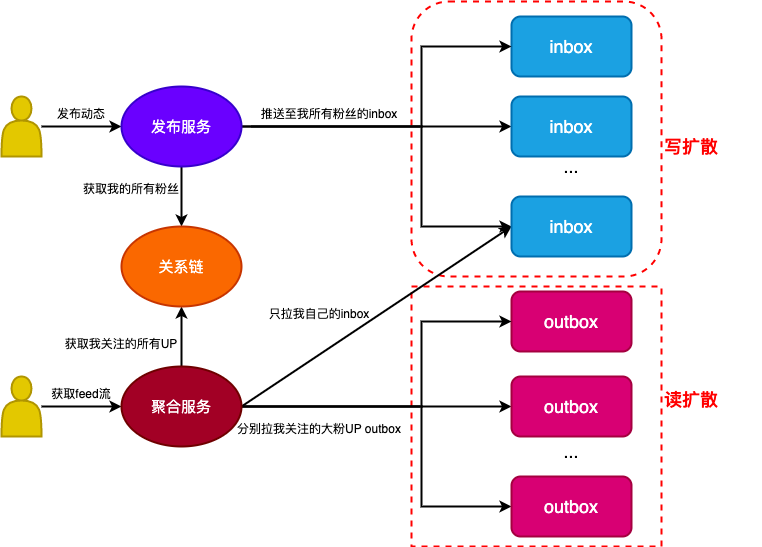
图2 动态时间线feed流推拉结合方案
解决方案的PK
那么, 如何进一步降低outbox redis压力,解决我们目前outbox遇到的可扩展性瓶颈呢?首先想到的方案是进一步提高inbox的利用率。可以提高目前既定的符合“推”inbox条件的粉丝数阈值,对更多的UP做“推”处理,进一步减轻outbox的读扩散压力。但是该方案会引起inbox写扩散压力与存储空间成本成倍增加,最终获得的收益效果可能也比较有限。所以,我们又把焦点转移到了outbox本身。我们假设关系链中被”拉“outbox的UP存在热点,如果我们缓存这些热UP的最新一部分动态列表于本地缓存中,同样可以帮助redis抵挡相当一部分压力。对比两个方案发现,outbox本地缓存方案不仅不会额外增加硬件成本,而且实现简单,可以快速上线验证效果,收益可能比优化”推“方案要高。因此,最终它成为了PK的胜出方。
方案的设计与上线后的效果
缓存哪些UP
既然决定采用本地缓存优化的方案,那么我们首先需要知道哪些UP是热的呢?从关系链的特点,我们推断大粉UP被访问的概率应该更高。我们通过统计历史动态时间线的UP流量分布也论证了我们的猜测。所以,我们定义了一个粉丝数阈值,将粉丝数达到该阈值及以上的UP作为热key,缓存他们一部分最新动态列表于本地(阈值的设定基于内存可以承受的空间),理论上可以获得较高的缓存命中率,并有效缓解“拉”outbox对redis集群的压力。
如何构建本地缓存
因为设定的粉丝数阈值比较高,所以热UP的数量变更不会特别频繁。基于此特点,我们给出的本地缓存整体方案是(如图3):从数据平台每天离线T+1地统计出所有粉丝数达标以及因掉粉粉丝数从达标变为不达标的UP名单,并通过kafka推送写入redis。当outbox服务实例启动时,会从redis拉取到全量名单,并从outbox redis分别拉取这些被缓存UP的最新动态列表,构建于本地缓存中。而启动后的outbox实例每当感知到来自数据平台的被缓存UP(包括需要删除的)名单推新时,也会拉取推新后的名单,但只构建当前未被缓存的新UP,并删除粉丝数低于阈值的UP缓存。当用户获取feed流“拉”其关注的UP的outbox时,优先从本地缓存获取UP的最新动态列表,未命中的UP才回源拉,以此缓解outbox redis的读扩散压力。
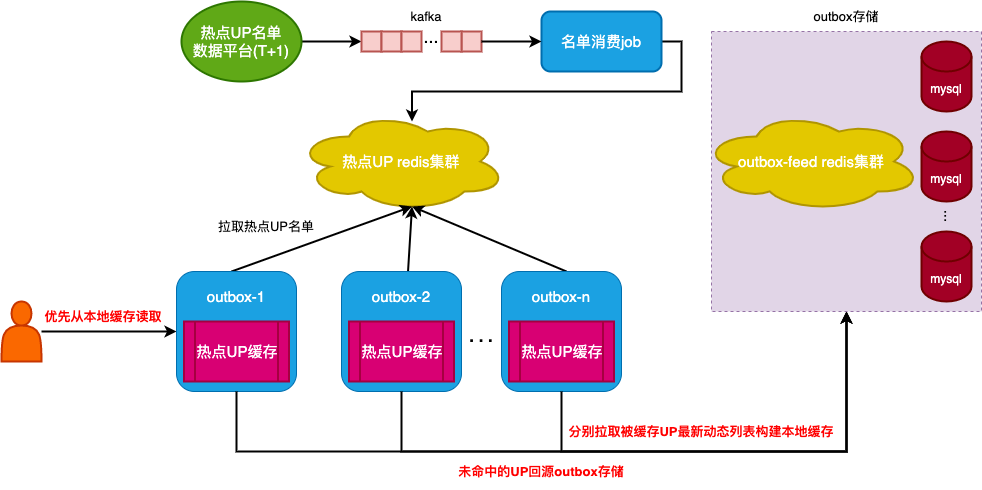
图3 outbox本地缓存整体方案
如何防止回源雪崩
被缓存UP的最新动态列表不是一直不变的,当UP发布或者删除动态后,需要及时回源outbox redis获取该up变更后的最新动态列表并重构其本地缓存。所以,该方案还需要考虑回源对outbox redis的压力问题。在万级别的热key个数加上百级别的实例规模场景下,如果我们采用简单、常规的对每个被缓存UP设置一个较短过期时间,过期后回源重构则容易造成大量key同时过期回源导致outbox redis集群瞬时压力过大,产生雪崩现象。因此,我们给出的回源重构方案是”变更广播+异步重构“(如图4)。在这个方案中,outbox实例本地缓存的UP最新动态列表是常驻不过期的。当某个被缓存的UP发布或删除动态时,会广播该UP的“动态列表变更”事件给所有outbox实例,outbox实例接收通知后异步回源并重构该UP的本地缓存。因为被缓存UP变更频次极少,所有这种回源重构方式对outbox redis的压力也很小。
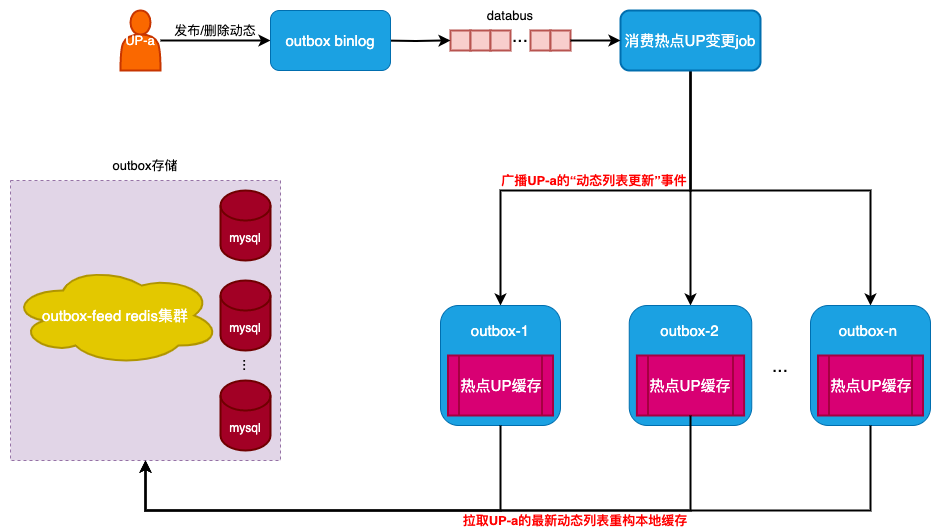
图4 变更通知+异步回源重构
如何保证本地缓存与redis的一致性
采用无过期常驻缓存的方案也让我们担心本地缓存中的值与outbox redis中的值会长期不一致。为了确保一致性,我们在方案中加入了一致性检测的功能。我们提供了”UP变更时检测“与”定期巡检“两种模式(如图5)。每个outbox实例每次回源重构某个UP的本地缓存后,会计算出该UP最新动态列表的checksum并存入redis中。UP变更时检测则会在某个被缓存UP发布/删除动态触发所有outbox实例重构本地缓存后,对比该UP在所有实例本地缓存中最新动态列表的checksum与在outbox redis中最新动态列表的checksum是否一致。而定期巡检则会在每天固定的时间,对比全量被缓存UP在所有实例本地缓存中的最新动态列表与在outbox redis中的最新动态列表是否一致。无论在”UP变更时检测“还是”定期巡检“的过程中,一旦检测到被缓存UP在本地缓存中的值与outbox redis中的值不一致时,皆会将该UP的”动态列表变更“事件再次广播到所有outbox实例触发对该UP缓存的重构,以实现自动修复不一致的功能。
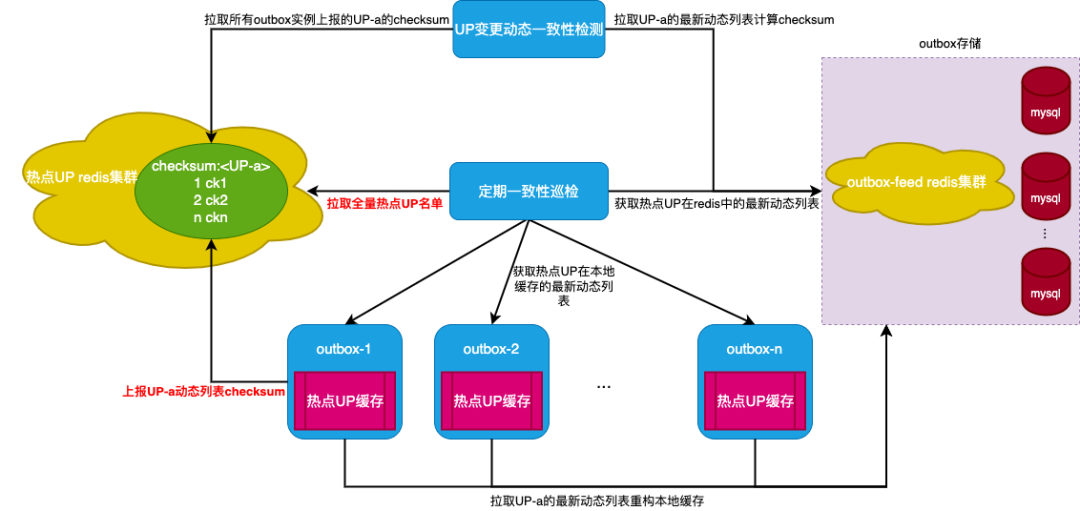
图5 一致性检测与自动修复
上线后的效果
outbox本地缓存优化上线后,命中率达到了55%以上(如图6)。环比优化上线前后的周末高峰outbox redis压力情况:outbox redis的压力峰值降低了上线前的近44%(如图7~8),而outbox redis集群单实例CPU使用率峰值也降低了上线前的37.2%(如图9~10)。
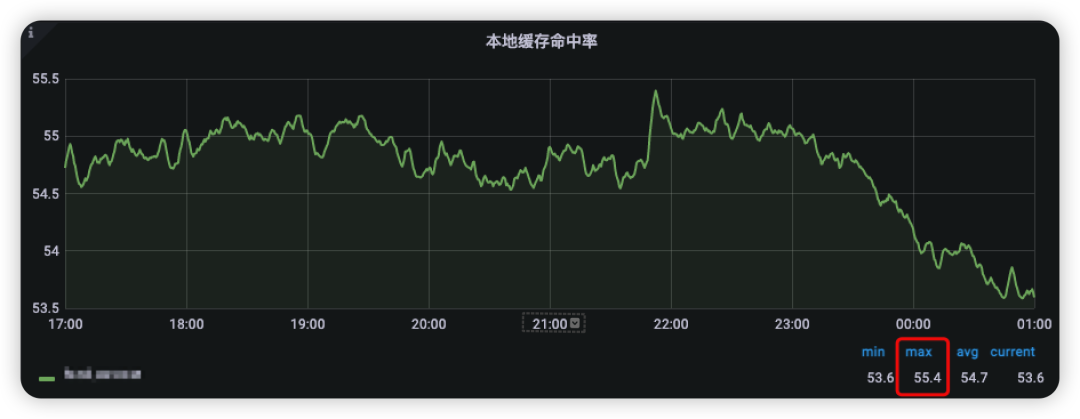
图6 outbox本地缓存命中率

图7 本地缓存优化上线前周末outbox redis的压力峰值
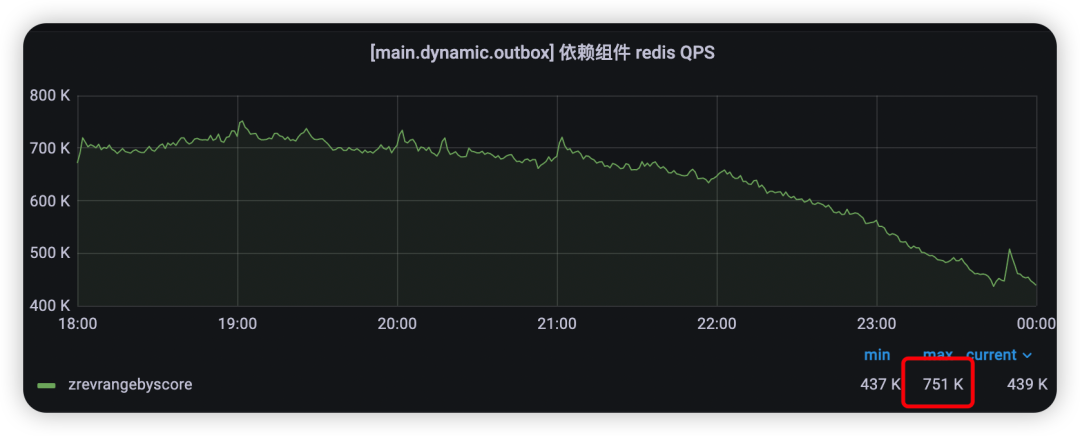
图8 本地缓存优化上线后周末outbox redis的压力峰值
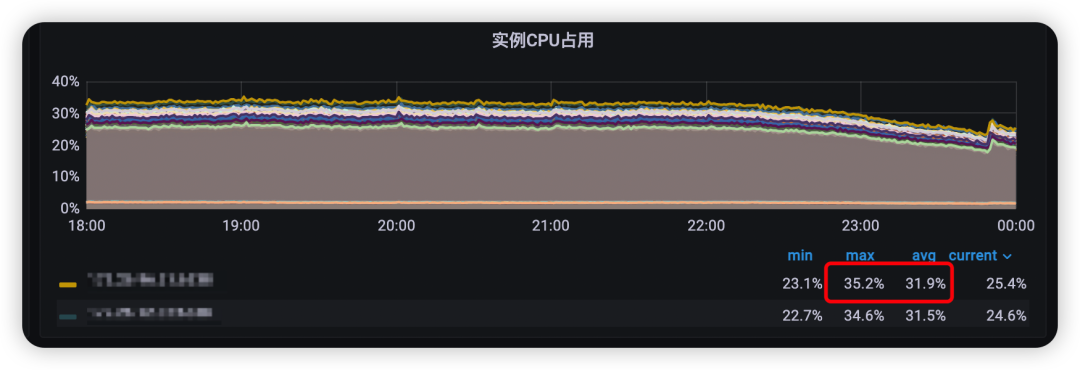
图9 本地缓存优化上线前redis的高峰期间cpu使用率
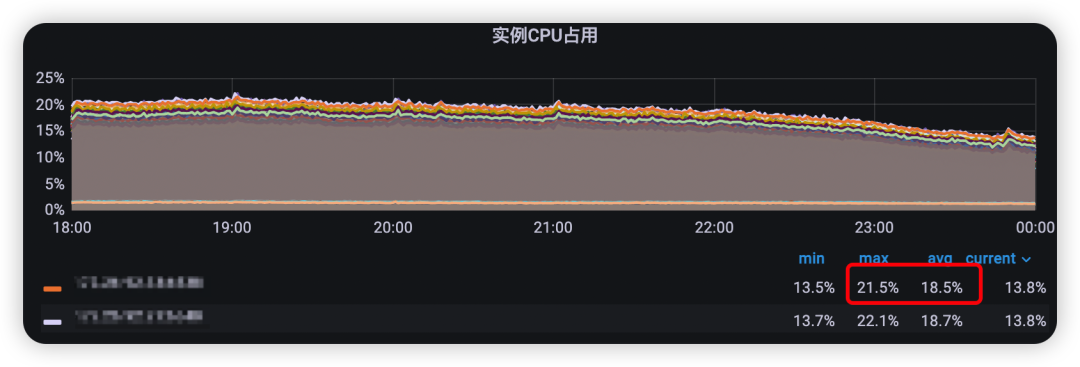
图10 本地缓存优化上线后redis的高峰期间cpu使用率
后续规划
目前我们只缓存了普通类型的热UP,然而从历史UP流量分析发现,番剧与付费视频类型的UP同样存在较多数量的热UP,如果我们后续将他们也构建与本地缓存之中,可以进一步提高缓存命中率。另一方面,对于粉丝数未达到阈值的UP,我们会对他们采用实时热key发现策略做本地缓存,以防止他们中少数UP在空间页等场景产生突发的高热流量,导致redis集群中部分实例CPU使用率过载的现象。

