百度智能云Redis容量版设计与实践
本文根据刘东辉老师在【第十三届中国数据库技术大会(DTCC2022)】线上演讲内容整理而成。
Redis作为“扛流量”和“加速”的利器,在百度集团内部有着极其广泛的应用。但由于数据全部存储在内存,Redis成本高昂,为此我们研发了兼容Redis协议、大容量、低成本的Redis容量版产品,在简单KV场景下性能为Redis 70%,单GB成本相比Redis降低80%+。
本次分享会阐述百度智能云Redis容量版(PegaDB)的设计与实践。内容包括:PegaDB简介及应用场景;PegaDB内核技术及实践经验;百度智能云Redis内核团队与开源社区的合作;PegaDB后续规划。
百度智能云Redis容量版概述
百度智能云Redis容量版又叫PegaDB,它是一个完全兼容Redis协议、大容量、低成本、高性能的分布式KV数据库。PegaDB具备以下特点:
1,全面兼容Redis,支持业务平滑迁移;
2,支持水平扩展,单集群PB级存储;
3,基于SSD构建,单GB成本相比Redis降低80%+;
4,支持毫秒级在线数据处理;
5,支持异地多活架构,提供多地域容灾能力;
6,支持可调一致性、冷热分离、JSON数据模型等企业级特性;
PegaDB典型应用场景包括: 大数据量场景,Redis存储成本高;开源KV数据库,在性能、功能和可用性方面无法完全满足需求;典型冷热分离场景,传统Cache + DB架构,业务开发复杂度高。目前PegaDB已广泛应用于百度凤巢、Feed、手百、地图、度秘等多个核心业务。
百度智能云Redis容量版设计与实践
PegaDB设计与实践丨背景
首先介绍一下研发PegaDB的背景。最早设计PegaDB主要是为了解决百度集团在使用Redis过程中遇到的成本和容量问题。要知道,Redis是内存存储,开启持久化时需要额外预留内存,存储成本较高;同时,Redis单个集群的容量是有限的,公有云产品最大支持4TB,无法支撑大数据量存储;不仅如此,百度集团还有其它KV数据库,在兼容性、通用性、易用性也存在一定的问题。
明确了业务痛点,PegaDB的定位也就清晰了。大容量、低成本、兼容Redis、通用KV存储, 同时还要具备高性能、高可用、可扩展等分布式存储系统必备的特性。
PegaDB设计与实践丨业界方案
兼容Redis协议的KV数据库,大致有如下三类方案:
第一类方案以Pika、Kvrocks为代表,采用基于磁盘的设计,数据全部存储在磁盘,在单机KV存储引擎RocksDB之上实现Redis的数据类型。但这类方案目前都没有成熟的集群方案去解决扩展性问题, 同时还存在性能、不支持多活架构等问题。
第二类方案以Meitu Titan、Tedis为代表的,也是采用基于磁盘的设计,数据全部存储在磁盘,但是在分布式KV存储引擎TiKV之上实现Redis的数据类型。但这类方案通常对Redis兼容性不太好,同时也存在性能、不支持多活架构等问题。
第三类方案以Redis On Flash为代表,数据存储在内存和磁盘,在内存中存储热点数据,在磁盘中存储冷数据, 可以调整内存和磁盘的配比。这类方案基于Redis二次开发, 再组合单机KV存储引擎RocksDB去扩展存储容量,但这类方案比较适合数据冷热区分明显的场景, 存在通用性问题, 同时也存在大Value场景性能不好等问题。
PegaDB设计与实践丨设计选型
PegaDB在选型时面临的主要问题有: 是二次开发还是从0开始? 如果二次开发, 基于哪个开源项目进行开发(Pika、Kvrocks、Ardb ……)?
出于研发人力、项目上线时间等因素考虑, 选择了基于开源项目进行二次开发。考虑到代码简洁性、方便二次开发、设计思路及发展规划契合度等因素, 最终选择了基于Kvrocks进行二次开发,并深度参与开源社区建设。
PegaDB设计与实践丨Kvrocks介绍
Kvrocks是美图公司开发的一款分布式KV数据库,并于2019年正式开源。使用RocksDB作为底层存储引擎并兼容Redis协议,旨在解决Redis内存成本高以及容量有限的问题。
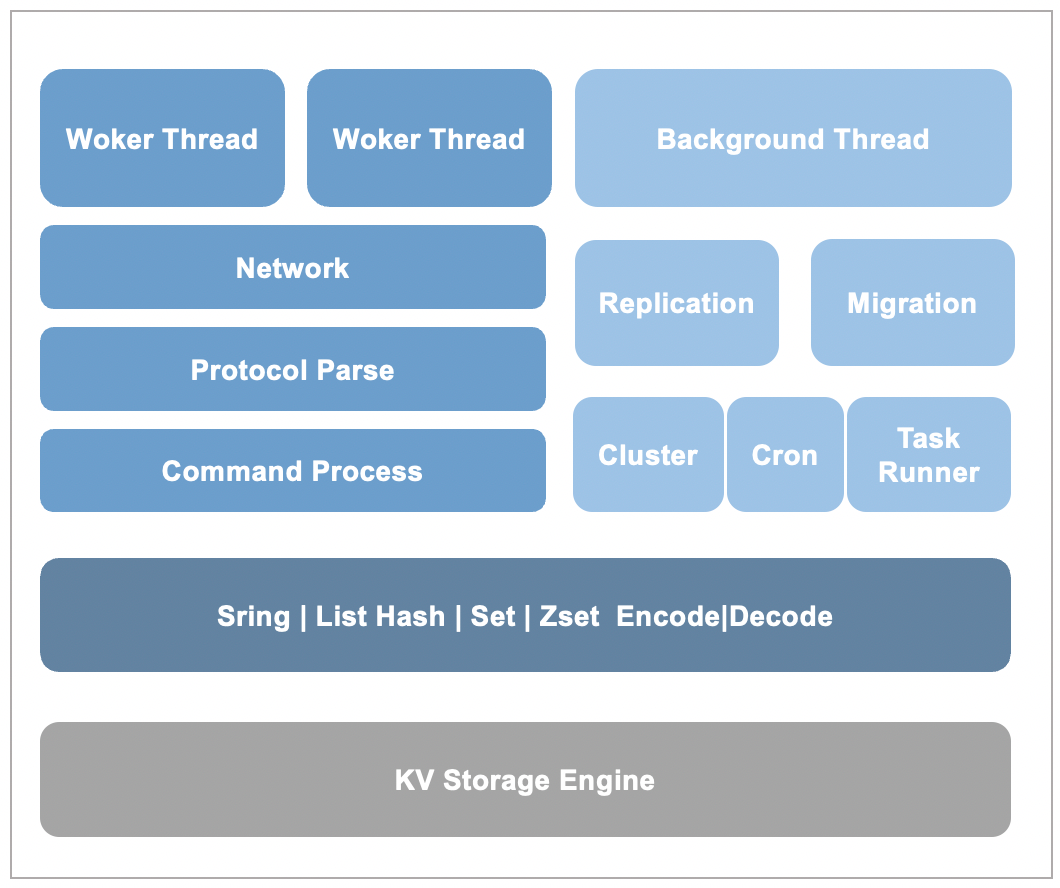
接下来分享一下Kvrocks的基本设计思路。
Kvrocks是基于RocksDB存储引擎来封装Redis的数据类型,Hash等复杂数据类型会被拆分为多条KV数据;同时为了提升性能,Kvrocks采用了多Worker线程的处理模型;多副本间数据复制,Kvrocks同Redis一样采用了主从复制的方式, 不过增量复制是基于引擎WAL的“物理复制”;此外,Kvrocks还借助RocksDB Compaction Filter特性实现了数据过期,并通过增加Version信息实现了大Key秒删。
PegaDB设计与实践丨Kvrocks不足
针对百度的业务场景, Kvrocks存在一定的不足。扩展性方面,Kvrocks不支持水平扩展,无法支撑业务几十TB甚至百TB级规模数据存储;性能方面,Kvrocks在大Value、冷热区分明显等场景下存在性能问题, 无法满足业务高QPS和毫秒级响应延迟的需求;可用性方面,由于Kvrocks和Redis一样, 选择了异步复制模型,无法满足较高一致性需求; Kvrocks不支持多活架构, 无法满足业务地域级容灾需求;功能方面,Kvrocks不支持Redis4.0以上版本命令、事务、Lua、多DB特性, 无法满足使用高版本Redis业务平滑迁移的需求。
为此,结合生产环境中实际遇到的问题,PegaDB在Kvrocks基础上做了很多改进:
PegaDB设计与实践丨集群方案
对于扩展性需求, 首先需要支持集群。在数据分布策略选择上,PegaDB选择了同Redis-Cluster一样的思路,预分配固定数量的Slot。在集群架构方面选择了中心化的架构,由MetaServer统一管理集群元信息。
同时,PegaDB的集群架构不强依赖代理层,支持MetaServer向PegaDB下发拓扑,完全兼容Redis-Cluster SDK。
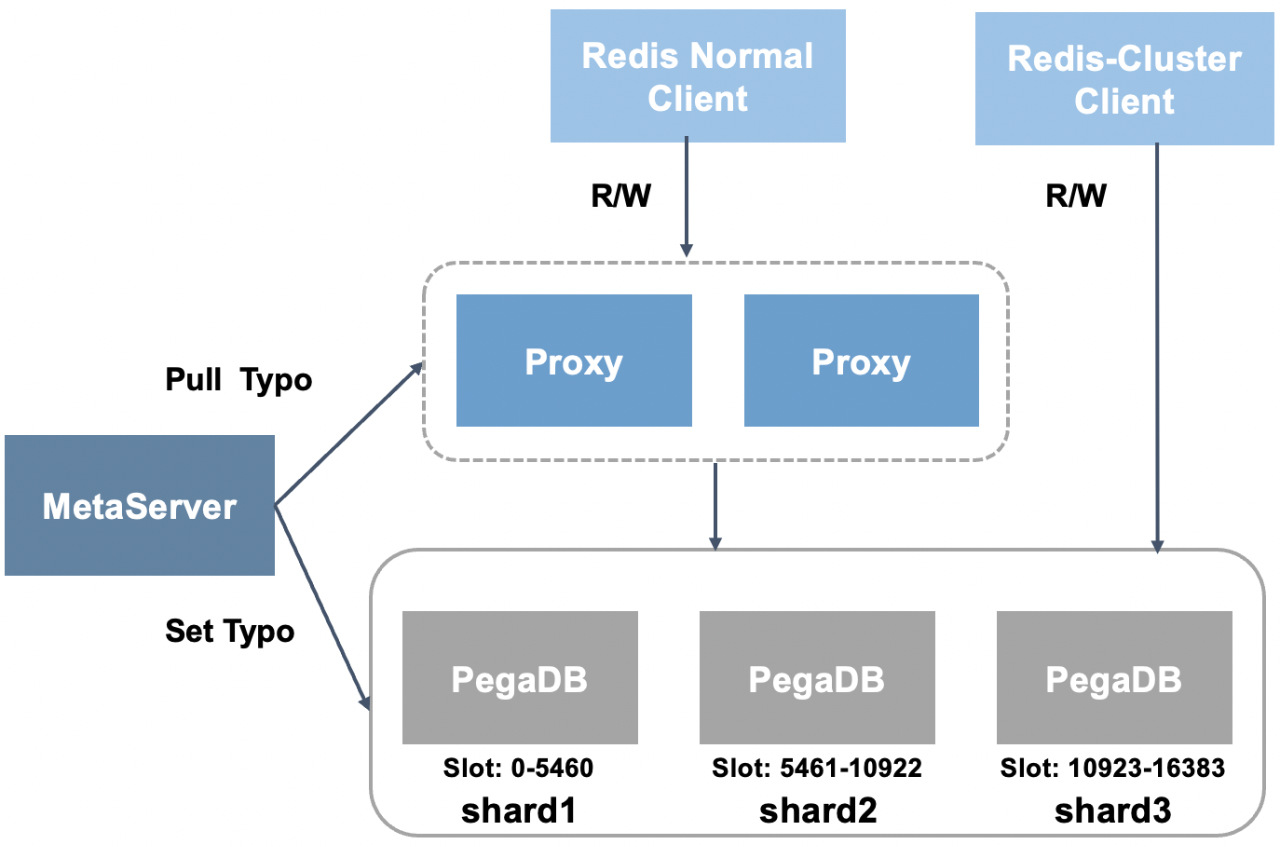
由于实际生产环境业务的数据规模和访问量是不断变化的,PegaDB集群还需要具备弹性伸缩的能力。
PegaDB设计与实践丨扩缩容设计
对于数据库这种有状态的服务,集群的扩缩容,主要有两个问题要解决:数据迁移和拓扑变更。
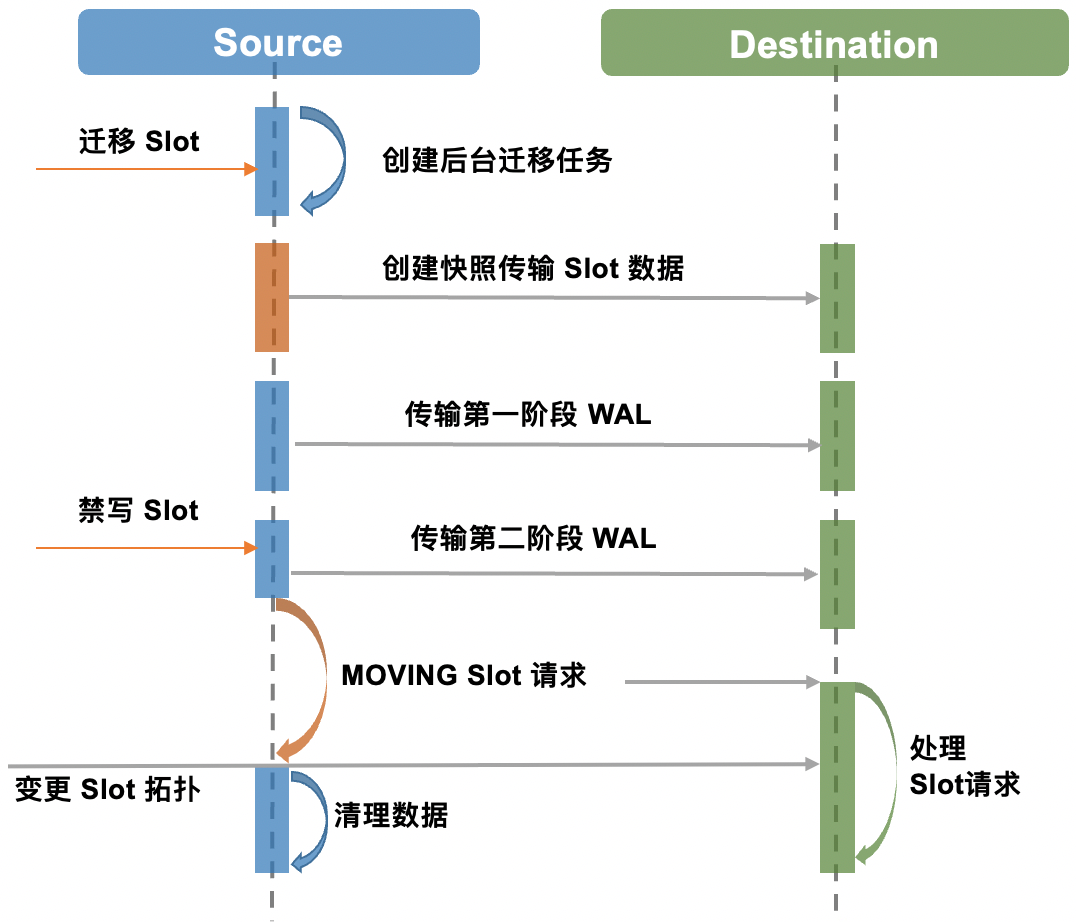
PegaDB集群的数据分布到固定数量的Slot,每个PegaDB负责一定数量的Slot,数据迁移就是将源节点中的一部分Slot搬迁到目标节点。PegaDB数据迁移采用了类似选择性复制的思路,迁移流程分为全量数据迁移、增量数据迁移两个阶段。
全量数据迁移借助RocksDB Snapshot 快照将需要迁移的 Slot 所包含的 Key 迭代出来,同时在 Key 编码中增加了 SlotID,这样同一个Slot的Key会存储在一起,显著提升了迭代效率。PegaDB 增量数据迁移直接使用了引擎层的 WAL 日志,这种方式不需要经过Redis协议解析和命令处理,相比发送原生Redis命令的方式更加高效。
此外,为了迁移时不影响正常请求,使用了独立的迁移线程,并且通过支持Slot并发迁移,利用RocksDB Delete Range特性清理源端数据来提升效率。为了保证数据一致性,拓扑变更期间会有短时间禁写,通常是毫秒级。
PegaDB设计与实践丨主从复制优化
介绍PegaDB对主从复制的优化前,先简单回顾下Kvrocks的主从复制实现。Kvrocks和Redis主从复制思路类似,都包括全量复制和增量复制。Kvrocks在全量复制方面基于RocksDB Checkpoint数据快照,增量复制基于引擎层WAL的“物理复制”,并且基于WAL seq_id实现了断点续传。
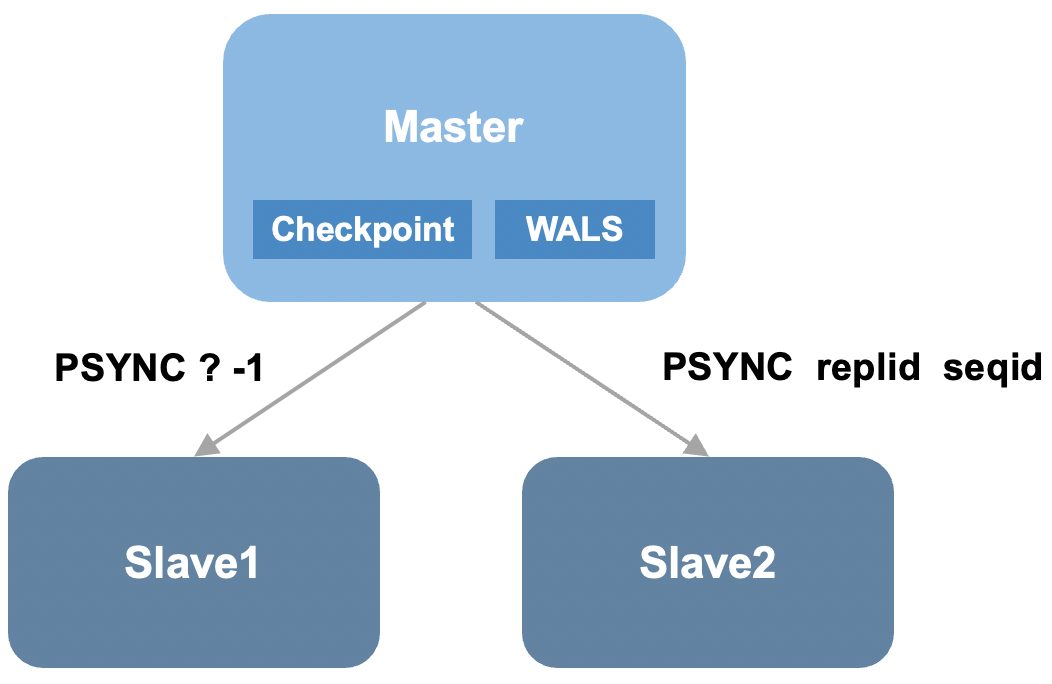
但是Kvrocks复制模型有两个典型的问题:第一,无同源增量复制保证主从切换会带来数据不一致;第二,异步复制模型,主从切换可能会导致数据丢失。
PegaDB是如何针对上述两个问题进行优化的呢? PegaDB引入了复制ID的概念,当实例成为主库时会生成新的Replication ID(复制历史的标识),每条写入RocksDB的操作都包含一个单调递增的Sequence ID和Replication ID,只有从库Replication ID与主库相同并且Sequence ID小于主库时才可以进行重同步。由于Sequence ID和Replication ID是存在于WAL中的,因此不仅支持Failover后部分重同步,而且支持重启后部分重同步。
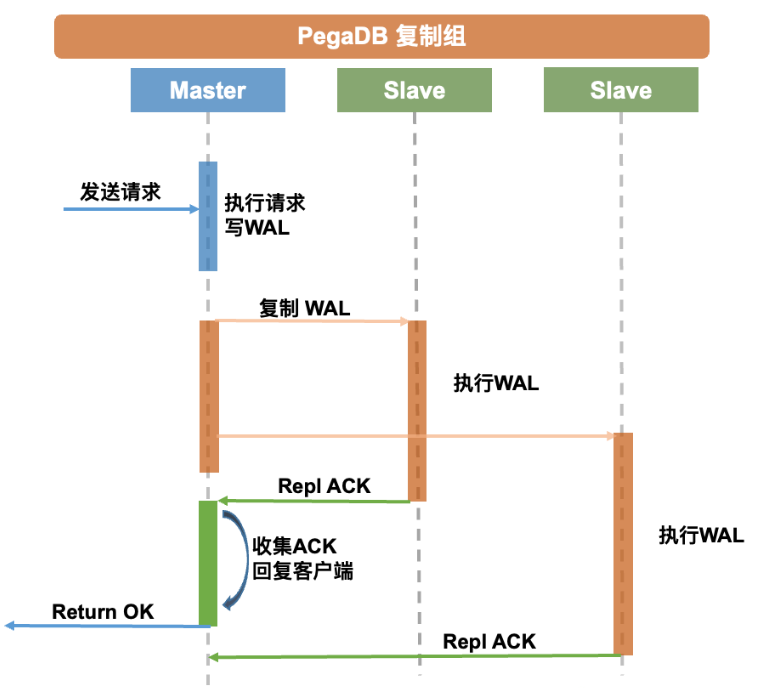
针对第二个问题,PegaDB采用了半同步复制的方案,其具有更强的一致性,支持配置同步的从库个数,并且支持超时机制。此外,PegaDB的代理层还支持配置请求粒度读取一致性。
PegaDB设计与实践丨性能优化
为了更好的满足业务需求,PegaDB在性能方面也做了很多优化。本次分享主要介绍PegaDB在存储引擎、缓存、数据编码方面所做的优化。
存储引擎方面,LSM引擎存在明显的写放大问题,尤其在写入量比较高的大Value场景下,经常会触发磁盘带宽瓶颈,导致性能显著下降。对于这个问题,业界有WiscKey和PebbleDB两种典型的方案, WiscKey采用了Key Value分离的思路,PebblesDB采用了弱化全局有序约束的思路。由于PebbleDB没有成熟的开源实现,最终我们选择了WiscKey的思路。对于WiscKey的方案,当时有Badger、TitanDB这两个相对成熟开源实现, TianDB基于RocksDB扩展了Key Value分离的功能,天然兼容RocksDB丰富的特性,而且方便后续升级到高版本RocksDB。而Badger是使用GO语言重新开发的存储引擎,Badger支持的特性相对较少,PegaDB使用了大量RocksDB的特性,选择Badger适配成本较高。再者TianDB也不会有Badger GO语言GC时带来的STW问题,因此最终选择了TianDB, 并扩展实现了CheckPoint特性(已提交社区#207)。随着RocksDB社区全新版本的Key-Value分离实现BlobDB(2021年发布)越来越成熟, PegaDB也从TianDB逐步迁移到了BlobDB。
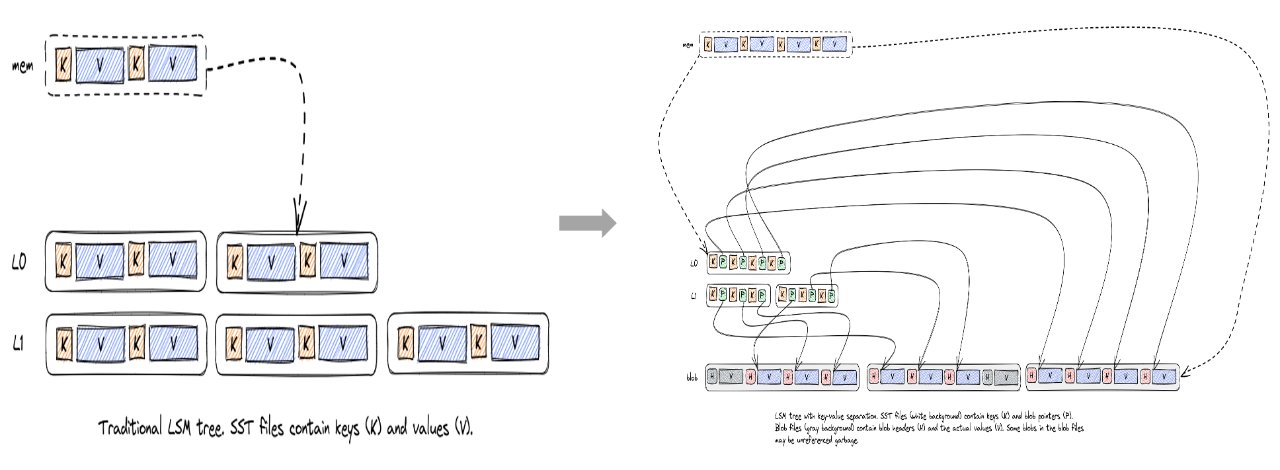
除了Key-Value分离,PegaDB针对存储引擎还做了很多调优工作,主要有耗时抖动优化、读取优化、写入优化。
耗时抖动优化:利用Rate Limiter对Compaction进行限速,支持部分Compaction,升级高版本RocksDB(Compaction有显著优化#9423),使用Partition index/filter;
读取优化:Memtable开启全局Filter,Data Block开启Hash索引,L0和L1不压缩,自定义Prefix Extractor,支持配置多CF共享和独享Block Cache。
写入优化:Key-Value分离,开启GC预读,开启enable_pipelined_write,开启sync_file_range。
接下来介绍一下在缓存方面所做的优化。
针对冷热数据区分明显场景通常采用传统Cache(Redis)+DB(MySQL)架构,但是这种架构需要业务自己来维护Cache的DB的数据一致性,业务开发复杂度较高。
为此PegaDB支持了热Key缓存,单节点可支持百万级热Key访问, 大大简化了冷热区分明显场景的业务架构。
RocksDB支持Block Cache和Row Cache, 为什么PegaDB还要再增加处理层的缓存?
PegaDB的热Key缓存,相比Block Cache, 粒度更细,缓存利用率高;相比Row Cache,没有Compaction导致的快速失效的问题,缓存命令中更高。
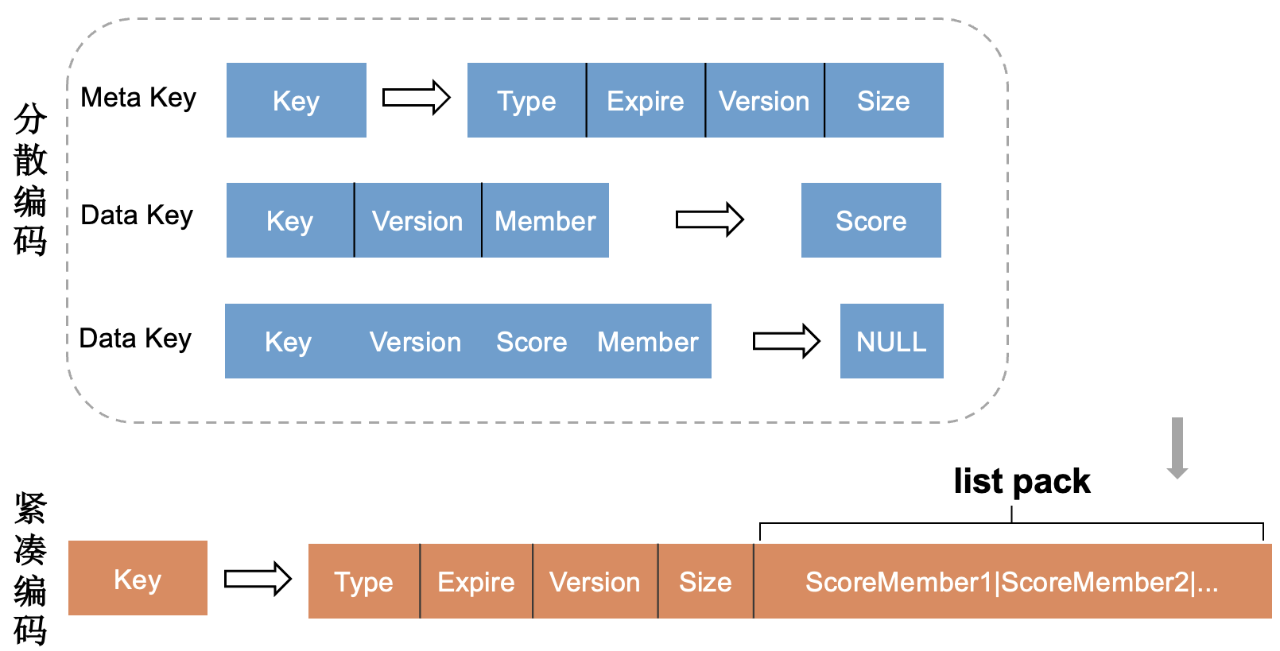
在编码优化方面,Kvrocks分散编码的方式在批量、范围操作时会涉及多次磁盘IO性能差。PegaDB自定了前缀迭代器,显著提升了迭代效率;同时,PegaDB扩展了紧凑型编码,批量、范围操作时,一次磁盘操作可以读到全部的数据,大大提升了性能。
PegaDB设计与实践丨异地多活架构
百度很多业务场景对可用性有着很高的要求,需要支持地域级别容灾。这就要求PegaDB支持多地域部署,同时为了降低业务访问延迟,PegaDB多个地域的集群还需要支持就近访问。
为此,PegaDB设计了异地多活的架构, PegaDB并没有采用传统基于DTS的方案来进行多个地域间数据的同步,这主要是出于同步性能的考虑。
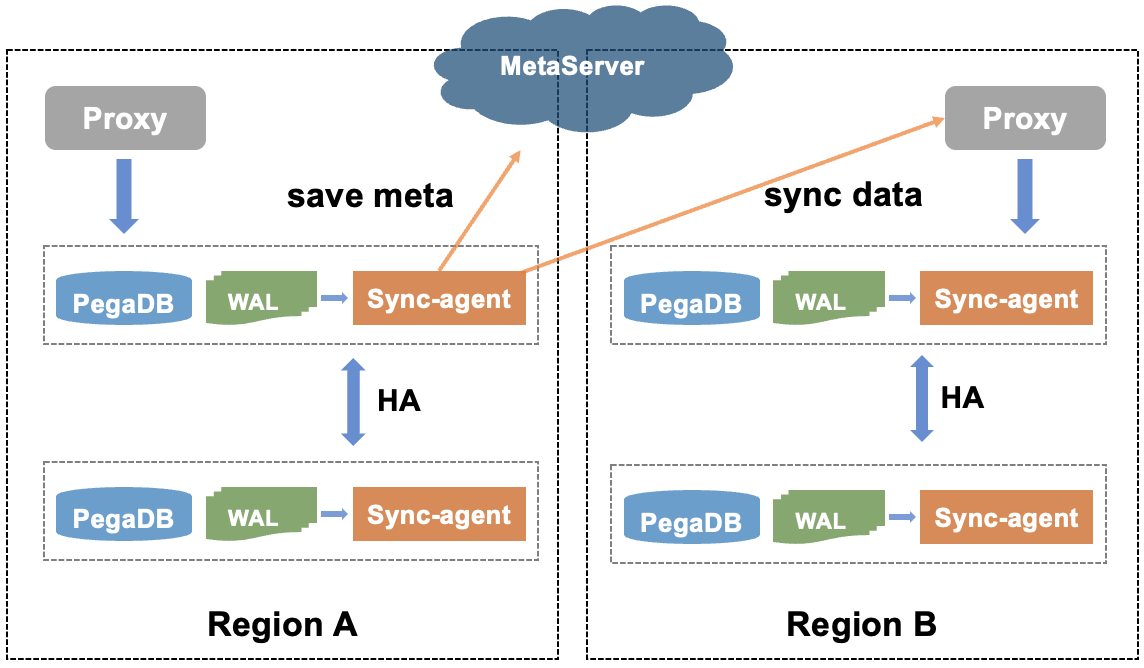
如下图所示,PegaDB设计了SyncAgent同步组件来同步数据,SyncAgent和PegaDB同机部署,并且出于HA考虑SyncAgent在PegaDB主从实例上都会部署,但是只有主库上的SyncAgent会工作;为了避免循环复制,在WAL日志中增加了ShardID信息,ShardID全局唯一,SyncAgent通过ShardID区分是否是本地域写入的数据,SyncAgent只会同步本地写入的数据,因此也就解决了循环复制的问题。为了支持断点续传, PegaDB增加了OpID信息,OpID单调递增,并且会及时更新到配置中心,同步中断后基于配置中心中存储的OpID信息进行断点续传。对于异地多活架构,还需要解决多地域写冲突的问题, PegaDB采用简单的LWW方案(Last Write Win)。
PegaDB设计与实践丨Json数据模型
PegaDB虽然兼容Redis丰富的数据类型,但是业务实际使用过程中仍遇到了一些问题。比如业务要存储JSON格式的数据,只能转换成STRING/HASH数据类型来存储,这就带来了一些问题:1、需要业务对数据进行序列化/反序列操作,增加了开发复杂度;2、读取、更新部分字段,存在读写放大问题;3、并发更新字段时存在数据一致性问题。
针对上述问题,PegaDB借鉴RedisJSON Module的思路,原生支持了JSON数据模型,这样做的好处是业务无需再做模型转换,使用STRING/HASH存储JSON格式数据的问题自然也就没有了。
PegaDB的JSON数据模型完全兼容RedisJSON Module的协议,同时支持JSONPath语法查询和更新文档中的元素,支持原子操作所有JSON Value类型,并且采用了紧凑型编码存储,天然支持热Key缓存,对于冷热区分明显的场景特别友好。
PegaDB设计与实践丨ZSET&HASH命令增强
除了JSON等新增的数据类型,PegaDB结合业务需求对现有数据类型也做了很多扩展,比如:ZSET类型支持聚合、结果过滤操作,HASH类型支持Range操作。
开源社区协作

PegaDB从设计之初,就坚定了深度参与社区,与社区共建的思路。截止到目前PegaDB已经持续向Kvrocks社区回馈了主从复制优化、事务、存储引擎优化、集群等多个重要PR。并且与社区一起推进了Kvrocks成为Apache孵化项目,目前百度Redis团队拥有2名Kvrocks PPMC成员(共4名),4个Commiter。后续会继续和社区一起努力让Kvrocks项目发展的越来越好。
未来规划
未来PegaDB会继续在以下几个方面继续提升,1、借助云基础设施进一步提升弹性能力,发布Serverless产品;2、借鉴Redis Module生态,支持更丰富的数据模型;3、支持连接器,更方便集成大数据生态,简化业务开发;4、通过内核io_uring特性、线程模型优化等方案持续优化性能
广告时间:百度智能云Redis容量版(PegaDB)已经在百度智能云正式发布,也欢迎大家使用!
|嘉宾介绍|

刘东辉
百度 资深研发工程师
刘东辉,百度智能云Redis内核团队技术负责人,开源项目Kvrocks Core Team成员。近十年一直专注于分布式缓存、存储方向,先后主导过微博、百度NOSQL数据库研发工作,并在DTCC、SACC等技术大会上做过多次技术分享,具有非常丰富的NOSQL数据库内核研发及优化经验。

