流批一体的实时特征工程平台建设实践
导读:本文主要分享阿里云 FeatHub 项目组在特征工程开发中的平台实践和建设经验。
本次分享分为四大部分,第一部分总体介绍 FeatHub 在特征开发、部署、监控、分享过程中面临的场景、目标、痛点和挑战;第二部分介绍 FeatHub 的架构思路实践,及相关核心概念;第三部分介绍 FeatHub 在使用过程中的 API 基本使用、基本计算功能,样例场景的代码实践,还有性能优化,未来的扩展目标,以及开源社区的共建,提供项目的学习、开发使用,还将分享 FeatHub 历史数据的回放功能, 支持离线、近线、在线处理和阿里云上下游组件的支持等问题。
01 为什么需要 FeatHub
1. 目标场景
(1)需要 Python 环境的数据科学家
今天大部分流行的机器学习的推理和训练程序基本都是由数据科学家用 Python 来编写的,比如流行的 TensorFlow、PyTorch 以及一些传统机器学习场景中用到的 scikit-learn 等等。我们希望支持数据科学家继续使用熟悉的 Python 编写特征工程代码来完成端到端机器学习链路的开发与部署,并且能够使用他们所熟悉的 Python 生态环境中的库。
(2)生成实时特征
越来越多的机器学习应用在往实时方向发展,通过实时处理可以提高机器学习的效率和准确度。为了达到目标,需要生成实时特征。这里不仅仅是去实时获取查询特征,而是要实时生成特征。例如需要实时获取用户在最近两分钟内的点击次数,为此需要使用流式计算引擎完成实时特征计算。
(3)需要开源方案支持多云部署
越来越多的中小型公司希望做到多云部署,以得到生产的安全保证,以及获得云厂商之间的竞价优势。因此我们的方案不要求用户绑定一个云厂商,而是要让用户能够自由地在不同云厂商之间做选择,甚至在私有云部署特征工程作业。
这是 FeatHub 项目设立之初所希望满足的一些条件。
2. 实时特征工程的痛点
今天已经有很多公司在开发实时特征工程作业。其中存在一些痛点,涵盖了特征的整个生命周期,包含开发、部署、监控、以及之后的分享。
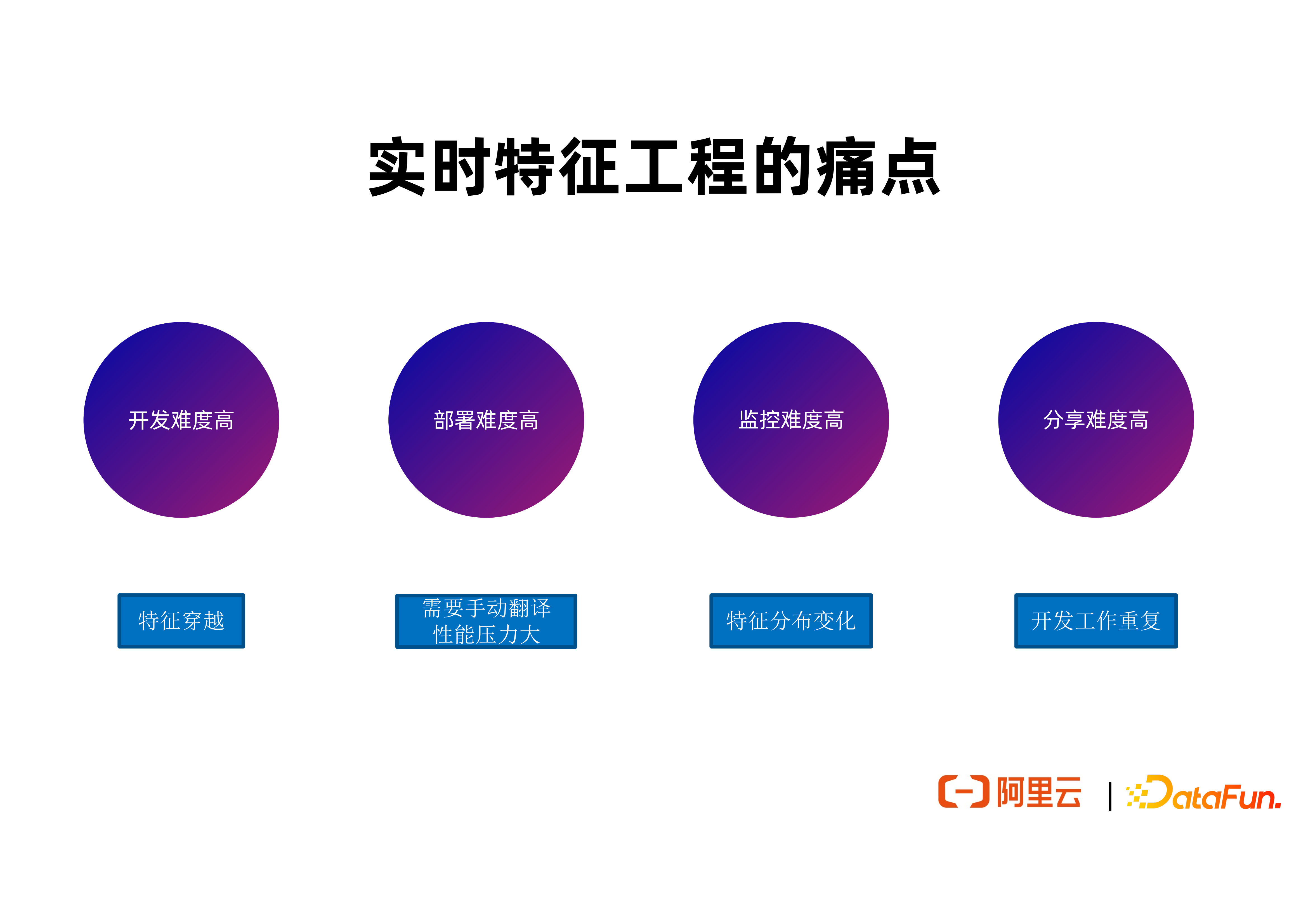
(1)开发难度高
① 特征穿越
开发阶段,用的比较多的是实时特征框架 Apache Flink,因为 Flink 已经基本上是实时流计算的事实标准,但是用 Flink 或者类似的框架来开发实时特征存在着需要解决特征穿越的难点。很多数据科学家并不了解特征穿越的解决经验,并且需要比较多的学习时间和成本来解决这类问题,这是开发阶段的主要痛点。
(2)部署难度高
① 需要手动翻译
很多公司会有一个专门的平台团队把数据科学家写的单进程 Python 作业翻译成可分布式执行的 Flink 或者 Spark 作业,来实现高性能高可用的部署。其翻译过程会增加整个开发生命周期长度。并且因为还需要额外的人力去做翻译工作,增加了开发成本,更进一步带来了引入 Bug 的可能。另一拨人将数据科学家的作业翻译之后的逻辑未必和原先的逻辑保持一致,这样就带来更多的 Debug 工作量。
(3)监控难度高
① 特征分布变化
特征工程作业的整个质量和效率不只是取决于作业有没有 Bug,还依赖于上游的输入数据数值分布能满足一些特性,例如能接近于训练时的数据数值分布。很多作业的推理效果下降,经常是由于上游作业生产的数据分布发生了变化。这种情况下,需要开发者去追踪整个链路,一段段去看在哪个地方的特征数据分布发生了变化,根据具体情况再去看是否需要重新训练或者解决 Bug。这部分人力工作量过大也是一个痛点。
(4)分享难度高
① 开发工作重复
虽然很多特征计算作业的开发团队和场景不同,但其实用了类似甚至相同的特征定义。很多公司中没有一个很好的渠道,让公司内不同团队能查询和复用已有特征。这就导致不同团队经常需要做重复开发,甚至对于相同特征需要重复跑作业去生成一些特征。这带来了人力和计算/储存资源的浪费,因为需要更多的计算、内存、存储空间去生成相同特征。
② point-in-time correct 语义
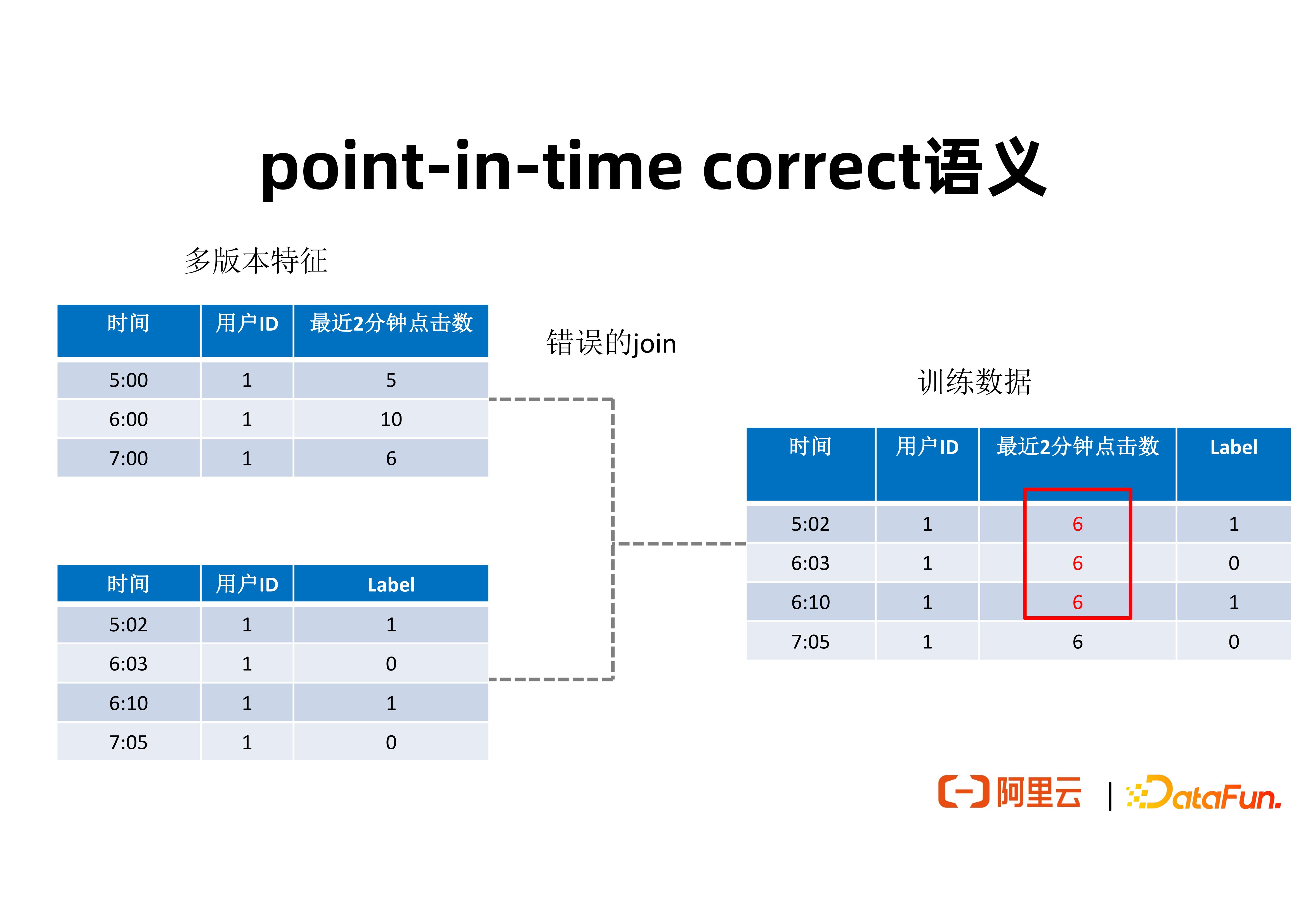
为了让大家能够理解什么叫特征穿越,上图给出了一个简单例子,来展现这个问题。图左上表是用户的一个行为特征,表达了在不同时间节点,对于一个给定 ID 的用户,在最近两分钟内的点击数。这个点击数可能帮助我们推理用户是否会点击某个广告。为了用这些特征去做训练,通常需要将特征拼接到用户带有 Label 的一些数据集上。图左下表展现的是一个用户实际有没有点击广告的一些正样本和负样本的数据集,标注了在不同的时间点,用户所产生的正样本或负样本。为了将这两个数据集中的特征拼接起来,形成训练用的数据集,通常需要根据用户 ID 作为 key 进行特征拼接。如果只是简单地进行 Table Join,不考虑时间戳,就可能产生特征穿越问题。 例如在 6:03 分时,用户最近 2 分钟点击数应该是 10,但拼接得到的特征值可能是来自 7:00 分时的 6。这种特征穿越会带来实际推理效果的下降。一个具有 point-in-time correct 语义的 Join 结果应该如下图所示:

为了在样本拼接时避免特征穿越,对于在上图左表中的每一条数据,应该在维表的多个版本特征当中找到时间戳小于并且最接近于左表中的时间戳的特征数值,并将其拼接到最终生成的训练数据集上。这样一个具有 point-in-time correct 语义的拼接,将产生上图右边所显示的训练数据集。针对不同的时间点,都有所对应最近两分钟内产生的特征值。这样生成的训练数据集可以提高训练和推理的效果。
3. Feature Store 的核心场景
接下来介绍 FeatHub 作为一个 Feature Store,对于整个特征开发周期的每一阶段试图解决的问题和提供的工具。
(1)特征开发
在特征开发阶段,FeatHub 会提供一个基于 Python 的具有高易用性的 SDK,让用户能简洁地表达特征的计算逻辑。特征计算本质是一个特征的 ETL。开发阶段最重要的是 SDK 的易用性和简洁性。
(2)特征部署
在特征部署阶段,FeatHub 会提供执行引擎,实现高性能,低延迟的特征计算逻辑的部署,并且能对接不同的特征存储。部署阶段最重要的是执行引擎的性能和对接不同特征存储的能力。
(3)特征告警
在特征监控阶段,为了方便开发者及时发现特征数值分布的变化并做出应对,FeatHub 将来会产生一些常用指标来覆盖常见的特征质量问题,例如具有非法数值的特征比例,或者特征平均值,并根据这些指标进行报警,去及时通知负责人调查相关特征分布变化的原因和做出应对,来维护端到端的推荐链路的效果。
(4)特征分享
在特征分享阶段,FeatHub 将来会提供特征的注册和搜索能力,支持同一公司内不同团队的开发人员去查询自己想要的特征是不是已经存在,并复用这些特征定义和已经产生的特征数据。
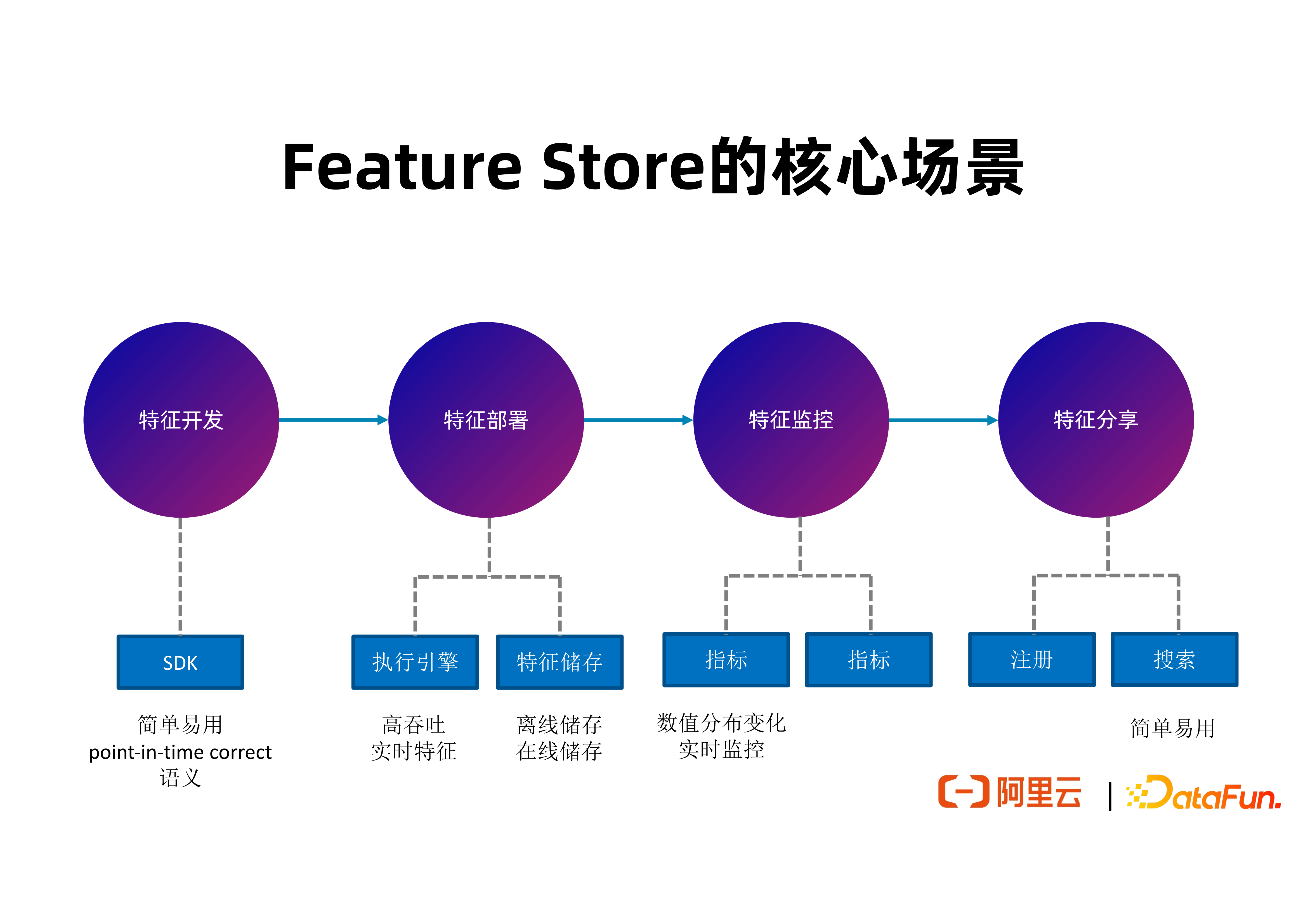
上图中说明 FeatHub 的核心特点。在开发阶段,FeatHub 能提供简单易用的 SDK,支持具有 point-in-time correct 语义的特征拼接,特征聚合等逻辑。在部署阶段,FeatHub 能支持高吞吐、低延迟的特征生成,支持使用 Flink 作为执行引擎来计算特征;并且能支持多种特征存储系统,方便用户自由选择所希望使用的存储类型。在监控阶段, FeatHub 将能提供实时指标来监控特征分布的变化,包含离线和实时监控,方便开发者及时发现问题。在分享阶段,FeatHub 将会提供简单易用的 Web UI 以及 SDK,支持开发者注册,搜索和复用特征。

在 Feature Store 领域内已经有一些具有代表性的 Feature Store 项目,例如今年初 LinkedIn 开源的 Feathr,以及开源了多年的 Feast。我们调研了这些项目,发现他们并不能很好地达成我们提出的目标场景。
FeatHub 相比现有方案,带来的额外价值包括:
① 简单易用的 Python SDK。FeatHub 的 SDK 参考了已有的 Feature Store 项目的 SDK,能支持这些项目的核心功能,并进一步提升了 SDK 的抽象能力和易用性,
② 支持单机上的开发和实验。开发者不需要对接分布式的 Flink 或 Spark 集群来跑实验,而只需要使用单机上的 CPU 或者内存资源就可以进行开发和实验,并能使用 scikit-learn 等单机上的机器学习算法库。
③ 无需修改代码即可切换执行引擎。当用户完成单机上的开发后,可以将单机执行引擎切换到 Flink 或 Spark 等分布式执行引擎,而无需修改表达特征计算逻辑的代码。使用 Flink 作为执行引擎可以让 Feathub 支持高吞吐、低延时的实时特征计算。FeatHub 将来会进一步支持使用 Spark 作为执行引擎,让用户在离线场景中可以得到潜在的更好的吞吐性能,根据场景自由选择最合适的执行引擎。
④ 提供执行引擎的扩展能力。FeatHub 不仅可以支持以 Flink、Spark 作为执行引擎,还支持开发者自定义执行引擎,使用公司内部自研的执行引擎进行特征 ETL。
⑤ 代码开源,使得用户可以自由选择部署 FeatHub 的云厂商,也可以在私有云中进行部署。
02 FeatHub 架构与核心概念
1. 架构

以上是包含 FeatHub 主要模块的架构图。最上层提供了一套 Python SDK,支持用户定义数据源、数据终点以及特征计算逻辑。由 SDK 所定义的特征可以注册到特征元数据中心,支持其他用户和作业来查询和复用特征,甚至可以基于特征元数据进一步分析特征血缘。特征定义包含了特征的 source、sink,以及常见的计算逻辑,例如 UDF 调用、特征拼接,基于 over 窗口与滑动窗口的聚合等。当需要取生成用户所定义的特征时,FeatHub 会提供一些内置的 Feature Processor,也就是执行引擎,去执行已有特征的计算逻辑。当用户需要在单机上做实验时,可以使用 Local Processor 使用单机上的资源,无需对接一个远程的集群。当需要生成实时特征时,可以使用 Flink Processor 完成高吞吐、低延时的流式特征计算。
将来也可以支持类似于 Lambda Function 的 Feature Service 来实现在线的特征计算,以及对接 Spark 来完成高吞吐的离线特征计算。执行引擎可以对接不同的离线和在线特征储存系统,例如用 Redis 完成在线特征储存,用 HDFS 完成离线特征储存,以及用 Kafka 完成近线特征储存。
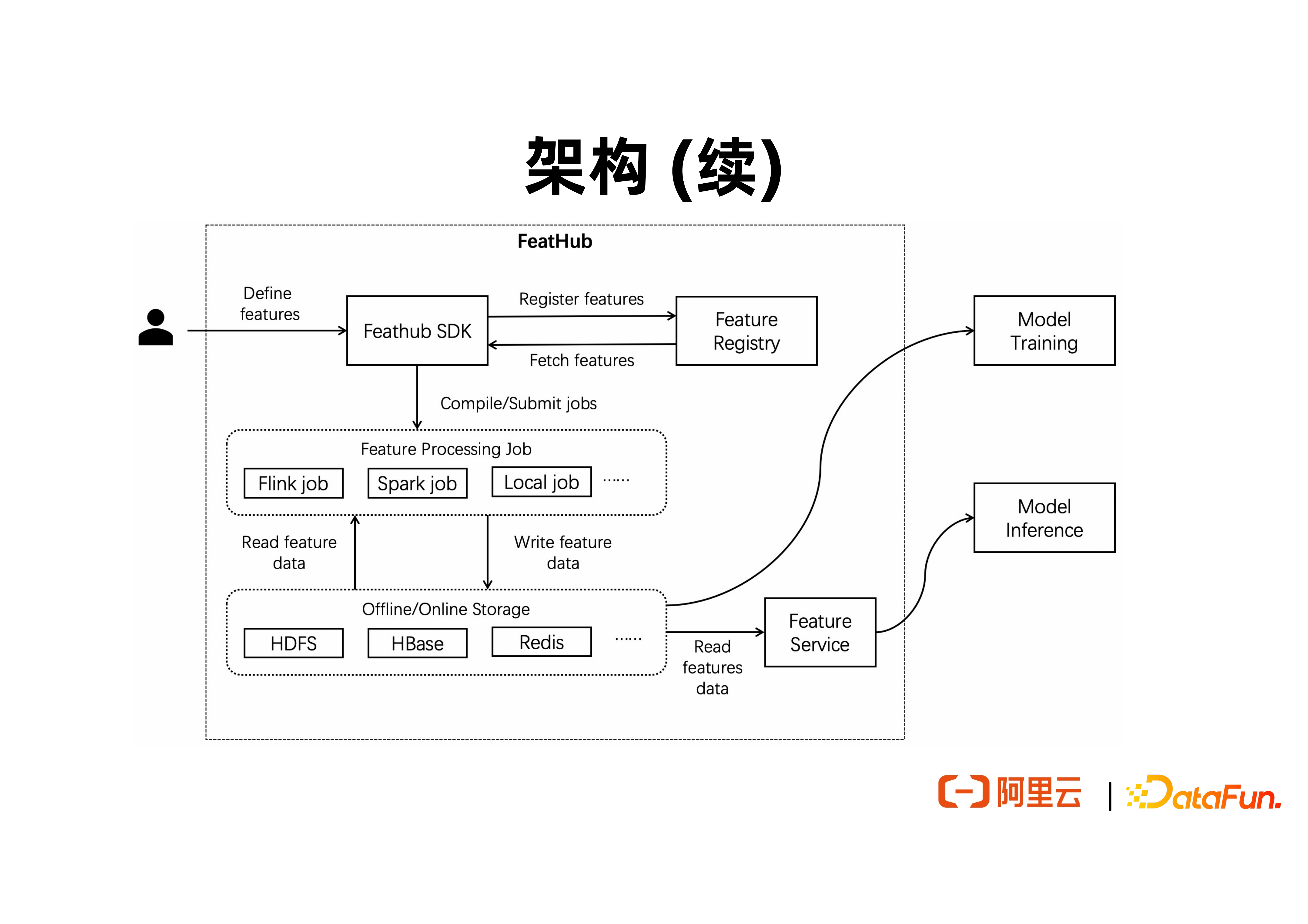
上图展现了 FeatHub 如何被用户使用,以及对接下游的机器学习训练和推理程序,用户或开发者将通过 SDK 来表达所希望计算的特征,然后提交到执行引擎上进行部署。特征经过计算后,需要输出到特征储存,例如 Redis 和 HDFS。一个机器学习离线训练程序可以直接读取 HDFS 中的数据去做批量训练。一个在线的机器学习推理程序可以直接读取 Redis 中的数据进行在线推理。
2. 核心概念
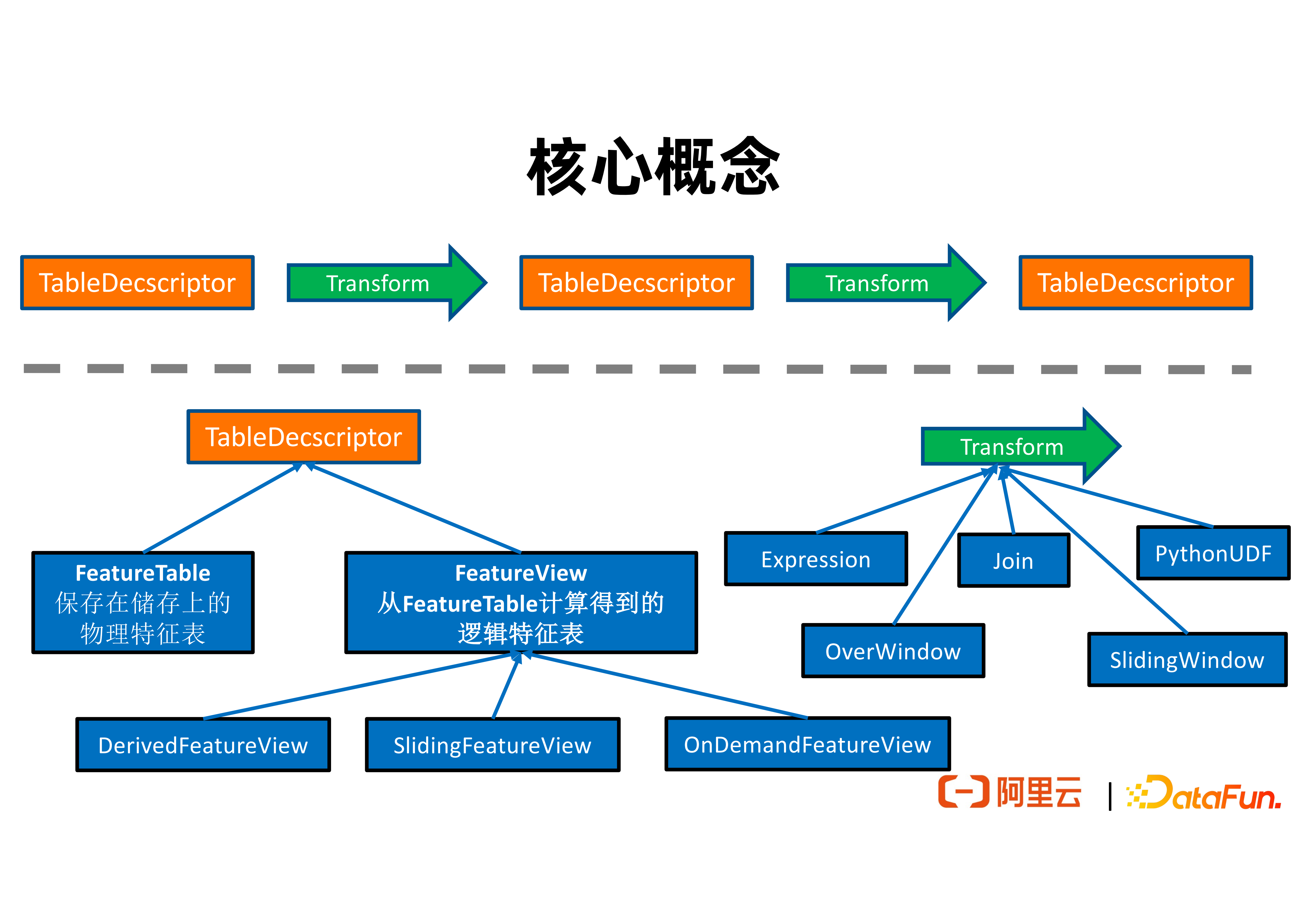
上图展现了 FeatHub 中的核心概念之间的关系。一个 TableDescriptor 表达一组特征的集合。TableDescriptor 经过逻辑转换可以生产一个新的 TableDescriptor。
TableDescriptor 分为两类。其中 FeatureTable 表达的是具有特定物理地址的表,例如可以是一个在 Redis 中的表,也可以是一个在 HDFS 中的表。FeatureView 则是一些不一定有物理地址的逻辑表,通常是从一个 FeatureTable 经过一连逻辑串转换后得到的。
FeatureView 有如下 3 个子类:
① DerivedFeatureView 输出的特征表和其输入的特征表(i.e. source)的行基本是一对一的。它可以支持表达单行转换逻辑(e.g. 加减乘除),over window 聚合逻辑,以及特征拼接逻辑。它可用于生成训练数据。例如在之前所介绍的例子中,需要将训练样本去拼接来自不同维表的特征以得到实际的训练数据,就可以使用 DerivedFeatureView 来完成。
② SlidingFeatureView 支持表达由滑动窗口计算得到的特征。它输出的特征表和其输入的特征表的行不一定是一对一的。这是因为即使没有新的输入,滑动窗口计算得到的特征数值会随着时间流逝而变化。SlidingFeatureView 可以用于维护实时生成的特征,并输出到在线特征存储,例如 Redis,用于在线推理。例如,我们可以用 SlidingFeatureView 去计算每个用户最近两分钟内点击某个网页的次数,并将特征数值实时更新到 Redis 中,然后广告推荐链路就可以在线查询这个特征的值来做在线推理。
③ OnDemandFeatureView 可以与 Feature Service 用在一起,支持在线特征计算。例如在使用高德地图时,开发者可能会希望在收到用户的请求之后,根据用户当前的物理位置与上一次发送请求时的物理位置,计算出用户移动的速度和方向速度,来协助推荐路线的决策。这些特征必须在收到用户请求的时候进行在线计算得到。OnDemandFeatureView 可以用于支持这类场景。
Transform 表达的是特征计算逻辑。FeatHub 当前支持如下 5 种特征计算逻辑:
① Expression 支持用户基于一个 DSL 语言表达单行的特征计算逻辑。其表达能力接近SQL 语言中的 select 语句,可以支持加减乘除和内置函数调用,可以让熟悉 SQL 的开发者快速上手。
② Join 表达的是特征拼接逻辑。开发者可以指定维表的名字和需要拼接的特征名字等信息。
③ PythonUDF 支持用户自定义 Python 函数来计算特征。
④ OverWindow 表达的是 Over 窗口聚合逻辑。例如在收到一行数据时,用户希望根据之前的 5 行数据,进行聚合并计算有多少条数据符合某个规则。
⑤ SlidingWindow 表达的是滑动窗口聚合逻辑。
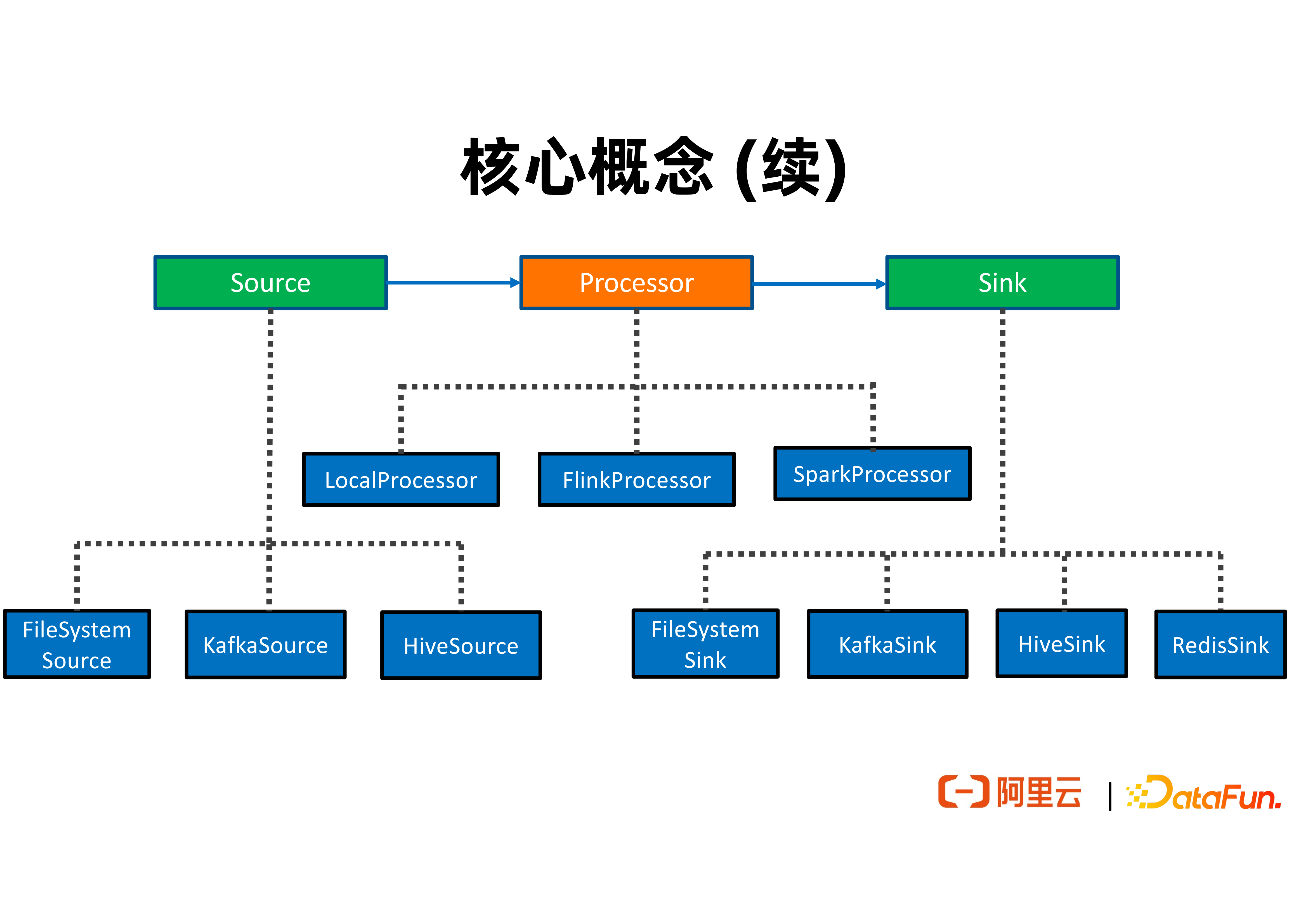
从上图中可以看到,通常一个特征 ETL 作业会从特征源表读取特征,经过多次特征计算逻辑产生新的特征,并将生成的特征输出到特征结果表。特征源表可以对接不同的特征存储,例如有 FileSystem,Kafka,Hive 等。类似的,特征结果表也可以对接 FileSystem,Kafka,Redis 等特征储存。
Processor 包括 LocalProcessor、FlinkProcessor、SparkProcessor,分别可以使用单机物理资源,分布式的 Flink 集群,以及分布式 Spark 集群,去执行用户所定义的特征计算逻辑。
03 FeatHub API 展示
1. 特征计算功能

在介绍了 FeatHub 的架构和核心概念后,我们将通过一些样例程序来展现 FeatHub SDK 的表达能力以及易用性。对于特征开发 SDK 来说,其最核心的能力就是如何表达新的特征计算逻辑。FeatHub SDK 支持特征拼接、窗口聚合、内置函数调用以及自定义 Python 等能力,将来还可以支持基于 JAVA 或者 C++ 的 UDF 调用。
上图展示了一个特征拼接的代码片段。在这个例子中,假设 HDFS 中有原始的正负样本数据,记录了用户购买商品的行为。我们想进一步想获取用户在购买每个商品时的商品价格。一个 price_updates 表维护了商品价格变化的数据。每次商品价格变化时,会在 price_updates 表中产生一行数据,包含商品 ID 和最新的商品价格。我们可以使用 JoinTransform,设置 table_name=price_updates,feature_name=price,以及 key=item_id,来表达相应的特征拼接逻辑。这样 FeatHub 就可以根据在 price_updates 中,找到具有给定 item_id 的行,并根据时间戳,找到最合适的 price 数值,来拼接到样本数据表上。
Over 窗口聚合的代码片段则展示了如何用 OverWindowTransform 来计算特征。用户可以使用 expr=”item_counts * price”,以及 agg_fun=”SUM”,来根据购买的商品数量和价格,计算出最近时间窗口中的总消费量。其中窗口的时间长度为 2 分钟。group_by_keys=[“user_id”] 则说明了我们会为每个用户单独计算出对应的总消费量。
滑动窗口聚合与 Over 窗口聚合比较类似,API 上唯一区别是可以额外指定 step_size。如果 step_size=1 分钟,则窗口会在每分钟进行滑动并产生新的特征值。
内置函数调用的代码片段展示了如何使用 DSL 语言表达加减乘除和 UDF 调用。假设输入的数据包含出租车接送乘客的时间戳。我们可以通过调用 UNIX_TIMESTAMP 内置函数将接送乘客的时间戳转换为整数类型的 epoch time,然后将得到的 epoch time 相减,得到每次旅程的时间长度,作为一个特征用于之后的训练和推理。
在 PythonUDF 调用的代码片段中,用户可以自定义一个 Python 函数,对输入的特征进行任意的处理,例如产生小写的字符串。
通过以上几个代码片段,我们可以看出 FeatHub 的 API 是比较简洁易用的。用户只需要设置计算逻辑所必须的参数,而无需了解处理引擎的细节。
2. 样例场景
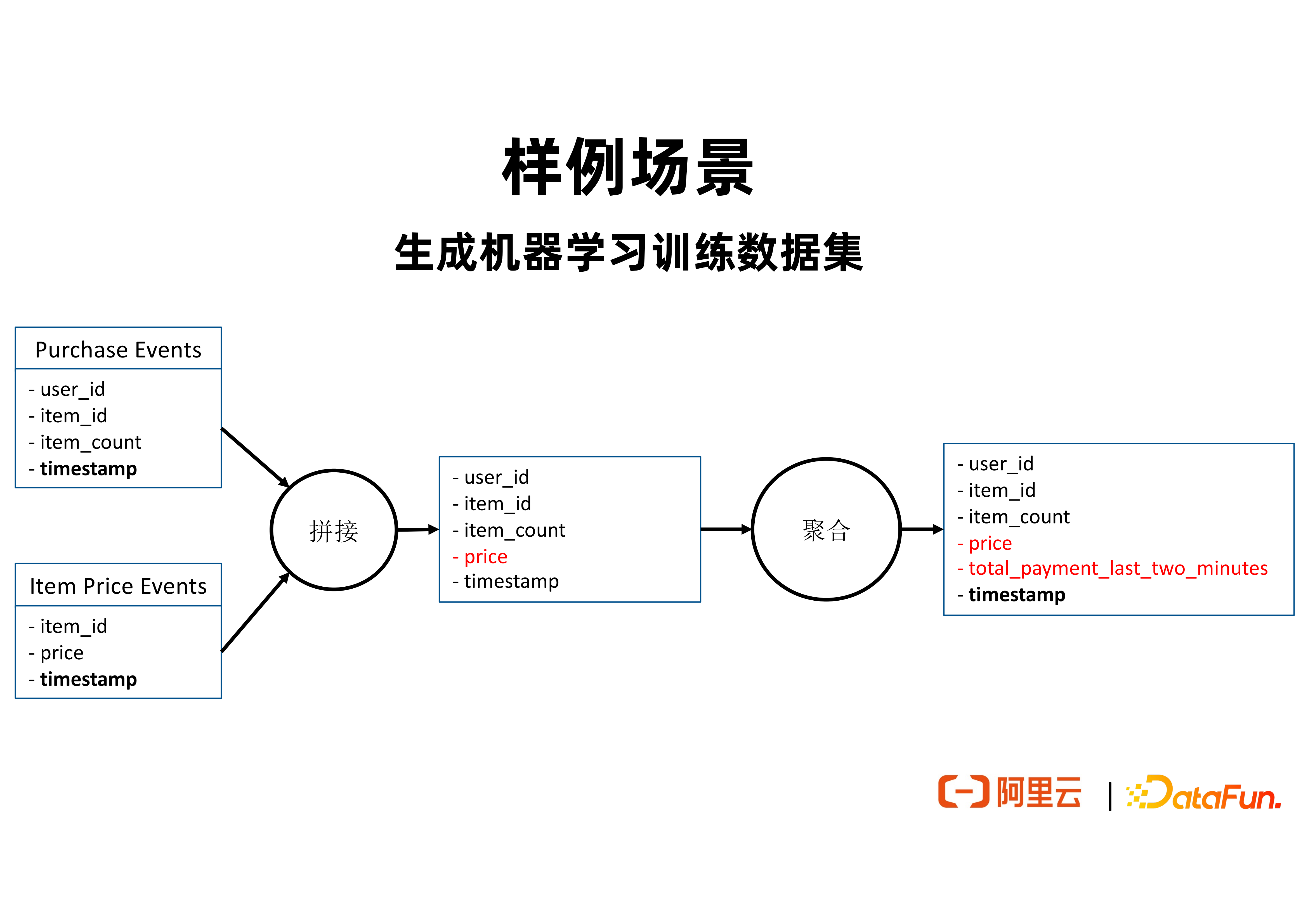
在以上样例场景中,用户有两个数据源。其 Purchase Events 包含用户购买商品的样本数据,可以来自于 Kafka,也可以来自于 FileSystem;Item Price Events 包含商品价格变动的数据。每次商品价格变化时,会在 Item Price Events 中产生一行数据,包含商品 ID 和最新的商品价格。我们希望对于每条用户购买商品的样本数据,计算用户在该行为发生时最近两分钟内的消费总量,作为特征来协助推理出用户会不会购买某样商品。为了生成这个特征,可以使用上图中所描述的计算逻辑,先将 Item Price Events 中的 price 特征以 item_id 作为 join_key 拼接到 Purchase Events 上。然后再基于时间窗口和使用 user_id 作为 group_by _keys 进行聚合,来计算得到每个用户最近两分钟内的消费总量。
3. 样例代码

以上代码片段展示了一个样例 FeatHub 应用所需要完成的步骤。
① 首先用户需要创建一个 FeatHubClient 并设置 processor_type。如果是本地实验,可以设置成 Local,如果是远程分布式生产部署,可以设置成 Flink。
② 用户需要创建 Source 来读取数据,例如可以使用 FileSystemSource 读取在离线储存系统中的数据,或者使用 KafkaSource 读取近线储存系统中的实时数据。FileSystemSource 中,用户可以指定例如 data_format,schema、文件的位置等信息。值得注意的是,用户可以提供 time_stamp_field 和 time_stamp_format,分别表达数据源表中代表时间的列以及对应的解析格式。FeatHub 将使用这些信息完成做 point-in-time correct 的特征计算,避免特征穿越的问题。
③ 用户可以创建一个 FeatureView 来表达特征拼接和聚合的逻辑。如果要做拼接,用户可以 item_price_events.price 来表达希望拼接的特征。FeatHub 会找到名字为 item_price_events 的表并从中拿到名字为 price 的特征。用户还可以使用 OverWindowTransform 来完成 Over 窗口聚合,定义一个名为total_payment_last_two_minutes 的特征。其中 window_size=2 分钟表示对于两分钟内的数据应用指定的表达式和聚合函数来计算特征。

④ 对于已经定义的 FeatureView,如果用户想做本地开发和实验,并使用 scikit-learn 算法库进行单机上的训练,可以使用 to_pandas() API 来将数据以 Pandas DataFrame 格式获取到单机的内存中。
⑤ 当用户需要完成特征的生产部署时,可以使用 FileSystemSink 指定用于存放数据的离线特征储存。然后调用 execute_insert() 将特征输出到所指定的 Sink 当中。

FeatHub 的基本价值是提供 SDK 来方便用户开发特征,并且提供执行引擎来计算特征。除此之外,FeatHub 还将提供执行引擎的性能优化,让用户在特征部署阶段获得更多的收益。例如对于基于滑动窗口聚合的特征,目前如果使用原生的 Flink API 来计算,Flink 会在每个滑动的 step_size 都输出对应的特征值,无论特征的数值是否发生了变化。对于 window_size=1 小时,step_size=1 秒这样的滑动窗口,大部分情况下 Flink 可能会输出相同的特征数值。这样会浪费网络流量、下游存储等资源。FeatHub 中支持用户配置滑动窗口的行为,允许滑动窗口只在特征数值发生变化的时候输出特征,来优化特征计算作业的资源使用量。
另外 FeatHub 还将进一步优化滑动窗口的内存和 CPU 使用量。在某些场景中,用户会定于许多类似的滑动窗口特征。这些特征只有 window size 不一样。例如我们可能希望得到每个用户最近 1 分钟,5 分钟,和 10 分钟内的购买商品的花费总数。如果使用原生的 Flink API 来计算,作业可能会使用三个聚合算子来分别计算这 3 个特征。每个聚合算子会有单独的内存空间。考虑到这些算子所处理的数据和计算逻辑具有较大的重合,FeatHub 可以用一个自定义算子,统一完成这些特征的计算,来达到节约内存和 CPU 资源的目标。

FeatHub 目前已经在 GitHub 开源,能够支持一些基本的 LocalProcessor 和 FlinkProcessor 的功能。我们会进一步完善 FeatHub 的核心功能来方便用户特征工程的开发和落地。其中包括支持更多常用的离线储存、在线存储,对接 Notebook,提供 Web UI 来可视化特征的元数据,支持用户做特征的注册、搜索、复用,以及支持使用 Spark 作为 FeatHub 的执行引擎。

