容器集群监控系统架构如何对症下药?
一、概述
在云原生的体系下,面对高弹性、拆分微服务以及应用动态生命周期等特点,传统监控体系如 cacti 、nagios 、Zabbix 等已经逐渐丧失了优势,难以适用和支撑,对应的新一代云原生监控体系应运而生,Prometheus 为核心的监控系统已成为云原生监控领域的事实标准。
之前公司有文章介绍过,Qunar 内部的一站式监控平台,后端存储是基于 Graphite+Whisper 做的二次开发,前端控制面是基于 Grafana 做的二次开发。而 Grafana 是支持多数据源的,其中就包含 Prometheus 数据源。所以在容器化落地期间最初计划采用的监控方案也是 Prometheus ,其本身是个 All in One 的系统,拥有强大的 PromQL ,集采集、处理、存储、查询、rule检测于一身,非常易于部署和运维。但每个系统都不是完全能够契合使用需求的,Prometheus 也一样不是完美的。
该文章将以 Qunar 容器监控实践过程和经验为基础,讲述我们监控体系构建、遇到的挑战和相应对策,以及对 VictoriaMetrics 的简单介绍与 Qunar 在过渡至 VictoriaMetrics 后的效果。
二、使用Prometheus的相关问题
Prometheus 是个 All in One 的系统,集采集、处理、存储、查询、rule 检测于一身,这样做易于部署和运维,但也意味着丧失了拆分组件所具备的独立性和可扩展性。实践测试摘录的几个问题如下:
数据采集量大存在瓶颈,目前 Qunar 单集群容器指标量级每分钟将近 1 亿;
不支持水平扩容;
只支持 All in One 单机部署,不支持集群拆分部署;
其本身不适用于作为长期数据存储;
占用资源高;
查询效率低,Prometheus 加载数据是从磁盘到内存的,不合理查询或大范围查询都会加剧内存占用问题,范围较大的数据查询尤其明显,甚至触发 OOM 。
如上例举的几项问题点,其实对于大多数公司来讲都不是问题,因为没有那么大的数据量和需求。但是对于我们或一些数据规模较大的公司来讲,每一项都在对我们的使用环境说 No... 我们也对这些问题尝试了以下解决方案:
使用分片,对 Prometheus 进行按服务维度分片进行分别采集存储。默认告警策略条件是针对所有 Targets 的,分片后因每实例处理的 Targets 不同,数据不统一,告警规则也需要随着拆分修改。
使用 HA ,也就是跑两个 Prometheus 采集同样的数据,外层通过负载均衡器进行代理对其实行高可用
使用Promscale作为其远程存储,保留长期数据注:Promscale是 TimescaleDB 近两年发布的一个基于 TimescaleDB 之上的 Prometheus 长期存储。
但做了这些处理后,其实还是留存问题,也有局限性和较大隐患:
例如 2 个实例,1、2 同时运行采集相同数据,他们之间是各自采集各自的没有数据同步机制,如果某台宕机一段时间恢复后,数据就是缺失的,那么负载均衡器轮训到宕机的这台数据就会有问题,这意味着使用类似 Nginx 负载均衡是不能够满足使用的。
各集群 2w+ Targets,拆分 Prometheus 后可以提升性能,但依然有限,对资源占用问题并未改善。
远程存储 Promscale 资源占用极大,40k samples/s,一天 30 亿,就用掉了将近16 cores/40G 内存/150GB 磁盘。而我们单集群1.50 Mil samples/s,一天就产生 1300 亿左右,而且需求数据双副本,这样的资源需求下如果上了线,仅磁盘单集群 1 天就要耗费 12TB 左右,这样的代价我们是表示有些抗拒的……
三、接触 VictoriaMetrics
在为调整后面临到的这些难点,进行进一步调研,结合 Qunar 自身经验和需求参考各类相关文档以及各大厂商的架构分享时,我们注意到了 VictoriaMetrics ,并在其官网列出的诸多用户案例中,发现知乎使用 VictoriaMetrics 的数据分享与我们的数据规模量级几乎一致,而且性能与资源表现都相当优异,非常符合我们期望需求,便开始了 VictoriaMetrics 的尝鲜旅程,也归结出适合我们生产场景的云原生监控体系架构,并在后续工作中通过使用测试完全满足我们需求,进行了全面替换使用。
在此,先对 VictoriaMetrics 进行介绍,也推荐给大家对 VictoriaMetrics 进行了解和使用,后面也会贴出我们的使用架构和效果展示。
1、VictoriaMetrics 介绍
VictoriaMetrics (后续简称 VM )是一种快速、经济高效且可扩展的监控解决方案和时间序列数据库,它可以仅作为 Prometheus 的远程写入做长期存储,也可以用于完全替换 Prometheus 使用。
Prometheus 的 Config、API、PromQL,Exporter、Service discovery 等 VM 基本都能够兼容支持,如果作为替换方案,替换成本会非常低。
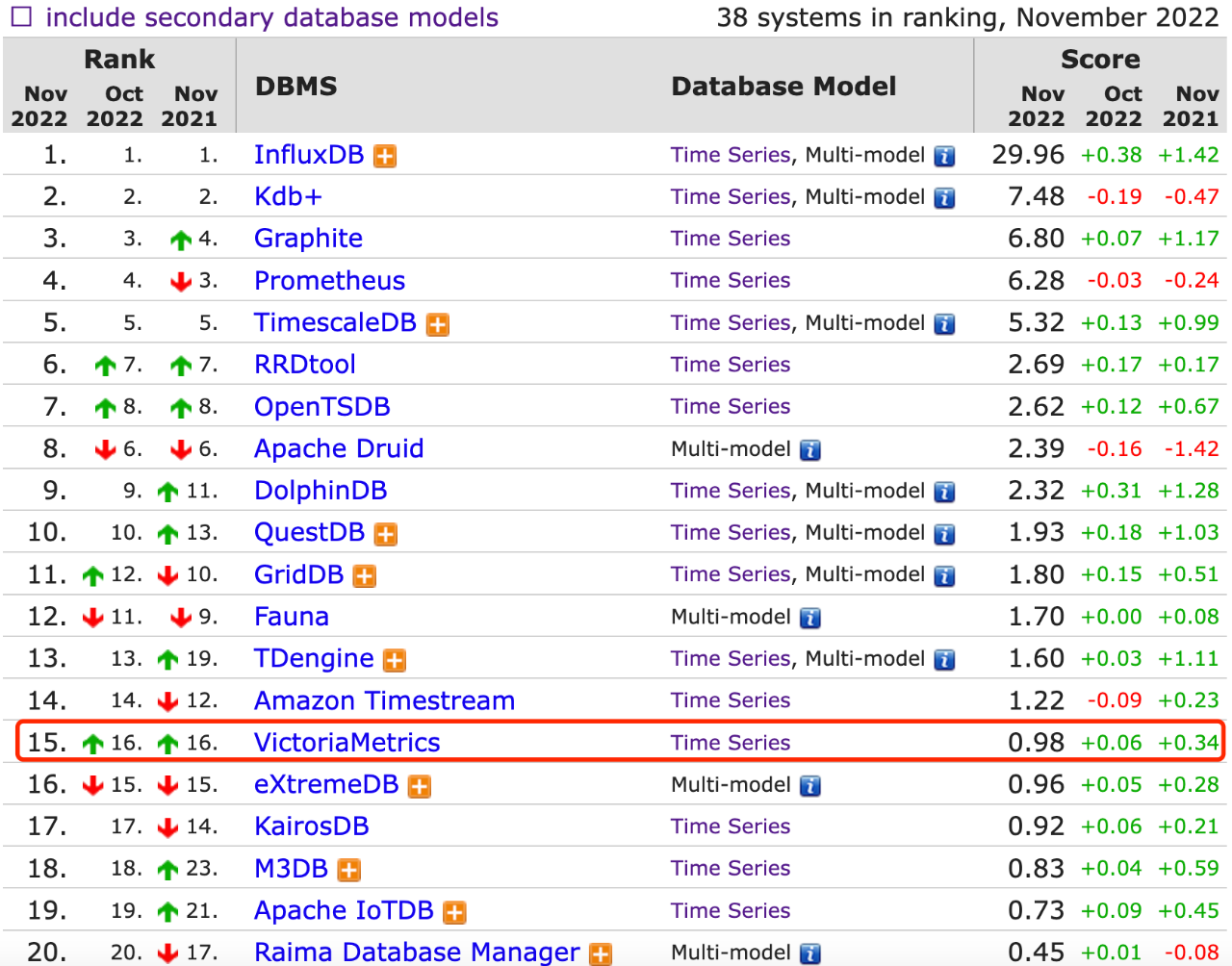
在 DB-Engines - TSDB 的排行中,VM 当前排名为 Top 15,并呈上升趋势,可见下图:
2、VictoriaMetrics特点
可以作为 Prometheus 的长期数据存储库:
兼容 PromQL 并提供改进增强的 MetricsQL ;
可以直接使用 Grafana 的 Prometheus DataSource 进行配置,因为兼容 Prometheus API ;
高性能 - 查询效率优于 Prometheus ;
低内存 - 相较 Prometheus 低 5 倍,相较 Promscale 低 28 倍;
高压缩 - 磁盘空间相较 Prometheus 低 7 倍,相较 Promscale 低 92 倍,详情可参见 Promscale VS VictoriaMetrics ;
集群版可水平扩展、可数据多副本、支持多租户。
3、VictoriaMetrics 架构
VM 有两类部署方式,都非常简单,如果对 Prometheus 有一定基础,整个替换过程会非常顺滑,这里就不对安装进行细述了。
VM - Single server - All in One 单点方式,提供 Docker image ,单点 VM 可以支撑 100 万 Data Points/s。
VM - Cluster - 集群版,拆分为了 vmselect、vminsert、vmstorage 3个服务,提供 Operate ,支持水平扩展;低于百万指标/s建议用单点方式,更易于安装使用和维护。
Qunar 单集群 Total Data points 17万亿,采用的是 VMCluster 方案。
另外对于指标采集和告警,需要单独以下组件:
可选,可按自身需求选择是否使用如下组件替代现有方案。
如果只是将 VM 作为 Prometheus 的远程存储来使用的话,这两个组件可忽略,仅部署 VM - Single 或 VM - Cluster ,并在 Prometheus 配置 remoteWrite 指向 VM 地址即可。
VMagent
VMalert
vmcluster 架构图
vm-single 特别简单不做赘述,这里说下 vm-cluster,vmcluster 由以下 3 个服务组成:
vmstorage 负责提供数据存储服务;
vminsert 是数据存储 vmstorage 的代理,使用一致性hash算法将数据写入分片;
vmselect 负责数据查询,根据输入的查询条件从vmstorage 中查询数据。vmselece、vminsert为无状态服务,vmstorage是有状态的,每个服务都可以独立扩展。
vmstorage 使用的是 shared nothing 架构,节点之间各自独立互无感知、不需要通信和共享数据,由此也提升了集群的可用性,降低运维、扩容难度。
如下为官网提供的 vmcluster 的架构图:

vmagent
vmagent 是一个轻量的指标收集器,可以收集不同来源处的指标,并将指标存储在vm或者其他支持 remote_write 协议的 Prometheus 兼容的存储系统。
建议通过VM Operate进行管理,它可以识别原Prometheus创建的 ServiceMonitor、PodMonitor 等资源对象,不需要做任何改动直接使用。
vmagent具备如下特点(摘要):
可以直接替代 prometheus 从各种 exporter 进行指标抓取;
相较 prometheus 更少的资源占用;
当抓目标数量较大时,可以分布到多个 vmagent 实例中并设置多份抓取提供采集高可用性;
支持不可靠远端存储,数据恢复方面相比 Prometheus 的 Wal ,VM 通过可配置 -remoteWrite.tmpDataPath 参数在远程存储不可用时将数据写入到磁盘,在远程存储恢复后,再将写入磁盘的指标发送到远程存储,在大规模指标采集场景下,该方式更友好;
支持基于 prometheus relabeling 的模式添加、移除、修改 labels,可以在数据发送到远端存储之前进行数据的过滤;
支持从 Kafka 读写数据。
vmalert
前面说到 vmagent 可用于替代 Prometheus 进行数据采集,那么 vmalert 即为用于替代 Prometheus 规则运算,之前我们都是在 prometheus 中配置报警规则评估后发送到 alertmanager,在 VM 中即可使用 vmalert 来处理报警。
vmalert 会针对 -datasource.url 地址执行配置的报警或记录规则,然后可以将报警发送给 -notifier.url 配置的 Alertmanager 地址,记录规则结果会通过远程写入的协议进行保存,所以需要配置 -remoteWrite.url 。
建议通过VM Operate进行管理,它可以识别原Prometheus创建的 PrometheusRule、Probe 资源对象,不需要做任何改动直接使用。
vmalert具备如下特点:
与 VictoriaMetrics TSDB 集成
VictoriaMetrics MetricsQL 支持和表达式验证
Prometheus 告警规则格式支持
自 Alertmanager v0.16.0 开始与 Alertmanager 集成
在重启时可以保持报警状态
支持记录和报警规则重放
轻量级,且没有额外的依赖
Qunar 的 VictoriaMetrics 架构
按照官网建议数据量低于 100w/s 采用 VM 单机版, 数据量高于 100w/s 采用 VM 集群版,根据 Qunar 的指标数据量级,以及对可扩展性的需求等,选择使用了 VM 集群版。

采集方面使用 vmagent 并按照服务维度划分采集目标分为多组,且每组双副本部署以保障高可用。各集群互不相关和影响,通过添加env、Cluster labels进行环境和集群标识。
数据存储使用 VMcluster,每个集群部署一套,并通过 label 和 tolerations 与 podAntiAffinity 控制 VMcluster 的节点独立、vmstorage 同节点互斥。同一集群的 vmagent 均将数据 remoteWrite 到同集群 VM 中,并将 VM 配置为多副本存储,保障存储高可用。
部署 Promxy 添加所有集群,查询入口均通过 Promxy 进行查询。
Watcher 中的 Prometheus 数据源配置为 Promxy 地址,将 Promxy 作为数据源
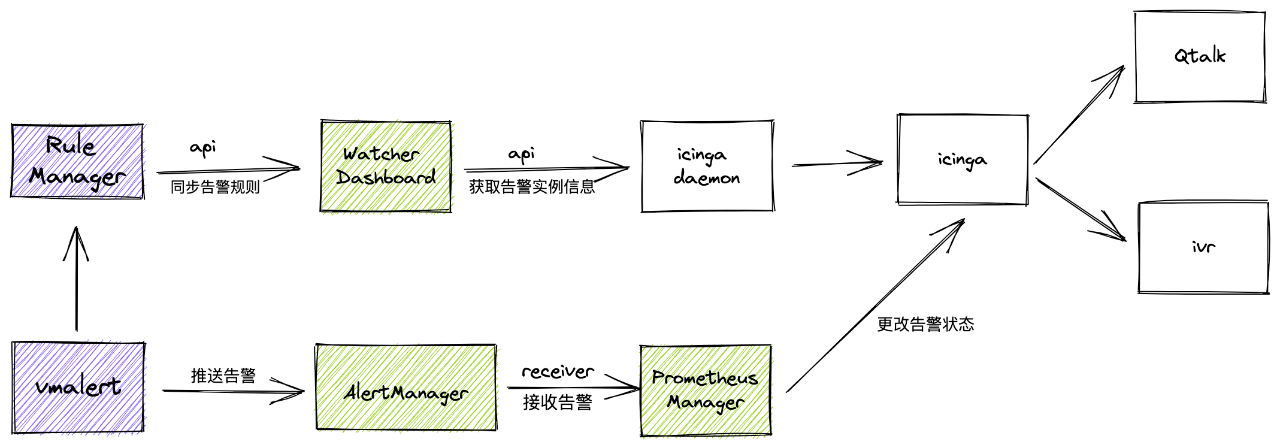
告警方面使用了 vmalert,并在 Qunar 告警中心架构上,Watcher 团队自研添加了 Rule Manager、Prometheus Manager 两个模块。
Rule Manager 表示的是 rule 同步模块,将规则同步至我们 Watcher Dashboard ,用于用户查看和自定义修改,便于一站式管理。同时也继续沿用原有告警实例信息同步 icinga daemon 逻辑。
Prometheus Manager 模块主要是实现了 reciever 接口,接收 alertmanager 的 hook ,然后更改 icinga 的报警状态。
最后对于 vmalert 本身状态,则是采用拨测监控实现。于此以最小改动代价融入至 Qunar 现有告警中心。
建议使用 vm-operate 进行部署和管理,它实现了如下几项 CRD:
VMCluster:定义 VM 集群
VMAgent:定义 vmagent 实例
VMServiceScrape:定义从 Service 支持的 Pod 中抓取指标配置
VMPodScrape:定义从 Pod 中抓取指标配置
VMRule:定义报警和记录规则
VMProbe:使用 blackbox exporter 为目标定义探测配置
同时默认也可以识别 prometheus-perate 实现的 Servicemonitor 、 PodMonitor 、PrometheusRule 、Probe 这些 CRD ,开箱即用平滑接替 Prometheus 。
完全替换后的表现
Qunar 容器化已将全环境集群的原 Prometheus 方案全部使用 VM 解决方案进行替换,所有的应用都是使用 VM-Operate 完成部署和管理的。
替换后其中某集群的数据表现如下:

后续准备做的几个优化
VM 开源版本不支持 downsampling ,仅企业版中有。对于时间范围较大的查询,时序结果会特别多处理较慢,后续计划尝试使用 vmalert 通过 recordRule 来进行稀释,达到 downsampling 的效果;
其实很多应用如 Etcd、Node-exporter 暴露出来的指标里有些是我们并不关注的,后续也计划进行指标治理,排除无用指标来降低监控资源开销。
总结
本文介绍了 Victoriametrics 的优势以及 Prometheus 不足之处,在 Qunar 替换掉的原因以及替换后的效果展示。也分享了 Qunar 对 VM 的使用方式和架构。
使用 VM 替代 Prometheus 是个很好的选择,其它有类似需求的场景或组织也可以尝试 VM 。如果要用最直接的话来形容 VM ,可以称其为 Prometheus 企业版,Prometheus Plus 。
最后,任何系统、架构都并非一劳永逸,都要随着场景、需求变化而变化;也并没有哪种系统、架构可以完全契合所有场景需求,都需要根据自身场景实际情况,本着实用至上的原则进行设计规划。

