导读:本文将分享领域知识增强的预训练语言模型在药电商搜索领域的实践。包括以下三大部分:1. 业务背景;2. 技术背景;3. 方法介绍。
01 业务背景
首先介绍一下业务背景。
电商场景下药品搜索,是一种垂直搜索(vertical search),使用搜索技术,连接用户用药需求和电商平台的药品供给。
相对一般电商搜索,药电商搜索具有以下特点:
用药场景的严谨性,客户搜索后应当推出准确的药物;
搜索结果的相关度高,病症和药品应该是匹配的,包含专业医学知识;
识别用户搜索的用药意图,要求达到高精准,当然普通用户搜索中,由于自身医学知识不够多,在搜索词 Query 中可能有不规范的表达,这种 Query 词和专业医学知识是存在偏差的;
药品的专业知识性强,比如药品说明书、药典,一些外部资源需要利用起来。
02 技术背景
接下来简单介绍一些技术背景,包括预训练语言模型和领域知识增强。
1. 预训练语言模型(Pretrained Language Model)
预训练语言模型是一种主流的 NLP 范式:主要是使用预训练+微调的方式,从大量的文本数据中通过自监督、自学习的方式来学习文本的表征(Embedding)。现在有一些特定领域的预训练模型可供使用,例如:医学领域、司法领域等。
那么在电商场景下能否直接使用一个开源的(比如中文 Bert)、别人训练好的模型呢?
经过对比,我们发现还是使用电商场景的一些自有知识数据来增强语言模型效果会更好,我们有 3 个具体的应用场景:
搜索词的实体识别(NER),主要识别 Query 中的品牌、药品主要成分、药品剂型等 28 类;
搜索词的意图分类,获取 Query 中搜索的意图,包括药品名、疾病、症状、问诊、医院等 22 类;
搜索词和药品标题的文本相关性,是否相关做二分类。
通过这 3 个场景,证明了领域知识增强预训练模型效果好于一般的开源的中文预训练模型。
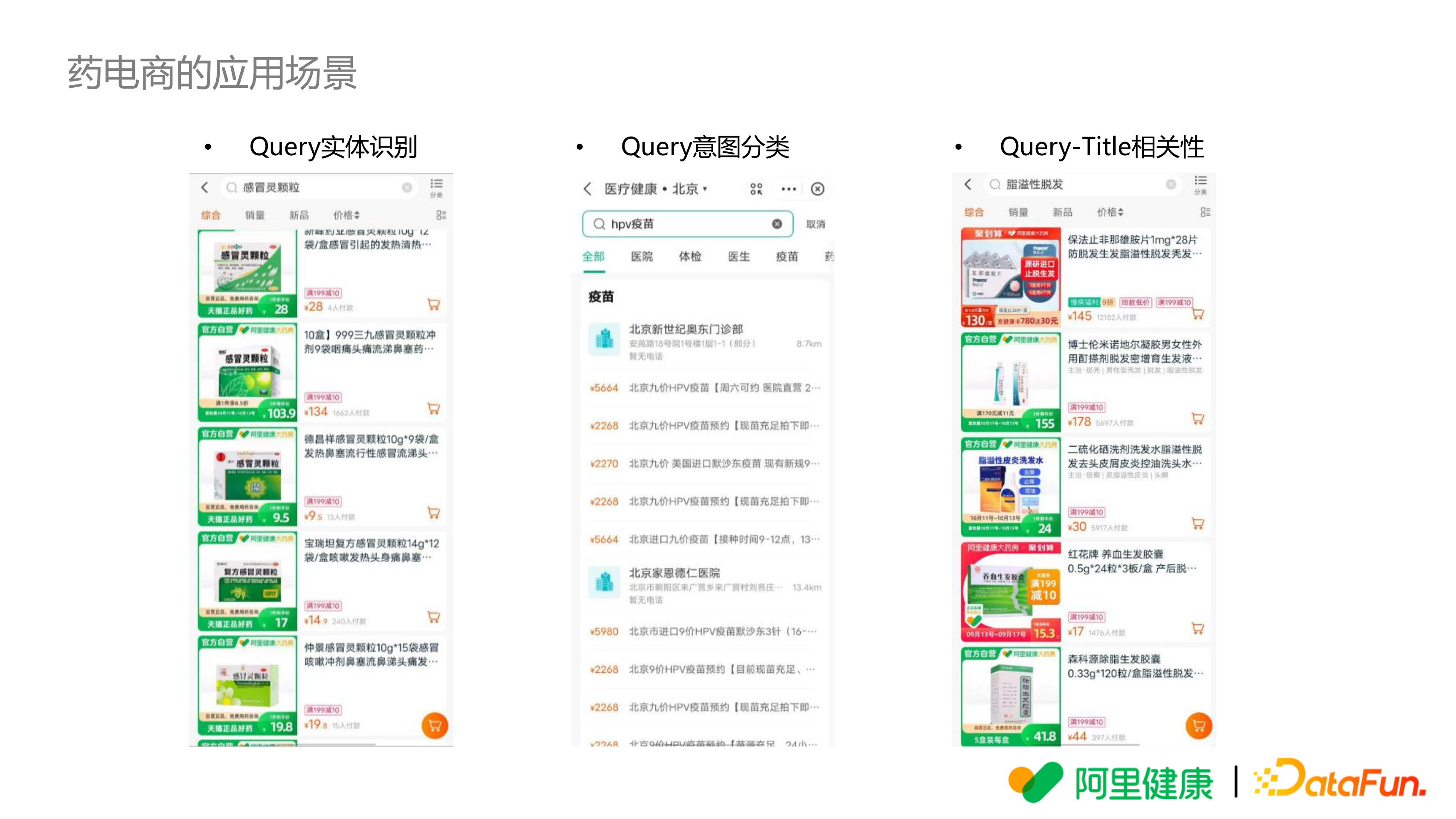
下图是 3 个场景的具体例子,左边是 Query 词实体识别(搜索的是感冒灵颗粒,感冒灵是药品名,颗粒是剂型,对此进行准确地实体识别);中间是 Query 词意图分类(HPV 疫苗,搜索的是疫苗,而且是 HPV 疫苗,这里有医院、体检、医生、疫苗等分类);右边是 Query-Title 的相关性(比如搜索“脂溢性脱发”,推出的药品应该是能够治疗脱发,并且和脂溢性脱发是匹配的)。
2. 领域知识增强
领域知识增强的常见做法包括:
在特定领域内对搜集的语料进行重头预训练、继续预训练,仍然复用 Bert 或者 Xlnet 语言模型重头做一遍;
把知识图谱(Knowledge Graph,KG)应用进来,方式也比较多,比如添加预训练实体向量 ERNIE(Informative Entities),QAGNN/GreaseLM;也可以在语言模型(LM)条件概率中引入图谱上的实体向量 KGLM;还可以修改训练数据(语料),比如将维基百科中的实体做随机的替换,这样就可以构造正负样本这就是 WKLM(replace mentions);也可以在 masking 阶段遮盖力度更大,这样语言模型训练过程中可以导入一些知识,这就是 Salient span masking, ERNIE(Knowledge Integration);还有联合训练的一些方法,比如KEPLER(KE+MLM)。
我们自己的方法是,采取重头预训练,语料包含一般领域语料(比如维基知识)和医学领域语料。另外有效利用药品的属性、结构化数据。
03 方法介绍
下面讲一下我们的方法。


预训练模型(PLM):一般领域模型,例如 BERT, oBERTa, XLNET, GPT, ELECTRA 等等。生物医学领域 PLM 模型,例如 BioBERT, PubMedBERT, BioMedBERT 等等。
我们的动机是将 PLM 应用在医药产品垂直搜索,以解决 Query 理解和Query-Title 相关性两个任务。
我们的目标:将领域产品知识注入 PLM 中。

领域知识(药品信息)的特点是:
通常存放在结构化关系型数据库中;
传统的 PLM 集中于处理自然语言句子中的文本。
用户在药品垂直搜索中的行为:除了会搜索药品名字也会搜索药品的相关属性,比如药品相关的疾病症状,这些数据在关系型数据库中是有存放的。
因此我们直接在结构化信息上训练语言模型。
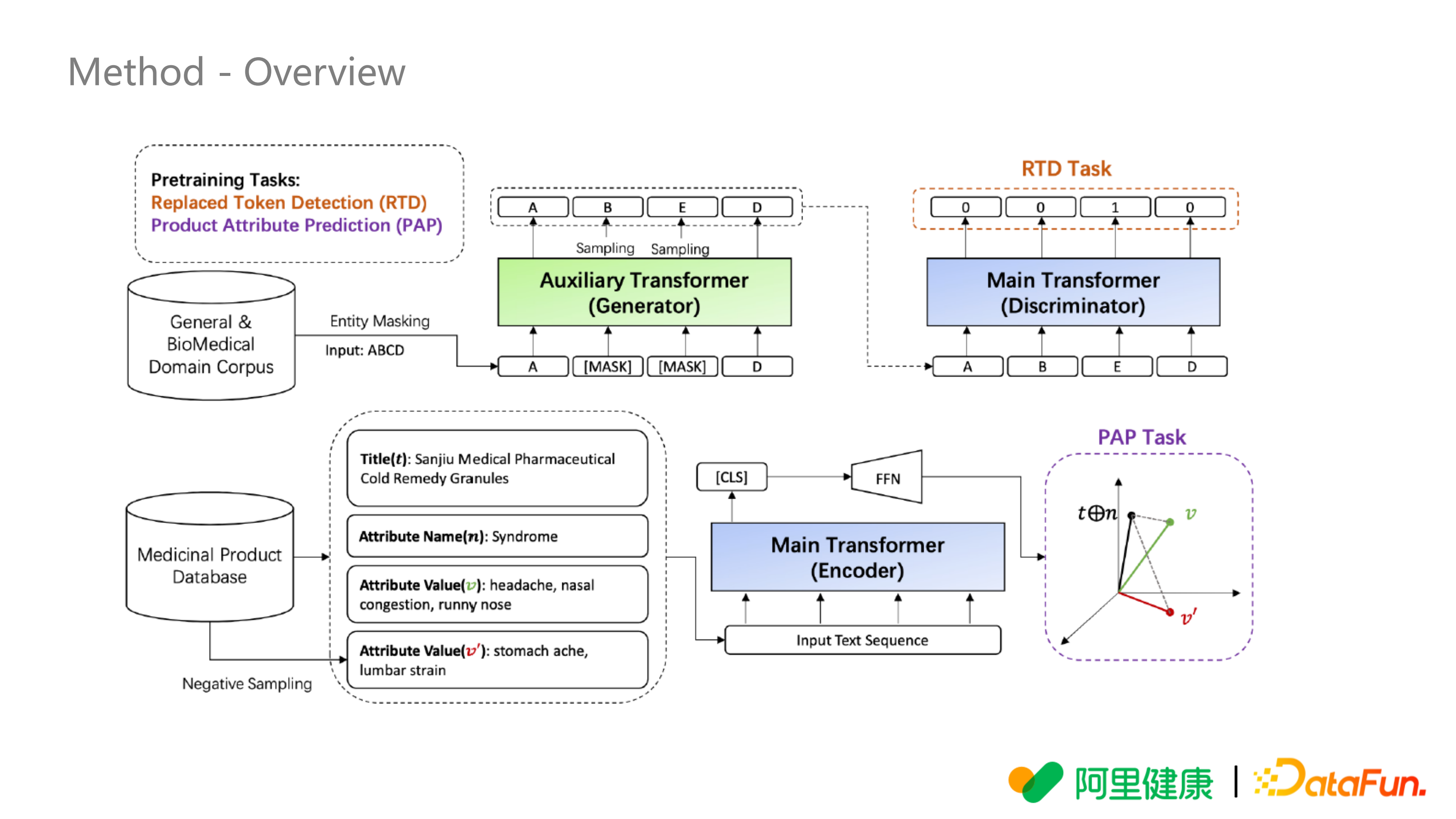
上图是模型的整体架构,使用的是联合训练的思想,主要有两部分任务:
一部分是 RTD,这里面做了一个改进就是 Entity Masking,后面的 Generator 和Discriminator 是复用的别人的网络结构。
第二部分是 PAP,这是我们主要的创新点,利用自有的电商平台药品知识库(Medicinal Product Database),主要使用了标题(Title,比如三九感冒灵颗粒)、属性、症状(头痛,流鼻涕),加入一些胃疼、腰疼等作为负样本,参考的也是对比学习的思路,这样构造一个 PAP 任务。
下面具体介绍这两部分。
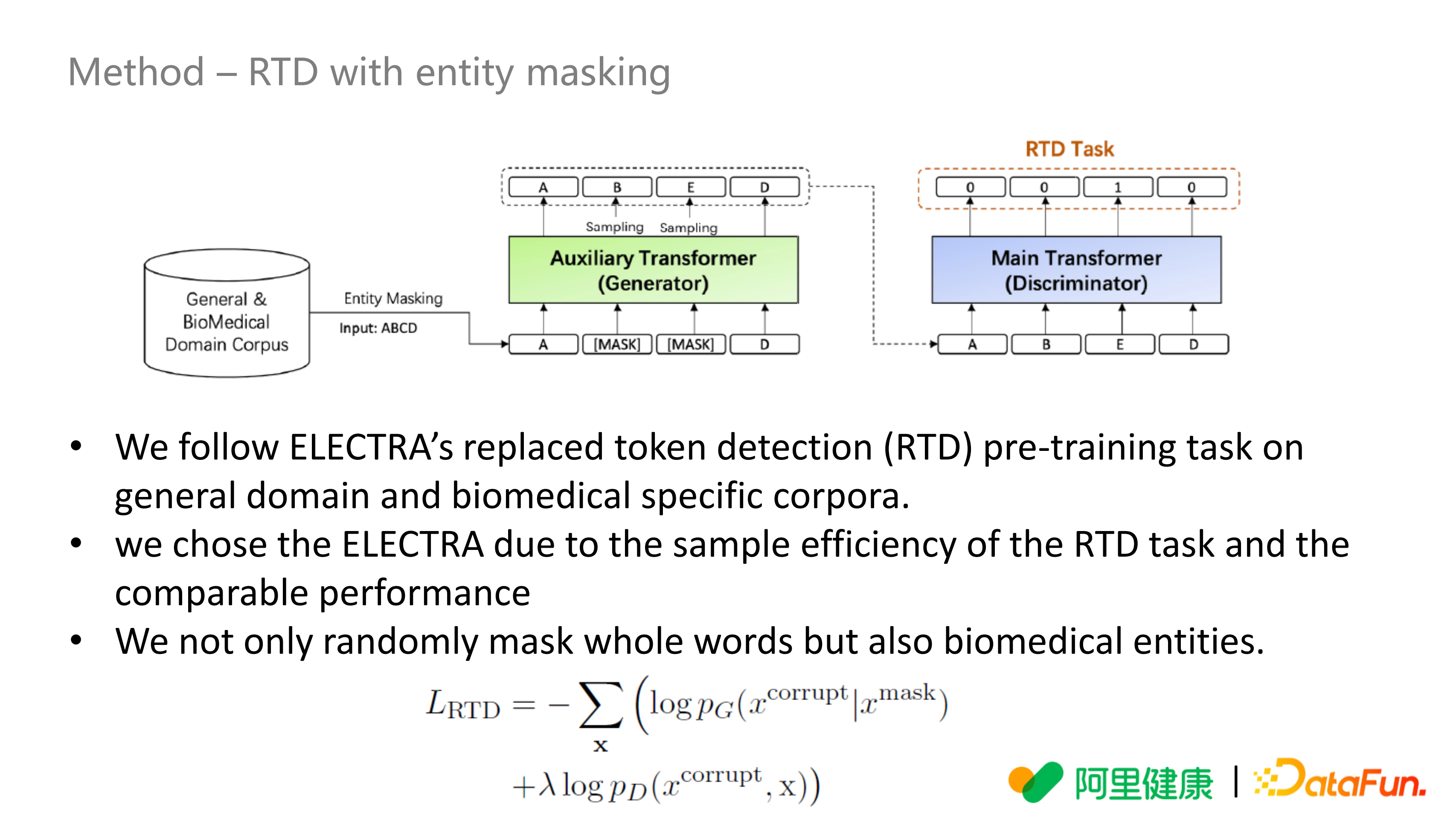
RTD 模型,沿用了 ELECTRA 的 RTD 训练任务,把通用语料、一些网站上的医学问答相关的语料用进来。选用 ELECTRA 的原因是考虑到训练任务样本利用的有效性,并且其 base 版本在英文上验证过,相当于 BERT-large 的效果。
我们在实体遮盖上进行了改进,不仅对中文分词的词级别遮盖,还有一些医学实体词,这样就可以有效的把我们在真实业务场景中积累的药品名、疾病名、症状名都应用进来,输入 input 为 ABCD,其中 BC 是一个药品名,把它给遮盖了,辅助网络 Generator 会生成一些遮盖掉的词 BE,然后用第二个网络 Discriminator预测它有没有改变,这里的 Main Transformer 参数在下面的 PAP 任务中是共享的。
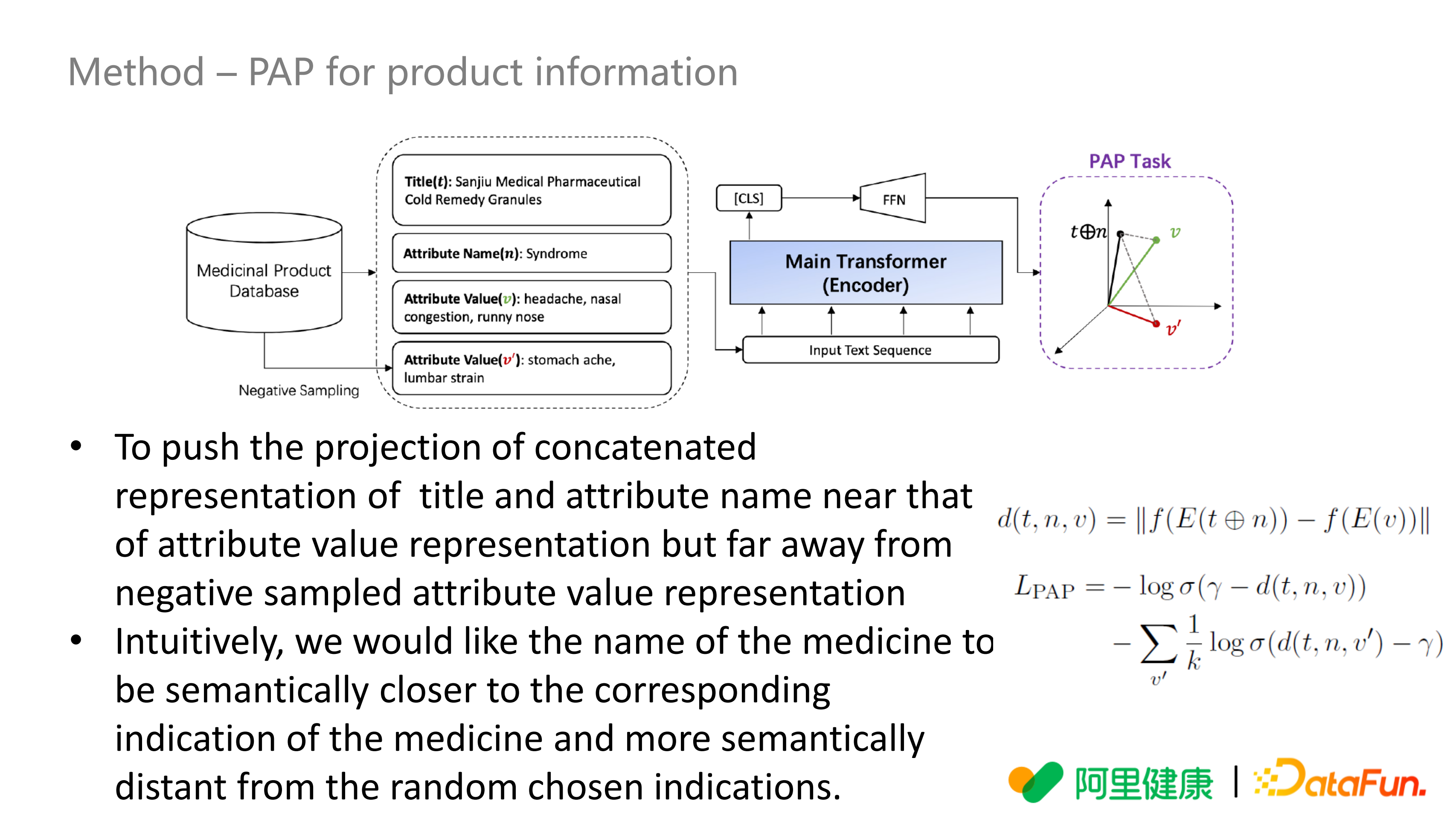
PAP 任务,在自有的属性数据上做训练,主要做了一个负样本的采样,就是对属性数据生成它的负样本,与正样本一起放在 Main Transformer,Encoder 对各种文本片段编码,主要有 3 个部分,分别是 t(Title),n(Attribute Name),v(Attribute Value),我们的想法是希望 t 和 n 做一次拼接,然后进行投影(全连接是一个投影),希望 t 和 n 拼接后与正样本 v 尽可能接近,与随机的负样本(红色v’)尽可能远离。

整体的 Loss 就是上述两个任务 Loss 的和:
整个训练在上面两个任务中进行交替学习,其中一个超参数是控制两个任务相互学习的比例。整体算法流程:
① 模型参数随机初始化;
② 标记实体边界以便后面好做实体遮盖;
③ 从药品数据库中收集药品标题、属性名、属性值的三元组;
④ 依据 Loss 进行训练。
下面介绍具体的实验结论。

前期实验准备:为了验证上述 Loss 的有效性,需要构造训练集,这里使用的是通用领域和医药领域的数据集,句子和 oken 规模如图左侧所示。右侧是药品实际搜索场景每次被召回的药品库,主要是商品标题、属性等。其中属性分类主要是疾病和症状。
在训练模型时对比了两个模型验证想法的有效性,一个是基于一般语料和医学语料训练一个非常强的 baseline:ELECTRA+EM,之所以这么做是为了对比 PAP Loss 的贡献。第二个是使用了医学产品的知识库做了一个多任务学习,其语料包括第一个方法的语料,及特有的语料(右边数据)。
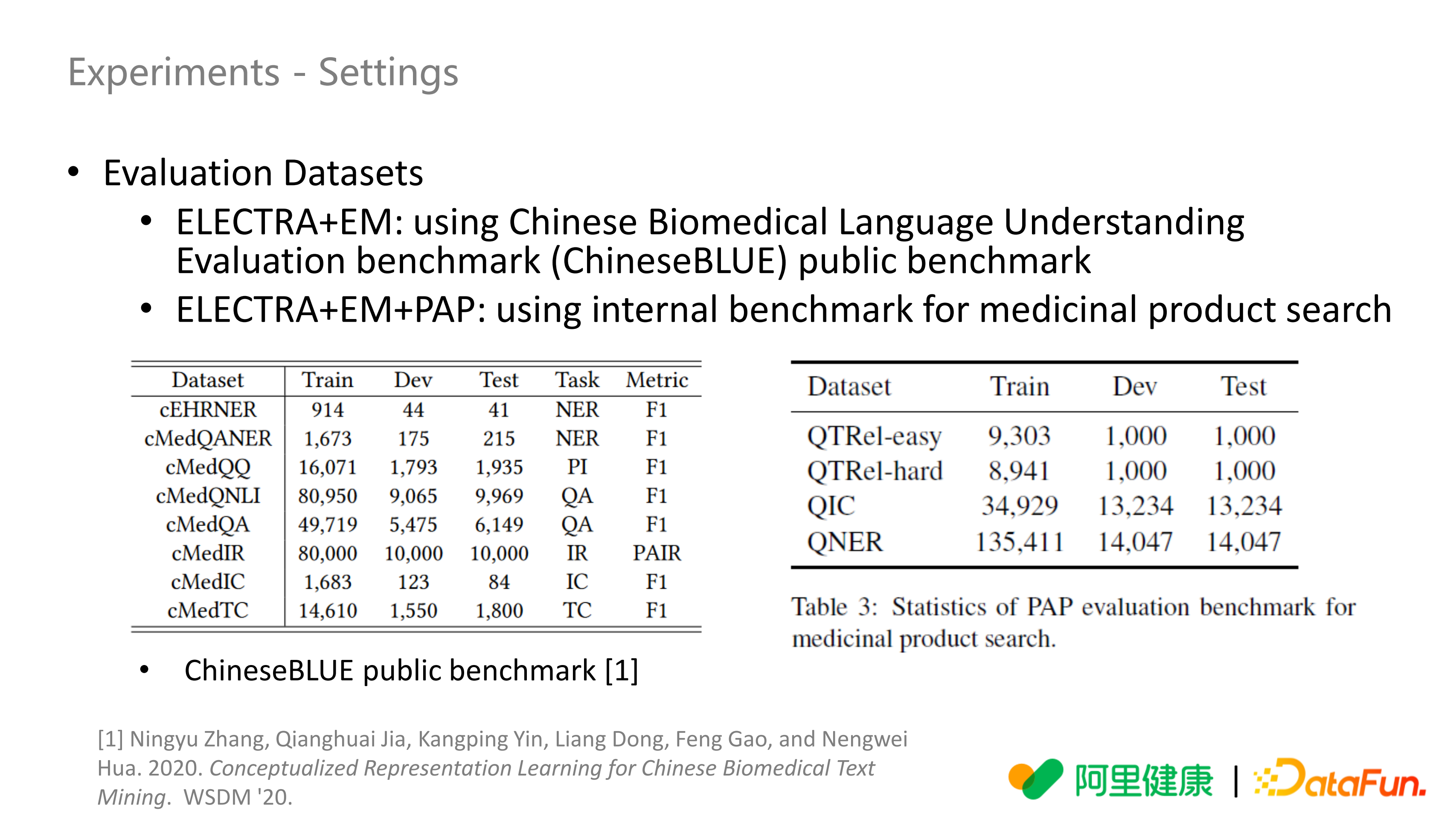
评估数据集:主要使用开源的 ChineseBLUE 数据集,是中文医学相关的数据,为了方便对比使用的是第一版,涉及到的任务有 NER、问答、句对、检索、文本分类、意图识别,数据集规模如上图左侧所示。也使用了自己的数据集(上图右侧),Query 和 Title 的相关性任务,分为 easy 和 hard,区别是 easy 对搜索日志数据没有限制,hard 是人为构造的比较难的 pair 对,把 Query 中的词(某个实体)在药品名标题里面出现过这种情况排除掉,这就要求 Query 和 Title 没有实体级别的重合。QIC 是意图分类,QNER 是 Query 中实体分类。

上图展示了实验效果,本文方法能够在大部分数据集取得最好的效果,有的是比较接近于更优。其中做了很多对比,第一个是 ChineseBLUE 论文的方法,后面 10K,20K 等是加入实体遮盖、短语遮盖的效果,后面三个是自己跑的效果,BERT-base是跑的哈工大的中文开源数据集,ELECTRA 只跑了 fine-tune 阶段。可以看到实体遮盖对我们的效果提升还是很明显的。我们的目的就是找到一个比较强的 baseline,直接与通用领域 BERT 对比可能不太合适,所以先验证一下实体遮盖的效果比较强,后面实验的方法对比主要是跟后面方法做对比。

超参数调整:加上 PAP 的 Loss 之后,调整 PAP task 训练比例 ρ,还有前面提到的三元组 margin 参数 γ。实验中也做了 Grid Search 设置一些参数,考虑到商品的属性、规模,跟维基百科等语料相比还是比较小,在自己的任务中稍微控制一下,ρ:[1%,5%,10%,15%],γ:[2,4,6,8],结果表明在我们自己的数据集上 γ=4,ρ=5% 效果比较好,ρ 比较敏感,对结果影响比较大。

在消融实验中,如果 PAP Loss 真有效果的话,尝试把它去掉,去掉以后指标都有所下降,hard 数据集下降的比较多,达 1.9%。因此有猜测,对于产品相关概念理解任务上使用属性预测任务会比较有效,加入的知识帮助更大。对于 NER 的任务,实体遮盖已经用到实体信息,再做属性预测,商品标题和商品语义之间的关系帮助可能就没那么大。

具体案例:给定 query “中耳炎”,让不同的模型去找,ELECTRA-base 和我们的模型,不同模型的打分。取了三个样本,前面两个是正样本,后面一个是负样本,我们希望正样本打分越高越好,比如 0.99,负样本小于 0.001。ELECTRA-base 模型打分 0.49 及 0.93 都是错的,而我们的模型打分都是正确的。“中耳炎”是个疾病,在产品标题(头孢,阿奇霉素)中是看不出来的,经过我们查找药品说明书,发现前面两种药是可以治的,而莫沙必利是不治这个病的。通过此案例,表明我们的模型能够理解药品和疾病之间治疗关系,这也和我们的 Loss 是呼应的。

结论:
我们在药品垂直搜索领域提出了知识增强的预训练模型;
相对中文 ELECTRA 我们加入了实体级别的 masking;
我们提出一个新的产品属性预测任务,并且把它融合到了语言模型当中;
实验证实取得了不错的效果,并且在药品垂搜场景验证了 PAP 预训练任务的有效性。

