导读:本文介绍众安百亿级数据集成服务的架构实践,主要包括三个方面:数据集成及常见的技术;众安数据集成服务业务支持的情况;众安数据集成服务技术演进的路线。
01 数据集成及常见的技术
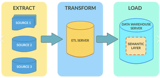
数据集成是数据中台建设的首要环节,以便企业各个业务系统之间的数据互联互通,打破数据孤岛,实现数据在公司级别的共享。数据中台常见的数据 ETL 任务,即从一个数据源通过数据集成将数据写入数据仓库或者数据湖,然后通过数据仓库或者数据湖将数据推到 Notebook 库或业务库的应用库里,从而实现数据服务以及数据应用。
数据集成产品致力于提供复杂网络环境下,异构数据源之间不同数据格式高速稳定的数据的移动能力。数据集成一般会有以下几个使用场景:
1. 数据迁移
① 业务数据上云,例如公司本地搭建的 CDH 或者 Hadoop,上亚马逊云、阿里云或腾讯云这种大规模的数据迁移,难免会遇到数据迁移这种数据集成服务。
② 业务数据库初始化导入数仓,我们在全新的业务线或公司初始化构建数仓的时候,也会有大量的业务数据库进行数据初始化导入数仓的数据迁移过程。
2. 数仓/数据湖
即最常见的数仓/数据湖实时数据 ETL 和离线数据 ETL 场景。
3. 平台融合
平台融合是指跨网络跨平台多数据源的融合和推送需求。例如我们金融风控的一些场景,不仅要把数据落到本地的数据库里,还可能会同时实时或离线将数据落到图数据库里,或者一些查询索引中,这种一份数据多份推送的场景,也是数据集成比较常见的场景。
4. 容灾备份
容灾备份包括历史冷数据备份和数据库灾备。例如众安 ES 集群中有一些很关键的数据,就是通过数据集成服务推送到一个 HDFS 集群进行冷备。
如果构建一个数据集成服务,或者进行技术选型,我们要考虑以下关键点:
数据同步机制,即 CDC 是基于查询还是基于日志,两者在成本或者方式上各有优劣。
数据同步模式,需要兼顾全量和增量两种模式。
数据同步并发和分布式能力。
数据同步链路,数据集成的组件依赖的链路越少,监控和运维分析问题的成本就越低,所以要采用尽量少的链路来实现我们最终数据集成的效果。
数据同步转换能力,其分为很多种,比如各种不同列格式的列隐式转换,比如 String可以写到目标源的 Date 字段或者 Double 字段里这种隐式的列格式转换以及中间的 Transformer 的能力,比如说数据同步过程中可以做掩码、脱敏或者一些空字段的补齐,这也是一个比较关键的附加功能。
数据源扩展能力,我们选型的技术或自己开发的组件需要具备数据源可插拔的能力,方便我们未来对于各种不同数据源的扩展。
数据同步是否依赖文件,像一些金融机构中一些数据的推送系统,依赖于一种叫做 CD 的系统,可能会比较依赖于文件多节点之间的转发,如果依赖于文件,可能会有更高的磁盘 IO 消耗,导致整个性能效率会比较低。当然如果对时效性要求不高,CD 系统也能满足要求。
数据同步低代码开发,最好可以通过统一的配置文件动态生成数据集成能力,而不是通过硬编码的形式进行管控,这样也不方便整体平台的运维和监控。
底层开源技术的社区活跃程度和影响力,如果特别小众,到后面可能写着写着就做不下去了。
下面我们介绍一些常见的数据集成工具。

数据集成工具已经不是一个很新鲜的东西,上世纪 90 年代就有 Informatica、IBM 的 DataStage、Oracle 的 ODI,到基于数据库的 BI 时代,这些数据集成工具均已提供成熟的市场化解决方案和大量的案例。
对于中小型公司,数据集成绝大多数还是基于开源技术的直接使用,或者在此基础上的二次封装。
我们更需要关注的是公司的业务场景、技术架构以及运维能力等多方面进行考虑,然后选择我们最合适的方案。
比如公司有一个 Hadoop 集群,资源也足够,我们进行数据集成的这个场景又是围绕着 Hive、HBase 以及关系型数据库,这个时候我们用 Sqoop 也可以实现比较好的分布式能力和简单的命令处理,一个脚本就可以搞定了。
如果公司没有 Hadoop 集群或者 K8s 部署,集群要留更宝贵给ETL处理,可能我们会选择轻量级的 DataX,我们可能需要有 ECS,如果集群节点的 CPU 足够,做好一定的资源隔离,这是最快速节约成本的一个方案,而且这个方案对阿里云生态会有比较好的支持,其 GitHub 上大概有 4000+ Star。
如果我们是一个新创立的公司,而且业务足够大,也有足够的运维和资源做这Hadoop 或者 K8s 部署,那我们也可以去考虑 Chunjun(FlinkX)或者 SeaTunnel 这种具有大量分布式能力的开源组件进行处理。所以要看各个公司具体的使用场景,没有最好的方案,只有更适合的方案。
02 众安数据集成服务业务支持的情况
1. 离线数据集成

离线数据集成主要面对的是传统数仓的离线ETL,调度频率现在是分钟到日级别,这依赖于我们现有调度系统的能力。技术组件用 DataX 3.0,作业的发布是依赖于我们内部研发的数据开发工作台DataIDE进行发布,作业的执行是调度系统调用我们的数据集成服务进行运行。
作业的规模 2017 年每天的作业数量大概是 2000 个左右 DataX,2022 年截止到今天。可能是 1.5w+ 个数据集成的任务。数据源有很多,例如 ODPS、RDS、CK、HDFS 等等,我们内部大概现在支持四十几种的数据源的异构传输。
数据的规模 2017 年我们每天同步的数据行数可能在两亿左右,到2022年每天的数据量同步,包括RTA可能会有 300 亿+的离线同步。
2. 实时数据集成

实时数据集成方面,我们目前主要的业务场景是实时回流业务数据库的数据到MaxComputer,用于小时/分钟级别的离线数仓任务,以减轻频度比较高的作业链路,提高其时效性,从而使金融数仓的一些时效性效果好一点。
我们目前用到的技术组件主要是 Blcs(众安统一的 Binlog 采集服务)+ FlinkSQL,目前作业发布平台是我们的流计算平台,作业执行是 Flink on Yarn 模式。
众安 2020 年开始做的时候有 200+ 的任务,2022 年目前有 1000+,目前我们有一个 60 节点的CDH集群专门跑 Flink on Yarn 任务,我们会
陆续把这一部分服务迁移到k8s上,以节约缩减 CDH 集群的规模。
3. 遇到的挑战

① 作业配置
作业的配置开发学习效率有挑战,对于 DataX 的作业配置、FlinkSQL、基于 Flink 的开发,其配置的学习成本比较高,因为有些高阶参数,如果没有调优好,会拖累整个数据集成作业的性能,导致时耗特别长。
开发作业配置效率低,没有自动化。
② 作业配置替换
替换主要是指作业配置替换的挑战,可能会有如下几个场景,数据源信息的变动可能会导致数据集成配置 DataX 的 JSON 大量的订正,以及数据源跨环境发布也会有数据源的订证,因为我们一直立志做到从测试到生产环境的一键发布功能。
③ 资源
资源问题主要是作业稳定性的挑战:
作业执行节点的负载会特别高,如果跑了特别多的 DataX 任务。
跑特别多的 DataX 任务消耗内存之后的资源隔离问题。
单点 DataX 作业性能的优化,包括开源插件的二次开发以及性能扩展。
03 众安数据集成服务技术演进的路线
1. 数据集成架构演进

主要是分为三个阶段:
第一个阶段是单机模式的阶段,包括 2014 年到 2017 年之间,我们的DataX是单机多进程的直接使用模式。我们从 DataX 2.0 开始使用,一直到 2017 年替换的 DataX 3.0 我们都经历过。最开始的作业开发是在本地写 DataX 的 JSON,可能对数据源的密码有掩码,然后进行上传。因为那时的数据源并不是很丰富,所以绝大多数都采用了这样的方式。
第二个阶段基本实现了数据集成的服务化、作业配置的服务化以及数据源管理的服务化。这三个方面主要是通过我们的 DataIDE 以及获管平台,还有数据集成服务三个系统来实现。
第三个阶段我们现在到达了实时数据集成有很多需求的阶段,我们今年致力于做流批一体的这个数据集成组件,以及实时数据集成服务,包括底层流计算服务的一些共建,可能是我们今年着重要做的一些事情。
2. 离线数据集成技术选型
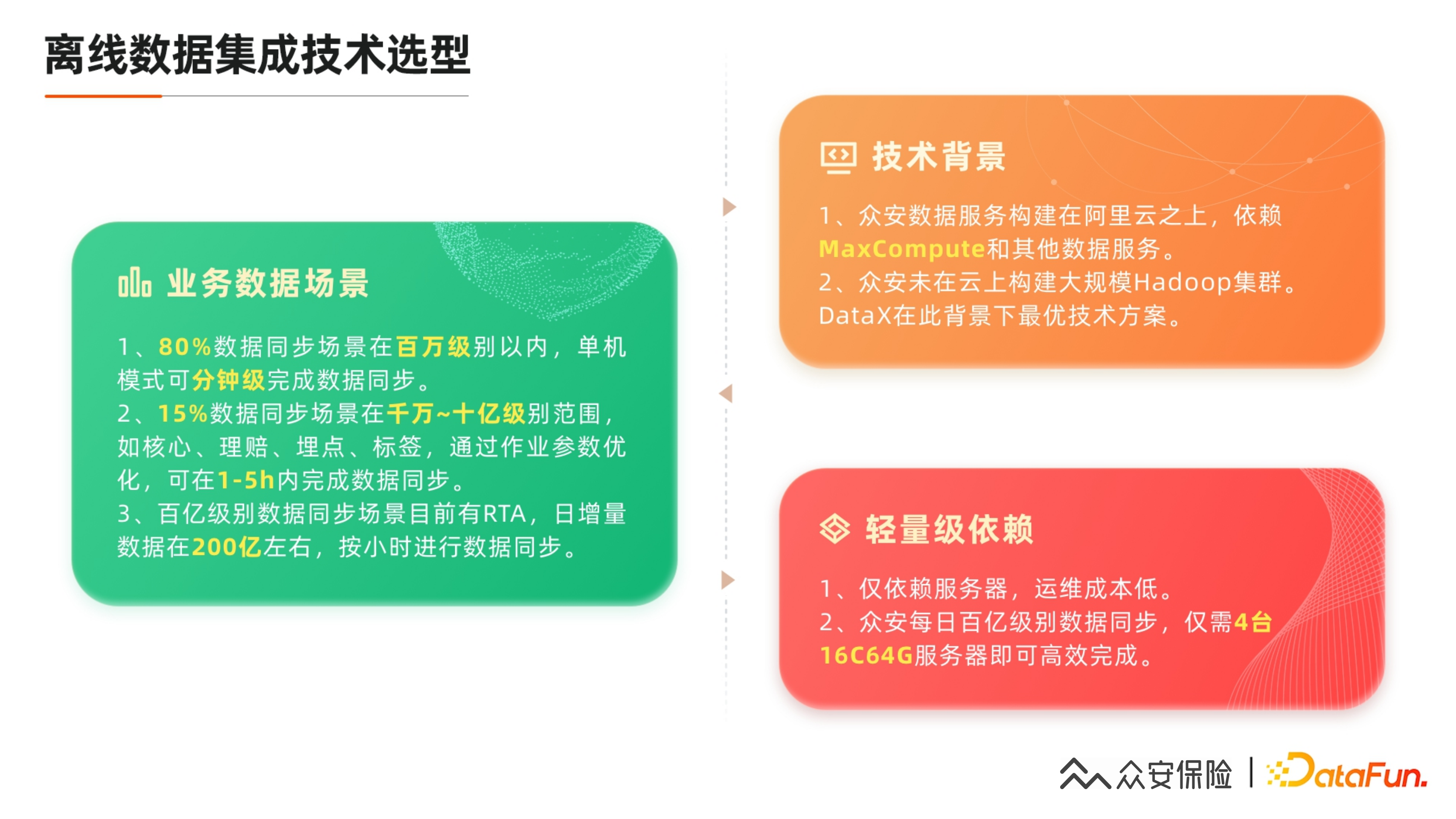
离线数据集成的选型为什么要选 DataX?
① 最重要的是业务场景决定技术选型
80% 的数据同步场景的数据量在百万级以下,DataX 单机模式基本上可以在分钟级实现这种数据同步作业完成。
15% 的作业在千万到十亿级别这个范围,这种业务包括保险核心、理陪、埋点、标签,甚至还有很多推 CK 这种做报表展示的作业。这个级别的作业通过作业参数的调优,基本上可以实现 1~5 小时之内完成数据同步。如果像一些 CK 这种特别大的同步作业中间出错,例如 CK 节点的主从问题导致出错后,我们可能会重跑会,会有一定的数据延迟。那么目前这一部分的 1~5 小时的作业绝大多数还是可以接受的。重点的任务会有高优先级的调度来保证尽早的时间来完成。
百亿级别的数据同步场景目前只有 RTA,日数据增量在 200 亿左右,我们目前 T+1 日的这个调度向前推为 T0 的这种小时级别的任务,然后进行回流。有些同学也许会问为什么不把数据完全写入到Kafka,或者写到一个 Notebook 库里,然后再进行回流,因为RTA场景要求比较高的时效性,每次请求的要求时间是 50 毫秒以内,这样在进行数据同步的时候,更多是基于应用本地的日志回流到指定的文件服务器,然后进行解压再进行同步。像众安的 RTA 机器可能会有上百台,如果后面做实时化,这个文件的实时数据采集也要有一定的工具配合才可以完成。
② 技术背景
我们的数据服务构建在阿里云之上,依赖于 Max Compute 和其他的数据服务。我们未在云上构建大规模的 Hadoop 集群,集群只有六十几台机器专门用于实时计算。从更早的 2014 年至今,DataX 基于阿里云的生态和我们的业务数据量来看,目前是一个比较合适的方案。
③ 轻量级依赖
仅依赖服务器,运维成本非常低,只要有一个分布式发布插件,就可以管好这几台机器,众安目前百亿及三百亿左右的数据同步,仅有 4 台 16C 64G 的服务器就可以高效完成。不过现在压榨的比较厉害,整个 CPU 下午 3 点之前都会有 100% 的状态。
3. 单机模式
① 单机模式 – 系统设计
这种模式的优点是轻量级依赖快速部署、成本最优,这种部署方案比较依赖于调度系统的能力,包括整个资源的管控以及横向的水平扩展。这种模式不适用于极大数据量高时效的场景。
我们常见的做法是有一个调度系统,自研的或者 DolphinScheduler、XXL-Job、Azkaban、Airflow 等。初期如果是单节点的调度,则采用 DataX 和调度进行混部,如果作业到达一定瓶颈之后,单节点跑不动了,就引入分布式调度,可以理解为调度执行节点和 DataX 进行混部,在每一个执行节点上拉起一定数量的 DataX JVM 进程。同时我们作业的管理基本上是杀进程来实现作业的管理和存活的校验。这种模式适用于绝大多数的业务场景,但这个模式也有一些要注意的地方。
② 单机模式 – 作业稳定性挑战
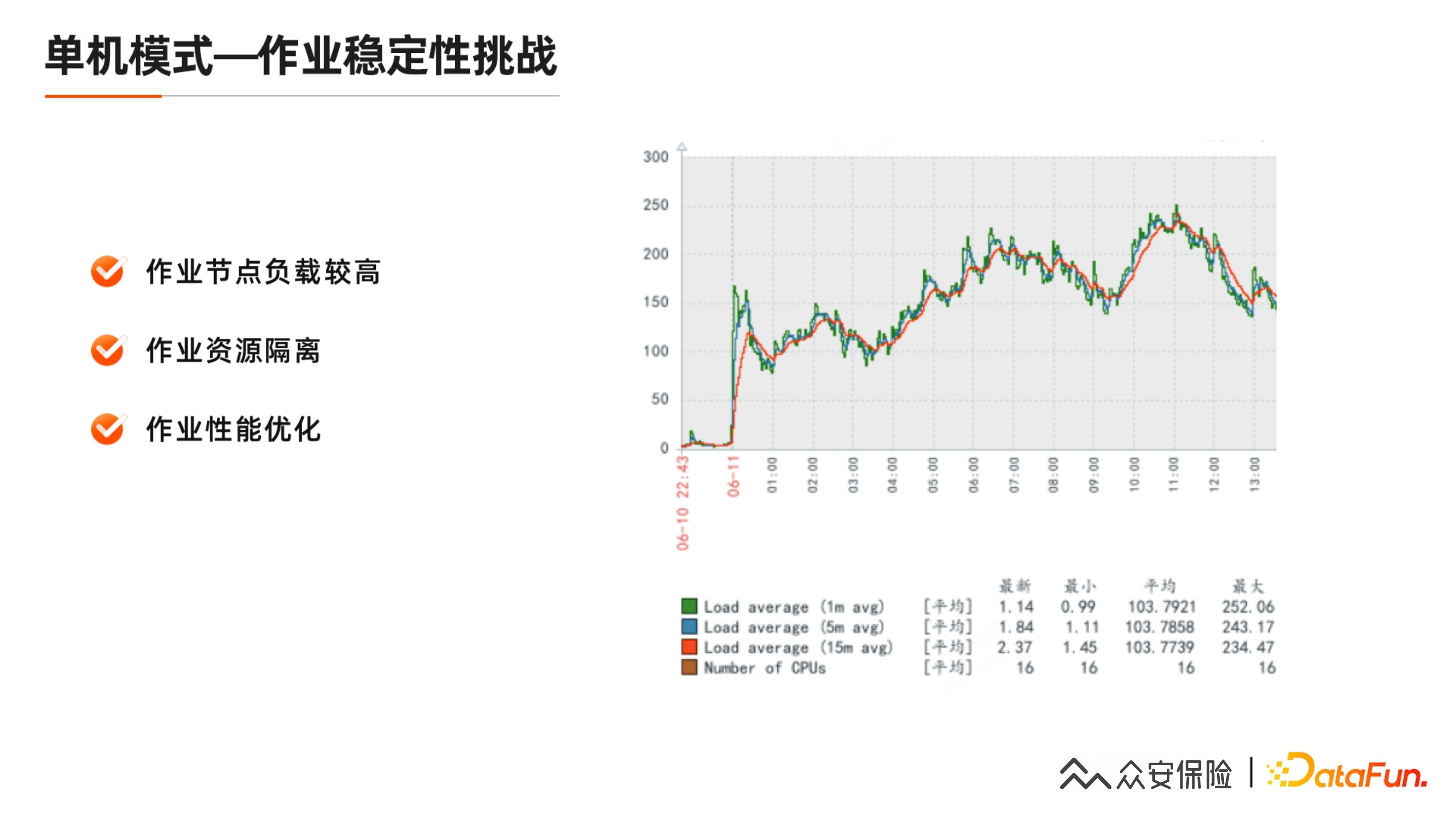
这是我们 6 月 12 号左右,某一台 DataX 节点 Zabbix 的情况,可以看到 15 分钟平均负载基本在 100 以上,0 点到 11 点左右的峰值可能会到 250,机器的压力相对来说比较大。
假如我们是一个分布式调度系统,最大的问题就是查分布式节点的日志,以及这个分布式作业分配的 RPC 请求可能会有一定的超时。
同时还会有资源隔离的问题,因为目前绝大多数的开源调度系统,只会对任务的数量进行控制,比如追求差异化的 DataX 作业 JVM 的分配,以及 DataX 总数控制的情况下,不同作业的控制会比较低,一旦我们不小心把节点分配了过多的任务,操作系统可能认为内存吃完了,会批量杀掉一波最耗内存的任务,可能会误杀一大片的 DataX 任务,导致晚上的作业稳定性极差。
最后就是刚提到的单个作业的性能问题,一些参数没有设计好,或者没有配置好,可能会导致整个作业断崖式的性能下降。
③ 单机模式 – 资源隔离设计
针对单机模式,资源隔离应该如何设计?
我们做设计的时候,应该强化调度系统的能力,包括调度节点的能力,执行能力,还有资源管控能力。
资源管控能力,不仅去看这个作业并发度的控制,包括调度的总的并发度以及执行节点的并发度,还需要对不同种类的调度任务抽象出一定的资源消耗,以及在每一台执行器的节点上能分配多少种作业,以及这个作业上可以跑多少个资源,经过一定的抽象之后,就可以实现上述的效果。
我们的调度节点在分配作业的时候,肯定去看下面的执行器集群中资源最多的一个节点,然后进行分配。作业执行完后,回调时对这个作业的资源进行回收。
执行器的节点上,要计算各种各样作业的资源上限,预留和给予一定的缓存,避免超卖过多导致异常。
④ 单机模式 – 作业性能优化

减少同步数据量
第一种是回流时全量改增量。
第二种是列裁减,例如 ES 索引上有 500 列,如果不指定回流的时候,只回流 100 列。如果不进行列裁剪,每次网络带宽请求的时候,会把这 500 列都回流回来,就会导致整个速度的下降。
还有就是作业数据的拆分,例如分库分表作业拆分的时候,可以将若干个分库和分表拆成多个任务,写入同一个 ODPS 或 Hive 表当天分区下的二级分区,变相把 DataX 变成分布式的,然后实现我们预计的回流效果,对于当天回流超大的一个作业,比如刚才提到的 RTA 埋点或者 RTA 日志及埋点,我们可以把它 T 到 T0 用小时级别提前汇流,实现减数据量的效果。
框架参数优化
首先是并发度的控制,没有超大的作业,不要把 DataX 的 Channel数量开的特别大。
第二是要充分利用框架的并发读特性,单库单表超大表的关系型数据库的 Split PK,按主键的 Range 去切分,ES 的 Scroll Slice 特性或 MongoDB 的 SplitVector 特性,把数据源切成多份,并发去读,以提高整体的吞吐量。
充分利用批量写,尽量减少和目标数据源的交互次数,例如一个事物提交 1024 条记录肯定比一条一条提交记录的交互次数少,变相减少连接的次数和所谓写插件的消耗。
第三是 JVM 的调优,如果是大数据量多通道的作业,尽量分配更多的JVM,如果是少量数据的作业,尽量分配一个标准配置的 JVM,以实现差异化的管理。
最后就是 Core JSON 的一些配置,例如 Task 的数量以及 Channel上线的数量。
数据源优化
使用关系型数据库的从库避免主库 IOPS 打满导致数据集成的性能下降,以及充分利用数据源的一些特性,例如 OceanBase 的 Read By Partition 的一些特性,还有ES写超大索引的时候,比如一些索引基于 Translog 或者 Source 禁用的性能优化,这主要是单个作业的优化。
4. 服务化模式
① 服务化模式 – 作业开发效率的挑战
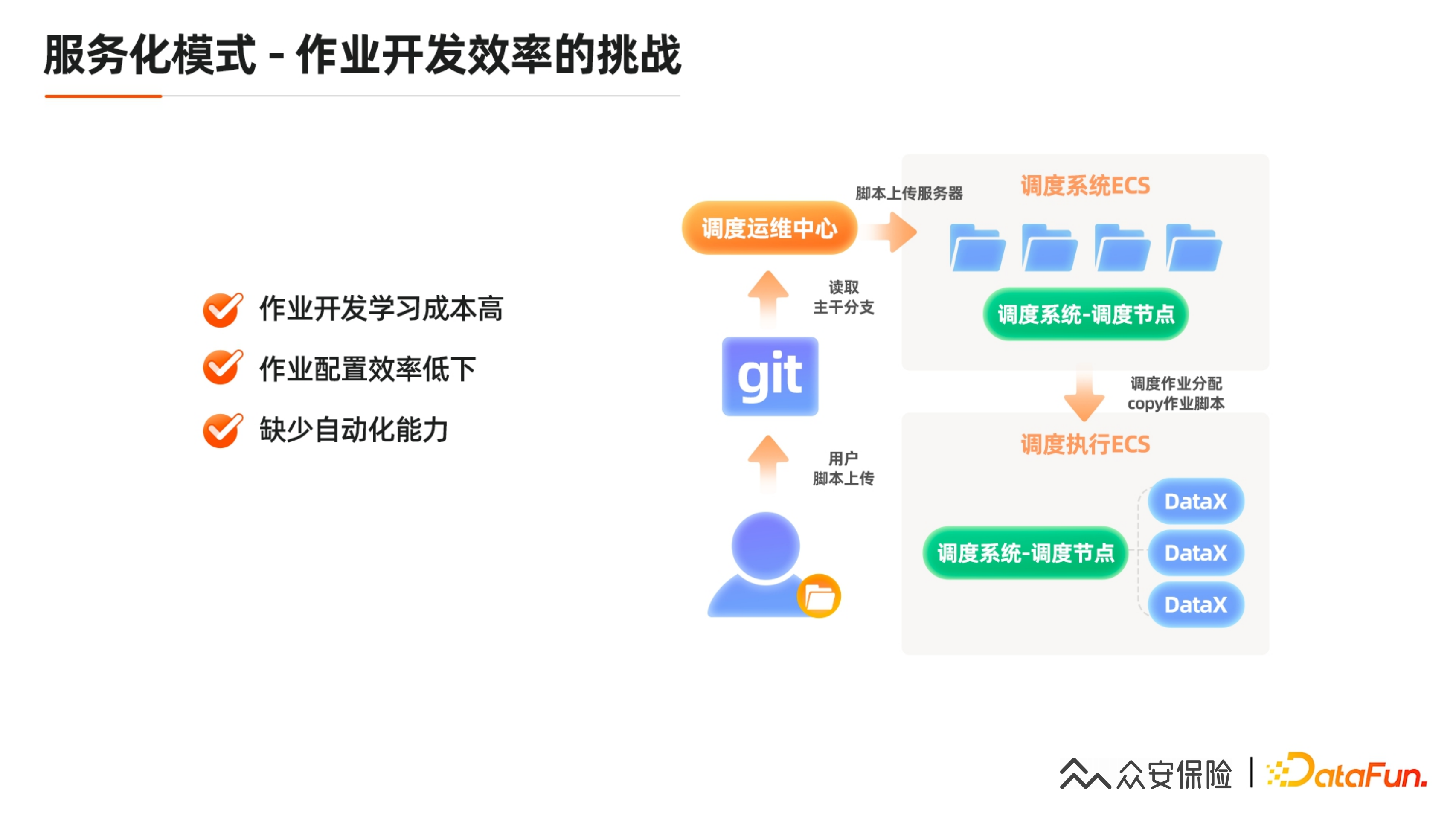
之前我们的做法是用户在本地开发脚本,之后上传到 Git,调度中心拉主干分支推到服务器上,在执行前把这个脚本再拷到执行节点,替换变量之后再拉起来。
痛点在于如何去动态拉这些元数据,例如表字段增加之后,人工去写这些列效率会非常低下,同时还有一些 DataX 不知道的参数,无法配置,发布前也没办法做校验,可能出错重发,这样的效率会非常低下。
我们采用自研的数据工作台来应对这个挑战。
② 服务化模式 – 工作台作业开发
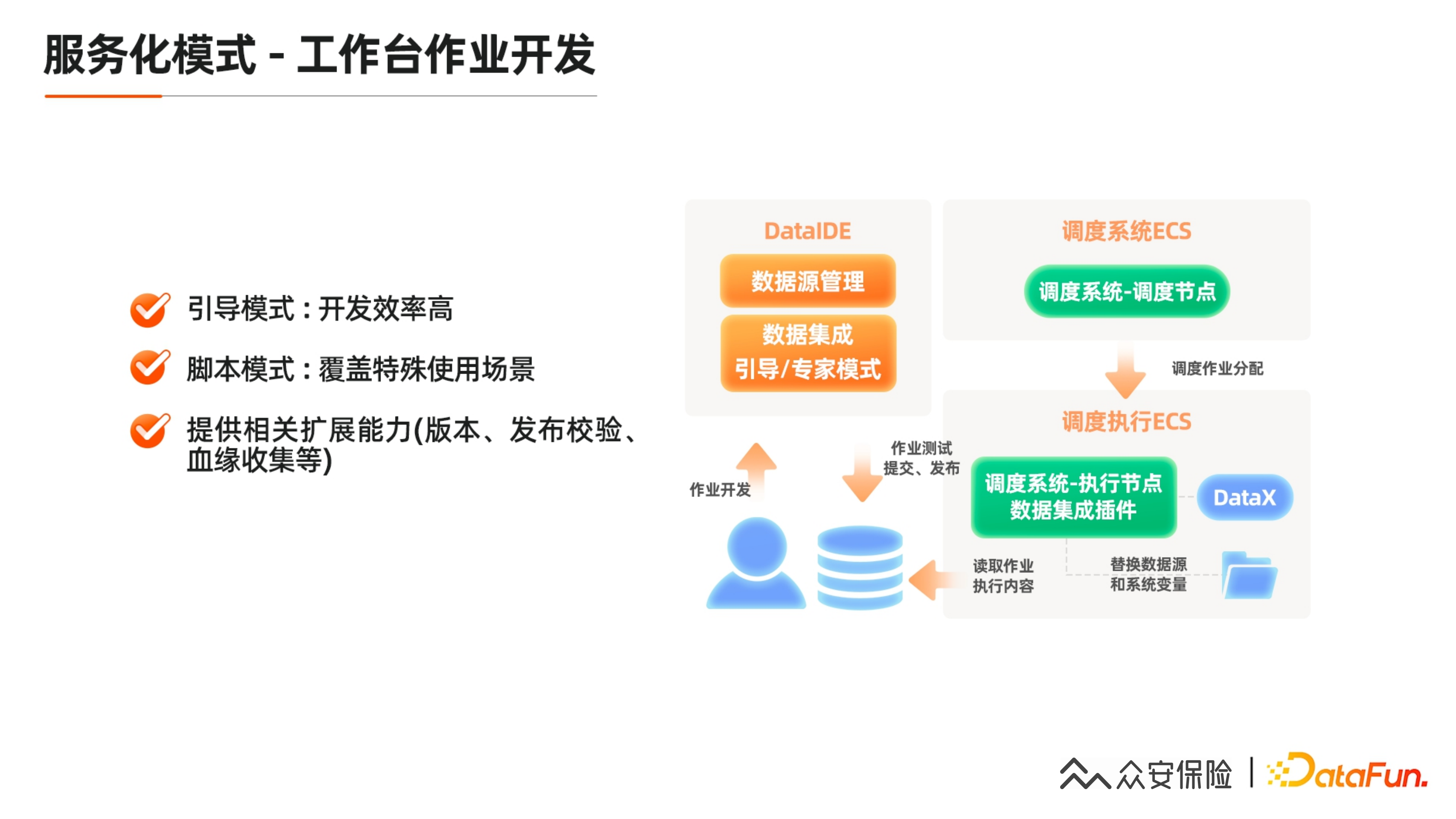
我们现在在数据工作台进行数据集成和数据源管理。数据集成主要有引导和专家两个模式,引导模式的开发效率较高,我们所有的源数据库下的库表可以直接自动化的进行获取和配置,包括同名映射和同行映射的功能可以一键做好。
同时我们发布时的校验以及发布版本之后的血源收集,都是基于这个平台来实现,所有的脚本都是存在数据库里,执行节点只要读取当前作业最新发布版本的内容,在本地生成执行文件并替换变量之后,就可以用DataX把它给拉起来了。这是一个比较常见的做法。
我们仍然保留脚本模式,一是方便存量任务的迁移,还有一些比较特殊的场景,比如 MongoDB 或者 ES 按天去切分,这种原数据我们没有办法拉到,它是一个变量,这个时候就需要依赖脚本模式来实现动态配置。
③ 单机模式 – 作业配置替换的挑战

我们在作业开发时遇到的最大挑战是刚才提到的作业配置问题。众安内部现在有大量的原有自建的数据源上云,例如 MongoDB 或者 ES,还有阿里云的 HBase,上云后原有的作业必须要通过改脚本的形式,才可以把这个作业发上去或进行修改。这样就非常的不自动化,会有大量的运维压力。
当作业换环境发布的时候,还需要进行一个替换,改变配置文件本身的内容,可能会有多份脚本要管理。
数据源鉴权扩展性特别差,比如有一些极端的情况下,通过配置 DataX 的连接串,是没有办法做鉴权的。我们现在的做法是把数据源给一个统一的名字,然后在名字下会配测试和生产环境。在 DataX 中我们用名字替代所有的数据源连接,例如一个 PG 的回流,一个数据源的名字可以代替原有的 JDBC URL 以及用户名密码,当从测试向生产发布的时候,测试任务替换测试数据源的信息,生产任务替换生产数据源的信息,从而实现这三个问题的解决。
对于 PG 可能效果不明显,如果后面我们用到特别复杂的数据源,比如Neo4j Graph 或者 Hadoop 的双活模式,HDFS 的双活模式,这样一些比较高级的数据源的时候,这种做法的优势就会非常明显。
④ 单机模式 – 离线集成服务化
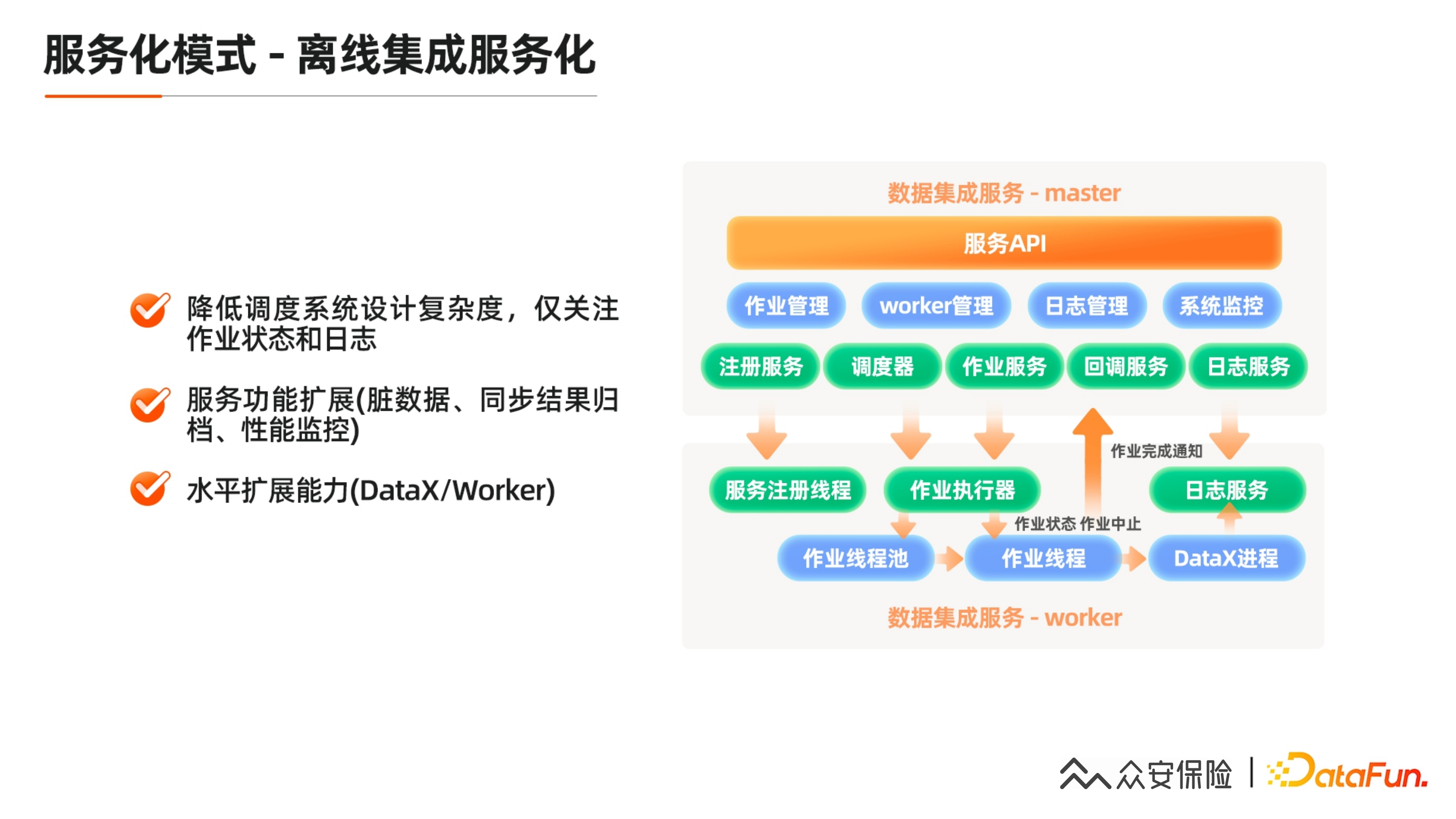
作业配置服务化作业开发完之后,我们正在趋向于做离线数据集成的服务化。其最大好处是降低调度系统设计的复杂度。对于这种数据集成作业,调度节点不是拉起一个 DataX 进程,而更多的是一个 DataX 作业调用 API 之后关注作业的状态和日志的一个过程,这样会极大的降低调度执行器节点的资源消耗。
基于此功能我们还可以开发很多扩展性功能,例如去修改 DataX 的源码,把其中的脏数据即 Plugin Collector 里的 Dirty Data,或者最终的同步结果,通过接口的形式进行上报,最终进行统计和归档。这块也可以延伸到数据质量,也可以使用一些相似的功能。
同时我们还可以对同一个作业历史上发布的数据推送量趋势等进行监控,这对后面的数据治理也会有极大的裨益。
服务化之后,我们可以利用执行节点的水平扩展能力,或者说是 DataX 分布式化的扩展能力。
图示是最常见的一种离线作业服务化模式,以两个 Master 作为 HA。
作业管理,即调用 API 分配给它一个实例 ID。
Worker 管理,对执行器节点的注册和资源使用情况的监控。
日志管理,动态实时的查询日志给调度系统,查询使用情况或者历史日志。
系统监控,即监控整个作业集群的使用情况,往往通过分布式调度系统,调度执行器会选择节点最空闲的资源分配给作业,线程池拉起作业守护线程,最终拉起 DataX 进程。我们可以对 DataX 进行一定的封装,上传一些事件,给一些回调接口来同步当前作业的同步进度或同步数据量的日志,类似于本地 Communication 里打的日志都可以收集上来。

资源隔离部分,目前众安的做法是把若干个 Worker 编为一个 Cluster,每个 Cluster 下 DataX 并没有对 CPU 进行消耗,而是以内存为单位进行资源控制。我们现在的标准最少内存是 1GB,相当于 DataX Core JSON 默认的配置,如果数据量更小,可以把这个参数调到 500 兆甚至更小。一般我们建议每一个 Worker 下面留 20% 内存作为冗余资源的备份,以避免超卖或者本地一些对外内存使用导致的爆满,或者操作系统使用导致的爆满。
我们对现在的 Cluster 有很多考虑,例如不同网络环境下可以放不同的Cluster,甚至不同的部门可以放 Cluster,假如A部门采购三台机器,可以把 A 部门的这些作业优先分配在这几个 Worker 上或者这个 Cluster 上跑。
一些重点任务也可以单独放在一个 Cluster 上进行运行。这样就只需要在调度系统作业配置的时候,指定作业执行的集群和资源使用量,分配的时候,还是分配到最空闲的节点,如果无资源再拒绝。在调度执行器端的插件里,可以写轮巡等待有资源,而不是直接报错,或者重试若干次之后再报错,同时我们在执行完作业之后释放资源,如果再进一步甚至可以把资源的配置和所配置的通道数进行绑定,可能对 CPU 的限制会更好。
5. 实时数据集成
① 实时数据集成 – 为什么需要实时集成
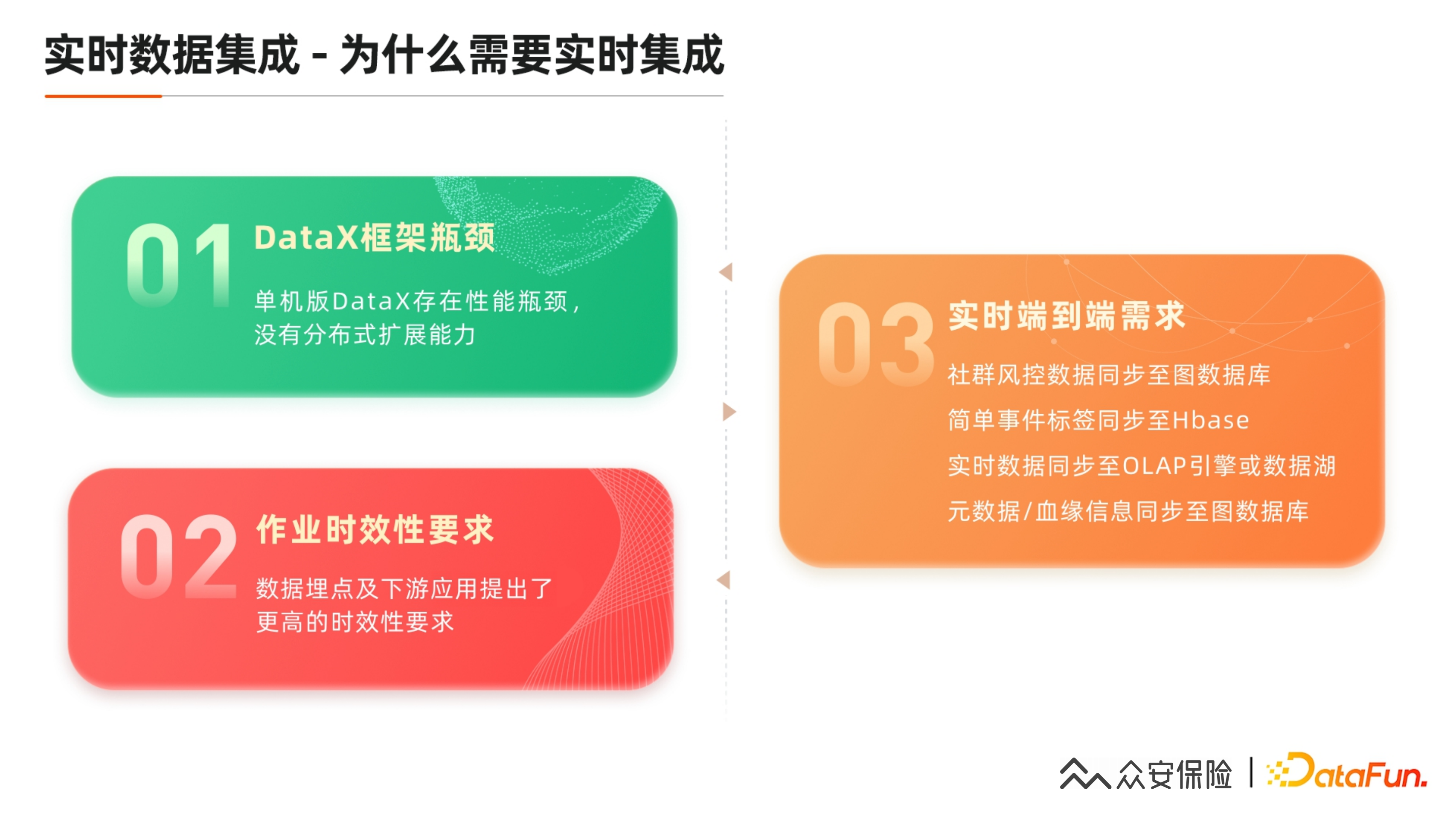
我们有大量超大数量的作业回流,单机版 DataX 存在性能瓶颈,其没有分布式的扩展能力。如果定制开发可能会有比较大的代价,尤其对一些小公司,这个代价会比较大。
我们现在的数据埋点以及下游应用提出了更高的时效性要求,不仅要求数据采集时间缩短,ETL 时间缩短,还有更多的可能性应对突发问题,有更多的 Buffer 来处理突发问题。比如我们今年出现一次埋点采集日志程序问题,堆积大概四五亿的数据,可能需要两个小时以内回流完,会需要有更空闲的节点,分布式的能力来应对这种突发情况,还有双 11、618 这样的活动投放,当天埋点的数据量会激增,可能突破 10 亿以上。针对这种情况,我们还是需要有必要来做一些实时集成,或者扩展流批一体组件的能力。
我们现在有一些实时端到端的需求,包括:
社群风控的数据实时同步到图数据库,主要是针对金融场景。
简单的基于事件的标签,直接写入 HBase 或阿里云的 Table Store。
实时数据直接同步到 Hive 或数据湖,直接在湖里查询明细,如果各位公司的数仓比较小,可直接基于 OLAP 引擎,这是使用比较多的一个场景。
我们打算做的资产管理平台,元数据和血缘的实时变更和日志写到图数据库。
② 实时数据集成 – 技术选型
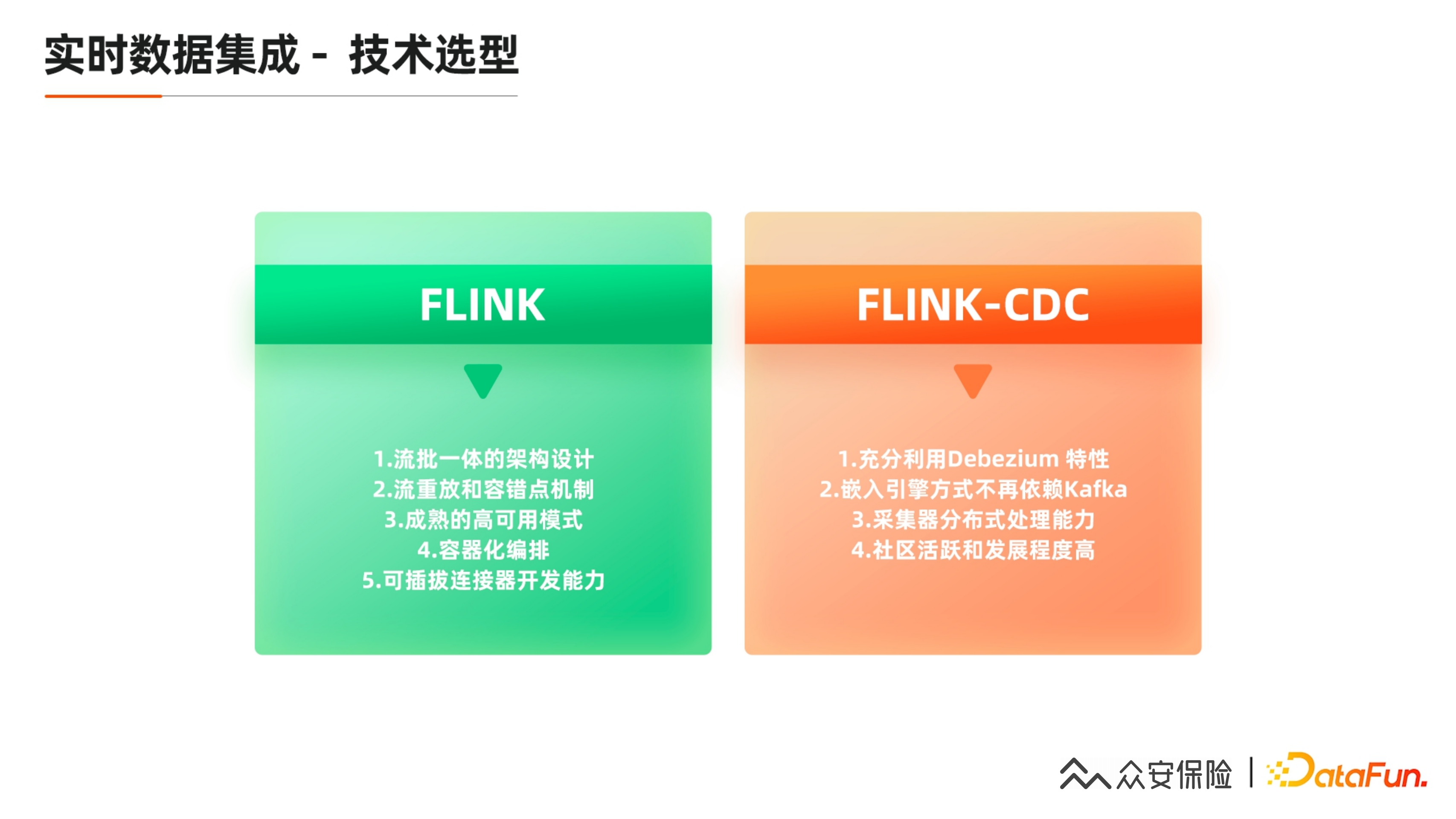
我们的技术选型是基于 Flink 和 Flink CDC:
Flink是考虑流批一体,尤其是 1.12 版本之后,Stream API 一统天下同时支持流或者批。
流重放和检查点机制,可以对我们的部分数据源的回流,实现断点续传,比如我们有自增的主键以及能过滤的数据源,都是基于以上功能实现断点续传。
成熟的高可用模式,包括 Standalone,HA,K8S 上都有成熟方案。
容器化的编排,对于 CPU 控制会有更好的效果。
可插拔的 Connect 插件的开发能力。
对于 Flink CDC:
我们充分利用 Debezium 的特性
选 Flink CDC 相当于嵌入式使用 Debezium 引擎的模式,可以不再依赖于 Kafka 或 Kafka Connect,省了一个 Kafka 集群。
Flink CDC 2.0 之后,其采集器 Debezuim 有一些 Split 特性,支持分布式处理,比原来的单机模式有更好的性能,尤其是全量模式加载会有更好的性能。
社区发展跟活跃度很高,包括未来 2.0 计划支持 MongoDB 或一些新的数据源,可能会更好的利用到我们现在的场景当中。
③ 实时数据集成 – 流批一体组件

我们实现实时数据集成之前,一定要做一个流批一体的组件。
基于我们现有的 DataX 的 One Configure 能力,类比于 Flink,有相似的抽象,比如 Flink 的一个 Connector里有 Sink 和 Source,Source 相当于 Read plugin,Sink 相当于 Write Plugin。同时 Stream Record 的概念和 DataX 的 Record 非常像,所以整体上无论离线还是实时我们的配置可以抽象成一种。
底层的数据源扩展可以基于 Flink Connector,作业发布可以基于 Flink on YARN 或 K8S,Connector 层和发布层,我们可以和公司内部共建流计算平台。
如图示我们实时数仓的 ETL,更偏向于基于 Connector 的 Flink Table API或 SQL API 做实时的 ETL。实时集成更多的其实是基于 Connector 的能力,封装一些参数来直接生成 JSON 配置,通过 JSON 配置直接生成一个实时任务的一个效果。
④ 实时数据集成 – 服务化架构

我们要统一集成作业的配置,不管实时还是离线任务,都是 One Configure,我们可能更多的是在插件层或 Adapt 层对原有 DataX 的参数进行更多的封装,实现区分它是实时集成作业还是离线的集成作业,或者说它是一个 DataX 作业,还是一个Flink作业,同时兼顾实时和离线的场景,因为目前来看,我们的实时 ETL 不可能代替所有的离线 ETL,所以还是需要两者兼顾。
与此同时我们也要兼顾 DataX 和 Flink 两种 Case 的情况,因为基于成本上的一些考虑或者未来商业化输出的一些考虑,比如有些公司完全没有 K8S 或大数据集群会直接走 DataX,如果一些性价比低的作业也可以放在 DataX。
对于一些比较高效企业数据量特别大的作业,通过实时的场景进行运算,同时底层的 Flink 的编排服务也是可以复用的。与和前文中离线数据集成服务化的架构类似,我们更多的是在服务 API 层之后进行解析,看它是实时集成作业还是离线集成作业。如果是实时集成作业,则直接进入到编排服务进行作业的管理以及日志的查询。流批一体的组件会打成镜像,发到这边,然后通过发布服务统一进行作业的提交。
离线作业进来之后,同样会解析它的插件,实时数据集是基于 Flink 流组件的离线作业,还是基于 DataX 的作业单机拉起进程,离线作业我们同样去调编排服务,和实时不同的是离线往往要 Hang 住,等到这个作业完全执行 OK 再终止,所以还是需要执行器的 Worker 节点进行一个轮巡的等待。
实践经验告诉我们,没有完美的架构或设计方案,而是要结合成本和资源的使用率,结合公司的业务场景,来选择最合适的一个数据集成方案。也不必超前,可以一步一步的迭代,不断完善。