导读:电商场景数据量大、业务复杂,搜索场景作为其中最为核心的流量分发与转化场域,更面临着诸多数据科学领域的问题与挑战。
本文将分享京东零售搜索数据科学团队在电商搜索场景下的数据科学实践,主要介绍:1. 电商搜索场景的特点;2. 实验科学和因果推断实践;3. 观测指标设计和业务分析。
01 电商搜索场景的特点
首先介绍电商搜索场景下基础数据建设与AB实验体系的特点。
1. 搜索订单归因
京东零售搜索业务负责精准高效地连接搜索用户和商家,涵盖各零售渠道的关键字搜索、店铺内搜索、优惠券与活动搜索等核心搜索业务。
京东零售搜索的核心目标是:提升订单转换效率,兼顾结果的精确性和丰富性。因此,搜索订单数据,是搜索业务最为核心的 feature、label、metrics 数据源
一条订单,如何归因到搜索订单?
(1)订单事件归因

多触点归因(MTA, Multi-Touch Attribution Model)是计算广告里的经典问题,对于一次转化中的各模块影响进行定性/定量的判断。归因模型对于搜索跟单、AB 口径、样本 Label 都有直接的影响,常见的规则型的归因模型有首次归因、末次归因、平均归因、复杂归因模型(Markov 模型归因、Shap 值分解归因)。比如推荐模块,更为关注何时进行首次触达,进行有效“种草”,倾向于进行首次归因;如果是关注转化的模块,例如搜索,会注重最后的订单成单是否是由搜索转化的,因此会倾向于末次归因。不同的归因方式,会用来解决不同的业务问题。
(2)时间相关性
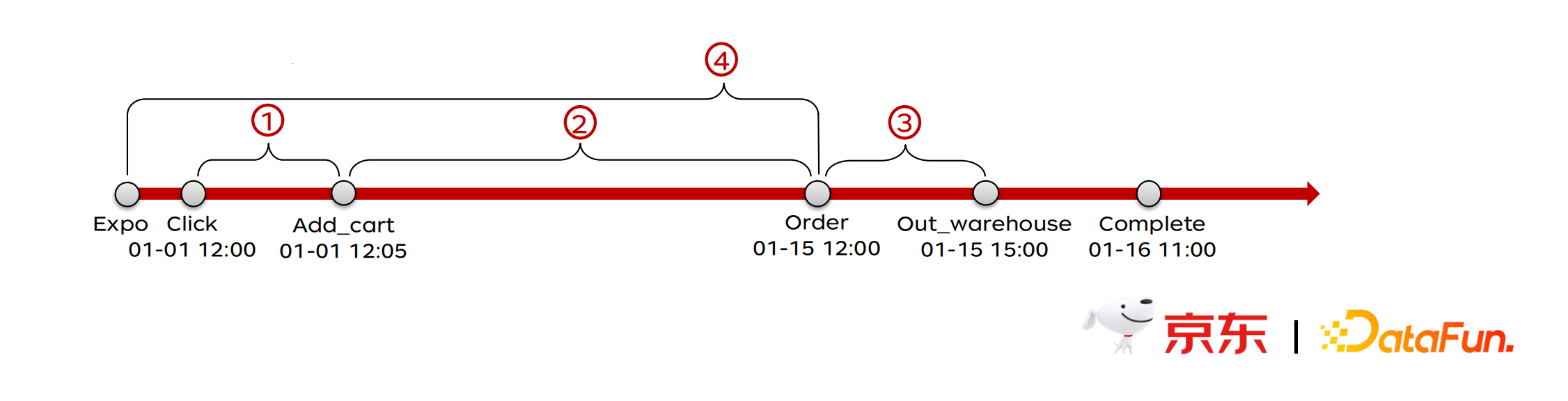
在归因分析中,关联事件的时间窗口是很重要的。例如,怀疑因素 X 引发了疾病 Y,那么对于 Y 的实验分析工作,就需要观察 X 发生的时间来做判断。
一条订单的产生,通常会经历这些流程:曝光→点击→加购→下单→支付→出库→完成。这一流程,往往会跨越一定的时间窗口, 也就是说电商里的订单反馈,是有很大迟滞的!
对于我们的 AB 实验同样,6 月 1 8 日用户 A 从购物车里下的订单,是 06-01 的时候进入 Test 实验 X 并加购的。即使 06-18 的时候 Test X 下线了,用户 A 已经被划分到 Test F 了,那么这个订单依然和 Test F 无关。
因此,我们需要回追真正用户真正受到策略影响的时间,以此保证下单行为和搜索行为在时间窗口上的相关性。
2.搜索场景下的 AB 实验
随机分流的 AB 实验是最好用的因果效应分析工具,在线 AB 实验是互联网产品迭代的核心方式。AB 实验的核心,有三个要素:
实验对象——Randomization Unit
实验变量——Treatment
实验效应——Metrics
(1)实验对象——Randomization Unit
随机分流单元的选择很多,包括:浏览器 Cookies(PC)、device id/ MEID_ IMEI(APP)、PIN、request id。选择不同的分流单元,可能会面临不同的问题。例如实验效应有跨天的情况,那么 request id 就可能无法追到,但 device id 不会变。需要特别注意,当随机分流的单元与指标分析单元不同时,评估需要非常谨慎。例如,分流单元为 device id,但分析单元为 request id 时,一方面要注意,从分流单元到分析单元之间还有一个“平均请求数”指标可能会变化;另一方面,在假设检验时,对于 request id 为单元的指标,其 variance 需要通过 delta method 进行校正。
随机分流的稳定性是电商平台经常会面临的一个问题。电商平台频繁开展促销,短期内的样本分布会产生剧烈波动。最常用的方式是先开一组AA实验,看实验效果来评估现在流量是否均匀。但如果每次都去开 AA 实验,流量稳定了,再开一组 AB 实验,这样代价是非常大的。因此希望在观测到波动的情况下,对波动进行剔除。另外,每天电商都有巨大的流量,如果是多层正交的分流实验平台,一天在线实验可能会有几百层,有的 AA 波动显著,有的没有,那么如何评估整体流量分发是否平稳呢?我们的办法是做 Multi-AA Test,比如在一个实验层上切 50 组 AA,两两之间计算显著性差异,在 95% 的显著性水平下,P 值应当服从均匀分布。如果 P 值分布明显出现左偏(如下图所示),则意味着可能有系统性的 AA 波动出现,而右偏则可能是检验效力不足。因此,Multi-AA Test 除了检测 AA 异常之外,也是对 Metrics 稳定性与假设检验方式是否合理的一种有效工具。

另一个有趣的问题是,样本独立性问题,在社交/团购类 APP 很容易出现样本间溢出效应。例如,当团购 APP 在针对新的“促销推送”功能做 AB 实验时,test组收到影响的用户可能通过分享、或者线下方式,告知自己周边的 base 用户,从而造成 treatment 策略同时影响了 base 和 test 组的用户。
(2)实验变量——Treatment
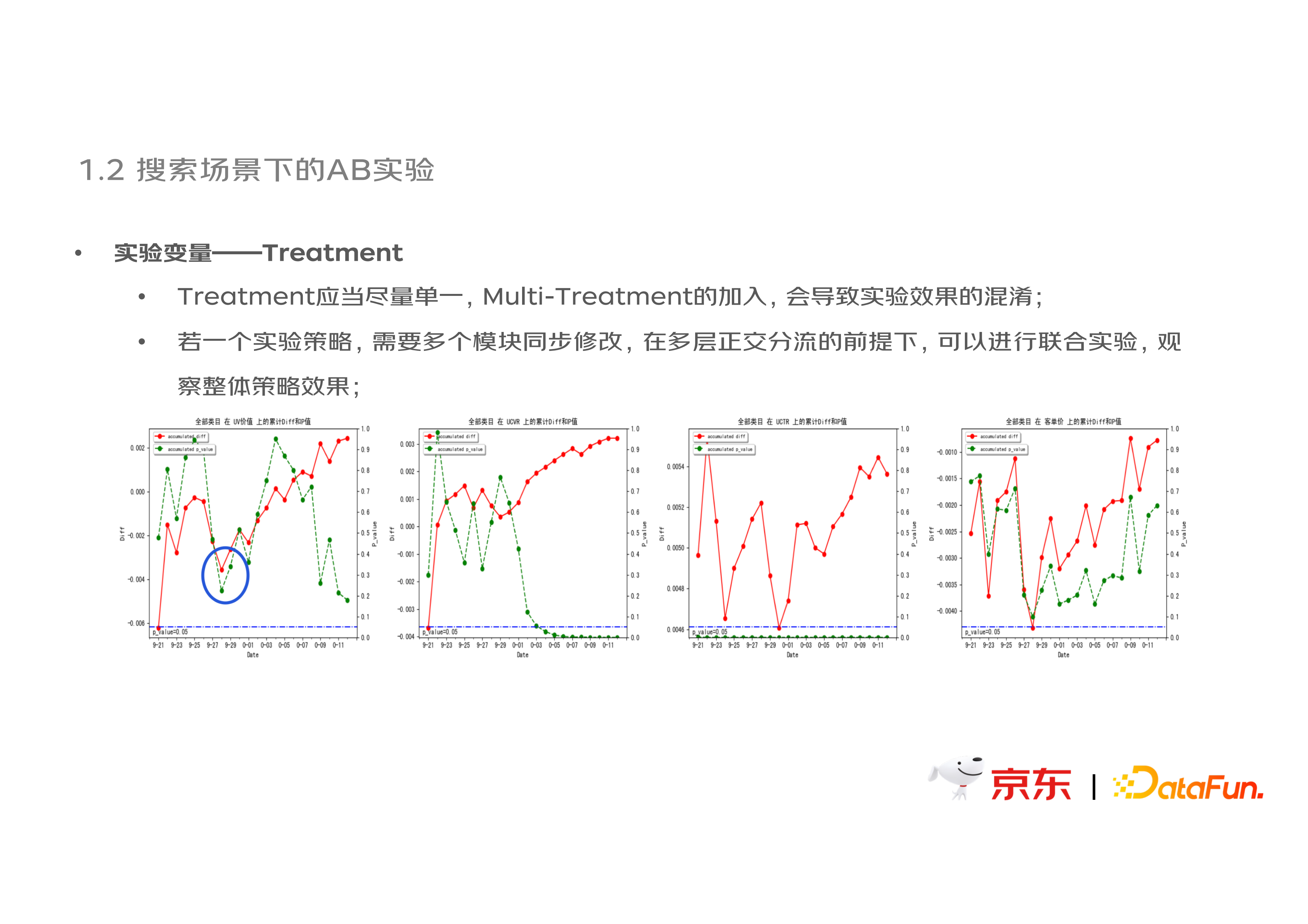
Treatment 应当尽量单一,Multi-Treatment 的加入会导致实验效果的混淆。若一个实验策略,需要多个模块同步修改,在多层正交分流的前提下,可以进行联合实验,观察整体策略效果。
如下图中的例子,在蓝色圈选的时间点,一个精排排序策略的全量,导致了当前在观测的 EE 策略实验效果突然反向。因此,实验期间出现多个 treatment 共同影响的时候,很难严谨评估出这个策略本身是否有问题,因此要尽量保证单一 treatment,减少实验间的耦合破坏多层正交性。
(3)实验效应——Metrics
评估一个实验指标的优劣,可以考虑以下三个方面:
敏感性:指标收敛能力,指标的 Test Power 与所需 Sample Size 预估,根据历史实验 case 进行 variance 估计,下图中给出了一个经典的预估公式;
解释性:指标是否可拆解、是否便于 AB 效果的分维度分析、是否直接反映到业务上,在电商搜索场景下,一个指标的解释性往往更加重要;
鲁棒性/稳定性:指标是否会误显著,需要关注指标的 AA 稳定性。

02 实验科学&因果推断实践
通过前面的讲解可以看到,电商 AB 实验过程中可能会存在一些问题,我们通过实验科学和因果推断技术不断迭代和修正,积累了一些成功案例。
1.因果推断基础框架

因果推断典型框架之一是 Rubin’s Potential outcome 框架,其核心是寻找反事实样本。从个体效应的角度,在现实生活中反事实样本通常难以获取,但通常电商样本的数据量足够大,在一群人中总能找到某个事实的反情况样本。
个体实验效应是指电商场景下某个单独的人或某件单独的商品的情况。
子群实验效应是指某个商品类目、某个用户群分层下的收益。
全局实验效应是指整个电商销售平台的大盘收益或者整体销售价值提升。
另外一个典型框架是 Peral’s Causal Graph 因果图框架,即建立有向图描述因果关系,通过确认节点与节点之间的关系,来剔除更多的 confounder,以保证更加单纯无偏的因果关系。但在电商场景下,每天用户点击搜索会是上亿甚至十亿级别,这样规模上建模因果图成本会很大。仅在 case 级别的研究时会用因果图框架。
我们归纳了因果推断基础框架,如上图右侧所示,包括实验数据因果推断和观测数据因果推断两个方向。实验数据虽然由随机分流AB实验得到,但是依然可能存在实验前样本差异,实验中低渗透率,实验后损益不均等问题,因此主要使用因果推断方法来修正或者下钻实验效应分析。当没有条件进行 AB 实验时,针对观测数据也有一些方法,如策略全量生效时,有经典的断点回归和时序分析;当策略分批生效时,可能存在组间差异,可以使用宏观双重差分 DID、宏观合成控制 SCM 等技术;当全局不均匀生效,则需要样本微观层面进行 PSM、SCM-DID 等工作。
2.小流量/高波动场景下的实验方法论
搜索实验,由于订单反馈的延迟、频繁的促销行为、垂直场景丰富等原因,往往可能存在以下问题:
样本量小,反馈稀疏
方差大,难收敛
波动大,不稳定
混淆因子多,随机性差

(1)样本纠偏
为解决以上问题,首先会做样本纠偏,用 PSM 回归 propensity score,修正样本分布,借用用户画像 tag 寻找 confounder。例如年龄可能会导致抽烟和不抽烟的用户发生变化,如果直接把抽烟的用户和不抽烟的用户放在一起,去看死亡率,那肯定会有问题。因此首先要控制 base 和 test 组年龄分布相同。当实验只看一个 treatment 的影响时候,年龄这样的 confounder 就会带来影响。在对于 ATE 的计算上可以把 propensity score 代入,去做 PSM,找两组样本尽可能一样,或者是用 IPTW 这种方法,把每个样本对于 treatment effect 的贡献做权重上的调整。我们更多会关注 IPTW 的方法,因为 PSM 有一个关键的问题是,去做 matching,总有一部分样本是 match 不到的,那么 match 不到的这部分样本上面的收益和损失,可能就已经带来了选择偏差。
(2)方差缩减
CUPED 方差缩减的想法也很朴素,就是如果能够找到在 treatment 真正作用之前,这个样本本身就是一个很爱点击很爱反馈的样本,那么进入 treatment 之后,这样的可能会给 treatment effect 的估计带来偏差。我们要尽可能用实验前的样本行为来减少实验中带来的 variance。这时的做法就如图中公式,找到一个协变量x。比如要去评估 UCTR 指标,如果能找到他的回访周期是否频繁,浏览深度如何等,就可以通过这些协变量来消除点击上的 variance。这个协变量的相关系数越高,对方差的缩减就越大。
上图右下角的图展示了 P 值的缩减效果,原本要七八天都无法收敛的实验,现在使用 CUPED 方法,第四天就可以看到收敛效果。但这里的缩减不一定正确,可能让你在第四天就做出了错误的决定,p 值后续可能又会增高。因此使用方差缩减,在反向实验时要加强验证,避免误显著带来错误决策。
(3)分流单元切换

在电商搜索里,用户划分在样本量不足的情况下,通常难以构建有效的 AB实验。解决方案是让一个用户同时暴露在两种实验策略下,即不使用用户维度分流,而是使用 interleaving 坑位穿插分流,这种实验方式在 feed 流实验中会更为有效。对比正交分流实验,interleaving 分流方式收敛速度会非常快。但是,在电商排序场景中,interleaving 分流方式会存在一定的风险:一方面,电商场景存在 position bias,首位商品的 ctr 会明显高于后续位置,interleaving 分流需要非常严格按照位置进行分流,否则极易产生错误结论;另一方面,base 和 test 穿插的搜索结果页,可能导致用户整体翻页下滑,换句话说,坑位样本的提升效果不一定在用户样本上仍然存在,后续的正交分流 holdback 实验是非常重要的。
3. 异质性效应分析
为应对异质性效应,可以通过以下方式建模:
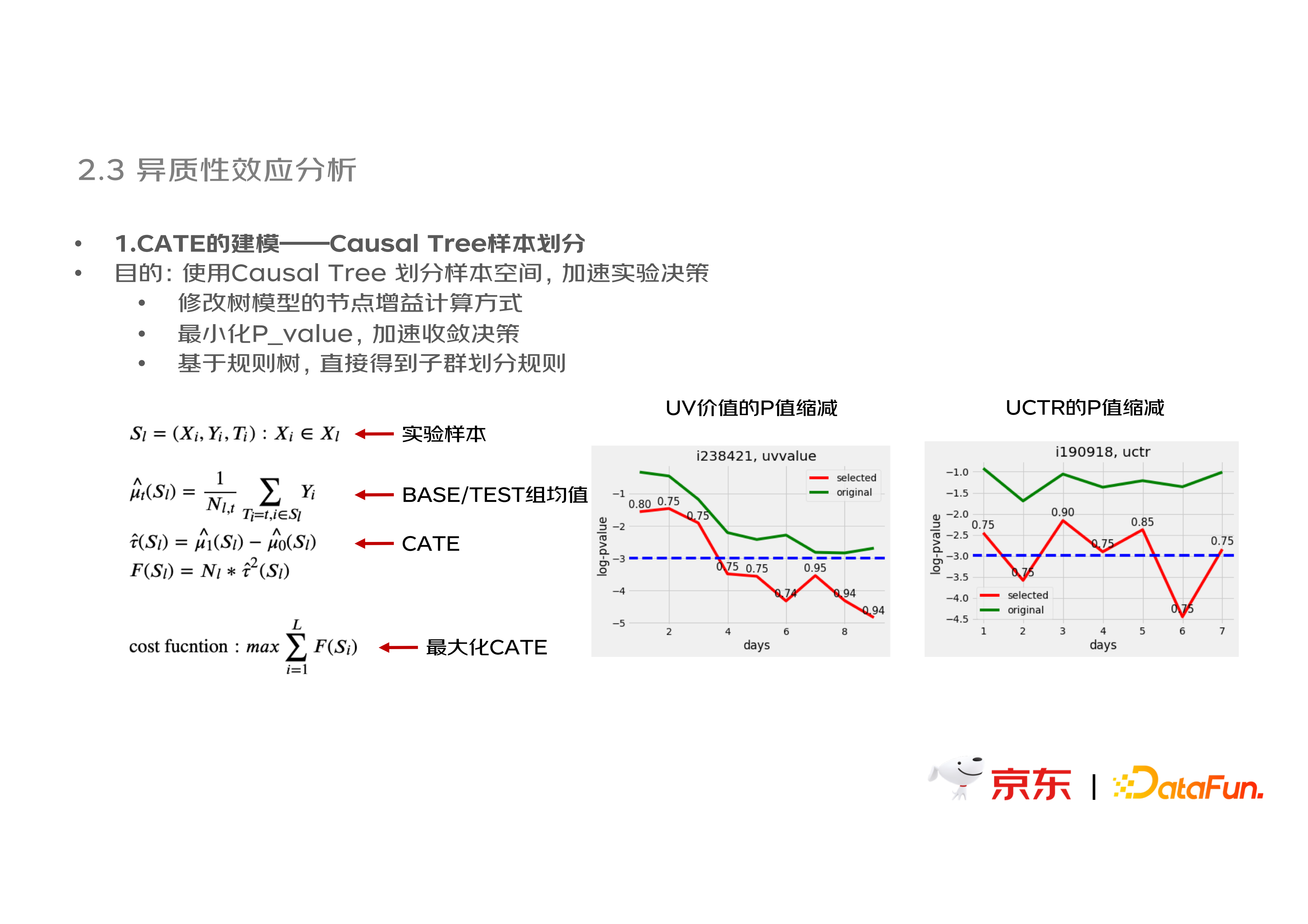
(1)CATE 的建模——Causal Tree 样本划分
此处的建模目的是,使用 Causal Tree 划分 AB 实验样本空间,剔除不敏感的用户子群,从而加速实验决策。具体方法如下图,修改树模型的节点增益计算方式,从而使树模型最小化 P_ value 。基于规则树的建模方式,可以直接得到子群划分规则,小幅度剔除不敏感用户子群后,P 值收敛明显加快,从而加速实验的分析决策。
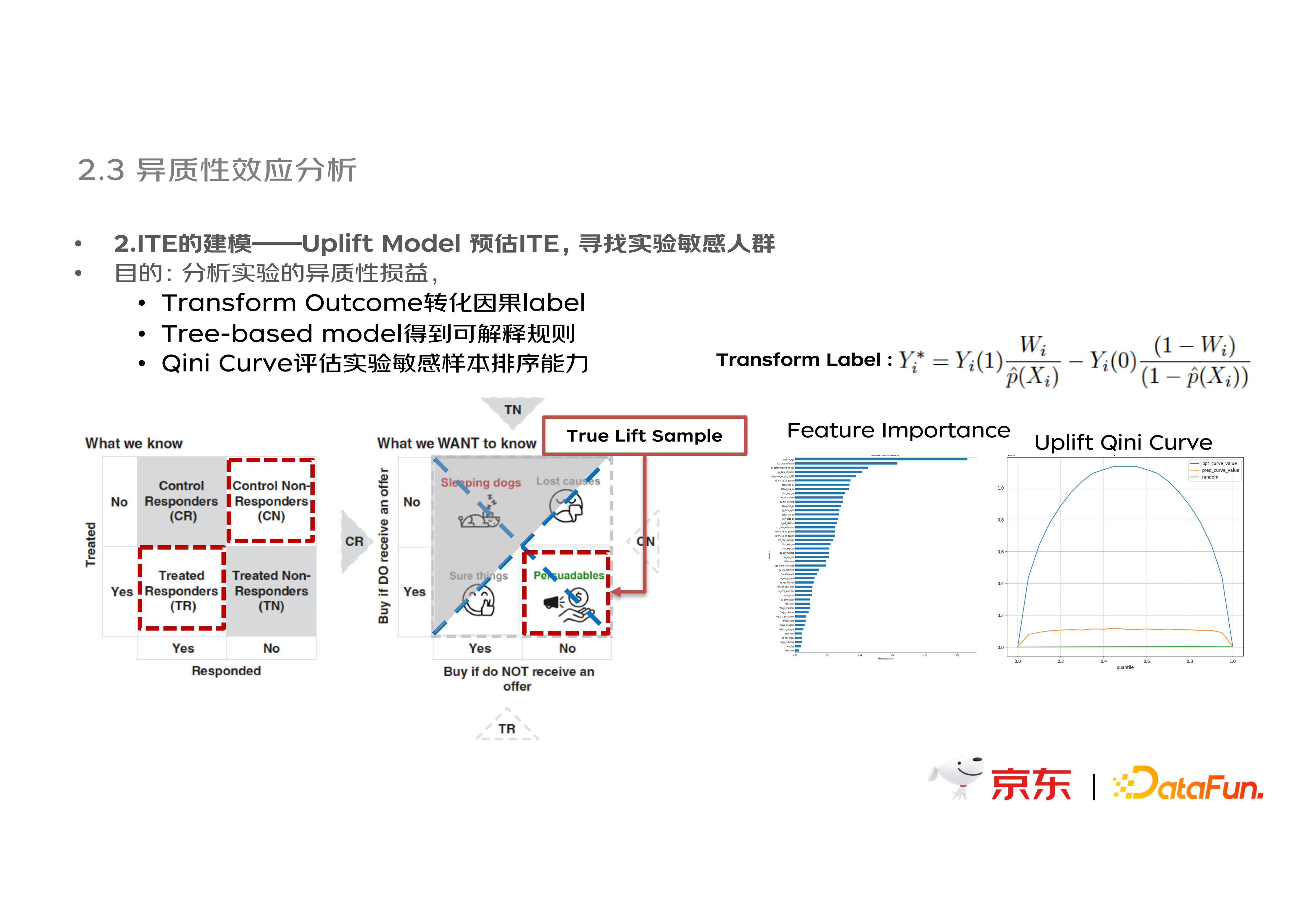
(2)ITE 的建模——Uplift Model 预估 ITE
此处建模的目的是,分析实验在样本维度的异质性损益,用于综合评估实验风险。其中,Transform Outcome 方法用于转化因果 label,Tree- based model 建模用于得到可解释规则。使用 Qini Curve 评估实验对于敏感样本的排序能力。例如,对于新品实验进行分析,其中较为敏感的 feature 是“商品评论数”,基于该 feature 划分样本可以发现,对于高评论用户的新品策略收益是最大的。
4.准实验评估方案
在没有条件进行 AB 实验, 或 AB 实验受到干扰导致随机分流失效时,就需要我们构建准实验。具体应用如下:
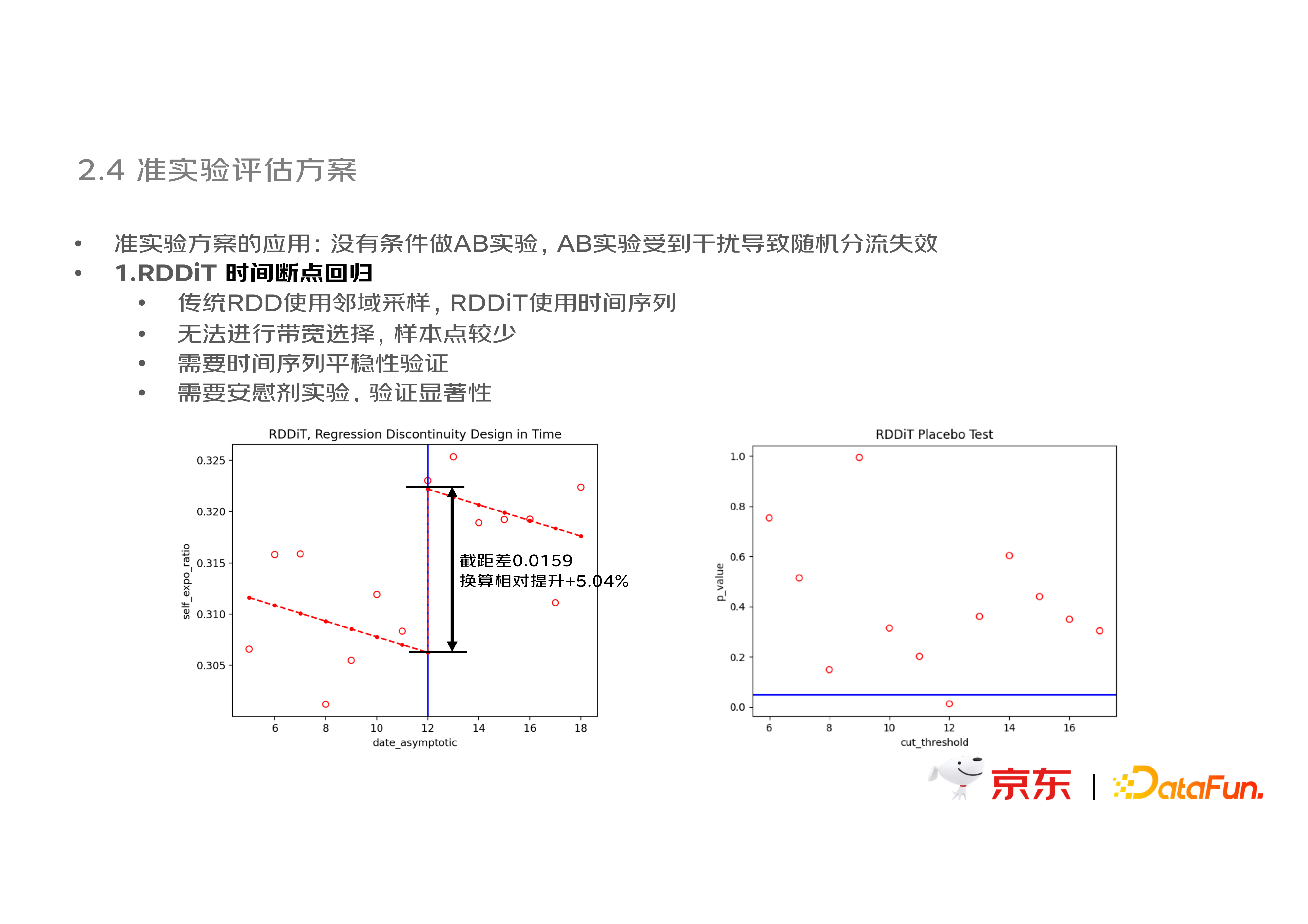
(1)RDDiT 时间断点回归
断点回归 RDD 的应用例如下图中,在 12 号存在一次集群配置突变,该数据仅有大盘整体的 daily 数据点,需要评估该集群突变带来的用户转化变化,此处就需要使用 RDDiT 进行。左图可以看出断点明显,回归后得到量化的截距差就是这个 treament 带来的影响;右图的安慰剂实验也可以判断,仅在 12 号存在断点显著差异。传统的 RDD 使用邻域采样,RDDiT 使用时间序列,因此会有以下区别:无法进行带宽选择,样本点较少;需要时间序列平稳性验证;需要安慰剂实验验证显著性。
(2)DID 修正后的多重差分
在下图例子中,一组物理实验,在 2022-01-07 前后出现了集群切换,同时在 2022-01-12 前后出现了实验策略的反向交换。因此,此处不再是常规的 DID 双重差分,而是需要引入 treatment、timing、group 三重变量的多重差分。搜索实验中应用 DID 方法有以下问题需要关注:
首先,DID 务必需要进行 Common Trends 校验,回归实验前虚拟的时间变量和分组变量交叉项;对于非平稳时间序列,此处增加时间项修正误差;经典双重 DID 评估斜率变化,适合评估绝对值,而搜索场景评估截距变化,关注的是 ratio 指标。

03 观测指标设计与业务分析
除了以上实验科学的工作之外,指标设计也是数据科学中一项重要的工作。除了传统的 CVR、CTR 等指标之外,在复杂业务场景中还有诸多业务效果的衡量诉求,这些业务的 Metrics 都是需要一定设计的。
1. 流量分发的度量
大家默认有个共识,搜索的流量会集中在很多头部词上,而长尾词和长尾供应上天然是不足的。但是,搜索词是否真的全部符合“长尾分布”?这个“长尾效应”的强弱到底如何?这些问题一直是没有固定答案的。
那么,如何度量搜索流量分发的头部效应?就是一个困难而有趣的课题。
观察搜索 Query 的 Session 量分布,有很明显的幂率分布的特征,头部query 的 Session 量聚集明显。

搜索 session 分布符合一种很典型的分布,即幂率分布,它的特征是有显著的转折点,累积可能有一个很快的上升并最终收敛在某一区间,如果对纵轴和横轴都取 log 会变成线性。
而幂律分布的成因,有一个非常有趣的解释。借由无标度网络的角度来看,样本间不独立,增量与存量不独立,从而带来了头部节点指数级别的“度”增长。

结合幂率分布的性质,我们可以围绕流量分发的集中程度进行指标设计:
幂率分布的幂指数
双 log 后会看到典型的线性特征。斜线的斜率可以很好的度量当前流量集中情况。幂指数可以全面衡量数据分布,稳定性好,但解释性差,敏感度差。
Top80% 搜索量覆盖的 query 个数/占比
关注业务解释性,稳定性和敏感度较差。
搜索 Querv 熵指标
稳定性和敏感度较好,但解释性较差。
拟合一个幂率分布很难,但拟合一个线性关系很简单。我们对于双 log 图进行线性拟合,发现大量腰尾部点是符合幂率分布性质的,但是头部 query 却并非完全符合幂率分布。这里体现的,在实践中,长尾效应并非是覆盖所有样本点的,存在明显的分段幂率效应(Broken Power Law)。
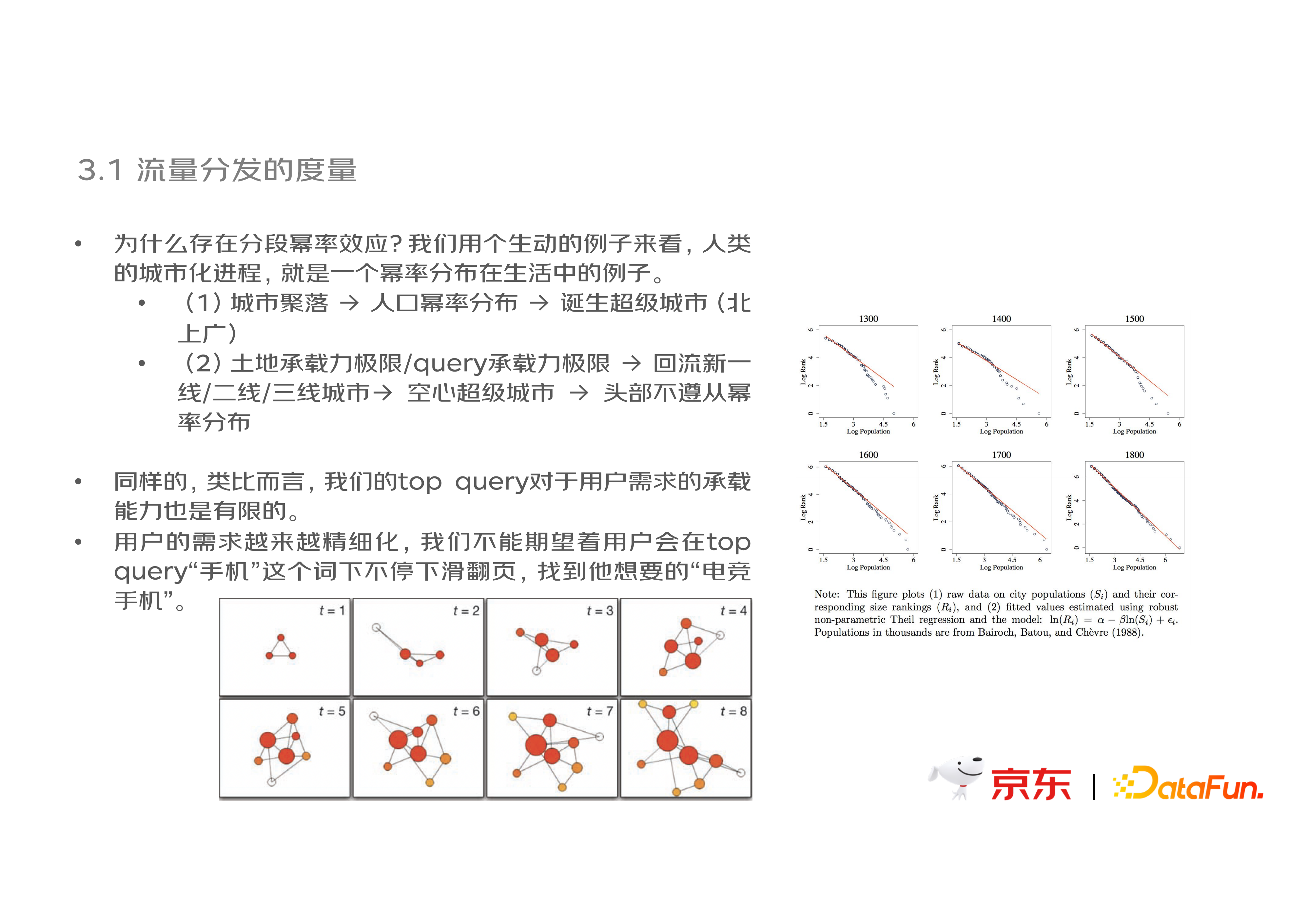
为什么存在分段幂率效应?我们可以通过一个生动的例子来看,人类的城市化进程中,人口的分布就是一个典型的幂率效应。人类的迁徙聚落,就是一个无标度网络连接的过程。我们会从一个县走到一个省的省会,也可能从省会走到首都,北上广这样超级城市的诞生就是人口流动和迁徙带来的。但是,人口的流动和迁徙也会有不满足线性特征的情况,比如右图中西欧城市化进程中的人口分布,因为土地承载力是有极限的,头部城市无法完全满足幂率特征。类似的,我们 query 的承载力也是有极限的。不可能在一个 query 上满足所有用户需求。用户的需求会进一步细化。
这样去看我们现在的流量分发,就可以很好的意识到,头部流量上偏离拟合,就是因为这一部分的流量承接已经饱和了,没有更多的成长空间了。通过拟合值和真实值之间的差异,或者去校验幂率分布和真实分布之间的差异是从哪个断点开始的,就能很好地确认哪些词是头部词。同时,在二八定律下,80% 的流量能覆盖哪些词,这些词其实就是我们真正的去再做细化的腰部词。最后,可能还有很巨量的尾部词,已经是非常细化的用户需求了,我们也需要通过算法去引导。

结语:
从订单样本的构建,到 AB 实验与因果推断的应用,以及最后流量分发的metrics 设计。搜索数据科学始终坚持以业界先进方法解决实际的业务难题,坚持从基础数据入手为复杂方法论构建地基。如果读者对我们的团队感兴趣,欢迎参考下图中的团队介绍,或通过邮箱 sunxiaoyu5@jd.com 与我交流。


