导读:大家好,我是来自飞猪推荐算法团队的里熙,今天给大家分享的是本团队在飞猪首页猜你喜欢推荐 Feeds 流的召回阶段做的一些优化工作。
今天的分享主要包括三个部分:第一部分是相关的一些背景介绍,第二部分是目前飞猪首猜线上主流的一些召回方法,第三部分是本团队在飞猪首猜向量召回上做的一些实践和优化点。
01 背景介绍
首先看一下应用的场景,飞猪首页猜你喜欢是多物料混排的 Feeds 流场景,其中多物料包括商品、酒店、POI、视频内容、图文内容等等。每种物料都是由对应的子场景来负责推荐的,主场景通过异步调用的方式获取每个子场景的推荐结果,混排之后得到最终的推荐结果。
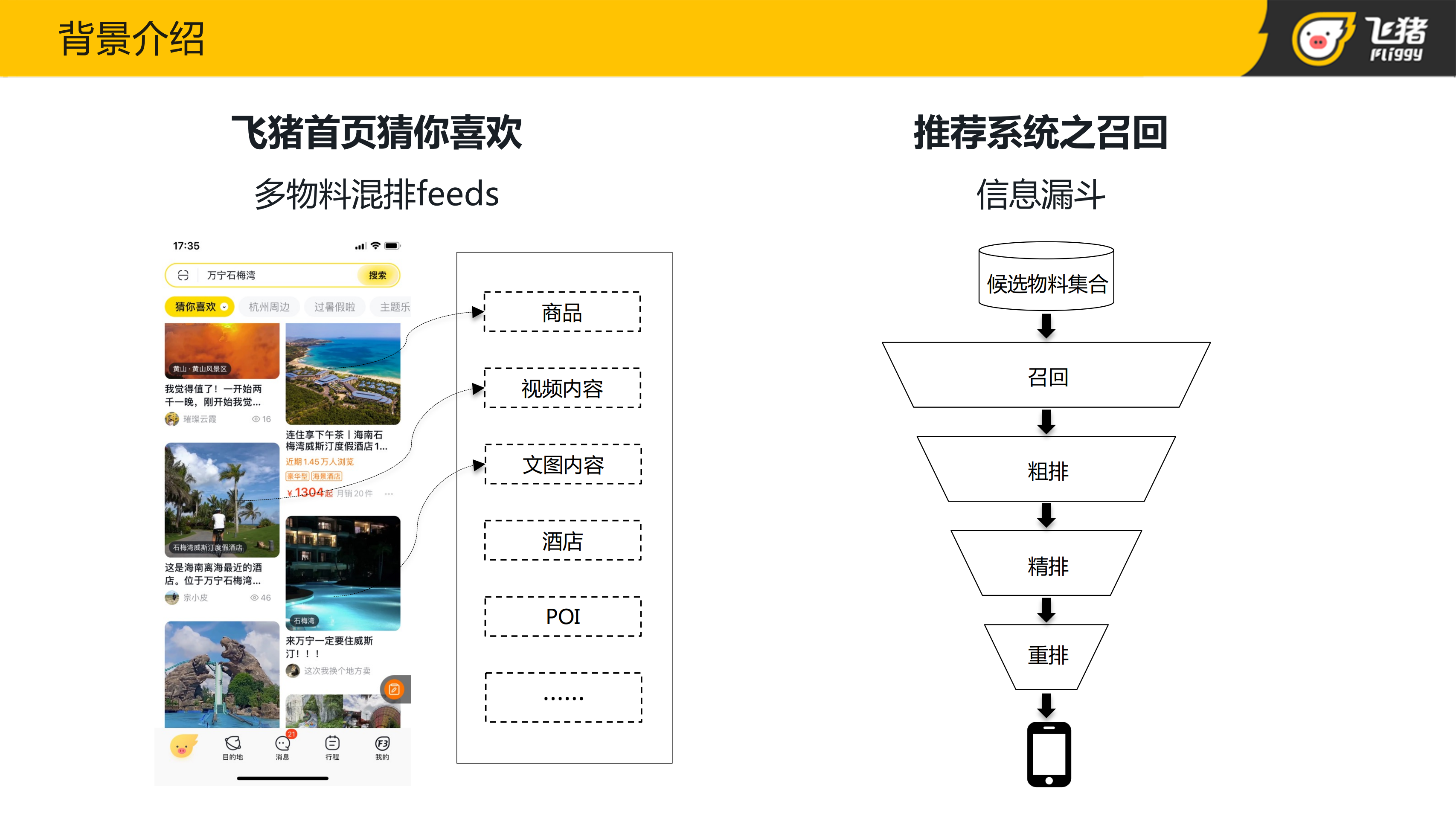
推荐系统一般是由召回、粗排、精排等多个阶段组成的。其中召回作为推荐系统的第一个环节,它的主要作用是在海量候选中快速筛选出用户感兴趣的内容,得到相对较小的候选集,从而缩小排序算法的搜索范围。作为整个信息漏斗的第一个漏斗,召回面临的挑战在于:需要在海量候选中快速筛选出用户感兴趣的内容,交给粗排层,在大力出奇迹的同时可以做到快而准。
目前工业界普遍采用多路召回的方式,各召回策略之间保持一定的独立性与互斥性,保证在各个链路并行召回的同时增加召回结果的多样性。飞猪首猜使用的正是多路召回的方式,以飞猪首猜商品物料的召回为例,其中包括一些主流的、效果较好的 I2I 召回,一些偏泛化的属性召回 ,一些富有航旅特色的地理位置召回及旅行状态的召回,用于兜底的热门召回,一些偏业务策略的冷启动和保量机制,以及今天重点介绍的向量召回。

向量召回是通过学习 User 和 Item 的低维向量表征,把召回问题建模成了向量空间的近邻检索问题,已经被大量证明可以提升召回结果的多样性和泛化能力。下面将介绍本团队在飞猪首猜向量召回的优化过程中遇到的一些问题和一些优化点。
02 飞猪首猜向量召回算法演进
1. v1版-双塔模型
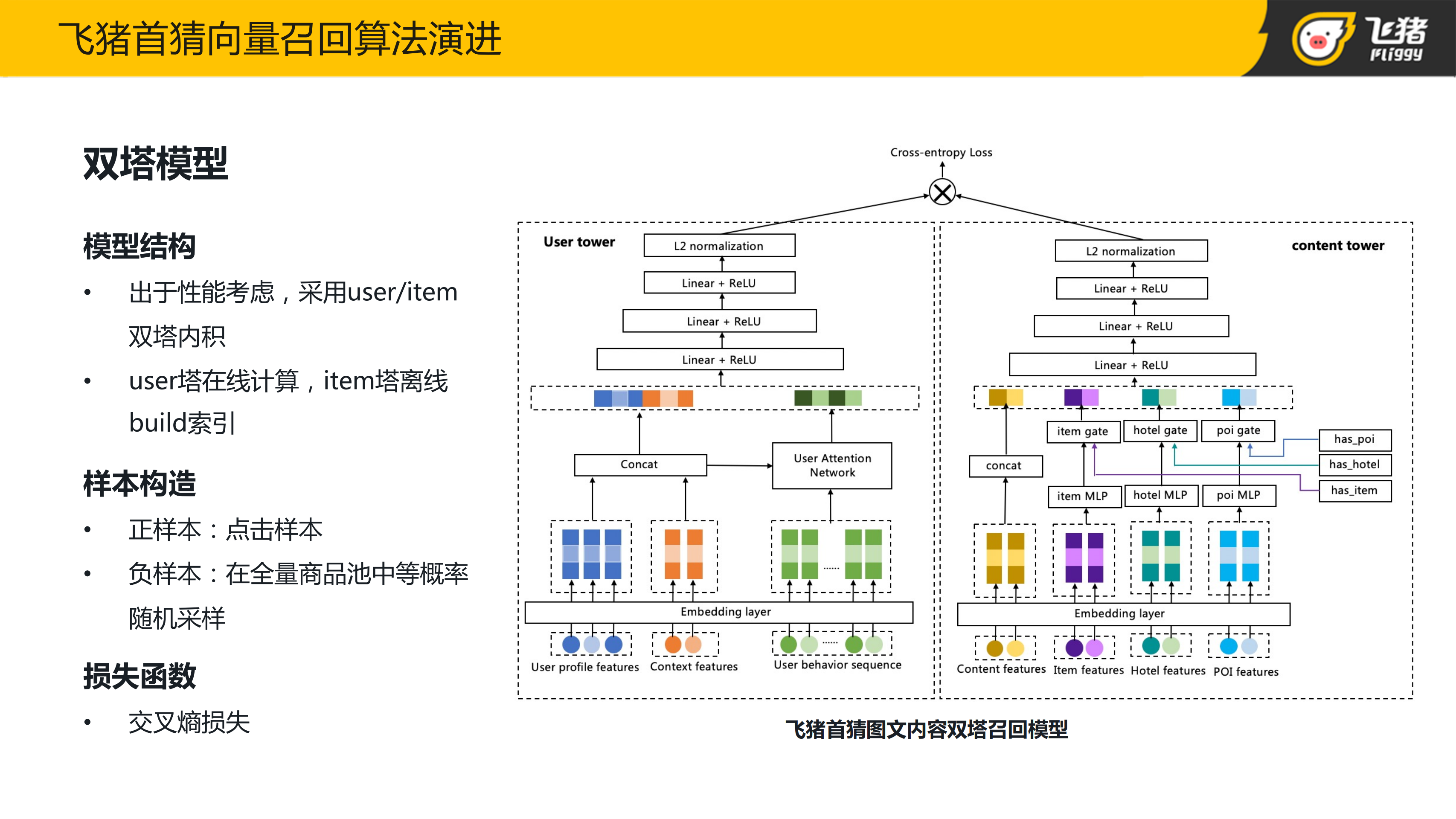
我们的第一版向量召回模型是经典的双塔模型,双塔的设计解耦了 User 和 Item 的底层特征交叉,可以在离线对所有的 Item 过一遍 Item 塔,得到 Item 的低维表征。双塔召回模型虽然牺牲了一定的精度,但速度快,能够很好地胜任召回侧的工作。
以飞猪首猜的图文内容的双塔召回模型为例,在 User 塔中输入的特征包括:用户的基本属性特征,用户的历史行为序列,以及上下文特征。在行为序列的处理方式上,我们利用用户的属性特征和上下文特征拼接之后作为 Query,对用户的历史行为序列做了 User Attention,得到用户的行为表征向量。将该向量和其他特征拼接之后一起输入到 MLP 中,再经过归一化之后,得到固定维度的 User Embedding。
在内容塔中,除了内容的属性特征,统计效率特征以外,还引入了内容所挂载的子物料的特征。旅行内容挂载的子物料包括:商品、酒店和 POI,通过门控机制来控制不同子物料的特征输入。最终所有的特征也是通过拼接之后输入到 MLP 中,再经过归一化后得到和 User Embedding 相同维度的内容 Embedding。在最后一层将归一化之后的 User Embedding 和内容 Embedding 做内积计算,得到向量之间的相似度。
在训练模型时,如果采用精排思路,将点击的样本作为正样本,曝光未点击的样本作为负样本来训练召回模型的话,训练出来的模型和向量用于线上检索时的效率是比较差的。因为召回面临的是整个候选池的商品,而曝光样本只是全量候选池中的部分子集。如果只拿曝光样本来训练召回模型的话,会面临离线训练和线上数据分布不一致的问题,也就是常说的样本选择偏差问题。而召回里负采样的目的就是为了尽量符合线上的真实分布。全局随机负采样是经常用到的一种方法。在本团队实验中,取点击样本作为正样本,在全量候选池中等概率的抽样来构造负样本。

V1 版简单的双塔模型,在首猜的图文子场景和视频子场景都进行了上线,可以看到线上两个子场景的点击率都有比较明显的提升。除此之外,本团队还利用双塔模型所产出的内容 Embedding 和 User Embedding 做了两个附加的实验。
第一个附加实验是基于双塔模型所产出的内容 Embedding,基于向量的相似度计算了一路内容召回内容;第二个附加实验是利用双塔模型产出的 User Embedding 做了人群的聚类,线上增加了一路基于人群相似度的召回。可以看到这两路召回也给我们的场景带来了一定的点击率的提升。
2. v2版-基于增强向量的双塔交互模型

双塔模型由于对 User 特征和 Item 特征进行了分离,导致双塔模型难以引入 User 和Item 之间的交叉特征。另外双塔模型只有在 User Embedding 和 Item Embedding 在最后计算内积的时候才会发生交互,这种过晚的两侧特征交互相比从网络底层就进行特征交叉必然会带来一定效果损失。
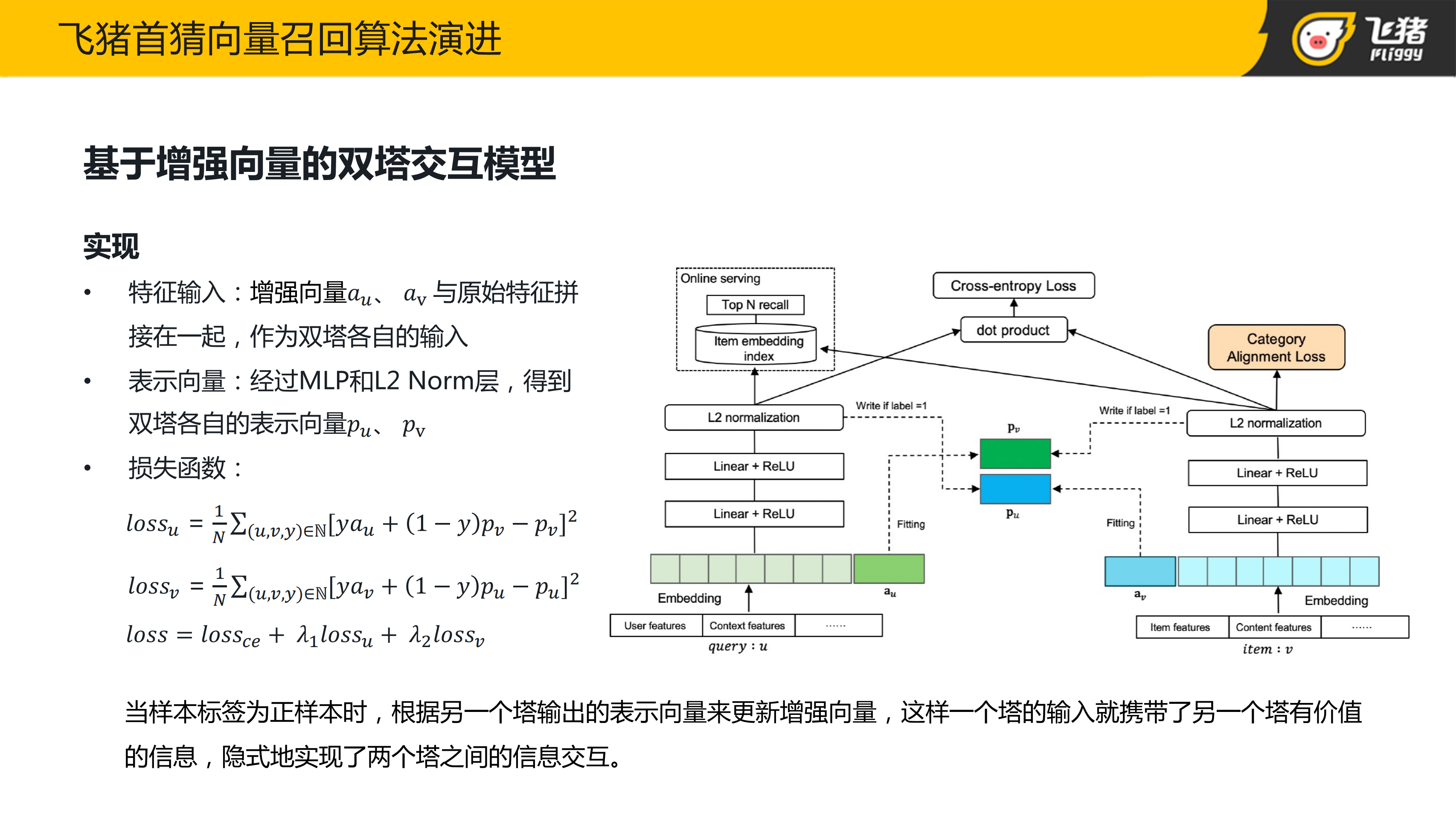
美团在这方面提出一种新的模型,通过在 User 塔和 Item 塔中分别引入增强向量来实现双塔从底层就开始特征交互,从而进一步提升 Base 双塔模型的效果。在实现时,User 侧的增强向量,实际上代表的是来自 Item 塔中与该 User 有过正向交互的所有 Item 的信息;Item 侧的增强向量,它代表的是来自 User 塔中与该 Item 有过正向交互的所有的 User 的信息。增强向量实际上是通过拟合对应的 User 或 Item 在另一个塔中的所有的正样本的输出,来实现双塔从底层就开始进行特征交叉。
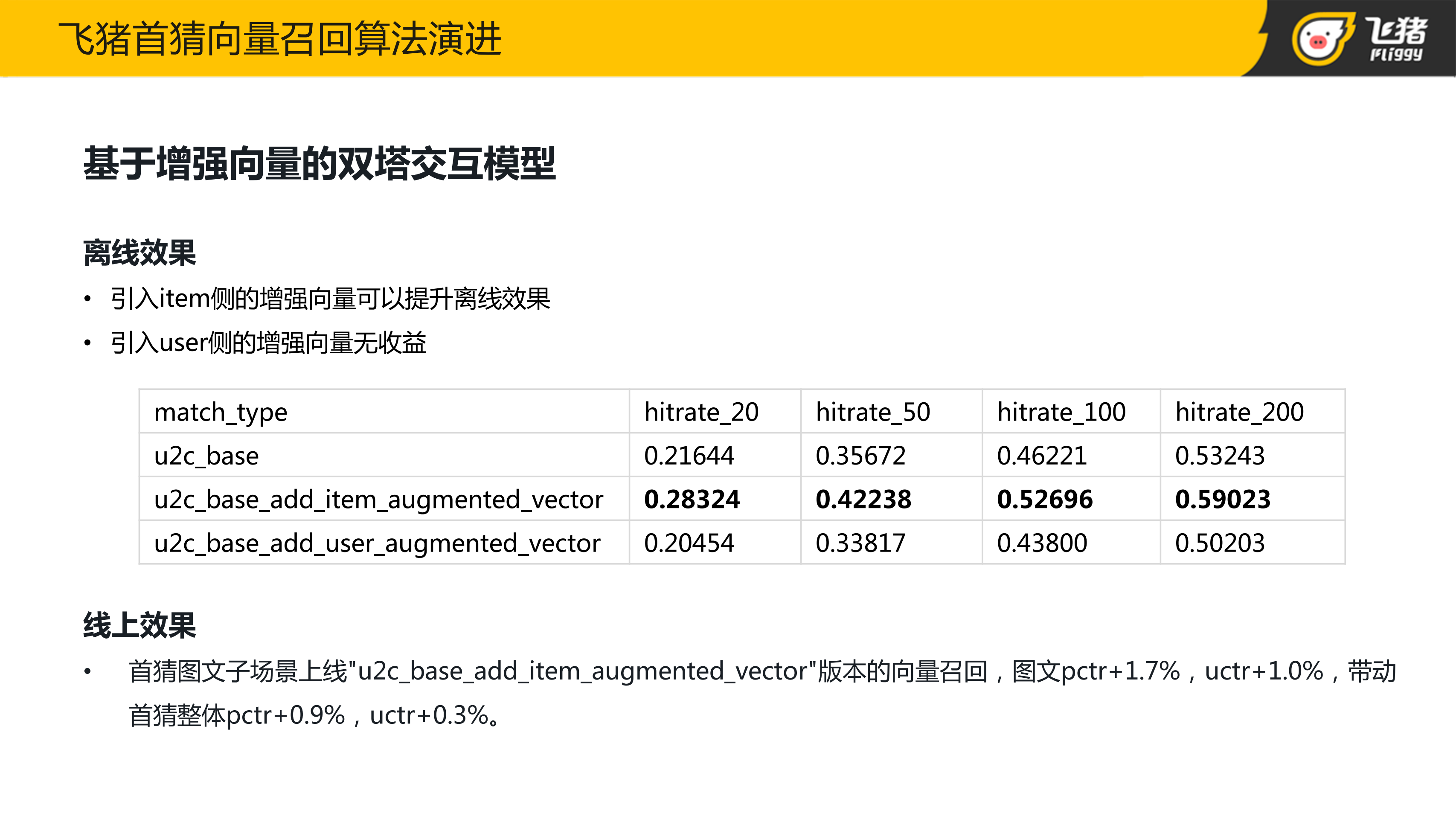
我们也在 V1 base 双塔模型的基础上引入 Item 侧的增强向量和 User 侧的增强向量。通过离线实验效果发现引入 Item 侧的增强向量,可以提升离线效果,但引入 User 侧的增强向量并没有拿到收益。分析原因可能是 User 侧的增强向量,实际上代表的是用户他所行为过的所有的 Item 的信息,但在 Base 模型中,User 塔已经有了用户的历史行为序列,也就是说在引入 User 侧的增强向量,并没有引入额外增量信息,反而引入了更多要学习的参数。最终,本团队将 Item 侧引入增强向量的模型在飞猪的图文子场景进行了上线。可以看到相比第一版 Base 双塔模型来说,线上的点击率也是有提升的。
3. v3版-模型无感的无偏召回框架
前面我们提到为了解决召回的样本选择偏差问题,我们是采用了全局随机负采样的方式来构造负样本,也就是在全量的候选集中等概率的抽样来构造负样本,且这些负样本在训练时也是被平等对待的。但是假如我们将采样空间划分成四个互斥部分,由内而外分别是:点击空间、曝光未点击空间、召回未曝光空间以及未召回空间。很显然来自不同子空间的负样本所承担的重要性是不同的。以 A 空间-曝光未点击的样本为例,由于这些样本在线上的时候是经过召回、粗排、精排等阶段层层筛选出来的,说明与用户还是比较相关的,这些样本相比于 B 空间或者 C 空间的样本而言,并不是用户特别不喜欢的。因此,召回模型有必要对这些负样本进行有差别处理。
基于上述思考,本团队提出了模型无感的无偏召回框架,利用了因果推断中的 IPW(Inverse Propensity Weighting)思想来对召回模型里面的负样本进行有差别处理,并利用多任务学习方式来实现端到端训练,该工作是 2022 年发表在 SIGIR 2022 上的一篇短文。

整个框架是由两部分组成:左边是主任务,它是模型无感的,可以是任意双塔结构的向量召回模型。右边是有两个子任务构成的辅助网络,其中第一个子任务是用于预估全空间到召回空间的概率,它的训练样本是以召回未曝光的样本作为正样本,未召回的样本作为负样本来训练的;第二个子任务是用于预估召回到曝光空间的概率,它是以曝光未点击的样本作为正样本,召回未曝光的样本作为负样本来进行训练的。

接下来两个子任务产出的概率会用于主任务中相应负样本的去偏。以 B 空间中的负样本为例, 也就是召回未曝光的样本,我们会将主任务中召回未曝光的这些样本的 loss 用子任务一产出的概率进行逆倾向加权,从而得到理论无偏的估计。同理也可以对 A 空间中曝光未点击的样本,以相同方式来进行处理得到理论无偏估计。最后整个模型是以多任务学习的方式实现端到端训练的,它的 loss 由两部分组成:一部分是双塔模型里面的交叉熵 loss,另一部分是两个子任务的 loss。

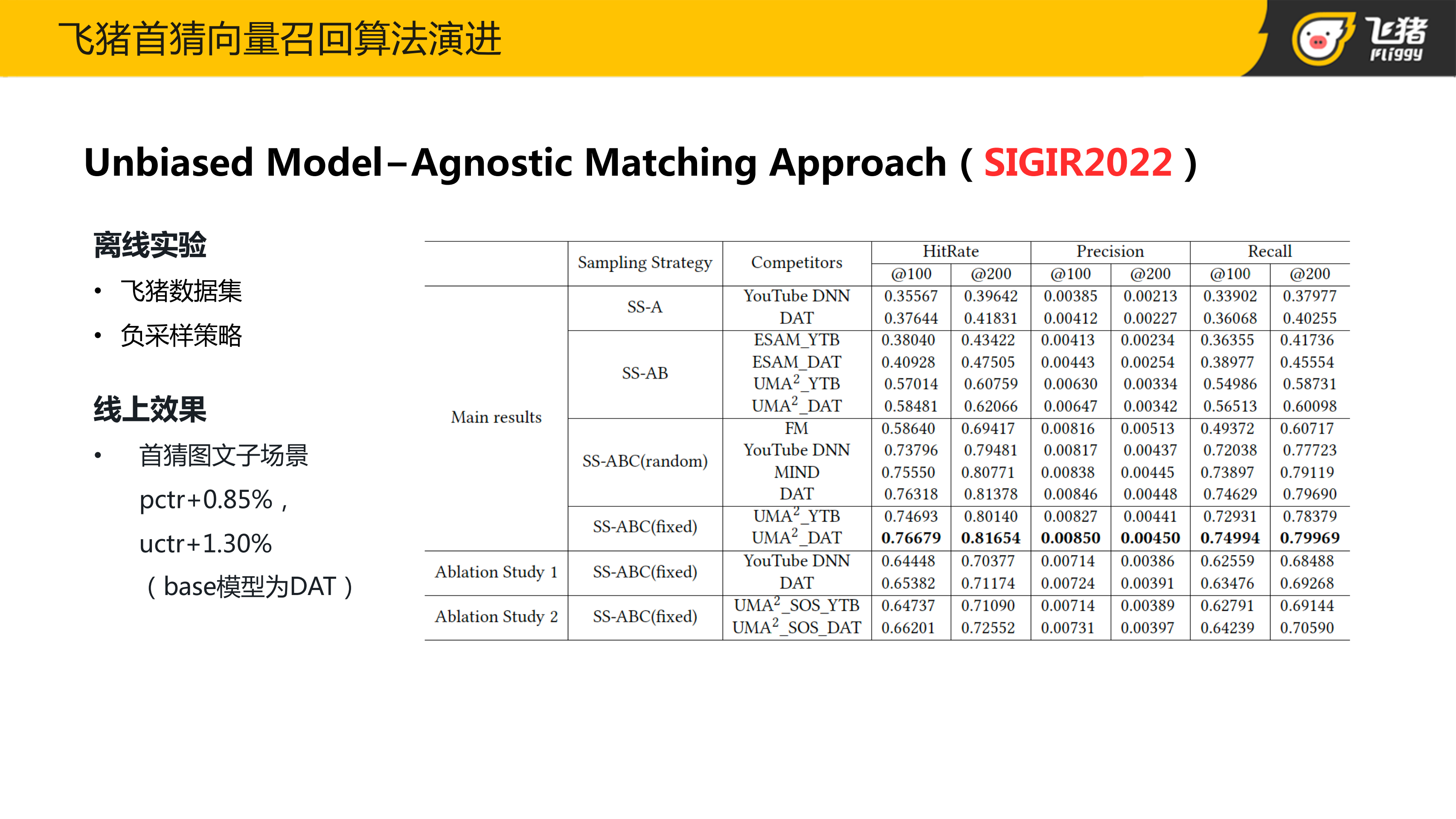
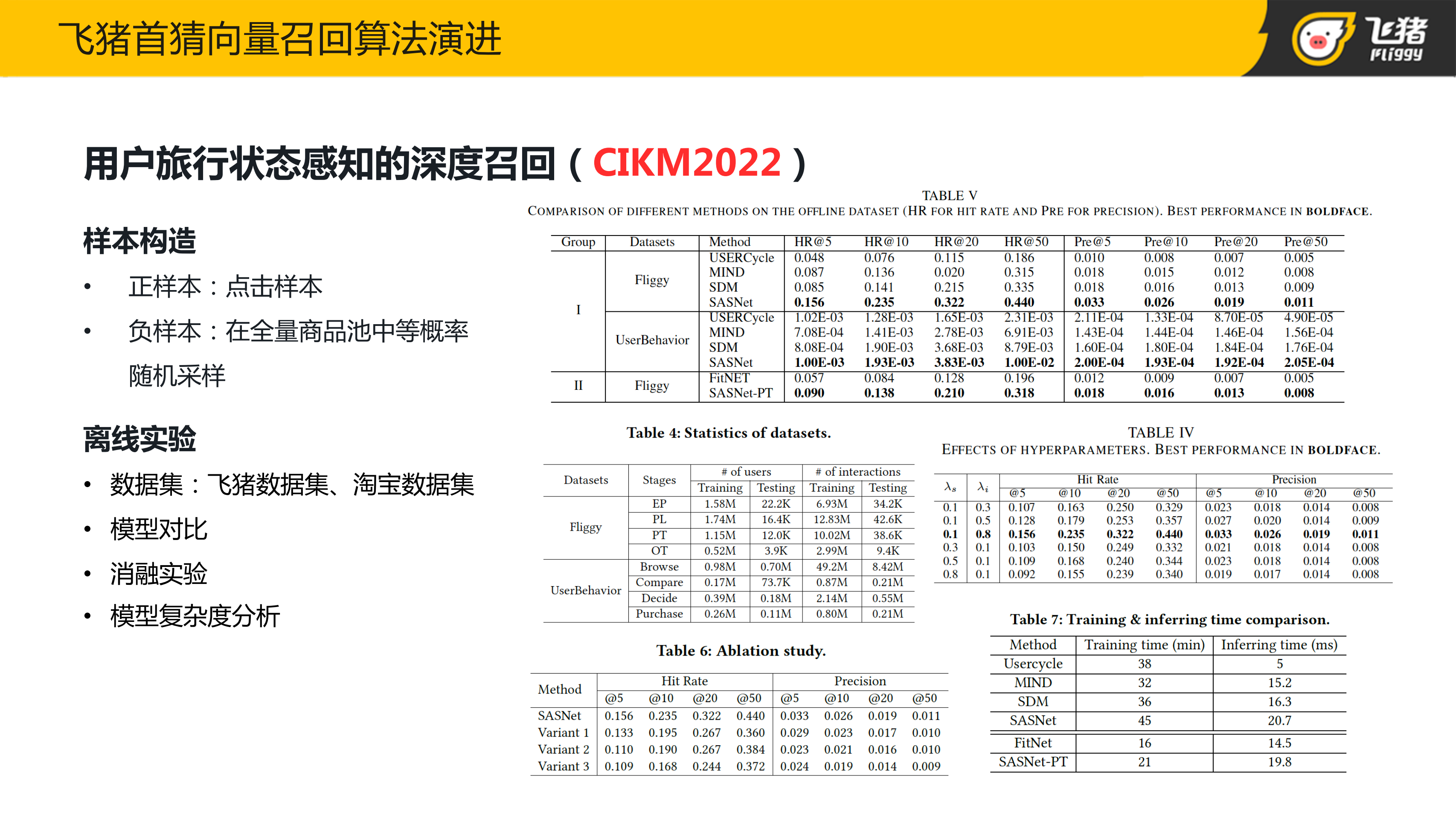
由于目前没有公开的做全空间召回负采样的数据集,且我们需要用到“是否召回”与“是否曝光”等多个 lable,因此在离线实验部分,本团队基于飞猪场景的数据构建了召回数据集。离线实验部分,对比目前主流的召回方法,可以发现在不同的采样策略下,该方法都是可以得到离线最优效果。
本团队也将离线最好的一版召回模型在飞猪首猜的图文子场景进行上线,在持续一周的线上实验中,实验组的点击率也是持续正向的,对比版本是前面我们提到的美团的 DAT 模型。
4. v4版-用户旅行状态感知的深度召回
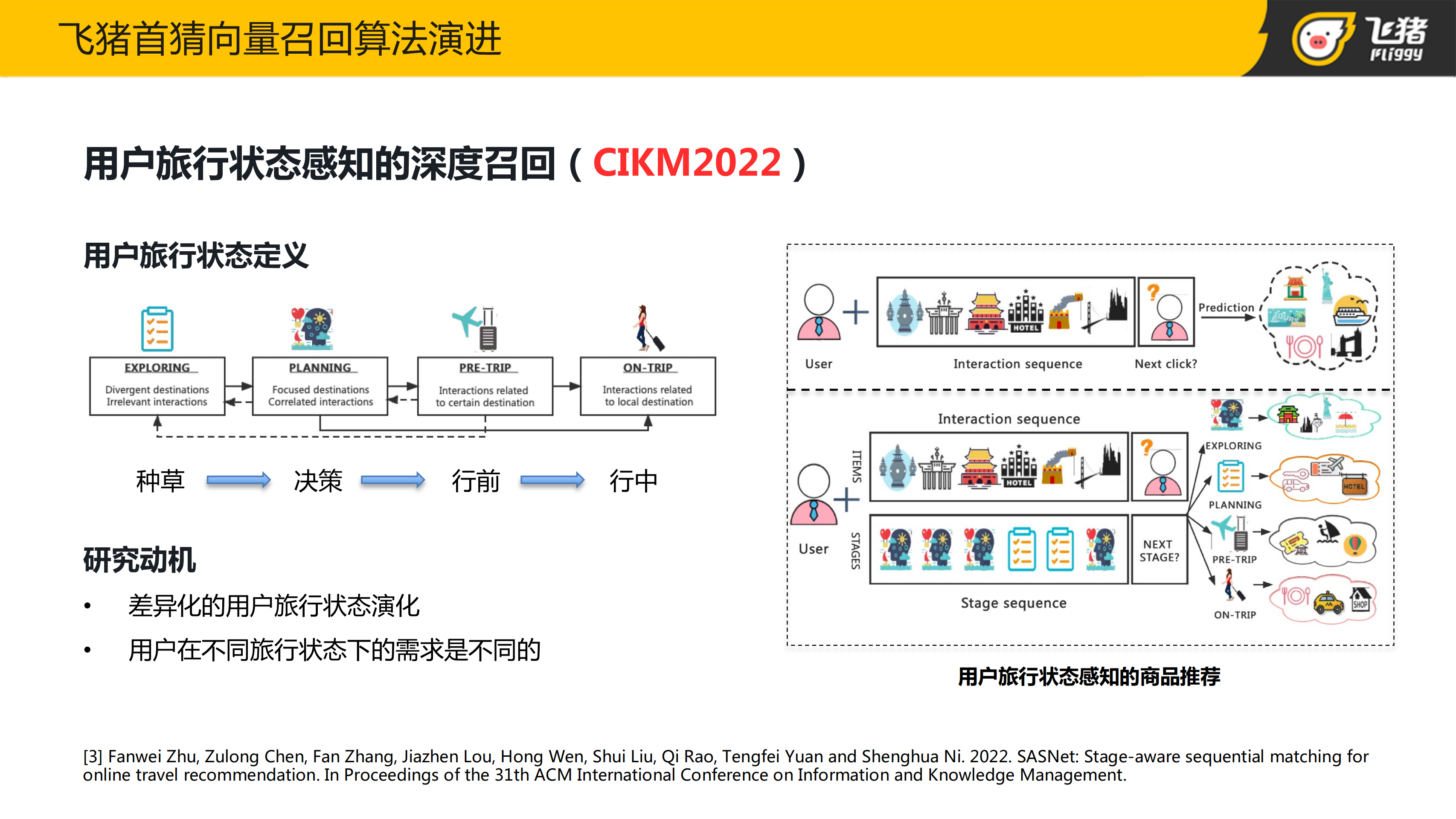
接下来要介绍的是我们小组 2022 年在 CIKM2022 上发表的,基于行业特色提出的深度召回模型。由于旅行是全链路多阶段的服务,常常会用到旅行生命周期概念。我们基于人工定义的一些启发式规则,把用户的旅行生命周期划分成四个不同的阶段:种草,决策,行前和行中。
当用户行为比较发散时,定义用户处于种草的阶段;当用户行为比较丰富,行为的商品主要集中在某个特定目的地时,认为用户处于决策状态;当用户存在即将出发的行程时,认为用户处于行前的状态;当用户的 LBS 发生位移,并且 LBS 所在地并不是用户的常去地时,认为用户处于行中状态。
很显然在不同旅行状态下,用户的行为偏好,或者说用户的需求是不同的。比如说,对于种草阶段的用户,他们往往会对一些全局热门的商品比较感兴趣,行为也会比较发散。对于行中用户,他们一般会对当地的一些景点或者美食比较感兴趣,行为也比较集中。所以说,用户的行为和用户的旅行状态是相互耦合的。一方面用户的行为取决于用户当时所处的状态,另一方面我们也可以根据用户的一些历史行为来对用户的状态进行推断。
现有的大多数用户建模的方法往往是从 Item 粒度来建模用户的行为序列,而忽略了行为序列内部的一些上下文信息,比如说前面所提到的用户旅行状态,也就无法建模出用户的行为偏好随着用户状态转移发生的变化,导致召回的结果虽然与用户存在一定相关性,但是它未必契合当时用户所处的状态。这里我们在建模用户的行为序列时,尝试引入用户的旅行状态这一先验知识来进一步提升双塔模型中的用户向量学习,并进一步提升召回结果的可解释性。
整个模型的框架图如下所示。本质上还是召回模型的双塔结构,左边是用于学习用户向量的 User 塔,右边是用于学习商品向量的 Item 塔。该工作主要的优化点是集中在左边用户塔的用户建模上。
首先引入状态转移概率预估模块预测用户的下一个旅行状态,然后通过多个不同的专家网络来学习不同状态下用户的不同表征,再利用用户状态转移概率向量,对不同状态下的用户表征进行自适应的聚合,得到状态增强的用户表征向量。最后将用户向量和商品向量分别进行归一化,通过内积来计算相似度。接下来,会具体讲解每个模块的细节。

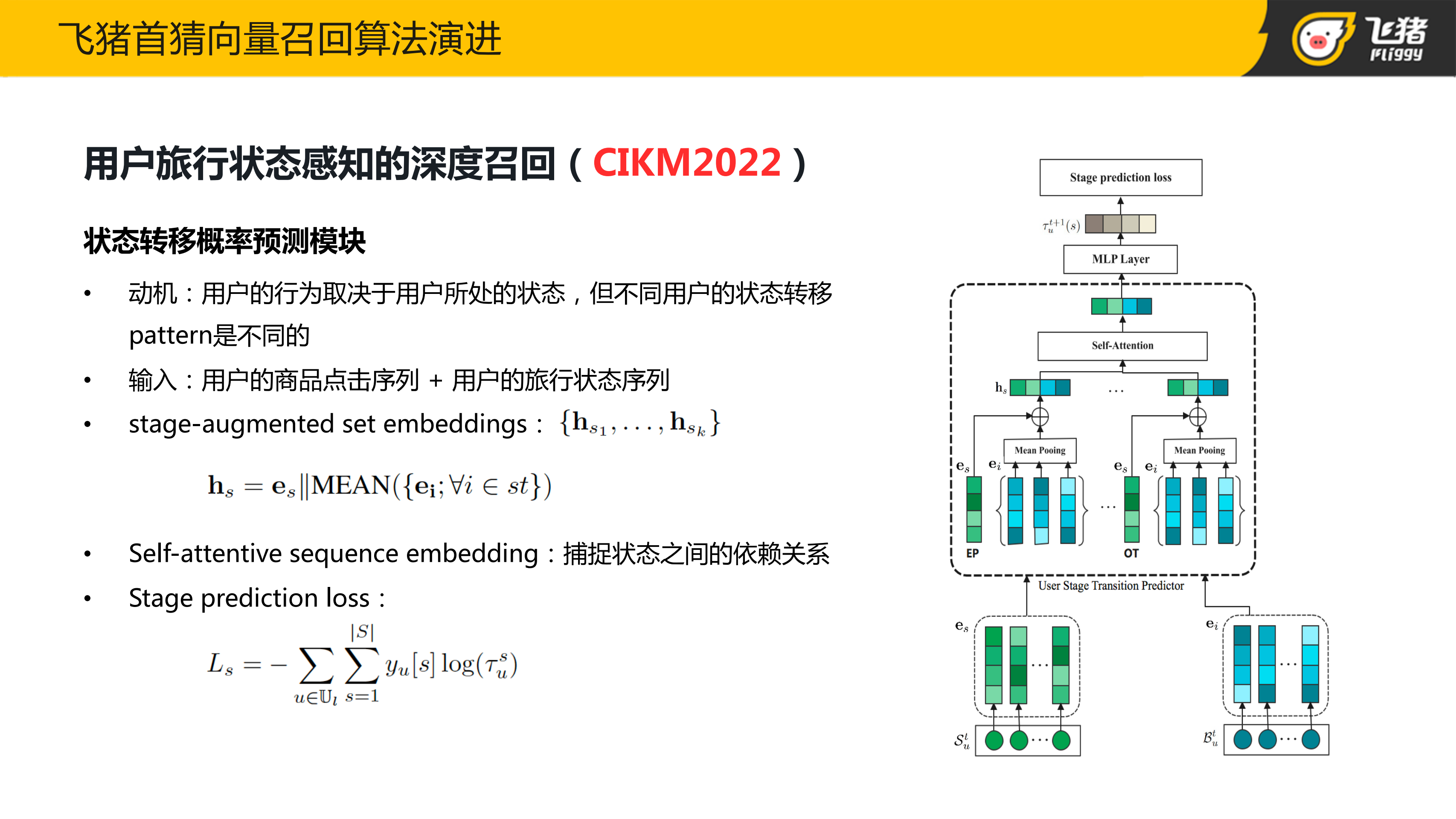
首先是状态转移概率预测模块。
如前面所说,由于用户的行为取决于用户所处的状态,因此在给用户推荐商品的时候需要知道用户的下一个状态。但由于不同用户的状态转移 pattern 是不同的,所以我们引入了状态转移概率预测模块来预测用户的下一个可能状态。由于用户的状态不仅跟用户的历史行为有关,还跟用户的历史状态有关,这里是将用户的历史点击序列和用户的历史状态序列作为该模块的输入,在对两个序列处理时,首先根据状态将用户的历史行为序列划分成一个个子集,通过 Mean Pooling 的方式对子集内部的行为向量进行聚合,然后将聚合之后的行为向量和对应的状态向量进行拼接得到了状态增强的行为表征序列。
接下来,通过 Self-attention 捕捉不同状态之间的相互依赖。
最后,通过 softmax 来预测不同状态下的概率。该模块它本质上是建模了多分类的问题,对应的类别是我们的四种不同的旅行状态。
第二个模块是状态差异化的用户编码模块。
通过捕捉状态内部的行为依赖来学习不同状态下不同的用户表征。首先我们认为不同的用户属性,它在不同状态下所贡献的重要程度是不同的。利用状态转移概率预测模块产出状态转移向量,对用户的属性特征进做 Feature Level 的 attention 计算,来建模不同状态下不同属性特征的不同重要性。利用 self-attentation 模块对行为序列部分进行处理,来建模序列内部的依赖关系。接下来会将用户的属性特征和用户的行为表征向量拼接作为上面四个专家网络的输入,每个专家网络分别对应某一种特定的状态,因此能学习不同状态下不同的 User Embedding。

为了监督专家网络的学习,我们引入了四个辅助 loss。每一个专家网络所产出的 User Embedding 会和 Item 塔所产出 Item Embedding 做内积来计算相似度。最后,基于状态转移概率向量对四个不同状态下的 User Embedding 做自适应聚合,从而得到状态增强的 User Embedding。
将 User Embedding 和 Item Embedding 分别做归一化,通过内积可以计算两个向量之间的相似度。整个模型的 Loss 由三部分组成:一部分是第一个模块的状态转移概率预估模块的多分类 Loss;第二个是双塔模型的交叉熵 Loss;第三部分是四个专家网络的辅助 Loss。整个模型是用端到端的方式联合训练的。

由于我们是召回的模型,在样本部分,取观测到的点击样本作为正样本,负样本用全局随机负采样的方式得到。离线实验部分,分别在飞猪内部场景的数据和淘宝公开的推荐数据集都做了对比实验。
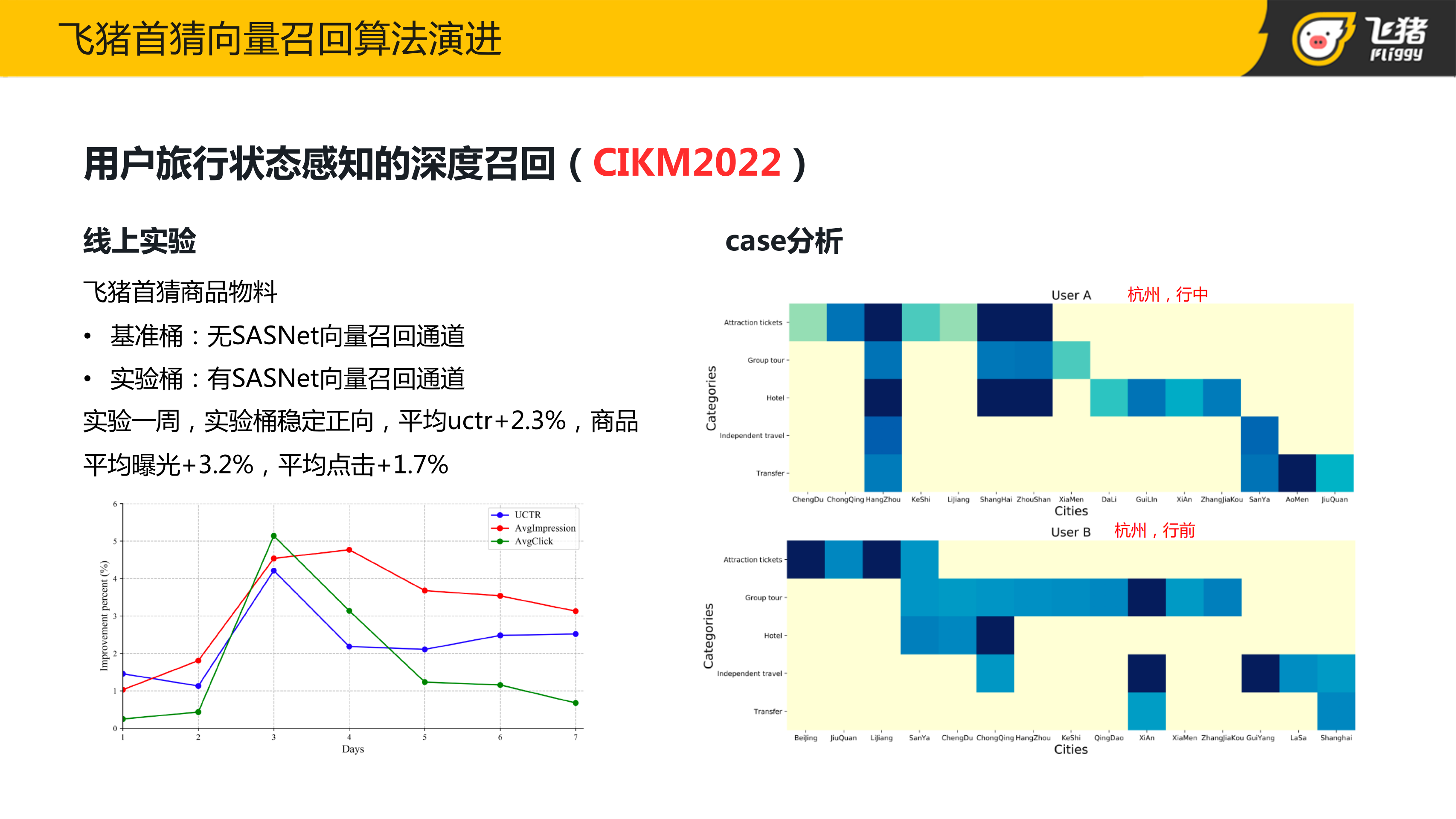
在飞猪数据集里,将用户的旅行生命周期的四个阶段当作用户的四种状态。在淘宝推荐数据集中,将点击收藏加购购买四种行为当作四种状态。在两个数据集上对比了一些基于序列表征的召回模型,我们提出的方法都取得了最好的效果。另外,我们也做了大量的消融实验,来验证每个模块的有效性,具体的实验细节可以去看论文。最后我们也在飞猪首猜的商品物料上上线了这版商品召回,在持续一周实验中点击率是稳定正向的。
右边是我们随机抽样的两个用户的向量召回的结果。上面用户是 LBS 在杭州,状态处于行中的用户,其向量召回结果主要集中在杭州以及杭州周边城市的一些商品;下面用户同样是 LBS 在杭州,但状态是行前,其向量召回结果在城市粒度上就会比较发散。说明用户旅行状态感知的深度召回模型,通过引入用户状态这一先验知识可以很好区分用户在不同状态下的不同行为偏好, 同时也说明我们提出的模型具有一定可解释性。