导读:本团队主要负责京东零售领域的风控算法模型构建,针对京东零售风控方面,业务要求不断地更新、模型失效快、更新迭代慢以及成本高昂等情况,我们提出了自己设计研发的 NLP 预训练架构模型和用户行为预训练模型,并进行预训练模型的平台化,方便一键部署开发,快速迭代,简单易用,推理速度提升等,有效解决了业务问题,并在公开数据集上也得到了很好的效果。
本文将对我们的一些工作进行介绍,并对未来京东零售风控的发展方向进行展望。主要包括以下几部分:
背景介绍
NLP 预训练
用户行为预训练
预训练平台化
展望
01 背景介绍
首先介绍一下京东零售风控的背景。
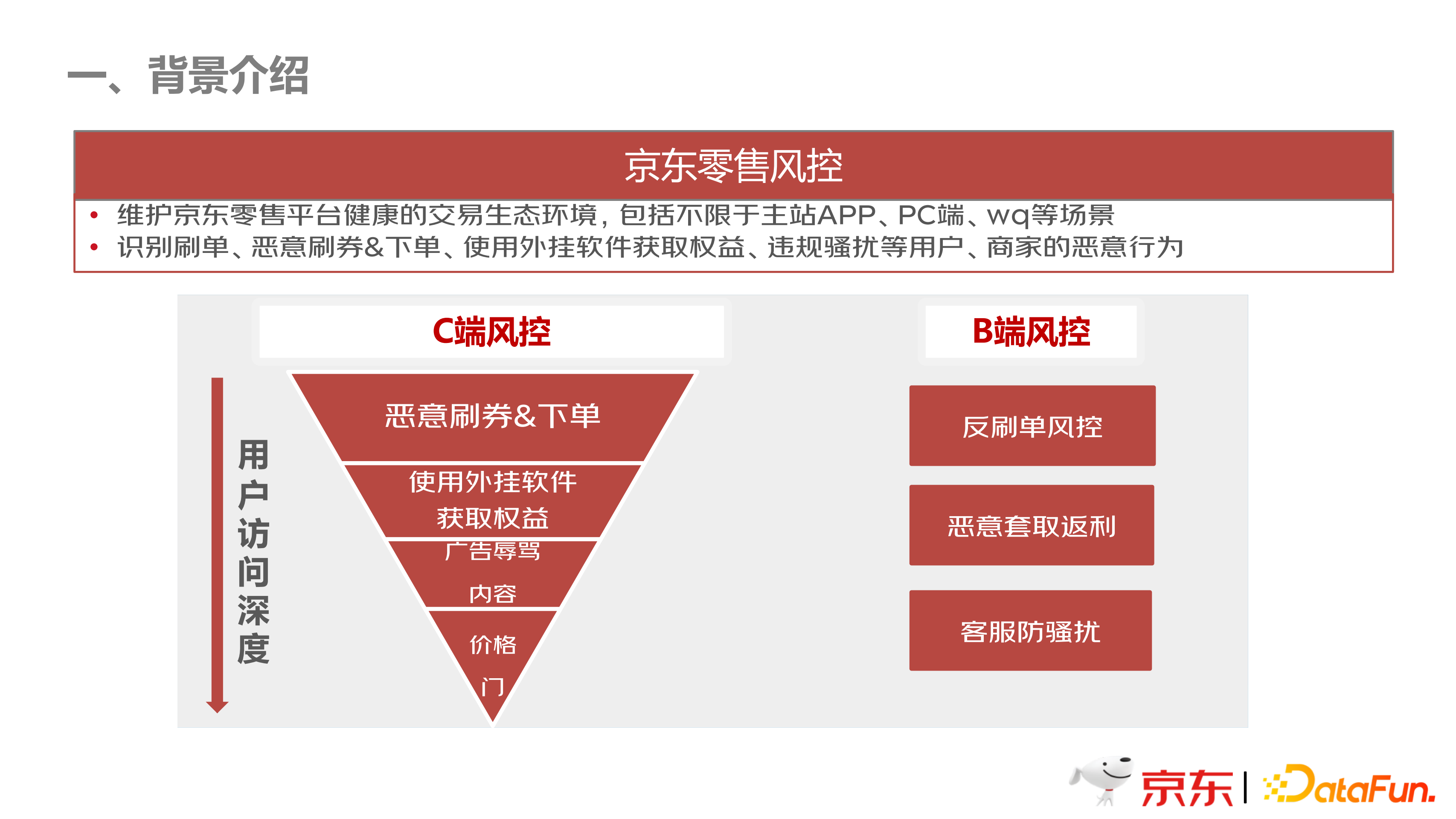
如上图所示,京东零售风控的任务是维护京东零售平台健康的交易生态环境,主要包括主站 APP、PC 端等。场景包括 C 端和 B 端两大部分。
C 端风控主要针对恶意刷券,使用外挂软件获取权益,比如用一些黑客软件抢茅台等,还有一些广告辱骂的内容,比如发小广告、不合规的内容等,以及价格方面的管控等。B 端风控主要是针对商家刷单行为、恶意套利行为,以及客服防骚扰。
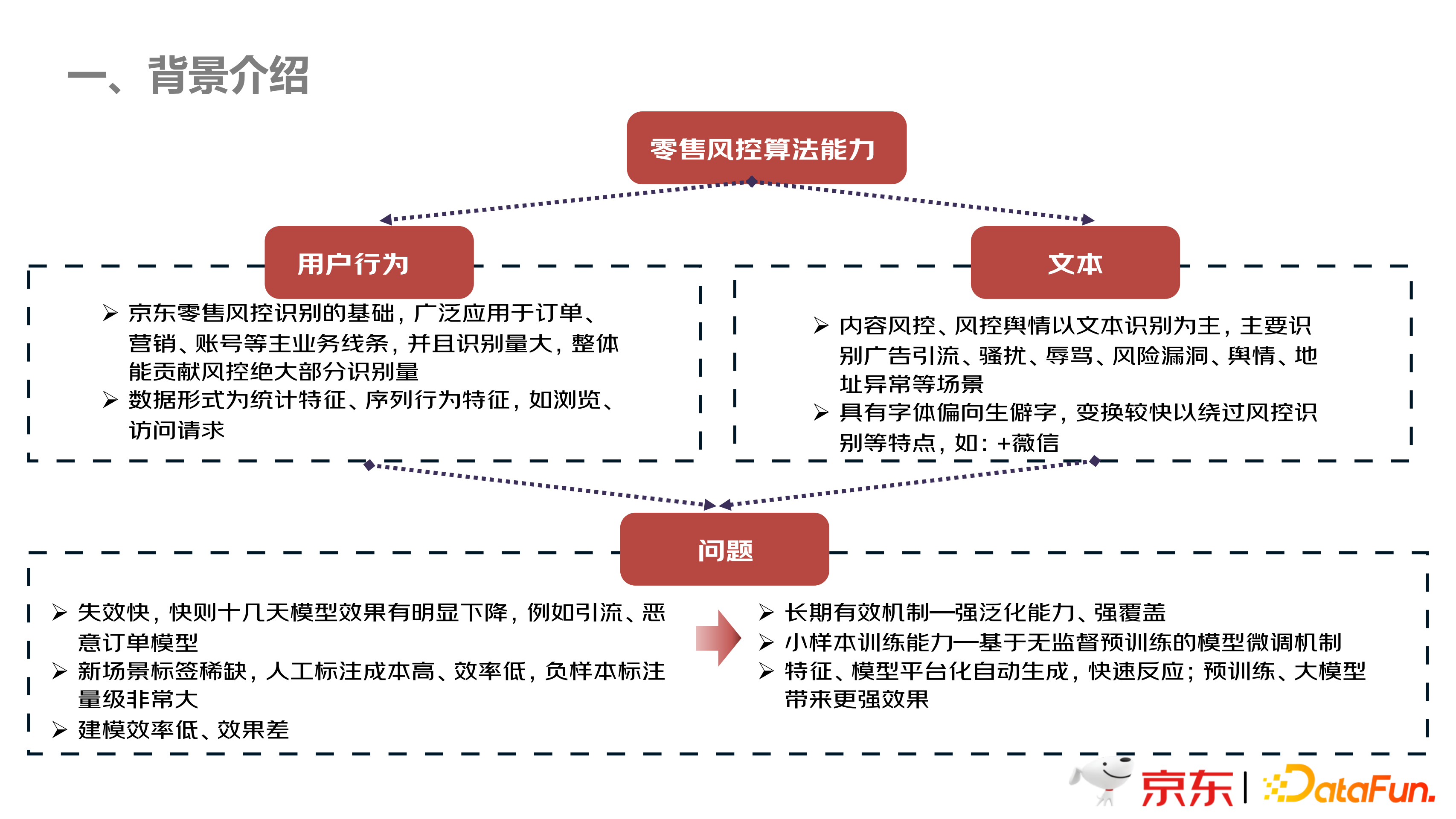
如上图所示,零售风控算法能力整体上分为用户行为和文本两大部分。用户行为这一块,通过上面提到的场景,算法人员可以将这些场景的数据构建成统计特征、序列行为特征,比如浏览页面等。文本这一块,主要是内容风控,包含舆情,地址异常等场景识别作为基础,以 NLP 的文本特征作为识别的基础。风控领域相对于其他领域的 NLP 场景,其主要的特点是异音异形字的识别,比如加微信,如上图中所示,通过一些异形字体,+薇信,躲避文本的风控检测。
以上两大场景,存在以下几个问题:
第一,失效快,比如广告引流场景,模型很快就会有效果衰减,具体原因就是恶意攻击者,会反复尝试不同的字体和形式,用以破解算法模型,从而达到自己的目的,导致模型失效或者效果下降。
第二,针对新的业务场景,需要大量的人工标注数据,人工标注的成本会非常高,而且耗时比较长。
第三,建模的效率低,效果差,因为首先要做特征,特征完之后,再预训练模型,整个链条拉得非常长,等到模型做好之后,业务方可能不需要这个模型了,或是效果不能达到预期,有的模型效果要求准确率达到接近 100%。
针对这三个问题,我们做了一些思考研究。针对失效快的问题,是否可以建立一个长期有效的机制来解决;针对需要人工标注大量数据这个问题,是否可以建立一个小样本学习能力的模型,不需要标注那么多的标签数据,使用无监督的方式进行训练;针对建模效率低、效果差等,是否可建立一个特征,模型平台化自动生成的机制,使预训练模型和大模型更好地发挥作用,快速建模和生成模型。
基于以上思考,我们依赖于预训练技术,做了一些改进优化。
02 NLP 预训练

如上图所示,NLP 是风控内容、舆情、地址等风控能力的基础,而且,近年来,预训练技术是处理 NLP 的最常用的方式。整体的流程如上图所示:首先数据采集,然后进行模型预训练,最后对模型进行微调。
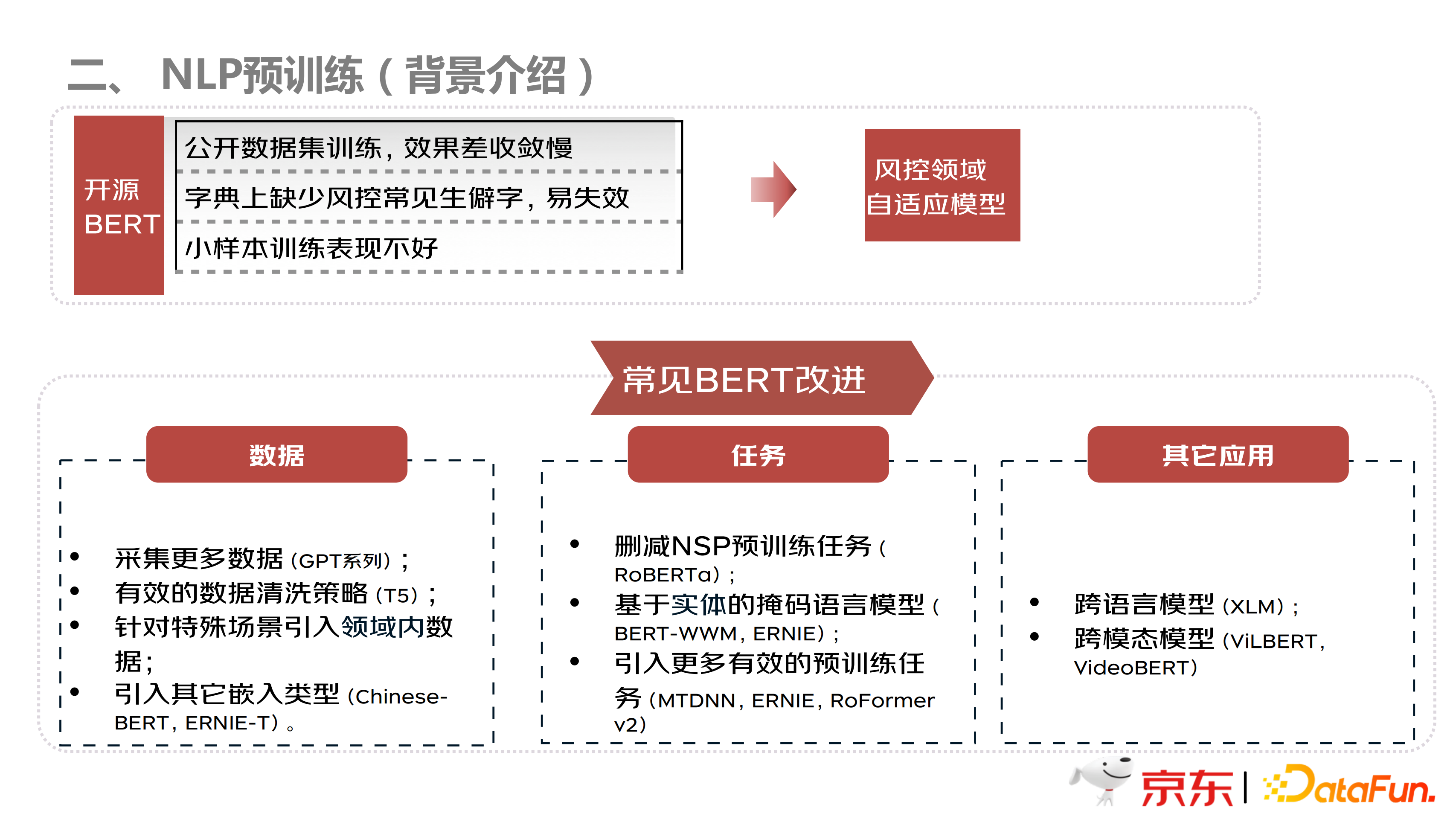
如上图所示,本团队也尝试在开源 Bert 上进行微调训练,发现效果很差,主要原因有三:第一,公开数据集覆盖的是普通文本,不是风控领域的数据,所以,收敛效果很差;第二,开源的数据集上没有生僻字等情况,导致训练出的模型容易失效,因为风控领域有很多的生僻字;第三,在小样本的训练集上效果不好。整体而言,就是数据偏差,即没有风控领域的数据进行训练,导致开源 bert 的效果无法发挥出来。
首先,常见的 bert 改进分为三个方面:
第一,数据方面,主要通过采用更多的数据集,或者有效数据的清洗策略;以及针对特殊领域引入领域内的数据,包括引入其他嵌入模型等,比如 Chinese-Bert,Ernie-T 等模型。
第二,改变训练任务,从而提高模型的泛化能力。主体上的改进方向有以下几种:删减 NSP 预训练任务,比如 Roberta;基于实体的掩码语言模型,比如 BERT-wwm 等;以及引入其他有效的预训练任务等,比如 ERNIE 等。
第三,其他的应用方向,比如一些跨语言模型,跨模态模型等。
结合以上问题,以及常用的 BERT 改进方向,本团队设计出一个适用于风控领域的自适应模型。
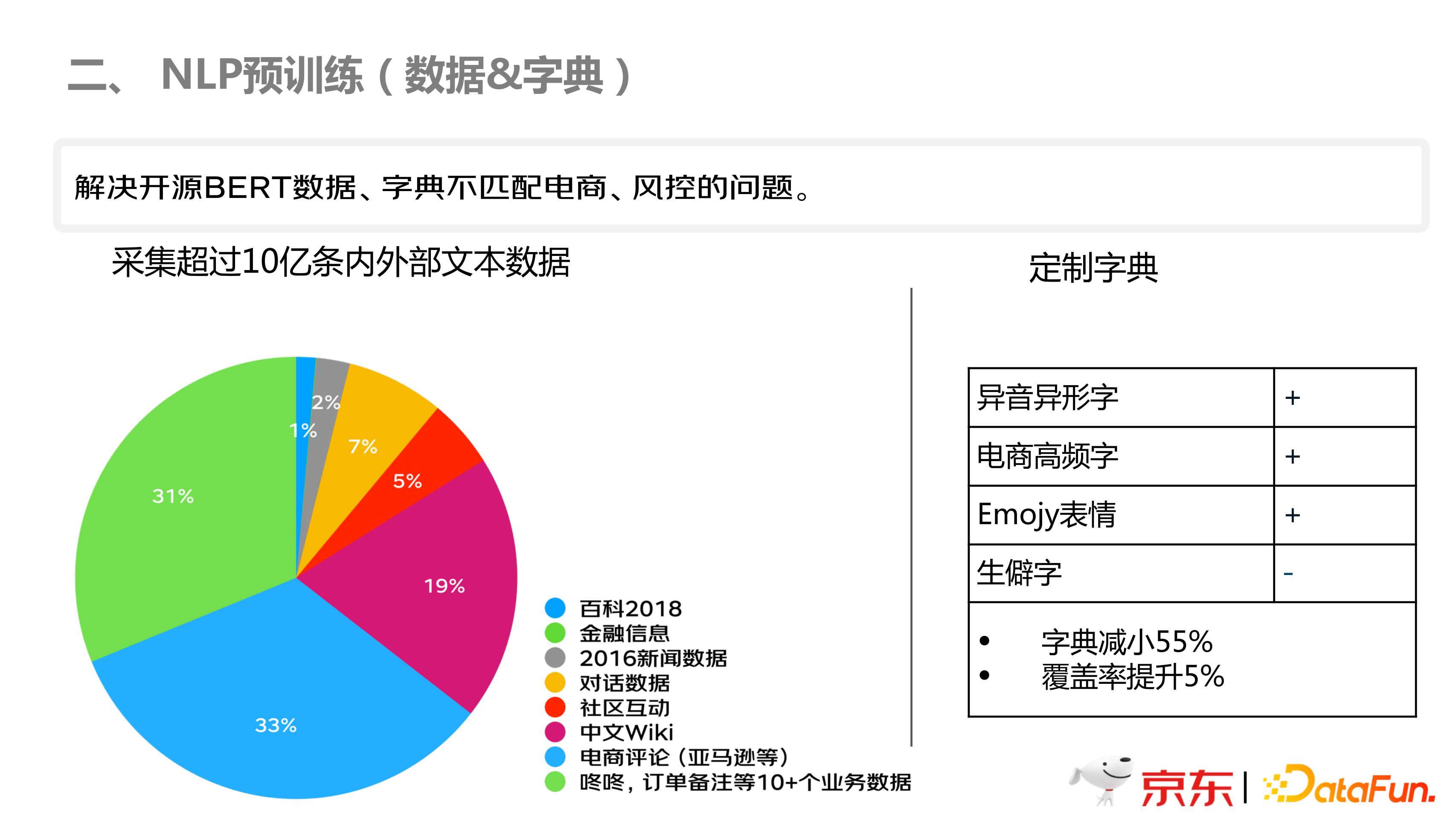
如上图所示,结合调研的情况,本团队在数据和字典这一块,做了风控领域的数据和字典。如上图左图所示,主要是零售领域的业务数据,以及电商领域的数据,为了具有泛化能力,需要社区互动、对话数据以及百度百科等的数据,总共采集了 10 亿条数据;在字典方面,如上图右图所示,增添了异音异形字、电商高频字、生僻字等。
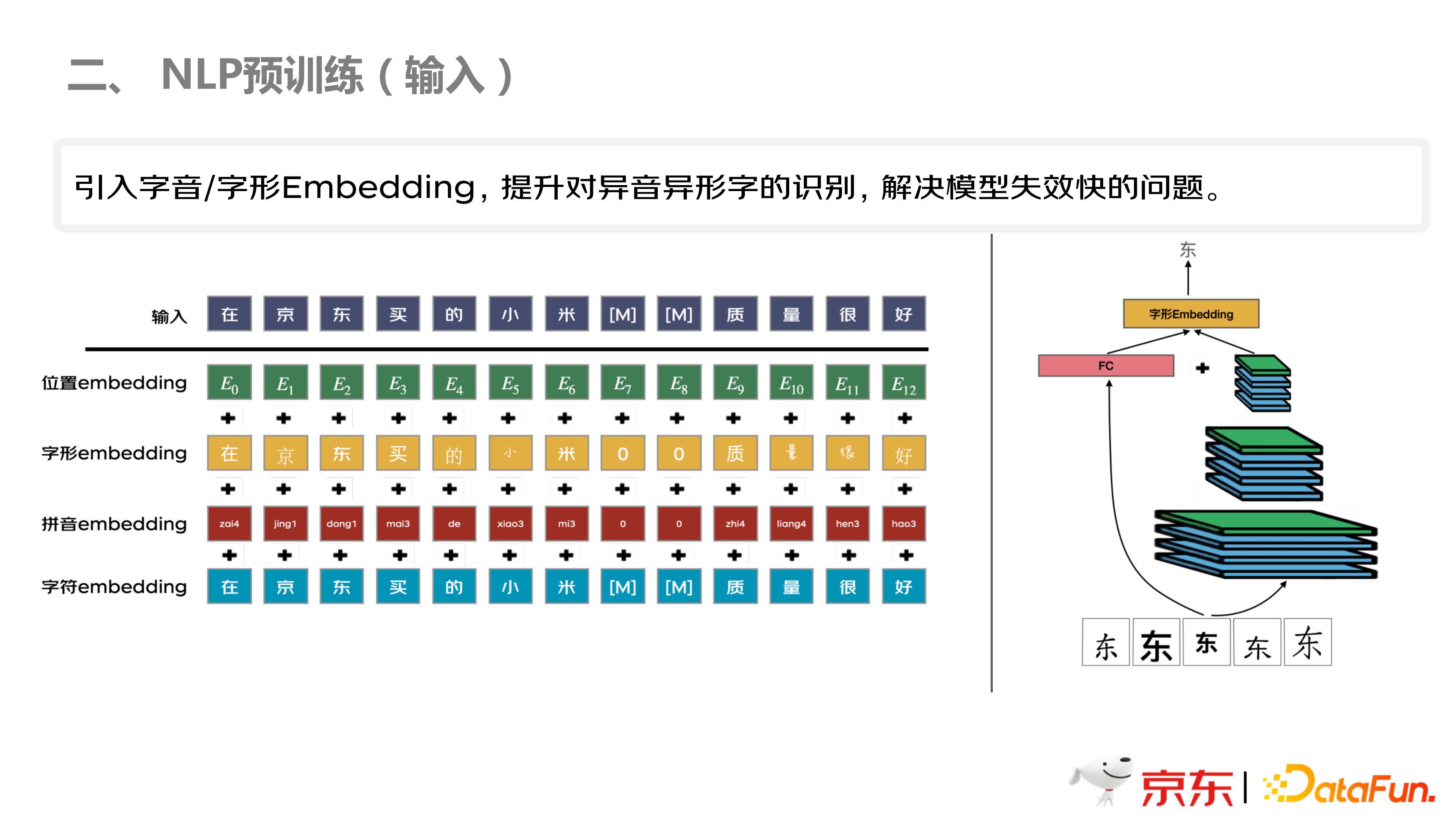
如上图所示,第一步将语料和字典构建好,但是,如果仅仅引入生僻字,还是不具备足够的泛化能力, 如果输入换了一批生僻字,还是不能很好的识别,本团队进行充分实验和调研,针对异音异形字,有很多情况是形不一样,但是音一样,比如“+”和“加”,是一个音,所以添加了拼音的编码。另一块就是字形,比如“京东”的“京”,再加一个单人旁,变成“倞”,和“京”很相似,所以也引入了字形的编码,从而提高对异音异形字的识别。

接下来,针对任务调度进行规划。引入任务调度,主要是为了解决不同的业务场景,比如评论、舆情、地址、咨询、直播等十几个场景效果不均衡的问题。如上图左图所示,是本团队调研的开源的解决方案。方案1主要是通过多任务的学习方式进行学习,所以,会导致不同任务的收敛程度不一致;方案2是通过持续学习,但是,但是,比如 task1 已经学习的非常好了,但因为后面的 task 并没有训练好,共享的BERT部分的参数还是会不断的调整,可能会破坏 task1 已经学到的特征;方案3是结合了方案1和方案2,有一定的优化,但是,task 的难易程度是人为定义的,具有很大的主观性,而且,也还是会存在 task1过度训练的情况。
针对前面几个方案的分析,本团队提出了上图右图的方案,构建内循环可持续学习任务调度方案。首先,针对不同的任务进行分组,然后在训练过程中,感知到不同的组的训练情况,比如某一个 task 的效果变差,即针对性的去训练这个组,从而提升模型的能力。

接下来,如上图所示,是本团队针对训练加速的方案设计。如果按照传统的训练方式,从头训练一个亿级的规模模型需要十几天的时间,如果是 T5 模型需要几十天,耗时过长。本团队基于京东自己的架构,并对数据和模型进行改进。首先,使用 ZeRO 的框架,可以在不影响通信效率的情况下,让模型的内存均匀的分配到每个 GPU 上,减少单个 GPU 的显存个,提高并行效率。其次,在操作融合方面,通过将多个操作进行融合,一次执行多个计算逻辑,减少全局内存的访问,有效的提高训练吞吐。最后,基于多源头数据读取能力,充分发挥 A100 显卡潜能。

推理加速方面,因为模型部署主要是实时场景,对时延要求比较高,所以需要对模型进行蒸馏,提高推理速度。基本上使用业界的主流方式,将模型参数压缩 90%,推理速度提升 3 倍,效果接近于原始预训练模型。
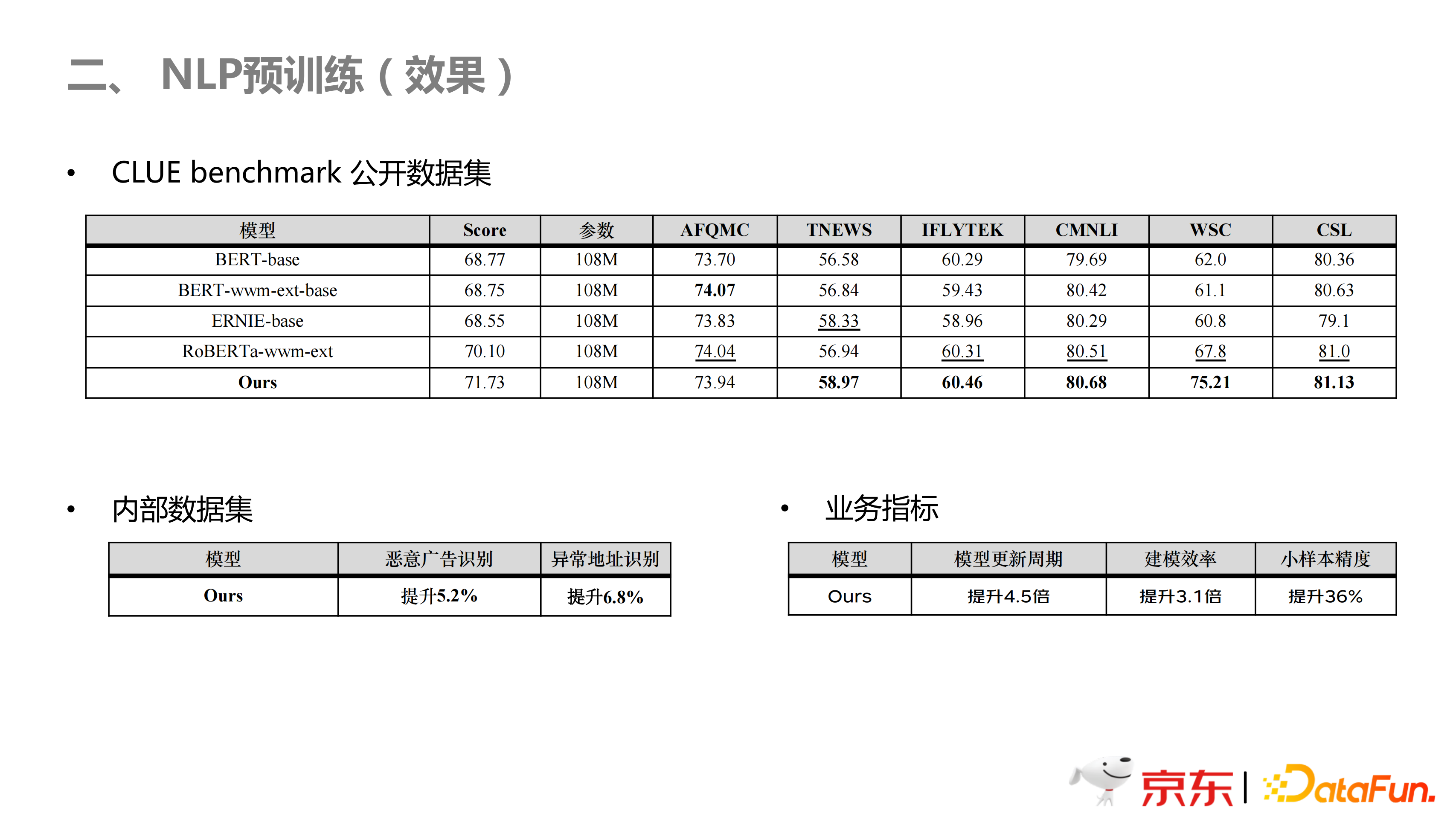
上图是本团队预训练模型的效果展示。因为使用了开源数据集的缘故,所以具有泛化性,在开源的 6 个数据集上,基本上都达到了最好的效果。在内部数据集上,广告识别,以及异常地址识别,有非常明显的提升。在业务指标上,模型更新以及建模速度有了非常大的提升,并且小样本训练的效果有了非常大的提升。
03 用户行为预训练
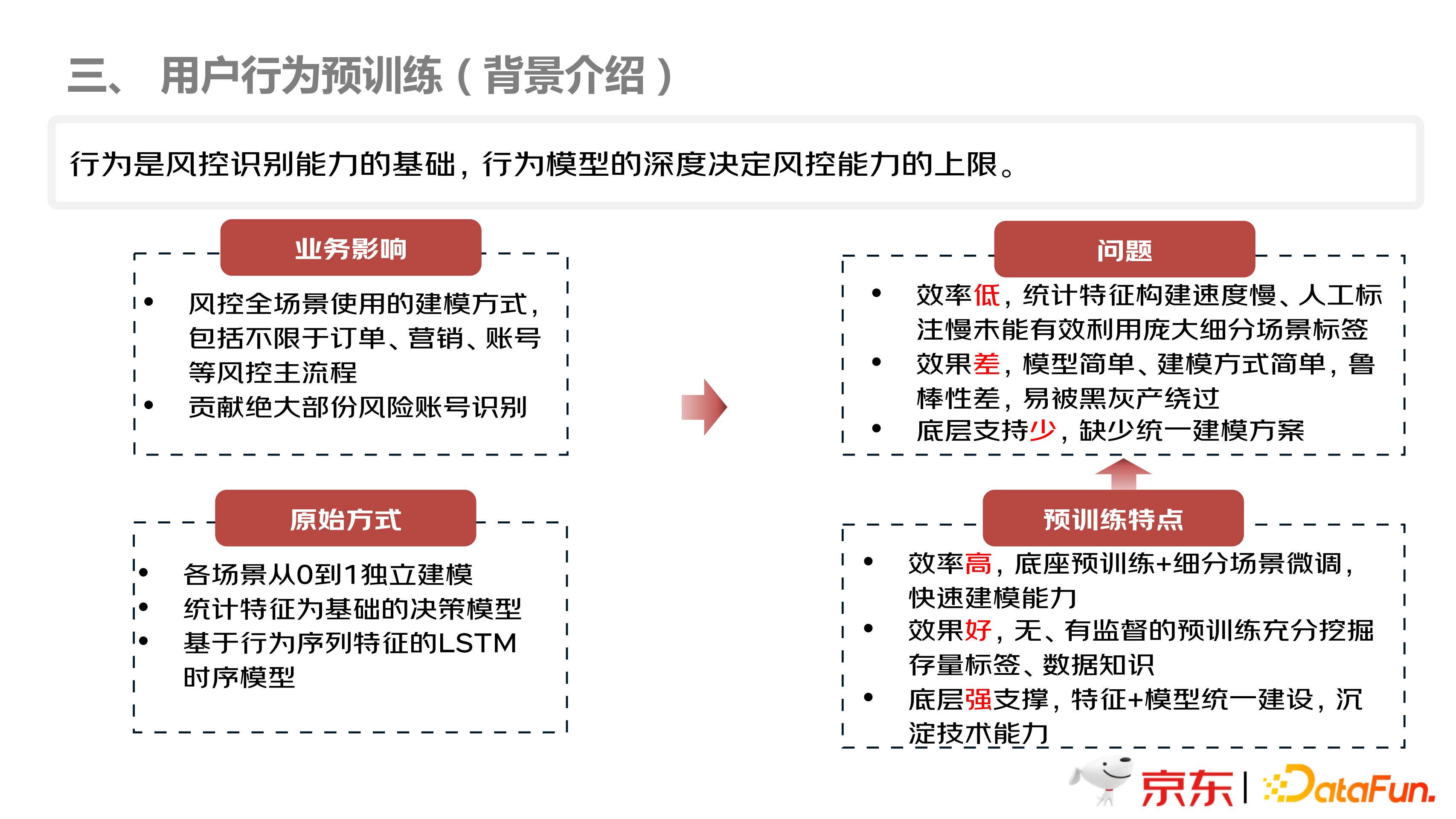
接下来介绍用户行为预训练。前面讲到,用户行为是风控能力识别能力的基础,行为模型的深度决定了风控能力的上限。预训练模型使用以前,不同的业务场景,会各自建设一个风控的模型,存在重复性的劳动,而且特征选择不尽相同,各个场景都是从 0 到 1 独立的建模。该方式存在的问题:
第一,效率低,统计特征构建速度慢、人工浇筑慢,未能有效利用庞大细分场景标签;
第二,效果差,模型简单、建模方式简单,鲁棒性差等;
第三,底层支持少,缺少统一建模方案。
预训练模型的特点,可以克服以上几个问题,毕竟预训练是站在巨人的肩膀上,底座模型加细分场景微调,可以快速建模;并且效果好,有监督、无监督预训练可以充分挖掘存量标签、数据知识等;由于特征和模型统一建设,底层具有强支撑。

预训练模型主要应用于 NLP 领域和 CV 领域,其他的领域方面,还处于起步阶段。在业界,谷歌和腾讯等有行为预训练在推荐和画像等场景有应用,但是行为预训练在风控领域处于空白状态。风控领域的用户行为特征,主要还是浏览、搜索等序列特征,以及大量手动设计的统计特征。

上图展示了用户行为预训练模型的整体算法模型。首先,将用户的行为、类别等多模态信息进行融合,通过 Transfermer 将其转化成统一的行为特征,输入到 bert 中进行预训练。总的参数量达到了 5 亿多,表达能力远超 Bert 模型。未来使用预训练模型达到业务目的,本团队也应用了很多对比学习的方法,比如 NSP、MLM、有监督等方法,放到内循环的学习系统里面,使模型充分地学习到数据的知识。下一个阶段,是进行微调。当微调的样本不是很多,由于参数量很大,为了防止微调调偏,需要定制化的操作,比如冻结部分参数等,使模型具有更好的泛化性能。
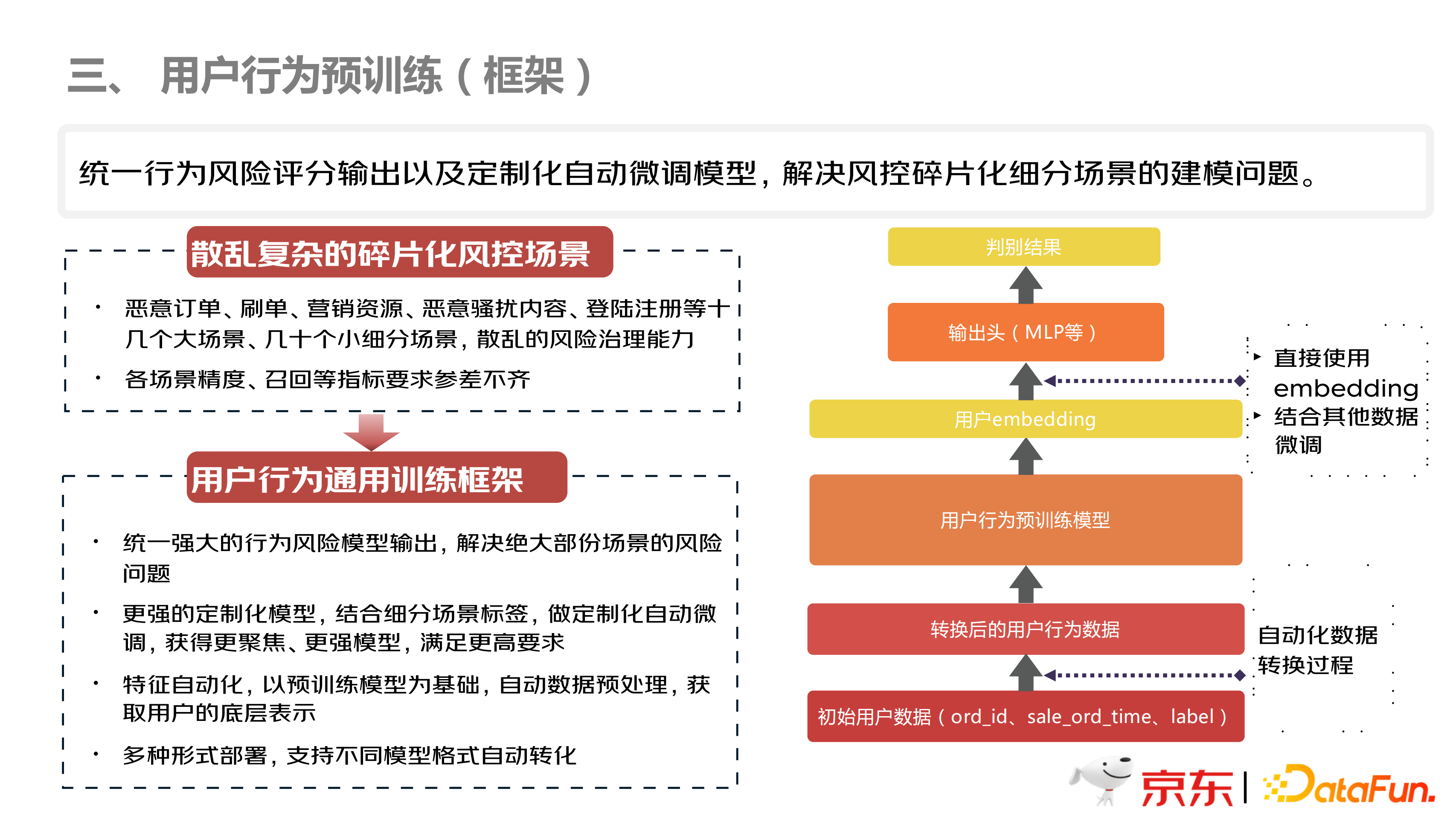
上图是整个用户行为预训练的框架。风控的场景有很多,比如恶意订单、刷单等,异常的散乱复杂,而且碎片化,每个场景的准确度、召回率等要求不尽相同,所以需要考虑框架的适用性和泛化性。如上图右边所示,在自动化数据转换过程中,直接将用户的数据封装起来,不同场景的输入,作为参数,输入到数据中,然后输出转换后的行为数据。并且将预训练模型训练过程也进行封装,主要是对微调阶段进行训练处理。在微调阶段,根据自定义模式,对模型进行微调,这样不管业务是几十个,甚至几百个场景,底层的训练是保持不变的,微调阶段可以部署到不同的业务场景。
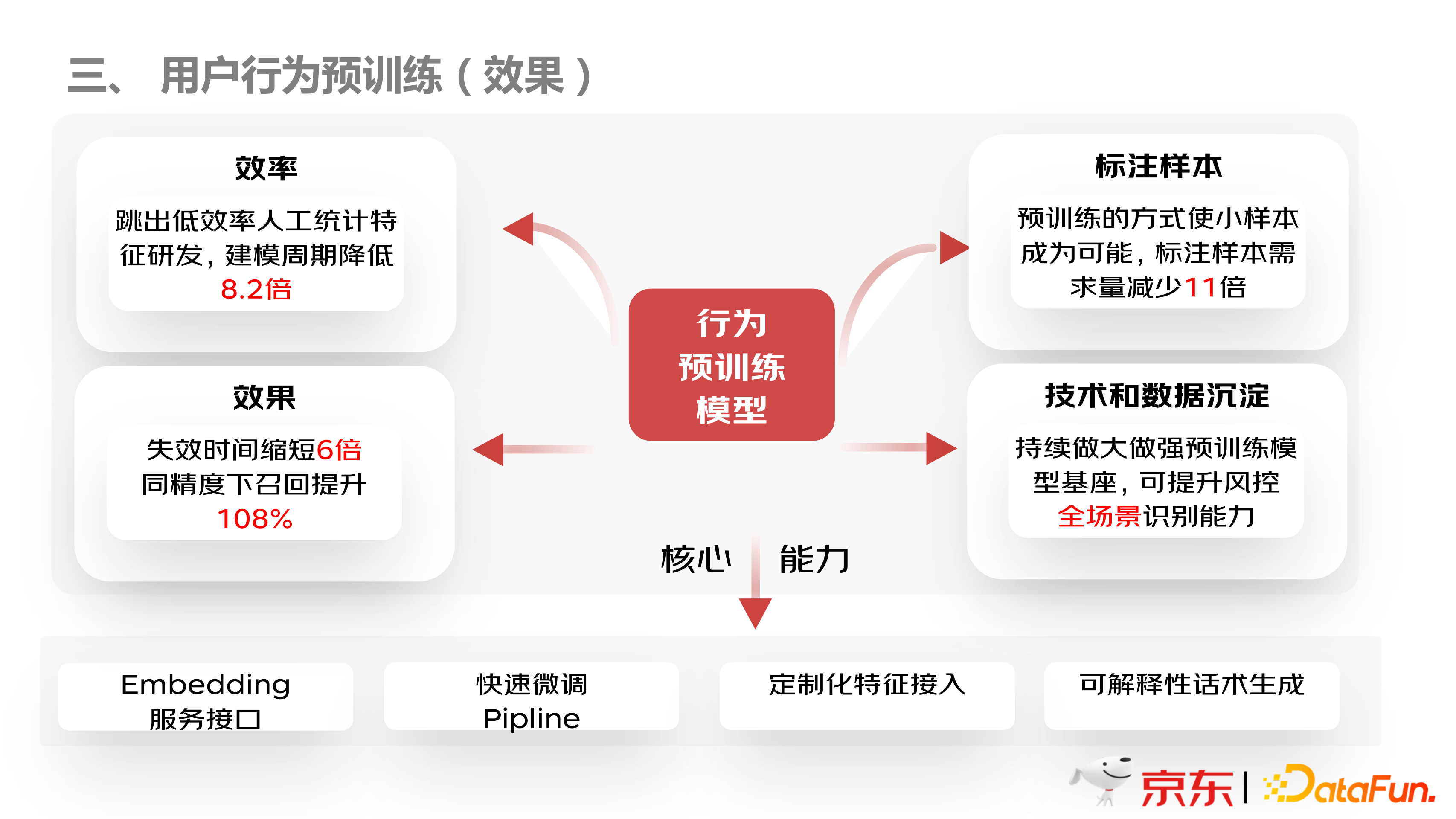
用户行为预训练模型的效果如上图所示。首先在效率方面,建模效率大大提升,周期降低 8 倍以上;其次,在效果上,模型效果长期稳定,鲁棒性非常强,而且在同等精度下,召回率提高一倍以上;在标注样本方面,支持小样本标注数据;在技术和数据沉淀方面,持续做大做强预训练模型,提升风控全场景识别能力。
04 预训练平台化
预训练平台化的目的,是为了解决之前存在的问题:之前的模型框架的使用,只存在于代码阶段,存在阅读代码费时间、费人力,并且接口混乱,杂乱无章等问题。搭建平台之后,支持一键式使用,方便高效。
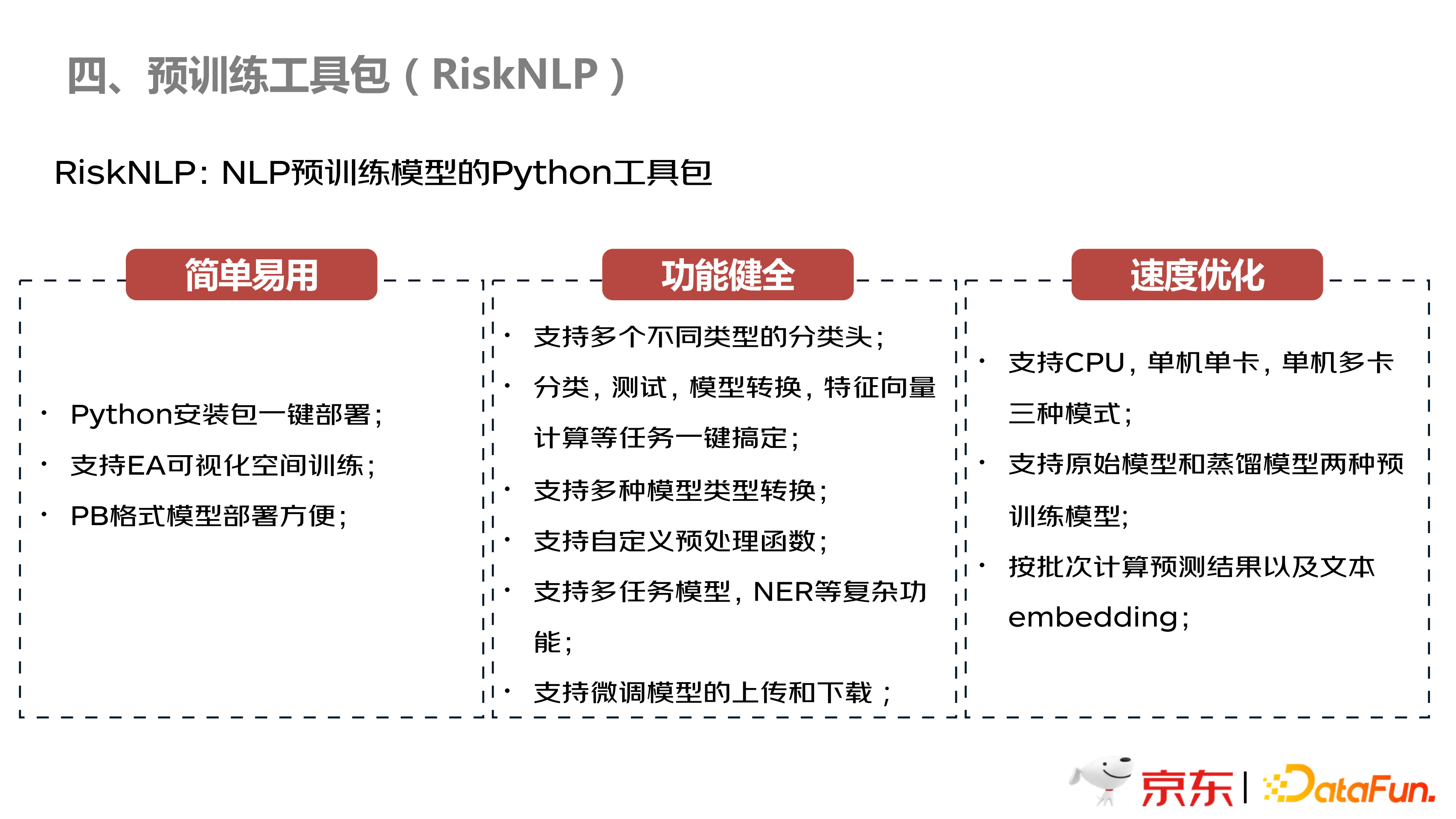
如上图所示,本团队将 NLP 这块的内容封装到 RiskNLP 包中,非常简单易用,而且功能十分健全,比如支持多种模型类型转化,多任务模型,NER 等复杂的功能,都可以一键式训练出来;并且训练速度,推理速度等,都可以一键式的配置,非常方便。

上图是本团队提出的 RiskCDA 工具包,主要是提高异音异形字的对抗能力。这个工具包,既支持 Python 安装包一键部署,还支持本地线上扩充方式,并且支持自定义词典,最重要的是支持多种基于深度学习的前沿扩充方式,比如 TextFooler 等。

最后,如上图,是用户行为预训练模型的工具包——RiskBehavior 包。一键部署使用,与前面包所不同的地方就是这边的特征展出,也是部署成为服务的形式,针对内部需要的特征,都可以进行产出。并且在速度优化方面,也得到了很好地实现。
05 展望

对于未来的展望,主要分为以下几个方面:
第一,预训练模型不能只停留在 NLP 和 CV 领域,可以在更多的领域,比如风控,多模态等特征,容纳更多的数据知识,赋能业务。
第二,更强大的模型,包括更大的参数、更强结构模型以及蒸馏能力等。
第三,更强大的易用能力,更加快速便捷地应用到业务。
第四,拥抱开源,将框架,以及数据和模型脱敏之后进行开源。

