玖章算术CEO叶正盛:程序员必须掌握的数据库原理
本文根据叶正盛在【第十三届中国数据库技术大会(DTCC2022)】线上演讲内容整理而成。

本期分享嘉宾

叶正盛
玖章算术科技公司CEO
【嘉宾介绍】原阿里云资深技术与产品专家,数据库产品管理与解决方案部总经理。20年软件研发经验,曾主导过多个工业控制软件、ERP、大型电力计费系统研发,见证与实践了阿里巴巴去IOE、异地多活、云计算多次技术变革。
演讲内容:
合理的设计数据架构是程序员的核心竞争力,也是普通程序员走向技术专家的必修课。数据库一直是计算机核心基础软件,经历了40年的发展,从关系型数据库,到数据仓库、NoSQL、大数据以及云原生数据库,体系越来越复杂。
本次主题重点介绍应用软件到底层数据库全链路的核心原理,希望帮助广大序员更好的理解并使用好数据库。

数据库简介

数据库管理系统(DBMS)是管理数据库的大型软件,可以建立、使用和维护数据库,其提供了数据采集、存储、查询和分析的功能。
在没有数据库之前,如果我们要做库存管理,以小超市、夫妻店为例,我们可以用手工记账,但随着数据越来越多,我们可以用Excel管理,如果是大型超市或大型库存中心,Excel就不能应对了,需要使用数据库来管理。那么,数据库和Excel有什么区别呢?
第一,管理的数据量不同,Excel可以管理上万条数据,而数据库可以轻松管理数亿条数据;
第二,多用户,高性能,Excel一般是个人操作,数据库系统需要处理互联网平台上可能是数亿用户同时请求;
第三,安全管理的不同,Excel只能设置密码保护,数据库支持用户的复杂权限控制;
第四,开发接口不同,Excel开发接口比较多,但基本是应用在内置单机开发,数据库有面向应用软件的开发接口,适合大型应用软件或者互联网平台业务。
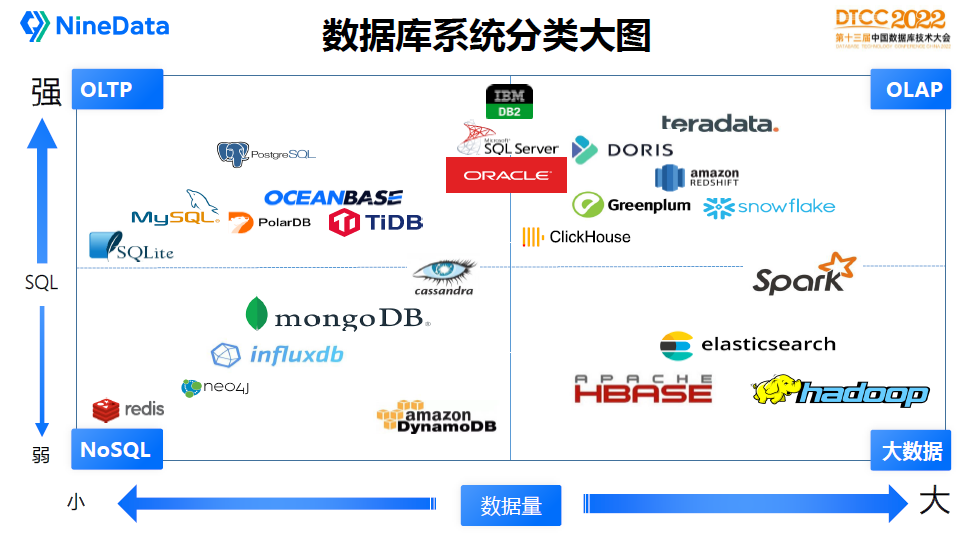
主流的数据库有几十种,这张图描述了当前数据库主流产品定位,通过管理数据量大小和SQL功能强弱把各个产品分为四大类:
OLTP:在线事务处理平台,一般都是关系型数据库来支撑,常见的数据库有:SQLite、MySQL、PostgreSQL、PolarDB、TiDB、OceanBase
OLAP:在线分析业务,一般是数据仓库,常见的产品有:Teradata、Clickhouse、Doris、Greenplum、Snowflake、AWS Redshift
NoSQL:新数据模型,互联网行业用得非常多,代表产品有:Redis、Neo4j、InfluxDB、MongoDB、Cassandra、AWS DynamoDB
BigData:大数据业务,和数据仓库比较类似,但是更擅长处理大规模数据分析业务,主流产品有:HBase、Hadoop、ElasticSearch、Spark
另外DB2、SQLServer、Oracle这几款产品在OLTP和OLAP领域都比较强,有时称为HTAP产品,也是目前数据库的领导者。
不是说管理的数据量越大和SQL功能越强就越好,每一种数据库它是在特定的场景能够展开它的优势,这里只是把它划分在不同的区域。
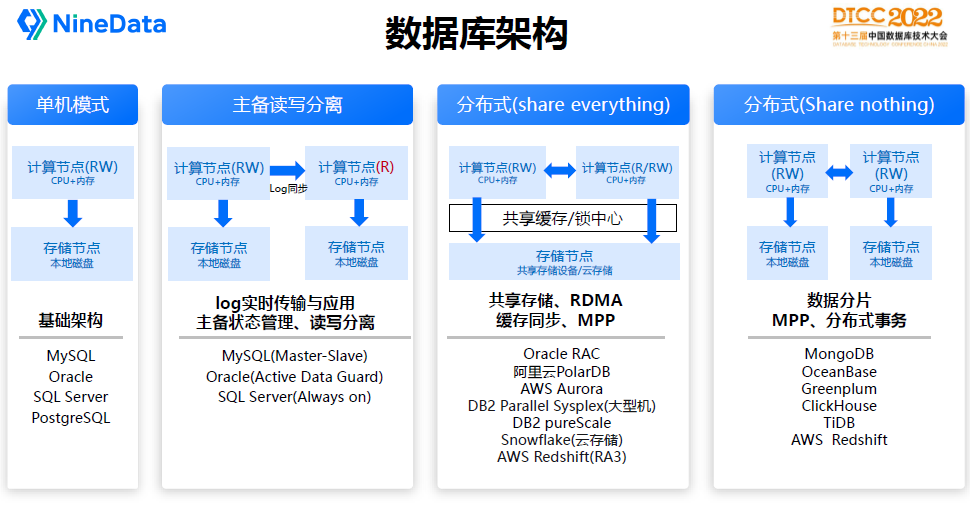
根据数据库计算节点和存储节点部署整体架构分为几大种类:
单机:计算节点和存储节点一般在同一台机器上,通常存储节点是本地硬盘,如单机版的MySQL、Oracle。单机模式没有高可用保障,常用于临时开发测试或者个人学习场景,生产环境不建议使用。
主备读写分离:在单机模式上增加了备用节点,备用节点既可以作为高可用保障,也可以承担只读业务请求,主备之间通过数据库的log实时传输实现。比较常见的有MySQL的Master-Slave,Oracle的Active Dataguard,SQL Server的Always on,主备模式也是当前生产环境最常见的部署架构。
随着数据量或者负载的增加,主备模式已经无法满足业务需求,因此诞生了分布式的软件架构,数据仓库和大数据产品通常都是分布式架构,主要由两种模式:
分布式(Share everything):Share everything架构通常存储节点采用分布式的共享存储,比如专业的EMC存储设备或者是云存储OSS/S3。因为数据共享问题解决了,计算节点就能扩展多个,从而承担更多业务负载。典型代表有Oracle RAC、阿里云PolarDB、Snowflake、AWS Redshift(RA3)。IBM DB2也是典型的分布式架构,它同时还采用了集中式共享缓存的模式。
分布式(Share nothing):在没有共享存储的情况下,通常会采用Share Nothing的架构设计。这类架构是存储数据分片存储在不同的节点,因此计算和存储节点都是独立运行,通过MPP计算引擎实现集群资源的调度运算。
数据库内部结构
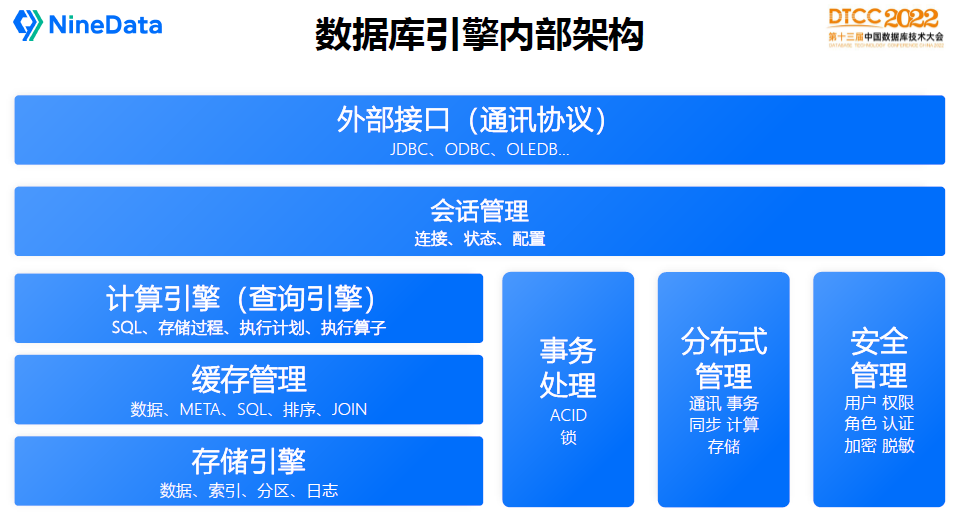
数据库引擎主要包括以下组件:
存储引擎:负责数据的存储管理,包括数据、索引、日志等数据的管理;
缓存管理:负责数据库的缓存管理,包括数据缓存、SQL缓存、会话缓存、运算缓存等等;
计算引擎:也称为查询引擎,负责业务请求的逻辑运算,包括SQL解析、执行计划生成、执行算子下发到存储引擎等等;
事务处理:负责数据库的事务管理,ACID、锁等特性的实现;
分布式管理:分布式数据库的核心组件,用于协调数据库各个节点通讯、事务状态一致性协调、分布式计算等等;
安全管理:数据库的安全访问基础,包括基本的用户、角色认证,加密解密,以及高级的数据脱敏特性;
会话管理:数据库连接和连接池状态、配置等管理;
外部接口:负责对外提供标准的数据库访问接口,支持应用软件通过JDBC、ODBC、Socket等方式访问数据库。
每种数据库都有自己的实现方案和技术架构,但通常都会包括以上组件功能。

存储引擎最基础的是HEAP结构,这也是表数据文件通常的保存格式。
常见的数据库,像Oracle,SQL Server,MySQL(ISAM),PostgreSQL表的基础结构都是堆表引擎。可以理解为一条记录过来,就把它按先后顺序堆进去。数据库由多个文件构成,一个文件由多个Extent/Segment构成,每个Extent包含多个Block/Page,OLTP通常在4K~32K大小,Block里面就是具体的行数据信息。
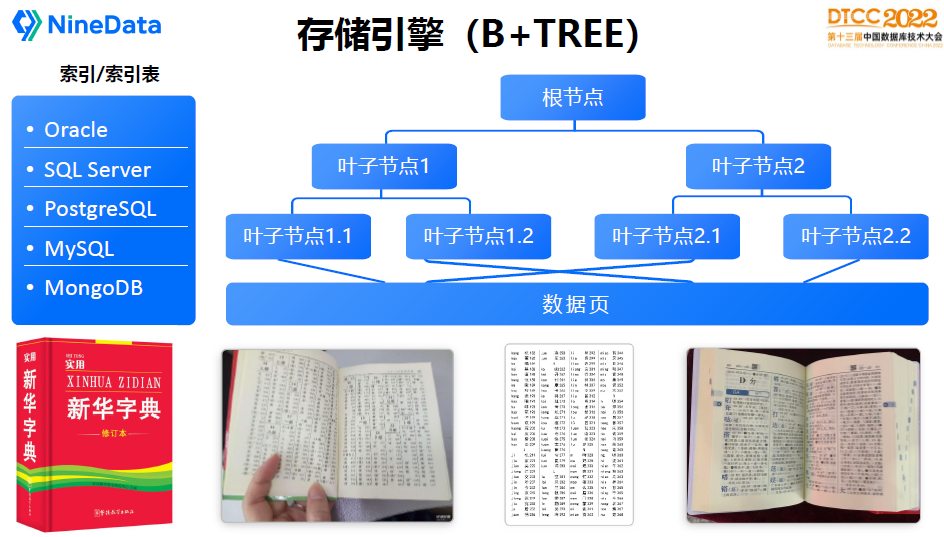
B-TREE是数据库索引最常用的数据结构,MySQL(InnoDB)的表数据也直接采用了B-TREE的存储结构。
B-TREE的核心特点是对数据排序,可以从根节点到叶子节点再定位到数据,叶子节点可以有多层,就像一棵树的树枝一样。
我最喜欢的例子还是用新华字典来形容,大家小时候经常查字典,其实就是B树的原理,要查一个字,首先要找索引,如果知道它的拼音,根据拼音索引里面的位置去找到页码,再找到数据,查询效率还是非常高的。
字典可能有很多种目录索引,常见的有拼音、部首、笔划,这样就可以按不同的方式快速找到要需要的字。数据库B-TREE原理跟查字典基本上是一样的,很多文章介绍不等于、大于、小于等条件能不能使用上索引,其实想想这个逻辑,用字典目录能不能查,就能大概判断出来能不能做,原理是完全一样的,没有什么特别之处。

HEAP和BTREE通常是OLTP数据库使用,而OLAP通常数据量非常大,COLUMN-STORE(列存)是更常见的存储结构,因为按列存储数据可以做到更好的编码压缩,并且当SQL只是需要请求大宽表的部分字段时,COLUMN-STORE就非常有优势。
开源的ORC和PARQUET是列式存储的典型模型,都比较常见。Greenplum、ClickHouse等数据仓库都支持列式存储。
在我们生活中也有这样的例子,比如说大超市的货架,通常都是按品类摆放的,电器、水果、零食都是放在不同的位置,这就是一种列式分类管理的概率,查询效率也比较高,也可以摆放更多的货物。

再谈谈LSM-TREE,上面是阿里内部X-DB的技术架构图,很好的描述LSM-TREE模型。业务往里面写数据时,先写日志,同时放在内存里面,内存积累到一定的数据,就排好序往底下磁盘刷盘,按同样的逻辑一层一层刷盘,这是典型的分层存储的概念。
它在写方面非常强,尤其是顺序写,像日志这种数据比较适合。它的缺点是读性能比B树差,尤其是按范围读取数据。大量的传统OLTP商业数据库依然用B树去做,因为实践下来综合读写会更高效。LSM-Tree在日志存储场景比较合适,如Hbase,另外我们也会看到一些分布式数据库存储用LSM结构,如TiDB、OceanBase,这个还有待验证。LSM-Tree在面向传统硬盘上有顺序写入优势,对SSD写磨损也更友好,但在SSD硬盘上的整体性能提升收益没有传统硬盘突出,因为SSD的随机IO性能也不错。
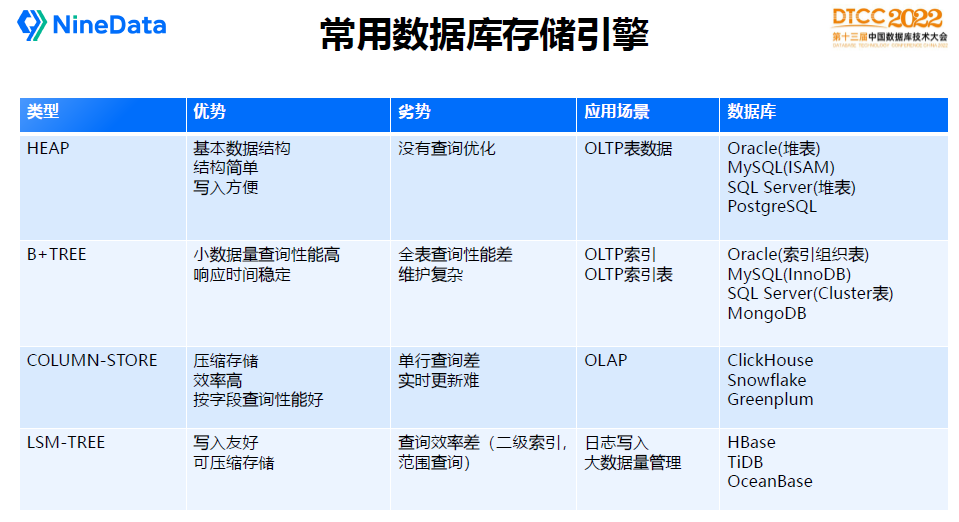
用一个表格汇总各种存储引擎的优劣势和应用场景。

数据库缓存分为几大板块,第一是数据缓存,一般来说是全局性的,所有的会话都在统一的数据缓存里读取和写入数据。框的大小代表着占用内存的大小,比如数据块,这是占用最多的,其次是索引块,另外是日志,比如REDO LOG。
也有一些开发者会问,这个缓存为什么数据库单独去管理?用操作系统不行吗?如果说不深度理解这个问题,确实操作系统缓存也做得很好,有些数据库确实没有缓存,但是我们看到非常强大的数据库都有自己的缓存管理模块,比如Oracle、SQLServer等等。
数据库自己做缓存管理可以做得非常精细,比如说有全表扫描和按索引扫描,如果不做精细化的缓存,有可能一个大表的查询就把以前有效的缓存都给清出去了,对于数据库来讲是不能接受的,所以需要自己做管理,因为可以判断这个缓存的重要性。Oracle,MySQL(InnoDB)这方面都做了很多细的工作,这是操作系统不一定能解决好的问题。
当然也会存在一定问题,数据库有缓存,操作系统还有缓存,会不会导致缓存重复使用,效率不高?因此有些数据库就把操作系统的缓存给旁路了,操作系统会提供DirectIO这样的接口。
图中右上角是SQL与对象的缓存,有两个比较重要的,一个是SQL的文本和执行计划,第二是元数据,比如说表结构定义信息。SQL文本和执行计划缓存比较大,尤其像Oracle这些成熟的商业数据库,因为需要支持非常复杂的SQL最优执行计划制定,所以缓存管理就更加重要。反而开源的数据库执行计划缓存会做得非常弱,比如MySQL,可以说是几乎没有。如果有执行计划缓存,像Oracle这种数据库,效率是完全不一样的,每次执行,效率有可能会有10倍以上的提升。
然后是会话缓存,这块比较好理解。还有是运算缓存,在数仓里非常重要,OLTP系统,一般数据缓存很重要,OLAP运算缓存会更重要,主要原因是OLAP系统的Hash与排序运算量比较大。

数据库事务处理的核心是ACID:
Atomicity:原子性,表示数据库一个事务操作要么成功,要么失败,不能出现部分成功或者部分失败的情况。通常采用WAL(Write Ahead Log)来实现,同时利用了硬件的原子写接口。
Consistency:一致性,表示数据库要能保证定义的约束有效性,包括定义的主键、唯一约束、外键、NOT NULL等约束,在每个事务提交后都要确保约束有效。在事务过程中没有强制约束,因此不同数据库对约束的实现会有些区别,比如插入唯一约束重复的数据是立即失败,还是等事务commit再检查唯一约束?
Isolation:隔离性,这个是事务最复杂的地方,国际标准定义了4种事务隔离级别。对于OLTP系统,大部分都采用了Read Committed的隔离级别,唯独MySQL(InnoDB)默认采用了Repeatable Read的隔离级别,这个也是由于历史原因,MySQL的主备同步使用了Statement模式导致的。现在MySQL基本都是采用ROW格式的Binlog格式,所以建议改为Read Committed隔离级别更好,也能减少Repeatable Read带来的各种锁和死锁问题。我在第一次使用MySQL就踩了一个坑,当时使用Create table as select备份一张线上表,然后表就被锁定了,导致业务故障,这个也是非常坑的地方。阿里巴巴集团内部和阿里云RDS也默认把事务隔离级别改为了Read Committed,系统也更加稳定。
Durability:持久性,意思是事务提交后,数据库一定要确保生效,即使操作系统重启或者是服务器掉电。数据库通常也是使用WAL加硬件的持久性来实现,这里需要保证commit后刷盘立即写入,不能临时缓存在内存中,否则服务器掉电就丢失数据。
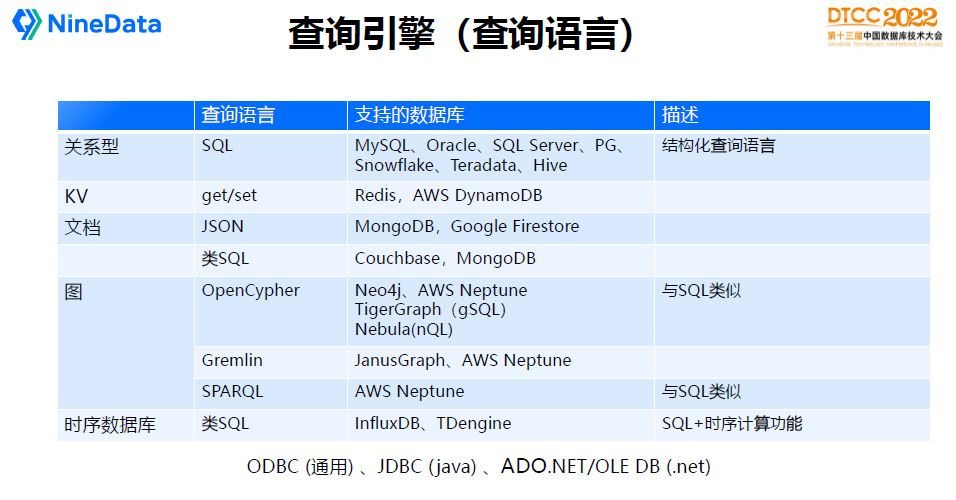
查询引擎是数据库最复杂的模块,核心是处理业务请求逻辑,如SQL怎么解析、执行,可以称为数据库的大脑。
每种数据库使用的查询语言不太一样。关系型数据库通常使用SQL语言,KV数据库一般使用get/set语义,文档数据库一般是用JSON模型表达,图数据库比较复杂,有OpenCypher、Gremiln、SPARQL等。时序数据库,也大部分是类SQL的模型,它在SQL的基础上增加了一些时序计算窗口类的表达模型。
数据库设计与SQL优化

SQL是数据库最常用的语言,也是数据库的核心资源开销,因此SQL优化是程序员的必备技能。
SQL优化通常分3个阶段,我们常称为SQL优化三板斧,这三板斧下去,90%的问题都可以解决。
第一是先找到问题SQL,有两种情况,如果是现在系统有问题,我们可以去看活跃的连接在干什么,把正在运行的SQL取出来。每种数据库通常都提供了查询当前活跃会话的接口,比如MySQL使用show processlist,Oracle可以查询v$session视图信息。如果说问题已经过去了,没有现场,可以通过Slow Log,或者TOP SQL,找到问题,这个需要数据库开启历史SQL记录功能。
第二是分析问题SQL,最主要先看SQL的执行计划,再去看整个数据库的IO访问量是不是符合预期,缓冲命中率怎么样,如果不是99%以上,可能都有问题,有些程序员看到内存都用完了,其实也不是什么问题,比如有10G的内存,如果你的数据量超过10GB,那内存很快都会用满,关键要看缓存命中率。另外是网络IO,多集群的话,需要关注网络传输的延迟和带宽容量。如果有锁,要分析SQL锁的模型。CPU重点要看一下排序、函数计算等操作。
最后是解决问题,就是优化SQL,可以修改SQL提升性能,如果没有索引就要增加索引,如果缓存命中率有问题就要调整内存配置。数据整理也是比较常见的,有些数据库历史数据非常多,影响了效率,要考虑怎么把历史数据归档,提升数据访问效率。
再有是提升硬件性能,最后是分布式改造,分布式改造比较困难,如果前面几个步骤能解决最好,实在不行再去考虑比较复杂的分布式改造。
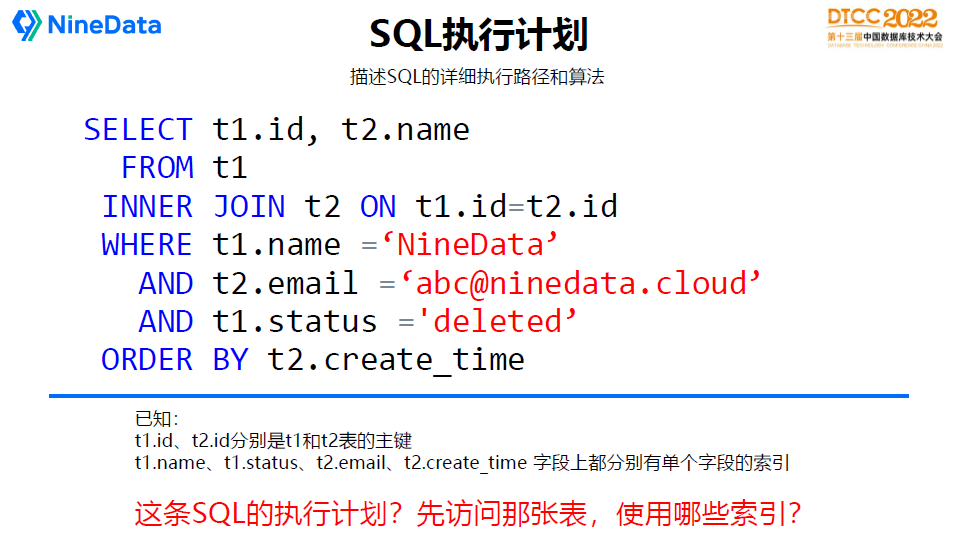
接下来重点讲一下执行计划。有些初级程序员往往忽视这个问题,SQL执行计划是描述SQL详细执行路径和算法。
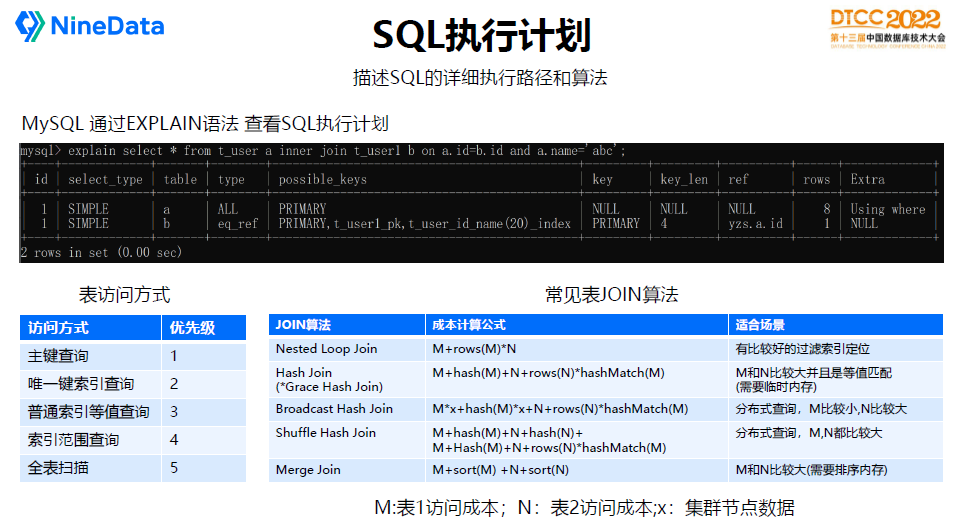
数据库通常支持使用EXPLAIN语法来查看SQL的执行计划,会展示出SQL具体的执行路径和算法,包括访问表的顺序,每张表使用索引访问还是全表扫描,每次执行预计返回的行数等等,信息会比较详细。
SQL访问单表主要有几种方式,包括:
主键:示例SQL:select * from t where id=?
唯一索引:select * from t where uk=?
普通索引:select * from t where name=?
索引范围扫描:select * from t where create_time>?
全表扫描:select * from t
对于多表连接,通常有以下几种JOIN算法:
Nested loop join:适合两张表有非常好的索引访问路径,如:select * from t1 inner join t2 where t1.id=t2.id and t1.id=?
Hash Join:适合两张表都没有好的索引,需要全表扫描,并且是等值关联查询,如:select * from t1 inner join t2 where t1.id=t2.id
Hash Join需要把一张表加载到内存后,另外一张表再通过Hash匹配到对应的记录,所以会需要临时内存,当临时内存不够时会产生临时磁盘转储的开销。为了解决Hash Join在分布式场景的问题,也诞生了Shuffle Hash Join和Broadcast Hash Join算法。
Merge Join:适合两张表都没有好的索引,需要全表扫描,支持非等值关联查询,关联字段最好是有排序,因为Merge Join算法是需要把两边数据排序再Merge 。

数据库如何生成SQL执行计划,如何选择最优的执行路径,通常是内部有个优化器的组件来完成。优化器类型有RBO和CBO两种。
RBO:Rule Base Optimizer,意思是基于规则的优化器逻辑,早期数据库都是采用RBO,实现比较简单,但很依靠程序员对数据库的逻辑理解,在SQL非常复杂的情况下很容易走到糟糕的执行计划。
CBO:Cost Base Optimizer,意思是基于成本的逻辑,优化器会计算各种不同的路径成本,最后选择一条最优的路径来执行。
举个例子,我们通常的交通方案有飞机、火车、汽车、轮船、步行,每种方案的速度都不同。如果我们要从杭州去北京,那么该选择那种交通方式?
对于RBO来说,它总是会选择飞机,不管是否发生交通管制,以及去机场的交通是否顺畅。
对于CBO来说,它会评估从出发点到杭州机场/火车站,北京火车站/机场到目的地的交通时间,综合评估一个最短时间的交通方案。
CBO是目前数据库主流的优化器模型,实现难度也更大,需要收集很多统计信息,如每张表的存储空间大小和记录数,字段的区分度等等,在数据经常变化时需要保证统计信息的准确性。
RBO和CBO通常都是在生成执行计划后就不能再修改,即使执行过程中发现严重偏差也不会改变,因此后来有些数据库在CBO的基础上实现了更智能的Adaptive的逻辑,意思是在执行过程中,如果发现有更优路径,那优化器可以调整执行计划。就好像本来选择坐飞机从杭州去北京,但是到了机场,发现航班大量延误,起飞时间完全不确定,这个时候可以调整计划,选择做火车出发。
开源数据库的优化器相对比较弱,商业数据库更领先。国内在这块技术相比国际落后很多。

接下来讲一下数据库的设计,基础知识是要掌握范式,在教科书里面非常多,这里不多讲 。反范式我觉得是比较有意思,尤其是表设计里面,有非常多的反范式的案例。比如说标记组合是比较常见的,如果有多个标记状态位,可能会用bit的数据类型去存储,这其实就已经违反了第一范式,因为第一范式要求字段的内容要原子性,不能拆分。实际上数据库内核里面,它用了很多bit类型这种反范式来设计元数据,从而提升存储和查询效率。
另外一个是日常习惯字段,拿身份证号码来举例,也是违反了第一范式,因为身份证号码已经包括所在的地区、出生年月、登记顺序以及校验码这4个信息。但是我们实际的表结构设计,还是会把身份证号码当做一个字段,不会说把身份证号码拆成4个字段,否则阅读习惯会不太方便。
还有计算列,典型的违反了第三范式,如商品的金额=单价*数量,订单总金额,我们一般都会冗余去存储。
数仓里面就更多的反范式的案例,历史数据快照,会把相关的信息都保存下来,也是违反范式,但我们基本都这么干。
拆表也是一种常见设计,比如说一张表里面有常用和不常用的字段,如有个字段是大字段,我们就会把它拆成另外一张表。
这些其实都是比较常见的反范式设计的场景。所以部分场景下我们不用去特别纠结一定要遵循范式,如果说你觉得合理,业务逻辑实现可控,适当的冗余数据其实也没什么问题。

关于主键选择,比较推荐两种,一种是自增字段,比较适合内部系统的表,如果说是对外的互联网应用需要注意,有被猜测攻击的隐患。我们公司比较喜欢用雪花模型,根据时间序列加上顺序号产生主键,性能比较好,比较安全,实现相对复杂,需要应用程序产生。

接下来介绍几个常见的数据模型:
首先是平台型互联网数据模型,像淘宝、微信公众号、美团、BOSS直聘、滴滴等等,他们的数据模型都比较类似,主要包括以下对象。
会员信息:买家(淘宝、美团)、乘客(滴滴)、读者(公众号)、求职人(BOSS直聘)。
服务提供者信息:卖家(淘宝、美团)、博主(公众号)、司机(滴滴)、主播(抖音)、公司(BOSS直聘)
服务内容信息:商品、文章、微博、用车、视频、职位
库存信息:电商的概念
互联网平台根据以上几张表信息,通过搜索、推荐等各种匹配算法,最后产生订单信息,接着是付款信息、物流/配送信息,最后是服务反馈信息。
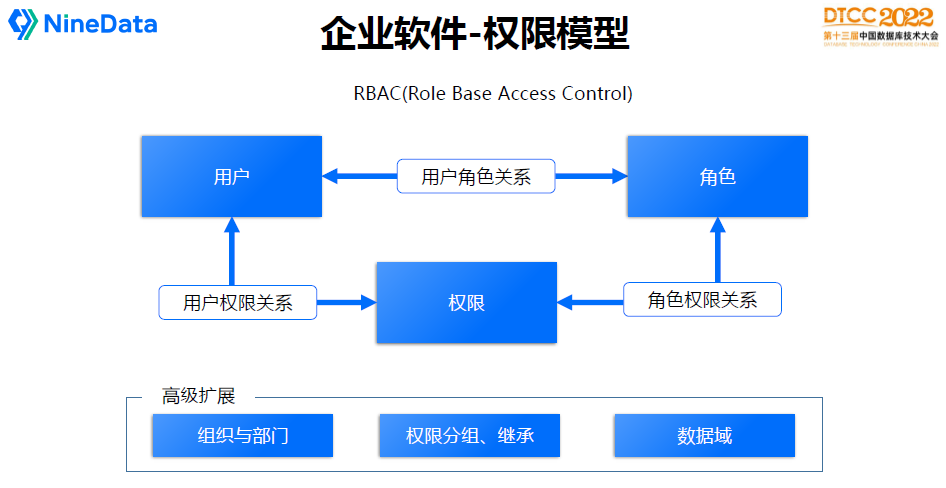
刚才是互联网的模型,企业软件不太一样,企业软件讲究两个东西,一个是安全,一个是流程规范。
安全核心是权限模型设计,比较标准的是RBAC(Role Base Access Control),我们可以参考这套模型演进。核心是理解用户、权限、角色三个重要的对象。按照RBAC设计问题不会太大,有可能会有扩展的东西。比如面向公司的用户,会有组织和部门的关系。权限会扩展出权限分组,角色会有继承等。另外一个是数据域权限,同样的权限与角色,但是能访问的是不同范围的数据,就会有数据域等高级定义。
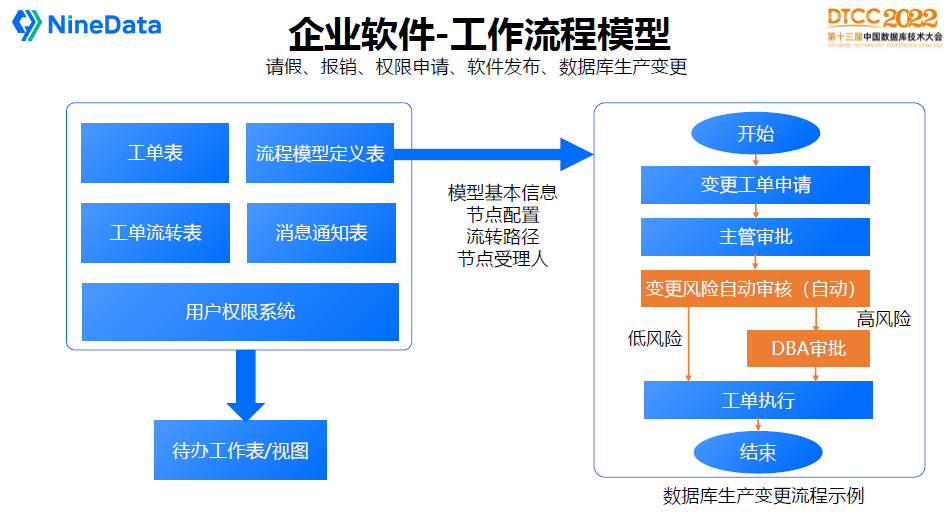
我们再看企业软件里比较常见的流程规范,最常见的是工作流引擎。
首先有工单表,不管是请假、权限申请还是生产变更,都有一个工单来存储你做什么事情。
然后是流程模型定义表,例如数据库产生变更的流程,现在做生产发布,变更表结构,要提交变更申请,主管要审批,如果高风险还需要DBA的审批,这就是一个业务流程模型。
流程模型会包括基本定义信息,有哪几个节点,流转路径,根据什么条件流转,哪些人受理等等。
针对每个工单的流程处理,都有工单流转表,消息通知表,再加上用户权限系统,这样就可以形成工作流的待办工作表,基本上就是这么一个套路,大家理解这个概念,在企业级软件里就可以如鱼得水了,不会那么纠结。
数据传输和安全管理
前面是数据库架构和 SQL优化板块,最后一个板块我要讲一下数据传输和安全管理,这个也是我们开发者其实经常会遇到的问题。

数据传输是一个统称,包括数据迁移、数据同步、数据分发等,也称为数据复制。
比较常见的几个场景:数据库上云、更换数据库、数据同步到备库、异地数据多活、数据ETL等等。
通常包括结构迁移、全量数据复制、增量数据复制几个核心模块,为了保障数据复制的正确性,还需要数据对比模块。这里面最难的增量数据复制模块,市场上很多产品会采用按日期增量抽取简化处理,只能做到定时复制,要做到实时数据复制需要使用CDC技术,要精通数据库的内部原理,适配各种主流数据库产品和版本,技术难度和工程难度都是非常有挑战。
我在这个领域做了10年,从早期的去IOE、异地多活到发布阿里云DTS,里面有非常多的问题,尤其是在生产环境下,源端经常会有各种DDL变更的情况很容易链路中断或者数据错乱。目前市场上推荐的三款代表产品:
阿里云DTS:功能完备,与阿里云集成度很好
NineData(重点推荐):玖章算术公司研发的SaaS产品(www.ninedata.cloud),支持阿里云、华为云、腾讯云、AWS等多个云平台,技术指标上更领先,易用性也更好,免安装使用
Canal:阿里开源的产品,影响力很大,不算是完整的产品,一般需要二次开发。

数据安全管理,太重要了,我把这个单独列出来讲。
先说软硬件的故障,比如服务器,磁盘肯定会坏,过保机器坏的可能性更高了,所以一定要做好灾备工作。再有是机房也有可能发生灾难,业界每个月都会有机房出问题,像火灾,地震,或者是断电、光缆断了等,都是机房故障。另外是软件Bug,一般是指数据库本身的软件Bug,成熟的数据库Oracle、MySQL每次发布都会说修复了几十个Bug,普通数据库的bug可能更多。
如果用云平台会好一些,比人工管理更安全,云很注重服务器的故障检测,及时升级数据库最新的安全补丁,大型云厂商都有专业的团队去做这个事情。
第二大类是人为故障,比如黑客入侵会造成数据泄露或者勒索,黑客通常会利用软件里面SQL注入,只要有注入的风险,黑客是全网扫描的,一旦扫到就进来了。
还有是密码泄露,如果是弱密码就肯定能被黑客发现,只是等黑客啥时间要搞你。另外是如果有系统漏洞,黑客一般来说提前就知道了,会去看能不能攻破你。今天还有一点非常重要,就是内部数据泄露,还有删库跑路。在今天员工和公司对立的情况下,还是时常发生的,尤其是和主管关系不好,迟早都会发生删库跑路的事情,管数据库的员工还是要比较慎重。
最后是数据误操作,比如说做软件的升级发布,不小心写错了,我做DBA的时候就碰到过非常多,每个月都会碰到程序员将提交的SQL给搞错了,需要恢复数据,这些都是人为的问题。数据备份是一定要做的,如果没有备份一定是不踏实的,总会发生问题。
如果是非常重要的数据,要考虑异地容灾。如果是敏感的数据,要考虑数据加密,包括数据传输的加密。
另外一点,流程规范非常重要,尤其是对生产系统的数据操作,最好有系统来支撑,靠人监督是没有用的。一定要通过平台来管控,不要把数据库账号密码放出去,包括只读权限的账号密码,这些都是系统隐患,说不准哪天你家公司的敏感数据就在网上被黑客贩卖…

最后,希望让每个人用好数据和云,这个也是我们玖章算术公司的使命。NineData是我们研发的产品,希望可以帮助你解决相关的问题,欢迎访问www.ninedata.cloud,它提供了企业级的SQL开发流程管理,数据复制、数据备份、数据对比等功能。

