一、实时数仓
当前,企业对于数据实时性的需求越来越迫切,因此需要实时数仓来满足这些需求。传统的离线数仓的数据时效性通常为 T+1,并且调度频率以天为单位,无法支持实时场景的数据需求。即使将调度频率设置为每小时,也仅能解决部分时效性要求较低的场景,对于时效性要求较高的场景仍然无法优雅地支撑。因此,实时数据使用的问题必须得到有效解决。实时数仓主要用于解决传统数仓数据时效性较低的问题,通常会用于实时的 OLAP 分析、实时数据看板、业务指标实时监控等场景。
二、实时数仓架构介绍
2.1 Lambda架构
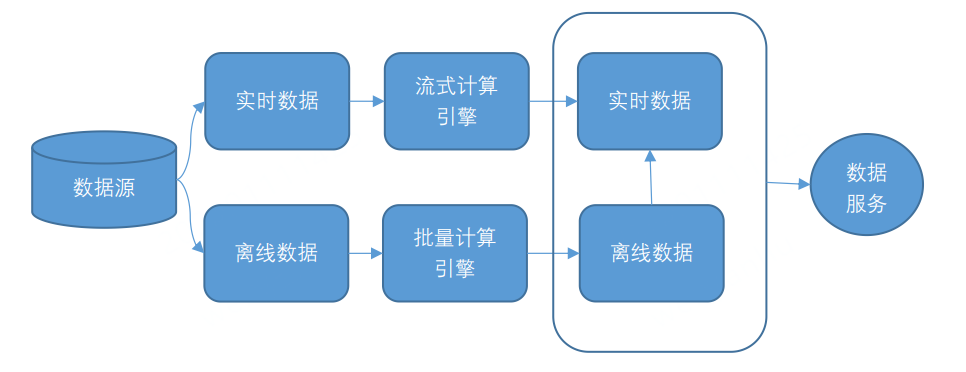
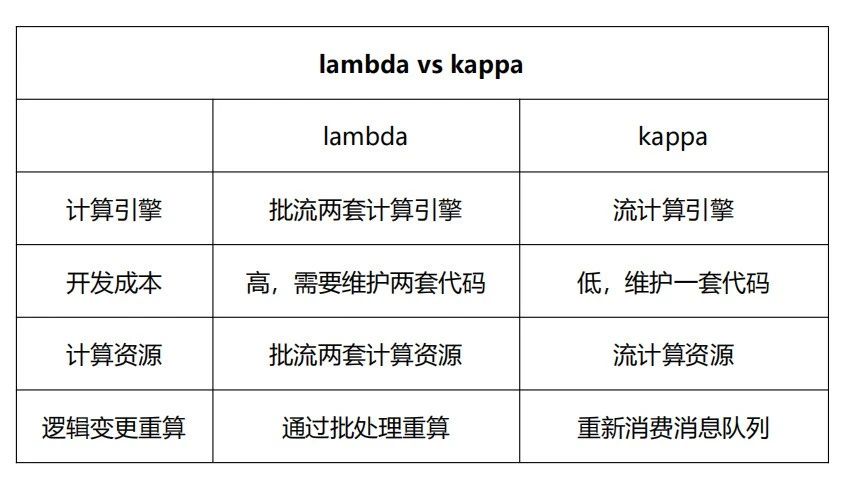
Lambda 架构将数据分为实时数据和离线数据,并分别使用流式计算引擎(例如 Storm、Flink 或者 SparkStreaming)和批量计算引擎(例如 Hive、Spark)对数据进行计算。然后,将计算结果存储在不同的存储引擎上,并对外提供数据服务。
2.2 Kappa架构
Kappa 架构将所有数据源的数据转换为流式数据,并将计算统一到流式计算引擎上。相比 Lambda 架构,Kappa 架构省去了离线数据流程,使得流程变得更加简单。Kappa 架构之所以流行,主要是因为 Kafka 不仅可以作为消息队列使用,还可以保存更长时间的历史数据,以替代 Lambda 架构中的批处理层数据仓库。流处理引擎以更早的时间作为起点开始消费,起到了批处理的作用。

三、携程酒店实时数仓架构
3.1 方案选型
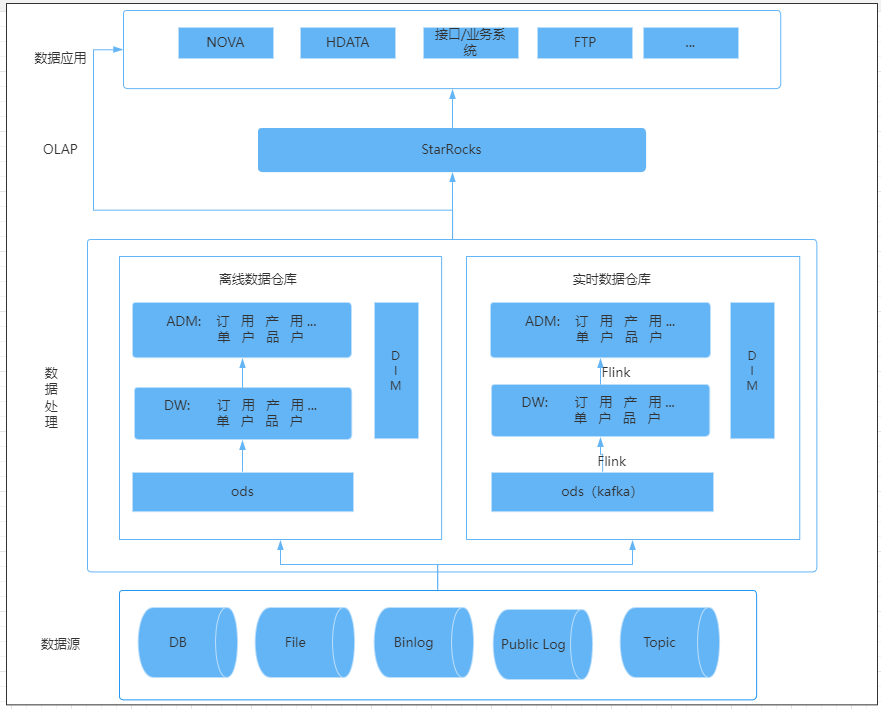
(1)架构选型:Lambda+OLAP 变体架构。Lambda 架构具有灵活性高、容错性高、成熟度高和迁移成本低的优点,但是实时数据和离线数据需要分别使用两套代码。OLAP 变体架构将实时计算中的聚合计算由 OLAP 引擎承担,从而减轻实时计算部分的聚合处理压力。这样做的优点是既可以满足数据分析师的实时自助分析需求,并且可以减轻计算引擎的处理压力,同时也减少了相应的开发和维护成本。缺点是对OLAP 引擎的数据写入性能和计算性能有更高的要求。
(2)实时计算引擎选型: Flink 具有 Exactly-once 的准确性、轻量级 Checkpoint 容错机制、低延时高吞吐和易用性高的特点。SparkStreaming 更适合微批处理。我们选择了使用 Flink。
(3)OLAP选型: 我们选择 StarRocks 作为 OLAP 计算引擎。主要原因有3个:
StarRocks 是一种使用MPP分布式执行框架的数据库,集群查询性能强大。
StarRocks 在高并发查询和多表关联等复杂多维分析场景中表现出色,并发能力强于 Clickhouse,而携程酒店的业务场景需要 OLAP 数据库支持每小时几万次的查询量。
携程酒店的业务场景众多,StarRocks 提供了4种存储模型,可以更好的应对各种业务场景。
四、实际案例—携程酒店实时订单
4.1 数据源
Mysql Binlog,通过携程自研平台 Muise 接入生成 Kafka。
4.2 ETL数据处理
问题一: 如何保证消息处理的有序性?
Muise 保证了 Binlog 消息的有序性,我们这要讨论的是 ETL 过程中如何保证消息的有序性。举个例子,比如说一个酒店订单先在同一张表触发了两次更新操作,共计有了两条 Binlog 消息,消息1和消息2会先后进入流处理里面,如果这两个消息是在不同的 Flink Task 上进行处理,那么就有可能由于两个并发处理的速度不一致,导致先发生的消息处理较慢,后发生的消息反而先处理完成,导致最终输出的结果不对。
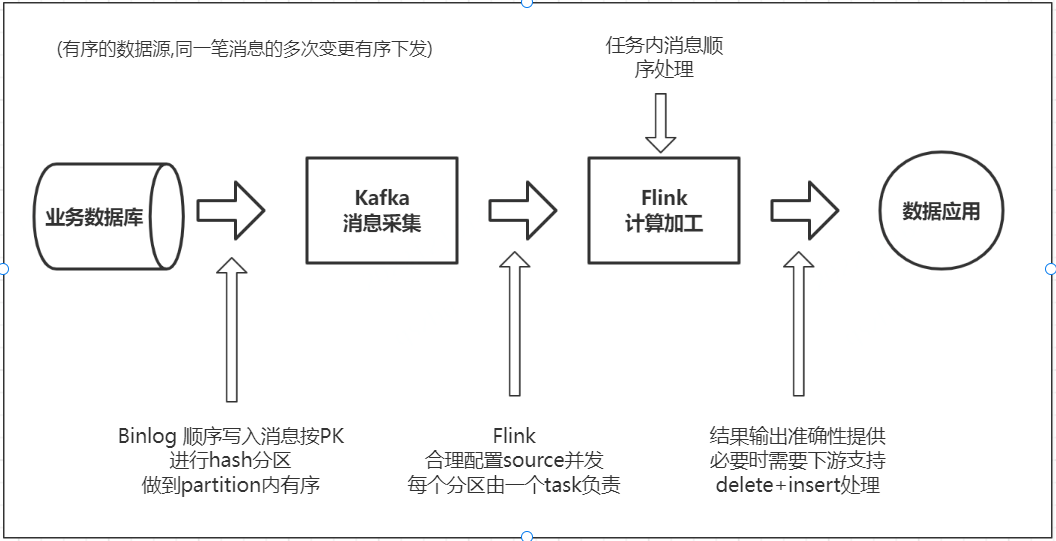
上图是一个简化的过程,业务库流入到 Kafka,Binlog 日志是顺序写入的,根据主键进行 Hash 分区,写到 Kafka 里面,保证同一个主键的数据写入 Kafka 同一个分区存。Flink 消费 Kafka 时,需要设置合理的并发,保证一个分区的数据由一个 Task 负责,另外尽量采用逻辑主键来作为 Shuffle Key,从而保证 Flink 内部的有序性。最后在写入 StarRocks 的时候,要按照主键进行更新或删除操作,这样就能保证端到端的一致性。
问题二:如何生产实时订单宽表?
为了方便分析师和数据应用使用,我们需要生成明细订单宽表并存储在 StarRocks 上。酒店订单涉及业务过程相对复杂,数据源来自于多个数据流中。且由于酒店订单变化生命周期较长,客人可能会提前几个月甚至更久预订下单。这些都给生产实时订单宽表带来一定的困难。
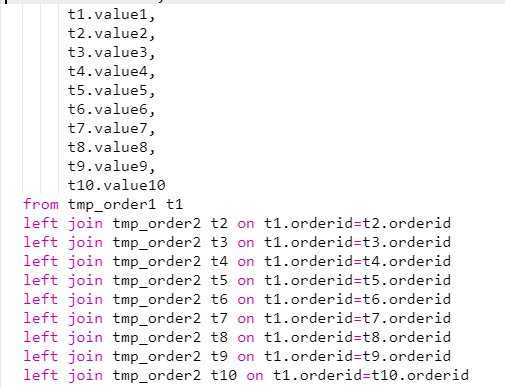
上图中生成订单宽表的 SQL 在离线批处理的时候通常没有问题,但在实时处理的情景下就很难行的通。因为在实时处理时,这个 SQL 会按照双流 Join 的方式依次处理,每次只能处理一个 Join,所以上面代码有9个 Join 节点,Join 节点会将左流的数据和右流的数据全部保存下来,这样就会导致我们这个 Join 的过程需要存储的数据规模放大9倍。
我们采用了 Union all+Group by 的方式替代 Join;就是用 Union All 的方式,把数据错位拼接到一起,后面加一层 Group By,相当于将 Join 关联转换成 Group By,这样不会放大 Flink 的状态存储,而且在增加新的流时,相比 Join,状态存储的增加也可以忽略不计,新增数据源的成本近乎为0。

还有一个问题,上面有介绍过酒店订单的生命周期很长,用 union all 的方式,状态周期只保存了30分钟, 一些订单的状态可能已经过期,当出现订单状态时,我们需要获取订单的历史状态,这样就需要一个中间层保存历史状态数据来做补充。历史数据我们选择存放在 Redis 中,第一次选择从离线数据导入,实时更新数据同时更新 Redis 和 StarRocks。
问题三:如何做数据校验?
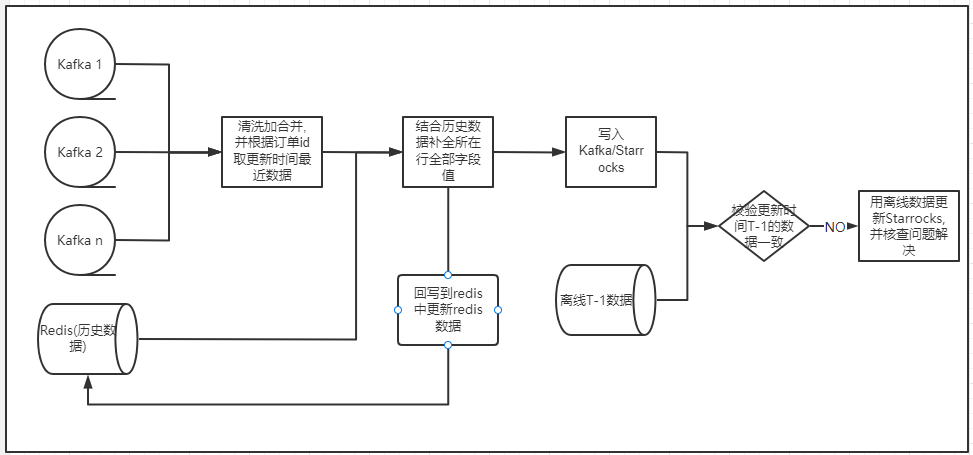
实时数据存在数据丢失或逻辑变更未及时的风险,为了保证数据的准确性,每日凌晨用数据更新时间在 T-1 和离线数据做比对,如果数据校验不一致,会用离线数据更新 StarRocks 中这部分数据,并排查原因。
整体流程见下图:
4.3 携程酒店实时订单表的应用效果
酒店实时订单表的数据量为十亿级,维表数据量有几百万,现已经在几十个数据看板和监控报表中使用,数据报表通常有二三十个维度和十几个数据指标,查询耗时99%约为3秒。
4.4 总结
酒店实时数据具有量级大,生命周期长,业务流程多等复杂数据特征,携程酒店实时数仓选用 Lambda+OLAP 变体架构,再借助 Starrocks 强大的计算性能,不仅降低了实时数仓开发成本,同时达到了支持实时的多维度数据统计、分析、监控的效果,在实时库存监控以及应对紧急突发事件等项目获得了良好效果。

