本文根据张伟杰在【第十五届中国系统架构师大会(SACC2022)】线上演讲内容整理而成。
本期分享嘉宾

网易高级技术专家 张伟杰
【嘉宾介绍】来自网易严选,12年起从事技术质量工作,先后就职阿里、网易公司。目前作为稳定性保障、数据算法质量团队负责人,从事性能&稳定性、大数据&算法质量、研发效能等方向解决方案建设。
本文摘要:微服务架构下的复杂在线系统,在保证系统稳定性方面存在以下典型难点:
1,从微观视角看,除了基建、运维的传统专职角色外,稳定性保障职责大多拆分到了各个“小型”研发团队手中。在繁重的需求压力下,各研发团队面临精力有限、目标模糊、人员交替等难题,导致稳定性建设水平参差不齐、依赖“事故驱动”。
2,从宏观视角看,由于复杂的调用链路和依赖关系,大量微服务组成了一个高频迭代的大型系统,对线上运行风险的快速识别和上线前拦截提出了较高挑战。
网易严选技术团队在过去几年中,面对上述挑战,从基础能力搭建到研发模式调整,逐步建立起一套技术团队广泛实施、覆盖全站1.5k个服务端应用的稳定性解决方案。
分享大纲:
1、严选稳定性建设的背景和难点
2、完善基建:工具链搭建和落地应用
3、落地长效机制:基于服务画像的标准化方案,以及在研发团队、迭代模式中的适配
4、拥抱DevOps:高频迭代下的稳定性风险发布卡点策略
背景和难点
网易严选是一家独立品牌电商,技术系统涉及C端:导购、交易、用户等;B端:库存、商品、客服等;数据&算法:智能营销、搜索、个推等;技术平台:自研、开源引入;PaaS/IaaS基建:自研、网易集团。
网易严选技术系统有两大特点:其一,高度微服务化,拥有1500+后端应用(服务)、30+特性研发团队;其二,业务需求饱和,全站服务端每周1000+次发布。
关于稳定性能力建设目标,网易严选希望通过工具、流程、团队等方面建设,持续、有效的识别和消除系统运行风险。如今正面临诸多挑战:
首先,风险难以充分识别,仅靠线上运维兜底是不行的,导致我们频繁救火、复盘;其次,需求迭代压力很大,投入不足,运动式治理、难以持续;最后,团队多、人员流转,导致标准混乱,依赖个人能力,人走政息、落地不易。
针对上述挑战,2019年严选决定建设一套长效的稳定性保障能力,并制定了阶段性目标,目标一:风险能力要充分识别,大促无故障;目标二:在高强度迭代压力下,持续性消费风险;目标三:守住基线,更快交付。
基础能力建设
从2019年开始,严选频繁落实研发标准和规范,以及快速建设了一些工具和平台。在工具平台建设方面,主要包括四大部分,即监控-报警-快恢、性能和容量管理、可靠性评估和治理、变更管控。

在性能、可靠性评估能力方面,下图左侧是生产环境全链路压测,导购交易链路,覆盖200+个线上应用集群,从2019年开始累积识别、修复风险点500+。
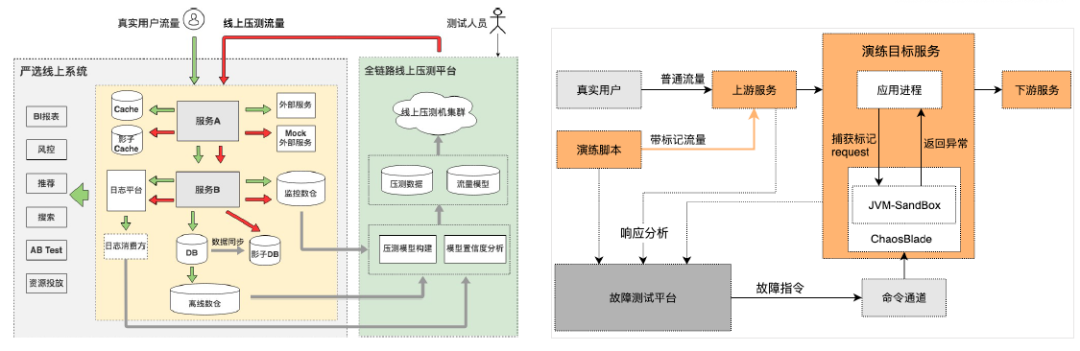
上图右侧是生产环境故障攻防演练,应用层故障识别流量标记后生效,让用户无感知,从2019年开始累积识别、修复风险点70+。
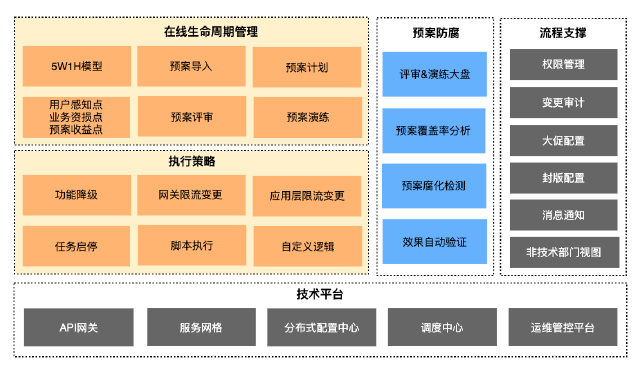
在应急预案管理方面,严选第一件工作就是把预案标准化,建立了5W1H标准化在线管理,300+在线预案,已支撑20+场大促。严选将预案实现了自动化,打通了各个技术平台,所有预案可一键执行,在大促高峰时段,做到了自动提前执行、自动恢复。同时,严选还建立了预案防腐,在S级大促之前,要做到100%评审、演练通过率。
落地长效机制
要知道,在研发规范、工具平台都具备后,仍然存在落地困难等诸多问题:
第一,工具需要更好用,最好是无人值守;第二,对系统“稳定性”的“水平”、“当前风险”,各团队、各职能缺少标准定义,沟通、协作成本高;第三,目标不清晰、成果难量化;第四,迭代需求繁重,难以驱动研发团队改进。因此,工具+规范并不等于实际落地。
对于落地长效机制,严选认为由三部分组成,包括更低成本的风险识别和治理能力、合理的度量能力和适应高速迭代的技术运营方案。
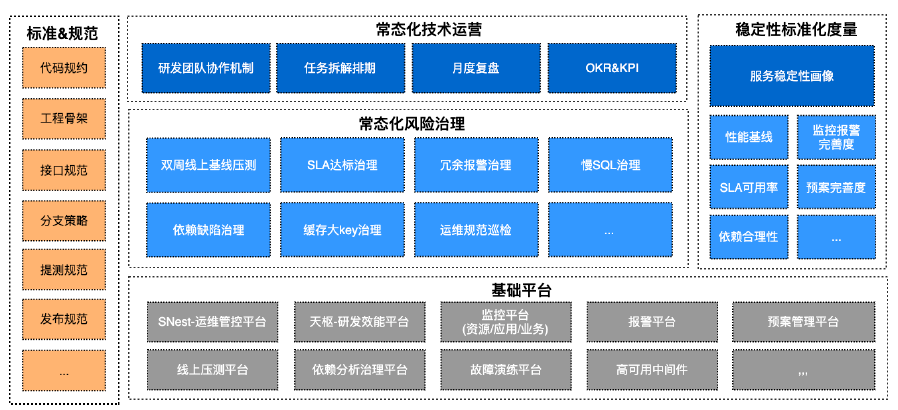
如何把风险识别和拦截做到更低的成本?例如,不仅要在大促之前做压测,平时也可以进行测试,实现常态化性能基线,安全保障是前提,做到基于依赖链路自动审计,将SOP线上化、压测值班线上化。据了解,从2020H1起,严选就实现了双周固定核心链路线上压测,完整实施小于30分钟每次。

在依赖变异监测方面,微服务整体稳定性存在“水桶效应”,历史事故和线上问题,30%以上来自不合理的依赖调用。常见高风险场景如过大调用扇出扇入比,危害是下游轻微抖动,上游成倍放大;在过大超时设置时,会导致被下游拖垮、雪崩等等。
严选方面采用了全域调用拓扑,据统计,约有10万个逻辑节点(接口)10万+条边,且随着迭代高频变更,人工治理成本高。严选的思路是自动化变异监测,T+1更新构建全域依赖拓扑,预发环境每日无人值守遍历故障注入。最终效果是覆盖100%依赖拓扑,做到每日自动监测,识别风险项6000+,低成本,不到人工review的千分之一。
在稳定性风险标准化度量方面,度量是改进的前提,合理的稳定性风险量化方案,应该具备哪些条件?为什么不直接选用SLA?我们考虑了以下几个指标:
1,指标成熟度:易理解、有共识、可获取
2,抗干扰能力:客观事实数据、减少人为干扰;能拉齐不同实现难度
3,指标透明能力:引入灰盒、白盒指标,方便下钻治理、方便任务分解和排期
4,指标灵活性:权重可调,牵引团队阶段性重心
针对上述需求,严选推出全新的度量方式——服务稳定性画像。其设有六大评估维度,即SLA可用分、基线压测分、容灾能力分、应用风险修复分、存储风险修复分、配置规范分。据严选统计,事实指标占比80%+,灰盒/白盒指标占比70%。
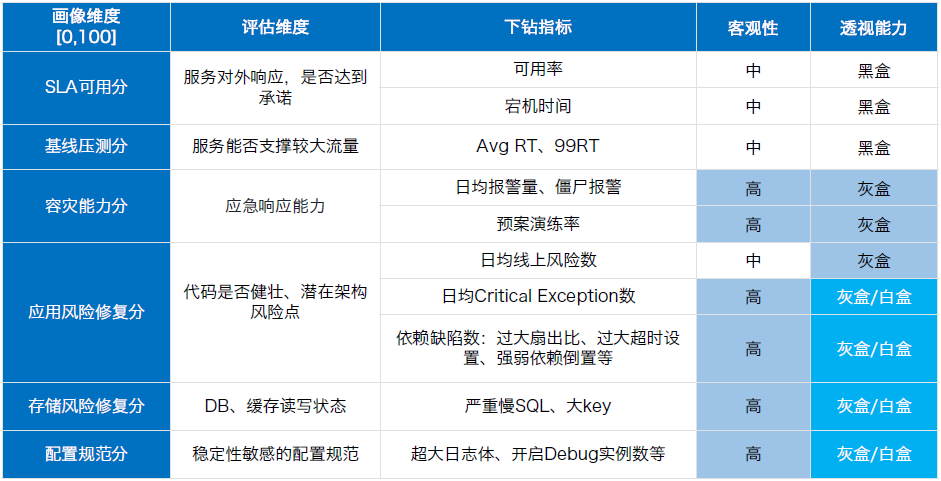
下图是目前严选采用的服务画像
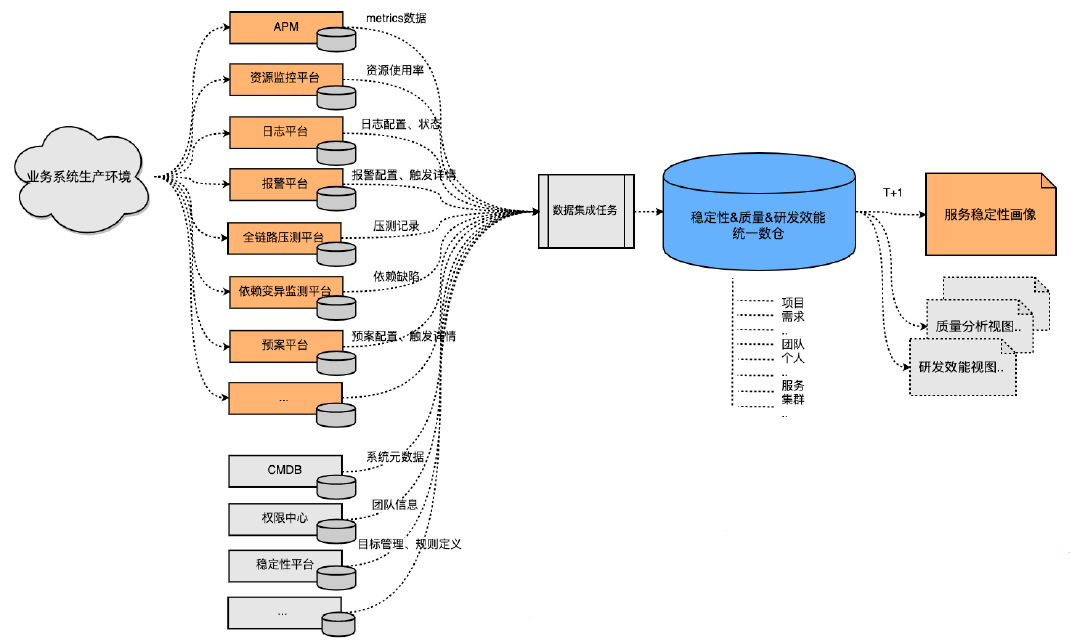
严选实现了数据层统一聚合,汇总500+表,建设全域稳定性&质量&效能数仓;在服务/接口/集群、项目/迭代/需求、工程/分支/commit、团队/个人、日/周/月/季等多维度分析;在低成本可视化方面,采用敏捷BI报表。
在长效技术运营方面,严选设置了研发团队OKR,L1服务大于85,L2/L3服务大于80,在协作流程方面设置了虚拟技术运营小组,月度Story做到提前筛选排序,开发+QA自主拆解,月度复盘。
在最近一年多的时间里,严选长效技术运营已覆盖后端应用1500+,覆盖C端、B端各业务线共30+特性研发团队,达成OKR基线的服务,占比从80%提升到95%。

在C端研发团队稳定性治理任务上,严选治理事项当月完成率从过去最低50%,提升到85%以上,研发团队用于稳定性治理的总投入降低30%以上,严选正在从“大促+事故驱动”到“常态运营”转换,目前,严选已经连续20个月无稳定性事故。

拥抱DevOps
严选如何在DevOps流程中实现稳定性的治理?我们认为本质是在不损失交付效率的前提下,确保质量基线,同时进一步确保质量+稳定性基线。
下面这张图是严选天枢-DevOps研发效能平台
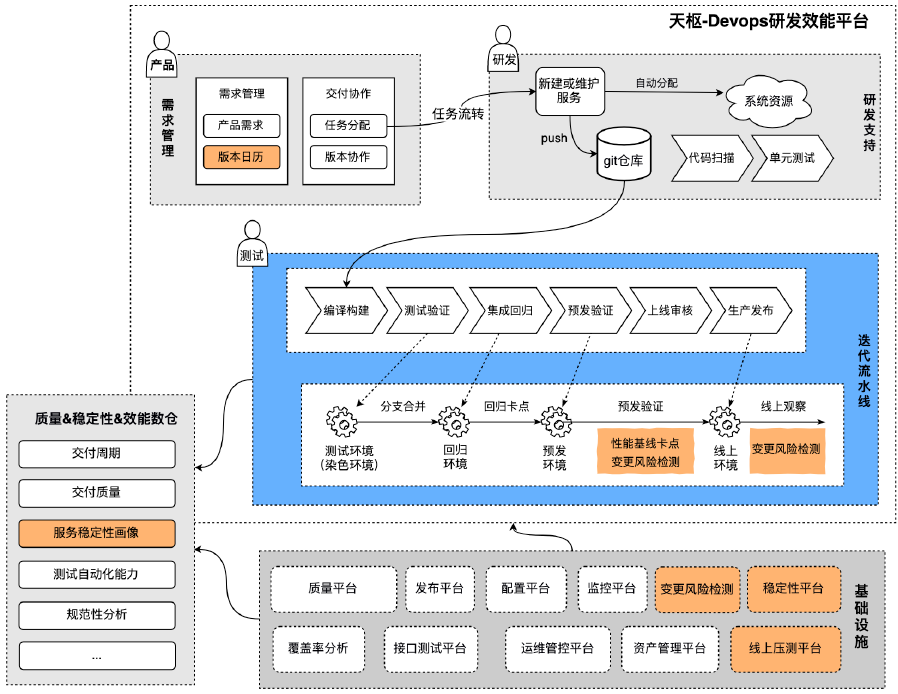
在产品方面有需求管理和交付协作,在研发方面有服务新建或维护、git仓库、代码扫描等等,在测试方面有编译构建、测试验证、集成回归、预发验证、上线审核和生产发布,在测试时有染色环境,集成回归时也有相应的回归环境,在预发和上线之前,我们会做性能基线卡点和变更风险监测。
简单总结,我们做了三件事情:第一,服务画像分,影响发布窗口:高分服务,不受窗口限制,大促不封版;第二,预发环境性能基线卡点:服务性能退化发布前自动拦截;第三,变更风险自动检测:DB、配置中心、MPS订阅配置完备性检查,发布前后监控数量对比,异常第一时间识别。
下面是系统截图

左图是性能基线发布卡点,我们发现流水线自动触发,预发发布阶段增加了3分钟,据统计,从2022Q3开始,拦截5例性能退化发布。
右图是变更风险检测,据统计在发布风险拦截方面,已经成功拦截变更错误367次,在制品合规性检查方面,不合规制品拦截5310次。
未来展望
未来,严选将持续深度融合DevOps流程,稳定性风险拦截环节持续左移,希望在研发阶段、测试阶段、甚至是需求阶段就能够实现风险的提早识别,而不是把所有的工作放到后面。同时,严选还希望引入算法能力,将风险探测和拦截能力增强,体感减弱。

