1 项目背景
我们团队为网易互娱大量游戏产品提供了常规概况、经济分析、留存分析、回流分析、付费分析、服务器分析、渠道分析、定制专题、社交分析、全球分析、问卷分析、全球设备等多种游戏分析专题服务,也支持自定义指标展示的BI看板分析。
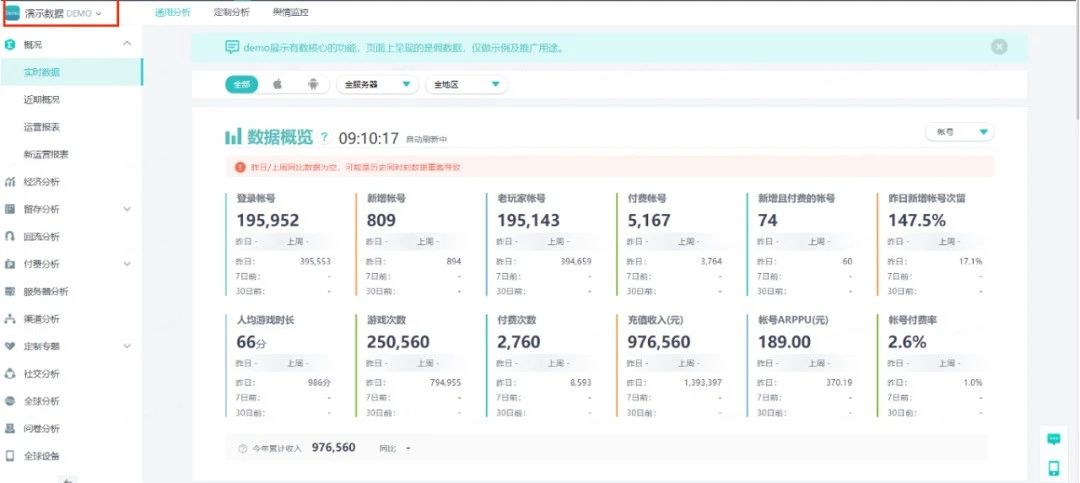
目前为止,已累计服务互娱300+款产品,离线数仓SQL月执行次数便最高可达近400万次。
2 项目挑战
随着业务发展,目前离线数仓执行作业数已达到每月三百万+个,各个环节的问题也凸显出来:
日志管理混乱,多产品多程序规范不统一,日志打印随意,解析与维护困难;
产品持续运营,作业与数据累积,作业常需长期执行,数据生命周期不明确;
日志重复存储,原始日志与经格式化解析后的原始表并存两份,成本负担大;
海外市场开拓,海外数据存储成本远高于国内,导致产品数据存储成本飙升。

为此,对项目进行数据成本优化迫在眉睫。
3 项目实现
我们总体的优化方向分为存储和计算两大部分,基于日志的处理流向分不同阶段进行优化。
对于存储部分,对互娱数仓总体存储进行占比分析,我们发现ODS层数据占据了全项目的75%的存储空间。因此,我们的首要目标便是优化ODS层的数据存储,分为存储前、存储时、存储后三个子目标进行优化。
对于计算部分,由于计算任务众多,我们优先针对耗时较长、逻辑通用性较高的P1指标的计算任务进行优化,分为计算前、计算时两个子目标进行优化。
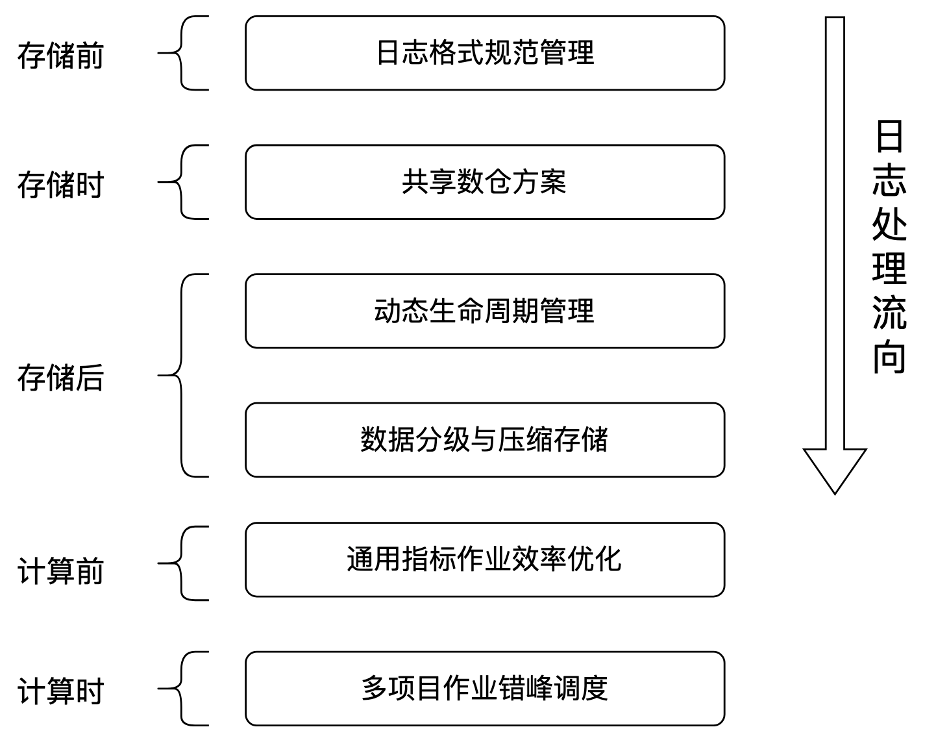
(1)存储前:日志格式规范管理
程序日志作为互娱ODS层数据的直接来源,合理的日志格式规范可以直接从源头上降低人力和存储成本。这里我们提出了日志打印的三大原则:
标准:日志打印遵守统一标准格式,保证下游可正常解析,异常日志的存储或特化解析会带来存储空间的浪费、人力维护跟进的投入开销与下游解析作业的性能开销;
按需:仅打印下游业务所需的日志,非必要的日志可不打印或不采集到下游链路中;在满足业务分析的前提下,日志打印可遵守最小原则,最大限度减少下游日志传输量;
精简:对于频繁在多条日志反复打印的字段,可仅在会话中的第一条日志打印完整信息,后续日志通过会话ID进行关联查询;可通过维表查询替换的字段,在日志打印时可进一步压缩字段的大小。
当然,基于人工遵守原则来保证日志规范总会有遗漏的地方,因此互娱数据治理平台的日志上报模块便应运而生。就以日志精简打印为例,用户可在日志上报模块上报和配置日志的映射关系,首先程序按约定打印日志时仅打印日志列名的缩写,其次业务同学按约定的映射字段登记表或字段的英文全名以及业务描述,理论上可以减少10%-20%的日志存储空间。

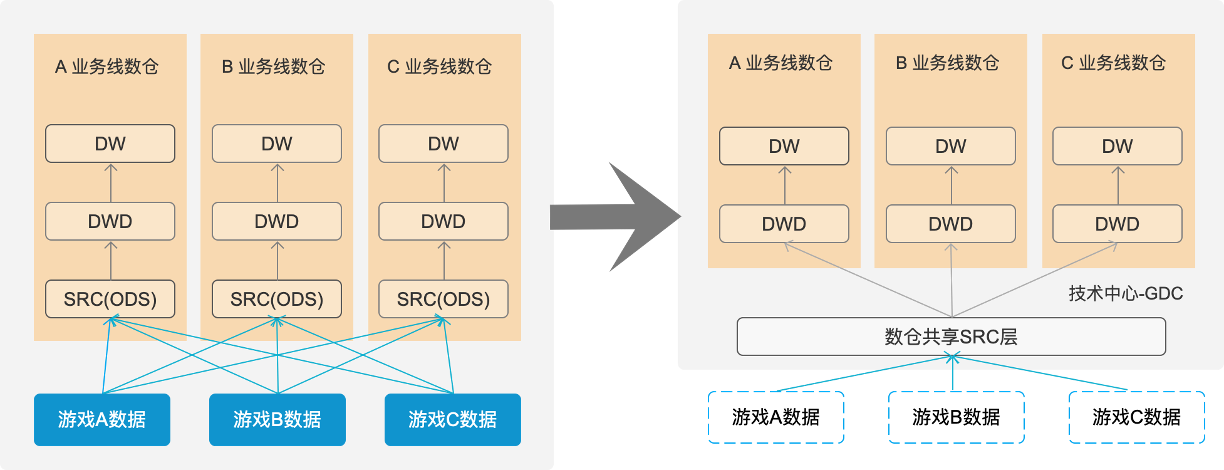
(2)存储时:共享数仓方案
互娱旧版原始日志存储架构中多个部门都有各自ETL后的ODS层,形成了多份原始日志重复存储的局面。为此,UX+SDC+GDC等多个部门联合推进了共享数仓的方案,实现一个多部门共享实时ODS层:读取实时流数据,实时ETL后按日志名入库为不同表,分钟级时效,业务部门直接基于共享ODS层进行上层指标计算,实现一份ODS层的最优存储。该方案的推进,也带来了诸多好处:
解决原先原始日志不可「查询」的问题:提供给用户最基础的ODS表查询,而原始日志本身将不再存储;
解决原先文件存储无法细粒度管理问题:调整为表存储模块, 给产品提供项目日志数据管理入口;
优化上层业务线按单日志重跑执行效率:底层日志按表分别存储,上层数据重跑无需扫描全部日志。
(3)存储后:动态生命周期管理
早期我们对于ODS层数据存储优化的手段便是由业务同学人工配置ODS表生命周期,但该方式存在诸多问题:
错误冲突:人工配置可能会误消亡正在读取的表分区数据,业务A配置的规则不一定符合业务B的要求;
维护麻烦:生命周期额外配置,与业务同学计算指标作业隔离,业务逻辑更新时需兼顾两处;
历史遗留:人工配置容易可能会造成历史遗留问题,出于稳定考虑,业务无法有绝对把握缩短生命周期。
因此,针对上述痛点,互娱数据团队提出了一个自动化方案:基于SQL审计记录,动态消亡长期未读分区数据,再次读取时自动重切数据。

2022年6~9月份,某海外大型项目,回收过期数据2229.5T,截止2022年09月27日,项目现存数据仅386.3T,减少了85%的存储空间。
(4)存储后:数据分级与压缩存储
当数据必须存储时,我们可以通过分级存储与压缩存储来进一步降低存储成本。
通过SQL审计信息发现,按时间从近到远,数据的读取频率也从高到低递减,因此我们提出了分级存储的模式:按数据生产日期从近到远,权衡读写性能,选择存储介质。
第一级:存储在常规Hadoop集群,保证读写性能;
第二级:存储在冷备Hadoop集群,可读写,但性能稍差;
第三级:存储在冷备S3集群,只读不可写,性能最差。
同时,在存储时,我们可以基于数据的读写特性,比如是否要支持追加写等约束,为数据选择合适的压缩格式,这里我们也分为两级进行实现:
第一级:格式压缩,基于不同表,压缩为orc/textfile+snappy格式,压缩率在30~48%左右;
第二级:使用纠删码技术,从3副本减少到1.5副本,压缩率在50%左右。
(5)计算前:计算效率优化
由于互娱数仓作业任务数众多,因此我们选择优先针对耗时较长、逻辑通用性较高的计算任务进行优化。具体思路是从数据仓库建模角度重新梳理数据链路,减少跨层引用,复用数据中间层降低重复计算和IO等。经过测验,项目里满足条件的作业所需计算资源会降低70%-90%,整体常规运营指标任务所需计算资源能降低30%-50%。

(6)计算时:任务错峰调度
在早期,由于缺乏有效规范,过往的计算任务分配调度时间相对随意。从项目调度图可以观测到,很多项目下的任务运行时间集中在了忙时阶段,造成计算成本相对较高。而不同的时段的内存、CPU等计算资源成本是不一致,一般可以分为忙时(凌晨2点-8点)和闲时两个阶段,忙时和闲时计算费用单价比为4:1。
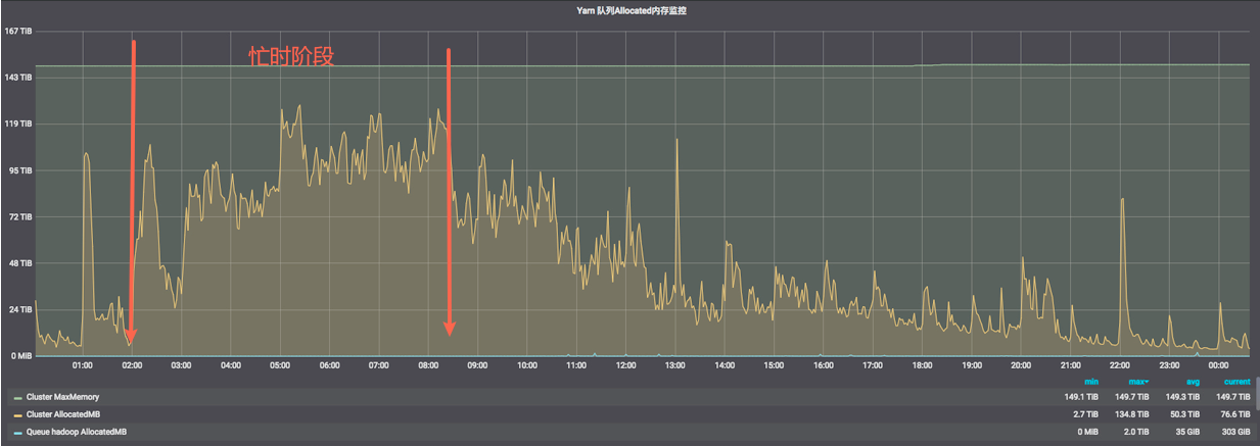
因此我们通过对项目任务优先级和预期产出时间进行梳理,使用迁移非关键分析指标至闲时等手段,重新合理分配了任务的调度运行时间,从而降低了总体项目的计算成本。
4 项目成果
(1)2021年的计算存储优化效果
2021年9月份对公司部分游戏业务进行存储和计算优化之后,如右图所示,在保障不影响业务运转的前提下,成本方面环比8月各业务都有了较为明显的下降。存储部分最高优化65%,计算部分最高优化71%,总计预估年节约成本约合960万元。

(2)2022年的计算存储优化效果
2022年6月份起对公司海外项目为主进行存储和计算优化后,优化占最终优化总体各为45%、55%,总计预估年节约成本约合1500万+元。

