Node 系统中定时任务的演化
01 背景
北斗前端监控系统是 58 内部的一个线上质量监控排查解决方案,用于帮助用户大幅提升定位问题和优化项目的效率。系统共分为数据收集(SDK)、数据处理(Java)、数据存储(Druid、……)、数据分析(Node.js)、数据展示(React) 5 层模型。Node.js 作为系统中的数据分析层,提供各种数据分析和应用的方式。
在一期之后,系统的基础功能已经完备。平台可以收集 5 种类型、30 多种指标的数据,已经具备了很强的数据收集能力,数据应用的方式却很匮乏。
所以在二期开发时,我们计划在 Node 端加入多种数据应用的方式。实时告警,就是其中之一。
简单分析需求,服务端需要以一定的频次(例如每分钟)监测不同项目中用户配置关注的指标数值。当数值出现异常时,给用户发送邮件、短信等告警信息用于警示。
而其中的重点,就是如何在 Node.js 中设计并实现定时任务系统?
02 定时任务1.0-简单场景下的快速应用
定时任务 1.0 - 简单场景下的快速应用
初期的定时任务,是为告警而开发的,所以场景较为简单。
生产者:定时生成多种告警指标、几百个项目下的定时任务。
消费者:执行定时任务,进行阈值计算并告警。

由于指标已经固定,且当时没有告警外的其他应用场景,所以可扩展性不是影响系统的重要因素。而集团内部平台用户量级较小,安全、成本等其他因素也不会成为瓶颈。系统的复杂度主要来自于对可用性的支持。
作为一个稳定的系统是必须在集群内多个机器中运行的。分布式必然会带来额外的系统复杂度。
2.1 分布式
当集群内有多台服务器,我们如何保证定时任务可以由不同的机器不重复的执行呢?
大家可以很容易的想到 MQ(消息队列)和分布式锁。两者也都有相关的 Node.js 库,基于 MQ 的 node-kafaka 以及基于锁的 Redlock
在当时的场景下,我们需要低成本快速的上线告警系统。MQ 虽然功能完备,支持更为复杂的功能,但是相对于抢锁机制复杂度太高,在简单的场景下优势又不是很明显。所以最终选择基于 Redlock 的抢锁机制实现分布式定时任务。
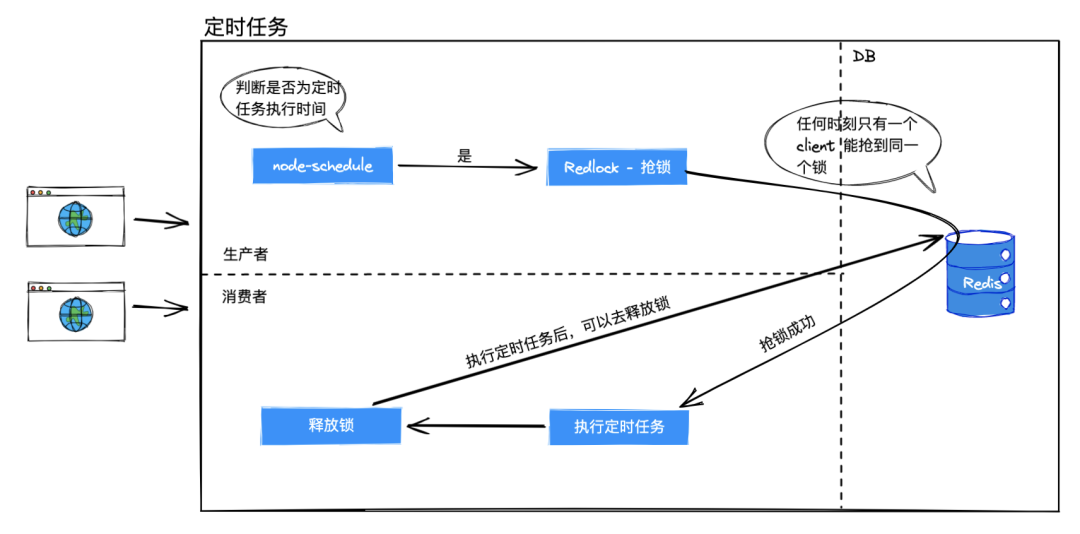
当集群内的机器使用 node-schedule 判断到达定时任务的执行时间时(例如每分钟执行),会同时使用 Redlock 进行抢锁操作。
多个定时任务,配置不同的 key。同一时间内,如果锁没有被释放它只会被一台机器获取。这样我们就保证了定时任务只被一台机器执行。
抢锁成功的机器会执行定时任务,计算数据是否异常并告警。
在适当时时机将锁释放即可,只要保证抢锁的时间段内锁存活即可。
这样我们就保证了分布式系统内定时任务只执行一次。
可以看到 1.0 版本的定时任务是单独为告警而开发的,此时的告警模块流程简单,且指标数量较少。系统内的生产者和消费者也没有进行解耦,整体流程是线性的。在当时的场景下,这种基于 Redlock 的定时任务方案完全可以支撑业务稳定运行。
03 定时任务2.0-复杂场景下的架构升级
随着平台的扩展,告警增加了自定义告警功能。定时任务也增加了采样分析、定时数据缓存、定时周报等大量定时任务的执行。此时,1.0 版本的定时任务系统开始涌现出各种问题。
任务分配不均匀。当定时任务数量增大后,出现了任务分配不平衡的问题,集群内某些机器抢到了更多的任务,某些机器抢到任务较少,资源利用不平衡。
随着数据量级增大,生成任务和执行任务时间复杂度相差较大,当定时任务过多时会对系统性能造成负担。
任务执行顺序无法保证,当遇到需要按序下发的定时任务时无法保证。
定时任务可靠性较低,没有持久化存储任务列表,执行异常的任务没有重试机制。
……
随着系统的扩展,单独为告警而开发的定时任务运行着很多额外的模块。虽然整体流程还没有被阻塞,但是随着后续系统的扩展,必然会导致系统越来越不稳定。于是我们计划重构定时任务,使其能够作为一个通用的子模块,承载多样的定时任务。
1.0 时没有引入消息队列或任务队列来处理定时任务,是因为当时的场景下对保序、异常任务重试等特性没有强需求,接入任务队列后系统复杂度却会高很多。而 2.0 时作为通用模块,则需要一定的机制来保证这些特性,于是我们决定引入任务队列的概念来进行系统重构。
此时的系统结构如下:

生产者生产任务,会将任务推送到任务队列中,通过任务队列可以保证任务的有序性。
消费者异步按需的获取对应的 Job,也可以选择在空闲时再继续获取执行新的任务,而不是所有的定时任务堆积到系统中一起执行。解决了任务均匀下发,按需执行的问题。
通过任务队列,可以维护任务的执行状态。这样持久化存储或失败重试的功能也可以开发相应的功能去做扩展。
3.1 业内实现
在业内 Node 端的任务队列也有很多完整的实现方案,且都经过了大量的场景校验,不需要我们去重复的造轮子。引用 bull 官方的一张对比表,我们整理部分对比如下。
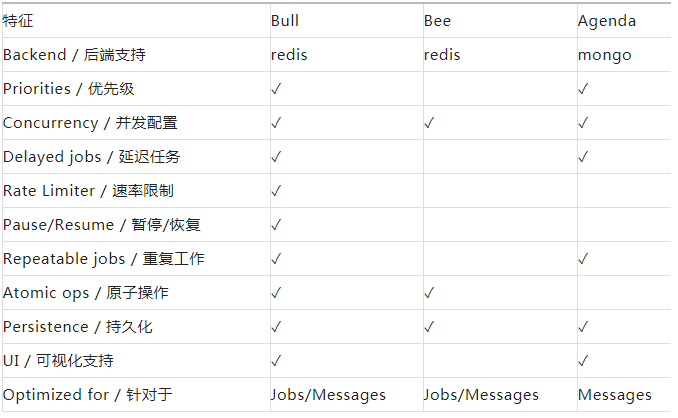
Agenda 是基于 mongo 的任务队列解决方案,更偏向于定时任务。
Bee 是一个简单、快速的 Node.js 作业/任务队列,更专注于小粒度任务的处理,并极大的优化此场景下的性能,由 Redis 提供支持。
Bull 提供完整的任务队列解决方案,有较活跃的受众及系统更新频率。
对比其功能及差异,bull 是目前功能最完善的框架,社区也非常活跃,其丰富的事件回调也能支持我们对流程进行细粒度的把控。
最终在做了技术调研之后,新系统的重构方案就选择使用 bull 来作为基础框架,特定的功能场景下单独进行开发支持。
那么在 bull 中,任务是如何进行流转的呢?
bull 中分为生产者和消费者两种角色,使用 LPUSH/BRPOPLPUSH 命令来维护任务主队列,同时还加入了多种辅助数据结构,为系统丰富的功能做支持。
当生产者生成一个 Job 后,会尝试推送到 Redis 对应的任务队列中(List)。bull 会通过 JobId 区分是否重复推送了一个 Job,以此来实现任务去重功能。
消费者使用 BRPOPLPUSH 命令阻塞式读取任务列表,而不需要轮询的读取。当 List 中有新的 Job 后会将任务分配给消费者。通过配置并发数,也可以控制同一个消费者并发执行任务的数量。
当 Job 执行完成后,消费者给出反馈。此时 bull 更新任务队列中 Job 的状态,并触发对应的事件。
依靠其细粒度的状态存储记录,bull 也支持可靠的任务重试机制,当服务重启或任务执行失败时,bull 可以通过 Job 执行记录来重新执行未完成的任务,极大的提高了系统的可靠性。

可以看到,bull 与 2.0 的系统结构非常契合,我们只需要在此基础上进行二次开发就可以完成 2.0 定时任务系统的重构。
最终定时任务系统架构的设计如下:

生产者
通过 node-schedule 触发定时任务。虽然 bull 也支持定时任务,但是其定时任务对 Redis 依赖过高。当 Redis 中数据结构改变时会影响到系统中定时任务的执行,其可用性较低。所以使用 cron 相关的库手动触发定时任务,来保证系统的稳定性。
当定时任务触发后,集群内的多个机器会构建 JobId,然后使用 bull.add 将任务推送到任务队列。此处我们使用一定的 JobId 生成算法来保证同一时间段内,JobId 的一致性。当任务队列检测到相同的 JobId 时,只会添加一个。
Redis 使用 List 及其他的数据结构来维护任务队列的执行及对其持久化存储。
消费者
消费者会使用 BRPOPLPUSH 命令阻塞式读取任务队列中的任务,当队列中有任务添加时将其弹出并执行。这里可以通过并发配置同时执行的任务数量。
系统检测 process 函数是否有对应 name 或 * 的 handler,如果有执行对应的回调函数。
在不同的事件流节点中,会触发对应的事件回调函数。
当任务执行完成时,必定会指向 completed(成功)、failed(失败)的状态。在其回调函数中判断是否为同一批任务的最后一个任务,如果是最后一个任务则本批次的定时任务全部执行完成,触发 finished 事件。此处注意读取状态及状态写入 Redis 需要使用事务保证原子性。
到此,2.0 版本的定时任务系统就已经设计完成了。
纵观北斗监控系统中定时任务的发展。
初期由于功能简单,且需要快速上线。所以使用 Redlock 开发了基于抢锁机制的定时任务。
后续由于系统功能的扩展,需要支撑更多的定时任务。原系统中的弊端逐渐显露并对系统开发维护带来了困难,此时引入了消息队列的概念优化系统模型。
在持续的迭代中,系统功能也趋于稳定和完善。在目前的北斗监控系统中,定时任务系统支撑着实时告警、采样分析、定时数据缓存、定时周报等大量任务的稳定运行。
但这不是终点,后续一定会遇到更多的挑战,系统的架构也可能进一步升级。而我们需要做的就是拥抱变化,适配我们当下的业务场景去做合适的选择。

