01 游戏中的因果推断:挑战与解决方案
在游戏场景中,常常会面临如下问题:
(1)在一些游戏业务中的运营策略和活动是难以对用户进行实验的,因为会带来异质化的体验引发用户的感受的差异。通常产品运营和策划会经验性地设计运营策略和活动,但随着精细化运营的思想的逐步深入,需要具体量化的数据表现以辅助决策, 而离线因果推断就是非常适配此类问题的方法论。
(2)一般而言,观察数据中的干预不是随机的,常常带有人工运营或算法的选择性偏差。在实际的对比中我们发现选择的干预组与对照组用户所不一样的特有属性,因此怎样进行科学化的计算或推断就显得至关重要。
为了应对此挑战,我们可以采用以下可行性方法:
针对实验数据缺乏的问题,利用观测数据:可使用 ATT(干预组处理效应,ATT=E[Y1-Y0|T=1])来评估对受到干预人群的效应,例如使用倾向性得分匹配(PSM),PSM可以将干预组和对照组进行一对一匹配,并且可以提取匹配后的用户个体。
可以使用因果推断计算 ATE(平均处理效应,ATE=E[Y1-Y0])来评估整体效应。另外,有时会通过加权的方法使样本分布得更均匀,均匀备选方案有 Inverse-Probability-Treatment-Weighting(IPTW)、Double-Machine-Learning(DML)、Double-Robust-Estimator(DRE)、X-Learner 等。
此外在比如利用双重稳健评估(DRE)时,由于在业务中可能无法覆盖全部的混淆因子,DRE 在这种场景下更加稳健,且 DRE 可在倾向性分数预测不准的情况下通过结果预测来进行调整。
游戏中的因果推断所面临的技术挑战主要包括:
一般的因果推断无法解决业务中遇到的数据量巨大的问题,而单次抽样又会导致数据抽样偏差,所以尽量用全量数据。因而,一般可选的常见的因果推断工具集如微软 Econml、Dowhy和Uber Causalml 这类非分布式实现的工具集就无法满足我们的业务需求。
众多业务均需要精细化运营策略,多场景的数据量挑战巨大。尤其是需要在短时间内高质高量地做出推断结果,因此对于运算能力是非常严峻的考验。
当面对游戏中的大规模推断场景,我们可以采用针对性的解决方案。本文将选取以下三方面展开讲解:
分布式低复杂度倾向性分数匹配;
分布式鲁棒双重稳健评估;
基于多干预或长时间干预、有混沌效应的分布式面板双重差分方法深度实现。

02 分布式低复杂度倾向性分数匹配
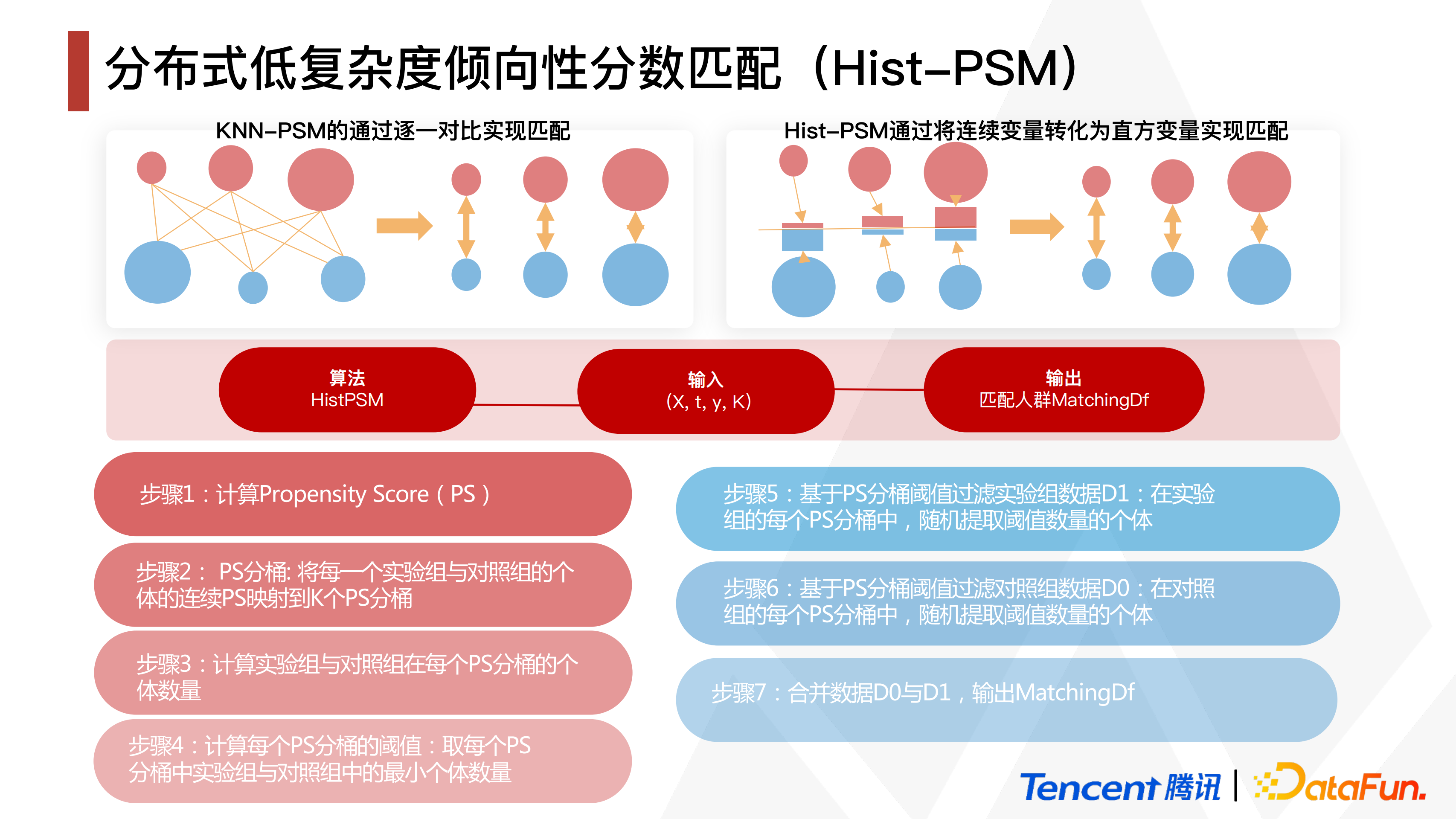
以往的倾向性分数匹配的计算步骤主要为,先进行 Propensity Score(PS)计算,之后进入 Matching 阶段。而在 Matching 阶段计算的工作量是非常复杂且巨大的,如在 KNN-PSM 的通过逐一对比实现匹配的过程中,实验组每计算出一个相应分数,就会逐一跟对照组进行匹配,此类匹配就是基于 KNN 的思想而进行的。
为了弥补倾向性分数匹配的计算复杂且工作量巨大的缺陷,我们提出了运用 Hist-PSM来将连续变量转化为直方变量实现匹配的策略。大体可总结为以下步骤:
① 计算 Propensity Score(PS);
② 根据 PS 的分布,进行 PS 分桶,即,将每一实验组与对照组的个体的连续 PS 映射到 K 个 PS 分桶中去;
③ 计算实验组与对照组在每个 PS 分桶的个体数量;
④ 计算每个 PS 分桶的阈值,取每个 PS 分桶中实验组与对照组中的最小个体数量;
⑤ 基于 PS 分桶阈值过滤实验组数据 D1,在实验组的每个 PS 分桶中,随机提取阈值数量的个体;
⑥ 基于 PS 分桶阈值过滤对照组数据 D0,在对照组的每个 PS 分桶中,随机提取阈值数量的个体;
⑦ 合并数据 D0 与 D1,输出 MatchingDf。总结来说,即无论 PS 是大是小,只要将其丢入分桶,即可找到相应分桶中的对应群体,这将大大降低运算的复杂度和工作量。
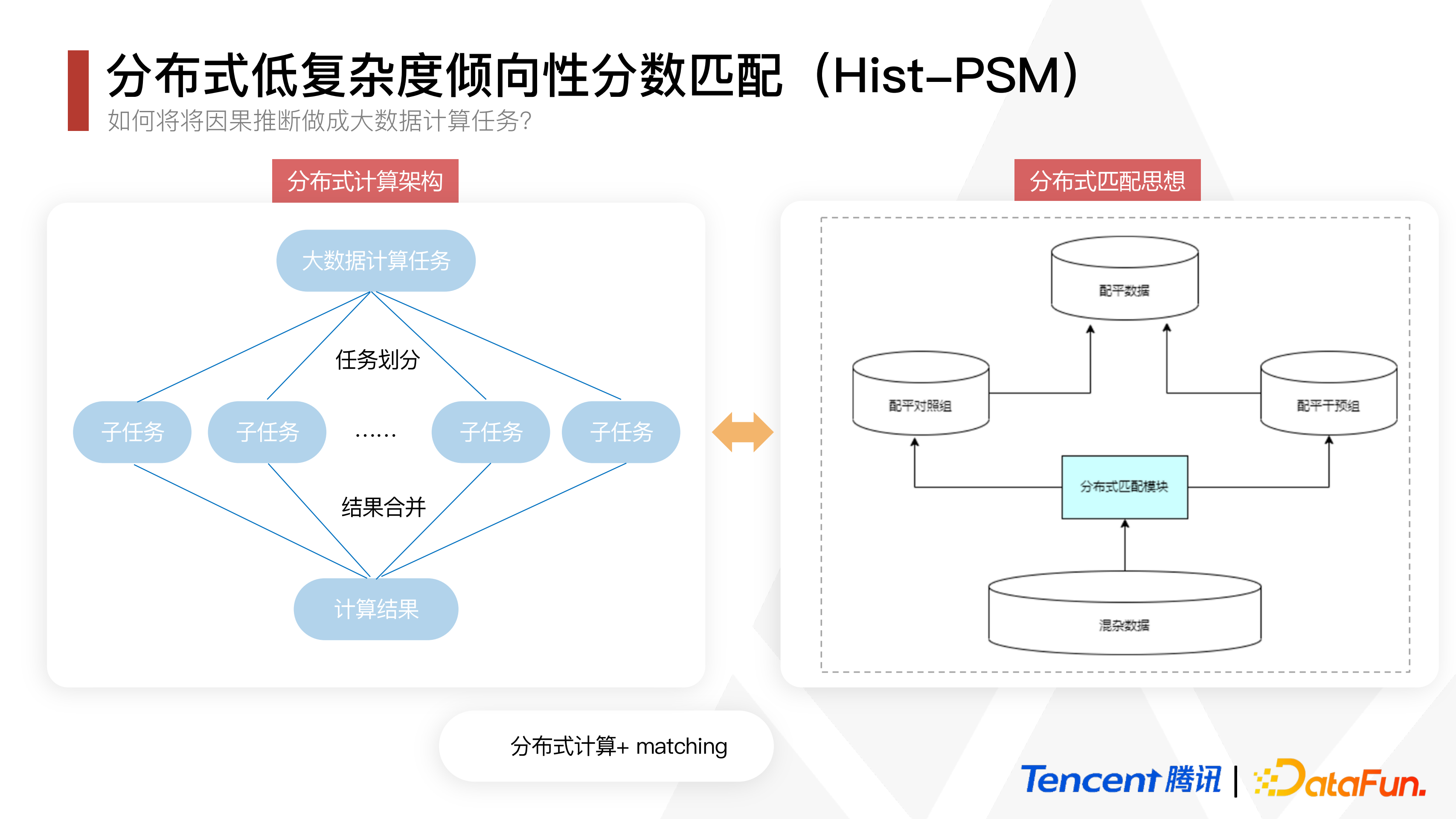
除了要达到降低运算复杂度的目的,还应满足最大程度适配平台的要求。分布式计算架构就是把大数据计算任务划分为多个子任务进行计算,然后将结果合并汇总为总的计算结果。分布式匹配思想就是将混杂数据通过分布式匹配模块分为配平对照组和配平干预组,然后再汇总为配平数据。
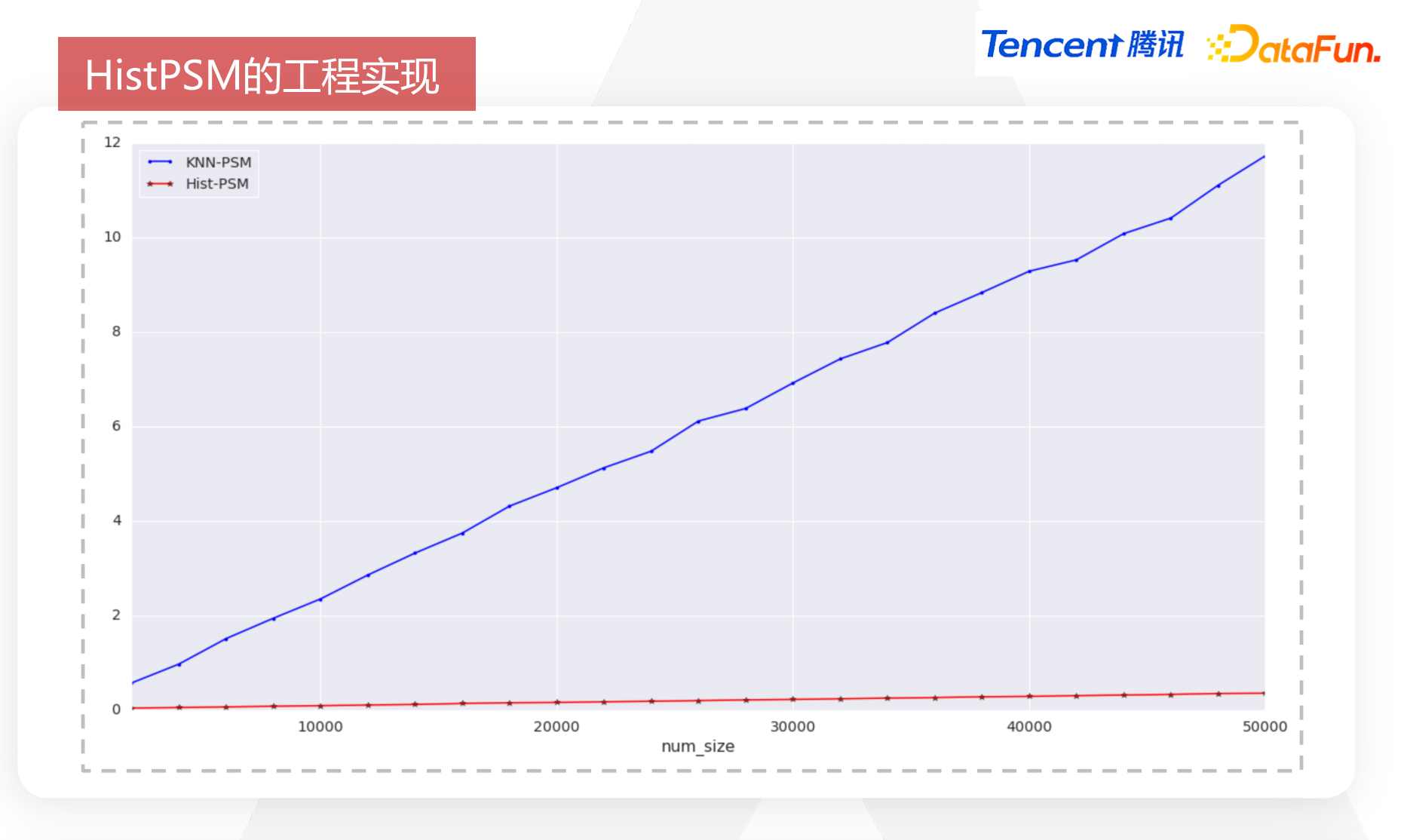
分布式低复杂度倾向性分数匹配(Hist-PSM)相较而言具有以下优势:
内存占用更小:KNN-PSM 需要用 32 位的浮点数去存储特征值,并用 32 位的整形去存储索引,而 Hist-PSM 只需要用 8 位去存储直方图,相当于减少了 1/8;
计算代价变得更小了:计算特征分裂增益时,KNN-PSM 需要遍历一次数据找到合适的分裂点,而 Hist-PSM 则只需要遍历一次即可。相对来说任务量更低,非常适合诸如游戏的天量级复杂场景的任务量。
分布式 Hist-PSM For 大规模推断的匹配度是如何的呢?在一项针对开放数据集进行测试的验证当中,我们发现 Age、SibSp、Parch、Fare 在进行匹配前,实验组和对照组是有显著差异的。KNN-PSM 可以一定程度上控制一些混淆变量,也能一定程度上控制两组间的差异。但在 SibSp 项里,由于某些重要混淆因素的存在,KNN-PSM 对其的控制相对欠缺。而 Hist-PSM 对实验组和对照组的控制效果良好,两组之间的差异并不显著。
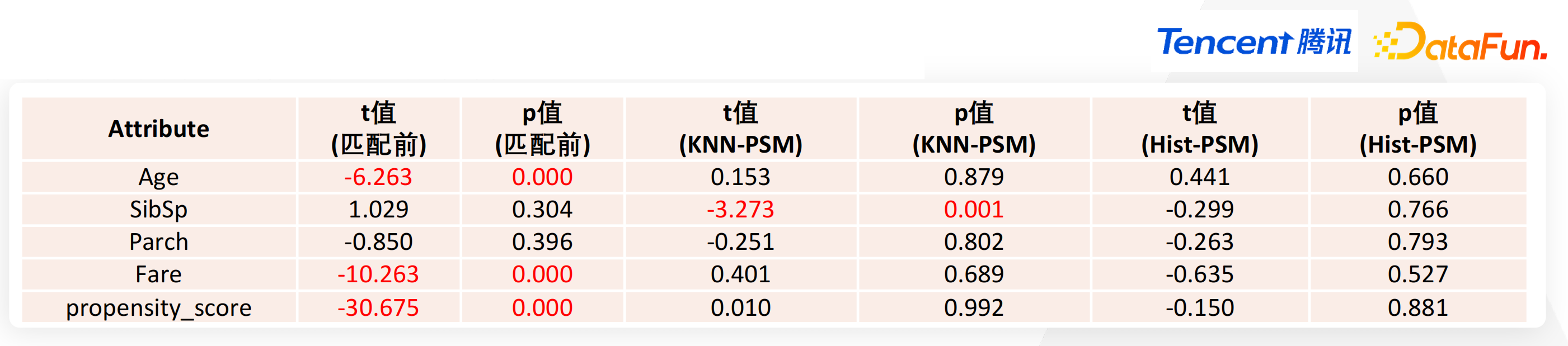
而从 SibSp 的属性分布结果当中也能看出,实验组和对照组变量在进行匹配前的差异较大。在通过 KNN-PSM 进行匹配后,差异一定程度上被控制但未完全消除。而通过 Hist-PSM 进行匹配后,混淆变量被有效控制,分布呈现拉齐的状态。

03 分布式鲁棒双重稳健评估
在很多场景下,PSM 需要对所有的混淆变量取得一定的控制才能得到真实的影响(ATE)和效果提升。但在实际操作的过程中,想要控制所有的混淆变量取得却困难重重。因此,我们提出了改进型的分布式鲁棒双重稳健估计方法来作为应对策略。
一般来说,传统双重稳健估计在对实验组的 PS 进行计算时是将倾向性分数逆加权与线性回归(Linear regression)来进行融合,以此达到双重稳健的目的。但其在计算过程中比较适配于连续性问题(如学生的分数、工人的收入等),但如果进行的计算是针对留存、流失等类似的问题,那这类二元类型的问题的计算量在有些情况下会非常庞大,由于双重稳健估计没有均一化(Uniformization)的过程,对于倾向值得分的倒数较大的场景,会导致大量小于 -1 或者大于 1 的 ATE 出现。
运用 Binary 双重文件估计则可通过逆映射将二元问题结果转化为连续回归问题,使用线性回归模型的预测值逼近分类任务真实标记的对数几率。

在一项针对开放性数据集的应用当中,在具有 Hidden-Confounder 的二元结果环境下,我们进行了 1 万次ATE拟合仿真检验。发现相比 UBER 表现好的算法 UBER-X-Learner,Binary 双重稳健估计将平均偏差降低了 42.16%;相比传统双重稳健估计,Binary 双重稳健估计将平均偏差降低了 38.54%。

由此我们可以看出,分布式鲁棒双重稳健评估可以经受住真实数据计算任务的考验,而且也得到了实验的验证。此双重验证充分说明了该类双重稳健评估方法的科学性和可靠性。
在之后的安慰剂(Placebo)检验任务中,我们发现在对输入干预随机化之后,Binary双重稳健估计比 PSM 和 DRE 更加密集地分布在 0 附近(DML 会存在大量 ATE>1的点)。这就说明针对留存或流失这类的二元问题,传统的双重估计策略的效果就显得差强人意。

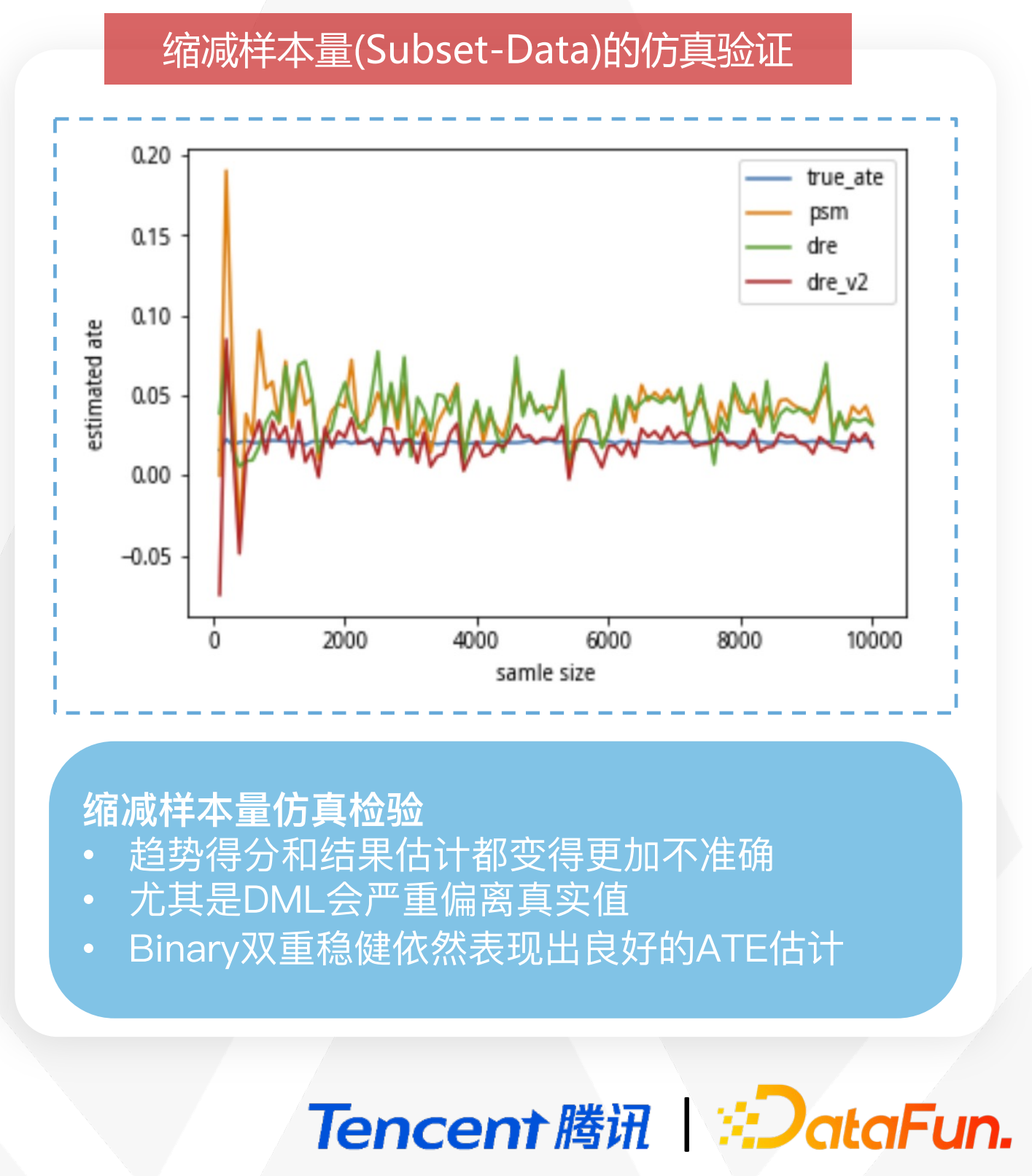
而在缩减了样本量(Subset-Data)的仿真验证当中,PSM 和原始双重稳健估计(DRE)与 True-Ate 的真实值是呈现出一定偏差的,即趋势得分和结果估计都变得更加不准确,尤其是DML会严重偏离真实值。而我们的 Binary 双重稳健估计则表现出与真实值的良好契合度,也就是说依然表现出了良好的 ATE 估计,这也是其良好稳健性的充分证明。
04 分布式面板双重差分
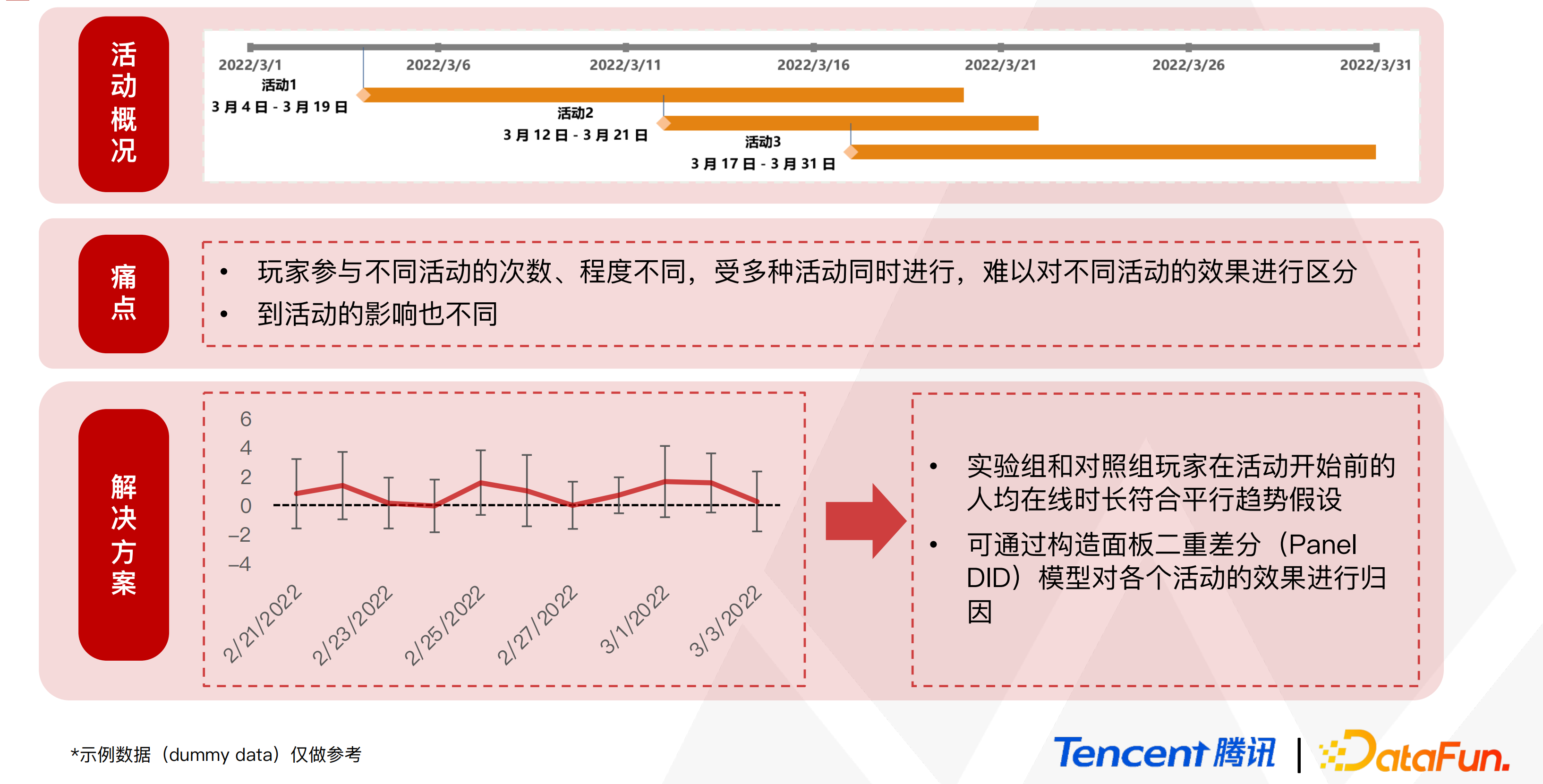
在多干预场景当中,尤其在游戏当中面对连续性投放如多次、多干预、覆盖众多用户、存在多次参与的用户、有的用户在其间有中断和退出行为时,即当用户参与活动的次数、程度不同时,按照以往的传统方法是难以对此类不同活动进行区分的。那么为了准确估计各类活动的真实影响,我们提出了运用 DID 的策略来进行干预。
考虑到在活动过程中,主动参与类型的用户因为其目的和愿望的主动性,相较于非主动参与类用户,可能会存在一定的选择和行为偏差以及显著性差异。此时,运用 DID 策略则可以在满足平行趋势假设的前提下,对实验组和对照组两组的差异的交叉项进行计算。随着时间的变化,我们发现两组交叉项的系数的偏离度在可接受范围内(始终处于 0 值附近),尤其始终处于置信区间内。这就说明实验组和对照组的用户在活动开始前的指标是符合平行趋势假设的,也说明是满足 DID 使用条件的。
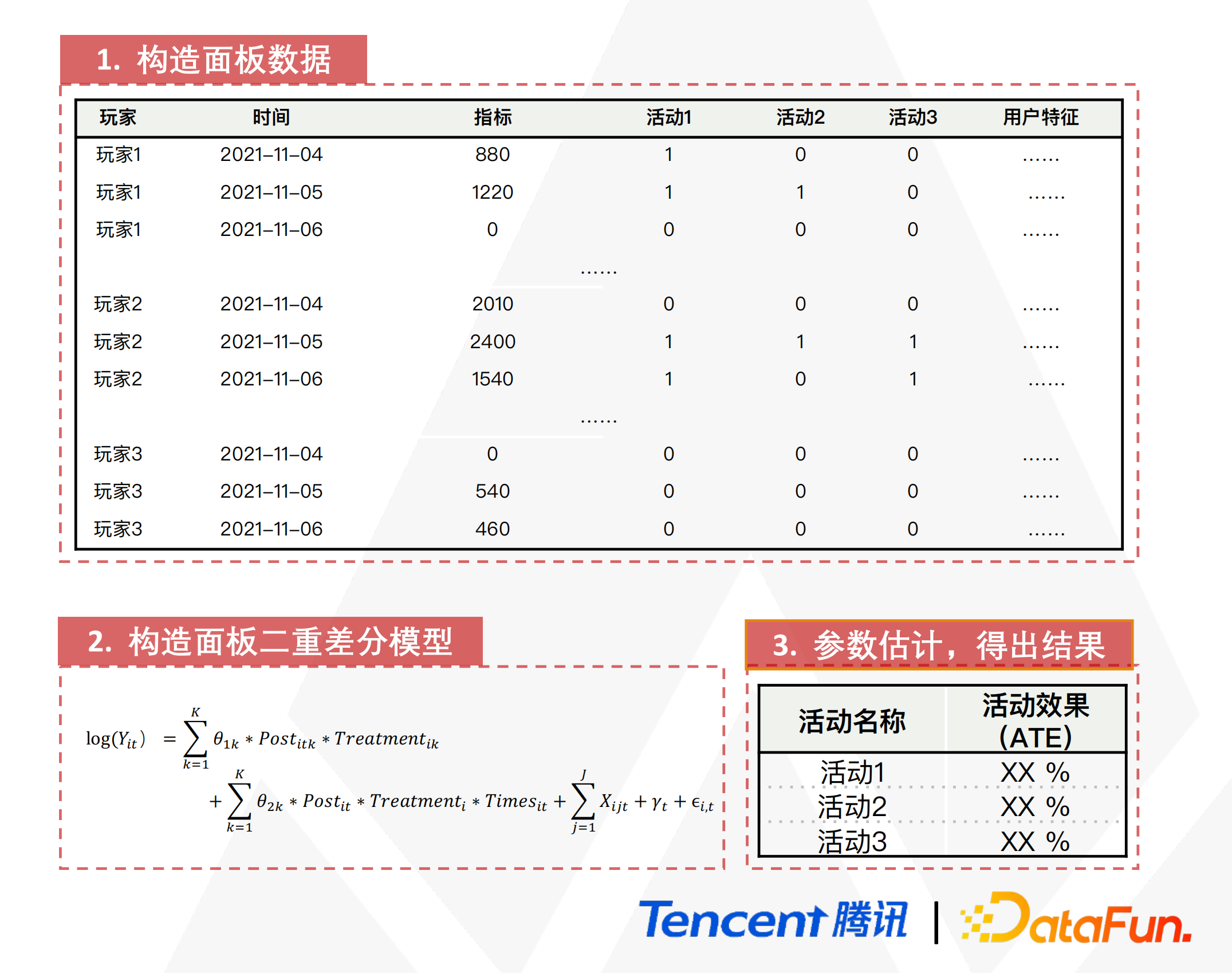
接下来我们就可以通过构造面板二重差分(Panel DID)模型对各个活动的效果进行归因。
首先对用户的数据进行初步的整理,以对所有用户从活动的起始至完结的所有数据进行有效的捕捉。接下来构造一个面板差分数据,明确干预组和对照组及各干预项的开始时间,进行计算并对干预项进行评测。在平行趋势假设验证完毕的前提下,利用面板二重差分模型进行拟合,对数据集进行线性回归拟合并利用最小二乘法进行参数估计,根据参数估计的结果进行统计推断并量化最终的结果。最终就可以根据量化得出的结果来评估活动的优良度并进行反馈。
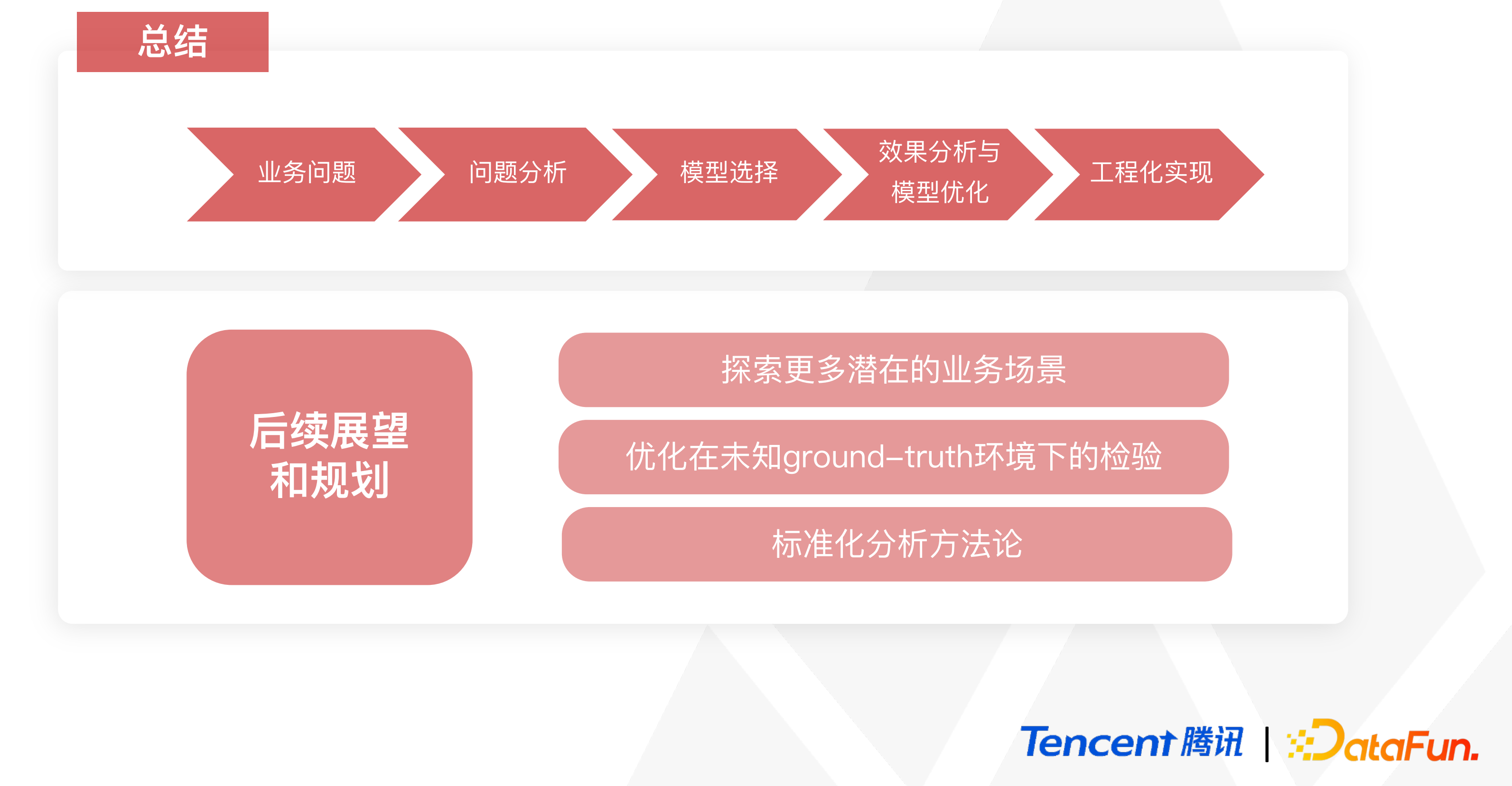
05 总结与展望
我们的策略选择原则是:在面对海量数据的推断任务时,要将任务进行拆分从而获得更加明确的选择项,然后最大程度地实现分布式策略方法对于任务和场景的适配程度。
尽管目前现有的因果推断工具相对完备,但针对大规模的离线推断方法论的建设缺比较缺乏。因此我们仍需要不断总结经验,进行方法的完善,优化模型契合度和完备性。
未来,我们将继续探索潜在的应用场景,不断挖掘其中的数据集的分布规律,为模型和方法提供更多的前置和后置检验,实现对方法论的标准化和对大数据和平台的适配性。