前言
为了给用户提供更好的视频观看体验,B站已研发出很多先进的视频图像分析与处理算法。在视频转码任务中,这些算法既可以改善视频画质,也可以促进转码效率的提升,从而实现更高清、更流畅的视频效果。研发的算法种类繁多,用途各异,同时B站不同业务对于算法的要求也各不相同。为了能够对各种基本算法进行高效部署和管理,同时向各个业务方提供简单灵活且统一的调用接口,B站研发了一套功能强大的视频图像分析与处理引擎——BANG(Bilibili video/image Analyzing and processiNg enGine)。
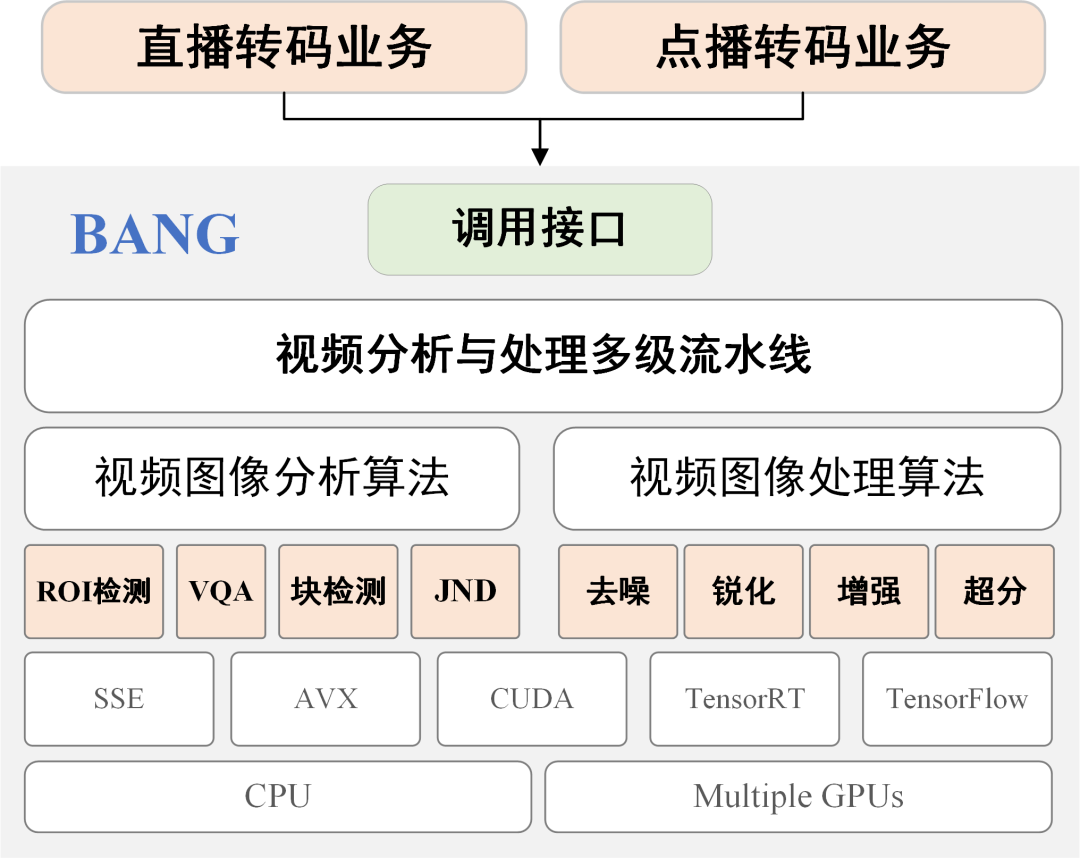
B站视频图像分析与处理引擎
BANG 向下包罗各种视频图像分析与处理算法,向上提供即插即用的调用接口,从而为直播和点播转码等业务提供服务。目前, BANG 已应用到多项视频云转码业务中。比如,在质量可控的点播优化转码系统中,负责感兴趣区域(ROI)检测、传统视频前处理,以及机器学习视觉无损前处理算法的部署;在 S12、TI11 赛事直播转码业务中,负责 深度学习超分和增强算法的部署。
针对直播和点播转码业务的特点,BANG对于算法部署执行的效率有极高的要求。BANG 引擎内部采用了高效的多级流水线架构,同时引入了帧内分块并行、多帧并行等多种并行机制,使整个转码流程可以获取尽可能大的吞吐量。此外,为了充分利用 GPU 资源,BANG提供了基于 CUDA 的核心算子,同时还封装了 TensorRT、TensorFlow 等深度学习模型推理库,从而让核心算法工作在高效率。
对于业务方,BANG 提供了一套统一且简洁的调用接口,可以方便快捷地集成到各种直播、点播的转码系统中,有效避免了重复开发。转码系统调用算法时,只需传入配置视频图像分析与处理逻辑的字符串。BANG 可以自动管理基本算法,生成符合业务需求的视频处理流水线。比如,在 S12 超分算法中,为了避免对三次元人脸过度处理而产生失真,业务方只需通过配置,调用 ROI 检测和人脸区域旁路处理,即可达到人脸保护的效果。下面我们对 BANG 进行更详细的介绍。
01 高效的多级流水线架构
一种典型的视频处理和转码系统是采用单线程,对每一帧依次进行解码、分析、处理和编码操作。虽然这样实现起来很简单,但由于每一帧的处理周期是所有操作的时间之和,因此系统的吞吐量非常低。为了提高系统的吞吐量,我们采用了多级流水线架构。下图中的模型展示了多级流水线提高吞吐量的原理。

BANG 的多级流水线架构可以显著提高吞吐量
如图所示,BANG 为解码、分析和处理阶段分配了独立的缓冲队列,同时为分析和处理单独分配了线程。因此,分析、处理可以与编、解码并行执行。在该流水线架构下,视频转码系统按照如下步骤对每一帧进行处理:
解码器对码流进行解码。解出一帧放入解码队列后,继续解码下一帧。
视频分析线程从解码队列中读取解码帧,然后对视频内容进行分析,获取 ROI、视频质量等信息。分析之后将视频帧和结果送入分析队列。
视频处理线程从分析队列中读取视频帧及其内容分析结果,然后按照配置对视频图像进行处理。处理之后的图像放入处理队列。
编码器读取处理队列中的视频帧,进行编码输出。
上述 4 个操作分别由 4 个线程并行执行。每个线程各司其职,整个流水线在同一时间对多帧进行处理。因此,系统可以充分利用计算资源,显著提高转码系统的吞吐量。
由于输入、输出以及内部处理的缓冲队列由BANG维护,因此调用 BANG 的方法非常简单。业务方只需提供一个返回处理结果的回调函数,并将解码图像一帧一帧送给 BANG 即可。BANG 在收到解码图像后,会对视频帧进行异步处理。处理结果会通过回调函数返回给转码系统。
基于高效的多级流水线结构, BANG 既可以被方便快捷地集成,同时也能取得到非常高的吞吐量。比如,在 S12 4k 超分项目中,超分模型本身的推理速度为 75fps;而采用 BANG 的超分转码系统,端到端也能达到同样的速度。换句话说,在转码业务中,BANG 几乎可以让处理算法发挥出百分之百的效率。
02 基本算法的加速和部署
从上面的示意图可以发现,整个转码系统的吞吐量取决于解码、分析、处理和编码中最耗时的模块。因此,为了进一步提高吞吐量,需要对比较耗时的分析和处理算法进行加速优化。在 BANG 中,视频图像分析和处理算法大致分为两类——基于传统方法的算法和基于深度学习的算法。我们对这两类算法采用了不同的加速策略。
基于深度学习的算法一般是以一个网络模型的形式存在。通过标准的卷积、归一化等操作,此类算法对图像进行端到端的处理。算法逻辑由模型结构和模型参数隐式定义。对于基于深度学习的算法,BANG借助 TensorRT 深度学习推理库进行部署。TensorRT 是 Nvidia 推出的加速深度学习推理的工具集,主要包含模型优化工具和运行时推理库。在 Nvidia 系列显卡上,TensorRT可以有效加速模型的推理速度。

Nvidia 关于 TensorRT 的介绍
我们首先利用 TensorRT对各种深度学习模型进行离线优化,将模型转换成 32 位和 16 位混合精度的模型。然后, BANG 调用 TensorRT 推理接口,载入模型文件后,即可进行推理,对图像进行分析和处理操作。实践表明,与TensorFlow 推理库相比,使用 TensorRT 优化和部署模型可以取得约 100% 的加速。不过,TensorRT 还在发展过程中,有一些个性化的操作还不支持。因此,BANG中仍加入了 TensorFlow 推理库,以部署包含特殊操作的深度神经网络。最近,随着 TensorFlow 逐渐式微,PyTorch 不断完善,BANG后续还将加入 PyTorch 推理库,以获得更大的兼容性。此外,考虑到模型推理前后往往涉及数据的基本预处理和后处理,比如像素拷贝、图像缩放、图像块融合等,BANG也利用 CUDA 对这些通用的基本操作进行了 GPU 加速。
虽然深度学习方法具有优异的性能,但其依赖于 GPU 资源,计算量非常大。因此这类方法主要适用于少数热门直播房间的转码业务。对于B站每天需要处理的数十万点播转码任务,目前还无法替代传统算法。传统算法一般由C/C++ 实现后运行在 CPU 上。

SIMD 模式可以在一个指令周期内同时处理多个数据,可以显著加速密集的像素运算
对于传统算法,BANG 采用 SSE、AVX 等系列指令集进行基本操作的SIMD (Single Instruction Multiple Data)加速 。这些基本操作包括像素拷贝、向量元素类型转换、矩阵加法等。加速优化后的基本算子可以显著提高传统算法的执行效率.。
对基础核心算法进行加速,可以减少视频分析和处理的执行时间,提高整个转码系统的吞吐量。
03 帧内分块并行和多帧并行机制
视频图像的数据量非常巨大。因此,对于需要处理所有像素的去噪、增强、超分等操作而言,计算压力极大。有时即使对算法进行 GPU、SIMD 加速之后,单线程处理整张图依然会耗费很多时间,从而影响系统的吞吐量。因此,对于优化后速度低于 60fps的算法,仅仅使用多级流水线架构仍无法满足 1080p 增强或 4k 60fps 超分直播这类任务的实时要求。
为了进一步提高转码系统的吞吐量,我们还需要继续提高图像处理环节的运行速度。在多级流水线架构基础之上,我们引入了子线程机制。在处理线程中开辟多个子线程,让子线程对单帧进行分块并行处理,或者对多帧并行处理。下图展示了两种并行机制进一步提高系统吞吐量的原理。
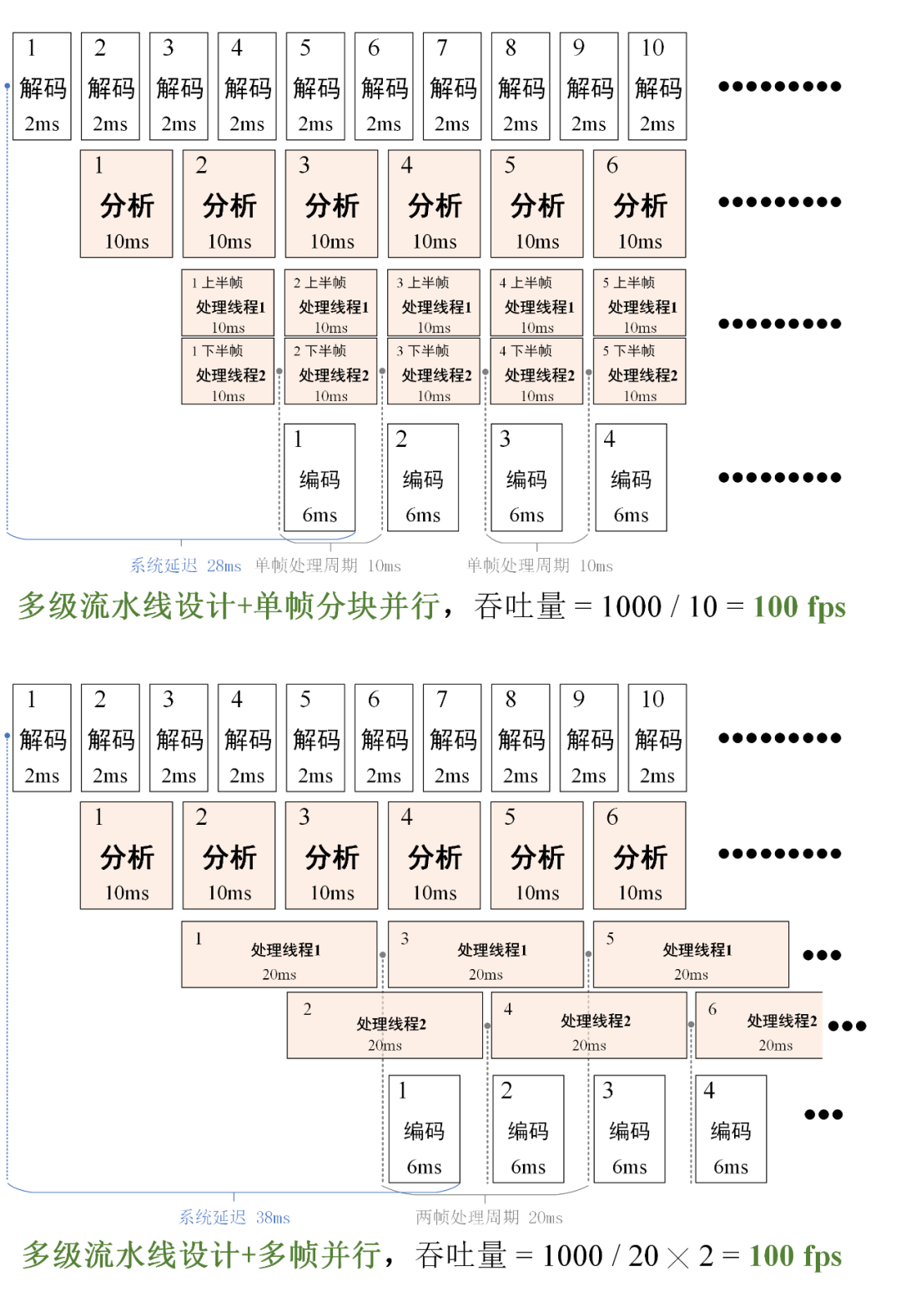
在多级流水线架构中引入多线程机制可以进一步提高系统吞吐量
上图展示了两种不同的对视频图像处理环节进行多线程加速的方案。第一种是将图像分成多个子块,为每个图像块分配一个处理线程。图像块之间可以并行处理。这种并行机制适合去噪、增强等不需要全局语义信息的像素级处理,可以分块处理后再拼接图像。该方案能进一步降低系统延迟,适用于直播场景。
另一种并行机制是同时并行处理多帧。虽然是由单个线程处理整张图像,但同一时间处理多帧也能提高吞吐量。这种机制适合所有处理算法,尤其是需要图像全局信息的算法,比如图像填补修复等。不过相比于单帧分块机制,这种机制的延迟会稍大一些,更加适用于点播场景。使用并行策略之后,视频图像处理的时间可以成倍减少,从而能显著提高系统的吞吐量。分块并行和多帧并行的特点可以总结为下表。

两种并行机制的吞吐量一样,但是系统延迟和适用范围有所不用
当算法需要使用 GPU 时,我们会在每个处理子线程内都实例化一个推理引擎。BANG 支持为每个子线程绑定特定的 GPU 设备,以便业务方在多卡机器上灵活地部署。
当然,在计算资源充足的条件下,上述两种并行机制可以同时启用。此时, BANG 可以同时处理多帧,每一帧内还并行处理多个分块。该模式可以进一步降低处理阶段的运行时间,使系统达到最大的吞吐量。
大幅提高处理阶段的运行效率后,视频图像分析模块往往会成为性能瓶颈。与处理算法不同,视频图像分析算法一般对图像的局部信息并不敏感。因此,可以将原图降采样后再送入分析算法。这样可以显著降低分析的复杂度,但仍能得到与直接使用原图相近的结果。在分析模块中,我们也引入了多帧并行机制,以进一步提升系统吞吐量。
通过引入多线程机制,BANG 可以充分利用计算资源,使整个转码系统的吞吐量成倍增长。比如,在使用深度学习增强算法的 KPL 赛事直播中,没有开启多线程机制时,系统只能使用一张 GPU 显卡,吞吐量只有 45fps 左右。达不到 60fps 的实时要求。而当启动分块并行机制后,可以配置对每张图使用两张显卡分块并行处理。此时,单帧处理时间会减少一半,整个转码系统的吞吐量能翻倍达到90fps,远远超过 60fps 的实时要求。
04 通过字符串配置处理流水线
BANG 中包含很多视频图像分析与处理算法,而不同转码任务的业务需求各不相同,为了应对多变的应用需求,BANG 设计了一种基于字符串的流水线配置方法。所有云转码业务都可以集成同一个 BANG 引擎项目,不同的转码业务只需要传入一个字符串即可自定义满足各自需求的视频图像分析与处理流程。
为了实现这个功能,我们采用工厂设计模式,将所有分析算法与处理算法放入到工厂类中进行管理。在收到配置信息之后,对流水线配置信息进行解析,然后实例化需要执行的基本算法,再装配到一个流水线类中,即可初始化一套具有特定功能的分析与处理流水线。下面来看几个具体的案例。
4.1 S12、TI11 赛事直播:
4k 超分 + ROI 人脸保护 + 硬件编码
在这个直播转码任务中,系统需要对 1080p 60fps 的源视频进行超分,得到 4k 格式视频,再经过硬件编码器压缩后输出码流。那么转码系统就可以通过传入下面的参数配置字符串,来调用 BANG 实现上述超分功能。
BANG="process='dnn_sr S12':scale=2x2:output_cuda_device='0'"
上述配置中 "process='dnn_sr S12'" 表示对解码图像使用深度学习超分算法[3],采用代号为 "S12" 的模型文件。由于该处理会将 1920x1080 的图像变换成 3840x2160 的图像,这个可以通过 "scale=2x2" 进行配置。最后通过 output_cuda_device='0' 设置 GPU 处理后的数据继续保留在 0 号显卡内,直接供后续硬件编码器读取。这样可以避免处理后像素从 GPU 传回 CPU,再从 CPU 上传到 GPU 中进行硬编。此时就可以实现实时超分转码的功能,而对于 TI 11 比赛,可以直接修改模型名称,使用专门针对 DOTA2 画面优化的超分模型即可。
但是使用上述配置进行超分时,会发现处理后画面中人脸的区域可能会被过度增强,出现失真现象。这是由于这些模型是专门针对游戏画面进行优化的,对于非自然的游戏画面内容效果很好,但是对自然场景下的三次元内容效果欠佳。那么此时可以修改 BANG 的配置参数,使用 ROI 检测和画质保护功能。
BANG="analyze=roi:process='dnn_sr S12|-face bicubic':scale=2x2:output_cuda_device='0'"
上述配置中首先使用 "analyze=roi" 在 BANG 中添加一条功能为 ROI 区域检测的图像分析流水线。那么在 BANG 对每一帧进行处理时就会调用检测算法,检测出视频中的人体、人脸、文字等人眼比较感兴趣的内容。"process='dnn_sr S12|-face bicubic'" 表示对整张图进行深度学习超分处理,同时对人脸区域进行简单的放大处理,最后将自然放大的人脸图像块融合回超分图像上,就可以达到对人脸区域的保护效果。下图展示了配置 ROI 人脸保护后,三次元人脸更加自然,同时游戏内容依然清晰。

深度学习超分和 ROI 保护配合使用
4.2 点播优化转码前处理:
传统/深度学习前处理 + 多帧并行
我们在对热门的点播视频进行优化转码[1]的时候,会投入额外的算力,引入一些前处理算法,去除视频画面中的视觉冗余信息,提高整个转码系统的编码性能。这些算法包括传统方法和深度学习算法[2]两大类。和直播转码系统一样,这些算法也可以通过 BANG 集成到点播转码系统中。使用时只需要修改配置参数即可,比如使用 CPU 资源进行传统方法前处理,参数可以配置成:
BANG="process='vod_code_process':frame_threads=8"
该配置表示使用点播转码前处理方法对视频进行消除冗余的处理,同时通过 "frame_threads=8" 配置 8 个帧处理线程,对解码帧进行帧并行处理。在要使用深度学习方法时,也只需要修改配置字符串即可。
此外,BANG 还可以单独工作在分析模式,此时只对视频图像进行分析,输出分析结果,而不进行图像处理。比如在上述质量可控的点播优化转码系统中[1],我们使用 BANG 对视频源文件进行 ROI 检测,并保存 ROI 区域信息,以供后续多次编码重复使用(同一个文件,不同分辨率和帧率的编码过程可以使用同一个 ROI 信息文件,因此只需要进行一次 ROI 检测)。使用下面的配置就可以对视频进行 ROI 检测,同时保存 ROI 信息到 'roi.json' 文件中。
BANG="analyze=roi:analyze_file='roi.json'"
4.3 KPL 赛事直播:
1080p 增强 + 帧内分块并行
对于 KPL 比赛的增强,我们采用了一个更大规模的神经网络,该网络在单张 GPU 下的速度只有 45fps,为了达到 60fps 的实时转码速度,可以配置使用多线程,如下。
BANG="analyze=roi:process='dnn_enhance KPL|-face bicubic':block_threads=2:gpu_list='1,2'"
对于 KPL 比赛视频的增强,我们同样开启了 ROI 保护,防止对人脸过度处理。处理算法调用的是深度学习增强方法,模型使用的是专门针对 KPL 优化的模型文件。同时我们通过 "block_threads=2" 配置 BANG 分配两个处理线程,对每帧进行分块并行处理,通过 "gpu_list" 指定系统编号为 "1" 的显卡处理上半部分,编号为 "2" 的显卡处理下半部分。
在使用这样的配置之后,KPL 增强直播转码即可稳定达到 60fps,为用户提供清晰且流畅的观赛体验。
这种基于字符串的配置方法,可以让多个业务方十分方便和灵活地调用 BANG, 为各自的转码系统提供个性化的视频图像分析和处理的功能,有效避免了重复开发,显著提高了业务迭代效率。
05 总结
为了高效部署和管理大量的视频图像分析和处理算法,同时为直播和点播转码业务方提供简单、一致且灵活的调用接口,我们开发了一套功能强大的视频图像分析与处理引擎——BANG(Bilibili video/image Analyzing and processiNg enGine)。直播和点播转码系统可以很方便地集成 BANG,然后通过基于字符串的配置方法,灵活地定制符合各自业务需求的图像分析与处理流程。通过采用多级流水线架构、分块并行、多帧并行、基础算法加速等技术,BANG极大优化了系统的吞吐量,满足了业务中苛刻的速度要求。未来,我们还将继续完善 BANG,加入更丰富的基本算法,同时对算法进行更深入的优化,将 BANG 打造成更加强大的视频图像分析与处理引擎,为视频业务提供更大的帮助。

