一、背景
最近晚上23:00甚至是凌晨总收到告警通知:磁盘可用量低于20%,这个时候不得不爬起来处理告警。当然这里要提醒大家:对于小问题,运维也绝不要抱着侥幸的心理,因为只有痛过才知道。
磁盘类告警只是我们诸多告警中的冰山一角,虽然我们有值班人员甚至是运维团队支撑,但是也不能因为这种小问题就分散注意力,这时我们就需要考虑如何通过自动化实现。
针对这种情况,我们通常会想到以下几点:
在告警机器上设置定时任务
编写脚本压缩日志或清理磁盘空间
这种方案虽然可行,但是试想下:如果我们管理的是上千台机器且目录结构混乱,那么我们面临的将是上千个脚本及定时任务,这个工作量是非常大的。
运维累都是有原因的,此时就可以轮到故障自愈出场了。
二、故障自愈
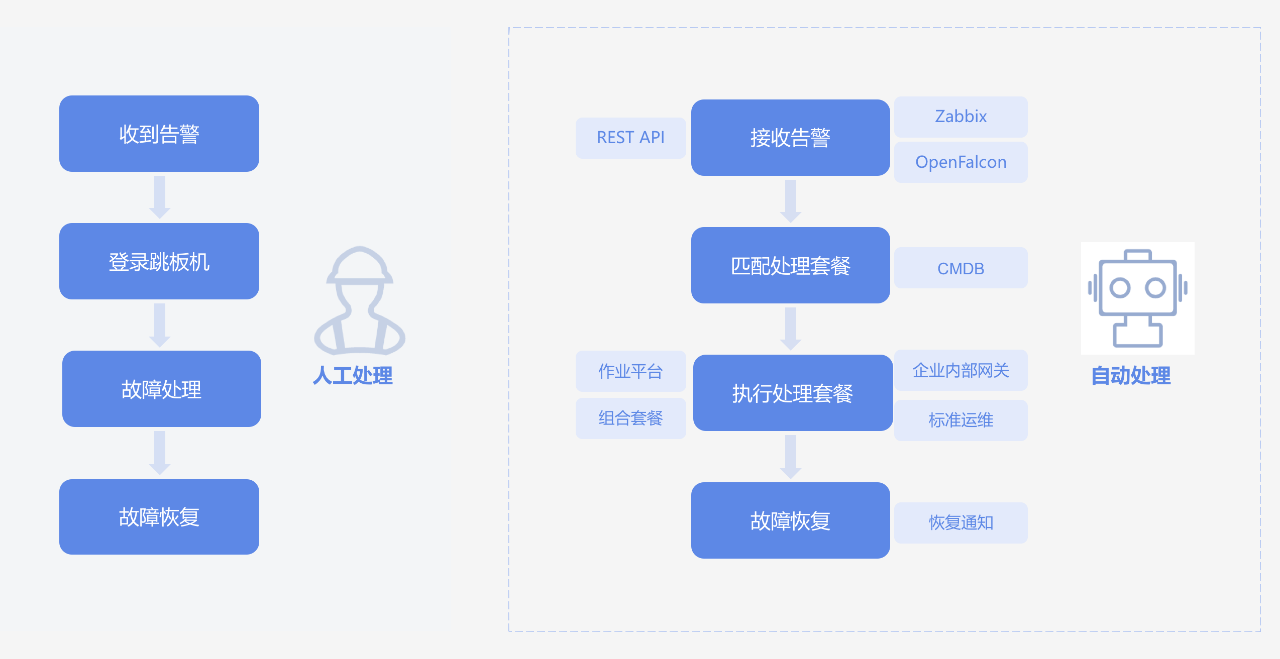
如图所示,对于生产故障,运维标准的处理流程是收到告警、登录跳板机、故障处理、故障恢复,整个过程都是通过人工手动处理。而故障自愈则是接受监控平台的告警定位,匹配预设的故障处理流程,进而通过自动化手段实现故障的自动恢复。
在认识故障自愈后,我们需要考虑的就是如何让运维管理的生产环境更广泛地接入故障自愈,而不是只针对单一的机器或某一类故障。因此在正式接入故障自愈前,我们还有很多的工作要做。
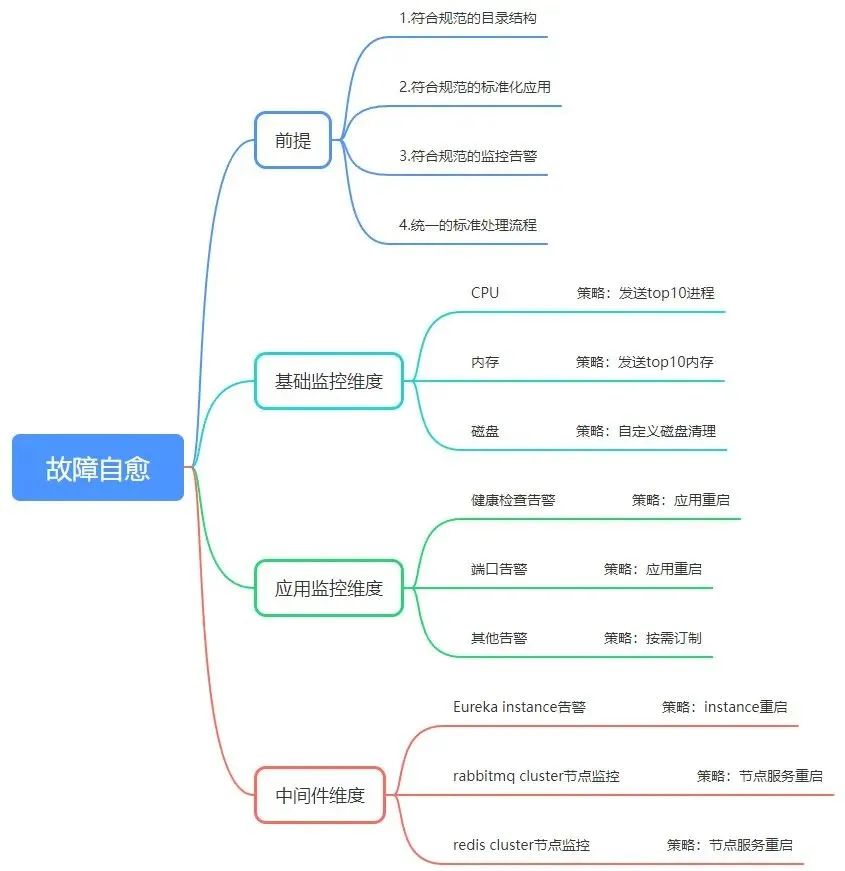
三、前提
为满足故障自愈通过自动化手段处理故障,我们必须提前制定一系列的流程规范:
1)目录管理规范
标准的目录结构,接入故障自愈后可以用一套自动化脚本管理所有文件资源。
2)应用标准规范
标准应用规范,接入故障自愈后可以用一套自动化脚本管理所有应用。
3)监控告警规范
标准的监控告警规范,通过告警通知,无论是运维团队或自愈平台,都能通过告警通知更快速的定位问题。
4)标准的故障处理流程
标准的故障处理流程,不仅可以帮助我们更快速地解决问题,而且可以帮助我们建立起运维团队的知识库。
这些流程规范不仅是故障自愈,也是我们日常运维工作过程中需要持续关注的,这也意味着这些基础性的工作是多么的重要。
四、监控平台
监控平台作为整个故障自愈的源头,必须满足快速准确定位故障的要求,因此就需要在多个维度提供可靠的监控。
1)硬件监控维度
此类监控故障自愈一般无法接入,仅作为辅助手段帮我们及时发现问题。
2)基础监控维度
基础监控主要是对CPU、内存、磁盘等资源使用情况进行监控,接入故障自愈后可发送占用资源的前10进程及自定义的磁盘清理策略。
3)应用监控维度
应用监控主要是对应用状态进行监控,如健康检查、端口、其他自定义告警,接入故障自愈后可对应用进行重启。
4)中间件维度
中间件维度主要是对集群的健康状态进行监控,如eureka instance、rabbitmq集群各节点服务、redis集群各节点服务等,接入故障自愈后可对各节点的服务进行处理。
当然根据监控平台的维度和粒度,我们可以将更多的故障场景接入故障自愈,这个随着我们运维经验的增多会不断丰富。
五、故障自愈平台
1、多告警源
故障自愈的源头是监控平台,因此我们希望故障自愈平台不能是只针对某一特定的监控平台,因此它一定是多源的,这也符合当今监控工具的发展趋势。新的业务、系统和场景会催生新的监控需求,企业未来监控一定是多种监控产品并存,构建功能可持续成长的监控平台才能适应满足运维监控需求。
当今主流的监控工具如下:
Zabbix
Nagios
Open Falcon
Prometheus
等等
当然除了满足与监控工具对接,还要兼具REST API等方式接入。
2、统一数据源
试想一个场景,通过监控平台发送的告警通知,我们可以快速定位到业务、应用、IP,那么故障自愈平台如何接入这些资源呢?因此我们就需要一个统一的数据源,为监控平台、故障自愈平台等上层应用提供可靠的权威数据源,此时CMDB就可以担任如此重要的角色。
在 ITIL 体系里,CMDB 是构建其它流程的基石,为应用提供了各种运维场景的配置数据服务。它是企业 IT 管理体系的核心,通过提供配置管理服务,以数据和模型相结合映射应用间的关系,保证数据的准确和一致性;并以整合的思路推进,最终面向应用消费,发挥配置服务的价值。
CMDB的建设是一个非常痛苦的过程,虽然我们是站在巨人的肩膀上直接使用其能力进行纳管资源,但其实也是走了很多弯路的:
运维团队内部的认可
按部门、角色对基础设施的职责划分
CMDB的管理规范
CMDB如何按组织架构对环境、部门、业务、应用等情况划分
如何更合适的纳管物理机、虚拟机、网络设备、数据库、中间件等资源
CMDB如何为架构提供数据支撑
以上这些问题也只是在使用推广阶段我们所遇到的,因此在很多情况下CMDB都从万众期待走向了置之不理,但“拨开云雾见天日,守得云开见月明”,随着我们不遗余力的尝试与调整,CMDB 最终还是扛下了所有,发挥了它真正的价值。
3、故障处理
有了统一的数据源,剩下的操作就是如何进行故障处理了,此时就需求故障自愈平台能够远程执行脚本。在日常运维工作中,我们一般通过以下几种方式:
Ansible、SaltStack等自动化运维工具
中控机通过ssh远程执行命令
以上是我们通常使用的手段,但是还有更高级或更优雅的方式供我们参考:
集成CMDB的统一作业平台
Jenkins流水线参数化构建
当然了,“不管黑猫白猫,能捉老鼠的就是好猫”,只要是适合当下运维能力的任何方式都可以。不要一味地追求高大上,给我们带来其他额外的工作负担。
4、结果通知
无论最终的故障处理是否成功,我们都需要知道结果来决定是否要人工干预,因此我们希望处理结果能够对接多种渠道通知,如:
邮件通知
微信通知
钉钉通知
短信通知
电话通知
等等
六、总结
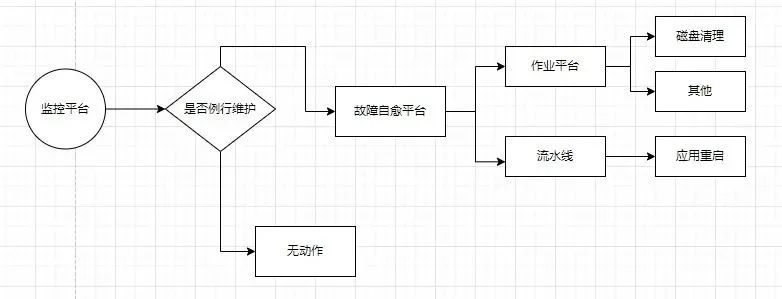
从上图我们可以看到,故障自愈虽然可以帮助我们解决很多问题,但其也只是问题处理过程中的一个环节,例如例行维护期间我们需要做到不触发故障自愈,否则还可能引起一些不必要的问题。因此,故障自愈还需和其他组件做好密切的对接,这就通过运维管理人员进行调度了。
最后需要明确的是,故障自愈只是运维过程中的一种手段而已,如何将其更广泛的应用还需运维本身去脚踏实地地去实践摸索。

