一、 背景概述
框架Dashboard是一款携程内部历史悠久的自研监控产品,其定位是企业级Metrics监控场景,主要提供用户自定义Metrics接入,并基于此提供实时数据分析和视图展现的面板服务,提供可定制的基于时间序列的各类系统级性能数据和业务指标数据的看板。还可以提供灵活的数据收集接口、分布式的大容量存储和灵活的展现方式。
由于时间较早,那时候业界还没有像样的TSDB产品,类似Prometheus,InfluxDB都是后起之秀,所以Dashboard选型主要使用了HBase来存储Metrics数据。并且基于HBase来实现了TSDB,解决了一些HBase热点问题,同时将部分查询聚合下放到HBase,目的是优化其查询性能,目前看来总体方案依赖HBase/HDFS还是有点重。
近些年,随着携程监控All-in-One产品的提出。对于内部的Metrics存储统一也提出了新的要求。由于Dashboard查询目前存在的诸多问题以及Metrics统一的目标,我们决定替换升级Dashboard现有的HBase存储方案,并且在Metrics场景提供统一的查询层API。
二、 整体架构
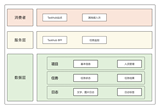
Dashboard产品主要分了6个组件,包括dashboard-engine,dashboard-gateway,dashboard-writer,dashboard-HBase存储,dashboard-collector,dashboard-agent。目前实时写入数据行数6亿条/分钟,架构图如下:
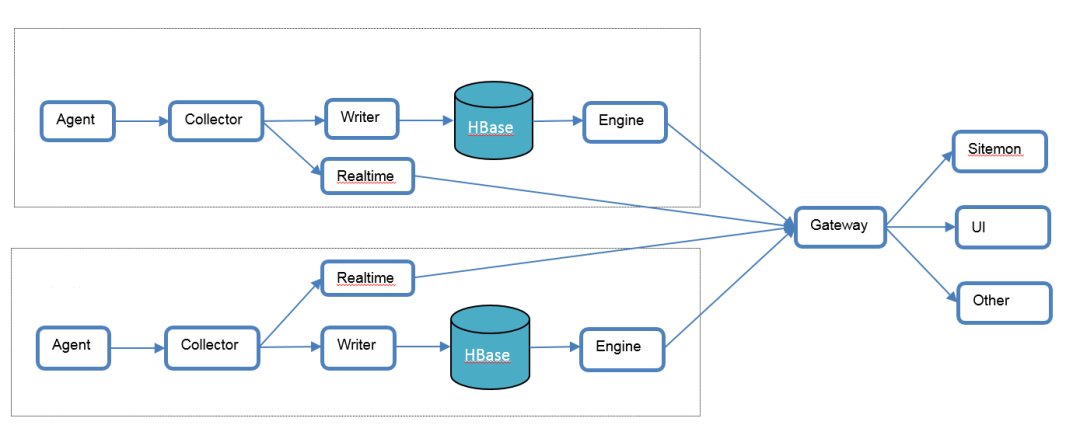
dashboard-engine是查询引擎。
dashboard-gateway是提供给用户的查询界面。
dashboard-writer是数据写入HBase的组件。
dashboard-collector是基于Netty实现的Metrics数据收集的服务端。
dashboard-agent是用户打点的客户端,支持sum,avg,max,min这几种聚合方式。
dashboard-HBase是基于HBase实现的Metrics存储组件。
产品主要特性如下:
支持存储精确到分钟级的基于时间序列的数据。
单个指标数据可支持多个tag。
展现提供任意形式的视图同时可灵活基于tag进行分组。
三、 目前的存在问题
基于HBase的Metrics存储方案虽然具有良好的扩展性,比较高的吞吐,但是随着时间发展,已经不是最优的TSDB方案了,可以归纳总结为如下几个痛点。
在TSDB场景查询慢,整体表现不如专业的TSDB。
HBase热点问题,容易影响数据写入。
HBase技术栈运维操作很重。
采用自研协议,不支持业界标准的Prometheus协议,无法和内部All-in-one监控产品较好的融合。
四、 替换难点
系统写入数据量大,6亿条/分钟。
Dashboard数据缺乏治理,很多不合理高维的metrics数据,日志型数据,经过统计,整体基数达上千亿,这对TSDB不友好,这部分需要写入程序做治理。如图2所示是top20基数统计,有很多Metric基数已经上亿。
Dashboard系统存在时间久,内部有很多程序调用,替换需要做到对用户透明。

五、 替换升级方案
从上面的架构来看,目前我们替换的主要是dashboard-writer和dashboard-HBase这两个最核心的组件。为了对用户的平滑迁移,其他组件稍作改动,在dashboard-engine组件上对接新的查询API即可替换升级成功。对于用户侧,查询的界面dashboard-gateway和打点的客户端dashboard-agent还是原有的模式不变,因此整个的替换方案对用户透明。具体如下:
1.1 dashboard-HBase升级为dashboard-vm
存储从HBase方案替换成VictoriaMetrics+ClickHouse 混合存储方案:
VictoriaMetrics是兼容主流Prometheus协议的TSDB,在TSDB场景下查询效果好,所以会接入绝大多数TSDB数据。
基于ClickHouse提供元数据服务,主要为界面的adhoc查询服务,原来这部分元数据是存储在HBase里面,新的方案采用ClickHouse来存储。元数据主要存储了measurement列表,measurement-tagKey列表,measurement-tagKey-tagValue列表这三种结构,目前在ClickHouse创建了一张表来存这些元数据。

ClickHouse存储少量日志型的数据
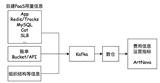
由于长期缺乏一些治理,Dashboard还存储了一些日志型数据,这类数据是一些基数很大但数据量少的数据,不适合存储在VictoriaMetrics。为了实现所有数据透明迁移,这部分数据经过评估,通过白名单配置的方式接入ClickHouse来存储,需要针对每一个接入的日志型指标来创建表和字段。目前的做法是按照BU维度来建表,并且针对指标tag来创建字段,考虑到接入的日志型指标数量少,所以表的字段数量会相对可控。用机票FLT的表结构举例如下图。

1.2 Dashboard-writer升级为Dashboard-vmwriter
Dashboard-collector会分流全量的数据到Kafka,Dashboard-vmwriter的工作流程大致是消费Kafka->数据处理->数据写入存储。Dashboard-vmwriter主要实现了以下几个核心的功能:
Metrics元数据抽取功能,负责抽取出measurement,tagKey,tagValue写入ClickHouse的mtv本地表。这块元数据存储主要依赖了Redis(用于实时写入)和ClickHouse(用于查询)。
指标预聚合功能,用于加速查询。对接公司内部的配置中心来下发预聚合的配置,配置格式如下。
下面的配置会生成ClusterName和appid这两个维度组合的credis预聚合指标。

配置下发后,Dashboard-vmwriter会自动聚合一份预聚合指标存入VictoriaMetrics,指标命名规则为hi_agg.{measurement}_{tag1}_{tag2}_{聚合field}。同样的,查询层API会读取同样的预聚合配置来决定查询预聚合的指标还是原始的指标,默认为所有的measurement维度都开启了一份预聚合的配置,因为在TSDB实现中,查一个measurement的数据会扫描所有的timeseries,查询开销很大,所以这部分直接去查预聚合好的measurement比较合理。
数据治理:异常数据自动检测及封禁,目前主要涉及以下两方面:
(1)基于HyperLogLog的算法来统计measurement级别的基数,如果measurement的基数超级大,比如超过500万,那么就会丢弃一些tag维度。
(2)基于Redis和内存cache来统计measurement-tagKey-tagValue的基数,如果某个tagValue增长过快,那么就丢弃这个tag的维度,并且记录下丢弃这种埋点。Redis主要使用了set集合,key的命名是{measurement}_{tagKey},成员是[tagValue1,tagValue2,… , tagValueN],主要是通过sismember来判断成员是否存在,sadd来添加成员,scard判断key的成员数量。
写入程序会先在本地内存Cache查找Key的成员是否存在,没有的话会去Redis查找,对Redis的qps是可控的,本地Cache是基于LRU的淘汰策略,本地内存可控。整个过程是在写入的时候实时进行的,也能保证数据的及时性和高性能,写入Redis的元数据也会实时增量同步到ClickHouse的mtv表,这样用户界面也能实时查询到元数据。
(3)数据高性能写入,整个消费的线程模型大概是一个进程一个kafka消费线程n个数据处理线程m个数据写入线程。线程之间通过队列来通信,为了在同一个进程内方便数据做预聚合操作。假设配置了4个数据处理线程,那么就会按照measurement做hash,分到4个bucket里面处理,这样同一个measurement的数据会在一个bucket里面处理,也方便后续的指标预聚合处理。

经过程序埋点测算,正常情况下整体链路的数据写入延迟控制在1s内,大约在百毫秒级。
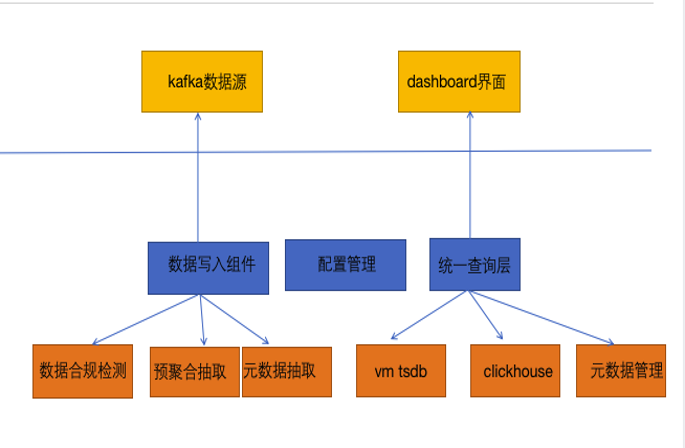
1.3 Metrics统一查询层
契约上,兼容了Dashboard原来的查询协议,也支持标准的prometheus协议。
实现上,封装了VictoriaMetics+ClickHouse的统一查询,支持元数据管理,预聚合管理,限流,rollup策略等。
查询层主要提供了以下四个核心接口。
Data接口:根据measurement,tagKey,tagValue返回时序数据,数据源是VictoriaMetrics。
Measurement接口:返回limit数量的measurement列表,数据源是ClickHouse。
Measurement-tagKey接口:返回指定measurement的tagKey列表,数据源是ClickHouse。
Measurement-tagKey-tagValue接口:返回指定measurement和tagkey的tagValue的列表,数据源是ClickHouse。
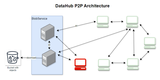
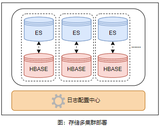
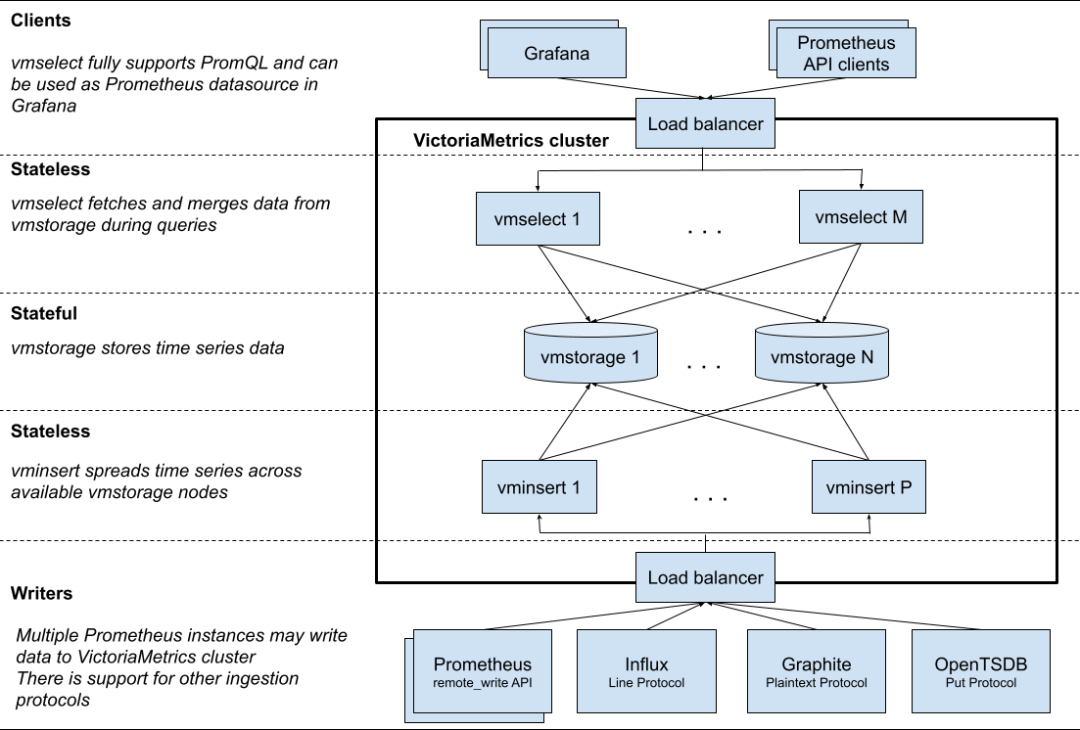
如下图第一张所示是新的存储架构,第二张是VictoriaMetrics自身的架构。
需要注意到,整个数据写入层是单机房写单机房的存储集群,是完全的单元化结构。最上层通过统一的数据查询层汇总多个机房的数据进行聚合输出。在可用性方面,任何单一机房的故障仅会影响单机房的数据。
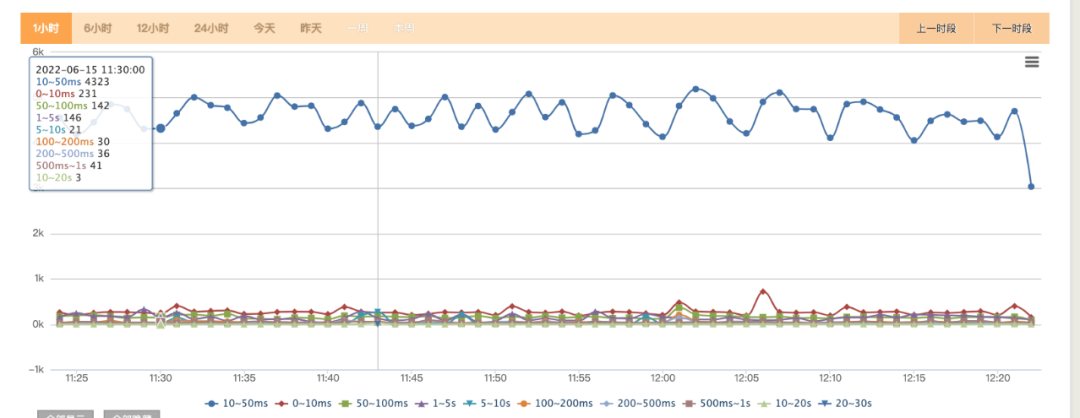
六、 替换前后效果对比
(1)替换后的查询耗时从MAX,AVG,STD提升近4倍。查询耗时大多落在10-50ms之间。相比之前HBase经常查询超时,整体查询的稳定些也好了很多,见图6,7。
(2)写入稳定性提升,彻底解决了因为HBase热点引发的数据积压。
(3)替换后支持了更多的优秀的特性,可以基于promQL实现指标的逻辑计算,同比环比,模糊匹配等。

七、 未来规划
(1)统一查询层接入所有Metrics数据,除了Dashboard,目前内部还有HickWall,Cat有大量Metrics数据没有接入统一查询层,目前采用的是直连openrestry+VictoriaMetrics的方式,openrestry上面做了一些简单的查询逻辑,这块计划后续接入统一查询层,这样内部可以提供统一的元信息管理,预聚合策略等,达到Metrics架构统一。
(2)提供统一写入层,总体Metrics目前是近亿级/秒,这块写入目前主要是基于Kafka消费进存储的方式,内部这块写入是有多个应用在处理,如果有统一的写入层那么就能做到写入逻辑统一,和查询层的查询策略也能做到联动,减少重复建设。
(3)Metrics的存储统一层提供了较好的典范,内部的日志存储层统一也在如火如荼的进行中,也会往这样的一个方向发展。