KubeZoo是由字节跳动自研的Kubernetes轻量级多租户项目,它基于协议转换的核心理念,在一个物理的Kubernetes Master上虚拟多个租户,具备轻量级、兼容原生API、无侵入等特点,是一种打造Serverless Kubernetes底座的优良方案。
https://github.com/kubewharf/kubezoo
从 2014 年开源至今,Kubernetes 已经成为容器编排领域的事实标准,为开发者进行应用编排、提高资源利用率提供了极大便利。但面对集群管理,如何提升多租户集群管理能力仍是困扰开发者和企业的一个关键问题。
以私有云为例。在这类环境中,企业的云原生基础设施大多被微服务平台、大数据、机器学习和存储云原生等平台占据,它们对上层用户屏蔽 Kubernetes 的细节,呈现的是各自的接口和体验。
虽然屏蔽底层有助于开发人员更专注于业务本身,但现实中仍有不少业务需要独立的 Kubernetes 构建其系统所运行的环境设施,这些业务通常形态各异,资源体量小,但是却要求独占和完整的 Kubernetes。如何提供和管理这些小 Kubernetes 集群成为一个痛点,Cluster API 提供了集群自动化管理的能力,但是对基础设施成熟度有较高的要求。
无独有偶,在公有云上,各大云供应商托管着客户成千上万的集群,但是超过 100 个 ECS 节点的集群寥寥无几。事实上,绝大部分 Kubernetes 集群的规格都非常之小,几十核、上百核是常态。相比计算资源,托管版的 Kubernetes 的控制面占据了一定的资源,如高可靠的 Master 和 etcd 等等,这些免费的组件占据了相当比例的成本。
因此,增强 K8s 集群控制面的多租户能力已经成了一个现实问题:
从运维视角来看,即使 Kubernetes 具备自动化的集群生命周期管理,但是各项控制面组件的维护、升级,和周边庞杂设施的交互,对开发人员来说仍是棘手的问题;
随着机器学习任务、大数据平台接入云原生基础设施,基于 Kubernetes 打造的系统底座需要提供更快速、更低成本、更高效的管理 Kubernetes 集群的能力。
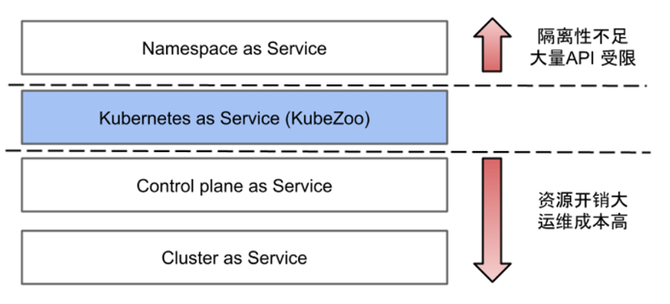
Kubernetes 多租户模型简介
伴随云原生技术的发展和推广,社区内已经先后涌现出多种方案,提供了不同层次的多租户能力,并在特定场景下具备一定优势。此前社区 Kubernetes Multi-Tenancy Working Group 曾进行了梳理归纳,定义了如下 3 种 Kubernetes 多租户模型。
Namespace as a Service(NaaS)

Namespace 是 Kubernetes 原生的资源,提供了原生的基于命名空间的多租户能力。众所周知,Kubernetes 的对象分为两种类型:
第一种是 namespace scope,比如常见的 deployment、pod 和 pvc 等,这类资源通常比较常用,为一般的用户所使用;
第二种是 cluster scope,比如 pv、clusterrole 等,这类资源通常需要更高的权限,一般由管理员管理。
由于这些比较通用的资源可以划分到某个 namespace 下,而 namespace 具备一定的权限和视图隔离能力,管理员可以通过为不同的租户分配不同的 namespace,并合理的设定租户的 RBAC、Network Policy 和 Quota,实现租户之间资源和视图一定程度的隔离。
这种方案的优点是不同租户共享相同的控制面和计算资源池,运维成本低、管理高效,比较适合仅依赖 namespace scope API 的私有云场景;缺点则是多个租户共享一个 K8s 集群,每个租户被限定在自己的 namespace,租户一般只能访问 namespace scope 的资源,通常不具备 cluster scope 的权限,故 API 访问很受限。
Cluster as a Service(CaaS)

顾名思义,Cluster as a Service 则是为每个租户分配一个完整的集群,包括独占的控制面和数据面。如此每个租户都有独立的 Master 和计算节点,该 Master 可以通过 Cluster API 等方式完成租户 Master 的生命周期管理。
在实现上,Master 可以容器化部署,也可以部署在虚拟机或者物理机上;而计算节点通常为虚拟机或者物理机。如此每个租户拥有一套独立的控制面组件(apiserver, controller-manager, scheduler, etcd),租户间完全隔离,互相不干扰,安全性和隔离性得到绝对的保障;缺点为每个租户的管理成本和资源成本较高。
Control Planes as a Service(CPaaS)
不难看出,NaaS 多租户之间完全共享控制面和数据面,而 CaaS 的控制面和数据面是完全隔离的。那么有没有一种介于此的中间形态,在隔离性和灵活性之间能得到良好的权衡?
这就是社区提出的第三种模式:Control Planes as a Service,在此形态下每个租户拥有独立的 Master(又称为 virtual cluster),因而它们在控制面上是独占和隔离的,也可以拥有灵活的 K8s 版本;但是在数据面上,各个租户共享相同的资源池。
这种形态典型的代表是 Virtual Cluster 项目,它在一个名为 supercluster 的 K8s 集群上容器化部署租户的控制面,因而各个租户拥有完整而隔离的 Kubernetes Master,可以自主的管理 namespace scope 和 cluster scope 的各类资源;但是在计算资源上,各个租户共享 supercluster 的计算资源池,虽然在数据面未达到彻底隔离的形态,但是胜在共享统一的资源池,利于提升资源效率和灵活性。
小结

综上深入分析,不难发现不同多租户方案各有侧重的场景,都尝试在成本、效率和安全之间进行权衡。上述方案一定程度提供了路径手段,但是依旧不够完美。
在字节跳动业务发展过程中,由 K8s 集群控制面的多租户功能带来的诸多困扰同样存在,基础架构团队期望近乎零成本、兼容 Kubernetes 原生 API 的多租户能力:一方面,它要具备极低的资源和运维成本、秒级的生命周期管理、原生的 API 和安全能力,能稳定支撑业务发展;另一方面,它也能面向团队技术演进方向 Serverless 展开设计,更好地兼容未来。
为了达成这个目标,基础架构团队推出了轻量级多租户解决方案 KubeZoo,并把它开放给社区。
KubeZoo 简介
本章重点介绍 KubeZoo 的架构和核心思想,包括总体架构、租户管理、控制面多租户(协议转换)和数据面多租户等等。
理念简介
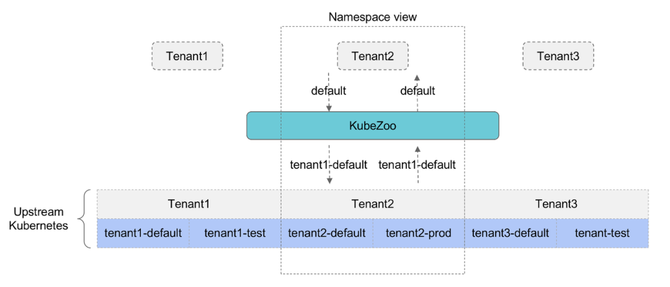
KubeZoo 基于“协议转换”核心理念实现控制面多租户功能,通过在资源的 name/namespace 等字段上增加租户的唯一标志,从而解决不同租户的同名资源在同一个上游物理的 K8s 冲突问题。
如前文所述,Kubernetes 的资源大致可以分为两大类型:namespace scope 和 cluster scope。其中,对于 namespace scope 的资源,同一种资源在相同的 namespace 下命名唯一;对于 cluster scope 类型的资源,同一种资源的命名全局唯一,不可重复。
在同一个 Kubernetes 下,开发人员可以在 namespace scope 资源的 namespace 上增加租户的前缀,在 cluster scope 资源的 name 上增加前缀,通过保证不同租户的前缀不一样,最终解决不同租户在资源命名重复冲突的问题,这种思想和 Linux 内存管理有些异曲同工之妙。
架构概览
KubeZoo 作为一个独立的服务部署于 Kubernetes 前端,对用户提供统一的访问入口,它接受用户的请求,并将请求经过处理后转发给后端的 Kubernetes,进而由上游的集群真正完成资源的表达,最终将结果返回给用户。

在具体结构上,KubeZoo 由一个 kubezoo-server 进程和 etcd 组成,其中 KubeZoo 作为无状态组件,可以以多主的形式部署,具备良好的横向扩容能力,etcd 主要提供租户的元信息的存储,就数据体量上非常轻,同时访问频率也较低,理论上不存在性能相关瓶颈。
KubeZoo 重点提供了控制面的隔离,对数据面的实现并没有相关的约束。如果控制面为常规的 Kubernetes 节点池,那么数据是共享的,隔离性等同 CPaaS;如果数据面采用云上的弹性容器服务,如 AWS Fargate、Aliyun ECI、火山引擎 VCI 等,则可以借用公有云的基础设施完成计算、存储和网络的隔离和表达能力,同时具备良好的弹性能力,这也是本文推荐的后端数据面载体。
租户管理
KubeZoo 内置 Tenant 对象,用于描述租户的基本信息,相关的结构体如下。其中 name 是必须字段,全局唯一,长度固定 6 位字符串(包括字符或者数字),理论上可以管理 2176782336 个租户(36 ^ 6),Tenant 对象存储于 KubeZoo 的 etcd 中:

KubeZoo 提供证书签发的功能,管理员拥有 Tenant 生命周期管理的能力。每当管理员创建租户后,即为该租户签发一份 X509 证书,证书中包含了租户的信息,如名字等等,并写入 annotations;同时将每个租户内置的 namespace、rbac 等同步到上游的 K8s 中。
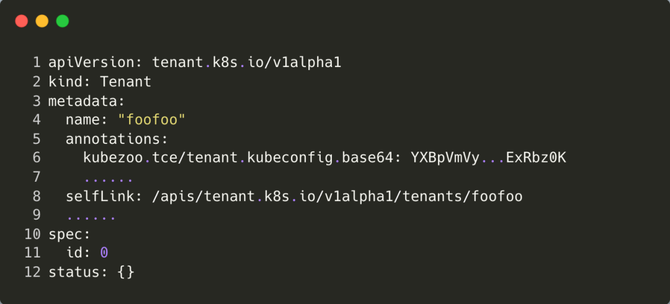
每当管理员删除租户时,会触发租户资源回收,KubeZoo 删除上游 K8s 该租户的所有资源,并清理 KubeZoo 侧的元信息。
由于租户的生命周期管理本质上是 Tenant 对象元信息的管理、证书签发和资源同步,因而过程简洁,无需创建物理的 Master / etcd 和计算资源池,因而其具备轻量级、秒级的海量租户生命周期管理能力。
安全设计
认证
KubeZoo 支持证书(X509)和 ServiceAccount 两种类型的凭据。这两种凭据均属于 PKI(Public key infra)token,故 KubeZoo 只需要和上游 K8s Master 共用相同的 CA 即可实现凭据的认证功能,并提取出租户信息。
对于管理员签发的 X509 证书,每当创建租户时,会将 Subject.OrganizationalUnit 字段设置为租户名称,进而完成证书的签发。每当 KubeZoo 收到租户的请求时,首先认证证书的有效性,进而解析证书中 OrganizationalUnit 字段,判断租户的真实性。
对于租户签发的 Service Account(SA) 证书,由于其本质上是 jwt token,解析后包含了 namespace 字段,因为上游 K8s 集群中租户的 namespace 已经包含了租户信息前缀,故租户签发的 SA 同样包含了租户信息,KubeZoo 首先认证 jwt token 的有效性,进而从 namespace 中解析出租户信息,进而判断租户的真实性。
流量管理
KubeZoo 基于令牌桶的原理实现租户的流控管理,包括租户流量隔离,即租户互不干扰,恶意租户(短时间内发送大量 API 请求)不会影响其他租户;租户流量加权,即允许管理员为不同租户设置不同权重,允许高优租户发送更多并发请求。
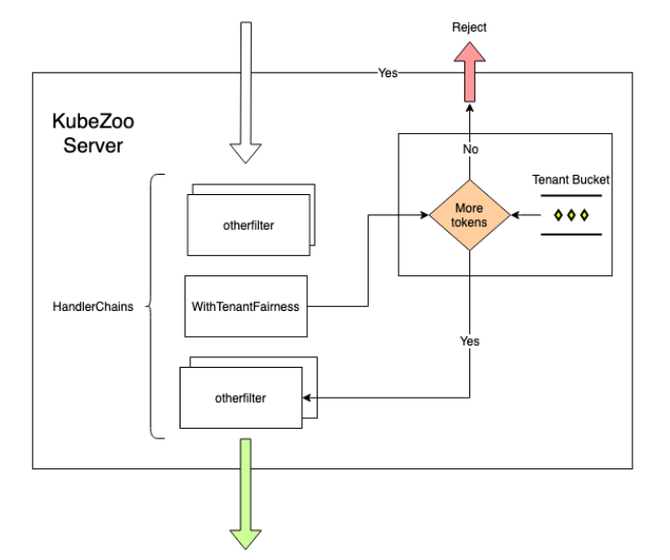
管理员创建租户时通过在 Tenant annotation 中的 tce.kubezoo/max-requests-inflight 字段设置来自该租户请求的最大并发数。KubeZoo 会统计当前租户的并发数(令牌数),每当收到来自某个租户的请求时,KubeZoo 会查看该租户下的 bucket 是否有令牌,如果有,则拿取一个并处理相关的需求,请求结束后归还令牌;如果并发数超过上限,即令牌为空,则拒绝该请求。
总结
本文 KubeZoo 基于协议转换的理念为 Kubernetes 多租户提供了一种新的思路,相比已有的方案,它具备轻量级、兼容原生 API 、无侵入等特点,或是一种打造 Serverless K8s 底座的优良方案。

