背景
随着携程酒店数据的膨胀以及个性化需求的增多,每个数据接口个性化的排期开发,因为没有标准化,从需求讨论,数据准备、接口封装、上线调试到接口api说明,期间需要花费大量的时间。一个接口的实现到生产上线至少需要2天甚至更多时间,这个时间成本不得不依赖排期开发;
随着历史接口的迭代,已对外提供的700多数据接口中,其中500多个还在使用,并且每年的增量在100多,开发和维护成本高,特别是在追溯上游离线数据逻辑的时候,过于依赖研发资源;
不同研发团队技术栈不一样,算法相关的研发更多偏向于python开发,对外输出的接口也是由python实现,但公司框架对java接口有更友好的支持,不同技术栈对外输出接口的稳定性存疑,特别是人员流动,团队职责变化后,同时也影响维护成本;
随着业务的发展,各个业务系统的数据需求越来越多,需求响应要求也越来越高;
通过历史接口的分析归类,80%以上的数据接口其实是针对离线数据或者实时数据加上需求方的检索条件返回数据,没有过多的加工逻辑或者过于复杂的业务逻辑在接口中实现;
为了能更快速支持业务个性化需求和降低研发成本,起到降本增效的效果,同时避免烟囱式数据接口开发,提高数据复用率,避免同样数据出现同样的多个接口,也避免不同的研发团队拿到同一份数据都在做自己场景的数据接口,减少数据孤岛情况。为此,我们设计了一套符合需求的数据服务平台。
一、平台介绍
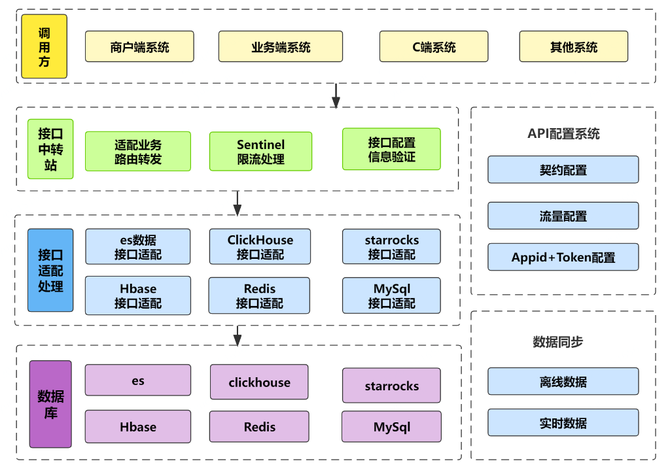
统一数据服务平台依托于公司soa服务基础之上构建,平台实现统一技术方案,降低运营成本,提升了接口稳定性,可维护性和持续性;
运维配置,降低数据接口实现成本,从个性化开发的2d+ 降低到4h甚至更快的上线,这个实现基本上可以不强依赖资源排期;
通过统一数据服务平台可视化界面配置,不依赖java开发人员介入,可由数仓团队产出hive表根据需求配置接口输出;
统一数据源,保证了数据使用的一致性;
为需求方申请接口提供标准模板,提升沟通效率以及需求方对大数据需求的满意度。
系统层面架构图:
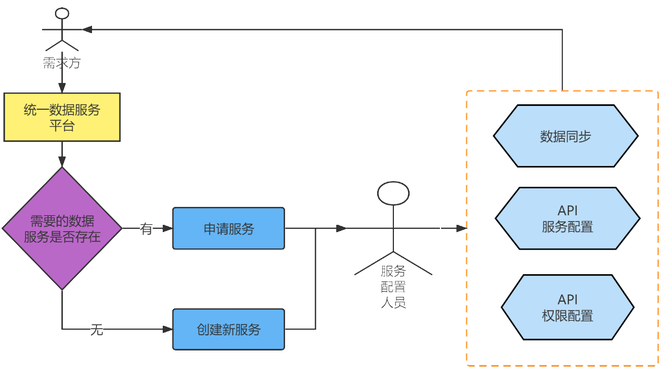
接口的申请配置流程如下图:
二、如何实现
2.1 平台收口
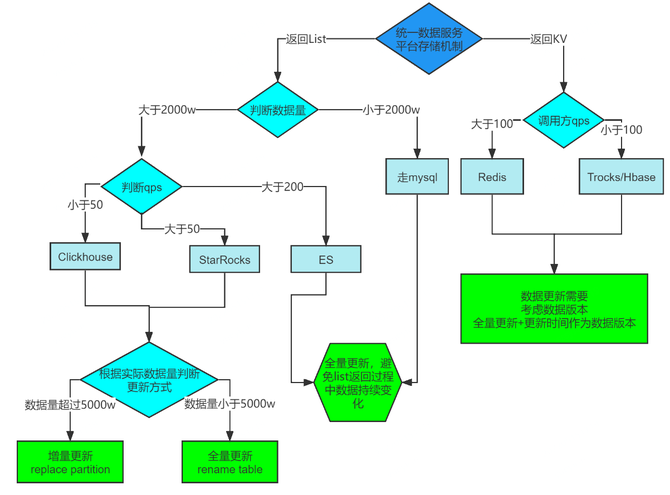
减少数据接口的输出团队和技术方案;另外随着业务量、数据量的增长,业务类型的累积,现在的接口不是完全靠mysql能支撑的,平台统一规划技术方案,调用方不用关心底层服务是用clickhouse,es,starrocks,redis等任何数据库以及相关数据库的技术特性和语法特征。在实际配置中,我们需要结合调用方的场景以及不同的olap数据库的特性和优缺点来选择;比如:
ES:核心,高并发非KV结构的搜索场景;
Redis:核心,高并发KV结构场景;
MySql:核心,千万级以内小表简单查询并且是高并发场景;
starrocks:次核心,QPS不是非常高,单表数据量在千万级,亿级场景;
ClickHouse:非核心, QPS在100以内,数据量在千万级,亿级场景;
Trocks/ Hbase:非核心的KV结构场景;同时,对于不同的数据库,更新机制上也是需要我们注意的哪些适合于全量更新,哪些适合于增量更新;
2.2 加强数据利用
有些数据只要表同步过,下次在其他业务场景使用的时候只要配置不同的查询sql就可以对外提供使用,通过血缘关系的监控,减少离线数据的重复同步,提升一份数据的应用面,从而提升数据的可用性和一致性,让数据复用而不是复制。
2.3 接口安全验证
每个调用方appid需要提前申请对某个接口的应用权限,统一服务平台通过授权token的方式,验证appid+token的权限防止未申请接口权限的应用非法调用,其中appid是通过公司soa框架自动获取避免appid被串改的情况,保证接口数据的安全性和稳定性。
2.4 限流保护
在一个高并发系统中对流量的把控是非常重要的,特别是在统一服务平台,当某个接口因为外部爬虫原因导致流量超过设置的阀值而没有拦住,可能导致整个平台对外输出接口都不可用。
为此,我们引入Sentinel限流机制。Sentinel是面向分布式服务架构的轻量级流量控制组件,主要以流量为切入点,从限流、服务降级、系统负载保护等多个维度来帮助我们保障服务的稳定性。
实现原理是根据指定的时间内生成预先配置好的令牌数,每一个请求都会消耗一个令牌,令牌申领完后就会拒绝服务。目前每一个接口名都会有一个独立的令牌,各接口间限流互相不干扰实现对每个接口的流量控制,qps超过设置阀值接口自动熔断。
2.5 数据缓存
接口的配置信息,这些信息持久化的存入硬盘中,在接口调用时会被频繁使用,如何快速高效的获取这些配置信息,需要使用到缓存机制。通过建立主动和被动缓存,避免服务器负载过高。数据源的配置信息定时缓存,接口在使用时能快速取到基础数据,不需要初始化。
2.6 服务契约统一
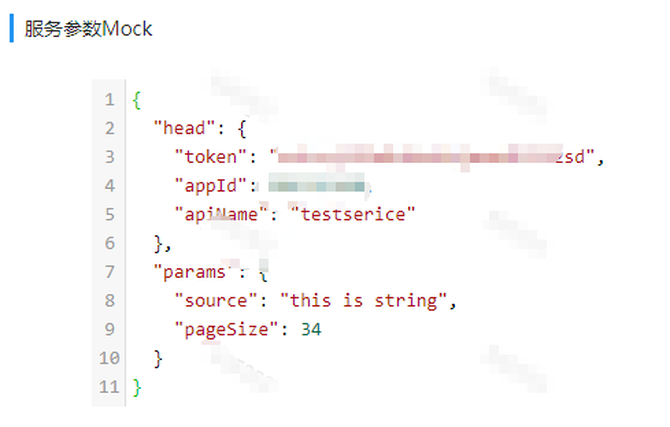
通过本平台调用的接口,现在所有的请求都是由一个入口中来完成。接口收到请求后根据接口的配置信息自动的进行分流处理。请求契约中包含head和params两部分,head负责接口的基本信息,用于服务验证和业务中转。params参数为json字符串参数对象,服务会动态根据json的信息与配置信息匹配进行解析参数。response契约中包含接口成功标志和result部分,其中result为json的字符串参数对象,需要调用方收到后进行解析。
Request如下图所示:
Response 如下图所示:

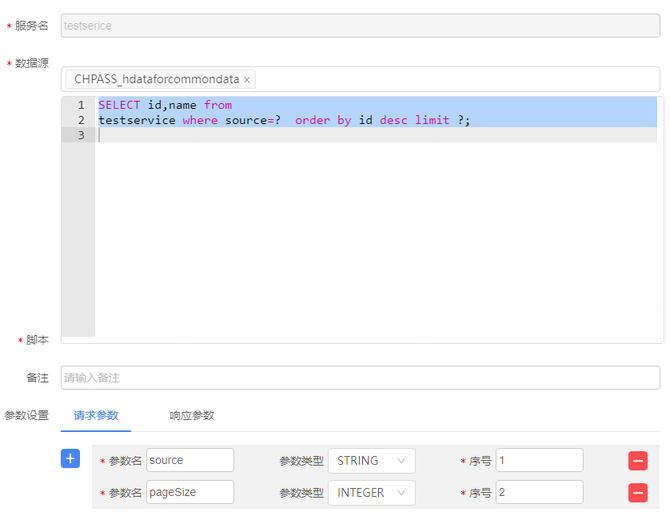
2.7 数据服务配置和映射
一个服务接口由数据源、sql语句、请求参数及响应参数组成。其中sql语句中的参数使用 ?、{序号} 占位符替代,与请求参数一起使用,sql有多少个参数占位符,请求参数就需要配置多少,接口运行时会根据请求的参数自动匹配到sql参数中。响应参数为了在查询结果中映射字段,sql查询输出的结果 ,可以通过映射转换真正想要的输出参数,配置的响应参数就是接口服务返回的查询结果。如下图是配置sql的查询方式:
2.8 契约文档自动生成
个性化接口开发,需要对接口进行解释,告知调用方如何调用。结合接口输入和输出参数都是自定义的特点,定义一套服务文档展示模板,文档中包含所有的调用该接口的详细信息。只要定义好接口后,会动态的生成契约文档,申请使用该服务的团队会通过邮件方式发送信息,节省接口解释成本。文档在线效果如下图,同时也会以邮件形式推送给申请人。

2.9 服务监控
服务接口正常运行后,借助于公司的clog和ck日志框架来监控接口调用情况。Clog监控主是要记录请求接口从开始调用到返回所有的过程记录,包含每个过程节点的调用时长,请求参数及返回参数。方便定位接口request的整条链路。ck监控主是要记录接口层请求的参数,返回的参数和响应时间。每次请求只记录一次,可以统计,监控每个时段调用的次数,接口响应的时长等信息。

2.10 生产运行效果
2021年12月初上线至今,目前对接调用方appid 10个,提供100多个接口服务。请求量随着接口的增加趋势增长,目前每天的请求量达390多万次。每个接口上线周期为半天时间或更短。接口上线只需要根据需求方配置后立刻就可以在线使用,大大的减少了上线的周期。生产接口响应时间91.49%在10ms内,99.99%是在100ms以内。
三、后期展望
现在所有的接口都部署在一个集群,对于一些调用方,我们其实也可以区分高中低三个等级,将高优调用方部署在一个独立集群上,中等调用方部署在一个集群上,低优调用方部署在独立集群上,相互之间资源隔离。
实现测试环境的打通。由于大数据环境大部分只有生产环境,没有测试环境和测试数据,所以统一服务平台现在只能用于生产环境。开发环境或者测试环境无法调用联调,对于调用方只能通过mock的方式测试,这个也是后面我们需要考虑如何利用最低的成本实现测试环境的可用性,让调用方使用起来更加便捷。

