林意群:eBay HDFS架构的演进优化实践
本文根据林意群在【第十二届中国数据库技术大会(DTCC2021)】现场演讲内容整理而成。
讲师介绍:

林意群,亿贝软件工程(上海)有限公司大数据开发工程师,拥有多年大数据从业经验,2019年加入eBay,主要负责eBay HDFS集群性能优化方面的工作。平时也活跃于开源社区,拥有多年参与开源社区的经验。目前主要专注于存储领域的研究和学习,同时也乐于总结分享,在eBay技术公众号,Alluxio官方公众号上发表过多篇技术文章。著有《深度剖析Hadoop HDFS》一书。
本文摘要:
HDFS作为大数据的底层存储系统,能够存储海量的数据并能够对外提供稳定的数据读写服务。eBay HDFS集群发展至今已达到PB规模量级的数据存储,同时目前在支持公司越来越多业务的发展。同样,业务的快速发展对我们的HDFS集群提出了更高的要求和挑战。
eBay HDFS架构经过多年的演进优化,在性能和稳定性上得到了极大的提升。在早期的时候,HDFS集群是以独立集群服务的模式对外提供数据服务。伴随着业务数据规模的快速增长,我们很快遇到了HDFS NameNode的性能瓶颈问题。
随后我们进行了HDFS Federation架构模式的尝试。我们将主集群NameNode的元数据进行了多namespace的拆分,形成多Federation NameNode共同服务的方式。同时在此期间我们持续地在进行HDFS自身的性能调优,使得NameNode的处理性能能够得到进一步地提升。
HDFS Federation架构横向扩展了HDFS集群的整体处理能力,但是不断增多的Federation namespace也加大了我们对此的管理和使用难度。如何更加有效地使用和管理这些namespace的数据成了我们又一个新的需要解决的难题。我们采用了社区RBF(Router-Based Federation)的架构模式来统一管理HDFS Federation。
在RBF架构模式下,引入了中间服务Router来做客户端和NameNode服务端的中间层,底层Federation NameNode对于客户端来说完全透明。基于Router服务的Federation方案使得我们能够更加灵活透明地扩展底层HDFS的服务能力。本文我们将详细讲述eBay HDFS集群架构从单独集群到Federation模式,再到RBF架构模式的演进历程,以及在此期间我们遇到的许多难题和相应的解决方案。
分享大纲:
a.介绍HDFS在ebay的使用现状
b.介绍ebay在生产中遇到的问题,以及我们应对和优化的策略。
c.介绍HDFS Rouer-based federation在ebay的应用。
演讲正文:
eBay Hadoop发展了很多年,目前拥有10+集群,总数在2W+节点以上,其中最大的一个集群HDFS超过5000台机器,总存储达到800PB+,日均Job数在100K+。
随着集群的不断扩大,会面临各种问题与挑战,在eBay HDFS集群演进方面,2019年之前是独立集群模式,随着数据量的增长,在2019年引入Viewfs Federation方案,在2020年遇到了NameNode单点瓶颈问题,我们做了很多集群性能优化,拆分更多Federation集群,在2021年,RBF方案逐步取代Viewfs Federation方式。
在单集群模式时,初始HDFS架构模式是非常简单的。上面是Namespace层,下面是BlockStorage层,各个集群相互独立,在数据量少时,这种部署模式是没有问题的。
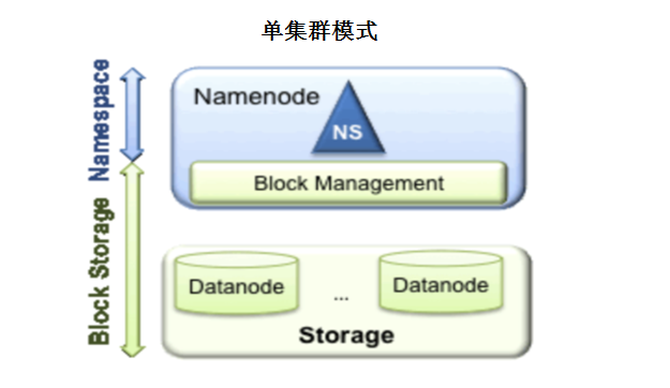
HDFS内部结构设计如下:HDFS有三副本的机制,通过将三个副本分布在两个Rack上。
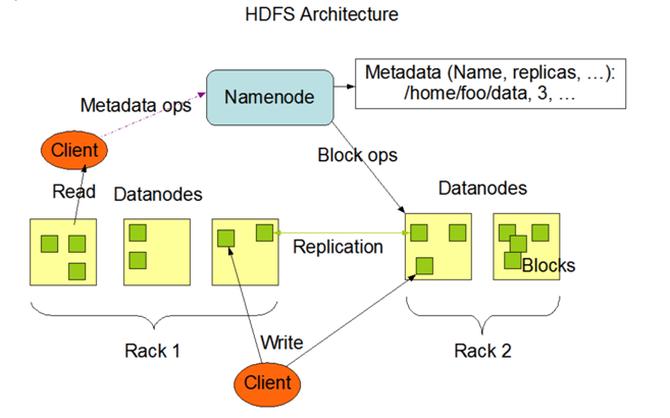
随着数据量的不断增长,HDFS集群面临的挑战也越来越大,如:持续增长的数据存储压力,包括文件数据和元数据;NameNode服务的单点性能瓶颈;多集群的运维管理,数据管理。
在HDFS性能优化方面,我们做了很多尝试,如:
减少HDFS繁重API操作影响:Balancer从Standby NameNode获取blocks操作;Delete操作按照batch size执行的限制;ListStatus操作忽略block location的获取;Snapshot操作拆分为多子目录的管理。
异步化RPC response :RPC的response阶段需要做加密操作,会造成一定的性能损耗,将此过程进行异步化地处理来提前释放NameNode的Handler资源(相关JIRA: HDFS-15486)。
NN锁优化处理:冗余目录锁的去除;SetTimes操作写锁转读锁;ReadWrite callqueue实现(相关JIRA: HDFS-15553)。
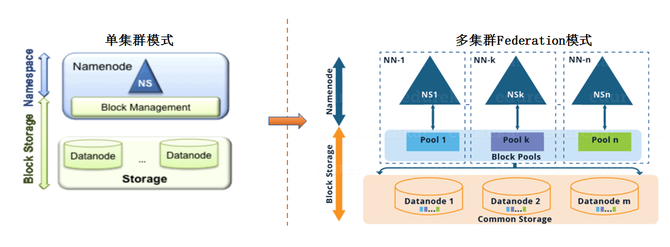
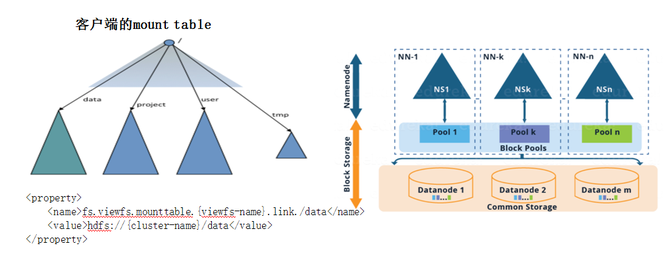
接下来,我们从单集群模式向多集群Federation模式进行了演变。基于Viewfs的Federation模式。但是在Federation模式下,我们需要能够对数据进行快速的迁移,这里我们使用的是fastcopy的方式来做。
我们基于Fastcopy的数据迁移流程如下:1,收回目录权限;2,关闭open中的文件;3,使用Fastcopy进行数据的迁移;4,如果3步骤失败,进行retry;5,恢复权限;6,更新mount table信息。
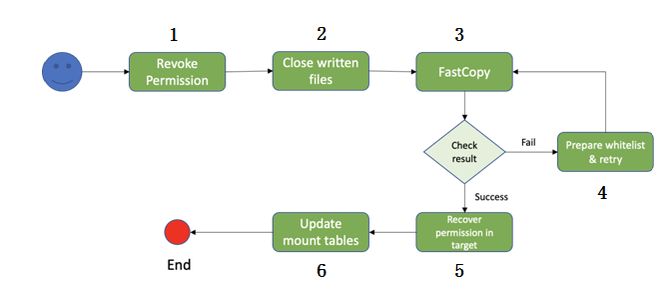
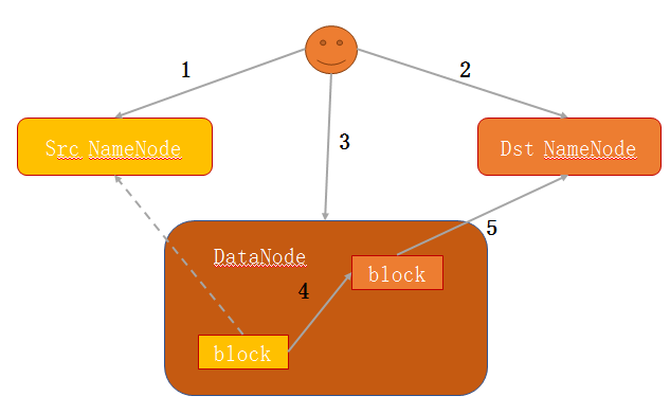
在数据迁移时,数据量是非常大的,分享一下Fastcopy原理:1,Client向源NameNode查询文件block信息;2,在目标NameNode上创建相应文件,block信息;3,发送copy block请求到block所属DataNode;4,DataNode创建block,hard link到源block文件;5,汇报block到目标NameNode。这就完成了Fastcopy的过程。
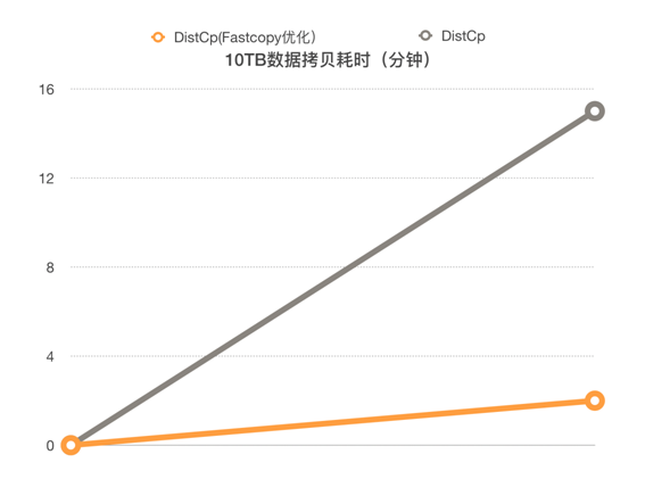
只靠Fastcopy还不够,还需要将Fastcopy功能集成进DistCp工具里。我们进一步对DistCp进行了改进优化,包括:统一化大文件小文件的长度,避免出现长尾任务影响;目录ACL preserve操作的前置;DistCp支持whitelist/exclude list的拷贝;DistCp job的参数调优。这样的结果就使性能提升近7倍。
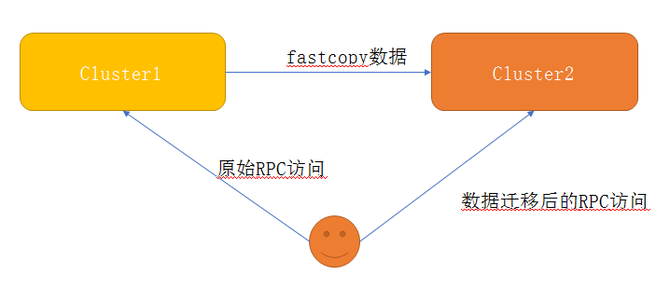
在集群RPC流量迁移方面,我们是如何做的呢?首先分析用户数据访问行为,主要检查是否有rename操作的行为;其次将Fastcopy数据从源cluster到目标cluster,最后用户重定向到新cluster进行数据的访问。
Viewfs Federation也不是完美的方式,它存在两大问题:
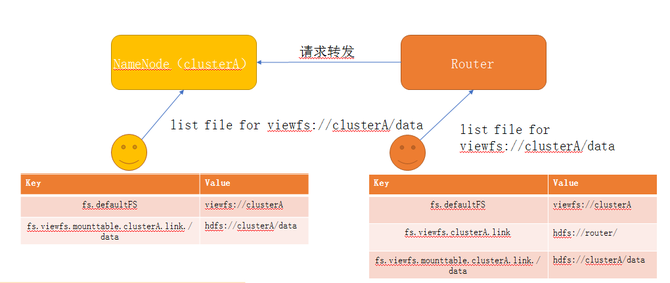
第一,维护成本高。随着Federation集群变多,Viewfs的更新维护成本过高,需要在每个client端做更新。
第二,对客户端不透明,Viewfs对客户端不透明,涉及到底层数据的迁移需要客户端的调整。
接下来,我们从多集群Federation模式向基于Router的Federation模式的演变。
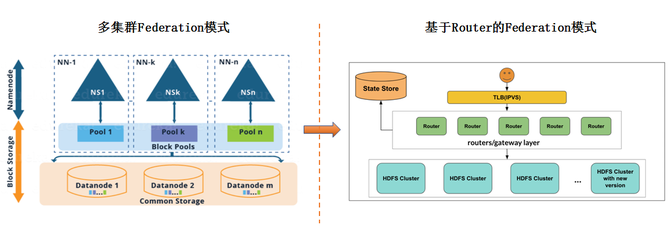
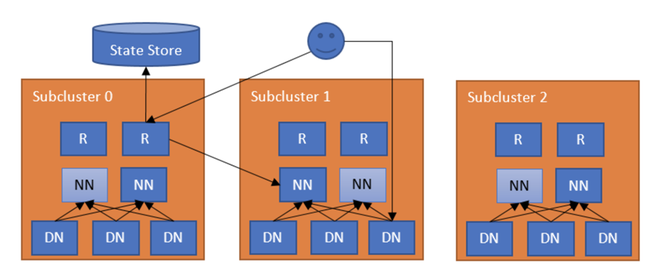
HDFS Router-based Federation架构如下:
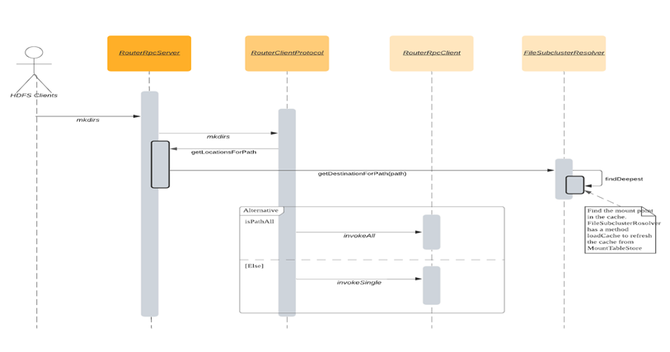
以下是RBF请求处理的过程:
RBF架构模式的优势如下:
第一,无状态的服务,cloud-native化部署,方便进行横向扩展;
第二,Federation路径更新对用户完全透明,用户无需进行任何更新;
第三,可基于RBF架构做数据split拆分的方案。
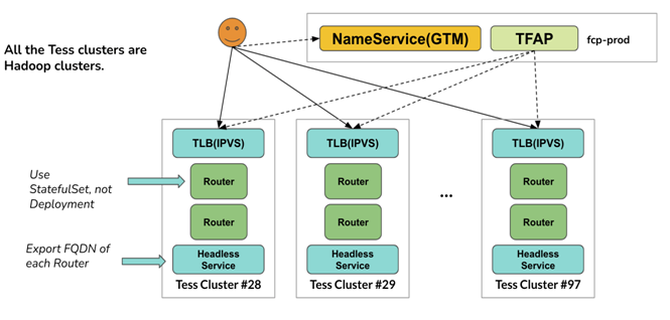
RBF的功能特性如下:
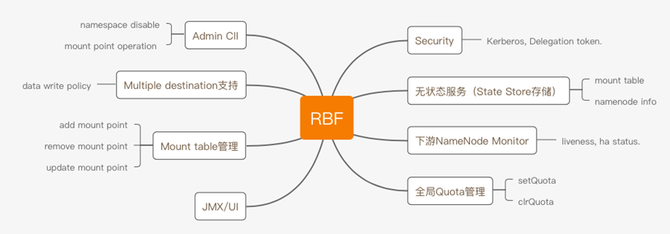
eBay针对RBF进行了很多优化,在RBF的平滑部署方面,我们提高了Viewfs到RBF的兼容性支持,同时针对YARN RM Security模式补token逻辑的改造。
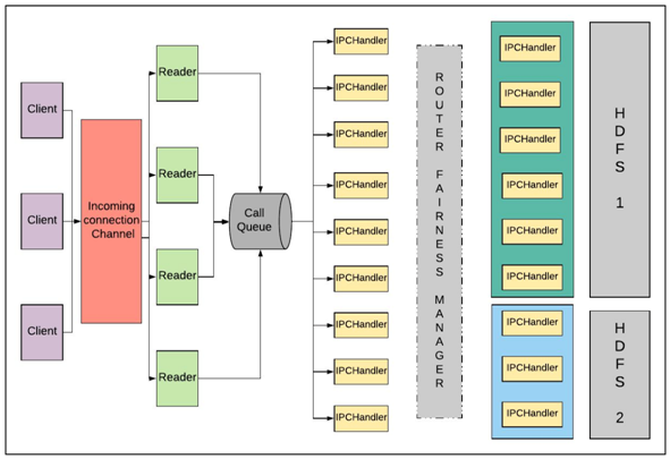
在RBF的性能改造方面,我们把Router服务支持更大的RPC吞吐量,解决Router内部的连接复用问题,去掉Router和NameNode之间的Sasl加密操作;Router支持客户端ip地址,clientId的保留,不会影响到任务data locality的读写;多挂载点模式下,moveToTrash文件删除问题的解决。
以下是Viewfs到RBF的兼容性改造:
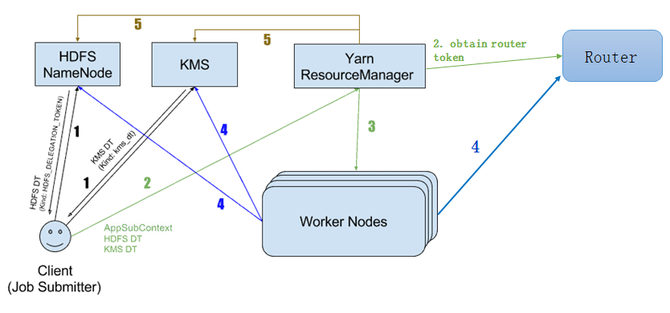
在RBF补token改造方面,主要有五步:
1,Client从NameNode获取token;2,Client提交Job到RM(携带token);3,RM额外向Router获取Router token,随后token通过任务调度下发到work node上;4,Work node上跑的任务通过token来做HDFS认证,以此进行HDFS数据和Router服务的访问;5,Job运行结束,RM进行token的删除操作。
关于RBF的未来展望
我们希望在RBF模式上做更多的内容,如:RBF异步化RPC处理来进一步提升RPC吞吐量;基于RBF做更为自动化的数据split拆分;基于RBF模式下做Tiered Storage,提升集群存储的效率;RBF对底层namespace间RPC处理的隔离。

