【IT168 专访】2012年,我第一次采访Mellanox市场副总裁Gilad Shainer,他的睿智和坚定给我留下了深刻的印象。时至今日,我已经跟踪Mellanox四年多的时间,每年也有机会与Gilad Shainer进行近距离的交流。
 Mellanox公司全球市场部副总裁Gilad Shainer
Mellanox公司全球市场部副总裁Gilad Shainer
日前,Gilad Shainer再次来到中国,不过相比之前不同的是,这一次Gilad Shainer当着在场媒体的面表达了对于竞争对手的嘲讽。于是乎,本次采访的重点分为了两大部分——协同设计(Co-Design)战略描述与竞争对手数据分析。
Co-design战略解读
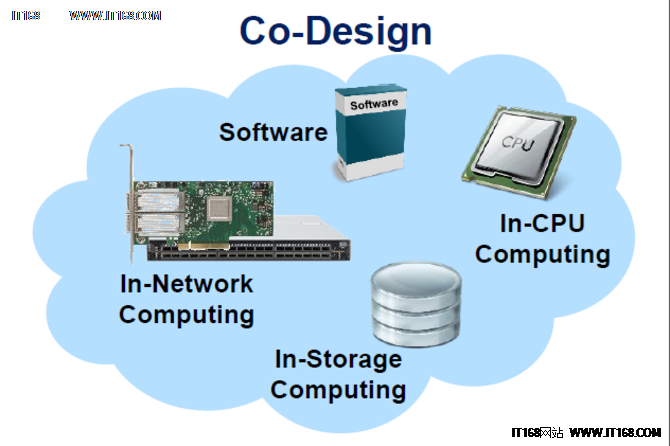
Co-Design是Mellanox最近几年一直在强调的概念,其核心在于实现不同的分工与合作。Gilad Shainer从网络发展的角度说明了Co-Design存在的必要性:“十年前,网络延迟和软件都是100微秒。如今,网络延迟已经降低到了1微秒,而软件延迟停留在10微秒的水平。与十年前相比,硬件快了100倍,而软件优化只快了10倍。最郁闷的是,接下来无论硬件如何优化提升,基本上已经达到物理极限。同时,整个应用程序性能提升也是微乎其微了,因为软件负荷太大”。

Co-Design存在的意义就是通过一种任务卸载的方式,让很多组件共同协同完成一个任务,通过专业的芯片进行处理,从而实现性能的大幅度提升——“通过很多技术协同和卸载的功能,可以让虚拟化做到更高效率,更好地处理这种应用程序失败的情景。将来虚拟化在高性能计算上是大有用武之地的。”这个想法听起来与英特尔的所作所为大相径庭,这也是Gilad Shainer一直强调的任务卸载(Offloading)。
卸载与加载之间的争论主要集中在CPU效率方面。研发出一项基于卸载架构的互连技术的难度和复杂度都不容小觑,但其回报也不菲——它能够让CPU从网络管理中脱身,进而能够轻松提升40-50%的CPU与系统利用率。而基于加载(onloading)架构的互连技术开发则相对简单的多,它只不过是一个简单的通道,所有的网络操作仍然必须由CPU来管理和执行;从应用的角度来看,一半的CPU资源都被浪费了。
此外,基于任务卸载(Offloading)的架构能够让像RDMA(远程内存直接访问)这样的技术变得可用,而这是加载(Onloading)架构无法做到的。“我们已经见过无数应用性能展示的示例,这些示例无一不证明了基于任务卸载解决方案对比Onloading产品的显著优势”,Gilad Shainer表示。

如今,随着人工智能、深度学习等全新HPC概念的普及与发展,InfiniBand网络也从HPC领域逐渐深入到各行各业当中。Mellanox表示,非常先进的100GB/s EDR网络已经在中国、欧洲和美国市场有所应用。而在谈到未来计划的时候,Gilad还特别展示了Mellanox EDR产品的发展路线图,包括明年即将出现的200Gb/s网络甚至2020年计划中的400GB/s网络。
Mellanox眼中的“Omni-Path内幕”
多年来,Mellanox凭借着InfiniBand领域的优势一直是高性能计算行业的佼佼者,每年两度公布的全球高性能计算机TOP500排行榜上,InfiniBand也占据着巨大的市场份额。不过这一切都在去年11月出现了变化。在2015年的SC15大会上,英特尔正式宣布了新一代Omni-Path网络,这正是英特尔对标InfiniBand网络的撒手锏。如此一来,Mellanox的核心竞争力遭到了挑战,也难怪此次Gilad Shainer如此来势汹汹。
当然,Omni-Path网络的出现并非是一蹴而就的,事实上在更早些时候业内就有各种关于Omni-Path的传言。作为InfiniBand网络的领军企业,Mellanox也并非没有预见到这个问题。其实早在2013年,笔者就曾针对这个问题采访过Gilad Shainer,那时候他对InfiniBand的信心满满。
首先,Mellanox公司与英特尔有着良好而且密切的合作关系,双方在服务器板载网络芯片方面有着深度的合作。其次网络并非是英特尔的核心业务,而当下来源于ARM的冲击使得英特尔在新兴的移动互联市场和传统的数据中心市场疲于应付;更重要的是,Mellanox公司是一家以产品品质取胜的公司,过去的若干年间Mellanox的竞争对手都败在Mellanox领先的技术与过硬的产品之下。从这个角度来说,Mellanox公司还将一如既往的提供更多更好的产品,靠产品品质赢得市场的检验——2013年Gilad Shainer谈竞争对手。
如今,三年过去了。虽然只有三年,但是这个市场却发生了翻天覆地的变化,Mellanox也不得不重新审视英特尔这一强大的竞争对手。而事实上,借助“处理器”这一核心优势,英特尔对于任何对手都可以给予致命性的打击,这一点在NVIDIA身上已经得到了充分的证明。

不过在Mellanox看来,英特尔的Omni-Path网络显然不够完善,至少在应用方面还有不少的欠缺。为了证明这种说法,Mellanox给出了一组数据来说明Omni-Path的性能劣势。在测试中,Omni-Path的性能不随着设备的增加、带宽的增大而提升,相反这些数据的表现非常诡异,忽高忽低的成绩也证实了Mellanox的说法。“12个节点的时候,如果你采用的是Omni-Path网络,你就没有必要再增加你的集群规模了,因为它越跑越慢”,Gilad Shainer表示。
除了性能之外,Gilad Shainer还从成本的角度进行了分析。他首先引用了一句犹太谚语来证明自己的观点:“我们太穷了,所以买不起便宜货”。随后,Gilad Shainer对比了同样性能情况下使用Mellanox网络和使用英特尔网络所需要的成本,以证明使用Mellanox网络的成本投入只有使用英特尔平台的80%。相对应的,如果客户投入的成本是固定的,那么使用Mellanox网络将会获得更好的性能。

