曙光I840四路六核Dunnington服务器评测
【IT168评测中心】Intel推出六核心Dunnington至强处理器已经有约一年的时间了,作为面向四路服务器市场的处理器,满配置达到24个处理核心数量,比起传统的四路四核,要多出整整8个处理核心,系统性能得到了明显的提升,因此虽然是Penryn核心/FSB总线的末代产品,Dunnington的市场表现却是不错。

六核心45nm Penryn Dunnington——Xeon 7400系列处理器
不少厂商都推出了基于Dunnington至强Xeon 7400的四路服务器,我们前段时间收到了国内的主力厂商Dawning曙光送来的一台Dunnington服务器,型号是I840r-H。

曙光I840r-H四路六核Dunnington服务器
一般的双路服务器都是以6开头,例如我们测试过的双路Nehalem-EP服务器I620r-H,可以猜测,以8开头的型号自然和他们不同,I840r-H是一台基于Intel Xeon X7460的服务器。

曙光I840r-H四路六核Dunnington服务器
可以说,Dunnington和Nehalem-EX是都属于同一产品线的产品,只不过一个基于45nm Penryn架构,另一个则属于下一代的45nm Nehalem架构。它们都处于4个或以上Socket的Xeon MP产品线。Dunnington已经在2008年9月发布,按照Tick-Tock战略,Nehalem-EX则要等到2009年下半年。
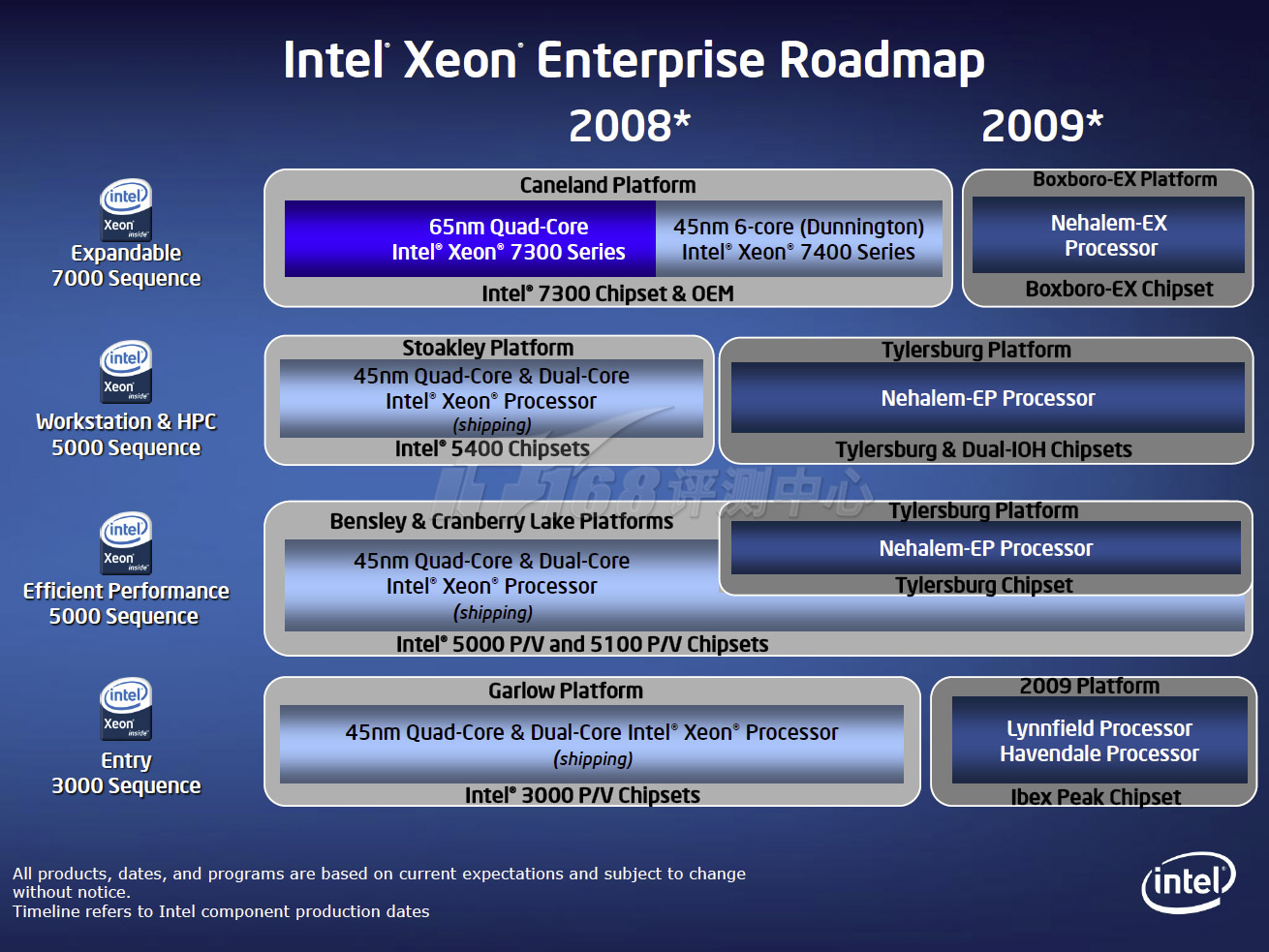
Intel至强处理器路线图

Xeon DP、Xeon MP处理器对比,左上是双路四核Xeon DP,右上是四路四核Xeon MP,最下方则是四路六核Dunnington,和Nehalem-EX一起,都属于Xeon MP产品线
《Over 1 Million TPC-C with a 45nm 6-Core Xeon® CPU》由Intel的数位来自India印度Bangalore班加罗尔的工程师主讲,这里又有一个故事……和Nehalem-EX、Tukwila以及QPI相关——话说,按照Intel的计划,首款被称为Whitefield的Xeon MP四核心至强应该是配合Itanium 2(四核心Tanglewood,也就是后来的Tukwila)一起引入CSI总线(Common System Interconnect,通用系统互联)实现“通用”的“处理器系统”的“互相连接”的,但是,Tanglewood因重新设计,被推迟到2007年,还因为商标纠纷被迫改名为Tukwila,并之后继续推迟到2008年。而Intel在印度开发的Whitefield则由于各式各样的问题被取消了,随后位置被Tigerton代替——Tigerton仍然使用了FSB总线,并且是两个Cornoe内核“粘”在一起,作为Tigerton的后继,Dunnington的任务就是将Tigerton的“粘结”架构改进为现在的类似Nehalem的架构,你看,这个工作就是Whitefield的原班人马做的——就是位于India印度Bangalore班加罗尔的设计团队。

ISSCC上Intel发布的四篇论文,包括了Nehalem-EX(45nm Nehalem Xeon MP)、Tukwila(45nm Itanium 2)、Dunnington(45nm Penryn Xeon MP)三个大系列的处理器
《ISSCC2009 Over 1 Million TPC-C with a 45nm 6-Core Xeon CPU》是来自Intel在ISSCC 2009上一共发布的四篇论文的其中一篇。这四篇论文除了讲Nehalem-EX的《A 45nm 8-Core Enterprise Xeon® Processor》之外,还有一篇专门说Dunnington的《Over 1 Million TPC-C with a 45nm 6-Core Xeon® CPU》,这个结构图就来自这篇论文。在论文里面提到了很多Dunnington与普通45nm Penryn处理器很不相同的地方,实际上,它带有很多Nehalem处理器的特色,作为45nm Penryn架构Xeon的最后一款处理器,它就像是45nm Penryn与45nm Nehalem之间的杂合物,关于Nehalem架构,可以参阅笔者的《2008年度评测报告:深入Nehalem微架构》,接下来我们来看看Dunnington的架构是如何与众不同。

为什么这篇论文要叫《Over 1 Million TPC-C with a 45nm 6-Core Xeon® CPU》呢?就是因为一台8路Dunnington服务器在测试当中获得了超过1 million(一百万)的破纪录(Xeon而言)TPC-C成绩,TPC-C是一种衡量数据库性能的标准的其中一个测试
Dunnington采用其后来者Nehalem一样的45nm CMOS工艺,采用了金属栅极High-K电介质晶体管以及9层铜互联技术,总晶体管数量则为1.9 Billion——19亿,已经和Nehalem-EX的23亿很接近了,新增加的核心和大容量的L3都需要占据很多的晶体管。Dunnington的核心面积为503.2mm2。
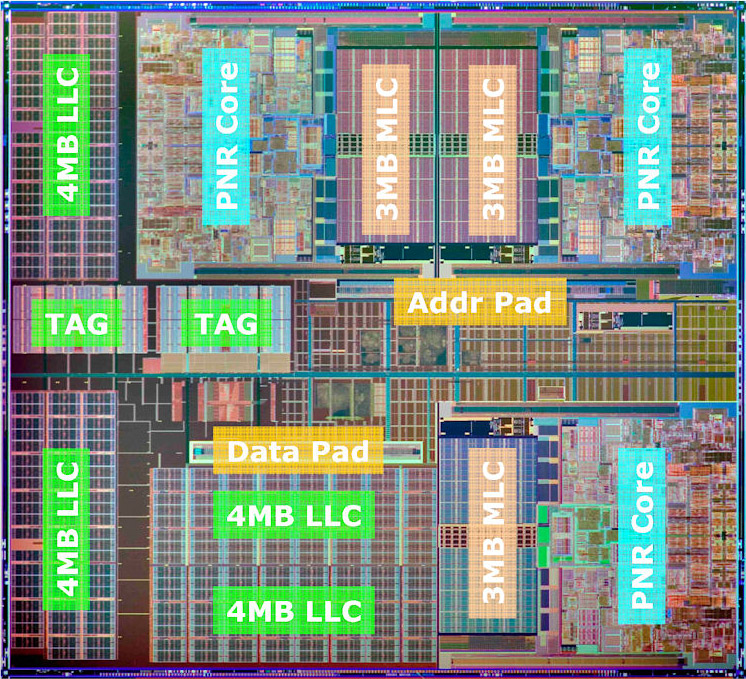
六核心45nm Penryn Dunnington——Xeon X7460的结构图,和其他Penryn不同,是一整块“原生”的核心
来源:ISSCC2009 Over 1 Million TPC-C with a 45nm 6-Core Xeon CPU
对于一款处理器来说,除了外部平台的架构之外,处理器内部架构和处理器微架构都是对性能有很大影响的主要因素。如图所示的Dunnington属于规格不凡的一款,型号是X7460(曙光I840-H就采用了这款处理器),架构上具有6个Penryn核心,每个核心带有64KB L1缓存(32KB L1-I,2KB L1-D),每两个处理核心共享3MB的L2缓存(果然还是带有“粘”的性质),三对处理器内核就总共带了9MB容量的L2,每个核心通过一条128Bytes的缓存线联结L2。Intel宣称不同的一对核心之间的L2是具有其他互通界面的(被命名为Advanced Transfer Cache Architecture),不过语焉不详。其他的四核45nm Penryn也具有这个高级缓存传输架构。X7460的核心频率为2.66GHz,不算太高。Dunnington里面最高主频就是2.93GHz。

7400系列处理器的规格,注意7400系列处理器里面也有4核心的型号

7400系列处理器的缓存架构细节
重点来了,除了上面这些传统的架构之外,Dunnington特别的地方是多了一个Uncore结构,这个结构包括了容量达到了16MB的L3缓存,所有的处理核心经过L2联结到中央系统逻辑,如下图所示,标明为Uncore的中央电路联结着所有的核心以及16MB L3缓存,并通过一个传统的FSB总线与处理器外部通信,由于所有处理内核是通过新的总线与Uncore联结,而与以往的“粘结产品”使用FSB互联不同,大部分的交通都发生在内部,从而可以大为节约处理器的FSB带宽。Xeon X7460的FSB频率为1066MHz,提供8.5GB/s的带宽,现在的Xeon MP都支持MIB(Multiple Independent Bus,多重独立总线,Xeon DP的DIB的进阶版本),每一个处理器都通过独立的FSB与MCH联结,因此效率上还可以。
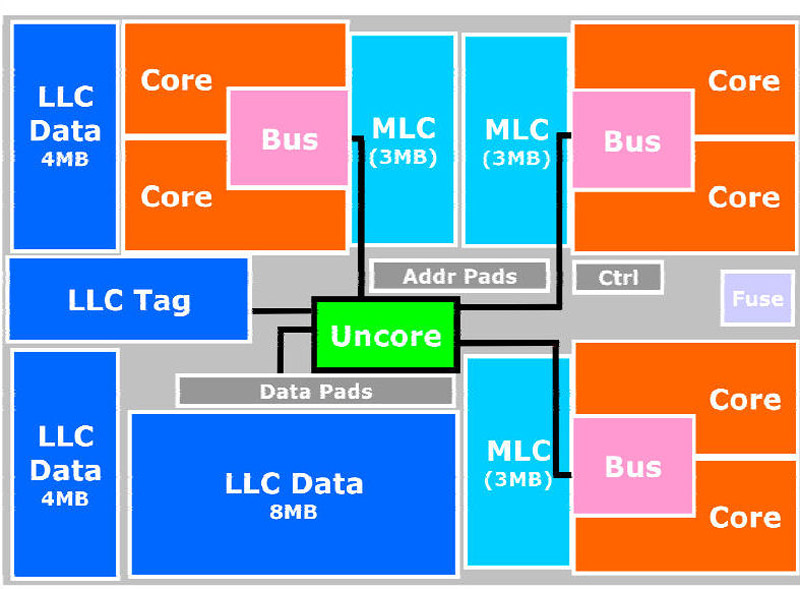
"Uncore"是六核心45nm Penryn至强Dunnington的重要部分
在L2上,每两个Dunnington共享3MB Cache,这一点上和其他的Penryn无不同之处(虽然总数量9MB的L2看起来很怪),Dunnington特别的地方在于其架构:Uncore部分,这部分包含了16MB的L3缓存。
来源:ISSCC2009 Over 1 Million TPC-C with a 45nm 6-Core Xeon CPU
Dunnington所有核心共享的16MB L3缓存分成了4块,每块4MB,7400系列处理器当中也有12MB的型号,这样就是3个L3缓存块。和Nehalem一样,这些缓存块都可以设置为关闭模式以节约能耗。Dunnington的每个4MB缓存块有4096组缓存线,16路组关联(或,集合关联),缓存线为64字节——Dunnington最多允许所有内核进行32个缓存线存取。Dunnington具有两个TAG缓存,每个容量为1.5MB——总共就是3MB。
L3缓存被划分成多个子阵列:1MB每个,总共就是16个子阵列,子阵列架构和Nehalem-EX一样,如下图:每一个访问只有整体阵列的3.125%加电,从而降低了耗电量。数据阵列使用0.3816um2的单元并使用DECTED(Inline double-error correction and triple-error-detection,双位纠错三位检测)ECC进行保护,具有可变的访问延迟;Tag索引阵列则使用了0.54um2的单元并使用SECDED(Inline single-error-correction and double-error detection,单位纠错双位检测)ECC进行保护,并具有固定的访问延迟。数据阵列具有行冗余和列冗余,Tag阵列则只有列冗余,这些特征都和Nehalem-EX完全一样。

Nehalem-EX的L3缓存Slice结构
仍然和Nehalem-EX类似,Dunnington按时钟分为三个部分:核心、核外(L3和系统逻辑)和IO部分(就是FSB),这三个部分的频率关系没有Nehalem-EX那么复杂,对于Xeon X7460而言,核心频率GCLK就是2.66GHz,核外(Uncore)的SCLK则是GCLK的一半(不过,貌似L3仍然是全速的),IO的ZCLK则是1066MHz。
来源:ISSCC2009 Over 1 Million TPC-C with a 45nm 6-Core Xeon CPU
在电压上,Dunnington也没有Nehalem-EX处理器这么复杂,它的核心、Uncore核外(L3和系统逻辑)共用一组输入,I/O部分和模拟电路(热感应器)部分则共用另外一组输入。
热感应器上Dunnington也比Nehalem-EX少一些,Nehalem-EX是每个核心一个热感应器,而Dunnington所有核心共用一个叫做Proc-hot Sensor的过程热感应器来监控温度,并通过Thermal Management Protocol来执行如C1E、EIST以及风扇控制(不过,机架式服务器通常没有独立的CPU风扇)这样的工作。除了测温感应器之外,Dunnington每两个处理核心还共用一个称为Catastrophic Trip Sensor的应急保护感应器用于在对应处理核心对过热的时候切断供电,总共就是三个这样的热感应器。
可以说,晶体管方面,Dunnington完全使用了和Nehalem-EX一样的工艺,和Penryn完全不同。Dunnington也使用了Static CMOS线路:

为了降低能耗,Nehalem架构将以往应用的Domino线路更换为Static CMOS线路,速度有所降低,但是能源效率提升了。Dunnington也采用了这样的做法
除了线路类型的变更之外,Nehalem的晶体管也进行了变化:

Intel High-k Metal Gate晶体管,S极到D极的红色箭头就是“channel沟道”,也就是耗尽区所在
在同一个线路中,使用的晶体管不同,耗电也是不同的,MOSFET元件按沟道长度可以分为长沟道Long Channel和短沟道Short Channel,短沟道具有较好的性能,不过其漏电流也相应更大(耗尽区宽度不足而与源极合并而导致大量漏电电流)。
这个图可不容易明白:沟道长度与漏电的关系,请自行理解(越低的延迟,越高的漏电电流)
在《透视八核心至强 Nehalem-EX处理器解析》提到Nehalem-EX使用了Long Channel长沟道晶体管元件,Dunnington上也有使用,只不过“分量”有些不同。在IC设计当中通常需要根据不同的情况使用不同沟道长度的晶体管,对于Nehalem而言,非关键时序(non-timing-critical)的线路可以使用性能略差的长沟道MOSFET晶体管以减少亚阈值漏电(subthreshold leakage,MOSFET的subthreshold亚阈值特性被广泛利用在低电压线路上),实际上Intel用的是"longer-channel"——“更长沟道”的MOSFET。
Nehalem-EX核心部分的58%和核外部分(不包括缓存阵列)的85%都使用了更长沟道晶体管,最后其漏电功率被控制到总功耗的16%,付出的代价是Nehalem的L1-D延迟由上一代的3时钟周期上升到4时钟周期。Dunnington则是核心部分的65%和核外部分(不包括缓存阵列)的90%都使用了省电的长沟道晶体管,可见同样的45nm工艺,Dunnington做得比Nehalem-EX好一些,因为Nehalem-EX的运行速度更高,Uncore、QPI等的频率都要求用较多的高性能高漏电的短沟道晶体管。
不过,Nehalem架构设计上就具有PCU(Power Control Unit,电源控制单元)可以彻底关闭不需要用到的核心、缓存,因此其闲置功耗表现将会好一些。可以做一个直观的比较,6核心、2.66GHz的Xeon X7460和8核心、约更高频率的Nehalem-EX的TDP都同样为130W。
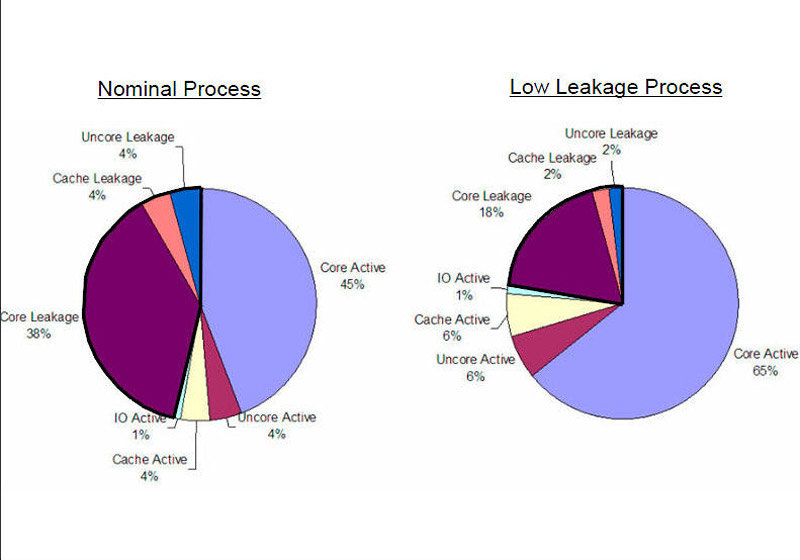
左:一般工艺,右:Dunnington的低漏电工艺
在使用Long Le(长沟道晶体管)技术之后,和同样45nm的其他Penryn架构处理器(如Harpertown等)相比,漏电降低了约1/3(一般45nm处理器漏电占总功耗的46%),降低到22%。如此这般,在增加了内核数量的情况下,Dunnington的功耗并没有上升,在使用较低的供电电压情况下,6核心的Dunnington甚至可以做到65W的TDP。

L7455——低电压版本的6核Dunnington Xeon的TDP只有65W
Dunnington系列总共有15款处理器,除了传统的E、L、X这三个TDP划分前缀之外,最明显的是:Dunnington并不是所有型号都是六个处理核心。只有X7460、L7455、E7450这三款型号具备六个核心——刚好每一种前缀一个型号。它们的TDP分别为130W、65W、90W,频率分别为2.66GHz、2.13GHz、2.40GHz,FSB频率一样都是1066MHz。Dunnington中甚至还有两款双核型号。
最下方是四路六核Dunnington,基于7300芯片组
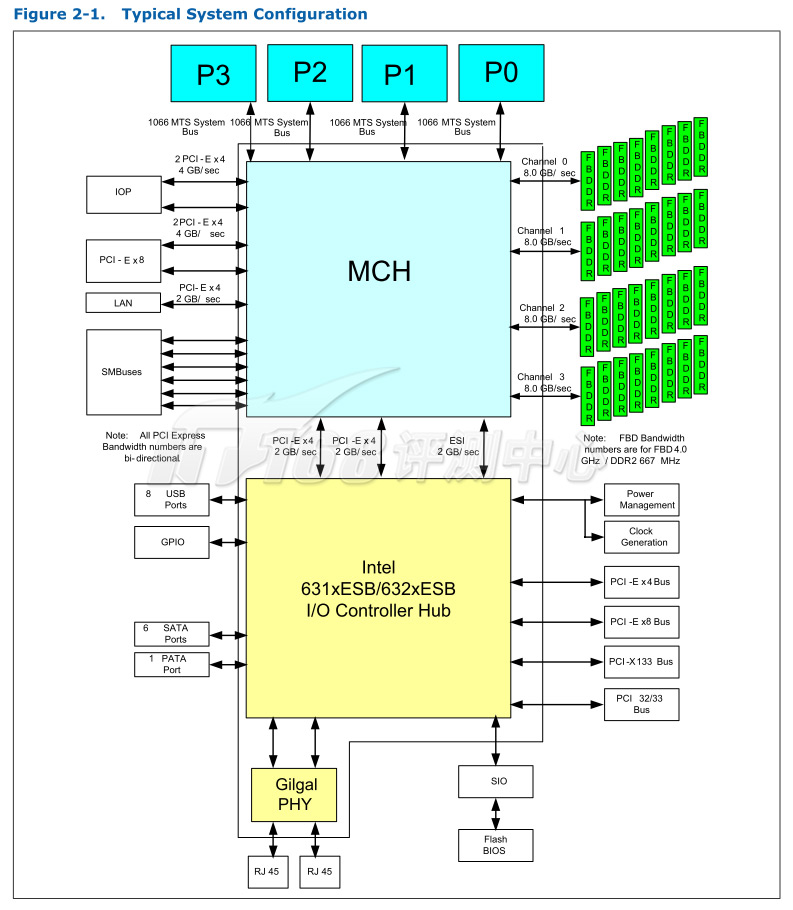
Intel 7300芯片组
7300芯片组提供了7组PCI Express x4 Gen1界面和1个ESI界面,其中ESI界面本质上就是一个PCI Express x4 Gen1界面,专门用来连接系统南桥。除去ESI,7300总共具备28个PCI Lane,这些PCIE x4端口可以聚合为PCIE x8端口,其中,有两个PCIE x4端口可以用来和ESI协作,扩展和南桥连接的带宽。曙光Dawning I840四路Dunington服务器还使用了两个IDT 89HPES24N3AZC PCI-E交换芯片来提供PCI Express Gen2总线,每Lane带宽达到500MB/s,是PCI Exrpess Gen1的两倍。每个IDT 89HPES24N3AZC提供24个PCI Express Lane。

南桥芯片上,7300芯片组使用的是ESB系列——现在一般都用6321ESB,可以提供PCI Express、PCI、PCI-X界面,从I/O上说,PCI Express设备连接到北桥性能会更好一些。6321ESB还提供了6x SATA 3Gbps(支持软RAID 0/1/5)、8x USB 2.0等传统功能。

曙光Dawning I840r-H四路Dunington服务器内部:最左侧是4个六核心Dunington处理器,其右边的白色散热器下方就是7300芯片组
虽然笔者也很像看到7300长什么样,然而散热器的结合实在太过于紧密,因此只能望而兴叹了。
曙光I840r-H四路六核Dunnington服务器

曙光I840r-H四路六核Dunnington服务器
曙光I840r-H四路六核Dunnington服务器,从前面看去有没有人觉得像一台录音机?

曙光I840r-H四路六核Dunnington服务器
在把I840r-H服务器搬来搬去之后我们了解了四路服务器的真谛:沉重!非常沉重!

曙光I840r-H四路六核Dunnington服务器:热插拔风扇

曙光I840r-H四路六核Dunnington服务器:拔掉风扇

曙光I840-H四路六核Dunnington服务器使用了2.5"的企业级硬盘,和3.5"相比,2.5"硬盘的特点就是寻道时间短,随机访问快,具有强劲的I/O能力,缺点则是容量不够大。我们收到的曙光I840-H评测样机配置了4个2.5"硬盘。

曙光I840r-H四路六核Dunnington服务器使用的Seagate Savvio 10K.2硬盘

曙光I840r-H四路六核Dunnington服务器使用的Seagate Savvio 10K.2硬盘

曙光I840r-H六核心Dunnington至强服务器

曙光I840r-H六核心Dunnington至强服务器:前面板拆下的热插冗余风扇

曙光I840r-H六核心Dunnington至强服务器:前面板拆下的热插拔冗余风扇,可以看到,风扇是两层的

曙光I840r-H六核心Dunnington至强服务器还有多个散热风扇

曙光I840r-H六核心Dunnington至强服务器:后面板拆下的热插拔冗余电源

曙光I840r-H六核心Dunnington至强服务器:来自DELTA的1570W的热插拔冗余电源
曙光Dawning I840r-H四路Dunington服务器内部:最左侧是4个六核心Dunington处理器,其右边的白色散热器下方就是7300芯片组

Intel 6-core Dunnington Xeon X7460

Intel 6-core Dunnington Xeon X7460

Intel 6-core Dunnington Xeon X7460与AMD Operton

曙光I840r-H六核心Dunnington至强服务器:内存RISER组件,四路服务器要提供强大的内存容量,将DIMM插槽全部放在主板上不太现实,于是需要这种类似转接卡一样的东西

曙光I840r-H六核心Dunnington至强服务器:共有4个这样的组件,每个组件8条FBD DDR2内存,总共就能使用32条DIMM,采用2GB一条的内存,容量就是64GB,使用4GB一条的内存,总容量就是128GB,如此巨大的容量下,才有启用I840r-H服务器的内存阵列的可行性
7300芯片组支持两个内存分支,每个分支支持两个内存通道,总共就支持4个内存通道。7300芯片组最多支持512GB的内存,这需要使用16GB的FBD-DIMM内存。曙光I840r-H提供了完整的7300芯片组内存支持,不过要使用到512GB内存,你可能需要订做内存。
7300支持内存阵列镜像功能,就像磁盘的RAID 1一样。7300的每一个内存模组都具有DIMM状态指示灯,总而言之,四路服务器注重稳定性和可用性,保障服务器的长时间可靠运行。
曙光Dawning I840r-H四路Dunington服务器内部
随着处理器处理能力的逐渐提升,服务器系统与外界环境的交通就越来越显得重要——也就是所说的IO能力,曙光Dawning I840r-H四路Dunington服务器使用的7300芯片组可以提供多达7组的PCI Express x4端口,并且可以组合成三个x8端口,总共就是28个PCIE Lane。
IDT 89HPES24N3AZC是Integrated Device Technology(IDT)推出的PCI-E交换器,主要为扩充服务器在I/O连结方面的瓶颈,IDT 89HPES24N3AZC是24信道(Lane)的PCI Express Gen2交换芯片,每信道传输带宽500MB/s(Intel 7300芯片组只能提供PCI Express Gen1总线,每信道带宽250MB/s),曙光Dawning I840r-H四路Dunington服务器使用了两个IDT芯片,总能就是48个PCI Express Gen2信道。虽然与7300芯片组的总带宽不会改变,然而提供PCI Express Gen2支持能力,可以连接更快速的外部设备。

曙光Dawning I840r-H四路Dunington服务器使用的阵列卡,基于LSI 1078芯片,具备500MHz的PowerPC 440处理器,提供两个SFF8087接口,支持最多8个SAS 3Gbps设备,仔细观察,电池旁边具有RAID Key的字样,这表明这是一块典型的ROMB(RAID on MotherBoard)卡,RAID Key相当于授权文件,没有RAID Key只能支持RAID 0/1

阵列卡使用的内存,容量达到了512MB

阵列卡背面。这块阵列卡采用的界面是PCI Express x8

主板上还有一个SFF8087接头,或者通俗一点地叫做Mini SAS接头,它其实是南桥芯片SATA接口的一个更方便、更节约空间的集成。一个Mini SAS接头可以替代4个SATA接头,因此主板上还有俩独立SATA接头用来接光驱
曙光Dawning I840r-H四路Dunington服务器内部
就服务器来说,对外界而言,网络是唯一的通信窗口,因此服务器的网卡也很重要,曙光Dawning I840r-H四路Dunington服务器提供了多个服务器网卡:

首先是板载的82563EB网络芯片
Intel 82563EB是一个双端口的千兆以太网PHY芯片——需要和MAC部分合作才能构成完整的网络功能,Intel ESB63x1南桥芯片就有MAC功能。曙光Dawning I840r-H四路Dunington服务器使用的就是ESB6321南桥。

曙光Dawning I840r-H四路Dunington服务器使用的一块网卡:看外形就知道厉害
曙光Dawning I840r-H四路Dunington服务器嫌提供一个双端口千兆网卡不足够,于是又增加了一块长长的双端口网卡

双口网卡

网卡芯片:82575EB
Intel 82575EB是一个完整的双端口千兆以太网芯片,除了563EB提供的基本的功能之外,575EB还能提供VMDq功能,并支持IOAT2,支持VT-c,特别为虚拟化应用而设计,性能和功能都不同凡响。
在2005年度服务器横评之后,我们认为当时的网络实验室无法满足今后继续发展的服务器测试的需要。所以,2006年我们IT168评测中心又斥资几十万对于IT168网络实验室的服务器测试平台进行了大幅度的升级,为思科Catalyst4500千兆交换机(WS-X4013+ Supervisor Engine II-Plus和WS-X4548-GB-RJ45)增加了一个思科全千兆24口模块WS-X4424-GB-RJ45,可同时连接72个千兆铜缆设备和2个光缆设备。另外,我们还购置了29台Dell PowerEdge SC430塔式服务器和原来的32台主流配置PC一起为服务器测试平台的提供负载。2007年,我们又采购性能更强的部分客户端,来确保为新一代的服务器提供足够的测试负载。2009年初,我们又对所有客户端的内存子系统进行了全面的升级。
Catalyst4500千兆交换机
部分Dell PowerEdge SC430服务器
在新的测试环境下,我们进一步完善了服务器性能测试方案:
SPEC CPU 2006 v1.0.1
SPEC是标准性能评估公司(Standard Performance Evaluation Corporation)的简称。SPEC是由计算机厂商、系统集成商、大学、研究机构、咨询等多家公司组成的非营利性组织,这个组织的目标是建立、维护一套用于评估计算机系统的标准。
SPEC CPU 2006是SPEC组织推出的CPU子系统评估软件最新版,我们之前使用的是SPEC CPU 2000。和上一个版本一样,SPEC CPU 2006包括了CINT2006和CFP2006两个子项目,前者用于测量和对比整数性能,而后者则用于测量和对比浮点性能,SPEC CPU 2006中对SPEC CPU 2000中的一些测试进行了升级,并抛弃/加入了一些测试,因此两个版本测试得分并没有可比较性。
SPEC CPU测试中,测试系统的处理器、内存子系统和使用到的编译器(SPEC CPU提供的是源代码,并且允许测试用户进行一定的编译优化)都会影响最终的测试性能,而I/O(磁盘)、网络、操作系统和图形子系统对于SPEC CPU2006的影响非常的小。
SPECfp测试过程中同时执行多个实例(instance),测量系统执行计算密集型浮点操作的能力,比如CAD/CAM、DCC以及科学计算等方面应用可以参考这个结果。SPECint测试过程中同时执行多个实例(instances),然后测试系统同时执行多个计算密集型整数操作的能力,可以很好的反映诸如数据库服务器、电子邮件服务器和Web服务器等基于整数应用的多处理器系统的性能。
我们在被测服务器中安装了当前最新版本的Intel C++ 10.1.025 Compiler、Intel Fortran 10.1.025 Compiler这两款SPEC CPU 2006必需的编译器,通过最新出现的QxS编译参数,Intel Compiler 10版本开始支持对Intel SSE4指令集进行优化(假如只支持SSE3,则使用QxT编译参数)。我们另外安装了Microsoft Visual Studio 2003 SP1提供必要的库文件。按照SPEC的要求我们根据自己的情况编辑了新的Config文件,使用了较多的编译选项。我们根据被测系统选择实际可同时处理的线程数量,最后得到SPEC rate base测试结果(基于base标准编译,SPEC base rate测试代表系统同时处理多个任务的能力)。
和其它测试部件不同,SPEC CPU 2006需要大量的系统物理内存,我们的SPEC测试在64bit Windows Server 2008 Enterprise下完成,对于每个运算核心,至少需要配置1.5GB内存。
Iometer 2006.7.27
Iometer是一款功能非常强大的IO测试软件,它除了可以在本机运行测试本机的IO(磁盘)性能之外,还提供了模拟网络应用的能力。在这次的测试中,我们仅仅让它在本机运行测试服务器的磁盘性能。为了全面测试被测服务器的IO性能,我们分别选择了不同的测试脚本。
Max_throughput(read):文件尺寸为64KB,100%读取操作,随机率为0%,用于检测磁盘系统的最大读取吞吐量
Max_IO(read):文件尺寸为512B,100%读取操作,随机率为0%,用于检测磁盘系统的最大读取操作IO处理能力
Max_throughput(write):文件尺寸为64KB,0%读取操作,随机率为0%,用于检测磁盘系统的最大写入吞吐量
Max_IO(write):文件尺寸为512B,0%读取操作,随机率为0%,用于检测磁盘系统的最大写入操作IO处理能力
SiSoftware Sandra v2009
SiSoftware Sandra是一款可运行在32bit和64bit Windows操作系统上的分析软件,这款软件可以对于系统进行方便、快捷的基准测试,还可以用于查看系统的软件、硬件等信息。从2007开始,Sandra的Arithmetic benchmarks增加了对SSE3 & SSE4 SSE4的支持,在Multi-Media benchmark中增加了对于SSE4的支持,另外还升级了File System benchmark和Removable Storage benchmark两个子项目。对于新的硬件的支持当然也是该软件每次升级的重要内容之一。SiSoftware Sandra所有的基准测试都针对SMP和SMT进行了优化,最高可支持32/64路平台,这也是我们选择这款软件的原因之一。
NetBench v7.03
NetBench是针对文件服务器的性能测试软件,影响NetBench性能的主要是服务器的磁盘子系统,服务器磁盘控制器、条带大小、读写缓存、硬盘类型、组建磁盘阵列模式、内存容量、网络拓朴结构等都会对测试结果有明显的影响。我们在被测服务器上设立了文件服务器,NetBench通过网络实验室中60个客户端来模拟网络中的PC向文件服务器所发出的文件传输请求,文件服务器则将存储在磁盘上的文件数据发送给相应的客户端。在测试过程中,客户端会以每四台一组的步进依次增加并且向服务器发送文件传输请求,测试结束后控制台收集数据并绘制出服务器的数据传输变化曲线。
CineBench R10
CineBench是基于Cinem4D工业三维设计软件引擎的测试软件,用来测试对象在进行三维设计时的性能,它可以同时测试处理器子系统、内存子系统以及显示子系统,在服务器测试平台中显示子系统不重要,因此就只有前两个的成绩具有意义。和大多数工业设计软件一样,CineBench可以完善地支持多核/多处理器,它的显示子系统测试基于OpenGL。
ScienceMark 2.0
ScienceMark 2.0可以用来评估测试对象在执行科学计算时的运算效能,这部分效能主要和处理器子系统和内存子系统相关。我们主要用来评估测试对象的内存子系统的性能。
系统功耗监测
我们使用UNI-T UT71E智能数字万用表对于被测服务器系统的整体功耗进行了监测,利用随机附带的接口程序,我们可以记录被测服务器任意时间段内的功率变化。
测试结果并会与我们IT168评测中心的DELL PowerEdge 2900 III服务器进行对比,并会加入最新的Intel Nehalem-EP官方送测样机和曙光的Shanghai Operton服务器,测试对比平台的详细参数如下:
测试平台、测试环境 | |||||
测试分组 | |||||
类别 | Dawning I840r-H服务器 四路Intel Dunnington Xeon X7460 | Intel Nehalem-EP官方送测样机 华硕RS700-E4服务器 双路Intel Gainestown Xeon X5570 | Dawning A650服务器 双路AMD Shanghai Opteron 2378 | 双路Xeon E5430基准平台 DELL PE2900 III服务器 | |
处理器子系统 | |||||
处理器 | 四路Intel Xeon X7460 | 双路Intel Xeon E5430 | 双路AMD Opteron 2378 | 双路Intel Xeon E5430 | |
处理器架构 | Intel 45nm Penryn/Dunnington | Intel 45nm Nehalem | AMD 45nm Shanghai | Intel 45nm Penryn | |
处理器代号 | Dunnington | Gainestown | Shanghai | Harpertown | |
处理器封装 | Socket mPGA604 | Socket 1366 LGA | Socket F 1207 | Socke 771 LGA | |
处理器规格 | 六核 | 四核 | 四核 | 四核 | |
处理器指令集 | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,EM64T,VT | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,SSE4.2,EM64T,VT | MMX,3DNow!,SSE,SSE2,SSE3,SSE4A, AMD-64,AMD-V | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,EM64T,VT | |
| 主频 | 2.66GHz | 2.93GHz | 2.40GHz | 2.66GHz | |
| 处理器外部总线 | FSB 333MHz 1333MT/s 10.6GB/s | 2x QPI 3200MHz 6.40GT/s 单向12.8GB/s(每QPI) 双向25.6GB/s(每QPI) | 2x HT 1000MHz 2.00GT/s 单向4.0GB/s(每HT) 双向8.0GB/s(每HT) | FSB 333MHz 1333MT/s 10.6GB/s | |
L1 D-Cache | 6x 32KB 8路集合关联 | 4x 32KB 8路集合关联 | 4x 64KB 2路集合关联 | 4x 32KB 8路集合关联 | |
L1 I-Cache | 6x 32KB 4路集合关联 | 4x 32KB 4路集合关联 | 4x 64KB 2路集合关联 | 4x 32KB 8路集合关联 | |
L2 Cache | 3x 3MB 12路集合关联 | 4x 256KB 8路集合关联 | 4x 512KB 16路集合关联 | 2x 6MB 16路集合关联 | |
L3 Cache | 16MB 16路集合关联 | 8MB 16路集合关联 | 2MB 32路集合关联 | ||
主板 | |||||
主板型号 | Dawning I840-H | ASUS Z8PS-D12-1U | Tyan S2932-E | DELL PE2900 III | |
芯片组 | MCH:Intel 7300 ICH:Intel 6321ESB PCIE:IDT 89HPES24N3AZC | Intel Tylersburg-EP IOH:Intel 5520(Tylersburg-36D) ICH:Intel 82801JR(ICH10R) | NVIDIA nForce PRO 3600 | MCH:Intel 5000X ICH:Intel ESB6321 | |
| 芯片特性 | 4x FSB1066 VT-d Gen 1 | 2x QPI VT-d Gen 2 | 1x HT | 2x FSB1333 12MB Snoop Filter VT-d Gen 1 | |
内存控制器 | Intel 7300: 四通道FBD DDR2 667 512GB(4x8x16GB) | 每CPU集成三通道R-ECC DDR3 1333 | 每CPU集成双通道R-ECC DDR2 800 | Intel 5000X 集成四通道FBD DDR2 667 | |
内存 | 2GB FBD-DDR2 667 SDRAM x32 | 4GB R-ECC DDR3 1333 SDRAM x6 | 2GB R-ECC DDR2 667 SDRAM x4 | 2GB FBD DDR2 667 SDRAM x4 | |
系统磁盘子系统 | |||||
磁盘控制器 | Intel ROMB SAS RAID Controller | LSI Embedded MegaRAID SAS RAID Controller | LSI MegaRAID SAS RAID Controller | DELL Perc 5/i RAID Controller | |
磁盘控制器规格 | PCI Express x8 Gen1 | 8x SAS 3Gbps | 8x SAS 3Gbps | 8x SAS 3Gbps | |
磁盘控制器设置 | PCI Express x8 Gen1 8x SAS 3Gbps RAID 5 | RAID 0 | RAID 5 | RAID 5 | |
磁盘控制器驱动 | - | LSI MegaSR 13.06.0212.2009 | LSI SAS 3.8.0.64 | LSI SAS 3.8.0.64 | |
| 磁盘 | Seagate Savvio 10K.2 ST9146802SS x4 | Fujitsu MBA3300RC x2 | Fujitsu MBA3147RC x3 | Seagate Cheetah 15K.5 ST314655SS x3 | |
磁盘规格 | 10000RPM 146GB SAS 3Gbps 16MB Cache | 15000RPM 300GB SAS 3Gbps 16MB Cache | 15000RPM 147GB SAS 3Gbps 16MB Cache | 15000RPM 146GB SAS 3Gbps 16MB Cache | |
磁盘设置 | SAS 3Gbps 50GB系统分区 | SAS 3Gbps 50GB系统分区 | SAS 3Gbps 30GB系统分区 | SAS 3Gbps 20GB系统分区 | |
网络子系统 | |||||
网卡 | Intel 82575EB Dual Port Gigabit Network Controller Intel 82563EB Dual Port Gigabit Network PHY | Intel 82574 Gigabit Network Controller x2 | NVIDIA nForce Pro 3600 integrated MAC with Marvell 88E1121 PHY GbE Controller x2 | Broadcom BCM5708C PCI-E千兆网卡 x2 | |
网卡设置 | 82575EB: PCI Express x4 I/OAT TCP/RDMA/iSCSI CRC Acceleration VMDq Intel Teaming Load Balancing 82563EB: Kumeran @ 6321ESB Intel Teaming Load Balancing | PCI Express x1 @ ICH10R I/OAT Intel Teaming Load Balancing | Forceware Teaming Load Balancing | PCI Express x1 @ ESB6321 Broadcom NIC Teaming Load Balancing | |
网卡驱动 | Intel PRO Set 13.5 | Intel PRO Set 13.5 | NVIDIA NIC/LAN v67.76.1 | Broadcom NetXtreme 2 11.04.01 | |
软件环境 | |||||
| 操作系统 | Microsoft Windows Server 2008 Enterprise Edition SP1 x64 | Microsoft Windows Server 2008 Enterprise Edition SP1 x64 | Microsoft Windows Server 2003 R2 Enterprise Edition SP2 x64 | Microsoft Windows Server 2008 Enterprise Edition SP1 x64 | |
曙光I840r-H搭配了两组网卡:575EB和563EB,575EB提供了更好的性能和更多的特性,我们选择了基于575EB的两个网络端口进行了测试。

用来对比的45nm Shanghai Opteron 2378(左),也是基于曙光的服务器

用来对比的Nehalem-EP:Xeon X5570,主频2.93GHz,QPI频率3.2GHz
Intel 6-core Dunnington Xeon X7460
Intel 6-core Dunnington Xeon X7460
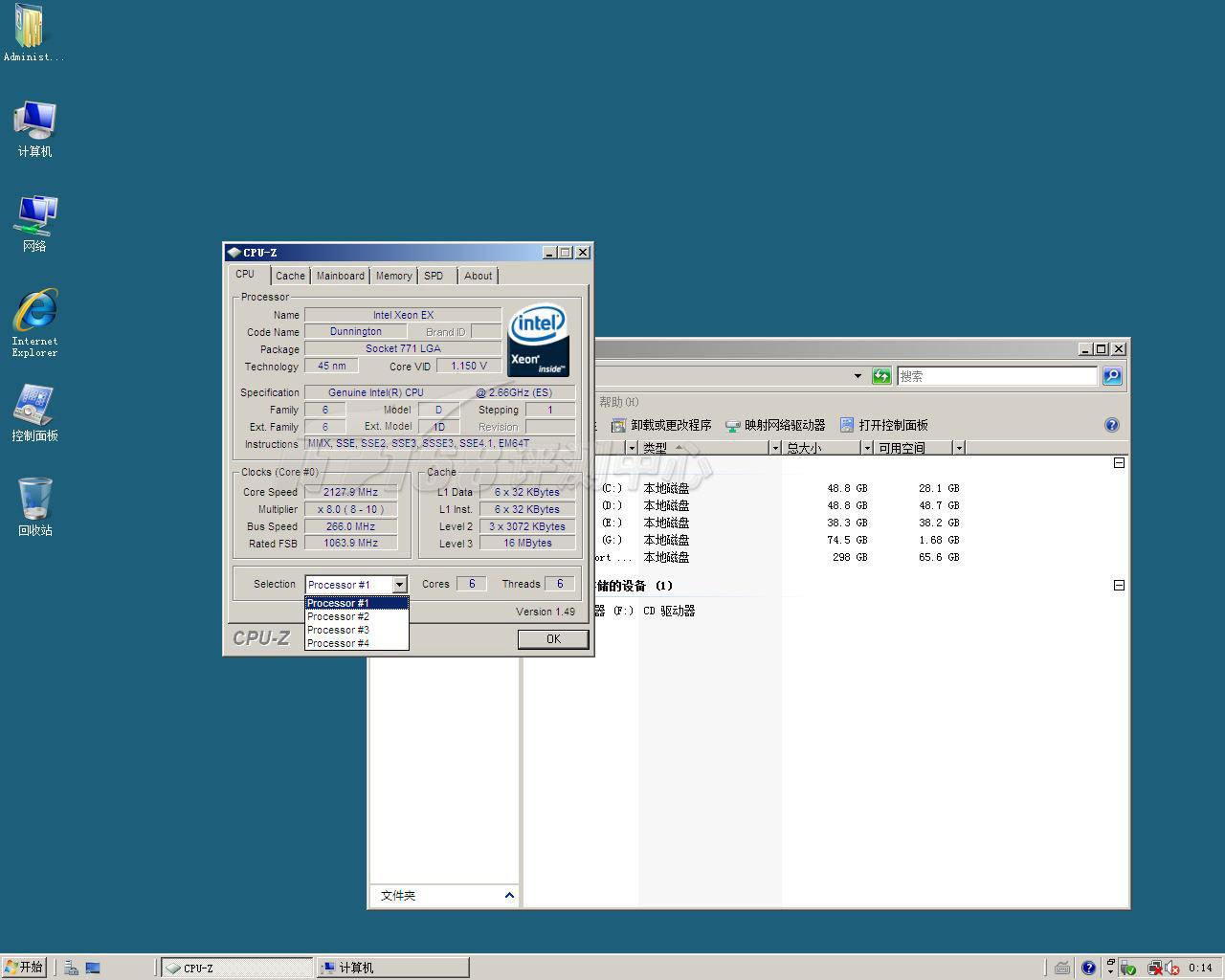
CPU-Z 1.49认不出Dunington Xeon X7460的准确型号,而显示为Xeon EX
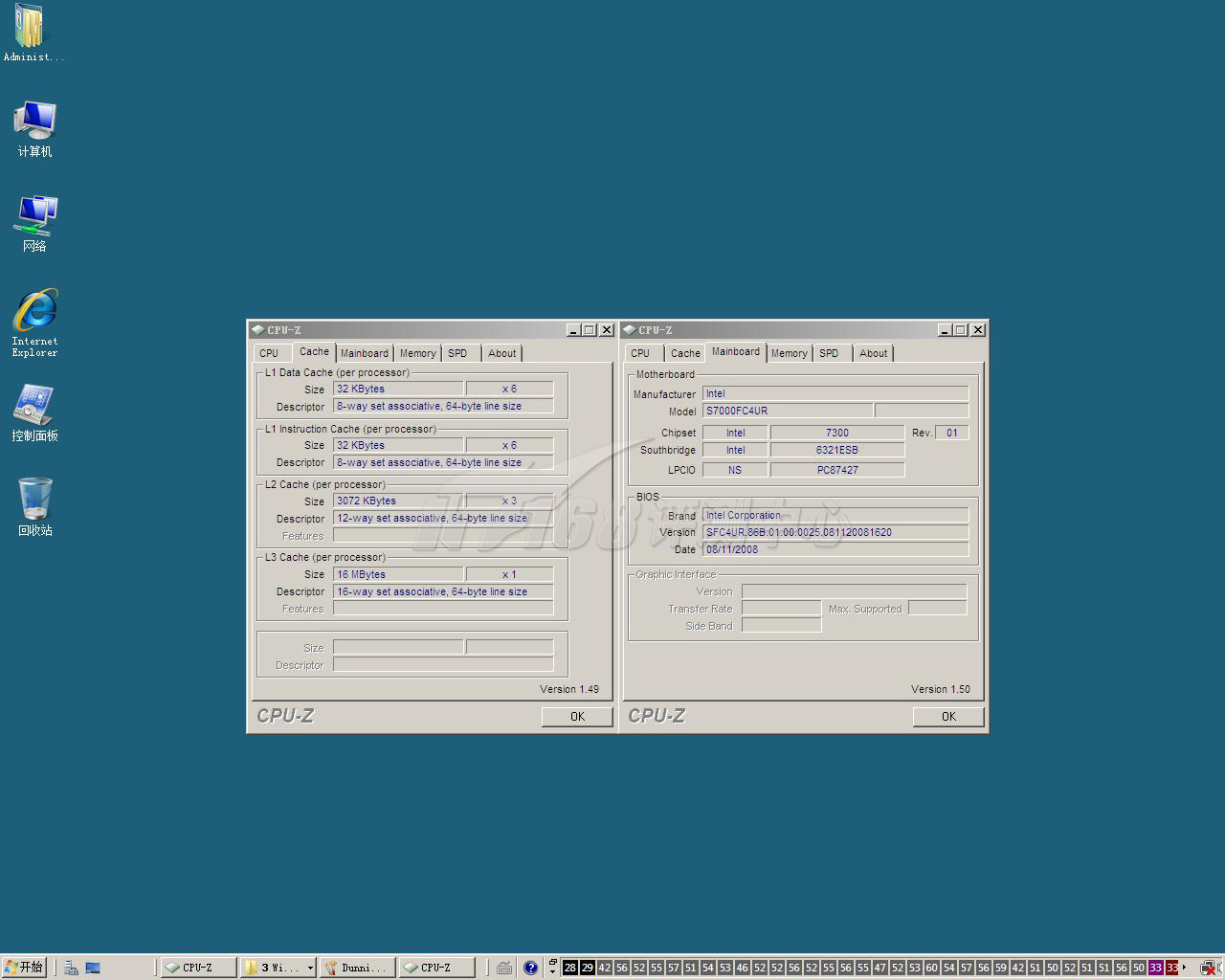
CPU-Z 1.50也认不出,我们顺便来看看缓存架构和主板……
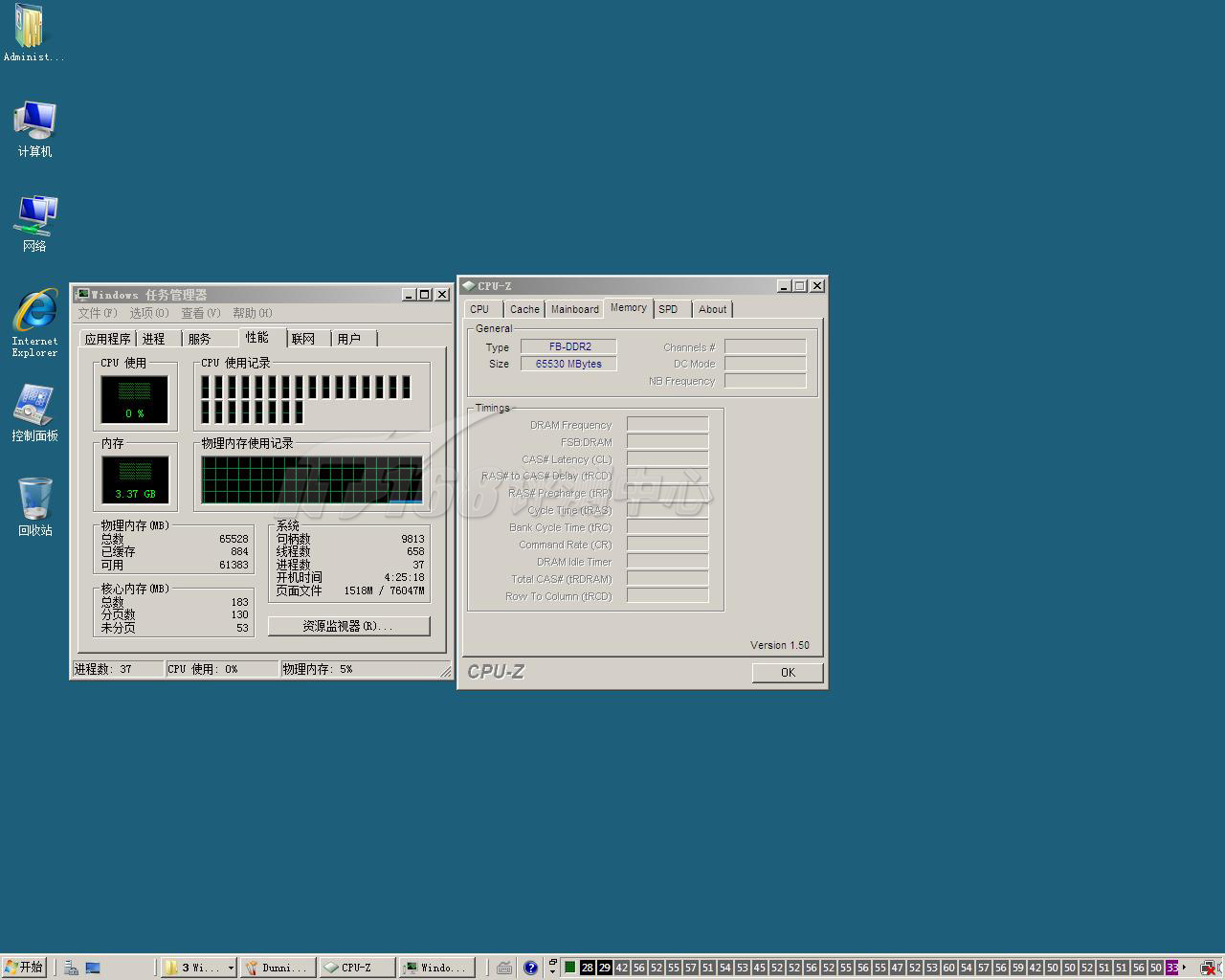
24个CPU核心,64GB内存,面对这样任务管理器面板你会有什么感觉?
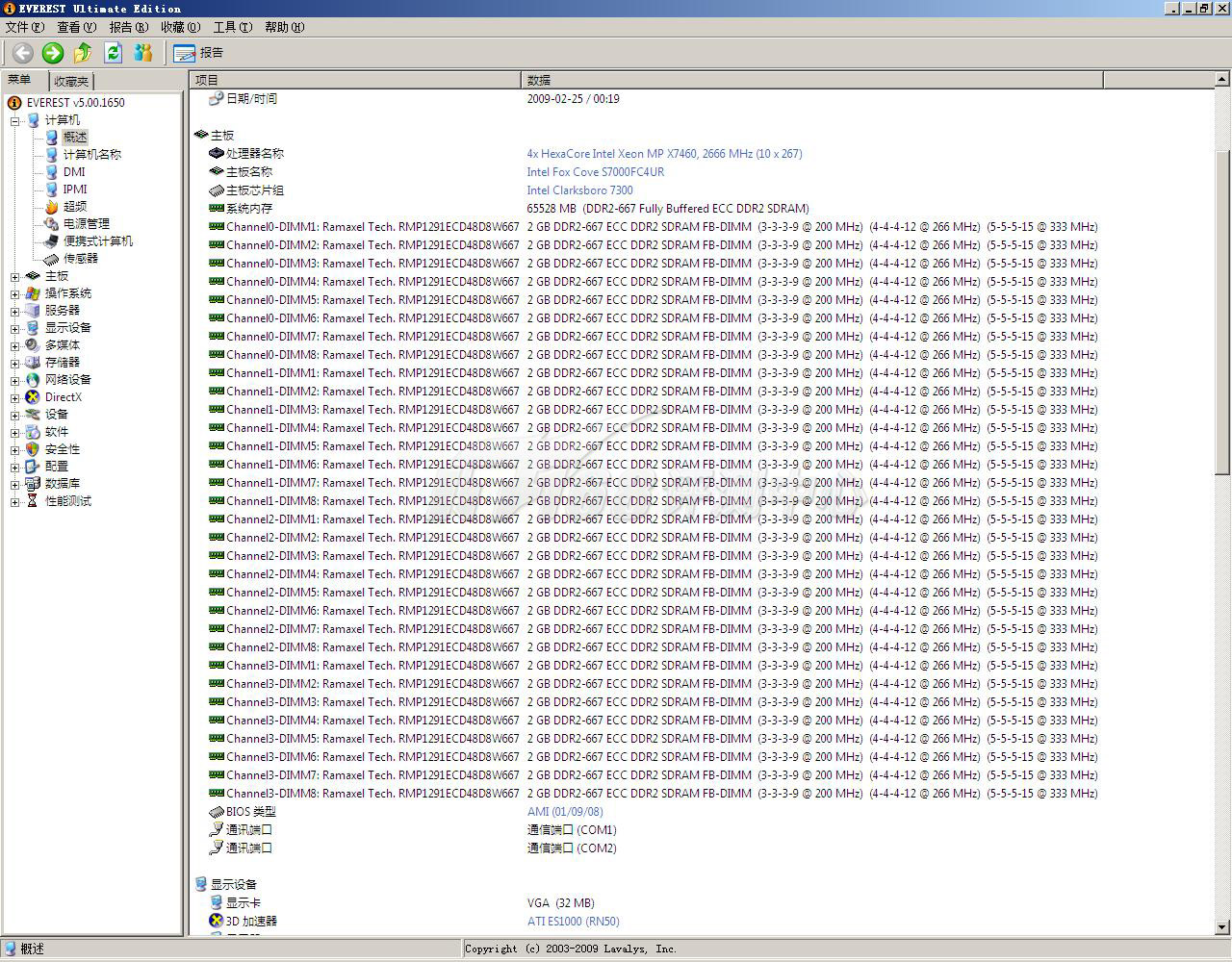
64GB:32条2GB FBD DDR2-667内存条,光是系统内存就显示了好长一列,不过Everest可以正确地认出Dunnington的型号规格:Xeon X7460
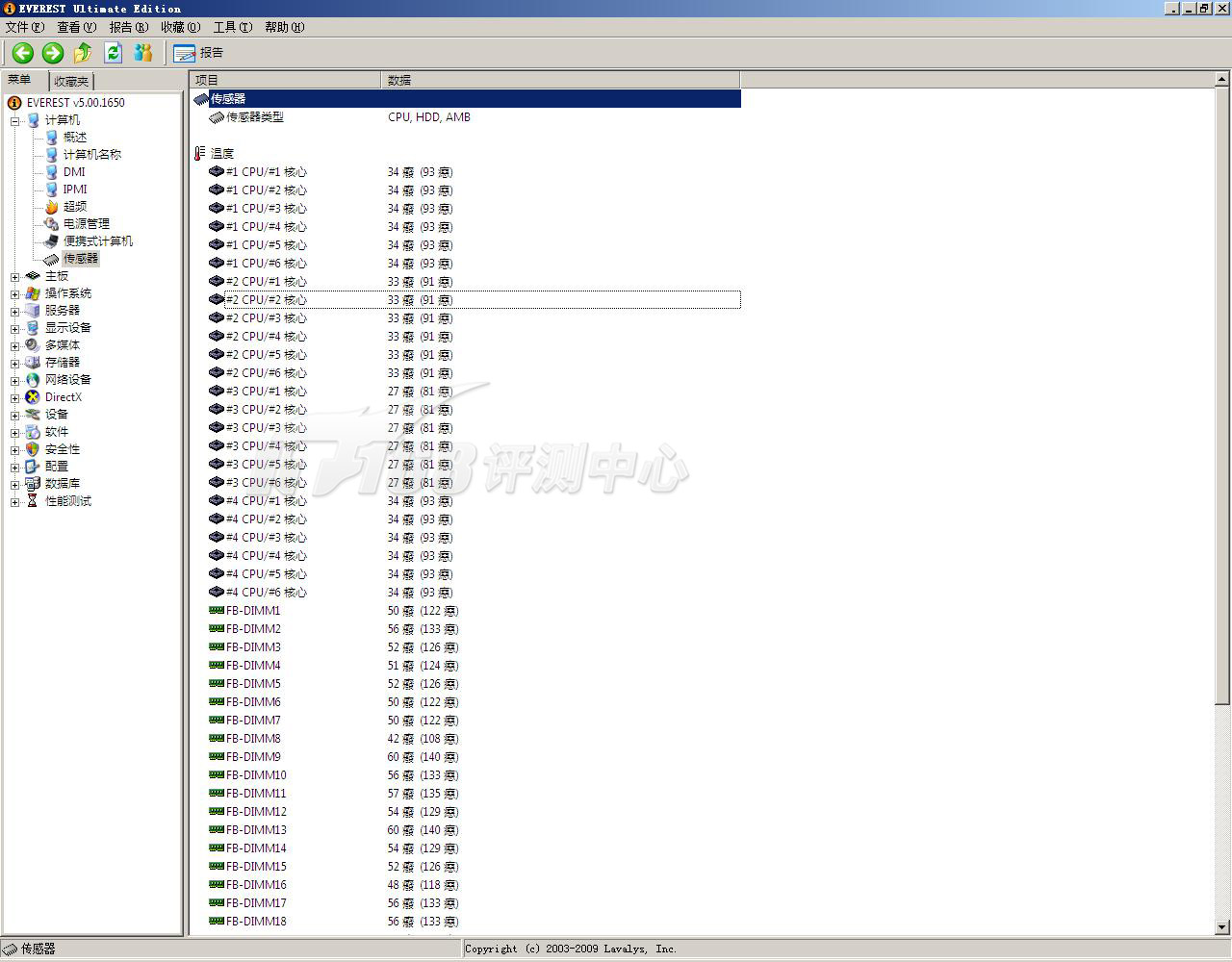
处理器温度和内存条温度
处理器温度和内存条温度
SiSoftware Sandra是一款可运行在32bit和64bit Windows操作系统上的分析软件,它可以对于系统进行方便、快捷的基准测试,还可以用于查看系统的软件、硬件等信息。SiSoftware Sandra所有的基准测试都针对SMP和SMT进行了优化,最高可支持32/64路平台。我们利用了其中多个性能测试模块对于被测系统的性能进行了快速的测试。
有一点需要说明的是,Sandra的处理器架构性能测试是根据处理器所能支持的所有指令集中选择进行的,不同的处理器支持的指令集不同,测试使用到的指令集也就不同。例如,Nehalem在这个测试当中就可以使用SSE4.2,而Penryn就只能使用SSE4.1,而Opteron可能就只能使用SSE3了。一般而言,由于可以使用SSE4,Intel的处理器理论性能会比较好。
| SiSoftware Sandra Pro Business 2009 | ||||
|---|---|---|---|---|
测试对象 | Dawning I840r-H服务器 四路Intel Dunnington Xeon X7460 2.66GHz | Intel Nehalem-EP 双路Intel Gainestown Xeon X5570 2.93GHz | Dawning A650 双路AMD Shanghai Operton 2378 2.40GHz | DELL PE2900 III 双路Intel Harptown Xeon E5430 2.66GHz |
Processor Arithmetic Benchmark 处理器架构测试 | ||||
Dhrystone ALU | 292201MIPS | 142977MIPS | 63082MIPS | 91006MIPS |
Dhrystone ALU vs SPEED | 109.85MIPS/MHz | 48.75MIPS/MHz | 26.28MIPS/MHz | 34.21MIPS/MHz |
Whetstone iSSE3 | 208685MFLOPS | 124035MFLOPS | 62993MFLOPS | 78385MFLOPS |
Dhrystone iSSE3 vs SPEED | 78.45MFLOPS/MHz | 42.29MFLOPS/MHz | 26.25MFLOPS/MHz | 29.47MFLOPS/MHz |
Processor Multi-Media Benchmark 处理器多媒体测试 | ||||
Multi-Media Int x16 iSSE4.1 | 753.51MPixel/s | 296.85MPixel/s | ||
Multi-Media Int x8 aSSE2 | 187.70MPixel/s | |||
Multi-Media Int x8 iSSE4.1 | 199.33MPixel/s | |||
Multi-Media Int x16 iSSE4.1 vs SPEED | 283.27kPixel/s/MHz | 101.21kPixel/s/MHz | ||
Multi-Media Int x8 aSSE2 vs SPEED | 78.21kPixel/s/MHz | |||
Multi-Media Int x8 iSSE4.1 vs SPEED | 74.94kPixel/s/MHz | |||
Multi-Media Float x8 iSSE2 | 501.36MPixel/s | 228.24MPixel/s | ||
Multi-Media Float x4 iSSE2 | 81.53MPixel/s | 108.69MPixel/s | ||
Multi-Media Float x8 iSSE2 vs SPEED | 188.48kPixel/s/MHz | 77.82kPixels/s/MHz | ||
Multi-Media Float x4 iSSE2 vs SPEED | 33.97kPixels/s/MHz | 40.86kPixels/s/MHz | ||
Multi-Media Double x4 iSSE2 | 260.18MPixel/s | 125.88MPixel/s | ||
Multi-Media Double x2 iSSE2 | 44.51MPixel/s | 55.75MPixel/s | ||
Multi-Media Double x4 iSSE2 vs SPEED | 97.81kPixel/s/MHz | 42.92kPixels/s/MHz | ||
Multi-Media Double x2 iSSE2 vs SPEED | 18.55kPixels/s/MHz | 20.96kPixels/s/MHz | ||
Multi-Core Efficiency Benchmark | ||||
Inter-Core Bandwidth | 12.88GB/s | 75.61GB/s | 6.54GB/s | 20.54GB/s |
Inter-Core Bandwidth vs SPEED | 4.96MB/s/MHz | 26.40MB/s/MHz | 2.79MB/s/MHz | 7.91MB/s/MHz |
Inter-Core Latency (越小越好) | 110ns | 16ns | 128ns | 90ns |
Inter-Core Latency vs SPEED (越小越好) | 0.04ns/MHz | 0.01ns/MHz | 0.05ns/MHz | 0.03ns/MHz |
.NET Arithmetic Benchmark .NET架构测试 | ||||
Dhrystone .NET | 75397MIPS | 32904MIPS | 12736MIPS | 10562MIPS |
Dhrystone .NET vs SPEED | 28.34MIPS/MHz | 11.22MIPS/MHz | 5.31MIPS/MHz | 3.97MIPS/MHz |
Whetstone .NET | 136088MFLOPS | 78286MFLOPS | 38737MFLOPS | 45399MFLOPS |
Whetstone .NET vs SPEED | 51.16MFLOPS/MHz | 26.69MFLOPS/MHz | 15.62MFLOPS/MHz | 17.07MFLOPS/MHz |
.NET Multi-Media Benchmark .NET多媒体测试 | ||||
Multi-Media Int x1 .NET | 119.30MPixel/s | 62.28MPixel/s | 24.48MPixel/s | 31.28MPixel/s |
Multi-Media Int x1 .NET vs SPEED | 44.85kPixels/s/MHz | 21.23kPixels/s/MHz | 10.20kPixels/s/MHz | 11.76kPixels/s/MHz |
Multi-Media Float x1 .NET | 31.74MPixel/s | 26.19MPixel/s | 5.29MPixel/s | 8.68MPixel/s |
Multi-Media Float x1 .NET vs SPEED | 11.93kPixels/s/MHz | 8.93kPixels/s/MHz | 2.20kPixels/s/MHz | 3.26kPixels/s/MHz |
Multi-Media Double x1 .NET | 58.72MPixel/s | 51.45MPixel/s | 21.31MPixel/s | 24.75MPixel/s |
Multi-Media Double x1 .NET vs SPEED | 22.07kPixels/s/MHz | 17.54kPixels/s/MHz | 8.88kPixels/s/MHz | 9.30kPixels/s/MHz |
SiSoftware Sandra对比,用蓝色标出了性能特出的项目
处理器架构性能测试分为整数和浮点两个部分,由于具有较多的处理核心(四路六核,总共24个物理内核),因此在频率更低的情况下,各种理论测试成绩都要超过Nehalem-EP处理器(双路四核带超线程,8个物理内核,16个虚拟处理器),得分幅度超出100%左右。Dunnington只有多核心效率方面带宽不如Nehalem-EP,FSB总线确实不如QPI总线架构。
SiSoftware Sandra缓存内存测试主要包括内存带宽、内存延迟等性能的测试。
| SiSoftware Sandra Pro Business 2009 | ||||
|---|---|---|---|---|
测试对象 | Dawning I840r-H服务器 四路Intel Dunnington Xeon X7460 2.66GHz | Intel Nehalem-EP 双路Intel Gainestown Xeon X5570 2.93GHz | Dawning A650 双路AMD Shanghai Operton 2378 2.40GHz | DELL PE2900 III 双路Intel Harptown Xeon E5430 2.66GHz |
Memory Bandwidth Benchmark 内存带宽测试 | ||||
Int Buff'd iSSE2 Memory Bandwidth | 3.49GB/s | 16.93GB/s | 16.59GB/s | 6.13GB/s |
Int Buff'd iSSE2 Memory Bandwidth vs SPEED | 25.52MB/s/MHz | 9.43MB/s/MHz | ||
Float Buff'd iSSE2 Memory Bandwidth | 3.50GB/s | 16.90GB/s | 16.58GB/s | 6.13GB/s |
Float Buff'd iSSE2 Memory Bandwidth vs SPEED | 25.50MB/s/MHz | 9.43MB/s/MHz | ||
Memory Latency Benchmark 内存延迟测试 | ||||
Memory(Random Access) Latency (越小越好) | 81ns | 106ns | 108ns | |
Memory(Random Access) Latency vs SPEED (越小越好) | 0.16ns/MHz | 0.16ns/MHz | ||
Speed Factor (越小越好) | 61.40 | 83.80 | 95.20 | |
Internal Data Cache | 4clocks | 3clocks | 3clocks | |
L2 On-board Cache | 10clocks | 16clocks | 18clocks | |
L3 On-board Cache | 48clocks | 58clocks | ||
Cache and Memory Benchmark 缓存及内存测试 | ||||
Cache/Memory Bandwidth | 143.24GB/s | 77.08GB/s | 68.88GB/s | |
Cache/Memory Bandwidth vs SPEED | 50.01MB/s/MHz | 32.89MB/s/MHz | 26.52MB/s/MHz | |
Speed Factor (越小越好) | 20.90 | 36.00 | 111.90 | |
Internal Data Cache | 448.46GB/s | 299.00GB/s | 421.23GB/s | |
L2 On-board Cache | 421.42GB/s | 162.91GB/s | 122.68GB/s | |
SiSoftware Sandra对比,用蓝色标出了性能特出的项目
可能是Sandra对多路系统支持不太好的关系,最终只得到一个内存带宽成绩,而且结果比起二路至强还要低不少。
SPEC CPU 2006整数运算主要包含编译、压缩、人工智能、视频压缩转换、XML处理等,此外,各种日常操作也主要是基于整数操作。SPEC CPU 2006的整数运算包含了400.perlbench PERL编程语言、401.bzip2 压缩、403.gcc C编译器、429.mcf 组合优化、445.gobmk 人工智能:围棋、456.hmmer 基因序列搜索、458.sjeng 人工智能:国际象棋、462.libquantum 物理:量子计算、464.h264ref 视频压缩、471.omnetpp 离散事件仿真、473.astar 寻路算法、483.xalancbmk XML处理共12项。
Dawning I840r-H四路六核Dunnington服务器SPEC CPU 2006整数运算性能
我们已经知道了Nehalem-EP/Gainestown具有非常强大的SPEC性能,它的直联架构(内置内存控制器和QPI总线)、超线程技术都具有很明显的效果——不过采用老FSB架构的四路六核Dunnington(172分)几乎已经追上了Nehalem-EP,在不少项目中甚至比Nehalem-EP都要强一倍以上,毕竟Dunnington具备的是实打实的物理处理核心,Nehalem-EP的超线程虚拟核心无法与之相比。
SPEC CPU 2006的浮点运算测试包括的全部都是科学运算,科学运算需要用到大量的高精度浮点数据,如410.bwaves 流体力学、416.gamess 量子化学、433.milc 量子力学、434.zeusmp 物理:计算流体力学、435.gromacs 生物化学/分子力学、436.cactusADM 物理:广义相对论、437.leslie3d 流体力学、444.namd 生物/分子、447.dealII 有限元分析、450.soplex 线形编程、优化、453.povray 影像光线追踪、454.calculix 结构力学、459.GemsFDTD 计算电磁学、465.tonto 量子化学、470.lbm 流体力学、481.wrf 天气预报、482.sphinx3 语音识别共17项测试。
Dawning I840r-H四路六核Dunnington服务器SPEC CPU 2006整数运算性能
浮点运算上的Dunnington和Nehalem-EP的差距比整数上的大一些,曙光I840-H的得分为129,在频率相同的情况下和Nehalem-EP差不了多少(X5570是2.93GHz)。有不少项目中Dunnington的物理核心表现出了很大的优势,不过也有不少项目略厚于Nehalem-EP较多。四路Dunnington是二路Harpertown的2~3倍性能。处理核心上Dunnington平台是Harpertown的3倍,结果有几个项目的成绩几乎达到了3倍的比率,这表明Dunnington架构的效率不错。
ScienceMark v2.0 Membench
ScienceMark v2.0是一款用于测试系统特别是处理器在科学计算应用中的性能的软件,MemBenchmark是其中针对处理器缓存、系统内存而设计的功能模块,它可以测试系统内存带宽、L1 Cache延迟、L2 Cache延迟和系统内存延迟,另外还可以测试不同指令集的性能差异。
首先我们进行的是ScienceMark的测试,主要考察系统的缓存和内存子系统情况。L1/L2 Cache的成绩主要是跟处理器频率相关,因为目前的处理器当中L1 Cache都是和处理器核心同频率的,而L2 Cache基本上也是——当前的处理器L2都是全速的(放置在处理器内但不在同一个芯片上的Pentium II为半速L2,而Pentium之前的处理器L2则和处理器分离,速度更低)。越快的频率,L1/L2性能就越好。而内存带宽主要由两部分相关:比较大的部分是内存架构,小部分是内存操作指令(集),例如使用最新的SSE指令集比通常的ALU指令集会得到更大的吞吐量,而不同的SSE版本性能也有不同。
| ScienceMark Membench | ||||
|---|---|---|---|---|
| 厂商 | Dawning | Intel | Dawning | DELL |
| 产品型号 | Dawning I840r-H服务器 四路Intel Dunnington Xeon X7460 2.66GHz | Nehalem-EP Intel Gainestown Xeon X5570 2.93GHz | Dawning A650 AMD Shanghai Operton 2378 2.40GHz | PowerEdge 2900 III Intel Harpertown Xeon E5430 2.66GHz |
| 内存技术参数 | 2GB FBD-DDR2 667 SDRAM x32 | 4GB R-ECC DDR3-1333 SDRAM x6 | 2GB R-ECC DDR2-667 SDRAM x8 | 2GB FBD-DDR2 667 SDRAM x8 |
| L1带宽(MB/s) | 58513.77 | 47880.48 | 48167.88 | 55376.16 |
| L2带宽(MB/s) | 17838.86 | 19604.64 | 14314.34 | 16757.55 |
| 内存带宽(MB/s) | 4900.96 | 10116.61 | 6672.76 | 4485.09 |
| L1 Cache Latency(ns) | ||||
| 32 Bytes Stride | 3 cycles 1.13 ns | 2 cycles 0.68 ns | 1.25 ns | 1.13 ns |
| L1 Algorithm Bandwidth(MB/s) | ||||
| Compiler | 26941.75 | 43072.25 | 34042.63 | 25201.96 |
| REP MOVSD | 26812.27 | 43467.25 | 34864.10 | 25467.15 |
| ALU Reg Copy | 13765.53 | 11949.09 | 12166.94 | 13093.65 |
| MMX Reg Copy | 26478.74 | 22537.36 | 25698.47 | 25242.19 |
| SSE PAlign | 51529.75 | 47773.13 | 48167.40 | 52826.21 |
| SSE2 PAlign | 58513.77 | 47880.48 | 48167.88 | 55376.16 |
| L2 Cache Latency(ns) | ||||
| 4 Bytes Stride | 3 cycles 1.13 ns | 3 cycles 1.02 ns | 1.25 ns | 1.13 ns |
| 16 Bytes Stride | 4 cycles 1.50 ns | 3 cycles 1.02 ns | 1.25 ns | 1.50 ns |
| 64 Bytes Stride | 12 cycles 4.51 ns | 8 cycles 2.73 ns | 3.75 ns | 4.51 ns |
| 256 Bytes Stride | 12 cycles 4.51 ns | 8 cycles 2.73 ns | 6.25 ns | 4.51 ns |
| 512 Bytes Stride | 12 cycles 4.51 ns | 7 cycles 2.39 ns | 6.25 ns | 4.89 ns |
| L2 Algorithm Bandwidth(MB/s) | ||||
| Compiler | 11437.71 | 18039.64 | 11609.57 | 11880.48 |
| REP MOVSD | 13352.53 | 19604.64 | 12140.00 | 12536.88 |
| ALU Reg Copy | 9126.84 | 8788.90 | 9273.71 | 8577.86 |
| MMX Reg Copy | 14282.76 | 14083.83 | 12042.45 | 13408.31 |
| SSE PAlign | 17799.83 | 18731.92 | 14314.34 | 16719.97 |
| SSE2 PAlign | 17838.86 | 5833.93 | 14289.88 | 16757.55 |
| Memory Latency(ns) | ||||
| 4 Bytes Stride | 3 cycles 1.13 ns | 3 cycles 1.02 ns | 1.67 ns | 1.13 ns |
| 16 Bytes Stride | 7 cycles 2.63 ns | 5 cycles 1.70 ns | 5.00 ns | 4.89 ns |
| 64 Bytes Stride | 28 cycles 10.53 ns | 22 cycles 7.50 ns | 20.00 ns | 19.17 ns |
| 256 Bytes Stride | 84 cycles 31.58 ns | 102 cycles 34.77 ns | 34.58 ns | 59.77 ns |
| 512 Bytes Stride | 92 cycles 34.59 ns | 117 cycles 39.88 ns | 81.24 ns | 68.04 ns |
| Memory Algorithm Bandwidth(MB/s) | ||||
| Compiler | 2164.80 | 9210.17 | 2872.77 | 3178.45 |
| REP MOVSD | 2190.46 | 10116.61 | 2887.02 | 3220.23 |
| ALU Reg Copy | 1956.91 | 8156.00 | 2654.29 | 2789.34 |
| MMX Reg Copy | 2021.46 | 9306.18 | 2943.85 | 2972.91 |
| MMX Reg 3dNow | - | - | 6631.75 | - |
| MMX Reg SSE | 4598.63 | 8781.26 | 6672.76 | 3978.53 |
| SSE PAlign | 4616.86 | 8580.24 | 5765.46 | 4128.59 |
| SSE PAlign SSE | 4886.40 | 9524.07 | 6611.10 | 4390.48 |
| SSE2 PAlign | 4608.71 | 8560.83 | 5766.87 | 4326.42 |
| SSE2 PAlign SSE | 4900.96 | 9555.13 | 6612.42 | 4441.71 |
| MMX Block 4kb | 2225.76 | 7743.82 | 4450.46 | 4063.30 |
| MMX Block 16kb | 3539.86 | 8321.35 | 4677.49 | 4479.88 |
| SSE Block 4kb | 2074.97 | 7890.10 | 4441.71 | 4074.79 |
| SSE Block 16kb | 3667.31 | 8355.86 | 4681.34 | 4485.09 |
表现比同频率Harpertown略好。
CineBench R10
CineBench是基于Cinem4D工业三维设计软件引擎的测试软件,用来测试对象在进行三维设计时的性能,它可以同时测试处理器子系统、内存子系统以及显示子系统,我们的平台偏向于服务器多一些,因此就只有前两个的成绩具有意义。和大多数工业设计软件一样,CineBench可以完善地支持多核/多处理器,它的显示子系统测试基于OpenGL。
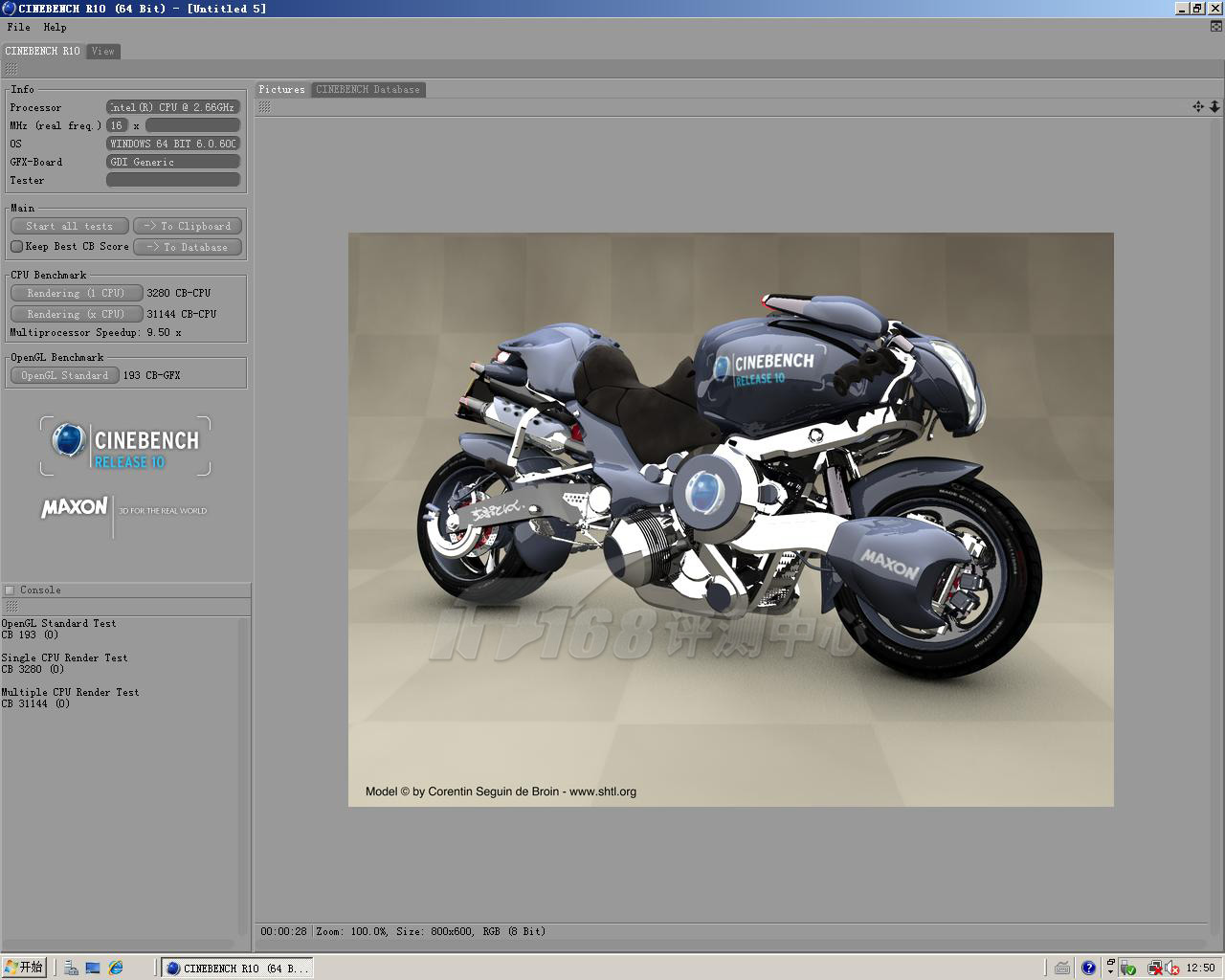
曙光I840r-H六核心Dunnington至强服务器测试成绩
CineBench R10 | ||||
处理器 | Dawning I840r-H服务器 四路Intel Dunnington Xeon X7460 | 双路Intel Gainestown Xeon X5570 | 双路AMD Shanghai Operton 2378 | 双路Intel Harpertown Xeon E5430 |
| 显卡 | - | - | - | - |
CPU Benchmark | ||||
| Rendering (1 CPU) | 3280 CB-CPU | 4410 CB-CPU | 1797 CB-CPU | 2931 CB-CPU |
| Rendering (x CPU) | 31144 CB-CPU | 28172 CB-CPU | 10734 CB-CPU | 16806 CB-CPU |
Multiprocessor Speedup | 9.50x | 6.39x | 5.97x | 5.73x |
OpenGL Benchmark | ||||
OpenGL Standard | 193 CB-GFX | 224 CB-GFX | 98 CB-GFX | 176 CB-GFX |
曙光I840r-H六核心Dunnington至强服务器测试成绩
单处理器的渲染性能,Dunnington Xeon比同频率的Harpertown要高11.9%,这应该是包括L3在内的Uncore部分带来的结果。
在多处理器的渲染测试中,Dunnington平台也是最高的,在图形相关的浮点运算能力上,四路六核平台表现不错,比Nehalem-EP平台要高。
Iometer 2006.07.27
我们的基准服务器采用了三块15000RPM的Seagate Cheetah 15K.5硬盘。曙光I840r-H则是用四块10000RPM Seagate Savvio 10K.2。基准平台使用了LSI MegaRAID SAS 8408E硬件阵列卡组建了RAID 5阵列,而测试样机使用了一块基于LSISAS1078芯片、512MB内存的Intel ROMB阵列卡。可见,曙光I840r-H的配置要高一些。
IO读
IO写
读吞吐量
写吞吐量
曙光I840r-H的阵列卡配置较高,而且Savvio系列硬盘是2.5"外形因子,因此具有较好的IO能力,最终性能表现比我们的基准平台好不少。
NetBench v7.03
NetBench 7.03 Ent_dm.tst测试脚本模拟的是企业级文件服务器应用,它不但要求被测服务器的磁盘子系统可以提供足够的吞吐量,还需要其具有较高的IO处理能力,并且需要较为平衡的读取能力和写入能力。
NetBench性能测试
Dunnington平台的成绩略为低一点。关于NetBench性能与处理器、内存、磁盘的关系可以看这里《评测机密:文件服务器性能提升N大要义》。
我们利用UNI-T UT71E智能数字万用表和相配套的软件对于对于被测服务器在几种不同的状态下的功耗进行了监测,主要包括如下项目:
P1:连接电源但不开机状态
P2:系统启动完毕,5分钟内无动作,但不休眠
P3:系统启动完毕,处理器满载、磁盘以最大吞吐量工作
功耗:四路平台
由于四路平台更多地为系统的RAS考虑,因此低功率通常不是考量方向,和二路平台没有太大的可比性。
我们还额外测试了只装备了两个处理器情况下的曙光I840r-H服务器的性能:
| SiSoftware Sandra Pro Business 2009 | |||
|---|---|---|---|
测试对象 | Dawning I840r-H服务器 四路Intel Dunnington Xeon X7460 2.66GHz | Dawning I840-H服务器 双路Intel Dunnington Xeon X7460 2.66GHz | DELL PE2900 III 双路Intel Harptown Xeon E5430 2.66GHz |
Processor Arithmetic Benchmark 处理器架构测试 | |||
Dhrystone ALU | 292201MIPS | 146284MIPS | 91006MIPS |
Dhrystone ALU vs SPEED | 109.85MIPS/MHz | 54.99MIPS/MHz | 34.21MIPS/MHz |
Whetstone iSSE3 | 208685MFLOPS | 104325MFLOPS | 78385MFLOPS |
Dhrystone iSSE3 vs SPEED | 78.45MFLOPS/MHz | 39.22MFLOPS/MHz | 29.47MFLOPS/MHz |
Processor Multi-Media Benchmark 处理器多媒体测试 | |||
Multi-Media Int x16 iSSE4.1 | 753.51MPixel/s | 376.72MPixel/s | |
Multi-Media Int x8 aSSE2 | |||
Multi-Media Int x8 iSSE4.1 | 199.33MPixel/s | ||
Multi-Media Int x16 iSSE4.1 vs SPEED | 283.27kPixel/s/MHz | 141.62kPixel/s/MHz | |
Multi-Media Int x8 aSSE2 vs SPEED | |||
Multi-Media Int x8 iSSE4.1 vs SPEED | 74.94kPixel/s/MHz | ||
Multi-Media Float x8 iSSE2 | 501.36MPixel/s | 252.26MPixel/s | |
Multi-Media Float x4 iSSE2 | 108.69MPixel/s | ||
Multi-Media Float x8 iSSE2 vs SPEED | 188.48kPixel/s/MHz | 94.83kPixels/s/MHz | |
Multi-Media Float x4 iSSE2 vs SPEED | 40.86kPixels/s/MHz | ||
Multi-Media Double x4 iSSE2 | 260.18MPixel/s | 130.98MPixel/s | |
Multi-Media Double x2 iSSE2 | 55.75MPixel/s | ||
Multi-Media Double x4 iSSE2 vs SPEED | 97.81kPixel/s/MHz | 49.24kPixels/s/MHz | |
Multi-Media Double x2 iSSE2 vs SPEED | 20.96kPixels/s/MHz | ||
Multi-Core Efficiency Benchmark | |||
Inter-Core Bandwidth | 12.88GB/s | 5.92GB/s | 20.54GB/s |
Inter-Core Bandwidth vs SPEED | 4.96MB/s/MHz | 2.28MB/s/MHz | 7.91MB/s/MHz |
Inter-Core Latency (越小越好) | 110ns | 113ns | 90ns |
Inter-Core Latency vs SPEED (越小越好) | 0.04ns/MHz | 0.04ns/MHz | 0.03ns/MHz |
.NET Arithmetic Benchmark .NET架构测试 | |||
Dhrystone .NET | 75397MIPS | 13460MIPS | 10562MIPS |
Dhrystone .NET vs SPEED | 28.34MIPS/MHz | 5.06MIPS/MHz | 3.97MIPS/MHz |
Whetstone .NET | 136088MFLOPS | 69152MFLOPS | 45399MFLOPS |
Whetstone .NET vs SPEED | 51.16MFLOPS/MHz | 26.00MFLOPS/MHz | 17.07MFLOPS/MHz |
.NET Multi-Media Benchmark .NET多媒体测试 | |||
Multi-Media Int x1 .NET | 119.30MPixel/s | 60.45MPixel/s | 31.28MPixel/s |
Multi-Media Int x1 .NET vs SPEED | 44.85kPixels/s/MHz | 22.72kPixels/s/MHz | 11.76kPixels/s/MHz |
Multi-Media Float x1 .NET | 31.74MPixel/s | 16.25MPixel/s | 8.68MPixel/s |
Multi-Media Float x1 .NET vs SPEED | 11.93kPixels/s/MHz | 6.11kPixels/s/MHz | 3.26kPixels/s/MHz |
Multi-Media Double x1 .NET | 58.72MPixel/s | 29.98MPixel/s | 24.75MPixel/s |
Multi-Media Double x1 .NET vs SPEED | 22.07kPixels/s/MHz | 11.27kPixels/s/MHz | 9.30kPixels/s/MHz |
性能下降比较明显,不过仍然比同频率的Harpertown高,一些项目高出一倍,除了核心数量上的差异,Dunnington的Uncore/L3缓存也发挥了作用。
| SiSoftware Sandra Pro Business 2009 | |||
|---|---|---|---|
测试对象 | Dawning I840r-H服务器 四路Intel Dunnington Xeon X7460 2.66GHz | Dawning I840r-H服务器 双路Intel Dunnington Xeon X7460 2.66GHz | DELL PE2900 III 双路Intel Harptown Xeon E5430 2.66GHz |
Memory Bandwidth Benchmark 内存带宽测试 | |||
Int Buff'd iSSE2 Memory Bandwidth | 3.49GB/s | 3.38GB/s | 6.13GB/s |
Int Buff'd iSSE2 Memory Bandwidth vs SPEED | 9.43MB/s/MHz | ||
Float Buff'd iSSE2 Memory Bandwidth | 3.50GB/s | 3.38GB/s | 6.13GB/s |
Float Buff'd iSSE2 Memory Bandwidth vs SPEED | 9.43MB/s/MHz | ||
Memory Latency Benchmark 内存延迟测试 | |||
Memory(Random Access) Latency (越小越好) | 108ns | ||
Memory(Random Access) Latency vs SPEED (越小越好) | 0.16ns/MHz | ||
Speed Factor (越小越好) | 95.20 | ||
Internal Data Cache | 3clocks | ||
L2 On-board Cache | 18clocks | ||
L3 On-board Cache | |||
Cache and Memory Benchmark 缓存及内存测试 | |||
Cache/Memory Bandwidth | 68.88GB/s | ||
Cache/Memory Bandwidth vs SPEED | 26.52MB/s/MHz | ||
Speed Factor (越小越好) | 111.90 | ||
Internal Data Cache | 421.23GB/s | ||
L2 On-board Cache | 122.68GB/s | ||
| ScienceMark Membench | |||
|---|---|---|---|
| 厂商 | Dawning | Dawning | DELL |
| 产品型号 | Dawning I840r-H服务器 四路Intel Dunnington Xeon X7460 2.66GHz | Dawning I840r-H服务器 双路Intel Dunnington Xeon X7460 2.66GHz | PowerEdge 2900 III Intel Harpertown Xeon E5430 2.66GHz |
| 内存技术参数 | 2GB FBD-DDR2 667 SDRAM x32 | 2GB FBD-DDR2 667 SDRAM x32 | 2GB FBD-DDR2 667 SDRAM x8 |
| L1带宽(MB/s) | 58513.77 | 58512.24 | 55376.16 |
| L2带宽(MB/s) | 17838.86 | 17821.69 | 16757.55 |
| 内存带宽(MB/s) | 4900.96 | 5060.06 | 4485.09 |
| L1 Cache Latency(ns) | |||
| 32 Bytes Stride | 3 cycles 1.13 ns | 3 cycles 1.13 ns | 1.13 ns |
| L1 Algorithm Bandwidth(MB/s) | |||
| Compiler | 26941.75 | 26943.69 | 25201.96 |
| REP MOVSD | 26812.27 | 26958.95 | 25467.15 |
| ALU Reg Copy | 13765.53 | 12497.85 | 13093.65 |
| MMX Reg Copy | 26478.74 | 26876.69 | 25242.19 |
| SSE PAlign | 51529.75 | 51529.75 | 52826.21 |
| SSE2 PAlign | 58513.77 | 58512.24 | 55376.16 |
| L2 Cache Latency(ns) | |||
| 4 Bytes Stride | 3 cycles 1.13 ns | 3 cycles 1.13 ns | 1.13 ns |
| 16 Bytes Stride | 4 cycles 1.50 ns | 4 cycles 1.50 ns | 1.50 ns |
| 64 Bytes Stride | 12 cycles 4.51 ns | 13 cycles 4.69 ns | 4.51 ns |
| 256 Bytes Stride | 12 cycles 4.51 ns | 12 cycles 4.51 ns | 4.51 ns |
| 512 Bytes Stride | 12 cycles 4.51 ns | 13 cycles 4.69 ns | 4.89 ns |
| L2 Algorithm Bandwidth(MB/s) | |||
| Compiler | 11437.71 | 12319.47 | 11880.48 |
| REP MOVSD | 13352.53 | 13318.08 | 12536.88 |
| ALU Reg Copy | 9126.84 | 9143.31 | 8577.86 |
| MMX Reg Copy | 14282.76 | 13618.03 | 13408.31 |
| SSE PAlign | 17799.83 | 17821.69 | 16719.97 |
| SSE2 PAlign | 17838.86 | 17819.32 | 16757.55 |
| Memory Latency(ns) | |||
| 4 Bytes Stride | 3 cycles 1.13 ns | 3 cycles 1.13 ns | 1.13 ns |
| 16 Bytes Stride | 7 cycles 2.63 ns | 7 cycles 2.63 ns | 4.89 ns |
| 64 Bytes Stride | 28 cycles 10.53 ns | 26 cycles 9.77 ns | 19.17 ns |
| 256 Bytes Stride | 84 cycles 31.58 ns | 85 cycles 31.96 ns | 59.77 ns |
| 512 Bytes Stride | 92 cycles 34.59 ns | 92 cycles 34.59 ns | 68.04 ns |
| Memory Algorithm Bandwidth(MB/s) | |||
| Compiler | 2164.80 | 2169.36 | 3178.45 |
| REP MOVSD | 2190.46 | 2205.04 | 3220.23 |
| ALU Reg Copy | 1956.91 | 1965.12 | 2789.34 |
| MMX Reg Copy | 2021.46 | 2027.41 | 2972.91 |
| MMX Reg 3dNow | - | - | - |
| MMX Reg SSE | 4598.63 | 4698.08 | 3978.53 |
| SSE PAlign | 4616.86 | 4737.16 | 4128.59 |
| SSE PAlign SSE | 4886.40 | 5010.16 | 4390.48 |
| SSE2 PAlign | 4608.71 | 4736.02 | 4326.42 |
| SSE2 PAlign SSE | 4900.96 | 5060.06 | 4441.71 |
| MMX Block 4kb | 2225.76 | 2184.10 | 4063.30 |
| MMX Block 16kb | 3539.86 | 3522.63 | 4479.88 |
| SSE Block 4kb | 2074.97 | 2073.95 | 4074.79 |
| SSE Block 16kb | 3667.31 | 3672.85 | 4485.09 |
CineBench R10 | |||
处理器 | Dawning I840r-H服务器 四路Intel Dunnington Xeon X7460 | Dawning I840r-H服务器 双路Intel Dunnington Xeon X7460 | 双路Intel Harpertown Xeon E5430 |
| 显卡 | - | - | - |
CPU Benchmark | |||
| Rendering (1 CPU) | 3280 CB-CPU | 3287 CB-CPU | 2931 CB-CPU |
| Rendering (x CPU) | 31144 CB-CPU | 26687 CB-CPU | 16806 CB-CPU |
Multiprocessor Speedup | 9.50x | 8.12x | 5.73x |
OpenGL Benchmark | |||
OpenGL Standard | 193 CB-GFX | 193 CB-GFX | 176 CB-GFX |
双路条件下Dunnington多核心渲染能力比同频的双路Harpertown要高58.8%,超出了核心多出的数量,这表明Dunnington对Harpertown架构上的改进。
双路情况下,Dunnington平台的Iometer表现有比较明显的下降。
而在NetBench当中,双路的表现和四路的表现比较接近,下降很小。
可见,除去两个处理器对功耗的影响很小。
【IT168评测中心】虽然六核心至强Dunnington内部仍然是基于Penryn架构,然而,在更高的架构层次上Dunnington借鉴了Nehalem-EX非常多的内容,如Uncore结构,L3 Cache的引入,Long-Le晶体管技术等,让Dunnington具有更多的处理核心、更高性能的同时功耗并没有升高,从而确实提升了能效比。 Dunnington看起来像是Penryn和Nehalem之间的半代处理器产品。
Intel 6-core Dunnington Xeon X7460
我们测试了一台6核心Dunnington平台:来自曙光的I840r-H服务器,采用的处理器型号为Xeon X7460,频率为2.66GHz,集成9MB L2和16MB共享L3,采用了和Penryn、Nehalem一样的45nm CMOS工艺,采用了金属栅极High-K电介质晶体管以及9层铜互联技术,总晶体管数量达到了19亿,使用了Nehalem中才开始使用了的 Static CMOS线路和长沟道晶体管元件,设计功耗仍然维持在4核心的130W的水平,功耗控制做的不错。
在总功率测试当中,搭配了4个Xeon X7460和32条2GB FBD-DDR2 667内存的曙光I840r-H满负荷功耗达到了776W,比两台我们的基准平台(双路Xeon E5430)高120W左右,而性能则是基准平台的2~3倍,从能耗比看,大致相当。
曙光I840r-H四路六核Dunnington服务器
曙光I840r-H据说卖的不错
曙光I840r-H四路六核Dunnington服务器:支持内存阵列功能的热插拔内存模组
曙光I840r-H六核心Dunnington服务器:1570W的高功率冗余电源
曙光Dawning I840r-H四路Dunington服务器:为虚拟化应用而优化的双口网卡

