平滑过渡上海 曙光A650服务器性能评测
【IT168评测中心】坦白而言,AMD的Barcelona在今年的表现不是非常好,特别是在TLB问题之后。不过今次我们仍然收到了数台Barcelona的机器,因为它在功耗表现上具有一些优势。

我们首先收到了曙光(Dawning)送来的两台机器:一台Intel Xeon,一台AMD Opteron。曙光集团在从入门级别的服务器直到数万颗CPU的超级计算机都可以提供。

曙光A650是一台塔式服务器
曙光A650是一台塔式服务器,显得个头很大,内部使用了Opteron 2350处理器(代号Barcelona),频率2.0GHz。曙光A650的特点是可以很轻松地支持AMD在11月份发布的Shanghai处理器,实际上我们的Shanghai处理器评测也是基于曙光A650平台。现在购买AMD服务器,都可以直接让厂商配上Shanghai,从而直接提升性能。

塔式服务器

黝黑的外观,显得稳重,专业


充足的散热孔是必须的


AMD Opteron标志和3C标签

可以锁定前面板,可以避免未任证的更换硬盘、开关机器

完整的型号是Network Server System A650

打开前面板可以看到扩展能力:两个4槽位硬盘槽、3个5.25英寸光驱位,还有一个软驱

4个热插拔3.25英寸硬盘槽


使用的是Fujitsu MBA3147RC硬盘,容量147GB,转速15000RPM,主流规格



深长的服务器机箱才能容纳Extented-ATX架构的主板

使用HuntKey航嘉的服务器电源,虽然和Delta等厂商比起来航嘉还比较年轻,不过已经是可用了

Tyan S2930主板,板载相应开关……这点在DIY主板上倒更为常见一些

CoolerMaster纯铜散热器












基于LSI SAS 1078E RoC芯片的硬件阵列列卡,假如是1068E芯片,那么就是通常的控制卡(当然,可以搭配其它处理器芯片实现阵列功能)



我们测试的平台仍然和《全国首发 AMD Shanghai/上海性能评测》中的一样,基于于一台曙光A650服务器,测试结果并会与我们IT168评测中心的DELL PowerEdge 2900 III服务器进行对比,测试对比平台的详细参数如下:
测试平台、测试环境 | |||||
测试分组 | |||||
类别 | Dawning AS650服务器 双路AMD Barcelona Opteron 2350 | 双路Xeon E5430基准平台 DELL PE2900 III服务器 | |||
处理器子系统 | |||||
处理器 | 双路AMD Barcelona Opteron 2350 | 双路Intel Xeon E5430 | |||
处理器架构 | AMD 65nm Barcelona | Intel 45nm Penryn | |||
处理器代号 | Barcelona | Harpertown | |||
处理器封装 | Socket F 1207 | Socke 771 LGA | |||
处理器规格 | 四核 | 四核 | |||
处理器指令集 | MMX,3DNow!,SSE,SSE2,SSE3,SSE4A,x86-64 | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,EM64T,VT | |||
| 主频 | 2.00GHz | 2.66GHz | |||
| 处理器外部总线 | HTL:1000MHz | FSB:1333MHz | |||
L1 D-Cache | 4x 64KB 2路集合关联 | 4x 32KB 8路集合关联 | |||
L1 I-Cache | 4x 64KB 2路集合关联 | 4x 32KB 8路集合关联 | |||
L2 Cache | 2x 512KB 16路集合关联 | 2x 6144KB 16路集合关联 | |||
L3 Cache | 2MB 32路集合关联 | ||||
主板 | |||||
主板型号 | Tyan S2932-E | DELL PE2900 III | |||
北桥芯片组(MCH) | NVIDIA nForce PRO 3600 | Intel 5000X | |||
| 北桥芯片特性 | - | 12MB Snoop Filter | |||
内存控制器 | 每CPU集成双通道DDR2-667 | 北桥集成四通道FBD DDR2 | |||
内存 | 2GB R-ECC DDR2 667 SDRAM x4 1GB R-ECC DDR2 667 SDRAM x4 | 2GB FBD DDR2 667 SDRAM x8 | |||
系统磁盘子系统 | |||||
磁盘控制器 | LSI MegaRAID SAS 8208ELP Controller | DELL Perc 5/i RAID Controller | |||
磁盘控制器规格 | SAS 3Gbps | SAS 3Gbps | |||
磁盘控制器设置 | RAID 5 | RAID 5 | |||
磁盘控制器驱动 | LSI MegaRAID SAS 3.8.0.32 | LSI SAS 3.8.0.32 | |||
| 磁盘 | Fujitsu MBA3147RC x3 | Seagate Cheetah 15K.5 ST314655SS x3 | |||
磁盘规格 | 15000RPM 147GB SAS 3Gbps 16MB Cache | 15000RPM 146GB SAS 3Gbps 16MB Cache | |||
磁盘设置 | SATA 3Gbps 30GB系统分区 | SAS 3Gbps 20GB系统分区 | |||
网络子系统 | |||||
网卡 | NVIDIA nForce Pro 3600 integrated MAC with Marvell 88E1121 PHY GbE Controller x2 | Broadcom BCM5708C PCI-E千兆网卡 x2 | |||
网卡设置 | ForceWare Teaming Load Balancing | Broadcom NIC Teaming Load Balancing | |||
网卡驱动 | NVIDIA NIC/LAN v67.76.1 | Broadcom NetXtreme 2 11.04.01 | |||
软件环境 | |||||
| 操作系统 | Microsoft Windows Server 2008 Enterprise x64 Edition SP1 | Microsoft Windows Server 2008 Enterprise x64 Edition SP1 | |||
和上一次测试不同的是,64位环境下的SPEC CPU 2006测试要求每一个测试进程都搭配1.5GB以上的内存,每个内核一个测试线程,总共就需要12GB以上的内存,因此在测试SPEC CPU 2006的时候我们将A650平台的内存增加到12GB,将DELL基准平台的内存增加到16GB,并保持双通道的设置不变。测试表明,12GB以上的内存对性能没有影响。在测试所有其他项目的时候,均适用8GB内存。
关于曙光服务器的网络子系统部分还有一个细节可以分享:它采用了NVIDIA nForce Pro 3600芯片组自带的网络控制器(Mac控制器 + Marvell 88E1121 PHY芯片),它的网卡Teaming功能和其他常见的不太一样:
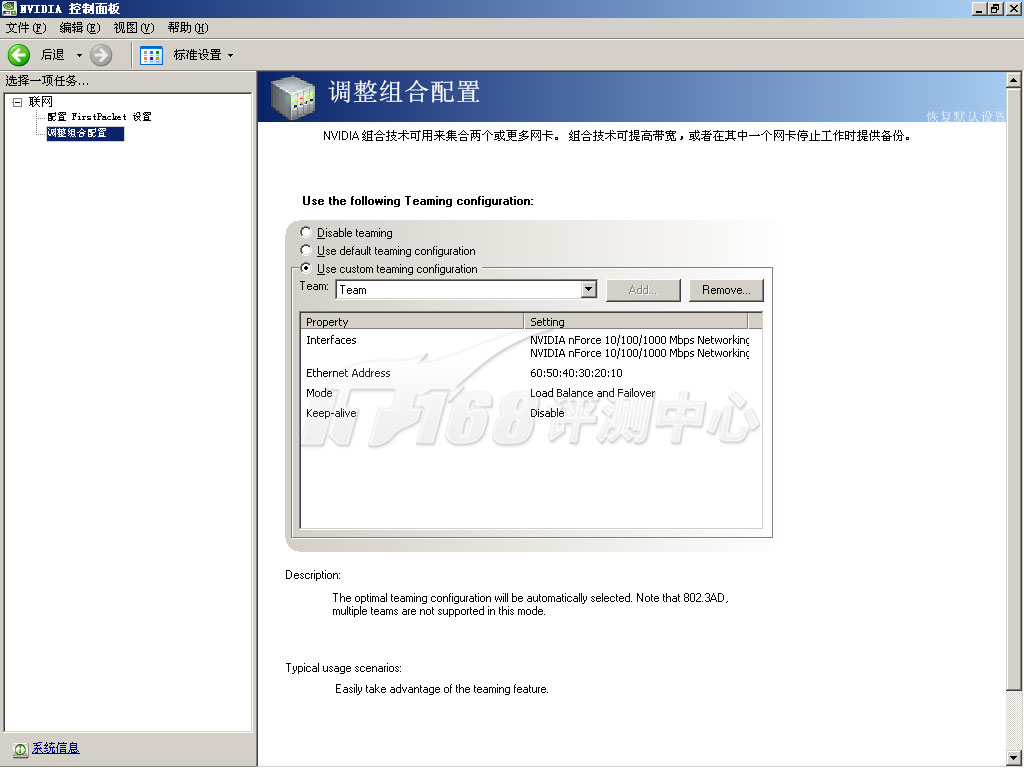
NVIDIA的网卡组合技术——也就是一般所说的网卡Teaming功能
这个功能有时会因为提示网卡使用了VLAN而无法打开(当然这时候VLAN功能是已经关闭了),并且几经周折设置好了之后,它和通常的网卡Teaming表现不同:它居然没有增加新的虚拟聚合网卡!例如Intel、Marvell、Broadcom这样的网卡厂商,在使用端口聚合/Teaming功能之后,都会生成一个新的虚拟网卡,这个网卡就是可以设置IP地址等信息的管理所有流量的网卡。
这两块NVIDIA的网卡不是这样,在设置网卡组合功能之后,系统设备完全没有变化——你需要在一块网卡上设置好IP地址、网关、子网掩码,同时保留另外一块网卡为自动获取IP,这样才能正常使用组合功能。希望用到这个功能的新用户看了之后可以不用再走我们走过的弯路。
测试方法介绍
SPEC CPU2006 v1.01
SPEC是标准性能评估公司(Standard Performance Evaluation Corporation)的简称。SPEC是由计算机厂商、系统集成商、大学、研究机构、咨询等多家公司组成的非营利性组织,这个组织的目标是建立、维护一套用于评估计算机系统的标准。
SPEC CPU 2006是SPEC组织推出的一套CPU子系统评估软件,它包括CINT2006和CFP2006两个子项目,前者用于测量和对比整数性能,而后者则用于测量和对比浮点性能。计算系统中的处理器、内存和编译器都会影响最终的测试性能,而I/O(磁盘)、网络、操作系统和图形子系统对于SPEC CPU2006的影响比较小。
SPECfp测试过程中同时执行多个实例(instance),测量系统执行计算密集型浮点操作的能力,比如CAD/CAM、DCC以及科学计算等方面应用可以参考这个结果。SPECint测试过程中同时执行多个实例(instances),然后测试系统同时执行多个计算密集型整数操作的能力,可以很好的反映诸如数据库服务器、电子邮件服务器和Web服务器等基于整数应用的多处理器系统的性能。
SPEC CPU 2006的运行有着比较特别的要求,我们将会在后面详细解释。
ScienceMark v2.0 Membench
ScienceMark v2.0是一款用于测试系统特别是处理器在科学计算应用中的性能的软件,MemBenchmark是其中针对处理器缓存、系统内存而设计的功能模块,它可以测试系统内存带宽、L1 Cache延迟、L2 Cache延迟和系统内存延迟,另外还可以测试不同指令集的性能差异。
CineBench R10
CineBench是基于Cinem3D物理建模软件的一个测试程序,主要针对处理器子系统、内存子系统和显示子系统,可以完善地支持多核/多线程。对于服务器来说显示子系统并不重要,因此主要用它来测试处理器子系统和内存子系统。
SiSoftware Sandra 2009
SiSoftware Sandra是一款可运行在32bit和64bit Windows操作系统上的分析软件,这款软件可以对于系统进行方便、快捷的基准测试,还可以用于查看系统的软件、硬件等信息。我们使用了SiSoftware Sandra的2009版,它可以支持各种最新的CPU指令集,并能良好地支持多核、多线程,我们主要用其来评估平台的理论计算性能。
IOMeter 2006.07.27
IOMeter是一款功能非常强大的IO测试软件,它除了可以在本机运行测试本机的IO(磁盘)性能之外,还提供了模拟网络应用的能力。在这次的测试中,我们仅仅让它在本机运行测试服务器的磁盘性能。为了全面测试被测服务器的IO性能,我们分别选择了不同的测试脚本。
Max_throughput(read):文件尺寸为64KB,100%读取操作,随机率为0%,用于检测磁盘系统的最大读取吞吐量
Max_IO(read):文件尺寸为512B,100%读取操作,随机率为0%,用于检测磁盘系统的最大读取操作IO处理能力
Max_throughput(write):文件尺寸为64KB,0%读取操作,随机率为0%,用于检测磁盘系统的最大写入吞吐量
Max_IO(write):文件尺寸为512B,0%读取操作,随机率为0%,用于检测磁盘系统的最大写入操作IO处理能力
NetBench v7.03
NetBench是针对文件服务器的性能测试软件,影响NetBench性能的主要是服务器的磁盘子系统,服务器磁盘控制器、条带大小、读写缓存、硬盘类型、组建磁盘阵列模式、内存容量、网络拓朴结构等都会对测试结果有明显的影响。我们在被测服务器上设立了文件服务器,NetBench通过网络实验室中60个客户端来模拟网络中的PC向文件服务器所发出的文件传输请求,文件服务器则将存储在磁盘上的文件数据发送给相应的客户端。在测试过程中,客户端会以每四台一组的步进依次增加并且向服务器发送文件传输请求,测试结束后控制台收集数据并绘制出服务器的数据传输变化曲线。
Benchmark Factory 4.6
大部分的服务器应用都同数据库有着密切的联系,因此在服务器测试当中这是一个很重要的测试。我们选择了Benchmark Factory 4.6软件和Microsoft SQL Server 2005来测试不同的硬件平台在数据库应用中的表现。
我们选择了BF内置的标准测试脚本AS3AP,这项测试可用于对于ANSI结构化查询语言(SQL)关系型数据库进行测试,它可用于测试DBMS(单用户微机数据库管理系统),也可用于测试高性能并行或者分布式数据库。
AMD 65nm Barcelona Opteron 2350处理器,2.0GHz,频率不高,功耗也低
AMD Opteron 2350并没有Intel那样的EIST技术,闲置时会自动降低到频率
AMD Barcelona/巴塞罗那架构图
缓存架构
Tyan泰安的S2932-M主板
测试SPEC时使用的12GB RAM
8GB R-ECC DDR2 667 SDRAM
SiSoftware Sandra Pro Business 2009
SiSoftware Sandra是一款可运行在32bit和64bit Windows操作系统上的分析软件,这款软件可以对于系统进行方便、快捷的基准测试,还可以用于查看系统的软件、硬件等信息。从Sandra 2007开始支持SSE4指令集。SiSoftware Sandra所有的基准测试都针对SMP和SMT进行了优化,最高可支持32/64路平台,这也是我们选择这款软件的原因之一。
SiSoftware Sandra Pro Business 2009 | |||
测试对象 | Dawning A650 双路AMD Barcelona Opteron 2350 2.0GHz | DELL PE2900 III 双路Intel Harptown Xeon E5430 2.66GHz | |
Processor Arithmetic Benchmark 处理器架构测试 | |||
| Dhrystone ALU | 51480MIPS | 91006MIPS | |
| Dhrystone ALU vs SPEED | 25.74MIPS/MHz | 34.21MIPS/MHz | |
Whetstone iSSE3 | 51400MFLOPS | 78385MFLOPS | |
| Dhrystone iSSE3 vs SPEED | 25.70MFLOPS/MHz | 29.47MFLOPS/MHz | |
Processor Multi-Media Benchmark 处理器多媒体测试 | |||
Multi-Media Int x8 aSSE2 | 155.64MPixel/s | ||
| Multi-Media Int x8 iSSE4.1 | 199.33MPixel/s | ||
Multi-Media Int x8 aSSE2 vs SPEED | 77.82kPixels/s/MHz | ||
| Multi-Media Int x8 iSSE4.1 vs SPEED | 74.94kPixels/s/MHz | ||
Multi-Media Float x4 iSSE2 | 67.86MPixel/s | 108.69MPixel/s | |
Multi-Media Float x4 iSSE2 vs SPEED | 33.93kPixels/s/MHz | 40.86kPixels/s/MHz | |
Multi-Media Double x2 iSSE2 | 37.15MPixel/s | 55.75MPixel/s | |
Multi-Media Double x2 iSSE2 vs SPEED | 18.58kPixels/s/MHz | 20.96kPixels/s/MHz | |
Multi-Core Efficiency Benchmark | |||
Inter-Core Bandwidth | 2.91GB/s | 20.54GB/s | |
Inter-Core Bandwidth vs SPEED | 1.49MB/s/MHz | 7.91MB/s/MHz | |
Inter-Core Latency (越小越好) | 185ns | 90ns | |
Inter-Core Latency? vs SPEED (越小越好) | 0.09ns/MHz | 0.03ns/MHz | |
Memory Bandwidth Benchmark 内存带宽测试 | |||
Int Buff'd iSSE2 Memory Bandwidth | 7.12GB/s | 6.13GB/s | |
Int Buff'd iSSE2 Memory Bandwidth vs SPEED | 10.94MB/s/MHz | 9.43MB/s/MHz | |
Float Buff'd iSSE2 Memory Bandwidth | 7.13GB/s | 6.13GB/s | |
Float Buff'd iSSE2 Memory Bandwidth vs SPEED | 10.96MB/s/MHz | 9.43MB/s/MHz | |
Memory Latency Benchmark 内存延迟测试 | |||
Memory(Random Access) Latency (越小越好) | 157ns | 108ns | |
Memory(Random Access) Latency vs SPEED (越小越好) | 0.24ns/MHz | 0.16ns/MHz | |
Speed Factor (越小越好) | 103.40 | 95.20 | |
Internal Data Cache | 3clocks | 3clocks | |
L2 On-board Cache | 16clocks | 18clocks | |
L3 On-board Cache | 47clocks | ||
Cache and Memory Benchmark 缓存及内存测试 | |||
Cache/Memory Bandwidth | 51.17GB/s | 68.88GB/s | |
Cache/Memory Bandwidth vs SPEED | 26.20MB/s/MHz | 26.52MB/s/MHz | |
Speed Factor | 45.50 | 111.90 | |
| Internal Data Cache | 244.31GB/s | 421.23GB/s | |
| L2 On-board Cache | 135.04GB/s | 122.68GB/s | |
.NET Arithmetic Benchmark .NET架构测试 | |||
Dhrystone .NET | 9551MIPS | 10562MIPS | |
Dhrystone .NET vs SPEED | 4.78MIPS/MHz | 3.97MIPS/MHz | |
Whetstone .NET | 31231MFLOPS | 45399MFLOPS | |
Whetstone .NET vs SPEED | 15.62MFLOPS/MHz | 17.07MFLOPS/MHz | |
.NET Multi-Media Benchmark .NET多媒体测试 | |||
Multi-Media Int x1 .NET | 20.11MPixel/s | 31.28MPixel/s | |
Multi-Media Int x1 .NET vs SPEED | 10.06kPixels/s/MHz | 11.76kPixels/s/MHz | |
Multi-Media Float x1 .NET | 4.34MPixel/s | 8.68MPixel/s | |
Multi-Media Float x1 .NET vs SPEED | 2.17kPixels/s/MHz | 3.26kPixels/s/MHz | |
Multi-Media Double x1 .NET | 17.49MPixel/s | 24.75MPixel/s | |
Multi-Media Double x1 .NET vs SPEED | 8.74kPixels/s/MHz | 9.30kPixels/s/MHz | |
SiSoftware Sandra对比,用蓝色标出了性能特出的项目
和频率较高的Intel Xeon 2.66GHz平台相比,2.0GHz的Barcelona的确不占据优势。在整数运算和浮点运算方面Xeon平台均大为胜出。
ScienceMark v2.0 Membench
ScienceMark v2.0是一款用于测试系统特别是处理器在科学计算应用中的性能的软件,MemBenchmark是其中针对处理器缓存、系统内存而设计的功能模块,它可以测试系统内存带宽、L1 Cache延迟、L2 Cache延迟和系统内存延迟,另外还可以测试不同指令集的性能差异。
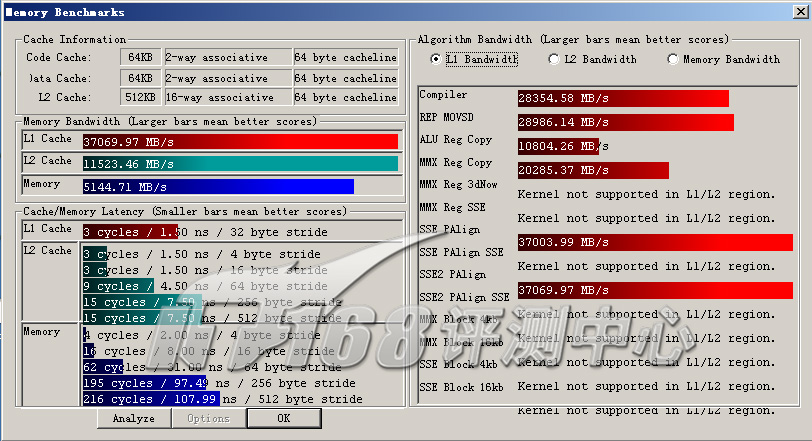
ScienceMark v2.0 Membench L1测试成绩
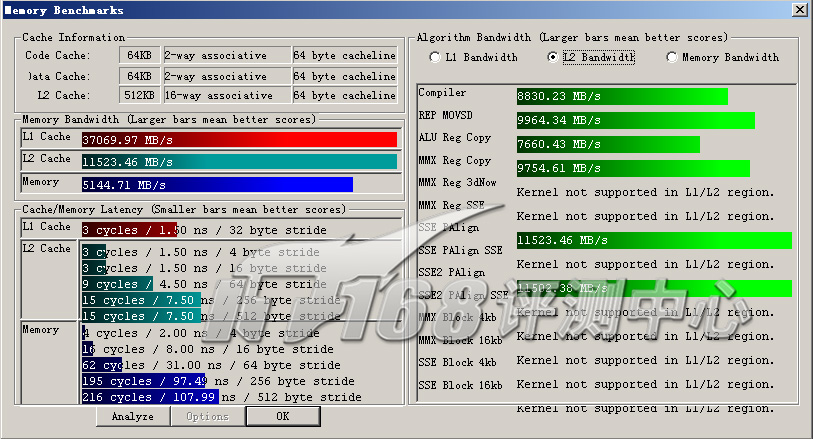
ScienceMark v2.0 Membench L2测试成绩
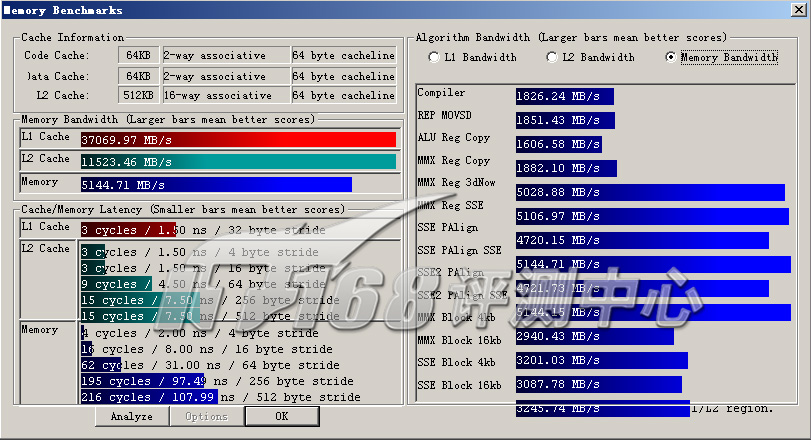
ScienceMark v2.0 Membench 内存测试成绩
首先我们进行的是ScienceMark的测试,主要考察系统的缓存和内存子系统情况。L1/L2 Cache的成绩主要是跟处理器频率相关,因为目前的处理器当中L1 Cache都是和处理器核心同频率的,而L2 Cache基本上也是——当前的处理器L2都是全速的(放置在处理器内但不在同一个芯片上的Pentium II为半速L2,而Pentium之前的处理器L2则和处理器分离,速度更低)。越快的频率,L1/L2性能就越好。而内存带宽主要由两部分相关:比较大的部分是内存架构,小部分是内存操作指令(集),例如使用最新的SSE指令集比通常的ALU指令集会得到更大的吞吐量,而不同的SSE版本性能也有不同。
ScienceMark Membench | |||
| 厂商 | Dawning | DELL | |
| 产品型号 | AS650 AMD Barcelona Opteron 2350 2.0GHz | PowerEdge 2900 III Intel Harptown Xeon E5430 2.66GHz | |
| 内存技术参数 | 2GB R-ECC DDR2-667 SDRAM x4 | 2GB FBD-ECC DDR2-667 SDRAM x4 | |
| L1带宽(MB/s) | 37069.97 | 55376.16 | |
| L2带宽(MB/s) | 11523.46 | 16757.55 | |
| 内存带宽(MB/s) | 5144.71 | 4485.09 | |
| L1 Cache Latency(ns) | |||
| 32 Bytes Stride | 1.50 | 1.13 | |
| L1 Algorithm Bandwidth(MB/s) | |||
| Compiler | 28354.58 | 25201.968 | |
| REP MOVSD | 28986.14 | 25467.15 | |
| ALU Reg Copy | 10804.26 | 13093.65 | |
| MMX Reg Copy | 20285.37 | 25242.19 | |
| SSE PAlign | 37003.99 | 52826.21 | |
| SSE2 PAlign | 37069.97 | 55376.16 | |
| L2 Cache Latency(ns) | |||
| 4 Bytes Stride | 1.13 | 1.13 | |
| 16 Bytes Stride | 1.50 | 1.50 | |
| 64 Bytes Stride | 4.51 | 4.51 | |
| 256 Bytes Stride | 4.51 | 4.51 | |
| 512 Bytes Stride | 4.89 | 4.89 | |
| L2 Algorithm Bandwidth(MB/s) | |||
| Compiler | 8830.23 | 118800.48 | |
| REP MOVSD | 9964.34 | 12536.88 | |
| ALU Reg Copy | 7660.43 | 8577.86 | |
| MMX Reg Copy | 9754.61 | 13408.31 | |
| SSE PAlign | 11523.46 | 16719.97 | |
| SSE2 PAlign | 11502.38 | 16757.55 | |
| Memory Latency(ns) | |||
| 4 Bytes Stride | 2.00 | 1.13 | |
| 16 Bytes Stride | 8.00 | 4.89 | |
| 64 Bytes Stride | 31.00 | 19.17 | |
| 256 Bytes Stride | 97.49 | 59.77 | |
| 512 Bytes Stride | 107.99 | 68.04 | |
| Memory Algorithm Bandwidth(MB/s) | |||
| Compiler | 1826.24 | 3178.45 | |
| REP MOVSD | 1851.43 | 3220.23 | |
| ALU Reg Copy | 1606.58 | 2789.34 | |
| MMX Reg Copy | 1882.10 | 2972.91 | |
| MMX Reg 3dNow | 5028.88 | - | |
| MMX Reg SSE | 5106.97 | 3978.53 | |
| SSE PAlign | 4720.15 | 4128.59 | |
| SSE PAlign SSE | 5144.71 | 4390.48 | |
| SSE2 PAlign | 4721.73 | 4326.42 | |
| SSE2 PAlign SSE | 5144.15 | 4441.71 | |
| MMX Block 4kb | 2940.43 | 4063.30 | |
| MMX Block 16kb | 3201.03 | 4479.88 | |
| SSE Block 4kb | 3087.78 | 4074.79 | |
| SSE Block 16kb | 3245.74 | 4485.09 | |
AMD 45nm Shanghai Opteron 2350的缓存架构,L3基于32路集合关联,并且容量只有2MB
Intel 45nm Harptertown Xeon E5430的缓存架构,L3基于24路集合关联
不得不说,直联架构的内存带宽是要高一些,而基本上,与处理器结合最紧密的L1,或L2(在有L3的情况下)的延迟总是跟处理器频率密集相关的,因此频率较高的Xeon平台在缓存方面就强一些。大容量的缓存在进行多任务处理器的时候会具有更高的效率。
CineBench R10
CineBench是基于Cinem4D工业三维设计软件引擎的测试软件,用来测试对象在进行三维设计时的性能,它可以同时测试处理器子系统、内存子系统以及显示子系统,我们的平台偏向于服务器多一些,因此就只有前两个的成绩具有意义。和大多数工业设计软件一样,CineBench可以完善地支持多核/多处理器,它的显示子系统测试基于OpenGL。
曙光A650服务器测试成绩
CineBench R10 | |||
处理器 | 双路AMD Barcelona Opteron 2350 | 双路Intel Harpertown Xeon E5430 | |
| 显卡 | - | - | |
CPU Benchmark | |||
| Rendering (1 CPU) | 1797 CB-CPU | 2931 CB-CPU | |
| Rendering (x CPU) | 10734 CB-CPU | 16806 CB-CPU | |
Multiprocessor Speedup | 5.97x | 5.73x | |
OpenGL Benchmark | |||
OpenGL Standard | 98 CB-GFX | 176 CB-GFX | |
曙光A650服务器测试成绩对比
从渲染性能,Barcelona Opteron不及Intel Xeon,因此当前工作站市场主要被Intel占据了。上海处理器的表现则会好上许多。
SPEC是标准性能评估公司(Standard Performance Evaluation Corporation)的简称。SPEC是由计算机厂商、系统集成商、大学、研究机构、咨询等多家公司组成的非营利性组织,这个组织的目标是建立、维护一套用于评估计算机系统的标准。
SPEC CPU 2006是SPEC组织推出的一套CPU子系统评估软件,它包括CINT2006和CFP2006两个子项目,前者用于测量和对比整数性能,而后者则用于测量和对比浮点性能。计算系统中的处理器、内存和编译器都会影响最终的测试性能,而I/O(磁盘)、网络、操作系统和图形子系统对于SPEC CPU2006的影响比较小。
SPECfp测试过程中同时执行多个实例(instance),测量系统执行计算密集型浮点操作的能力,比如CAD/CAM、DCC以及科学计算等方面应用可以参考这个结果。SPECint测试过程中同时执行多个实例(instances),然后测试系统同时执行多个计算密集型整数操作的能力,可以很好的反映诸如数据库服务器、电子邮件服务器和Web服务器等基于整数应用的多处理器系统的性能。
为了运行SPEC CPU 2006测试,我们统一安装了Windows Server 2008 Enterprise x64 Edition SP1操作系统,在主流的x64处理器下,原生64应用要比32位下快。我们还安装了Visual Studio 2005 SP1、Intel C++/Fortran Compiler 10.0.025编译器,对于支持SSE3指令集的处理器,我们使用了QxO编译指令进行了优化。编译时未使用SmartHeap商业优化库。
SPEC测试代表了绝大多CPU密集型的运算,包括编程语言、压缩、人工智能、基因序列搜索、视频压缩及各种力学的计算等,包含了多种科学计算,可以用来衡量系统执行这些任务的快慢。SPEC base测试包括浮点(fp)与整数运算(int)两部分。
整数运算主要包含编译、压缩、人工智能、视频压缩转换、XML处理等,此外,各种日常操作也主要是基于整数操作。SPEC CPU 2006的整数运算包含了400.perlbench PERL编程语言、401.bzip2 压缩、403.gcc C编译器、429.mcf 组合优化、445.gobmk 人工智能:围棋、456.hmmer 基因序列搜索、458.sjeng 人工智能:国际象棋、462.libquantum 物理:量子计算、464.h264ref 视频压缩、471.omnetpp 离散事件仿真、473.astar 寻路算法、483.xalancbmk XML处理共12项。
曙光A650服务器SPEC CPU 2006整数测试成绩
浮点运算包括的全部都是科学运算,科学运算需要用到大量的高精度浮点数据,如410.bwaves 流体力学、416.gamess 量子化学、433.milc 量子力学、434.zeusmp 物理:计算流体力学、435.gromacs 生物化学/分子力学、436.cactusADM 物理:广义相对论、437.leslie3d 流体力学、444.namd 生物/分子、447.dealII 有限元分析、450.soplex 线形编程、优化、453.povray 影像光线追踪、454.calculix 结构力学、459.GemsFDTD 计算电磁学、465.tonto 量子化学、470.lbm 流体力学、481.wrf 天气预报、482.sphinx3 语音识别共17项测试。
曙光A650SPEC CPU 2006浮点运算测试成绩
从实际应用来看,大部分的服务器应用都是基于整数运算,如通常的Web服务器、NetBench服务器和数据库、在线交易等,在这方面Intel Xeon平台表现就稍好一些,这些应用也通常能从大的缓存中获利。而通常的科学计算、工作站应用多是基于浮点运算,这方面AMD Opteron表现会更好,不过目前3D工作站市场被Intel占据了大部分的市场份额,AMD只有在高性能计算方面具有市场。
我们的基准服务器采用了15000RPM的Seagate Cheetah 15K.5硬盘,曙光A650则是4块Fujitsu MBA3147硬盘,他们都使用硬件阵列卡组建了RAID 5阵列。
IO读
IO写
读吞吐量
写吞吐量
硬盘多上一个,因此性能也就更强,只有在较低队列深度下曙光A650的磁盘性能不及基准平台,这个现象跟阵列卡有关。
NetBench v7.03
NetBench 7.03 Ent_dm.tst测试脚本模拟的是企业级文件服务器应用,它不但要求被测服务器的磁盘子系统可以提供足够的吞吐量,还需要其具有较高的IO处理能力,并且需要较为平衡的读取能力和写入能力。基准平台基于LSI MegaRAID SAS 8408E RAID 5阵列,曙光A650则基于LSI SAS 1078芯片的OEM RAID卡,也是RAID 5阵列,搭配的硬盘方面,我们的基准平台基于3块Seagate 15K.5 146GB,曙光A650的则是Fujitsu的MBA3147RC,147GB容量,它们都是15000RPM的SAS硬盘。目前企业级硬盘方面被Seagate占据了大部分的市场。
NetBench测试主要考察缓存、内存、磁盘子系统,这三个方面只有内存带宽是AMD平台占优的,缓存子系统和磁盘子系统都是我们的基准平台更强劲,吞吐量高56%左右。关于NetBench测试可以看这里《评测机密:文件服务器性能提升N大要义》。
Benchmark Factory 4.6
我们在被测服务器上安装了Microsoft SQL 2005 SP1,按照测试要求建立了数据库。BF在测试之前会在数据库中生成9个表,其中包括4个500万行的表格,每行包括100字节的数据,因此每个表格容量大约是476MB,整个数据库容量为1.86GB。我们用60个客户端模拟1000个用户,在这个数据库中进行查询、添加、删除、修改等操作。
曙光A650 SQL2005数据库性能测试
数据库测试是一个综合性的测试……除了对网络带宽的压力不大之外。从测试数据来看,曙光A650数据库的性能总体和我们的基准平台差不多,较低用户数量的时候AMD平台略为高一些,这些地方是内存子系统方面导致的一些优势,较高用户数量下基准平台略微好一点。部分是由于Intel平台整数运算性能比较高(参照前面的SPEC CPU测试)。
曙光A650服务器整体功耗
我们利用UNI-T UT71E智能数字万用表和相配套的软件对于对于被测服务器在几种不同的状态下的功耗进行了监测,主要包括如下项目:
P1:连接电源但不开机状态
P2:系统启动完毕,5分钟内无动作,但不休眠
P3:系统启动完毕,处理器满载、磁盘以最大吞吐量工作
曙光A650服务器功耗测试
尽管AMD处理器没有类似EIST的功能,不过塔式机箱的空间比较大,因此散热方面比较从容,使用的风扇也就不必很夸张。整体来看空载的时候功耗比我们的基准平台低不少,不过满载的时候反而要超出。
【IT168评测中心】从曙光的一贯型号就可以看出来:曙光A650使用的AMD平台(例如,I650就会是Intel平台)。它配置了较低频率的AMD Opteron 2350 2.0GHz处理器,采用了NUMA架构,总共支持64GB R-ECC DDR2 667内存,可以提供两个硬盘热插拔槽的位置,每个位置支持4个3.25英寸热插拔硬盘。曙光A650使用的是NVIDIA nForce Pro 3600芯片组,NV的网卡在使用上和其他老厂商网卡不太一样。
曙光A650是一台塔式服务器
曙光A650主板本身提供了充足的SAS/SATA连接能力,不过它仍然使用了一块基于LSI SAS 1078芯片的硬阵列卡,可以支持RAID 0、1、0+1、5、6阵列。它配了四块Fujitsu的MBA3147RC 15000RPM硬盘,磁盘性能很出色。
曙光A650内置两个2.0GHz Opteron 2350处理器,可以平滑地过渡到Shanghai处理器
从测试来看,基于AMD Opteron 2350 2.0GHz处理器的曙光A650的整数运算性能比我们的基准平台略低——而浮点性能则略高,这会导致曙光A650的服务器应用性能比我们的基准平台(Intel Xeon 2.66GHz)略低一些,不过在科学运算方面会有一些优势。从功耗上看,曙光A650在空载或者低负载的时候表现更好。曙光A650还可以平滑地过渡到上海处理器,实际上我们的上海处理器测试也是基于曙光平台。现在在购买服务器的时候,可以适当考虑一下直接上上海平台。

