性能大幅提升 Core i7 服务器应用测试
【IT168评测中心】从上一年中开始,Intel就陆续放出酷睿处理器的下一代架构Nehalem的相关消息,45nm Penryn处理器的功耗以及性能已经让我们非常满意了,作为Penryn的下一代,Nehalem让人期待不已。现在到了2008年十月,新架构Nehalem的处理器事物终于来到了我们的面前,同期到来的还有搭配的桌面级别主板两块(一块Intel X58SO,一块ASUS P6T Deluxe)。和以往Intel处理器架构总是先亮相于服务器或是移动平台不同,今次Nehalem架构的全新产品首先出现在了桌面平台上,对应于Core 2 Duo或是Core 2 Quad,Intel将这个全新的产品系列命名为Core i7。

Nehalem - Core i7 Extreme的黑色LOGO
 |
| 采用LGA1366封装的Core i7(左)与LGA775封装的Core 2(右)相比大上了不少 |
 |
| Nehalem桌面测试平台 |
预计Nehalem——Core i7将于11月正式发布,而服务器版本仍然还有一段时日,Nehalem作为桌面级别产品的性能我们已经可以从这篇《再攀性能之巅 Intel全新酷睿i7深度评测》看到了,然而服务器方面的性能呢?我们IT168评测中心已经等不及了。
点击查看相关文章:
|
| 我们自行购买的Nehalem也是一个工程样板 |
|
| CPU-Z 1.48可以正常识别出关于CPU的详细信息 |
全球首批三款Nehalem架构处理器型号分别为Core i7 965 Extreme、Core i7 940及Core i7 920,我们拿到的这颗Core i7处理器型号为Core i7 940,是目前发布的三款Core i7产品中定位居中的一款,和优异的Core i7 965 Extreme相比,它只是QPI规格稍低、倍频向上锁定以及缺少Turbo Mode功能。
 |
| 由于加入了更多核心外的复杂设计,因此Core i7的背面也更加复杂 |
|
| Core i7 940的缓存信息 |
Core i7 965 Extreme、940及920处理器,核心代号Bloomfield,均采用原生四核心设计,基于45nm工艺生产,拥有7.31亿个晶体管,每个核心拥有256KB的独立二级缓存,四个核心共享8M容量的三级缓存,TDP为130W。由于缓存总容量较之Penryn四核还有所下降,所以其晶体管数量实际上还略低于Penryn四核心。但由于三级缓存及内存控制器等复杂设计的加入,Intel为Bloomfield设计了一个LGA 1366接口,这也直接使得最终产品看上去比起LGA 775接口的产品大了不少,处理器基板上的金属触点是为了Debug而设计。
测试平台、测试环境 | ||||
测试分组 | ||||
类别 | Core i7 Extreme 940平台 | 双路Xeon E5450平台 DELL PE2900 III服务器 | ||
处理器子系统 | ||||
处理器 | Intel Core i7 Extreme 940 | 双路Intel Xeon E5450 | ||
处理器代号 | Bloomfield | Harpertown | ||
处理器封装 | Socket 1366 LGA | Socke 771 LGA | ||
处理器规格 | 四核超线程 内置内存控制器 | 四核 | ||
处理器指令集 | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,SSE4.2,EM64T,VT | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,EM64T,VT | ||
| 主频 | 2.93GHz | 3.00GHz | ||
| 处理器外部总线 | QPI Link:3200MHz | FSB:1333MHz | ||
L1 D-Cache | 4x 32KB 8路集合关联 | 4x 32KB 8路集合关联 | ||
L1 I-Cache | 4x 32KB 4路集合关联 | 4x 32KB 8路集合关联 | ||
L2 Cache | 4x 256KB 8路集合关联 | 12MB 16路集合关联 | ||
L3 Cache | 8MB 16路集合关联 | |||
主板 | ||||
主板型号 | ASUS P6T Deluxe | DELL PE2900 III | ||
北桥芯片组(MCH) | Intel X58 | Intel 5000X | ||
| 北桥芯片特性 | Intel VT-d技术 | 12MB Snoop Filter | ||
内存控制器 | 处理器内置三通道DDR3 | 北桥集成四通道FBD DDR2 | ||
内存 | 1GB DDR3 1066 SDRAM x6 | 2GB FBD DDR2 667 SDRAM x4 | ||
系统磁盘子系统 | ||||
磁盘控制器 | Intel ICH10R RAID Controller | DELL Perc 5/i RAID Controller | ||
磁盘控制器规格 | SATA 3Gbps | SAS 3Gbps | ||
磁盘控制器设置 | RAID 0 | RAID 5 | ||
磁盘控制器驱动 | Intel Matrix Storage Manager 8.5.0.10032 | LSI SAS 2.20.0.64 | ||
| 磁盘 | Seagate SV35.3 ST31000340SV x2 | Seagate Cheetah 15K.5 ST314655SS x3 | ||
磁盘规格 | 7200RPM 1TB SATA 3Gbps 32MB Cache | 15000RPM 146GB SAS 3Gbps 16MB Cache | ||
磁盘设置 | SATA 3Gbps 50GB系统分区 | SAS 3Gbps 20GB系统分区 | ||
网络子系统 | ||||
网卡 | Marvell Yukon 88E8056 PCI-E千兆网卡 x2 | Broadcom BCM5708C PCI-E千兆网卡 x2 | ||
网卡设置 | Marvell NIC Teaming Load Balancing | Broadcom NIC Teaming Load Balancing | ||
网卡驱动 | Marvell Yukon for Win64 10.55.3.3 | Broadcom NetXtreme 2 for Win64 11.04.01 | ||
软件环境 | ||||
操作系统 | Microsoft Windows Server 2008 Enterprise x64 Edition SP1 | Microsoft Windows Server 2003 R2 Enterprise x64 Edition SP2 | ||
我们使用了一套基于X58芯片组的主板搭配了测试平台,这块主板是ASUS P6T Deluxe,关于它的解析将会稍后推出。主要对比平台是一台安装了Windows Server 2003 R2 x64操作系统的DELL PowerEdge 2900 III服务器,包含了多款Xeon处理器的对比测试。DELL PowerEdge 2900 III服务器采用的主板基于Intel 5000X芯片组,带有12MB Snoop Filter缓存,它可以提升重负荷下缓存同步、进程调度方面的性能。5000X芯片组比较少见。前段时间推出的5400 Seburg芯片组带有24MB的Snoop Filter缓存。
我们使用的主板:ASUS P6T Deluxe
使用了6条DDR3-1066内存
Intel Xeon E54xx Harpertown处理器:
45nm Harpertown处理器
45nm Xeon E5450的频率为3.00GHz,和我们的Core i7 Extreme 940的频率很接近。Core i7 Extreme 940的频率是2.93GHz。
ScienceMark v2.0 Membench
ScienceMark v2.0是一款用于测试系统特别是处理器在科学计算应用中的性能的软件,MemBenchmark是其中针对处理器缓存、系统内存而设计的功能模块,它可以测试系统内存带宽、L1 Cache延迟、L2 Cache延迟和系统内存延迟,另外还可以测试不同指令集的性能差异。
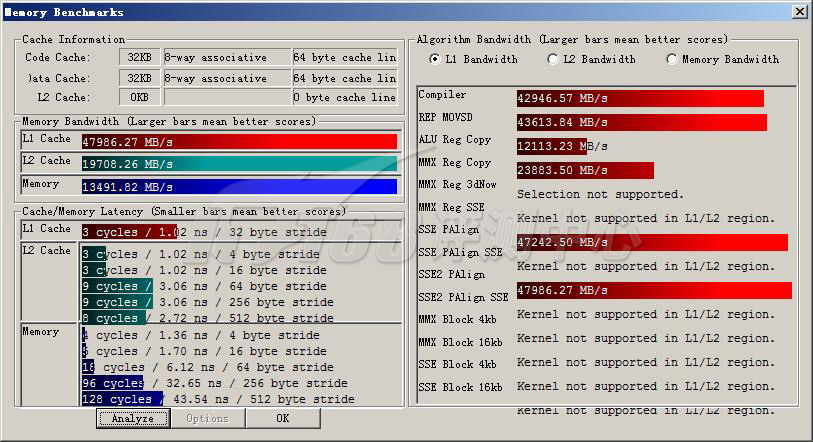
ScienceMark v2.0 Membench L1测试成绩

ScienceMark v2.0 Membench L2测试成绩
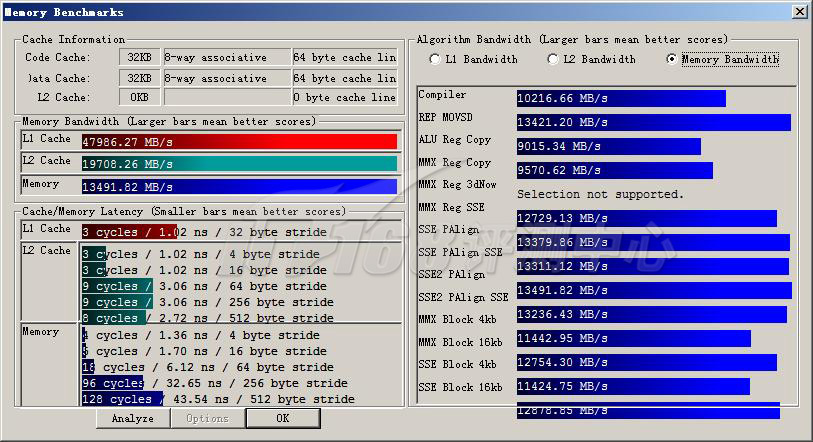
ScienceMark v2.0 Membench 内存测试成绩
首先我们进行的是ScienceMark的测试,主要考察系统的缓存和内存子系统情况。L1/L2 Cache的成绩主要是跟处理器频率相关,因为目前的处理器当中L1 Cache都是和处理器核心同频率的,而L2 Cache基本上也是——当前的处理器L2都是全速的(放置在处理器内但不在同一个芯片上的Pentium II为半速L2,而Pentium之前的处理器L2则和处理器分离,速度更低)。越快的频率,L1/L2性能就越好。而内存带宽主要由两部分相关:比较大的部分是内存架构,小部分是内存操作指令(集),例如使用最新的SSE指令集比通常的ALU指令集会得到更大的吞吐量,而不同的SSE版本性能也有不同。
ScienceMark Membench | ||
| 厂商 | Nehalem | DELL PE2900 III |
| 产品型号 | 单路Core i7 Extreme 940 | 双路E5450 |
| 内存技术参数 | 1GB DDR3-1066 SDRAM x6 | 2GB FBD ECC DDR2-667 SDRAM x4 |
| L1带宽(MB/s) | 47986.27 | 55707.30 |
| L2带宽(MB/s) | 19708.26 | 16740.23 |
| 内存带宽(MB/s) | 13491.82 | 4505.59 |
| L1 Cache Latency(ns) | ||
| 32 Bytes Stride | 1.02 | 1.00 |
| L1 Algorithm Bandwidth(MB/s) | ||
| Compiler | 42946.57 | |
| REP MOVSD | 43613.84 | |
| ALU Reg Copy | 12113.23 | |
| MMX Reg Copy | 23883.50 | |
| SSE PAlign | 47242.50 | |
| SSE2 PAlign | 47986.27 | |
| L2 Cache Latency(ns) | ||
| 4 Bytes Stride | 1.02 | 1.00 |
| 16 Bytes Stride | 1.02 | 1.34 |
| 64 Bytes Stride | 3.06 | 4.01 |
| 256 Bytes Stride | 3.06 | 4.01 |
| 512 Bytes Stride | 2.72 | 4.34 |
| L2 Algorithm Bandwidth(MB/s) | ||
| Compiler | 18218.37 | |
| REP MOVSD | 19708.26 | |
| ALU Reg Copy | 8797.54 | |
| MMX Reg Copy | 14108.99 | |
| SSE PAlign | 18752.85 | |
| SSE2 PAlign | 18763.34 | |
| Memory Latency(ns) | ||
| 4 Bytes Stride | 1.36 | 1.00 |
| 16 Bytes Stride | 1.70 | 4.68 |
| 64 Bytes Stride | 6.12 | 19.38 |
| 256 Bytes Stride | 36.65 | 59.48 |
| 512 Bytes Stride | 43.54 | 66.16 |
| Memory Algorithm Bandwidth(MB/s) | ||
| Compiler | 10216.66 | 3177.97 |
| REP MOVSD | 13421.20 | 3223.82 |
| ALU Reg Copy | 9015.34 | 2818.10 |
| MMX Reg Copy | 9570.62 | 2992.21 |
| MMX Reg 3dNow | --- | --- |
| MMX Reg SSE | 12729.13 | 3962.02 |
| SSE PAlign | 13379.86 | 4297.17 |
| SSE PAlign SSE | 13311.12 | 4124.61 |
| SSE2 PAlign | 13491.82 | 4293.79 |
| SSE2 PAlign SSE | 13236.43 | 4126.98 |
| MMX Block 4kb | 11442.95 | 4167.14 |
| MMX Block 16kb | 12754.30 | 4480.38 |
| SSE Block 4kb | 11424.75 | 4172.21 |
| SSE Block 16kb | 12878.85 | 4505.59 |
从测试结果来看,45nm Nehalem Core i7平台与45nm Penryn Xeon总体超出实在太多了。L1缓存因为与频率密切相关,而且从上一页的表格来看,Core i7 Extreme 940的L1 I-Cache(指令缓存)为4路集合关联,要弱于Xeon E5450的8路集合关联,因此L1延迟要高上一些,L1带宽则要低上不少。
Nehalem的三级缓存架构
|
| Core i7 940的缓存架构 |
对于Core i7 Extreme 940来说,有一处特别的地方就是L3 Cache的存在,L2和L1很相像,都是小容量、低延迟。Xeon E5450就不是这样,因此最终的结果是Nehalem的L2性能要强于Penryn Xeon。由于ScienceMark 2.0认不出Nehalem的L3,因此没有相关的数据。
|
到了内存延迟和内存带宽测试上,Core i7 Extreme 940完胜,这和Nehalem的架构密切相关:
Nehalem的内置内存控制器架构
由于内置了内存控制器,因此内存延迟极低,在使用同样内存基础频率的情况下,Core i7的延迟只有Xeon的2/3,也就是64%左右。在带宽方面,虽然Core i7只具有3个内存通道,而Xeon平台则具有4个内存通道,然而Xeon的内存数据还要经过狭窄的FSB来到达CPU,比起Core i7的完全独享来自然大有不如,因此Core i7 Extreme 940的内存带宽性能测试大约是Xeon E5450的3倍左右。它们的理论带宽分别是25GB(三通道DDR3-1066)和20.8GB(四通道FBD DDR2-667),可见Core i7的内存带宽效率也远比现在的Xeon + 5000X要高。
SiSoftware Sandra Pro Business 2009
SiSoftware Sandra是一款可运行在32bit和64bit Windows操作系统上的分析软件,这款软件可以对于系统进行方便、快捷的基准测试,还可以用于查看系统的软件、硬件等信息。从Sandra 2007开始支持SSE4指令集。SiSoftware Sandra所有的基准测试都针对SMP和SMT进行了优化,最高可支持32/64路平台,这也是我们选择这款软件的原因之一。我们在Core i7 Extreme平台上使用的是Sandra 2009,在E5450使用的是Sandra 2008。
SiSoftware Sandra Pro Business 2009 | ||
| 单Core i7 Extreme 940 | 双路Xeon E5450 | |
Processor Arithmetic Benchmark | ||
| Dhrystone iSSE4.2 | 71538 MIPS | |
| Dhrystone ALU | 110320 MIPS | |
Whetstone iSSE3 | 61616 MFLOPS | 87861 MFLOPS |
Processor Multi-Media Benchmark | ||
Multi-Media Int x16 iSSE4.1 | 148.56MPixel/s | |
Multi-Media Float x8 iSSE2 | 114.78MPixel/s | |
Multi-Media Double x4 iSSE2 | 63.17MPixel/s | |
Multi-Media Int x8 iSSSE3 | 655876 iit/s | |
Multi-Media Float x4 iSSE2 | 358011 fit/s | |
Multi-Core Efficiency Benchmark | ||
Inter-Core Bandwidth | 39.17GB/s | |
Inter-Core Latency | 16ns | |
Memory Bandwidth Benchmark | ||
Int Buff'd iSSE2 Memory Bandwidth | 19.11GB/s | 6264 MB/s |
Float Buff'd iSSE2 Memory Bandwidth | 19.11GB/s | 6262 MB/s |
Memory Latency Benchmark | ||
Memory(Random Access) Latency | 94ns | |
Speed Factor | 64.50 | |
Internal Data Cache | 4clocks | |
L2 On-board Cache | 11clocks | |
L3 On-board Cache | 53clocks | |
Cache and Memory Benchmark | ||
Cache/Memory Bandwidth | 60.02GB/s | 75623 MB/s |
Speed Factor | 27.30 | |
.NET Arithmetic Benchmark | ||
Dhrystone .NET | 16280MIPS | 12358 .netMIPS |
Whetstone .NET | 38076MFLOPS | 52176 .netMFLOPS |
.NET Multi-Media Benchmark | ||
Multi-Media Int x1 .NET | 29.06MPixel/s | 120421 .netiit/s |
Multi-Media Float x1 .NET | 12.59MPixel/s | 27648 .netfit/s |
Multi-Media Double x1 .NET | 24.87MPixel/s | |
SiSoftware Sandra对比(一些测试项目有所不同,如Nehalem上测试的是Dhrystone iSSE4.2,在Penryn上就只是Dhrystone ALU,这是因为Penryn不支持iSSE4.2)
虽然使用的Sandra版本不同,导致了部分数据不能直接对比之外,其他部分仍然可以一比高下。由于双路志强E5450是实打实地具有8个CPU核心,而Core i7的8个执行核心其实是4个CPU核心通过超线程技术“变”出来的,因此处理器的理论性能上Core i7 940不敌同频率的双路Xeon E5450,只有65%(整数)~70%(浮点)左右。
Nehalem的超线程技术
由于超线程技术实际上是使一个处理器内核的所有执行引擎的利用率提升的技术,因此其对性能提升的幅度就不如确实的处理器内核那么高,按照以往Pentium 4的经验,超线程对处理器的性能提升约为10%~30%左右(极少数情况下,还具有负作用),因此我们可以推测出除了超线程之后,Nehalem内核具有的性能提升幅度,考虑到4内核8执行核心的Core i7 2.93GHz相当于8内核Xeon 3GHz的65%~70%,而超线程可以提升10%~30%,则每一个Nehalem物理内核会比一个Xeon E5450内核提升约10%~15%左右。
内存带宽方面,Sandra结果表示Core i7平台的性能是Xeon平台的3倍,与ScienceMark的结果相同。
CineBench R10
CineBench是基于Cinem4D工业三维设计软件引擎的测试软件,用来测试对象在进行三维设计时的性能,它可以同时测试处理器子系统、内存子系统以及显示子系统,我们的平台偏向于服务器多一些,因此就只有前两个的成绩具有意义。和大多数工业设计软件一样,CineBench可以完善地支持多核/多处理器,它的显示子系统测试基于OpenGL。

Core i7 Extreme 940 CineBench R10 64bit测试成绩
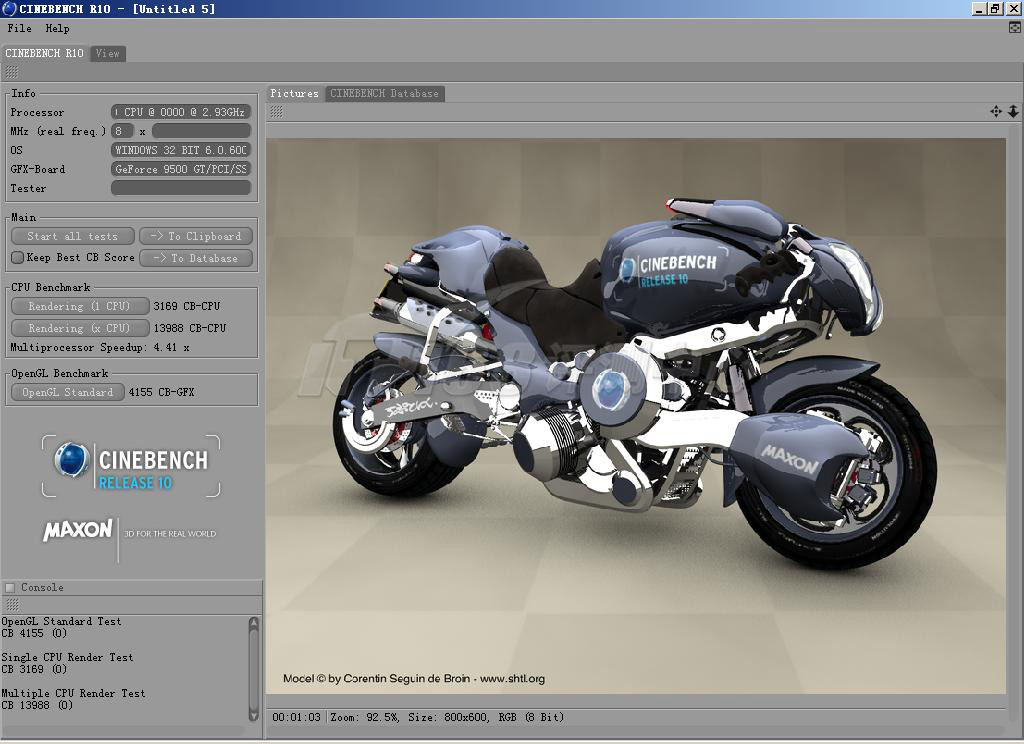
Core i7 Extreme 940 CineBench R10 32bit测试成绩
CineBench R10 64bit | ||
处理器 | 单路Core i7 Extreme 940 | 双路Xeon E5430 |
| 显卡 | NVIDIA 9500GT | 双ATI 3870x2 CrossFire-X |
CPU Benchmark | ||
| Rendering (1 CPU) | 3990 CB-CPU | 3257 CB-CPU |
| Rendering (x CPU) | 16919 CB-CPU | 19452 CB-CPU |
Multiprocessor Speedup | 4.24x | 5.97x |
OpenGL Benchmark | ||
OpenGL Standard | 4599 CB-GFX | 2505 CB-GFX |
没有采用E5450,不过我们有E5430的成绩,E5430的频率为2.66GHz,架构与E5450相同
单处理器的渲染性能,Core i7 Extreme 940要比Xeon E5450高22.5%,这混合了处理器的提升,以及内存子系统的提升。多处理器的渲染性能Core i7不敌Xeon,原因在于Core i7事实上只有4个处理器核心,通过超线程才“变出来”8个执行核心。Multiprocessor Speedup就体现了这个因素:Core i7的是4.24倍,而Xeon则是5.97倍。一方面确实表现了超线程技术并不是真正的多处理器核心,另一方面也表现了Nehalem的超线程技术和多核心化的性能相去也不是很远。例如,8个Xeon物理处理器核心的提升是5.97倍的话,那么4个Nehalem物理处理器核心可以粗糙地认为是3倍提升,则超线程相当于4.24/3 = 1.41倍的性能,也就是说,一个“虚拟”的CPU相当于0.4个“真实”的CPU,Nehalem的超线程技术可以说是比起Pentium 4的远为进化了。仅通过小部分线路就可以获得如此之大的提升,Nehalem的超线程可谓物廉价美。
WebBench v5.0
WebBench是针对服务器作为Web Server时的性能进行测试,我们在被测服务器上安装了IIS6.0组件,以提供测试所需的Web服务。在测试中我们开启了网络实验室中的56台客户端,分别使用了WebBench 5.0内置的动态CGI以及静态页面脚本对服务器进行了测试。
静态测试是由客户端读取预先放置在服务器Web Server下的Web页面(wbtree),这项测试主要考察的是服务器磁盘系统以及网络连接性能。我们使用了实验室中的56台客户端,配合Static_mt.tst多线程静态脚本测试向被测服务器发送请求。
动态测试偏重于对服务器CPU子系统的性能测试,它对于Web服务器提供了足够的负载。我们将一个C语言编写的CGI源文件Simcigi.c编译为Simcgi.exe,并将其作为动态测试中的CGI脚本。在测试过程中,每台安装了WebBench客户端软件的PC,会在300秒的时间内持续向服务器发送CGI请求,而控制台会纪录并汇总服务器所响应CGI请求的数据。CGI测试的成绩高低,主要取决于服务器处理器子系统性能的优劣。处理器子系统包括CPU、内存以及内存控制器,CPU频率、缓存以及内存容量大小和内存带宽,都会影响该项成绩。
Nehalem平台 - WebBench静态页面性能
Nehalem Core i7 Extreme 940大约可以达到25000每秒处理请求数,一般的服务器受限于千兆网卡带宽,为18000左右。一般的双千兆网卡捆绑可以达到22000每秒处理请求数的性能。
Nehalem平台 - WebBench动态页面性能
一般双路Xeon 54xx系列服务器动态页面性能可以达到11000左右,单路Nehalem Core i7 Extreme 940可以达到10860左右,略微低于双路Xeon。要记住,Nehalem只有4个物理处理核心,双路Xeon平台则是8个。
如同我们一再强调的那样,WebBench静态页面性能其实非常依赖于网卡带宽,其次,它对内存子系统也具有一些要求,而WebBench动态页面性能则不主要依赖于网卡带宽而依赖于处理器性能、内存子系统性能,依靠着强大的内核、超线程技术、内置三通道高带宽内存,Nehalem平台在所有测试当中力敌至强平台,这充分表明了Nehalem架构的威力,同时,超线程的实力也可见一斑,和真实的处理器核心有一拼之力。
注:
Nehalem处理器使用的IIS 7.0在我们以前的测试当中证明具有强劲的静态页面性能以及相对IIS 6.0较弱的动态页面性能,现在的测试的结果可以更加表明Nehalem的动态页面性能优势。
【IT168评测中心】经过测试,我们对Nehalem的强大有了深刻的认识,经过总结,它可以简单地归结为三个方面:
Nehalem - Core i7 Extreme的黑色LOGO
处理器内核架构
通过各式各样的架构上的改进,并配合SSE4.2指令集,Nehalem处理器架构的性能比Penryn处理器要高10%~20%左右,这和Penryn通过SSE4.1达到主要的性能提升不一样,Nehalem处理器的提升是着实地基于内核架构的提升(其实,SSE4.2指令集的数量很少)。这个数值也和Intel宣称同频率Nehalem比Penryn快约10%的说法相近。
内存子系统
记得Intel的老对手AMD在首次将内置内存控制器运用到x86处理器上的情景么?Athlon处理器,或者说K7处理器,由于内置了内存控制器,并使用了源自DEC Alpha的一系列技术,性能颇为强劲,风头一时盖过Intel,并促使了Core微架构最终代替了Pentium 4的NetBurst微架构。现在Intel也将内置内存控制器运用到了x86处理器上,Nehalem的三通道DDR3内存架构威力巨大,同时具有低延迟、高带宽的特点,从测试上看,延迟比四通道DDR2-667降低了33%,带宽提升了200%!在服务器、工作站应用上可以提升约10%的性能,处理器的数量越多,优势越明显。
超线程技术
对于桌面平台而言,超线程的存在对Benchmark性能并没有太大的提升,不过,在我们的服务器/工作站测试当中,Nehalem的超线程技术却是具有重要的地位:一个虚拟出来的处理器,相当于0.4个实际处理器,而只需要增加少量电子线路就可以达到,在提升能效比、提升计算密度方面具有巨大的优势,在桌面平台上,超线程技术其实也很有效果。超线程技术实是Nehalem的一大杀手锏。
|
| (左)Nehalem - Core i7 |
我们测试的Nehalem处理器并不是面向企业级市场,并且我们目前只能搭建单路平台,然而从测试成绩来看,在合适的条件下,单路Nehalem就可以和双路Xeon Harpertown打个旗鼓相当,未来企业级版本Nehalem的性能更加让人期待了!

