导读:在互联网应用场景下,日志是常见的数据来源。高效、稳定的日志采集传输服务对于企业构建离线/实时数仓、搜索推荐、应用性能管理等都有着非常重要的意义。网易的日志采集传输服务从2011年开始统一建设,技术方案经历了“依赖开源”、“完全自研”、”自研与开源相结合“的三个阶段。当前日志采集传输服务于2019年进行了重构,且已经上线运行3年,稳定支撑了集团内各业务线不同的日志应用场景。
本文主要介绍了网易在日志传输服务建设和上线后的优化过程。今天的分享会分成以下四块:
网易日志采集传输服务发展
Datastream-ng总体设计
核心组件与流程优化
应用效果与未来规划
01 网易日志采集传输服务发展
第一章介绍网易日志采集传输服务的发展历程。

网易做日志采集传输已经有很长一段历史了,从2011年就已经开始了相关的工作。
1. 1.0版本(2011-2014年)
2011-2014年间统称为1.0版本,还算不上一个完善的服务或系统。主要的方案是各个业务线自己部署采用各种各样的开源采集工具,例如flume、logstash-forwarder和fluent等。各个业务自立营地,缺乏统一的任务管理、数据路由、链路管理和完善的监控报警。整体日志采集较为混乱,如果数据有了延迟和丢失难以排查。
2. 2.0版本(2015-2018年)
经过了1.0版本的阵痛之后,在2015年时,网易开发了Datastream(后文统一简称为DS)2.0版本。
该版本抛弃了各业务线自由的采集体系,自研了采集客户端tailfile。网易的离线数仓整体是基于Hadoop体系的Hive数仓,大部分的日志最终是需要归档到HDFS上做离线分析,因此也自研了用于HDFS归档的handler服务。
同时引入了kafka作为数据流中间的消息队列。
任务管理做成了产品,但是依托于数据开发平台,还不是一个独立的可配置任务服务。
这一阶段的主要问题是,随着业务发展发现tailfile的性能比较低,对服务器资源使用控制也不是很好。采集客户端需要部署在应用服务器上和应用服务一起运行,如果采集客户端对资源利用控制不合理,就会对应用本身造成影响。
Handler服务最大的问题在于,当下游HDFS发生故障时,无法合理处理当前Handler中已经持有的数据。当时常见的做法是将Handler还未送出的数据做本地的持久化。Handler就会成为一个有状态的服务,当时的日志体量较大,对其所在机器的磁盘IO性能和存储量要求也很高。下游HDFS恢复后,Handler需要读磁盘,恢复日志发送。
3. 3.0版本(2019-至今)
基于上述问题,2018年计划重构DS,有了当前的DS-NG版本。
DS-NG版本2019年就上线了,至今已有三年时间。在这个过程中也一直在不断完善日志采集传输的体系。
自研了DS Agent作为日志采集器,并且自研了在1.0和2.0版本中缺失的Router服务,用来做数据路由和链路管理,通过这个服务可以统一控制数据流向和大小,对整体的下游服务比较友好。
研发了统一、独立的任务管理平台,当线上任务出现异常时,可以快速定位到出现异常的环节。
抛弃了自研的HDFS归档工具Handler服务,基于Flink实时计算框架研发了sink服务。将kafka中的数据sink到目的端。
4. 日志采集服务的特点
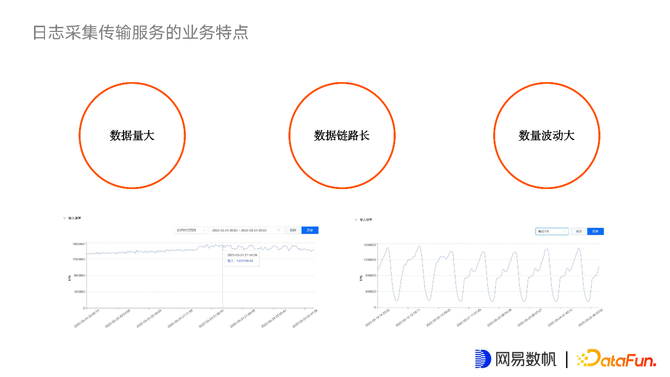
日志采集服务特点:
数据量大。互联网公司大量数仓数据,除了部分来源于在线数据库外,可能80%-90%都来源于埋点数据、后台服务数据、网关数据等,这些数据大都以日志形式储存在机器上。
数据链路长。从采集端到后端数仓或数据湖,做一些数据加工,到后续生成和应用一些指标,数据链路是非常长的。
数据波动大。C端业务都有一些周期性波动,例如白天是低峰期,晚上20-23点是高峰期,对同一个任务,数据量波动较大。同时也指平台上会有不同流量的任务,例如测试打点任务等流量很小,线上用户行为日志则会比较大,如何调配资源给不同任务,也是后续优化过程中不断改进的目标和方向。
5. 系统设计目标
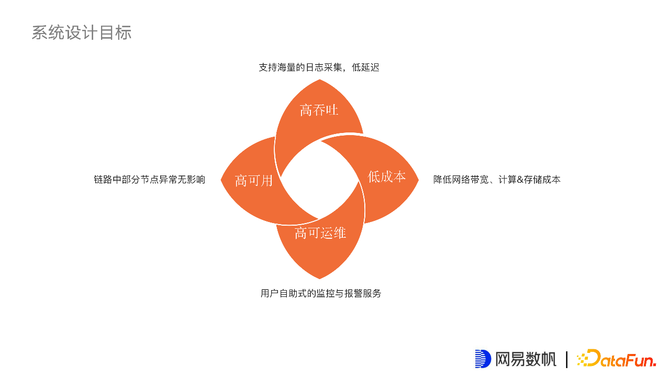
高吞吐:支持海量日志采集,低延迟。
高可用:链路中部分节点异常无影响,日志采集链路较长,部分节点出现异常之后,希望对所有链路没有大的影响。
高可运维:用户可以自助式的监控自己的采集任务,并且有完善的报警机制能够及时发现日志采集的问题。
低成本:降低网络带宽、计算和存储成本。
02 Datastream-ng总体设计
第二章介绍DS-NG当前线上版本的总体设计。
1. DS-NG分层架构
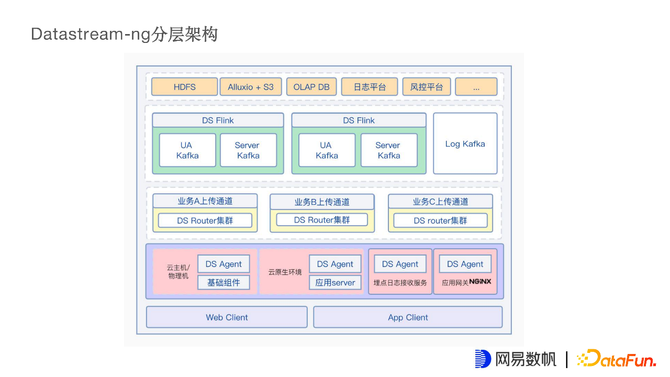
最底层是Web Client和APP Client,属于业务方自己的C端业务或B端业务,会将数据上报给埋点的日志接收服务。由于每个业务方提供给Client的SDK都不一样,因此将埋点日志接收服务交给业务方自己实现。这是DS Agent数据来源的第一个方向。
第二个方向是一些基础组件,例如一些大数据组件的日志,就需要在云主机或者物理机上部署DS Agent采集数据。
第三个是应用后端服务的应用打点日志,当前应用都是基于K8S云原生的Pod运行,DS Agent也适配了这种模式,去采集应用打点的日志。
最后一类是规模比较大的应用网关日志,会在Nginx集群上部署DS Agent采集从不同网关进来的请求日志。
再上一层就是DS Router服务,主要用于数据链路统一管理。根据不同业务,不同流量大小和任务优先级,划分出很多上传通道,上传通道背后是HAProxy集群,集群后是很多DS Router实例。通过上传通道,可以将不同业务和不同重要基本的流量分开,确保流量和业务之间不会相互影响。
再向上一层,通过DS Router将数据进行各种处理之后写入Kafka集群。例如,日志Kafka对接日志平台用于日志查询和分析,通过Kafka直接对接到实时数仓,或通过Kafka对接DS Flink服务,将用户的行为数据、服务端打点数据汇聚到数仓平台、离线数仓。例如HDFS、海外的Alluxio+S3数仓架构。亦或者一些支持OLAP的DB,例如Clickhouse,HBASE等。总之,通过Kafka作为数据的缓冲,将数据分发到业务需要的各种下游服务。
2. DS-NG数据流

如图是DS-NG的整体数据流。
图中灰色的部分是DS自有的服务:
DS任务管控服务是元数据服务,用于管控DS系统上所有日志采集任务。下设DS子域管控服务,部署在不同的机房里,对不同机房中的DS Agent和DS Flink做统一管理。会与管控服务做元数据通信和任务下发。
DS监控服务,将DS自身的埋点数据统一写入Redis和网易自研的时序数据库TSDB中。
当前DS Agent大约有20000多个实例,分别部署在云原生、非云原生等各种环境中。
在网易内部有一个CMDB哨兵系统,用于管理所有应用服务器的应用CICD上线分发。通过它来部署DS Agent并自动配置一些路径,对业务无感知,业务开发无需管理日志采集过程,都由DS系统自动化接管。
K8S集群的宿主机的Node上会启动DS Agent,采集全部Pod上的应用日志。
海外集群不受内部系统管理,通过软件包交付的方式,让运维手动部署DS Agent。
Agent部署之后会注册到DS注册中心(基于Zookeeper实现),通过注册中心可以感知到当前全部Agent的状态是否异常,以及异常的原因。都可以通过注册中心汇报给总控服务。
DS日志采集服务都会先发到HAProxy集群,经过负载均衡后会发送到DS Router集群,经过一系列处理后发送到业务kafka集群。
如果业务系统需要数据可以直接接入到业务kafka集群,或者可以在Kafka后接入DS Flink服务,通过该服务进行更下游的数据分发,做离线、实时数仓等。
上述就是整体的架构,其中有三个类型的数据,如图黑色虚线为管控数据,绿色虚线为监控数据,蓝色为业务日志数据,也是链路中最关注的数据。
3. DS-NG整体设计原则
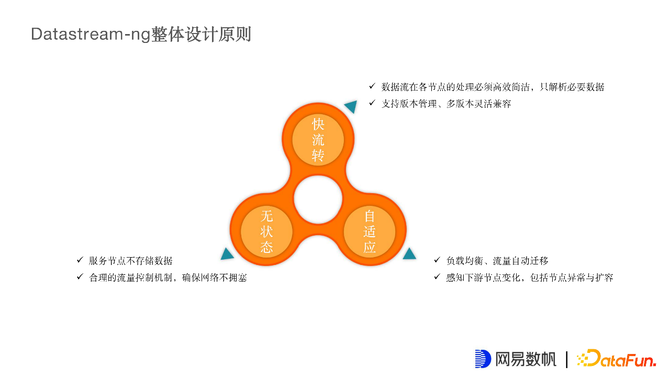
为了达到上文所述目标,在设计新的DS过程中也设计了几个原则:
快流转:数据在长链路中的每个节点上可以尽量快的流转,避免不必要的解析、拆包和装包等工作。
无状态:希望所有节点都是无状态的,可以自由扩缩容,无需考虑服务状态。
自适应:虽然前端已经有根据链接做的负载均衡,但不同链接的流量还是不一样的,因此希望下游节点可以感知自身的负载,并能感知到同机房下其他节点的负载,能自动将高负载节点的流量迁移到其他节点上。
4. DS-NG整体设计原则——快流转
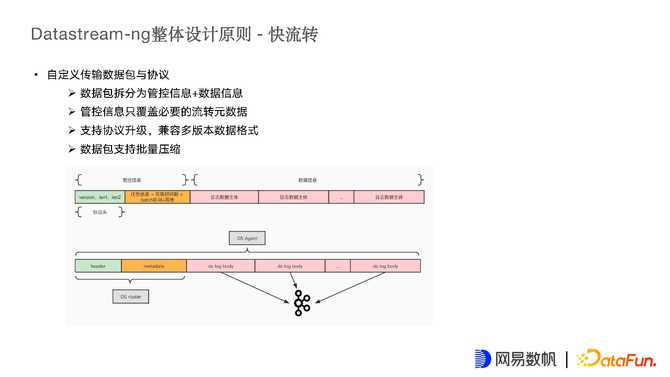
快流转是指希望链路上的节点不要拆包解包或解析数据内容。因此自定义了一套传输数据包和数据协议:
数据包可以拆分为管控信息和数据信息。
管控信息只覆盖必要的流转信息。
支持协议升级,兼容多版本数据格式,以应对不同时期对日志不同的处理逻辑,且向前兼容。
数据包支持批量压缩功能,可以将多个日志的数据主体放在一个数据包中批量发送。
5. DS-NG整体设计原则——无状态

无状态是非常重要的,无状态的系统运维工作可以非常简化,运维难度也会降低很多,对于一个高流量的系统,无状态的设计是非常有必要及合理的。为了实现无状态,做了如下工作:
使用Back Pressure模型。
基于信用的流量控制。
可靠传输设计。
ACK点位信号由目的端发送给源端,标识序列位点之前的消息都被下游可靠地接收了。
CheckPoint由源端用来记录最近的从目的端收到的ACK点位。
当目的端下游发生异常时,目的端返回异常标志位,源端回溯到上次CheckPoint位点重试。
保证At Least Once。
根据以上机制就可以保证数据是至少传输一次的,不会造成数据丢失,最多在异常时会有数据的重传,造成某小部分数据的重复。
如图是表示基于信用的流量控制,参考2018年Flink1.5版本基于信用做的流量控制,并实现了背压模型,DS-NG参考Flink的实现也做了相同的工作。
基于信用的流量控制,是为了防止数据阻塞在网络和下游节点中,实现了拥塞控制,当下游节点出现异常时,上游可以自动感知到,不再向下游发送数据,避免更多数据阻塞在网络或下游的节点中。
具体实现方法,上游在向下游发送数据时,不仅发送原本需要传输的数据,还要告诉下游当前待发的数据量,下游服务可以根据自身能力,例如池化管理、内存大小控制等感知到自身能接收的数据量。下游接收数据后,不仅返回给上游当前数据的成功状态,还要告诉上游当前下游还有多少空间供上游发送数据。上游感知到下游发送的信用值后,下次发送上游只会发送下游可承受的数据量,通过上下游协议控制,可以保证数据不会被阻塞在网络中,达到动态平衡的效果。
由于DS-NG的Router服务写Kafka,Kafka一旦返回成功,Router就会发送ACK和可接收的数据量给上游Agent,根据当前下游能力去判断是否继续采集应用服务的日志。当下游异常时,下游无法接收数据,Agent就收到了反压,将数据压在应用服务器上,采集过程就停止了,当下游恢复正常状态后,会通知上游可以接收数据,Agent会重新启动采集线程来采集应用服务器上的日志。
这样做可以让链路上所有节点,除应用服务器本端需要存储原始日志外,下游所有节点都无需额外存储业务日志数据,保证了无状态的设计
6. DS-NG整体设计原则——自适应
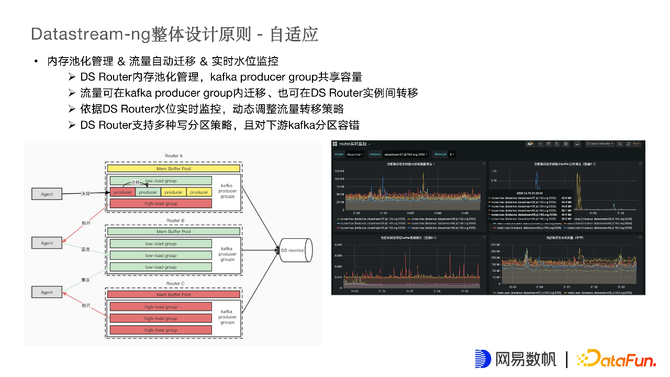
自适应主要是指Agent和Router在链接时会有流量不均衡的情况,因此Router设计了内存的池化管理,开发了流量自动迁移逻辑并配置了实时水位监控。通过这些步骤,Agent就可以自适应地选择一个合理的Router。
DS Router内存做了分区管理,Router中的Kafka生产者组共享内存池,在初始时会给每一个Router分配内存池,若新数据来内存不够时会向buffer申请新的内存池,当Router中的内存池被申请光时,Router就是高负载状态,这时,Agent将不再连接这个Router。Router能够将当前的Agent链接断开,让其尝试链接空闲的Router实例。以上是Router实例间的自适应切换。
在Router实例内也有类似的迁移,Group下有很多Producer,也具备水位概念,也有中低高的概念,组下高水位的Producer无法处理数据时,会自动让Agent链接到空闲的Producer上。这样既能保证实例间的自适应迁移,也能保证实例内的自适应迁移。
Router在写入kafka是也支持多分区的策略,根据不同业务的需要,有不同的写入策略。
例如一些业务要求同一个日志文件中的数据在kafka分区中是有序的,要保证在kafka分区中的顺序和原始日志一致。最常见的做法是建一个大分区的kafka topic,这样能保证写入顺序和原始日志一致,但显然不太合理。通过对文件做唯一标记,将某个文件的数据唯一写到某个分区上,从而实现文件中日志顺序与kafka分区中顺序一致。
还有一类场景是业务要求kafka分区中的数据是均衡的,方便下游消费。因此Router也对下游均衡性做了很大调整,第一版时想做绝对均衡,每条日志轮询全部分区,保证所有数据非常均衡,每个分区数据量相同。后来发现,这样做虽然可以保持分区数量一模一样,但会对目标端的kafka带宽压力非常大。原因是没有发挥出kafka Batch sink的性能,每条数据独立装包发送,如果发送10w条数据,就要发10w个包给到kafka Server端,造成Server端很大的压力。后来就放弃了强一致,强均衡的策略,使用批量均衡的策略,即每个分区写一部分数据,每次写1w、2w或者根据时间写一部分数据做Batch sink,然后再换下一个分区做同样的事情。达到一定运行时间后,分区也是相对均衡的,既能达到分区均衡的目的,也能让Kafka Server的网络压力不那么大。
03 核心组件与流程优化
接下来分享一些在运行一段时间后进行的核心组件和流程的优化。
1. 核心组件与流程优化——DS Agent

首先是对 DS Agent 的优化。
在2.0中,对tailfile的设计比较头疼,后来重新设计了Agent的采集模型,目标是保证性能的同时对CPU占用进行优化。
CPU优化的手段是对文件进行分类,将日志文件看做作业的概念,采集一个日志文件就是定义了一个作业,作业分为不同类型。日志文件有生命周期概念,可以分为快作业、慢作业和不活跃作业,阈值在系统中可配置。
例如每隔5s产生一条日志的为慢文件,每秒都有数据产生的为快文件,很久不产生数据的文件为不活跃文件。
针对不同类型的文件有不同的采集策略,对于快文件使用任务队列加轮询工作线程不断消费快队列中的文件,每采集一段时间或一定条数后,重新放回队列尾部,进行下一次采集。对于慢作业,采用了Linux的inotify事件驱动机制,不会主动探测文件是否有变化,通过Inotify主动上报文件发生了长度变化或文件打开操作等。通过操作系统事件驱动方式,可以异步监听文件变化,无需再设计一个长期工作线程来轮询或发现慢作业是否应该被采集。对于不活跃作业,使用定时工作线程,定时检查是否有长度变化,如果有则说明有新增数据,将新增数据的部分作为快作业,重新发回到快作业队列中去采集。
对内存的优化和Router一样,有对内存的预分配机制,空闲时再进行回收,只有在快作业时,会给作业分配一定的内存空间,快速地去采集、读写和发送。慢作业和不活跃作业都会分配比较小的内存。
第三点是对磁盘IO的保护,在高峰期日志量特别大的时候,如果不控制Agent的采集发送速度,会对磁盘IO产生非常大的影响,对下游的系统也会有很大的影响。所以在Agent基表做了限流,可以控制Agent每秒采集的量。
2. 核心组件与流程优化——DS HDFS Sink

数据主要还是进入到离线数仓,因此介绍一下HDFS Sink的优化。
基于Flink作业,本身提供了Exactly once特性,可以保证Kafka到HDFS中间的数据是准确无误的。其次利用日志数据时间和空间上的连续性特征,增强Batch sink效果。日志本身是空间、时间连续性比较明显的数据,来源于相同服务器的数据,数据相似性比较高,在时间上先后的连续日志相似性也比较高。基于这种认知,对数据Batch sink做了一些优化。
如图,首先Kafka Source算子负责提取日志分区中的元数据,接下来是自定义的Partition算子,主要用于定义分区策略。
例如服务器埋点日志等非网关日志和服务器本身IP、Host name等比较相关,因此就会提取原始日志中的host name或IP做hash key。网关日志则提取日志中client ip作为hash key。来源相同的日志大概率相似性较高。
在分区策略中,维护了去中心化的hash路由表。Partition算子很多,为了能有很好的Batch sink效果,下游HDFS Sink算子上需要保持来自同一个服务器或同一个Client IP的数据,因此在分区算子上,就需要保证所有算子的路由表一致,发送数据的链路才能相同。
起初是想基于中心化的方案控制绝对的相同路由表,后续发现并没有这个必要,数据日志是实时长期作业,只要制定大家共识的hash或排序算法,在算子内部维护单独的路由表是可行的。刚开始的两个Partition算子的路由表是不太一样的,通过相同的排序规则,一段时间之后自然而然就会变成相同的,通过这样的处理,可以去除维护中心化路由表的工作。通过每个Partition算子内部内存的维护就可以达到一段时间之后路由表都相同。就能保证下游HDFS Sink算子内部的数据是高度相似的。
在HDFS Sink算子中缓存了上游来的批量数据,并在这个过程中还会等待一段时间,攒满一定条数或时间后,按时间排序后写入HDFS。
通过这样一个优化过程,对存储空间有较大的节约,大约是1:6的水平,之前能存1份数据的空间,当前通过压缩可以保存6份。改善效果较为明显。
由于中间有了分区逻辑,因此无法直接使用Flink的SQL去实现,因此这套逻辑是基于Flink base用API实现的Flink Job。中间的CheckPoint也是自己实现的。如图CheckPoint看起来也是比较清晰的,需要保留Kafka offset和HDFS文件的bucket,写了多少文件,每个文件进度多少,都需要作为CheckPoint的数据结构存储下来。正常情况下是顺序执行的,每隔一段时间打一个CheckPoint出来,某次出现CheckPoint失败则回退到上一个CheckPoint。
Kafka侧较为简单,原本就支持流量回放,通过reset offset即可重放流量,HDFS则利用了其API提供的truncate能力,将其已经输出的数据直接truncate。这样就能保证整个流程是Exactly once。
Flink的Exactly once是基于其上下游都要支持事务的能力。如果下游目的端不支持事务,Flink也无法保证整个过程Exactly once。
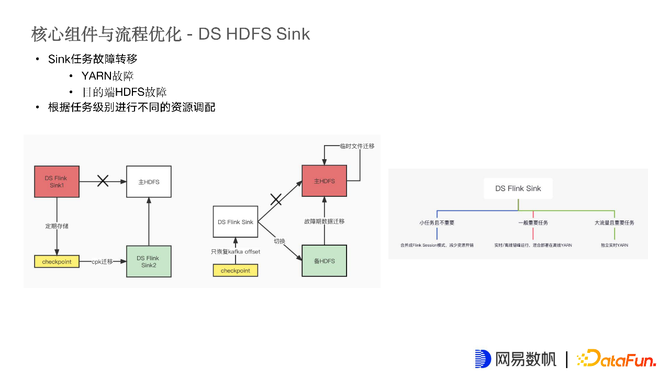
再来讲一下HDFS这里的故障转移相关话题。
Sink任务故障转移主要分为两类:
YARN故障,如左图所示,只需要有能力将当前YARN上的CheckPoint迁移到新的Flink任务上即可。
目的端HDFS故障,当发现主HDFS异常时,就需要将输入端切断,启用备用HDFS,将Sink端切到备用的HDFS上,并且Flink任务重启时,能够读Kafka的CheckPoint的状态数据回来,备HDFS上已经没有之前的File Bucket状态了。当故障恢复后,需要将备HDFS上的文件进行迁移,迁移到主HDFS上,并且将之前没有挪到准确目录下的临时文件进行写回迁移。
针对任务级别进行不同的资源调配,例如对小流量且不重要的任务,合并成Flink Session模式,减少资源开销,共享一个Job Task。大量减少小人物占用资源的问题。一般重要任务会和离线任务进行混部,通常白天是日志流量高峰,因此白天可以借助离线机器能力做一些数据归档工作。到夜间日志流量变小,可以跑一些离线任务,削峰填谷。对于一些大流量重要任务,独立部署实时YARN。
3. 核心组件与流程优化——链路监控与报警
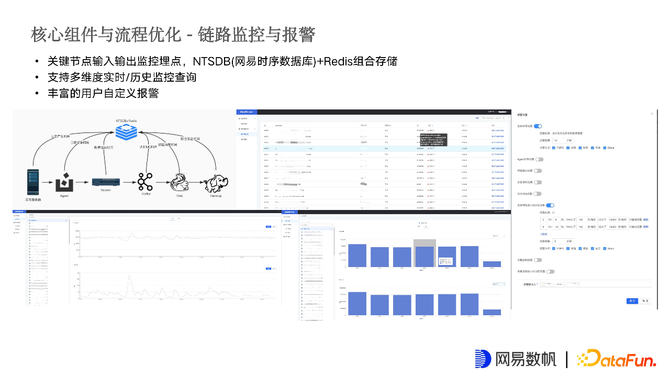
希望长链路的日志服务是可监控、可运维的,报警和链路监控是非常有必要的。在所有关键节点上都进行了监控埋点,并结合NTSDB存储监控数据,时序数据库存储历史的可做同比环比对比的数据,一些看过即毁的例如采集列表等数据则保存在Redis中。
设计支持多维度实时/历史监控查询。
支持丰富的用户自定义报警。用户可以配置任务报警,数据延迟报警、数据堆积报警等,基本可以监控到的数据维度都可以让用户来配置告警。
04 应用效果与未来规划
最后讲一下应用效果与未来规划。
1. 应用效果
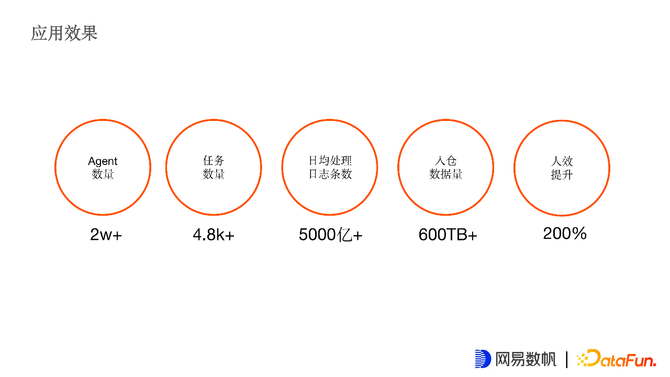
目前DS在网易内部部署的Agent数量有2w+部署在K8S和云主机环境都有,任务数量线上有将近5千个。日均日志处理条数是5000亿条,进入离线数仓的数据量大约是一天600TB左右。对比2.0的任务配置方式,新版DS人效提升达到200%。
2. 未来规划
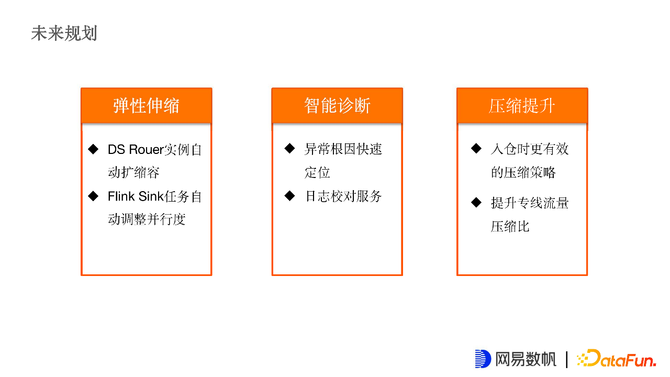
未来规划是想做更加智能的运维:
弹性伸缩,目前为止,DS Router虽然有完善的监控,但仍然需要运维通过监控去实时看到Router的水位情况,手动做扩缩容操作,还未做到弹性扩缩容。Flink任务也没有自动并行度调整机制。希望后续可以和智能运维团队合作,能够做到Router和Flink任务自动的伸缩效果。
智能诊断,希望能做异常根因快速定位,由于链路较长,一般有日志延迟或丢失,希望能快速定位到根因在什么地方。第二点是日志校对服务,初期比较头疼用户反馈丢失了某一两条日志,这种情况排查非常困难,每天上千亿条日志,从中找出一两条就会比较难。
压缩提升,希望入仓是能有更好的策略。跨机房专线流量上有比较好的压缩比效果。

