据了解,Databricks公司最近在企业人工智能市场中成为了赢家。这家初创公司日前以380亿美元的估值获得了16亿美元的H系列资金。而这个最新一轮的投资是在Databricks公司筹集了10亿美元之后几个月进行的。
Databricks公司是为统一、处理和分析存储在不同来源和架构中的数据提供服务和产品的几家公司之一。其他公司还包括去年进行了大规模首次公开募股(IPO)并拥有900亿美元市值的Snowflake公司,以及去年上市的另一家企业人工智能提供商C3.ai公司。
为什么投资者会青睐Databricks这样的公司?因为这些公司正在解决阻碍企业尝试启动机器学习项目以降低运营成本、改进产品和用户体验并增加收入的一些最主要的挑战。
人们对于Databricks这样的公司可以为企业人工智能市场带来什么而感到兴奋。但该公司的这一巨额估值是否合理,还是成为市场炒作的副产品仍有待观察。鉴于这些公司的结构及其商业模式,尚不清楚它们将如何继续保持投资者预期的增长,以及它们是否能够承受一些科技巨头带来的长期和不可避免的市场竞争。
解决数据问题
许多企业正试图改善数据驱动的运营并启动机器学习项目,但很难利用他们的数据基础设施。得益于可扩展的云计算服务,企业能够收集大量数据,而无需对IT基础设施和人才进行前期投资。
但是,使用这些数据说起来容易做起来难。对于一些大企业来说,数据通常分布在不同的系统中,并以不同的标准存储。它们结合了基于模式的传统数据仓库和无模式的数据湖,并存储在企业的内部部署服务器和云平台中。不同的数据存储可能使用不同的规则来注册相似的信息,从而使它们彼此不兼容。一些数据库可能包含敏感信息,这对将它们提供给不同的数据科学和商业智能团队带来了很大挑战。
所有这些问题都使得企业整合数据和准备机器学习模型和商业智能工具使用数据变得非常困难。事实上,一些调查表明,应用机器学习项目中的主要障碍与数据工程任务和人才有关。
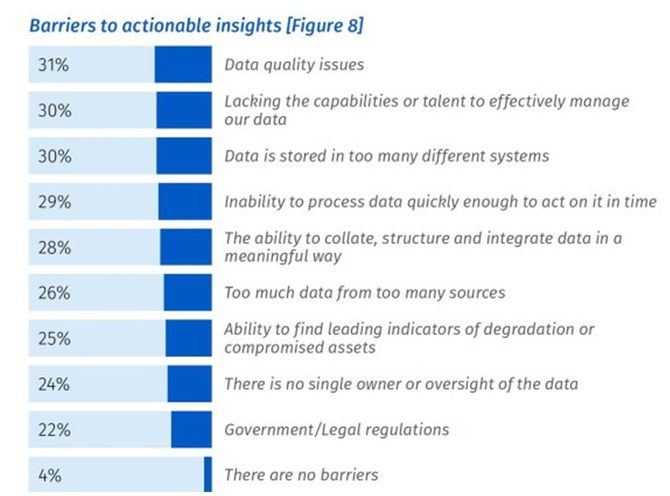
图中数据解释了从机器学习模型中获得可操作见解的大多数关键问题
这是像Databricks这样的公司正在解决的问题。Databricks公司的联合创始人包括采用Apache Spark、Delta Lake和ML flow的开发人员,这三个开源项目已经成为在非常大的不同数据源上运行的机器学习项目的关键组件。Apache Spark是一种分析引擎,可以处理各种格式的大量数据;Delta Lake是一个存储层,将数据湖和数据仓库结合在一个架构中,可以像传统数据库一样查询;ML flow是一种用于管理机器学习管道和跟踪不同版本模型的工具。
Databricks公司采用主要云计算服务Lakehouse使用所有这些项目将不同的数据源整合在一起,并使数据科学家和分析师能够从单个平台运行工作负载。
该公司的统一平台使商业智能和机器学习团队可以轻松协作和共享工作空间,它通过提供对不同数据源的统一访问来减少数据工程的负载。而在背后,它可以处理不兼容的模式、匿名化以及流数据和批处理数据之间的切换等问题。
与同一类别中的其他服务一样,Databricks的平台支持Microsoft Azure、AWS和Google Cloud,这是大多数企业用来存储数据的云计算基础设施。这使Databricks公司能够利用主要云计算提供商的坚固且可扩展的基础设施,并避免其客户迁移数据的需要,但也会给其业务带来一些风险。
大客户
Databricks公司的服务对于拥有大量未开发数据的企业来说具有巨大的价值。
例如,阿斯利康公司使用Databricks的平台来统一数百个内部和公共数据源。这导致更快和更顺畅的查询、更好的团队协作和更快的操作,这对于一个花费数十亿美元和多年研究寻找有希望的假设和运行实验的行业来说至关重要。
汇丰银行使用该平台改进其欺诈检测系统和推荐引擎。该银行能够将14个数据库整合到一个Delta Lake中,并将其提供给数据科学和机器学习团队使用。Delta Lake的设立是为了满足一些法律和监管要求,例如在将客户数据发送到机器学习模型之前对其进行匿名处理。改进后的数据管道使操作速度提高了几个数量级,并帮助机器学习团队加快模型的开发、训练和调整。其总体结果是客户体验得到改善,银行移动应用程序PayMe公司的用户参与度增加了4.5倍。
而如果了解一下Databricks公司的竞争对手,就会发现类似的趋势。C3.ai公司的客户包括石油和天然气巨头、政府机构、大型制造商和医疗保健公司。而Snowflake公司为超市和连锁餐厅、包装食品和饮料公司以及医疗保健组织提供服务。
大型科技公司对企业数据管理和人工智能服务也很感兴趣,但市场仅限于无法建立自己的数据管道或处于机器学习项目初始阶段的企业。大多数大型科技公司都拥有内部人才和工具,可以根据自己的需求定制数据基础设施,并充分利用开源和云服务。一个有趣的案例研究是Twitter公司使用内部部署和基于云的数据管理服务来运行机器学习工作负载。
竞争激烈的市场
在最新一轮融资中,Databricks公司报告了6亿美元的年度经常性收入(ARR),高于2020年的4.25亿美元。这种令人兴奋的增长吸引了投资者向该公司投入更多资金。Databricks公司获得380亿美元的估值主要是由于投资者押注该公司维持这种增长速度的能力。
但是,Databricks公司及其竞争对手必须克服一些挑战,例如市场竞争非常激烈。正如Databricks公司首席执行官Ali Ghodsi所说,“Data lakehouses是一个新类别,因此这是争夺市场份额的项目。我们希望尽快构建并完成这一项目。”
在某些市场中,企业通常利用网络效应或卓越的数据来锁定客户,并保持对竞争对手的优势。在数据处理行业,市场动态是不同的。虽然Databricks公司提供了一种非常有用的技术,但它并不是其他公司无法复制的。由于该公司的技术建立在主要云计算提供商提供的云计算服务之上,因此客户转向竞争对手几乎没有障碍。
这意味着获得成功将在很大程度上取决于市场参与者的客户获取策略以及他们通过持续创新留住客户的能力。
而业务的增长还将在很大程度上取决于该公司将获得的客户类型。Databricks公司在最新一轮融资中宣布其拥有5,000个客户。由于该公司尚未申请首次公开募股(IPO),人们不知道其财务细节。但如果有任何市场竞争的迹象,其收入的很大一部分来自少数一些规模非常大的客户。例如,C3.ai公司2020年收入的36%来自贝克休斯(Baker Hughes)和恩吉(Engie)公司。根据Snowflake公司提交的S-1文件,其2020年上半年近30%的收入来自其3,000个客户中的153个。
只要这几家公司能够获得愿意花费大量资金的大客户的支持,它们的业务就会增长。但一旦市场饱和,其增长将趋于平稳。然后,他们将不得不向现有客户追加销售新服务,而这么做是非常困难的;如果通过提供更具竞争力的价格来相互抢夺客户,但这将降低收入。每个大客户的流失都将对这些公司的财务状况产生巨大影响。
市场的未来发展
市场的竞争性将对推动企业人工智能公司快速创新产生积极影响。但在某个时候,市场将面临来自大型科??技公司的激烈竞争。
全球主要三个云计算提供商的产品都可以演变成Databricks提供的那种服务。例如,谷歌公司有BigQuery,微软公司有Azure Synapse,亚马逊公司有Redshift。
一旦市场发展成熟,预计云计算巨头将会采取行动来争夺更多的份额。鉴于其财力雄厚,这三家云巨头可以收购规模较小的数据管理公司,也能够以更具竞争力的价格收购其客户。
在这三家云巨头中,应该特别关注的是微软公司,由于其企业协作工具,该公司已经在Databricks和其他公司蓬勃发展的非技术市场获得了很大的份额。
微软公司也在和Databricks公司开展合作,Databricks公司的很多大客户都运行在Azure Databricks平台上。而微软公司也有将合作伙伴关系转化为收购的历史。
而在与行业媒体的探讨中,Ghodsi公司并不排除首次公开募股(IPO)的可能性。但如果这家公司最终成为微软的子公司,也不会让人感到惊讶。

