【IT168 编译】网站登录验证码的存在一直让人感到不爽,因为输错一个字往往就意味着账号密码什么的就得重新再输一遍。更有甚者(如12306网站),仅仅验证码一道工序就把人整到怀疑人生。不过看了国外一位大神的分享,小编我算是知道为什么12306网站要把验证码设置的这么变态了!
愿世间少一些套路,多一些真诚。

以下是原文:
相信每个人都对验证码没有好感——你必须输入图像里的文本,然后才能访问网站。验证码的设计是为了防止计算机自动填写表格,以此验证你是一个真实的人。但随着深度学习和计算机视觉的兴起,它们现在已经变得脆弱不堪。
我一直在读一本由Adrian Rosebrock写的《Deep Learning for Computer Vision with Python》(用Python实现机器视觉的深度学习)。在这本书中,Adrian通过机器学习,在E-ZPass纽约网站上绕过了验证码阶段:
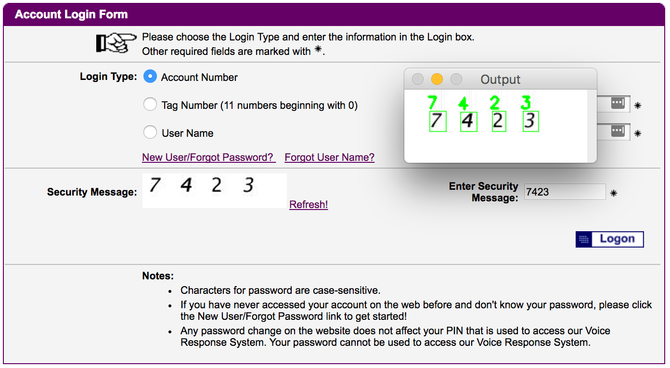
Adrian没有访问生成验证码图像的应用程序的源代码。为了打破这个系统,他不得不下载数百个示例图像,并手动输入每个图像对应的验证码来训练他的系统。
但是,如果我们想要破坏一个开源的验证码系统,在哪里我们可以访问源代码呢?
我在WordPress.org网站(一个插件下载网站)上搜索了“captcha”。网页置顶的搜索结果为“Really Simple CAPTCHA”(“真正简单的验证码”,一个验证码生成插件),其活跃安装次数超过100万:
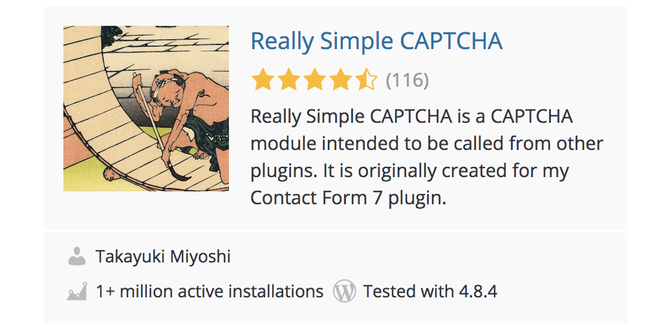
最棒的是,我们可以利用它获得生成验证码的源代码,所以这应该很容易被打破。为了使任务更有挑战性,我决定给自己一个时间限制。15分钟内,能否彻底破解这个验证码系统?擦亮眼睛看吧!
重要提示:这绝不是对该插件或其作者的挑衅或某种程度上的鄙视。插件作者自己也说它已经不安全了,建议你使用其他东西。这只是一个有趣和快速的技术挑战,但如果你是其100万用户之一,或许你应该换一个插件了:)
挑战开始
为方便定制攻击计划,我们首先看一下该插件会生成什么样的图像。在演示网站上,我们看到:

▲验证码图像展示
从图像看来,验证码明显是四个字母,不过我们要在PHP源代码中验证这一点:
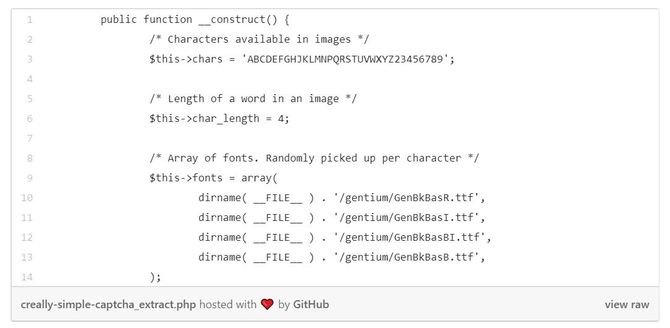
是的,它使用4种不同字体的随机组合生成4个字母的验证码。我们可以看到,在代码中它从不使用“O”或“I”,以避免用户混淆。这就给我们留下了32个可能的字母和数字。
目前记时:2分钟
我们的工具集
在我们进一步讨论之前,先来罗列一下解决这个问题的工具:
Python 3
Python是一种很有趣的编程语言,有很好的机器学习和计算机视觉库。
OpenCV
OpenCV是一个流行的计算机视觉和图像处理框架。我们将使用OpenCV来处理验证码图像。它有一个Python API,所以我们可以直接从Python中使用它。
Keras
Keras是一个用Python编写的深度学习框架。它能够以最少的代码定义、训练和使用深度神经网络。(这个评价可能不够客观。)
TensorFlow
TensorFlow是谷歌的机器学习库。我们会在Keras中编码,但是Keras并没有真正实现神经网络逻辑本身。因此,它使用谷歌的TensorFlow库来完成繁重的任务。
好的,回到挑战!
创建数据集
训练任何机器学习系统,我们都需要训练数据。要破解验证码系统,我们需要这样的训练数据:

因为我们有了该插件的源代码,所以我们可以通过修改它来保存10000个验证图像,以及每个图像的预期答案。
在对代码进行了几分钟的黑客攻击并添加了一个简单的for循环之后,我有了一个包含训练数据的文件夹—10,000个PNG文件,每个文件都有正确的答案作为文件名:

目前记时:5分钟
简化这个问题
现在我们有了训练数据,我们可以直接用它来训练神经网络:
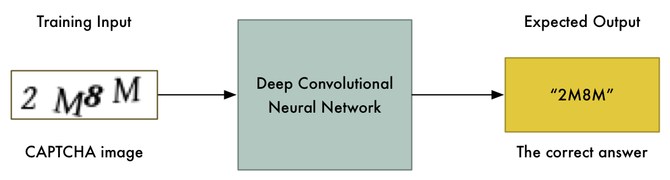
如果有足够的训练数据,这种方法甚至可能直接产生效果——但我们要使问题变得更简单。问题越简单,训练数据越少,我们解决它所需的计算能力就越小。毕竟只有15分钟!
幸运的是,验证码图像通常只由四个字母组成。如果我们能把图像分割开来,这样每个字母都是一个单独的图像,那么我们只需训练神经网络一次识别单个字母:
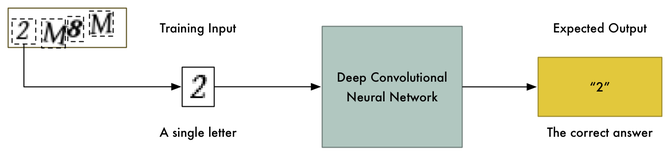
我没有时间去挨个查看10000个训练图像,然后用Photoshop将它们手工分割成不同的图像。这需要几天的时间,我只剩下10分钟了。我们不能将图像分割成4个等分大小的块因为验证码随机将字母放置在不同的水平位置,以防止出现这样的情况:

▲每个图像中的字母都是随机放置的,使图像分割变得更加困难。
幸运的是,我们仍然可以实现自动化。在图像处理中,我们经常需要检测具有相同颜色的像素的“blob”。这些连续像素点的边界称为轮廓。OpenCV有一个内置的findContours()函数,我们可以用来检测这些连续区域。
我们将从一个原始的验证码图像开始:
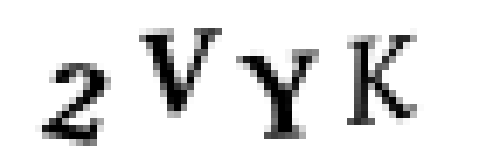
然后我们将图像转换成纯黑和白(这称为阈值化),这样就很容易找到连续区域:
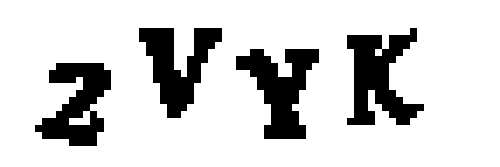
接下来,我们将使用OpenCV的findContours()函数来检测图像中包含相同颜色连续的像素点的图像的不同部分:

然后这就变成了一个简单的问题,可以把每个区域作为一个单独的图像文件保存。因为我们知道每个图像应该包含四个从左到右的字母,所以我们可以用这些知识来标记我们保存的字母。只要我们按这个顺序把它们存起来,应该就可以用正确的字母名称来保存每一个图像字母。
但是等一下——我发现问题了!有时验证码有这样重叠的字母:
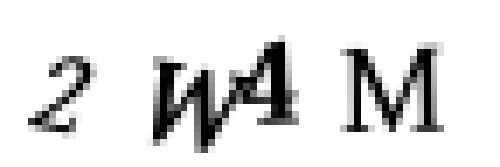
这意味着我们最终会将两个字母组合成一个区域。

如果我们不处理这个问题,我们就会产生“很脏”(dirty)的训练数据。我们需要解决这个问题,防止机器接受训练后仍然靠运气识别这两个重叠在一起的字母。
这里有一个简单的窍门:如果一个等高线区域比它的高度宽得多,那就意味着可能有两个字母在一起被压扁了。在这种情况下,我们可以把这两个字母放在中间,把它分成两个独立的字母:
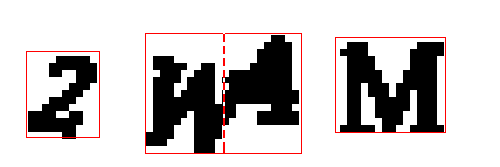
▲我们将把比它们高得多的区域分割成两半,把它看成两个字母。这里有黑客行事风格的嫌疑,但是对于验证码来说,它是可行的。
现在我们有了一种提取单个字母的方法,接下来在所有的验证码图像中运行这个方法。目的是收集每个字母的不同变体。我们可以把每个字母都保存在自己的文件夹里,井井有条。
这是我摘取所有字母后的“W”文件夹的图像:

从我们的10,000个验证码图像中提取的一些“W”字母。我最终得到了1,147个不同的“W”图像。
目前记时:10分钟
建立和训练神经网络
因为我们只需要识别单个字母和数字的图像,我们就不需要一个非常复杂的神经网络结构。识别字母比识别像猫和狗这样的复杂图像要容易得多。
我们将使用一个简单的卷积神经网络结构,它有两个卷积层和两个完全连通的层:

如果你想知道更多关于卷积神经网络的工作原理以及为什么它们是图像识别的理想方法,请查阅Adrian的书。
定义这个神经网络体系结构只需要使用Keras的几行代码:
# Build the neural network!
model = Sequential()
# First convolutional layer with max pooling
model.add(Conv2D(20, (5, 5), padding="same", input_shape=(20, 20, 1), activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# Second convolutional layer with max pooling
model.add(Conv2D(50, (5, 5), padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# Hidden layer with 500 nodes
model.add(Flatten())
model.add(Dense(500, activation="relu"))
# Output layer with 32 nodes (one for each possible letter/number we predict)
model.add(Dense(32, activation="softmax"))
# Ask Keras to build the TensorFlow model behind the scenes
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
现在我们可以训练它了!
# Train the neural networkmodel.fit(X_train, Y_train, validation_data=(X_test, Y_test), batch_size=32, epochs=10, verbose=1)
经过训练数据集10次之后,我们达到了接近100%的准确度。在这一点上,我们应该能够在我们想要的时候自动绕过这个验证码!我们做到了!
计时结束:15分钟。
使用训练的模型来求解验证码
现在我们有了一个训练有素的神经网络,用它来破坏一个真正的验证码是很简单的:
从一个使用该插件的网站上获取一个真正的验证码图像。
用我们用来创建训练数据集的方法将该图像分割成四个不同的字母图像。
让我们的神经网络对每个字母图像做一个单独的预测。
用四个预测字母作为验证码的答案。
狂欢接踵而来!
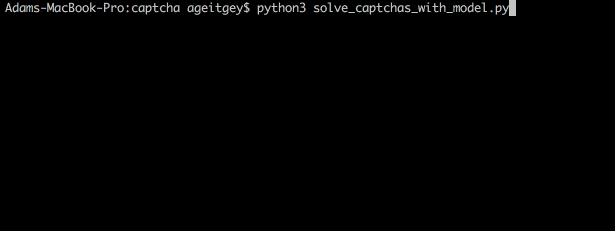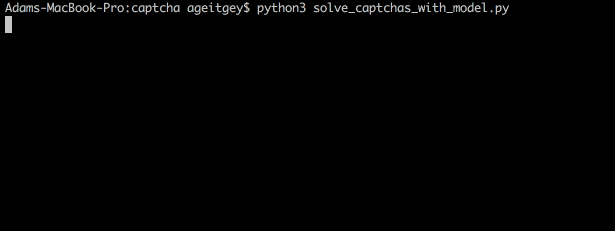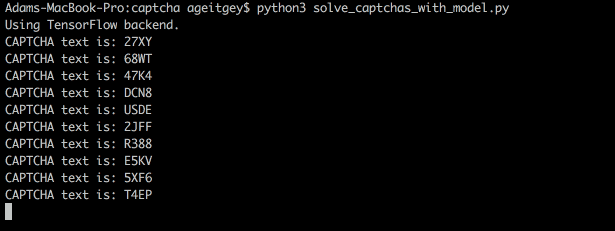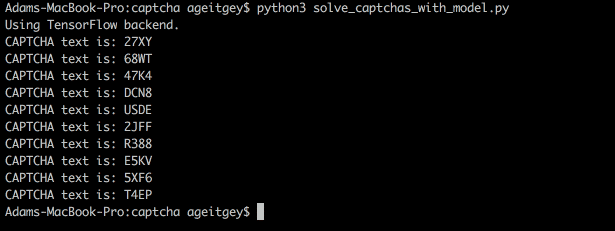
下面是我们的模型如何解码真实的验证码:

或从命令行来看:
试一下!
如果你想亲自尝试,可以在原文中获取代码。文件中包括10,000个示例图像和本文中每个步骤的所有代码。查看README.md文件,可阅读运行说明。

