
【IT168 应用】从CUDA 4.0开始NVIDIA就已经支持GPU Direct v2.0技术。GPU Direct允许GPU进行点对点通信。CUDA中的点对点通信指令允许GPU直接进行信息交互。点对点模式下所获得的有效通信带宽取决于GPU与系统连接的方式。具有特定通信需求的应用以及开发人员可利用的带宽能够决定使用多少颗GPU以及哪些GPU最符合他们的特定需求。让我们一起了解一下各种使用场景。
PowerEdge C410x是一个3U的机架,如果配置M2090 GPU最多可以配置16颗。最多可以有8台主机服务器,比如PE C6145或者是PE C6100能够通过主机上的主机接口卡以及iPASS线缆连接到C410x。C410x有两层交换机使用iPASS线缆连接到GPU。连接到C410x的所有主机通过非常易用的用户web界面映射到16个GPU上。另外需要提及的一个重点就是GPU与服务器的关联关系可以通过web界面进行变更并不需要对线缆的连接进行任何改变。当前GPU与主机之间的比率是2:1,4:1和8:1,所以单个主机接口卡最多能够访问8颗GPU。
下图从概念上展示了GPU之间的通信过程。C410x有16颗GPU,每颗GPU通过二层交换机与C410x上的8个端口之一进行连接(在图中交换机层用单个交换机表示)。黑线代表的是主机内部的IOH与C410x的交换机之间的连线,红线代表的是彼此通信的两颗GPU。
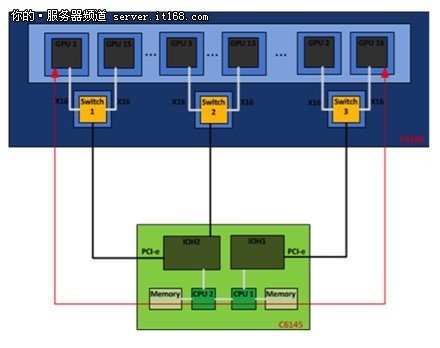
▲图1:GPU通过主机内存进行通信。总带宽大约为3GB/s。
第一种场景:图1展示了GPU通过单个IOH与系统连接的场景。在这种情况下不支持点对点传输,而且消息传递必须通过主机内存。整个操作需要进行设备-主机以及主机-设备之间的消息传递。在消息传递过程中信息是存储在主机的内存中的。

▲图2:通过主机节点共享的IOH进行GPU之间的通信。总带宽大约是5GB/s。
第二种场景:考虑两个GPU共享一个IOH的情况。正如图2所示,GPU连接到同一个IOH但是没有单独的PCIe x16连接。GPU Direct是必要的因为信息不必拷贝至主机内存中,而是直接通过IOH到达对端GPU的内存中。
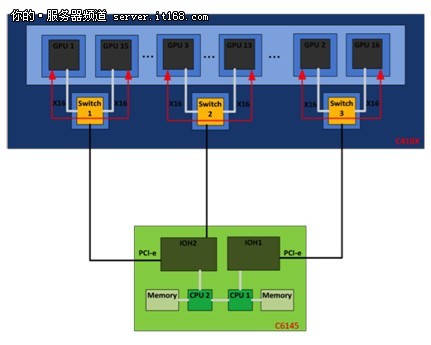
▲图3:GPU通过C410x上的交换机进行通信。总带宽大约为6GB/s。
第三种场景:图3展示了GPU通过C410x上的PCIe交换机进行点对点通信。这是两个GPU之间最短的通信路径。GPU Direct非常有利于GPU之间的通信,因为不必再通过IOH和主机内存进行路由。
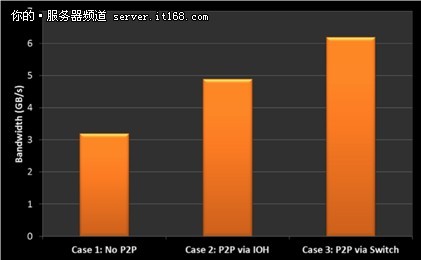
▲图4:上述三种情况下所获得的带宽表明了P2P通信的优势。
测试结果如图4所示,随着GPU之间的距离越来越近,GPU Direct提供了更快的点对点通信模式。通过IOH进行点对点通信时带宽提升了53%,通过交换机进行点对点通信时带宽提升了93%。此外,cudaMemcopy()函数调用能够自动选择在GPU之间可用的非常好的点对点通信方式。这一特性允许开发人员不依赖底层的系统架构使用cudaMemcopy()指令。
综上所述,PowerEdge C410x非常适合使用GPU Direct技术。在设计GPU加速计算系统时PowerEdge C410x所提供的计算能力,计算密度以及灵活性是少有的。
进入高性能计算社区。

