Decode
解码
解码是很有意思的一项设计,通常是类RISC处理器才有的一项设计,从Pentium Pro开始在IA架构出现,基本上,它是x86处理器独有的产品。
RISC架构的特点就是指令长度相等,执行时间恒定(通常为一个时钟周期),因此处理器设计起来就很简单,可以通过流水线设计来达到很高的频率(例如内部类RISC设计31级流水线的Pentium 4处理器……当然Pentium 4要超过5GHz的屏障需要付出巨大的功耗代价),IBM的Power6就可以轻松地达到4.7GHz的起步频率。关于Power6的架构的非常简单的介绍可以看《机密揭露:Intel超线程技术有多少种?》。和RISC相反,CISC指令的长度不固定,执行时间也不固定,这样设计的流水线效率就不会高,因此Intel就实现了一个RISC/CISC混合处理器架构:通过解码器将x86指令翻译为类似RISC的指令,按照RISC的方式设计和运行,从而获得RISC架构的长处,提升内部执行效率。
通常的RISC指令由于简单,因此都是直接运行而不需要进行解码(通常其标明“解码”的阶段其实是上一页“预解码”的工作:确定分支指令/提取参数/指令依赖性检测),然而龙芯2不同:它具备一个真正的解码阶段将MIPS指令翻译为龙芯2的内部指令(后面用微指令来指代),这一点看起来和现在的CISC处理器很相似。Intel的内部指令称为Micro Operation——micro-op,或者写为µ-op,一般用比较方便的写法来替代掉希腊字母:u-op或者uop。相对地,一条一条的x86指令Intel就称之为Macro Operation,或macro-op。
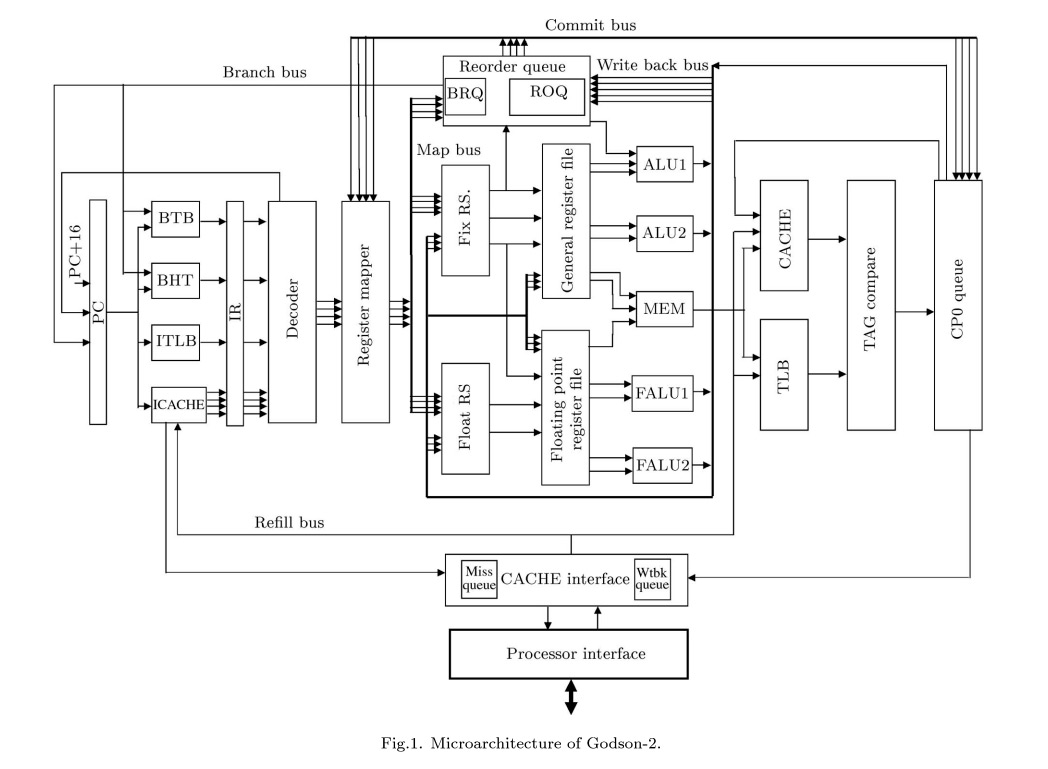
Godson-2 Microarchitecture
类似地,AMD的处理器也通过解码器将x86指令翻译为自己的内部指令,并且和Intel的不相同。内部指令集的选取和微架构息息相关,如何实现足见体现出设计团队的功力。内部指令的存在也让不停增加新的指令更为方面,只需要更新解码器的解码表即可。然而,解码器的存在无疑增加了新的流水级,并且很容易成为瓶颈——x86架构上解码器一直都是瓶颈,因为复杂的x86指令可以解码出非常多的微指令来(当然,将以前无解码器时的微架构设计上的困难集中转移到解码器上确实是一个进步)。
Nehalem的解码器是4个:3个简单解码器加1个复杂解码器,AMD K8则具有三个复杂解码器,龙芯2的数量看起来是四个。为了简化分支管理,每一个时钟周期内只可以解码一条分支指令,整数乘/除指令会被解码成两条微指令。解码是龙芯流水线的第3级。
对于Nehalem的解码器而言,简单解码器可以将一条x86指令(包括大部分SSE指令在内)翻译为一条uop,而复杂解码器则将一些特别的(单条)x86指令翻译为1~4条uops——在极少数的情况下,某些指令需要通过额外的可编程 microcode解码器解码为更多的uops(有些时候甚至可以达到几百个,因为一些IA指令很复杂,并且可以带有很多的前缀/修改量,当然这种情况很少见),下图Complex Decoder左方的ucode方块就是这个解码器,这个解码器可以通过一些途径进行升级或者扩展,实际上就是通过主板Firmware里面的Microcode ROM部分。由于复杂解码器只有一个,因此在碰到复杂指令比较多的时候,Intel的处理器解码效率会下降。
2006年进行的一个研究当中表示,最常用的20条x86指令当中:
mov占35%(寄存器之间、寄存器与内存之间移动数据),push占10%(压入堆栈,也经常用来传递参数),call占6%,cmp占5%,add、pop、lea占4%(实际计算指令非常少)
75%的x86指令短于4 bytes,也就是小于32 bits。不过这些短指令只占代码大小的53%——有一些指令非常长
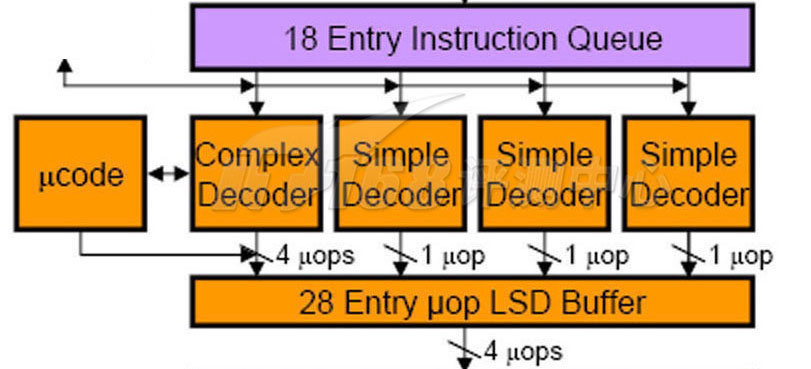
Nehalem: Decode
对x86而言,解码器十分重要。在解码器上,Nehalem做了不少优化,如将多条Macro Ops(就是x86指令)聚合的Macro Fusion和将多条uops聚合的Micro Fusion功能,总的来说是用于降低uop的数量。此外,在各种Fusion之后,Nehalem还会做循环检测,剩下相关指令的、取指、分支预测和解码工作。

